目录
- 摘要
- Abstract
- 一、迁移学习
- 二、机器学习项目的完整周期
-
- [1、 第一步--确定项目范围](#1、 第一步--确定项目范围)
- 2、第二步--收集数据
- 3、第三步--训练模型
- 4、第四步--部署到生产环境
- 三、生产部署
- 四、公平、偏见与伦理
- 总结
摘要
今天的学习让我对迁移学习和机器学习项目全流程有了系统认识。迁移学习通过复用预训练模型的前几层参数,能有效解决小数据集问题,就像站在巨人肩膀上做微调。我还了解了机器学习项目的完整周期:从确定范围、收集数据、训练模型到部署上线,其中误差分析和持续监控是关键环节。这些知识让我明白实际机器学习项目不仅是建模,更是系统工程。
Abstract
Today's study covered transfer learning and the complete machine learning project lifecycle. Transfer learning enables effective model training on small datasets by leveraging parameters from pre-trained networks. The ML project workflow includes scoping, data collection, model training, and deployment, with error analysis and performance monitoring being crucial throughout the process. This systematic approach demonstrates that successful ML applications require both algorithmic understanding and engineering implementation.
一、迁移学习
对于一款数据量不多的应用,迁移学习是一种很棒的技术,它可以让我们可以使用来自不同任务的数据来帮助我们的应用,让我们来看看迁移学习是如何运作的
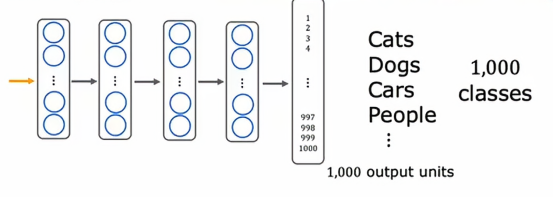
这就是迁移学习的工作原理,假设我们想识别0到9的手写数字,但我们没有太多这些手写数字的标签数据,我们可以这样做,假设我们找到包含100w张猫图片的大型数据集,狗,汽车、人等等,然后我们可以先在这个包含一百万张图片和一千个不同类别的大型数据集上训练一个神经网络,训练算法输入图像x,并学习识别这1000个类别中的任意一个,在这个过程中,我们最终学会了神经网络第一层的参数,第二层的w1,b1,w2,b2直到w5,b5的参数,应用迁移学习,我们所做的是复制这个神经网络,并保留参数w1,b1到w4,b4,但对于最后一层,我们将去掉输出层,并用一个更小的输出层替换它,只有10个输出而不是1000个输出单元,这10个输出单元将对应于类别0、1到9
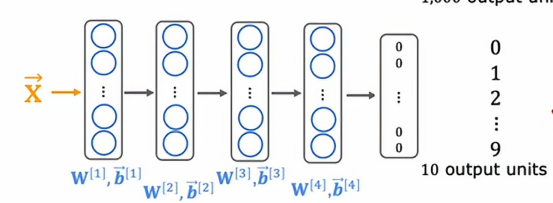
需要注意的是,w5,b5不需要复刻,因为已经是另外一个维度了,所以我们需要设计新的参数w5,b5,单论这一层,我们需要从头开始训练,而不是直接从之前的神经网络中复制,在迁移学习中,我们可以做的是使用前四层的参数,实际上是所有层,除了最后的输出层,作为参数的起点,然后运行一个优化算法,比如Adam优化算法,参数初始化使用这个神经网络上面的值,详细来说,我们有两种选择来训练这个神经网络的参数
选项一是你只训练输出层的参数,所以我们会使用参数w1,b1到w4,b4作为上面的值,并保持它们固定,不用去改变它们,使用像随机梯度下降或Adam优化算法,只更新w5,b5以降低成本函数,我们通常用来学习识别这些数字0到9的成本函数,从一个小的训练集这些数字0到9
选项二是训练神经网络中的所有参数,包括w1,b1,w2,b2,一直到w5,b5,但前四层的参数将使用我们在上面训练的值进行初始化,如果我们有一个非常非常小的训练集,那么选项一可能会更好一点,但如果我们有一个训练集稍微大点,那么选项二可能会更好一点,
这个算法被称为迁移学习,因为直觉上通过学习识别猫、狗、人等等,我们从前面几层学到一些更深层次的分类方法,然后我们将这些分类方法转移到另外一个更小神经网络,只要稍加训练,就可以发挥很好的效果,节省自己训练模型的时间,这两个步骤首先先在大型数据集上训练,然后在较小的数据集上进一步调整参数,在大型数据集上训练神经网络的步骤称为有监督预训练,比如一百万张与实际任务不完全相关的图片集,然后第二步称为微调,我们可以采取我们从有监督预训练中初始化或获得的参数,然后进一步运行梯度下降以微调权重以适应我们可能有的手写数字识别的特定应用
因此,如果我们有一个小数据集,即使只有几十或者几百,或者几千张图片,手写数字能够从这百万张不完全相关的任务图片中学习,实际上可以帮助我们的学习提升很多
迁移学习的一个好处,我们不需要亲自监督预训练,对于神经网络,已经有研究人员在大型数据集训练了神经网络图像,我们可以将网上已经训练好的神经网络下载到本地,然后我们用自己的输出层替换他的输出层,并进行选择一选择二来微调一个已经由他人进行监督预训练的神经网络,只需要稍加微调,就能快速获得一个别人已经训练好的神经网络。
1、为什么迁移学习能够发挥作用
有些人可能有一个问题,为什么我能通过学习分类猫和狗,转而能判断0到9这些手写数字呢?让我们来看看更深层次的学习逻辑
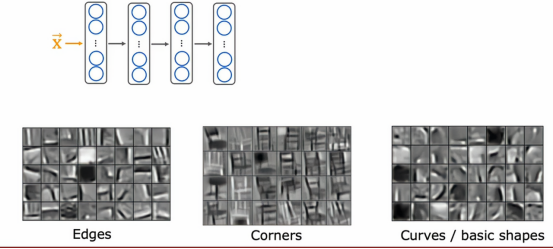
假设现在我们有一个神经网络来判断是谁的凳子,那么第一层隐藏层可能会进行初步的判断,即提取一些边边角角得特征,来判断是否属于目标凳子的特征,然后第二层隐藏层就是对一些转角的提取,进一步扩大判断的特征,让提取的特征更加的立体,而第三层就转而对一些基本形状和曲线这种复杂但又全面的判断,这一轮下来,基本能判断这些特征是否属于目标的特征。
我们迁移学习迁移的是更深层次的学习思路,通过找到一些小的特征,逐步扩大到较大的特征,然后逐步构建出完整的形状,就跟一个类型的解题思路一样,只要是属于这种类型,那么解题思路就是一致的
二、机器学习项目的完整周期
到目前为止,我们已经讲了很多关于如何训练模型的内容,也稍微谈了以下如何为机器学习应用获取数据,但当我们构建一个机器学习系统时,我们发现训练模型只是其中的一部分,所以本节旨在梳理一下我认为的一个完整的机器学习项目周期,也就是说,当我们构建一个有价值的机器学习系统时
让我用语音识别作为例子来说明一个完整的机器学习项目周期
1、 第一步--确定项目范围
机器学习项目的第一步是确定项目范围,换句话说,我们应该决定好我们需要做出什么效果,例如,如果决定开发一个用于语音搜索的语音识别系统,也就是通过对手机说话来进行网页搜索,而不是在手机上打字,这就是项目范围的确定
2、第二步--收集数据
在决定好需要什么数据来训练我们的机器学习系统,并付诸实践去获取音频,得到数据集的标签
3、第三步--训练模型
在我们完成初步数据收集后,然后我们就可以开始训练模型了,因此,我们会训练一个语音识别系统,进行误差分析,并迭代改进我们的模型,在我们开始训练模型之后,进行误差分析或偏差-方差分析是很常见的,分析告诉我们可能需要回去收集更多的数据,也许收集更多的所有数据,或者只是收集更多的错误分析中指出的特定类型的数据,例如,当研究语音时,我们发现我们的模型在有汽车噪音的情况下表现很差,那么我们需要着重收集有汽车噪音情况下的音频或者我们用数据增强来自己构造带有噪音的音频,这样专项训练后,模型就会在原来薄弱的地方表现的不错了,然后我们在计算一下误差和方差,经过在几次循环后,直到我们的模型表现的没问题,这一步就算完美结束
4、第四步--部署到生产环境
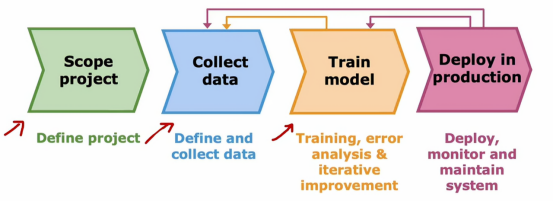
当我们认为模型足够好时,我们就可以部署到生产环境中,当我们部署一个系统时,我们还需要确保持续监控系统的性能,以便在性能下降时进行维护将性能恢复到原有的水平,而不仅是将我们的机器学习模型托管在服务器上,有时候我们发现它的表现不如预期,我们就需要重新训练一下模型,甚至重新获取更多数据,实际上,如果用户和我们有权使用生产部署中的数据,有时这些工作的语音系统数据能让我们获得更多数据继续提升系统性能,下图就是整个过程的示意图:
三、生产部署
让我们详细说明一下生产部署的样子,在我们训练一个高性能的机器学习模型之后,常见的模型部署方式是将机器学习模型实现到服务器中,我们称之为推理服务器,它的任务是调用我们的机器学习模型,如果我们的团队实现了一个移动应用,当用户对移动应用讲话时,移动应用可以进行一个API调用,将录制的音频片段传递到推理服务器,推理服务的任务是应用机器学习模型,然后返回预测结果,这种情况下就是用户说话的文本转录,这种方式是通过API调用推理服务器的常见实现方法,让模型根据输入x反复进行预测,这是一种常见模式,根据实现应用不同,通过API调用将输入 x提供给学习算法,要实现这一点,需要一些软件工程来编写这些代码,根据我们的应用需要服务的用户多少,所需的软件体量会有很大的不同
四、公平、偏见与伦理
计算机自从出现以来,一直以来都是一把双刃剑,既能造福人类,也能毁灭人类,我们所能做的就是引导计算机往造福人类的道路上走,就像之前我在短视频平台刷到一个机器学习的新闻,一个白人程序员做了一个门禁系统,也就是通过扫描通过者的脸部特征来匹配公司登录系统,看看被扫描者是否是公司员工或者提前预定者,但是这个门禁经常扫描不出肤色较深的员工,甚至将其跟网上那些犯罪者匹配上,闹了不少事情,网上很多人都职责该程序员是种族歧视,在经过公司内部调查后,确实发现了该白人程序员是一个严重的种族歧视者,他故意将程序写成这样,就为了困扰一些深肤色群体,最后这名员工也是被公司开除了
也不是所有人都支持机器学习,有些认为当机器学习这个领域高度成熟后,会代替很多人类的工作,导致大批人失业,这样会增加社会的不稳定因素,甚至有人更加激进的指出,这样下去,人们会越来越依赖机器,最终被机器取代,呼吁停止AI、人工只能的发展
我的看法是,在学习的过程中,我们不能只能学习知识本身,我们也要看到它们所能带来的影响,的确,现在AI的发展,deepseek、GPT、豆包这些AI的兴起,人们似乎越来越依赖AI,无论干什么事情,都需要询问AI,在我看来,我们应该保留自己的想法,不要被AI这些软件所制约,也希望在将来能够更好地使用、发展AI的用途
总结
今天的学习让我对机器学习有了更全面的视角。迁移学习的理念很巧妙------通过在大数据集上预训练,然后在小数据集上微调,既能节省计算资源又能提升性能。我特别理解了为什么迁移学习有效:底层特征检测器(如边缘、纹理)在很多视觉任务中是通用的。机器学习项目的完整周期让我认识到实际工作远不止训练模型,从确定项目范围到数据收集、模型迭代,再到部署和持续监控,每个环节都至关重要。部署部分提到的推理服务器架构也让我对如何将模型投入实际使用有了具体概念。这些知识打破了我认为机器学习只是调参的片面认知,明白了它更是一个需要系统思维和工程能力的完整流程。