文章目录
- 前言
- [一. 什么是自动化构建工具-make/Makefile](#一. 什么是自动化构建工具-make/Makefile)
- [二. make/Makefile的基本使用](#二. make/Makefile的基本使用)
-
- [2.1 依赖关系和依赖方法](#2.1 依赖关系和依赖方法)
- [2.2 伪目标(.PHONY)](#2.2 伪目标(.PHONY))
- [2.3 stat 指令](#2.3 stat 指令)
- [2.4 推导过程](#2.4 推导过程)
- [2.5 扩展语法------更加通用的Makefile](#2.5 扩展语法——更加通用的Makefile)
- [2.6 测试和优化Makefile](#2.6 测试和优化Makefile)
- [三. 第一个系统程序------进度条](#三. 第一个系统程序——进度条)
-
- [3.1 回车和换行](#3.1 回车和换行)
- [3.2 倒计时程序](#3.2 倒计时程序)
- [3.3 进度条程序](#3.3 进度条程序)
- 最后
前言
在上一篇文章中,我们详细介绍了编辑器vim的使用和理解gcc编译器的内容,内容还是挺多的,希望大家可以多去练习熟悉一下,那么本篇文章将带大家详细讲解make和Makefile自动化构建工具和第一个系统程序---进度条的内容,接下来一起看看吧!
一. 什么是自动化构建工具-make/Makefile
在 Linux(以及整个类 Unix 开发环境)里,make 是一个"任务编排器",Makefile 是它默认读取的"任务说明书"。
make
make是一个命令工具 ,是一个解释Makefile中指令的命令工具,一般来说,大多数的IDE都有这个命令,可执行文件通常是/usr/bin/make。功能 :读取"任务规则",比较文件时间戳,只执行需要重新做 的步骤------最常用来增量编译,但也能跑任意shell命令。
Makefile
Makefile是一个纯文本文件 ,默认文件名就叫Makefile(或makefile)。内容 :一条条"规则",告诉make
Makefile带来的好处就是------"自动化编译",一旦写好,只需要一个make命令,整个工程完全自动编译,极大的提高了软件开发的效率。
总结 :make 是"调度器",Makefile 是"说明书",两者配合,把手工敲的长串命令变成一条 make 就能完成的自动化流程。
二. make/Makefile的基本使用
创建了一个test.c 文件和Makefile 文本文件
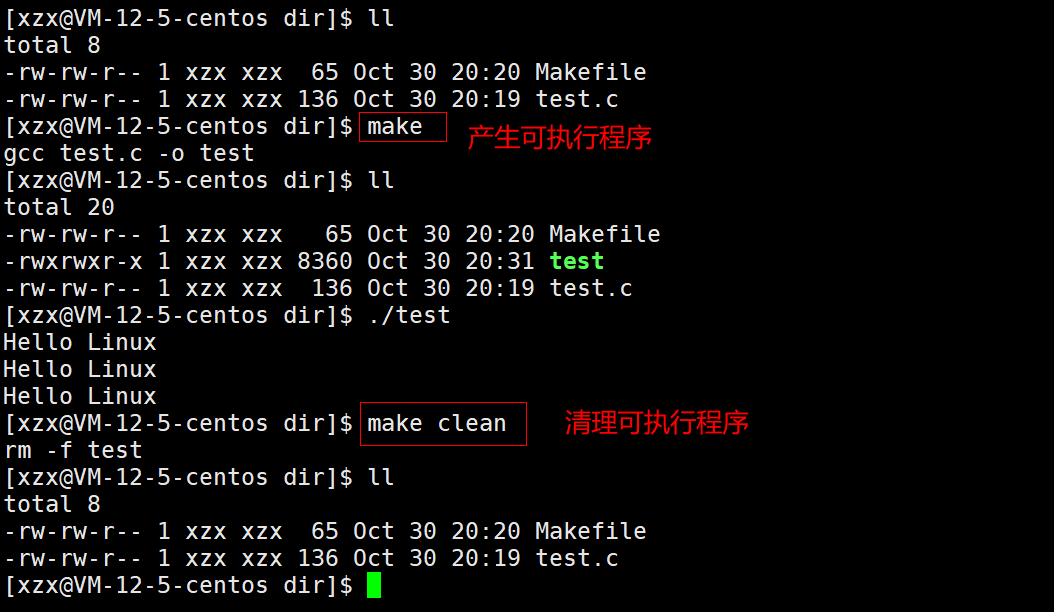
使用make命令可以自动编译test.c 文件产生test 可执行程序,使用make clean命令可以自动清理test 可执行程序。
那么Makefile中的内容有什么含义呢?
powershell
test:test.c
gcc test.c -o test
.PHONY:clean
clean:
rm -f test2.1 依赖关系和依赖方法
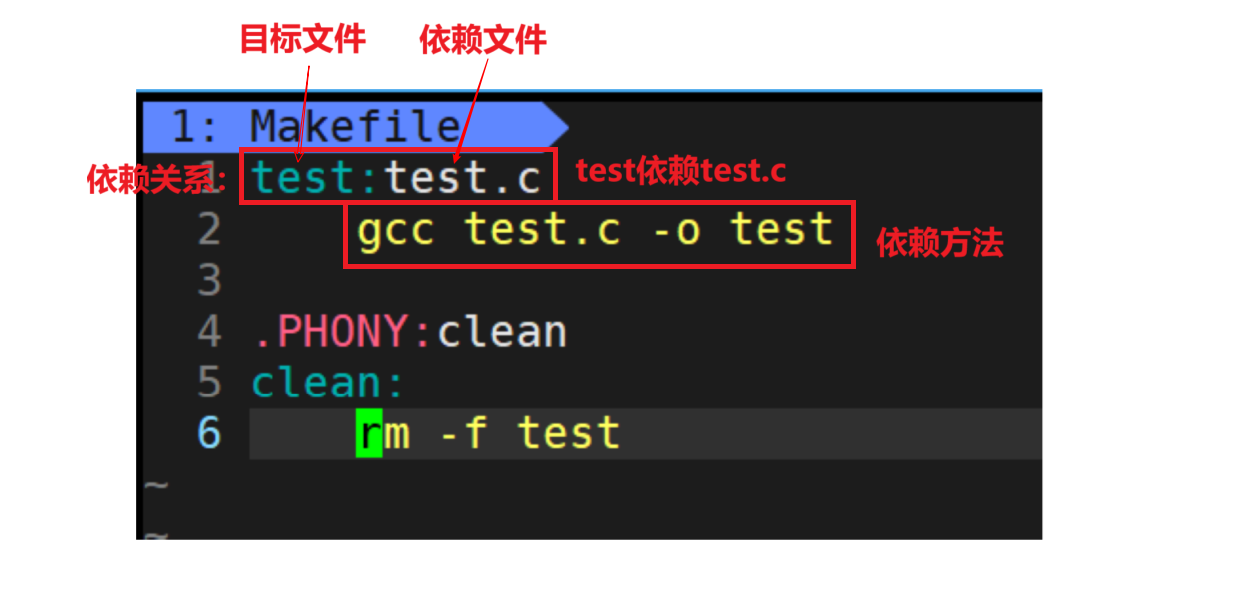
依赖关系
依赖关系定义了 "目标(target)" 与 "它所依赖的文件或其他目标" 之间的关联。简单来说:要生成目标,必须先确保其依赖的文件 / 目标已存在且是最新的。
核心逻辑
- 目标(target):通常是最终要生成的文件(如可执行程序、目标文件.o),也可以是伪目标(如clean)。
- 依赖(prerequisites):生成目标所需要的前置文件或其他目标(如源文件.c、头文件.h、其他.o文件)。
- make工具会比较目标与依赖的修改时间:如果依赖的修改时间比目标更新(或目标不存在),则需要通过 "依赖方法" 重新生成目标。
依赖方法
依赖方法(也称为 "命令")定义了 "当依赖满足更新条件时,如何生成或更新目标" 的具体操作(通常是编译、链接等命令)。
依赖规则
- 依赖方法必须紧跟在 "目标:依赖" 这一行的下方,且每一行命令必须以 Tab 键开头(不能用空格,否则make会报错)。
- 命令按顺序执行,若某条命令执行失败(返回非 0 状态),make会终止后续操作。
依赖关系与依赖方法的协同作用
make工具的工作流程正是基于二者的配合:
- 检查目标是否存在:若不存在,直接执行依赖方法生成。
- 若目标存在,比较目标与所有依赖的修改时间: 若所有依赖的修改时间都早于目标(依赖未更新),则目标无须重建 。
若任一依赖的修改时间晚于目标(依赖已更新),则执行依赖方法重新生成目标。
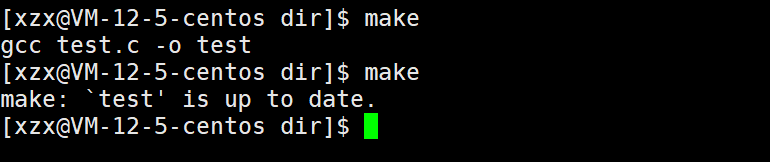
如果依赖未更新,则不会重复创建目标:
2.2 伪目标(.PHONY)
伪目标(如clean)本身不是实际文件,而是用于执行特定操作(如清理中间文件)。其依赖关系和方法通常用于定义 "无文件依赖的操作"。

powershell
# 声明clean为伪目标(避免与同名文件冲突)
.PHONY: clean
# 依赖关系:无实际依赖(可省略)
# 依赖方法:删除中间文件和可执行程序
clean:
rm -f test # 清理命令为什么要有伪目标?
伪目标既不产生目标文件,也不依赖于任何文件,只执行依赖方法,并且可以重复执行 ,常用于删除文件,做清理工作。
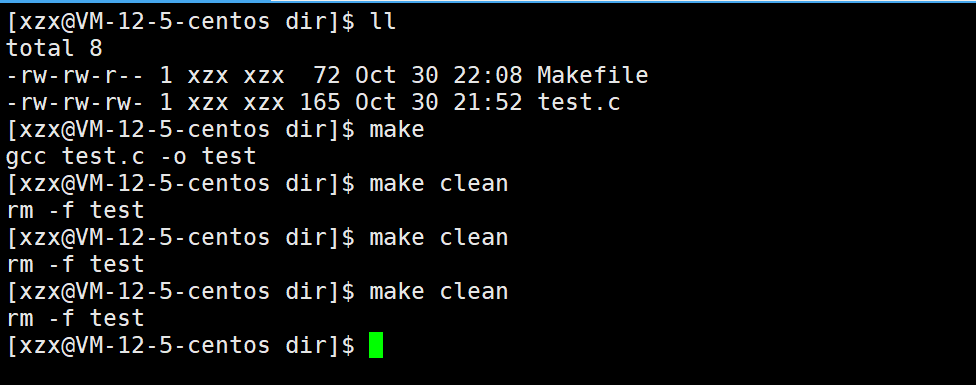
make clean命令可以重复执行:
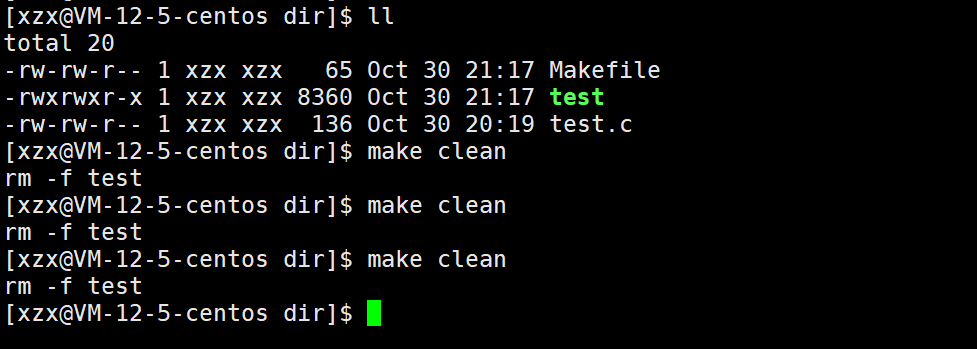
2.3 stat 指令
在 Linux 中,stat指令用于显示文件或文件系统的详细状态信息(元数据),包括文件的权限、大小、inode 信息、时间戳(访问 / 修改 / 变更时间)等。
三个关键时间戳:
Access(访问时间):文件内容最后被读取的时间Modify(修改时间):文件内容最后被修改的时间Change(变更时间):文件属性最后被修改的时间
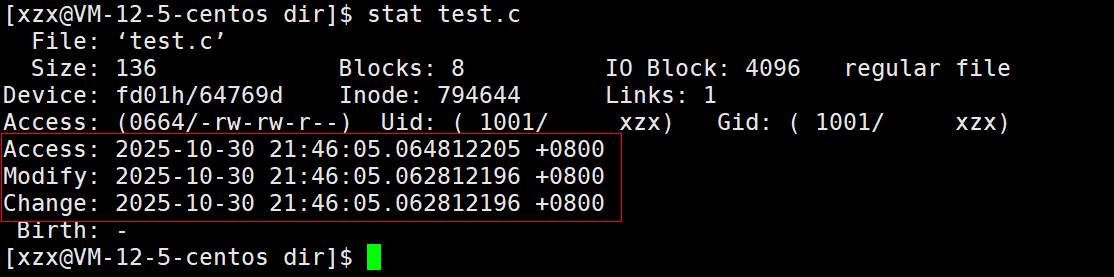
可执行程序test的Modify时间比test.c文件的Modify时间晚,说明依赖未更新。
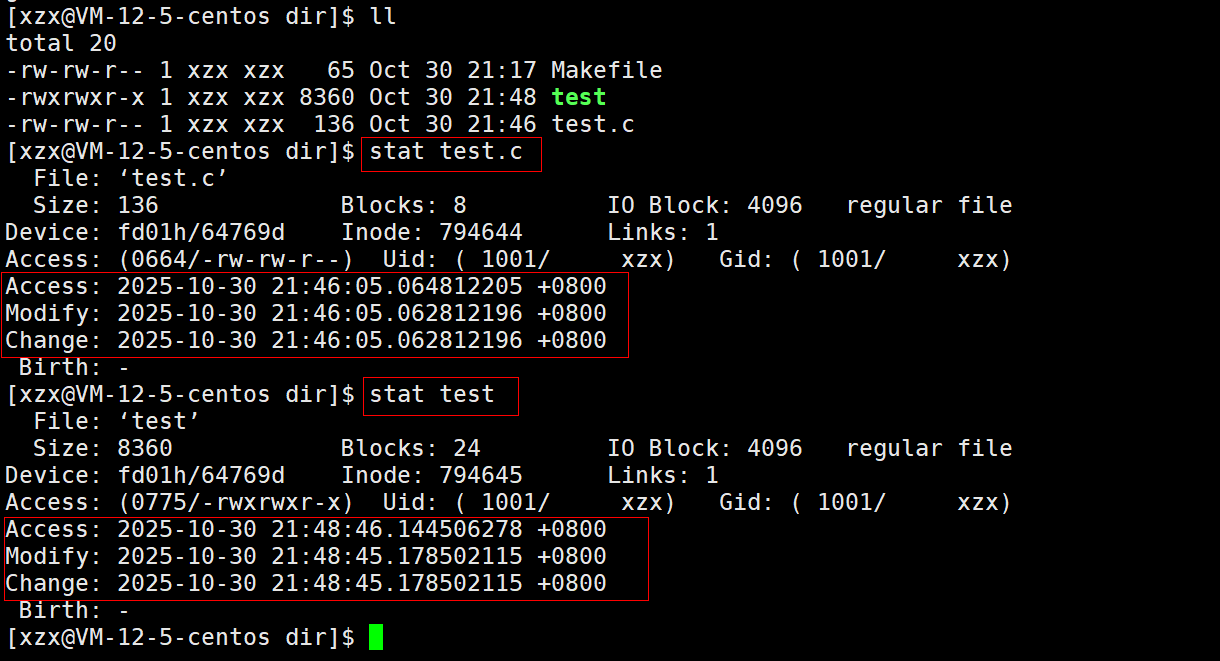
可执行程序test的Modify时间比test.c文件的Modify时间早,说明依赖已更新,可以执行make指令重新生成目标文件。
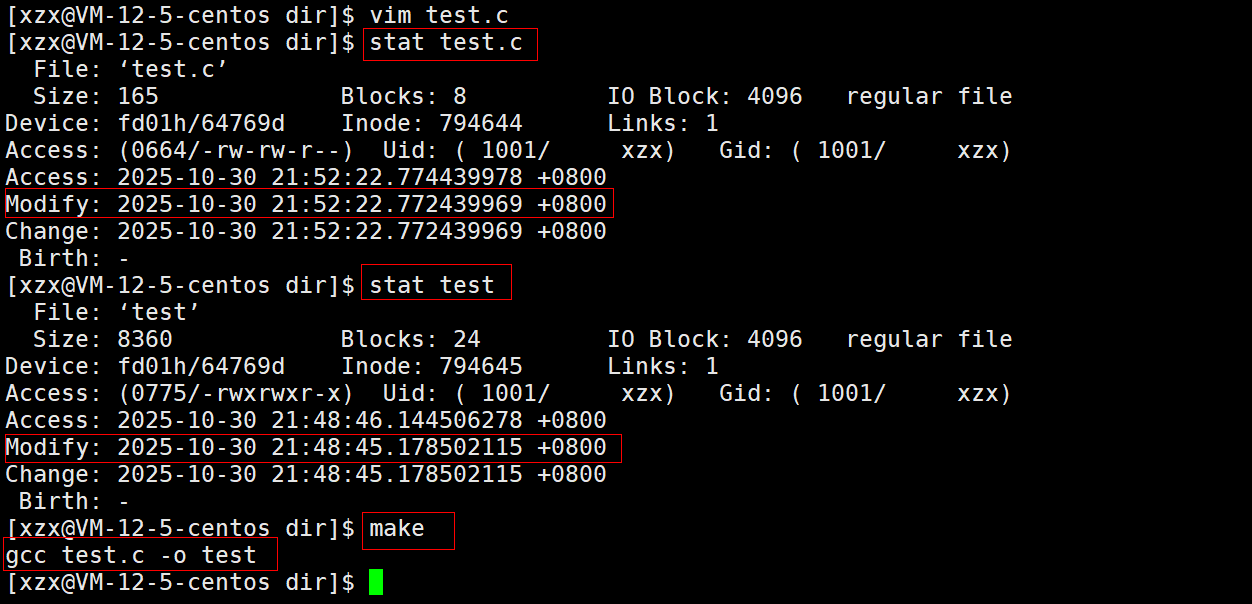
通过修改test.c文件的权限从而修改test.c文件的Change时间:
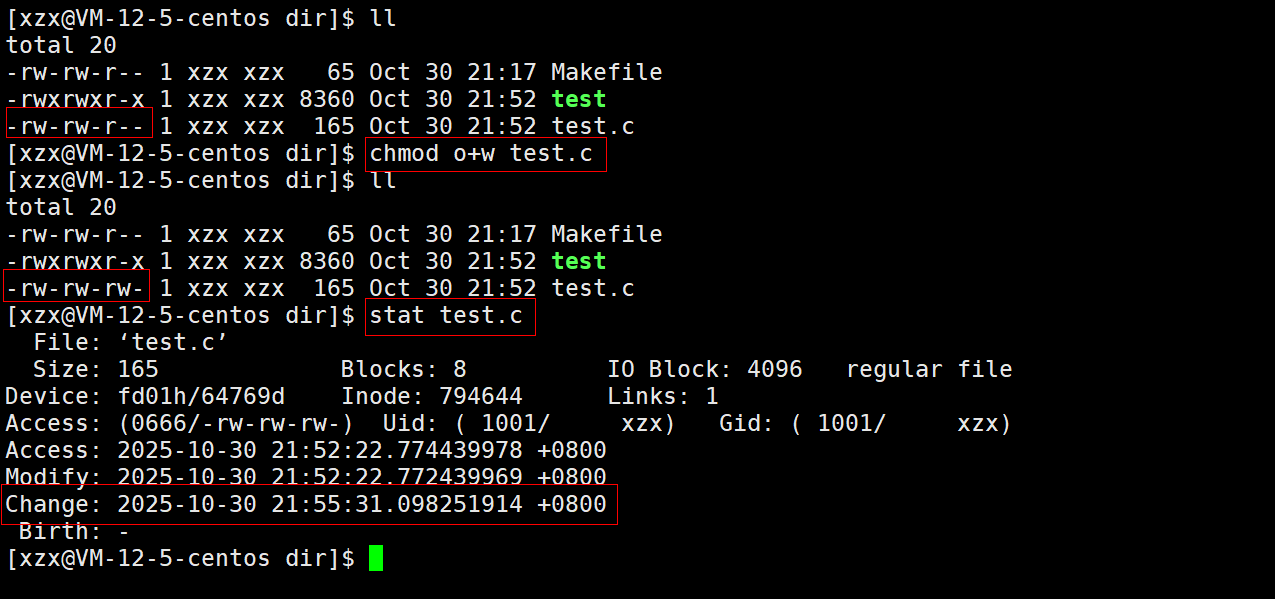
此时test.c的Change时间比test可执行程序的Change时间晚,但还是无法执行make指令,更加证明了只有当依赖文件的Modify时间晚于目标文件的Modify时间时,才可以执行make指令从而重新生成目标文件 。
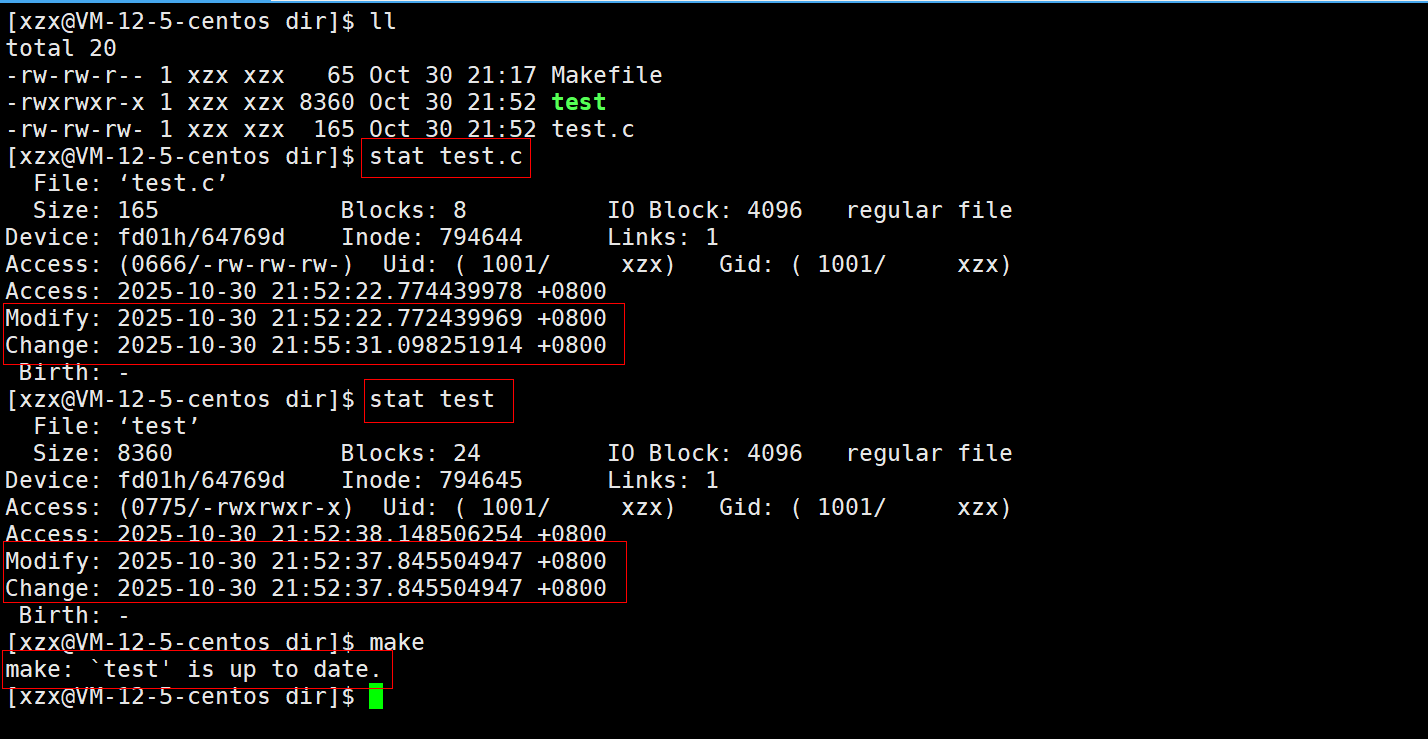
而.PHONY定义的伪目标clean之所以能够一直被执行,其原因就是它忽略了依赖文件与目标文件的修改时间的对比。
验证:就算写了伪目标依赖test.c 文件,但还是可以重复执行make clean,所以伪目标通常忽略依赖关系。
2.4 推导过程
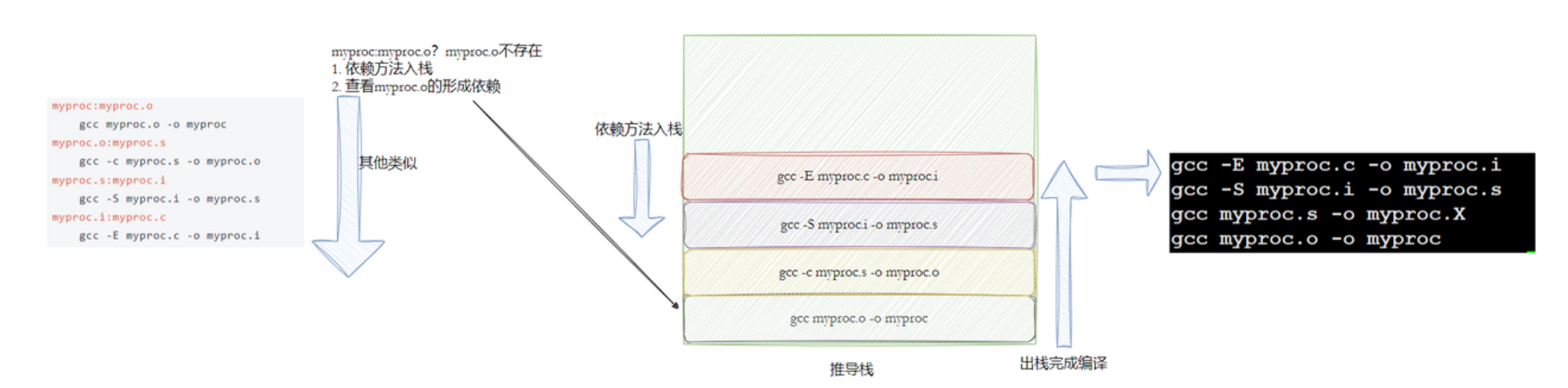
在上述过程中,我们写的依赖文件都是在当前目录中直接存在的;如果依赖文件并没有直接存在,而是依赖于其他依赖文件呢?
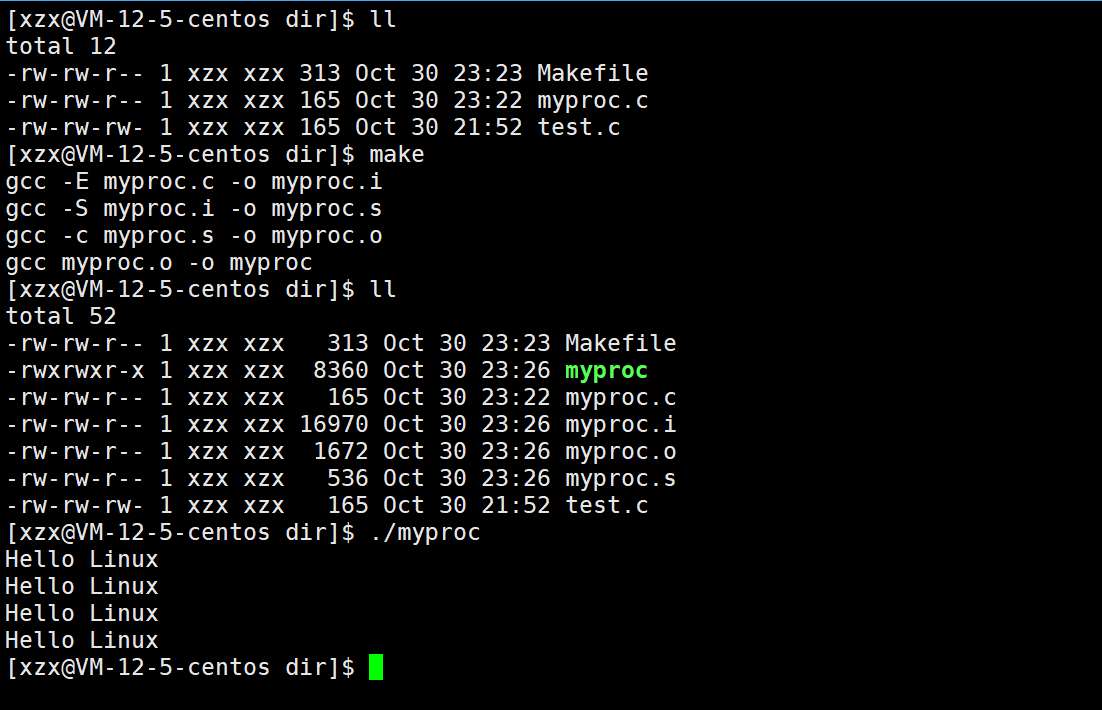
这里我们就根据编译过程,生成编译过程中所有的临时文件,来写makefile
powershell
myproc:myproc.o
gcc myproc.o -o myproc
myproc.o:myproc.s
gcc -c myproc.s -o myproc.o
myproc.s:myproc.i
gcc -S myproc.i -o myproc.s
myproc.i:myproc.c
gcc -E myproc.c -o myproc.i
.PHONY:clean
clean:
rm -f *.i *.s *.o myprocmyproc依赖于myproc.o、myproc.o依赖于myproc.s、myproc.s依赖于myproc.i、myproc.i依赖于myproc.c。myproc.c则直接存在于当前目录下。
2.5 扩展语法------更加通用的Makefile
上面的Makefile只适用于一个指定文件的情况下,如果换个指定文件或多个文件,那么Makefile就要重写了,接下来我们要学习更多Makefile的语法,使Makefile变得更加通用。
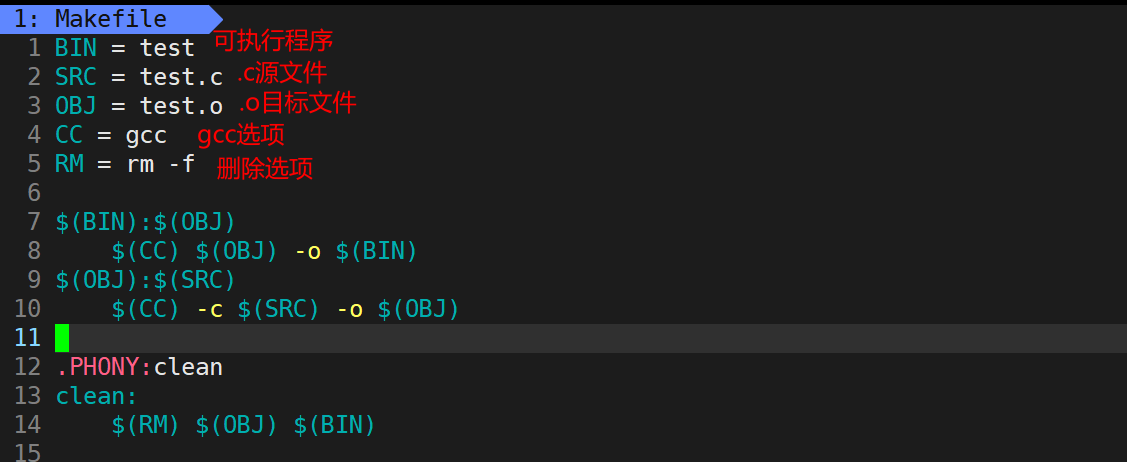
powershell
BIN = test
SRC = test.c
OBJ = test.o
CC = gcc
RM = rm -f
$(BIN):$(OBJ)
$(CC) $(OBJ) -o $(BIN)
$(OBJ):$(SRC)
$(CC) -c $(SRC) -o $(OBJ)
.PHONY:clean
clean:
$(RM) $(OBJ) $(BIN)我们可以通过创建变量来表示我们编译要用到的文件和选项,当需要访问这些变量的时候可以使用 $()来访问(使用$(BIN)来访问BIN变量的值)。
我们还可以使用$^ 和 $@ 来表示依赖关系中的依赖文件 和目标文件。
powershell
BIN = test
SRC = test.c
OBJ = test.o
CC = gcc
RM = rm -f
$(BIN):$(OBJ)
$(CC) $^ -o $@
$(OBJ):$(SRC)
$(CC) -c $^ -o $@
.PHONY:clean
clean:
$(RM) $(OBJ) $(BIN)编译当前目录下的多个文件
上面的Makefile还是只能操作一个.c源文件,如果当前目录下有多个.c源文件,有什么办法可以同时编译当前目录下的所有.c源文件吗?
获取当前目录下的所有.c文件
有两种方法:
$(shell ls *.c):采用shell命令行方式,获取当前所有.c文件名$(wildcard *.c):使用wildcard函数,获取当前所有.c文件名
将所有的.c修改为.o
对于多个.c文件,我们需要对它们进行编译从而产生对应的.o文件,最后再链接成可执行程序test;所以对于变量OBJ来说,我们需要获取所有.c文件对应的.o文件。
powershell
OBJ=$(SRC:.c=.o)这个语法就是将SRC所有的同名.c替换成为.o,形成目标文件列表。
通配符%和逐个执行$<
我们经常写的*.c表示所有以>.c为结尾的文件;在Makefile的使用中,通常需要用到通配符,而Makefile的通配符为%。
我们在写由所有的.c文件生成对应的.o文件时,就需要用到通配符%,这样就可以自动匹配了。
在匹配结束之后,多个.o目标文件分别依次依赖.c文件;这样就不能使用$^直接取依赖文件列表了,而是使用%<将依赖文件列表中的多个文件一个一个执行。
powershell
BIN = test
SRC = $(wildcard *.c)
OBJ = $(SRC:.c=.o)
CC = gcc
RM = rm -f
$(BIN):$(OBJ)
$(CC) $^ -o $@
%.o:%.c
$(CC) -c $<
.PHONY:clean
clean:
$(RM) $(OBJ) $(BIN)2.6 测试和优化Makefile
powershell
BIN = test
SRC = $(wildcard *.c)
OBJ = $(SRC:.c=.o)
CC = gcc
RM = rm -f
LFLAGS = -o
FLAGS = -c
$(BIN):$(OBJ)
$(CC) $^ $(LFLAGS) $@
%.o:%.c
$(CC) $(FLAGS) $<
.PHONY:clean
clean:
$(RM) $(OBJ) $(BIN)这里优化,新增加了编译选项FLAGS和链接选项LFLAGS。
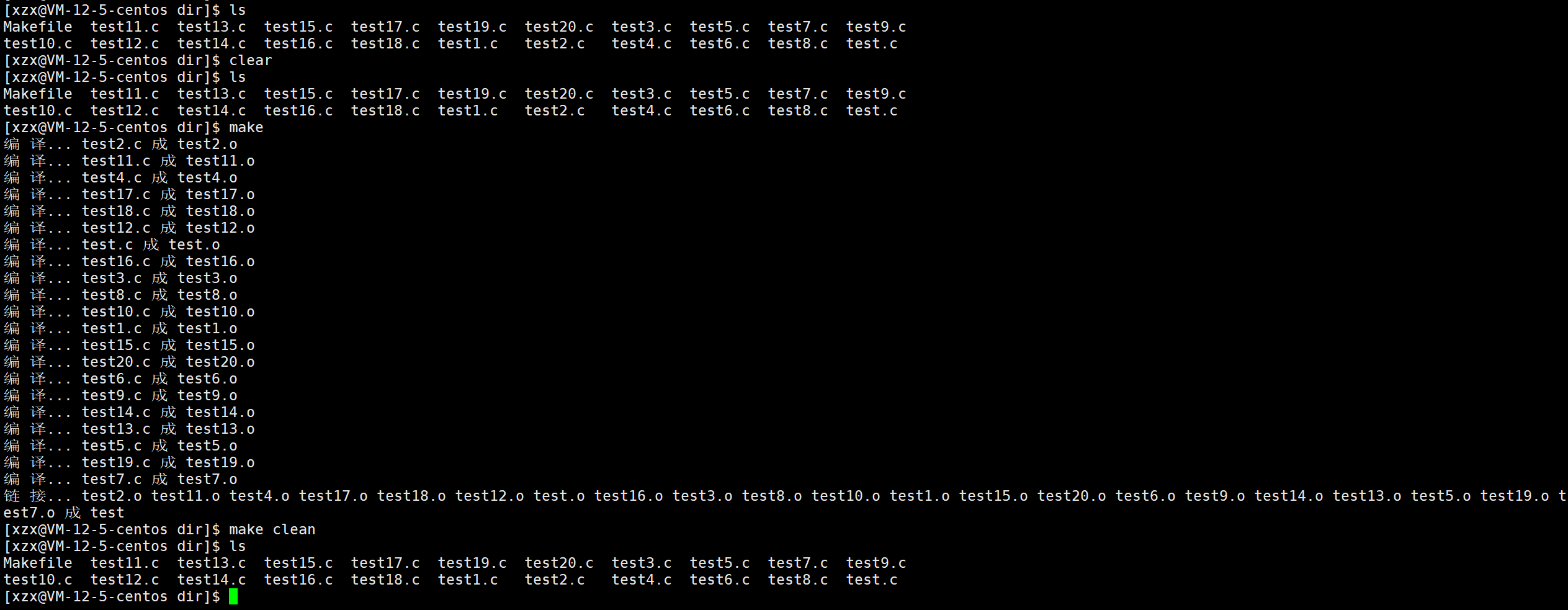
我们新建20个文件进行测试:
powershell
touch test{1..20}.c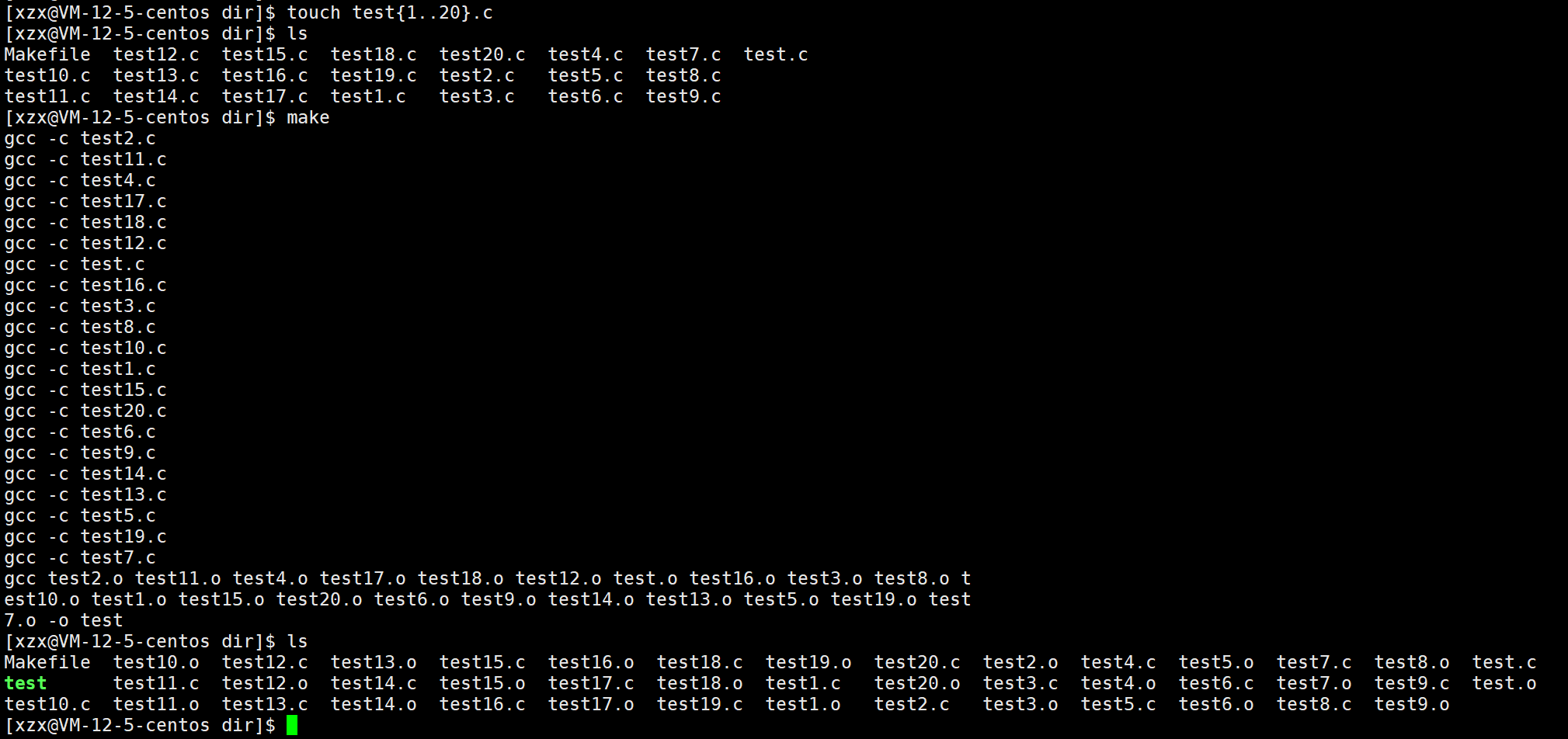
通过make的运行结果,我们可以知道:在执行依赖方法的每条语句时,都会回显每条语句的内容。
如果我们不想要回显每条语句的内容,可以在每条语句前面加个 @
powershell
BIN = test
SRC = $(wildcard *.c)
OBJ = $(SRC:.c=.o)
CC = gcc
RM = rm -f
LFLAGS = -o
FLAGS = -c
$(BIN):$(OBJ)
@$(CC) $^ $(LFLAGS) $@
%.o:%.c
@$(CC) $(FLAGS) $<
.PHONY:clean
clean:
@$(RM) $(OBJ) $(BIN)
但是这样的话,我们就不知道编译和链接的过程了,所以我们可以手动添加。
powershell
BIN = test
SRC = $(wildcard *.c)
OBJ = $(SRC:.c=.o)
CC = gcc
RM = rm -f
LFLAGS = -o
FLAGS = -c
$(BIN):$(OBJ)
@$(CC) $^ $(LFLAGS) $@
@echo "链 接... $^ 成 $@"
%.o:%.c
@$(CC) $(FLAGS) $<
@echo "编 译... $< 成 $@"
.PHONY:clean
clean:
@$(RM) $(OBJ) $(BIN)注意 :这里在echo语句前也要加@不让它回显,否则就会回显出来echo语句的内容,从而打印两遍一模一样的内容,不符合预期。
三. 第一个系统程序------进度条
3.1 回车和换行
在Windows下,我们通常认为回车和换行是一个概念,但事实上,换行是换到下一行的当前位置,而回车是回到当前行的起始位置 。我们之所以会认为回车和换行是一个概念,是因为\n它做了回车和换行两个操作。
下面来看两段代码:
c
#include <stdio.h>
int main()
{
printf("Hello Linux\n");
return 0;
}
cpp
#include <stdio.h>
int main()
{
printf("Hello Linux\r");
return 0;
}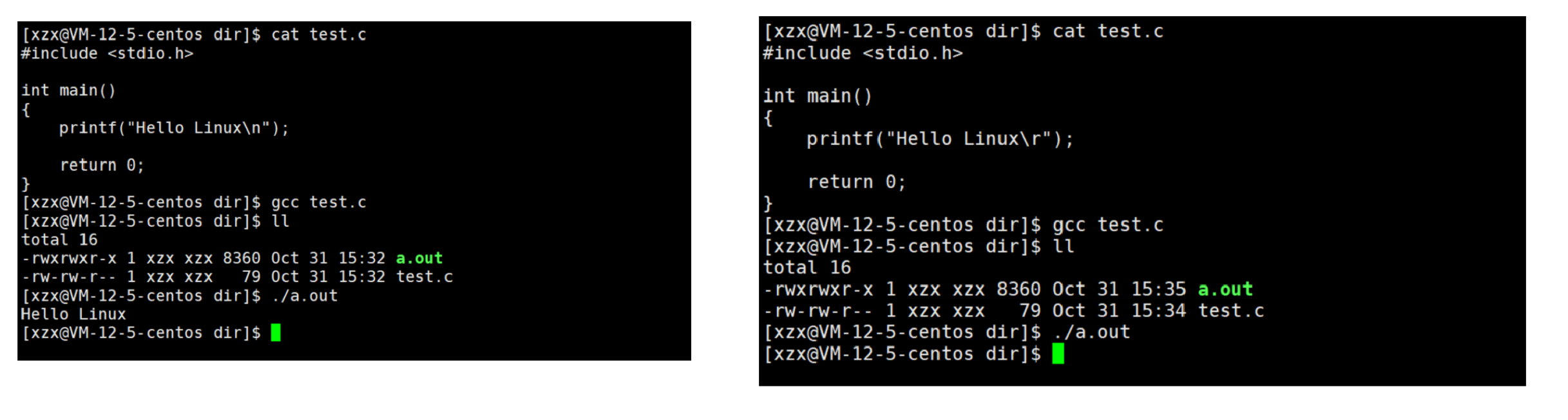
为什么回车\r之后什么都没输出?
因为回车是回到当前行的起始位置 ,当程序结束时确实是打印了
Hello Linux,但是光标确在当前行的起始位置,因为shell会在命令结束时,在光标位置打印提示信息,刚好把Hello Linux给覆盖了。
这里我们再看两段代码:
cpp
#include <stdio.h>
#include <unistd.h>
int main()
{
printf("Hello Linux\n");
sleep(3);
return 0;
}
cpp
#include <stdio.h>
#include <unistd.h>
int main()
{
printf("Hello Linux");
sleep(3);
return 0;
}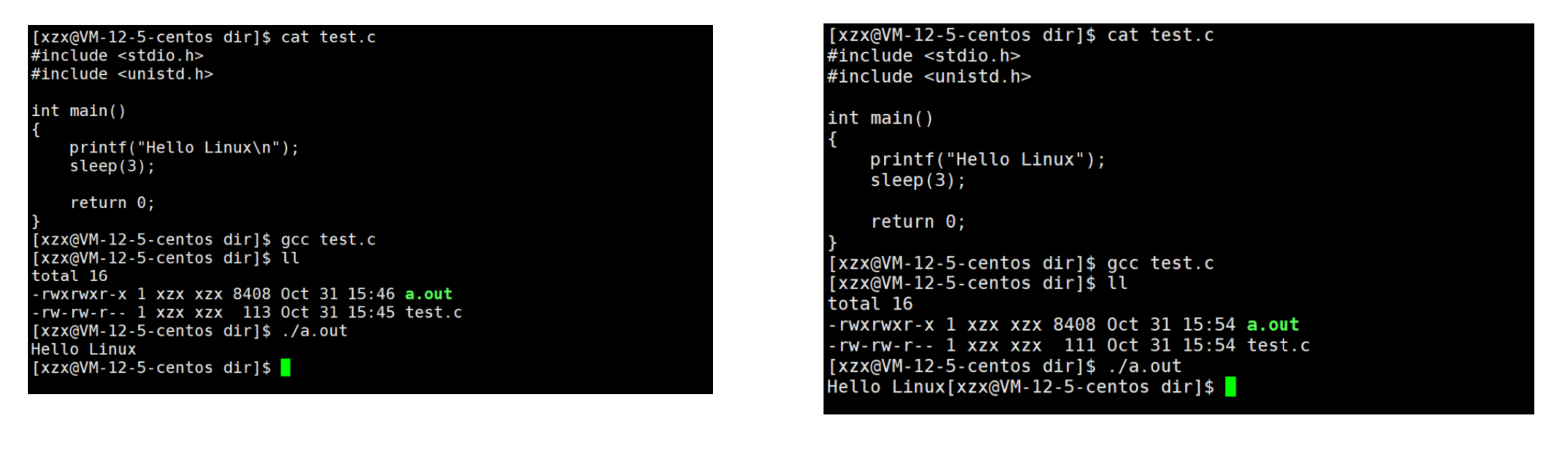
运行结果:
- 第一个代码先输出Hello Linnux,再睡眠了三秒
- 第二个代码先睡眠了三秒,再输出Hello Linux
这里是为什么呢?这里就要了解缓冲区这个概念了。
在计算机中,缓冲区(Buffer) 是一块用于暂时存储数据的内存区域,其核心作用是协调数据产生速度与处理速度不匹配的问题(例如 CPU 与外设、程序与 I/O 设备之间的速度差异),通过批量传输数据减少实际 I/O 操作次数,从而提高效率。
基本作用 :当程序进行输入 / 输出(I/O)操作时,数据不会直接实时传输到目标设备(如磁盘、终端)或从源设备读取,而是先暂存在缓冲区中。只有当缓冲区满足特定条件时(如满了、或遇到特殊字符),才会将数据批量传输。
行缓冲区 是一种按 "行" 划分的缓冲机制,其刷新(数据传输)的触发条件主要有两个:
- 遇到换行符('\n') 时,立即将缓冲区中当前行的数据传输出去;
- 当缓冲区存储的数据量达到其最大容量时,即使未遇到换行符,也会触发刷新。
所以第一个代码遇到换行符就立即把Hello Linux输出出去了,第二个代码则先把Hello Linux放在缓冲区,等程序结束时才把它输出出去。
如果我们想要让缓冲区强制刷新也是可以的,可以使用fflush函数来刷新缓冲区(stdout)的内容。
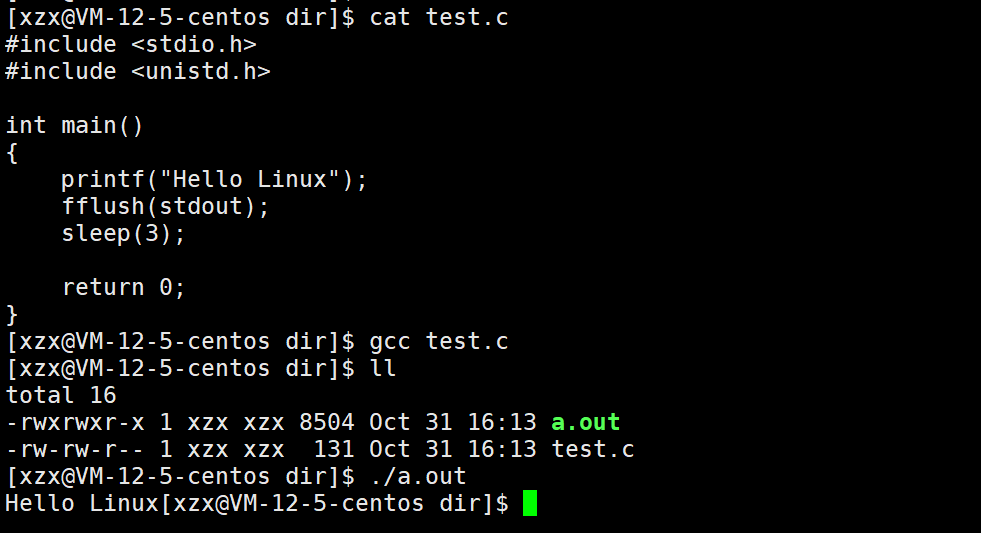
这样就是先输出Hello Linux,再休眠三秒。
3.2 倒计时程序
了解了回车和换行之后,现在来简单实现一个倒计时程序
c
#include<stdio.h>
#include<unistd.h>
int main()
{
int cnt = 10;
while(cnt>=0)
{
printf("%-2d\r",cnt);
fflush(stdout);
sleep(1);
cnt--;
}
printf("\n");
return 0;
}注意:
- 输出时记得要用
%-2d,让数字占两格,不够的用空格替代,并且向左对齐- 输出每个数字后,都要使用
fflush强制刷新缓冲区
3.3 进度条程序
首先要准备四个文件
Makefile文件main.c:程序主函数main所在的文件,也用于测试进度条process.h:进度条程序的头文件process.c:进度条程序的源文件
cpp
#include "process.h"
#include <string.h>
#include <unistd.h>
#define SIZE 101
#define STYLE '#'
// v1:展示进度条基本功能
void process()
{
int rate=0;
char buffer[SIZE];
memset(buffer,0,sizeof(buffer));
const char* label = "|/-\\";
int len = strlen(label);
while(rate<=100)
{
printf("[%-100s][%d%%][%c]\r",buffer,rate,label[rate%len]);
fflush(stdout);
buffer[rate]=STYLE;
++rate;
usleep(50000);
}
printf("\n");
}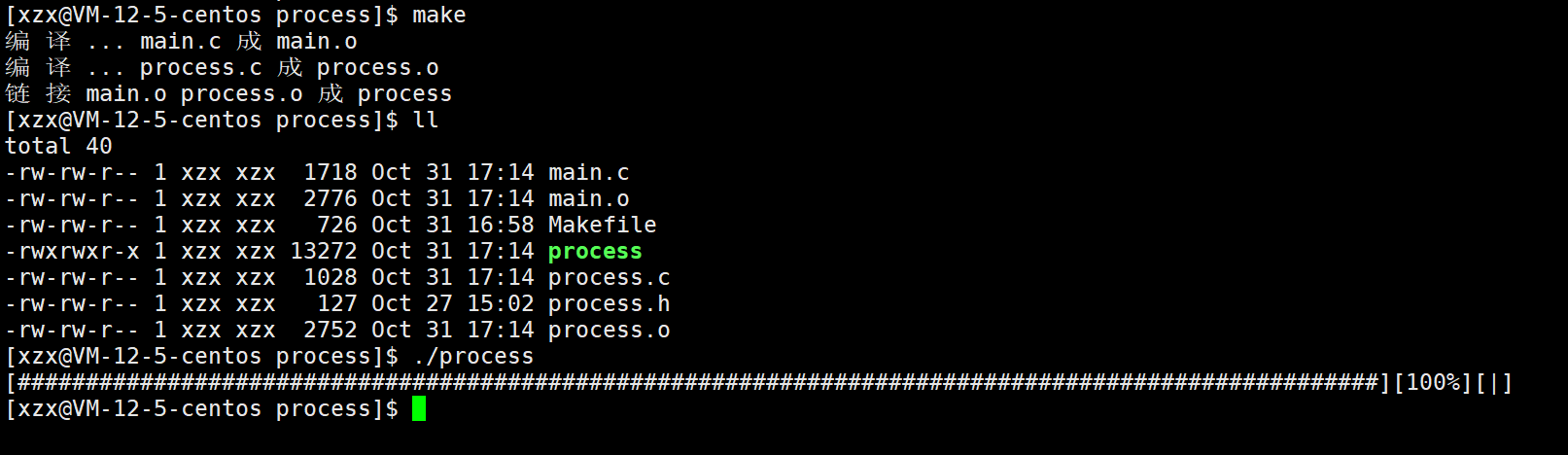
这个函数已经实现了进度条的基本功能,但是进度条每次累加的大小是相同的,这有点不太符合实际,因为现实中的网速不是固定的,是随时变化的,所以我们还需要再进行修改。
为了控制速度,我们可以控制current累加的值,也可以控制休眠时间usleep的大小。
cpp
#include "process.h"
#include <unistd.h>
#include <time.h>
#include <stdlib.h>
// 函数指针类型
typedef void (*call_t)(const char*,double,double);
double total = 1024.0;
//double speed = 1.0;
double speed[] = {1.0, 0.5, 0.3, 0.2, 0.1, 0.01};
// 回调函数
void download(double total,call_t cb)
{
srand(time(NULL));
double current = 0.0;
while(current<=total)
{
cb("下 载 中",total,current);
if(current==total) break;
int random = rand()%6;
usleep(5000);
current += speed[random];
if(current>=total){
current = total;
}
}
printf("\n");
}
cpp
// v2:根据进度,动态刷新一次进度条
void FlushProcess(const char* tips,double total,double current)
{
const char* label = "|/-\\";
int len = strlen(label);
static int index = 0;
char buffer[SIZE];
memset(buffer,0,sizeof(buffer));
double rate = (current*100.0)/total;
int num = (int)rate;
int i = 0;
for(; i < num; i++)
{
buffer[i]=STYLE;
}
printf("%s...[%-100s][%.1lf%%][%c]\r",tips,buffer,rate,label[index++]);
fflush(stdout);
index%=len;
}我们可以使用随机数来实现current每次加的值都是随机的,从而控制网速。
将每次刷新进度条的过程封装成一个函数,再利用函数指针去接受该函数的地址,实现出回调函数。
process.h
cpp
#pragma once
#include <stdio.h>
//v2
void FlushProcess(const char* tips,double total,double current);
// v1
void process();process.c
cpp
#include "process.h"
#include <string.h>
#include <unistd.h>
#define SIZE 101
#define STYLE '#'
// v2:根据进度,动态刷新一次进度条
void FlushProcess(const char* tips,double total,double current)
{
const char* label = "|/-\\";
int len = strlen(label);
static int index = 0;
char buffer[SIZE];
memset(buffer,0,sizeof(buffer));
double rate = (current*100.0)/total;
int num = (int)rate;
int i = 0;
for(; i < num; i++)
{
buffer[i]=STYLE;
}
printf("%s...[%-100s][%.1lf%%][%c]\r",tips,buffer,rate,label[index++]);
fflush(stdout);
index%=len;
}
// v1:展示进度条基本功能
void process()
{
int rate=0;
char buffer[SIZE];
memset(buffer,0,sizeof(buffer));
const char* label = "|/-\\";
int len = strlen(label);
while(rate<=100)
{
printf("[%-100s][%d%%][%c]\r",buffer,rate,label[rate%len]);
fflush(stdout);
buffer[rate]=STYLE;
++rate;
usleep(50000);
}
printf("\n");
}main.c
cpp
#include "process.h"
#include <unistd.h>
#include <time.h>
#include <stdlib.h>
// 函数指针类型
typedef void (*call_t)(const char*,double,double);
double total = 1024.0;
//double speed = 1.0;
double speed[] = {1.0, 0.5, 0.3, 0.2, 0.1, 0.01};
// 回调函数
void download(double total,call_t cb)
{
srand(time(NULL));
double current = 0.0;
while(current<=total)
{
cb("下 载 中",total,current);
if(current==total) break;
int random = rand()%6;
usleep(5000);
current += speed[random];
if(current>=total){
current = total;
}
}
printf("\n");
}
void upload(double total,call_t cb)
{
srand(time(NULL));
double current = 0.0;
while(current<=total)
{
cb("上 传 中",total,current);
if(current==total) break;
int random = rand()%6;
usleep(5000);
current += speed[random];
if(current>=total){
current = total;
}
}
printf("\n");
}
int main()
{
download(1024.0,FlushProcess);
printf("download 1024.0MB done\n");
download(512.0,FlushProcess);
printf("download 512.0MB done\n");
download(256.0,FlushProcess);
printf("download 256.0MB done\n");
download(128.0,FlushProcess);
printf("download 128.0MB done\n");
download(64.0,FlushProcess);
printf("download 64.0MB done\n");
upload(500.0,FlushProcess);
printf("upload 500.0MB done\n");
//process();
return 0;
}最后
本篇关于自动化构建工具make和Makefile和第一个系统程序---进度条到这里就结束了,其中还有很多细节值得我们去探究,需要我们不断地学习。如果本篇内容对你有帮助的话就给一波三连吧,对以上内容有异议或者需要补充的,欢迎大家来讨论!