何为Spring Bean容器?Spring Bean容器与Spring IOC 容器有什么不同吗?
简单来说,Spring Bean容器 和 Spring IoC容器 在绝大多数上下文和实际使用中,指的是同一个东西。它们是同一个概念的不同名称,侧重点略有不同。
-
当你强调功能(做什么) 时,你通常叫它 IoC容器。
-
当你强调内容(管理什么) 时,你通常叫它 Bean容器。
可以把它们理解为一个"盒子"的两个名字:
-
这个盒子的主要作用是控制反转(Inversion of Control) ,所以叫 IoC容器。
-
这个盒子里装的东西叫做 Bean ,所以它也是个 Bean容器。
什么是Spring容器?
Spring Bean容器 是一个负责管理应用程序中所有对象(这些对象在Spring中被称为 Bean)的运行时环境。
它的核心职责是:
-
实例化对象:根据配置(如注解、XML)创建类的实例。
-
组装依赖:将一个Bean所依赖的其他Bean(即其属性或构造参数)注入进去。这就是"依赖注入"(DI)。
-
管理生命周期:负责Bean的整个生命周期,包括初始化、使用、以及销毁。
-
提供配置:为Bean提供中心化的配置方式。
关键比喻:
你可以把Bean容器想象成一个超级智能的工厂 。你不需要自己用 new关键字来创建对象,只需要告诉这个工厂:"我需要一个UserService类型的对象",工厂就会帮你创建一个配置好的、所有依赖都齐全的UserService实例给你。
什么是Spring IOC容器
IoC 的全称是 Inversion of Control(控制反转)。这是一种设计原则,旨在将程序的控制权反转。
-
传统程序的控制流 :在传统程序中,一个对象(A)如果需要另一个对象(B),它会主动在内部通过
new B()来创建这个依赖。对象A掌控着依赖B的创建权。 -
IoC模式的控制流 :在IoC模式下,对象A不再负责创建B。它会以一种被动的方式(例如通过构造函数参数、setter方法)声明自己需要B 。然后,由一个外部的"容器"来负责创建B的实例,并在创建A的时候,将B"注入"到A里面。控制权从程序本身反转到了外部的容器。
Spring IoC容器就是实现这个"控制反转"原则的容器。它负责管理Bean之间的依赖关系,并进行依赖注入。
| 特性 | Spring Bean 容器 | Spring IoC 容器 |
|---|---|---|
| 强调重点 | 内容物 :它管理的是一个个的 Bean。 | 原则/功能 :它实现的是 控制反转(IoC) 和 **依赖注入(DI)**这个设计思想。 |
| 命名角度 | "容器里装的是什么?" -> 答案是 Bean。 | "这个容器的核心功能是什么?" -> 答案是 IoC/DI。 |
| 关系 | 它是IoC容器的具体体现和实现。我们说"Bean容器"时,指的是这个具体的、管理Bean的IoC容器实例。 | 它是一个更概念化的术语,描述了容器的设计模式和核心职责。 |
Spring DI如何理解?
一、核心思想:一句话概括
Spring DI(依赖注入)就是:你需要什么,别人(Spring 容器)就主动送给你,而不是你自己去造。
这里的"你"指的是程序中的某个对象,"需要什么"指的是它所依赖的其他对象,"别人"就是Spring容器。"送给你"就是"注入"(Inject)。
Spring中IOC和DI的关系
IoC 是设计目标和思想,DI 是实现这个思想的具体技术模式。
可以把它们的关系理解为:
-
IoC(控制反转) :是 "什么"(What) ------ 我们要达到的目标是让程序的控制权发生反转。
-
DI(依赖注入) :是 "如何做"(How) ------ 我们实现 控制反转这个目标所采用的具体方法。
更形象的比喻:
-
IoC 就像"自动驾驶"这个理念(目标是把驾驶控制权从司机交给电脑)。
-
DI 就像实现自动驾驶的具体技术,比如自动巡航、自动泊车等。
Spring 中基于注解如何配置对象作用域?
Spring 提供了多种作用域,最常用的有:
-
singleton(默认): 在整个 Spring IoC 容器中,只存在一个共享的 Bean 实例。 -
prototype: 每次请求(通过applicationContext.getBean()或注入)都会创建一个新的 Bean 实例。 -
request: 每次 HTTP 请求都会创建一个新的 Bean 实例(仅适用于 Web 应用)。 -
session: 在一个 HTTP Session 的生命周期内,容器会使用同一个 Bean 实例(仅适用于 Web 应用)。 -
application: 在一个ServletContext的生命周期内,容器会使用同一个 Bean 实例(仅适用于 Web 应用)。
使用 **@Scope**注解来显式定义 Bean 的作用域。
以及如何配置延迟加载机制?
延迟加载(Lazy Initialization)控制 Bean 实例的创建时机。
默认行为:急切加载(Eager Loading)
-
默认情况下,Spring 容器在启动时,会创建和配置所有的 **单例作用域(singleton)**的 Bean。
-
优点:可以在应用启动时就发现配置错误。
-
缺点:如果Bean很多或初始化很耗时,会导致应用启动缓慢。
- 配置延迟加载(Lazy Loading)
使用 @Lazy 注解可以延迟 Bean 的初始化。只有在第一次被请求时(如被注入或被getBean()调用),才会创建实例。
使用@lazy注解
Spring 工厂底层构建Bean对象借助什么机制?当对象不使用了要释放资源,目的是什么?何为内存泄漏?
Spring 通过反射 实现核心的实例化与注入,通过CGLIB 实现动态代理等高级功能,并将这些技术点串联在一个完整的生命周期流程中,从而实现了强大的 Bean 管理能力。
第一部分:Spring 工厂底层构建 Bean 对象的机制
Spring 容器构建 Bean 的底层机制可以概括为:以 Java 反射为基石,以字节码增强(CGLIB)为补充,并贯穿一个精心设计的生命周期管理流程。
就像一个高度自动化的智能工厂:
- 核心基石:Java 反射 (Reflection)
Spring 在运行时并不知道你的具体类(如 UserService),它完全依赖反射来动态操作。
-
加载类 :根据类全限定名,通过
ClassLoader加载Class对象。 -
实例化:
-
首选:构造器实例化 。通过
Constructor.newInstance(args)创建对象。Spring 会智能解析参数,并去容器中查找对应的 Bean 来作为入参(这就是构造器注入的底层实现)。 -
备选:工厂方法 。如果配置了静态或实例工厂方法,则通过
Method.invoke()来调用方法创建对象。
-
反射是 Spring 实现"控制反转"的基石,使得 Spring 无需在编译时知道具体的类型,从而实现了高度的灵活性。
- 关键补充:字节码生成(CGLIB 库)
反射能创建对象,但有些高级功能需要修改类的行为,这时就需要 CGLIB。
-
用途:
-
为没有接口的类创建代理(AOP):Spring AOP 默认使用 JDK 动态代理(要求有接口),如果目标类没有实现接口,则使用 CGLIB 动态生成一个该类的子类作为代理。
-
作用域代理 :如
@Scope("request")或@Scope("session")。单例 Bean 要注入一个 Request 作用域的 Bean 怎么办?Spring 会使用 CGLIB 创建一个代理对象注入给单例 Bean。每次调用代理对象的方法时,代理都会委托给当前请求/会话中的真实实例。 -
方法注入(
@Lookup):解决单例 Bean 中每次获取原型 Bean 的问题。
-
CGLIB 通过继承目标类并在运行时生成子类字节码,来增强功能。
- 标准化流程:Bean 的生命周期
Spring 不仅仅是用 new创建对象就完了,它围绕对象的创建、初始化、使用到销毁,定义了一套完整的生命周期回调机制。下图清晰地展示了这一核心流程,特别是初始化和销毁阶段:
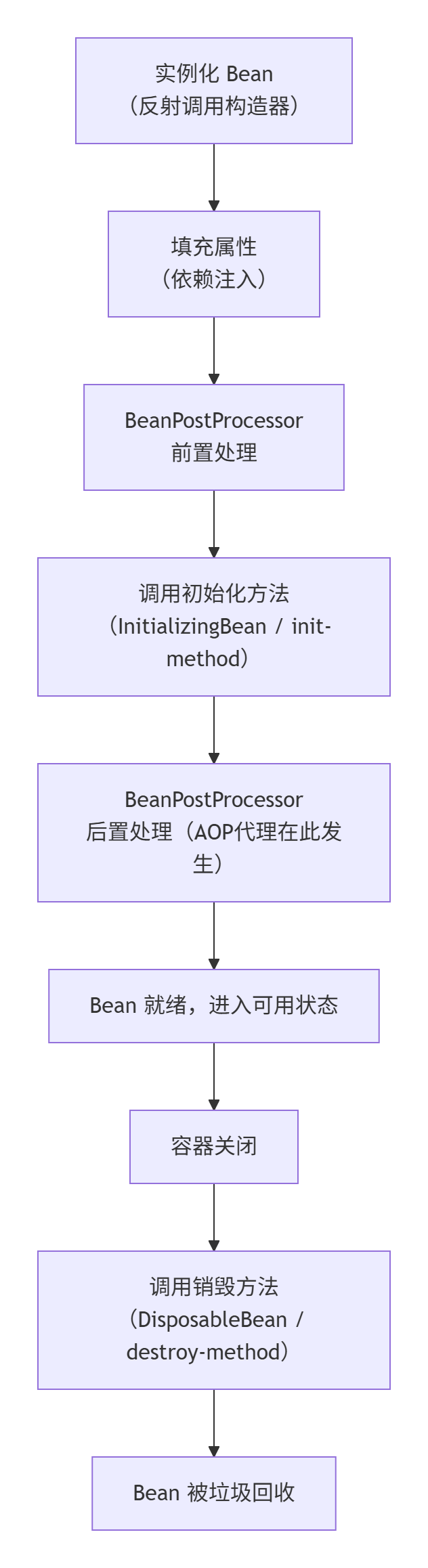
第二部分:释放资源的目的与内存泄漏
Spring 通过提供优雅的销毁回调机制(如 @PreDestroy)来帮助我们方便地释放非内存资源,但并不能自动防止逻辑上的内存泄漏。避免内存泄漏的关键仍在于开发者遵循良好的编程实践,及时解除对无用对象的引用。
- 当对象不使用了要释放资源,目的是什么?
目的是防止资源泄漏 ,尤其是内存泄漏,确保应用的稳定性和性能。
需要释放的资源分为两类:
-
内存资源:这是最基本的。Java 有垃圾回收(GC),但 GC 只能回收不再被引用的对象所占用的内存。如果对象不再使用但仍被引用,GC 就无法回收,导致内存泄漏。
-
非内存资源(需要手动关闭的资源):这些资源的管理权在 JVM 之外,GC 无法自动回收它们。如果不释放,会导致系统资源耗尽。
-
数据库连接:不关闭会导致数据库连接池耗尽,新的数据库操作无法执行。
-
网络连接(Socket):不关闭会占用端口和网络资源。
-
文件流(FileInputStream/OutputStream):不关闭会导致文件句柄泄露,最终无法再打开新文件。
-
线程:不正确地管理线程会导致线程泄露。
-
因此,释放资源的根本目的是:将宝贵的系统资源(内存、连接、句柄等)归还给系统,以便这些资源可以被重新利用,避免因资源逐渐耗尽而导致的应用程序速度变慢、崩溃或整个系统不稳定。
- 何为内存泄漏?
内存泄漏的官方定义是:程序中已动态分配的堆内存由于某种原因程序未释放或无法释放,造成系统内存的浪费,导致程序运行速度减慢甚至系统崩溃等严重后果。
通俗易懂的解释:
想象你的房间是一个内存空间。你从图书馆(系统)借了很多书(对象)回来看。
-
正常情况:你看完一本书(对象不再使用),就把它还回图书馆(GC 回收内存)。然后你可以再去借新的书。
-
内存泄漏:你看完一本书后,没有还回去,而是随手塞进了某个再也想不起来的抽屉里(被一个无用的、但一直存在的对象引用着)。你以为你没书了,又去图书馆借新的。久而久之,你的房间(内存)被这些"再也不看但也没还"的书塞满,新书再也放不进去了,房间也无法正常使用了。
在 Java 中的技术本质:
生命周期长的对象,不合理地持有了生命周期短的对象的引用,导致生命周期短的对象在该死亡的时候无法被垃圾回收器回收。
Spring 中的典型例子:
-
将
prototype作用域的 Bean 注入到singleton的 Bean 中 :这个prototypeBean 会一直活到singletonBean 被销毁,失去了"原型"的意义,但如果这个prototypeBean 持有大量数据,就会造成类似内存泄漏的效果。 -
静态集合(
static Map)的滥用 :例如,用一个静态的HashMap做缓存,不停地往里放数据,但没有清除策略。这个HashMap由于是静态的,生命周期与类一样长,会一直持有所有放入对象的引用,导致这些对象永远无法被 GC 回收。 -
监听器或回调未取消注册:向一个全局管理器注册了监听器,但在对象销毁时没有取消注册,导致管理器一直持有该对象的引用。
-
线程局部变量(ThreadLocal)使用不当 :如果使用
ThreadLocal保存了对象,在使用完后没有调用remove()方法,那么在 Web 应用等线程复用(如线程池)的场景下,该对象会一直存在于线程中,无法被回收。
描述Spring MVC处理流程及应用优势?
发送 HTTP 请求
请求到达 DispatcherServlet(前端控制器)
DispatcherServlet是 Spring MVC 的核心,是所有请求的统一入口。它本身不处理业务逻辑,而是作为一个调度员,将请求委托给其他组件处理。
DispatcherServlet查询处理器映射(HandlerMapping)
-
问题 :
DispatcherServlet需要知道"这个请求应该由哪个Controller来处理?" -
动作 :它询问
HandlerMapping:"请求/users/1对应哪个处理器(Handler)?" -
结果 :
HandlerMapping根据请求的 URL 进行匹配,返回一个HandlerExecutionChain(其中包含了目标 Controller 和方法信息,以及可能配置的拦截器 Interceptor)。
DispatcherServlet调用处理器适配器(HandlerAdapter)
-
问题 :
DispatcherServlet需要知道"如何调用这个处理器?" 因为处理器的类型可能多种多样(如基于@Controller注解的、实现Controller接口的等),调用方式不同。 -
动作 :
DispatcherServlet遍历所有HandlerAdapter,问:"你支持这个处理器吗?" 找到支持的适配器后,用它来真正调用我们的 Controller 方法。 -
这是适配器模式的经典应用 ,使得
DispatcherServlet的接口可以统一,而不用关心具体如何调用。
执行控制器(Controller)方法
-
HandlerAdapter调用实际的 Controller 方法(如UserController的getUser(...)方法)。 -
在此过程中:
-
参数解析 :方法参数(如
@PathVariable、@RequestParam、@RequestBody)被解析并传入。 -
业务逻辑调用 :执行你的业务代码(如调用
UserService.findById(1))。 -
拦截器 :如果配置了拦截器,其
preHandle和postHandle方法会在此前后执行。
-
控制器返回模型和视图信息(ModelAndView)
-
Controller 方法处理完后,返回一个结果。这个结果通常不是直接的视图,而是一个指示。
-
常见返回类型:
-
String:一个逻辑视图名(如"userDetail")。 -
ModelAndView:包含模型数据和视图名的对象。 -
Object(通常带有@ResponseBody):直接返回数据(如 JSON/XML),跳过视图解析。
-
处理返回结果(DispatcherServlet处理返回值)
-
如果返回的是视图名,
DispatcherServlet会继续下一步(视图解析)。 -
如果返回的是数据(如带有
@ResponseBody),DispatcherServlet会直接跳到第9步,通过HttpMessageConverter将对象转换为 JSON/XML 等格式。
解析视图(ViewResolver)
-
问题 :逻辑视图名
"userDetail"对应哪个真正的视图文件? -
动作 :
DispatcherServlet将视图名传递给ViewResolver(视图解析器)。 -
结果 :
ViewResolver解析出真正的视图对象(如InternalResourceView,对应/WEB-INF/jsp/userDetail.jsp)
渲染视图(View)
-
动作 :
DispatcherServlet将第5步中准备好的模型数据(Model)传递给视图对象(View)。 -
渲染:视图对象使用模型数据来渲染输出(如 JSP 中的 JSTL 标签将显示数据)。
-
对于 JSP,其实就是将模型数据放入 request 属性,然后转发(forward)到 JSP 页面。
返回 HTTP 响应
- 最终,渲染后的内容(HTML 页面、JSON 数据等)通过
HttpServletResponse返回给客户端,用户浏览器看到结果。
Spring MVC 的应用优势
-
清晰的职责分离(松耦合)
-
每个组件(
DispatcherServlet,Controller,ViewResolver,View等)职责单一,互不干扰。 -
开发者只需关注
Controller中的业务逻辑和View中的页面渲染,其他流程由框架自动组装。这使得代码结构清晰,易于维护和测试。
-
-
高度可配置和可扩展
-
核心接口都是可插拔的 !如果你不喜欢默认的
HandlerMapping、ViewResolver,完全可以配置或自定义自己的实现。 -
例如,可以轻松地从 JSP 视图技术切换为 Thymeleaf 或 FreeMarker,只需更换
ViewResolver配置即可,无需修改 Controller 代码。
-
-
与 Spring 生态系统无缝集成
-
Spring MVC 是 Spring 家族的一部分,可以轻松享受 Spring 核心容器的所有好处。
-
依赖注入(IoC):可以方便地将 Service、Repository 等 Bean 注入到 Controller 中。
-
面向切面编程(AOP):可以轻松地为业务逻辑添加事务管理、日志记录、安全控制等通用功能。
-
-
强大的数据绑定、验证和类型转换
-
自动将请求参数(String 类型)绑定到 Controller 方法的复杂对象参数上(如
User对象)。 -
内置强大的验证机制(如使用 JSR-303/349 规范的
@Valid注解),极大地简化了表单处理。
-
-
灵活的视图技术支持
- 不局限于 JSP,支持各种主流模板技术(Thymeleaf, FreeMarker, Groovy Templates等)甚至可以直接生成 PDF、Excel 等非 HTML 输出。
-
强大的注解驱动编程模型
- 使用
@Controller,@RequestMapping,@RequestParam,@PathVariable等注解,使得控制器代码非常简洁、直观、易于理解。
- 使用
-
RESTful 支持的"一等公民"
- 通过
@RestController,@ResponseBody,@RequestBody等注解,开发 RESTful Web Service 变得非常简单和自然,是构建现代前后端分离架构的理想选择。
- 通过
-
强大的拦截器(Interceptor)机制
- 提供了类似于 Filter 的功能,但更强大、更易于使用(可以访问 Spring 容器中的 Bean),常用于实现权限验证、日志记录、本地化解析等横切关注点。
Spring中的事务处理方式及优缺点?
Spring 事务管理的核心优势在于它提倡的 声明式事务管理。这与传统的编程式事务形成鲜明对比。
-
编程式事务 :在业务代码中,手动编写事务管理的代码(如
beginTransaction(),commit(),rollback())。事务逻辑与业务逻辑紧密耦合。 -
声明式事务 :通过配置(注解或XML)来声明事务的规则(如哪些方法需要事务,事务的传播行为、隔离级别等)。事务逻辑与业务逻辑完全解耦。
简单比喻:
-
编程式事务 :就像你开车时,每次换挡都要手动操作离合器(
beginTransaction())和换挡杆(commit())。 -
声明式事务 :就像开自动挡汽车,你只需要声明"我要前进"(
@Transactional),换挡的事情交给变速箱(Spring 框架)自动完成。
Spring 事务管理的核心接口是 PlatformTransactionManager,它为不同的事务 API(如 JDBC、JPA、Hibernate 等)提供了统一的抽象。
一、事务处理方式
Spring 提供了两种主要的事务处理方式。
- 编程式事务管理
这种方式允许你在代码中精确控制事务的边界。Spring 主要提供了两种实现:
TransactionTemplate(推荐方式):类似于JdbcTemplate,它使用了回调模式,帮助处理事务的打开和关闭,避免了常见的 try-catch 代码块。
java
@Service
public class UserService {
@Autowired
private TransactionTemplate transactionTemplate;
public void createUser(final User user) {
// 使用 TransactionTemplate 执行需要在事务中运行的代码
transactionTemplate.execute(status -> {
try {
userDao.save(user);
logDao.save(new Log("User created"));
// 如果一切正常,事务模板会自动提交事务
return null;
} catch (Exception e) {
// 如果发生异常,标记事务为回滚
status.setRollbackOnly();
throw e;
}
});
}
}-
优点:对事务的控制力非常强,可以在代码中灵活控制。
缺点:事务代码侵入到了业务逻辑中,破坏了代码的整洁性。
-
底层
PlatformTransactionManager:直接使用TransactionManager来手动获取和操作事务对象,代码最繁琐,一般不推荐。
- 声明式事务管理(主流方式)
这是 Spring 最推荐的方式,通过 **AOP(面向切面编程)**实现。你只需要通过注解或 XML 声明事务属性,Spring 会在运行时自动为方法创建代理,加入事务管理逻辑。
实现方式:使用 @Transactional注解
java
@Service
public class OrderService {
@Autowired
private OrderDao orderDao;
@Autowired
private InventoryDao inventoryDao;
// 在方法上声明事务属性
@Transactional(
propagation = Propagation.REQUIRED, // 传播行为:如果当前没有事务,就新建一个
isolation = Isolation.DEFAULT, // 隔离级别:使用数据库默认
rollbackFor = Exception.class, // 回滚规则:遇到所有Exception都回滚
timeout = 5 // 超时时间:5秒
)
public void placeOrder(Order order) {
// 业务逻辑:这些操作将在同一个事务中执行
orderDao.save(order); // 1. 保存订单
inventoryDao.reduce(order); // 2. 减库存
// 如果减库存失败抛出异常,保存订单的操作也会自动回滚
}
// 只读查询,可以优化性能
@Transactional(readOnly = true)
public Order findOrderById(Long id) {
return orderDao.findById(id);
}
}工作原理(基于AOP代理):
-
当你在方法上添加
@Transactional后,Spring 会为该 Bean 创建一个代理对象。 -
当你调用
placeOrder方法时,实际上是先调用代理对象的方法。 -
代理对象 在调用真实目标方法前后,会完成一系列事务操作:
-
开启事务(必要时)
-
调用目标方法(你的业务逻辑)
-
如果方法成功执行,提交事务
-
如果方法抛出异常,回滚事务
-
声明式事务的优缺点
| 优点 | 缺点 |
|---|---|
| 1. 非侵入式:业务代码纯净,完全不受事务代码污染。 | 1. 粒度较粗 :只能在public方法 上生效。同类方法调用 会失效(即一个没有@Transactional的A方法调用同一个类中有@Transactional的B方法,B方法的事务不生效)。 |
| 2. 易于维护:事务规则集中管理(在注解或配置中),修改容易。 | 2. 理解成本高:需要理解事务的传播行为、隔离级别等概念,配置不当容易出错。 |
3. 减少模板代码 :避免了大量重复的 try-catch-finally代码块。 |
3. 调试复杂:由于是基于AOP代理,当事务行为不符合预期时,调试起来比直接编码更复杂。 |
| 4. 一致性:为整个应用提供了统一、一致的事务管理方式。 | 4. 功能限制:对于极少数需要非常精细控制事务边界(如在方法中间提交事务)的复杂场景,声明式事务无法满足。 |
| 5. 易于测试:可以轻松地通过配置关闭事务,方便进行单元测试。 |
编程式事务的优缺点
| 优点 | 缺点 |
|---|---|
| 1. 控制力强:可以精确控制事务的边界,甚至在方法执行过程中进行细粒度控制(如部分提交)。 | 1. 侵入性强:事务代码与业务代码严重耦合,破坏了代码的整洁和可读性。 |
| 2. 灵活度高:适用于非常复杂的业务场景,声明式事务难以表达的逻辑。 | 2. 代码冗余:需要编写大量重复的事务管理代码模板。 |
| 3. 容易出错:需要开发者手动处理事务的提交和回滚,容易遗漏导致资源未释放或事务未正确结束。 | |
| 4. 难以维护:当需要修改事务规则时,需要散落到各处代码中去修改。 |
MyBatis应用中#与$有什么异同点?
一、核心结论
-
#{}:是参数占位符 。MyBatis 会将其解析为一个 JDBCPreparedStatement的参数标记(?),并进行预编译 。能有效防止 SQL 注入 ,是首选和推荐的方式。 -
${}:是字符串替换符 。MyBatis 会将其内容直接替换到 SQL 语句中,不做任何处理。相当于拼接 SQL 字符串,有SQL 注入风险,但在特定场景下必须使用。
简单比喻:
-
使用
#{}就像点外卖时报出菜名 ("我要一份鱼香肉丝"),厨房(数据库)会按标准流程为你制作,安全卫生。 -
使用
${}就像直接把你的话原样传给厨房 ("我要一份鱼香肉丝"或者"鱼香肉丝; DROP TABLE ..."),厨房会直接执行你传来的指令,非常危险。
| 特性 | #{}(参数占位符) |
${}(字符串替换) |
|---|---|---|
| 处理方式 | 转换为 PreparedStatement的 ?,预编译。 |
直接字符串拼接到 SQL 中。 |
| 安全性 | 高 ,能有效防止 SQL 注入。 | 低 ,存在 SQL 注入攻击风险。 |
| 性能 | 高。预编译的 SQL 可以被数据库缓存,下次执行更快。 | 低。每次都可能生成不同的 SQL 语句,无法利用预编译缓存。 |
| 使用场景 | 几乎所有传入参数值的场景。 | 动态指定表名、列名、SQL 关键字等非值参数。 |
| 参数类型 | 会自动识别并设置 JDBC 类型,可以处理复杂类型(如 Map, POJO)。 |
简单字符串替换,如果值不是字符串会报错。 |
| 举例 | WHERE name = #{name}-> WHERE name = ? |
ORDER BY ${columnName}-> ORDER BY create_time |
MyBatis应用动态SQL解决了什么问题?
| 解决的问题 | MyBatis 动态 SQL 的解决方案 | 带来的优势 |
|---|---|---|
| SQL 拼接易出错 | 使用标签逻辑代替字符串拼接。 | 编写简单,不易出错,可读性极高。 |
| SQL 注入风险 | 动态生成的 SQL 依然使用 #{}参数占位符。 |
保持了预编译的安全性,从根本上防止 SQL 注入。 |
| 代码冗长维护难 | 将动态判断逻辑从 Java 代码转移到 XML 配置中。 | 业务代码(Java)与数据操作代码(SQL)解耦,结构清晰,易于维护。 |
| 复杂业务查询 | 提供强大的标签(if, choose, foreach等)覆盖几乎所有复杂场景。 |
极大地提高了复杂查询的开发效率和代码的可表达性。 |
Shiro框架权限管理时的认证和授权流程描述?
首先,记住一个最简单的区分:
-
认证(Authentication) :你是谁?-> 验证用户身份,比如用户名密码登录。解决的是"身份"问题。
-
授权(Authorization) :你能做什么?-> 判断已认证的用户是否有权限执行某个操作。解决的是"权限"问题。
**先认证,后授权。**你必须先知道用户是谁,才能判断他有什么权限。
BeanFactory和ApplicationContext有什么区别?
ApplicationContext是 BeanFactory的子接口 。这意味着 ApplicationContext包含了 BeanFactory的所有功能,并在此基础上进行了大量的扩展。
可以这样比喻:
-
BeanFactory就像一个基础版的手机工厂 ,只负责手机(Bean)的组装 和基本的生命周期管理(打电话、发短信)。 -
ApplicationContext则是一个高级的智能手机工厂 。它除了具备基础工厂的所有功能外,还内置了应用商店 (国际化)、消息推送 (事件发布)、更智能的自动化流水线 (自动识别@Configuration等注解)等高级功能。
在绝大多数现代 Spring 应用中,我们直接使用的就是功能更强大的 ApplicationContext。
| 特性 | BeanFactory |
ApplicationContext |
|---|---|---|
| 继承关系 | 是 IOC 容器的顶层核心接口,最基础。 | 扩展了 BeanFactory接口,是其超集。 |
| Bean 的加载时机 | 延迟加载/懒加载 。只有在真正使用 getBean()获取某个 Bean 时,才会实例化该 Bean。 |
默认立即加载/预加载 。容器启动时,就会创建和配置所有的单例 Bean。 |
| 国际化支持(i18n) | 不支持。 | 支持 。通过 MessageSource接口,可以轻松处理多语言消息。 |
| 事件发布机制 | 不支持。 | 支持 。基于 ApplicationEventPublisher接口,可以实现 观察者模式的事件驱动编程。 |
| 资源访问 | 功能较弱。 | 功能强大 。提供更方便的 API(如 getResource())来访问文件、URL 等资源。 |
| 与 AOP 的集成 | 需要额外配置才能与 AOP 集成。 | 无缝集成AOP,提供了声明式企业服务的支持。 |
| 注解支持 | 不支持 Spring 的注解(如 @Autowired, @Transactional)。 |
全面支持 Spring 的各种注解(如 @Component, @Autowired, @Configuration)。 |
| 实现类 | 最常用:XmlBeanFactory(已废弃)。 |
丰富多样,如: • ClassPathXmlApplicationContext • AnnotationConfigApplicationContext • XmlWebApplicationContext |
请解释Spring Bean的生命周期?
Bean 的生命周期可以分为两大阶段:
-
Bean 的实例化与初始化:从无到有,成为一个功能完备的 Bean。
-
Bean 的运行时与销毁:提供服务,直至容器关闭时被销毁。
下图清晰地展示了 Spring Bean 从创建到销毁的完整生命周期流程,特别是那些可供开发者介入的关键扩展点:
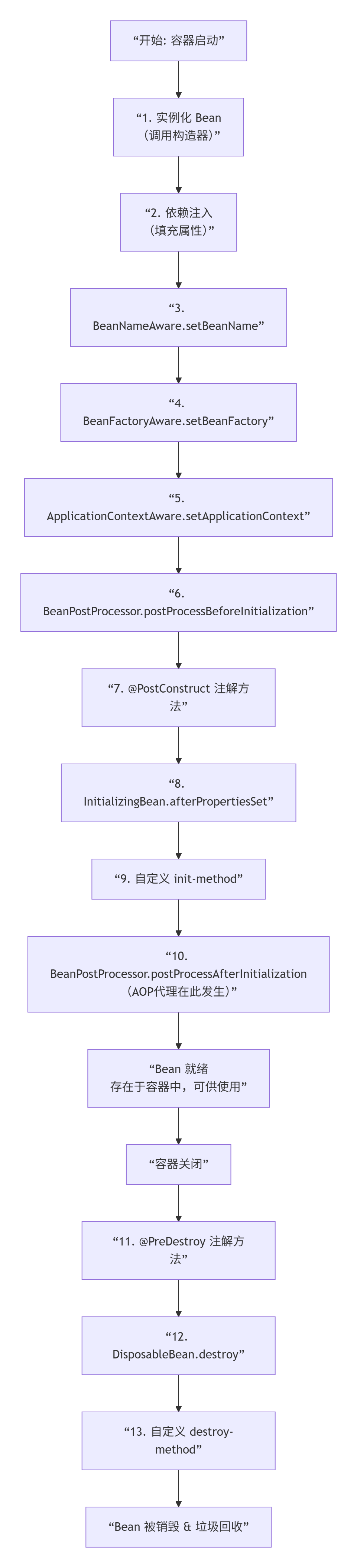
Spring Bean的作用域之间有什么区别?
| 作用域 | 说明 | 适用场景 |
|---|---|---|
| singleton (默认) | 在单个 IoC 容器中,一个 Bean 定义只对应一个实例。 | 无状态的 Bean,如服务层(Service)、数据访问层(Dao)、工具类。 |
| prototype | 每次通过容器获取该 Bean 时,容器都会创建一个新的实例。 | 有状态的 Bean,需要保持各自状态的场景,如购物车、表单对象。 |
| request | 一次 HTTP 请求范围内,一个 Bean 定义只对应一个实例。 | 用于存放每次 HTTP 请求的特定信息,如请求参数。 |
| session | 一个 HTTP Session 生命周期内,一个 Bean 定义只对应一个实例。 | 用于存放用户级别的信息,如用户登录信息、购物车。 |
| application | 在一个 ServletContext生命周期内,一个 Bean 定义只对应一个实例。 |
用于存放全局的、应用级别的信息,如应用的配置、缓存。 |
| websocket | 在一个 WebSocket 会话生命周期内,一个 Bean 定义只对应一个实例。 | 用于 WebSocket 通信,保存会话级别的状态。 |
使用Spring框架的好处是什么?
| 维度 | 好处描述 | 核心价值 |
|---|---|---|
| 架构设计 | 促进良好的编程实践,如松耦合、面向接口编程。 | 代码质量高,易于维护和扩展。 |
| 开发效率 | 减少大量样板代码,提供声明式编程模型,集成开发工具强大。 | 开发速度快,生产力高。 |
| 技术整合 | 一站式解决方案,能优雅地集成各种企业应用和技术。 | 技术选型成本低,解决方案成熟。 |
| 可测试性 | 依赖注入使单元测试变得非常简单。 | 软件质量有保障,易于重构。 |
| 社区与生态 | 拥有最活跃的 Java 社区,生态完整,持续更新。 | 学习资源丰富,技术有长期生命力,降低技术风险。 |
Spring 中用到了那些设计模式?
| 设计模式 | Spring 中的体现 | 解决的问题 |
|---|---|---|
| 工厂模式 | BeanFactory, ApplicationContext |
统一管理对象的创建与组装 |
| 单例模式 | Bean 的默认作用域 | 保证一个类只有一个实例,节省资源 |
| 代理模式 | Spring AOP | 在不修改目标对象的情况下增强其功能 |
| 模板方法 | JdbcTemplate, XxxTemplate |
消除重复代码,封装固定流程 |
| 适配器模式 | HandlerAdapter(Spring MVC) |
使不兼容的接口能够协同工作 |
| 策略模式 | Resource, CacheManager的实现 |
封装算法,使其可灵活替换 |
| 观察者模式 | 事件发布/监听机制(ApplicationEvent) |
实现应用内解耦的消息通信 |
Spring 如何保证 Controller 并发的安全?
Spring 通过其单例、无状态的默认设计 ,引导你走向线程安全的开发模式。你只需要遵循这个约定,不在 Controller(以及 Service、Dao)中保存可变状态,而将所有状态数据通过方法参数传递或交由数据库/Session 管理,那么你的应用自然就是并发安全的。
核心结论
-
Spring 的
Controller默认是单例的,且本身无状态,所以是线程安全的。 -
如果开发者不小心将
Controller变成了有状态的,那么它就不是线程安全的,并发问题就会出现。 -
Spring 保证并发安全的方式,其实是它推荐的"无状态"编程模型。你的任务是遵守这个模型。
| 做法 | 是否安全 | 说明 |
|---|---|---|
Controller无状态,只依赖无状态的 Service |
安全 (推荐) | Spring 设计的初衷,性能最佳,完全线程安全。 |
Controller包含可变成员变量 |
不安全 | 会导致脏数据、状态错乱等并发问题。 |
将 Controller设为 prototype作用域 |
安全但糟糕 | 通过牺牲性能(频繁创建对象)来规避问题,是错误的设计。 |
使用线程安全容器(如 ConcurrentHashMap) |
安全 | 适用于需要在多个请求间安全共享数据的特定场景。 |
在 Spring中如何注入一个java集合?
主要有两种方法:基于 XML 的配置 和基于注解的配置。
基于注解的配置(现代 Spring 应用首选)
1. 直接注入集合(注入所有同类型的 Bean)
如果你有一个接口 MyService和它的多个实现类,你可以直接将所有实现类的实例注入到一个 List或 Map中。Spring 会自动收集容器中所有匹配的 Bean。
java
public interface MyService {
void doSomething();
}
@Component("serviceA") // 给Bean指定名称
public class MyServiceA implements MyService { ... }
@Component("serviceB")
public class MyServiceB implements MyService { ... }
@Component("serviceC")
public class MyServiceC implements MyService { ... }使用 @Autowired注入 List(按实现类的顺序)
java
@Component
public class ClientComponent {
// 注入所有类型为 MyService 的 Bean
@Autowired
private List<MyService> allServices; // 包含 [serviceA, serviceB, serviceC]
public void useAllServices() {
for (MyService service : allServices) {
service.doSomething();
}
}
}使用 @Autowired注入 Map(Bean 名称作为 Key)
java
@Component
public class ClientComponent {
// 注入一个Map,Key是Bean的名称,Value是Bean的实例
@Autowired
private Map<String, MyService> serviceMap; // 包含 {"serviceA" -> MyServiceA实例, ...}
public void useServiceByName(String name) {
MyService service = serviceMap.get(name);
if (service != null) {
service.doSomething();
}
}
}| 场景 | 推荐方式 | 示例 |
|---|---|---|
| 注入所有同类型 Bean | @Autowired到 List或 Map |
@Autowired private List<MyService> allServices; |
| 注入配置文件中的简单值集合 | @Value配合 SpEL |
@Value("#{'${list}'.split(',')}") private List<String> list; |
| 需要完全控制集合内容 | Java Config 中的 @Bean方法 |
@Bean public List<MyService> myList() { ... } |
| 需要筛选特定 Bean 注入 | @Autowired+ @Qualifier |
@Autowired @Qualifier("cluster") private List<MyService> clusterNodes; |
| 传统项目或 XML 配置 | XML 中的 <list>, <map> |
<list><ref bean="..."/></list> |
Spring框架的事务管理有哪些优点?
| 优点 | 描述 | 带来的价值 |
|---|---|---|
| 一致的抽象 | 统一了不同数据访问技术的事务 API。 | 解耦 ,技术选型灵活。 |
| 声明式模型 | 通过注解配置,非侵入式。 | 代码简洁 ,可维护性高 ,开发效率高。 |
| 可测试性 | 易于进行单元测试。 | 软件质量高 ,调试简单。 |
| 功能丰富 | 支持传播行为、隔离级别等高级特性。 | 能处理复杂的事务场景。 |
| 集成性好 | 与整个 Spring 生态无缝集成。 | 开发体验流畅,学习成本低。 |
Spring MVC的主要组件?
| 组件 | 核心职责 | 比喻 |
|---|---|---|
DispatcherServlet |
总调度,统一入口 | 前台总机 / 交通枢纽 |
HandlerMapping |
路由映射,找处理器 | 路由表 / 导航仪 |
HandlerAdapter |
适配并执行处理器 | 万能适配器 / 翻译官 |
Controller |
执行业务逻辑 | 业务部门 / 工人 |
ViewResolver |
解析逻辑视图名 | 地址翻译器 |
View |
渲染最终响应 | 模板引擎 / 画笔 |
HandlerExceptionResolver |
统一异常处理 | 救火员 / 医生 |
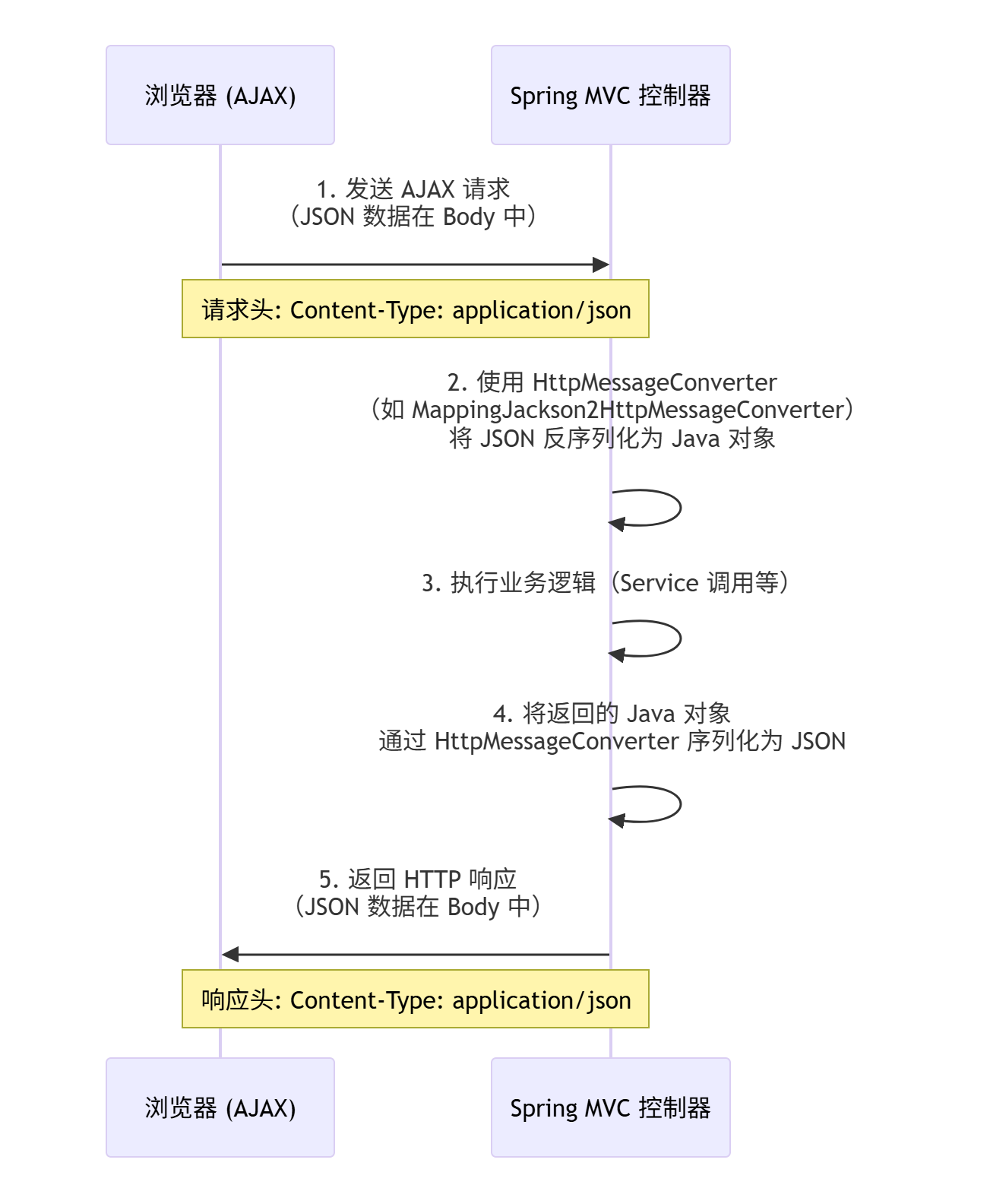
SpringMvc怎么和AJAX相互调用的?
Spring MVC 通过 HttpMessageConverter 机制来实现与 AJAX 的无缝集成。当控制器方法使用了 @ResponseBody注解时,Spring 会根据请求的 Content-Type和 Accept头信息,自动选择合适的 HttpMessageConverter来:
-
将 AJAX 请求体中的 JSON/XML 数据反序列化为 Java 对象 (
@RequestBody)。 -
将 Java 对象序列化为 JSON/XML 数据并写入 HTTP 响应体 (
@ResponseBody)。
下图清晰地展示了 Spring MVC 与 AJAX 请求/响应的完整交互流程:
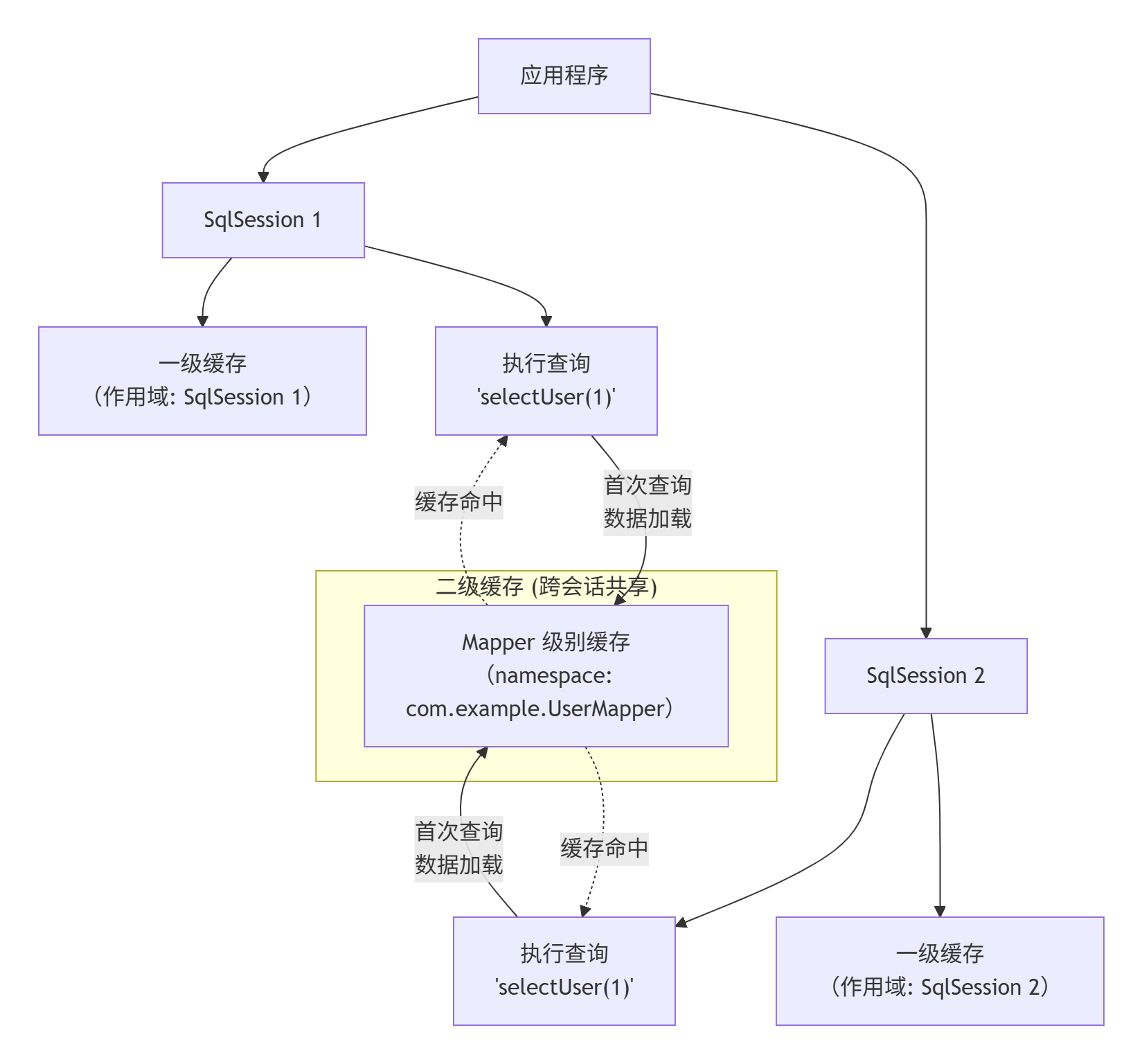
mybatis的缓存机制,一级,二级介绍一下?
核心结论
-
一级缓存 :会话级缓存 ,默认开启,作用域为 同一个
SqlSession。在同一个会话中,相同的查询只会执行一次 SQL。 -
二级缓存 :应用级缓存 ,需要手动开启,作用域为 同一个
namespace(Mapper 接口) 。跨SqlSession共享缓存数据。
为了更直观地理解这两级缓存的作用域与生命周期,下图展示了它们的核心区别:
| 特性 | 一级缓存 | 二级缓存 |
|---|---|---|
| 作用域 | SqlSession |
Mapper(namespace) |
| 生命周期 | 会话结束即销毁 | 与应用生命周期相同(可配置) |
| 默认状态 | 开启 | 关闭,需手动配置 |
| 共享性 | 不能跨会话共享 | 跨所有 SqlSession共享 |
| 存储位置 | 内存(SqlSession内部) |
内存/磁盘(可配置第三方缓存,如 Redis, Ehcache) |
| 数据提交 | 默认存在 | 在 SqlSession关闭后才提交 |
| 清空条件 | 执行 UPDATE/INSERT/DELETE 或 clearCache() |
执行同 namespace 的 UPDATE/INSERT/DELETE |
springMVC与Struts2的区别?
| 特性 | Spring MVC | Struts2 |
|---|---|---|
| 核心控制器与机制 | 前端控制器:DispatcherServlet(一个 Servlet) |
核心过滤器:FilterDispatcher(一个 Filter) |
| 入口点设计 | 基于 Servlet,更符合 Java EE 标准。 | 基于 Filter,可以对所有请求进行拦截处理。 |
| 处理请求的组件 | 基于方法的控制器 (@Controller类中的 @RequestMapping方法)。 |
基于类的 Action (通常继承 ActionSupport,每次请求创建一个新实例)。 |
| 实例化模式 | 默认单例模式 。一个 Controller实例处理所有请求,性能高。但需确保线程安全(即不要使用成员变量保存请求相关状态)。 |
每次请求创建一个新的 Action实例 。通过实例变量封装请求和响应数据,天然线程安全 ,但性能开销大。 |
| 依赖注入(DI) | 与 Spring IoC 容器无缝集成 ,是其核心优势。可以使用 @Autowired等注解轻松管理依赖,AOP 等企业级功能开箱即用。 |
整合能力较弱。需要与 Spring 集成时,通常通过插件(如 Spring Plugin)或手动方式,体验不原生。 |
| 配置方式 | 推崇注解驱动 (如 @Controller, @RequestMapping),配置简洁明了。 |
传统 XML 配置驱动 。需要在 struts.xml中为每个 Action 配置 <action>节点,繁琐且易出错。 |
| 数据传递 | 方法参数绑定 。可以通过 @RequestParam, @PathVariable, @ModelAttribute等注解灵活地将请求参数注入到方法参数中。 |
通过 Action 类的成员属性和 getter/setter 方法。需要为每个参数定义属性并提供 get/set 方法,代码冗长。 |
| 拦截器 vs 拦截器 | 拦截器(Interceptor):功能类似 AOP,可基于方法进行更精细的拦截。 | 拦截器(Interceptor):是其强大功能的基石(如验证、文件上传),但配置复杂。 |
| 社区生态与现状 | 极其活跃 。是 Spring 全家桶的一部分,与 Spring Boot、Spring Cloud 等无缝集成,是当今绝对的主流和事实标准。 | 基本被淘汰 。近年来爆出多个严重安全漏洞,官方已停止维护,新项目绝对不应再选用。 |
| 学习曲线 | 易于上手,尤其是与 Spring Boot 结合时。 | 配置复杂,需要理解其架构和标签库。 |
| 测试 | 非常容易测试。容器外的单元测试非常方便,无需启动 Web 服务器。 | 测试相对复杂,需要更多模拟。 |
| RESTful 支持 | 原生支持极好 。通过 @RestController, @GetMapping等注解,开发 REST API 非常简单优雅。 |
支持较差。需要额外的配置和约定,不如 Spring MVC 自然。 |
mybatis的基本工作流程?
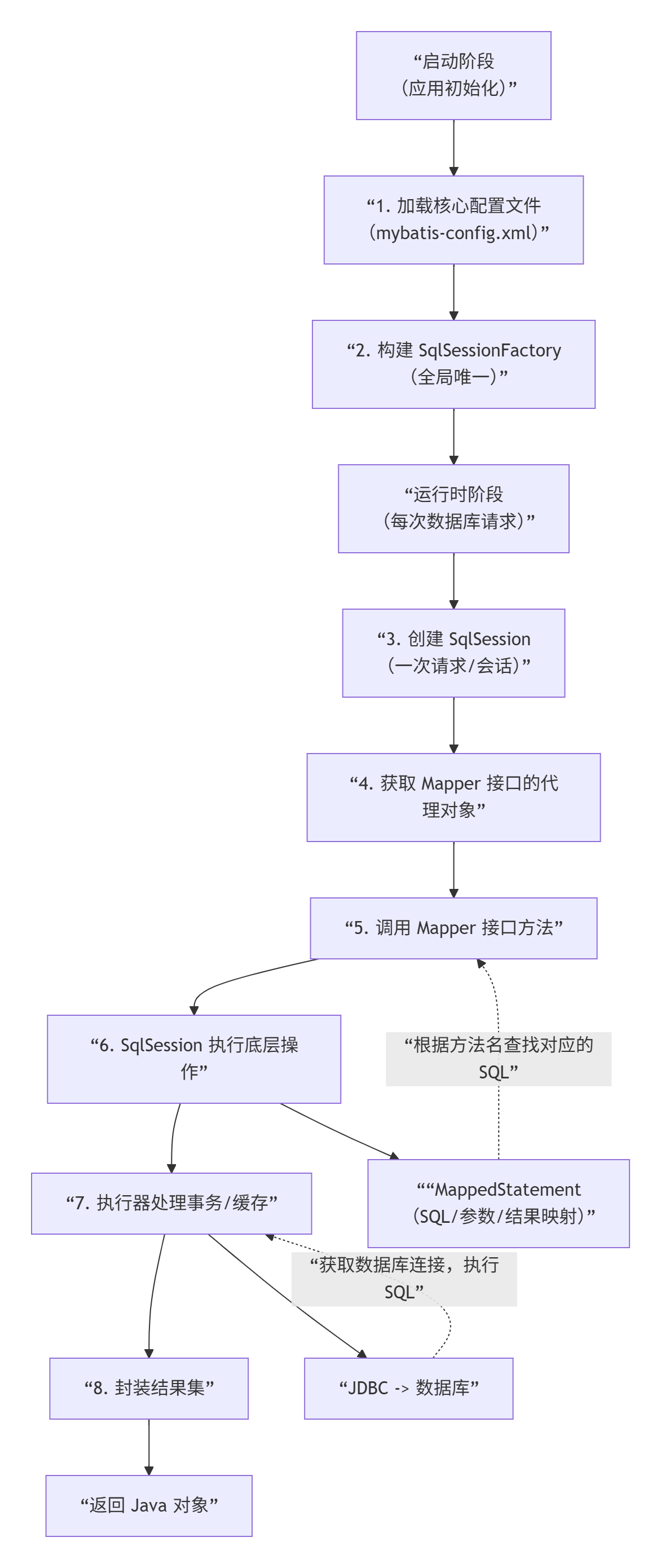
第一阶段:启动阶段(应用初始化时)
这个阶段发生在应用程序启动时,目的是为运行时操作准备好"工厂"。
步骤 1 & 2: 构建 SqlSessionFactory
SqlSessionFactory是 MyBatis 的核心,它是全局单例 的,一旦创建,在应用运行期间都会存在。它的作用是创建 SqlSession。
构建方式:
通常从 XML 配置文件(通常是 mybatis-config.xml)或通过 Java 代码(配置类)来构建。
java
// 经典方式:通过 XML 配置文件构建
String resource = "org/mybatis/example/mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSqlSessionFactoryBuilder().build(inputStream);
// Spring 集成下通常由 Spring 容器管理,直接注入即可
@Autowired
private SqlSessionFactory sqlSessionFactory;在构建过程中,MyBatis 会做哪些事?
-
解析全局配置文件:读取数据源、事务管理器、设置(如缓存、日志实现)等。
-
加载映射文件/接口 :解析所有的
Mapper.xml文件,或者扫描带有 MyBatis 注解的 Mapper 接口。 -
创建
Configuration对象 :将解析到的所有配置信息(环境、Mapper 注册信息、缓存的配置、每个 SQL 语句的定义等)都保存在一个全局的Configuration对象中。你可以将Configuration理解为 MyBatis 的"大脑",它包含了整个框架运行所需要的全部信息。
第二阶段:运行时阶段(每次数据库操作)
当需要执行数据库操作时,流程进入运行时阶段。
步骤 3: 创建 SqlSession
SqlSession代表了和数据库的一次会话 。它包含了执行 SQL 所需的所有方法。它的生命周期应该很短暂 ,通常在一个请求或一个方法中创建,使用完毕后必须立即关闭,以防止数据库连接泄漏。
步骤 4 & 5: 获取 Mapper 接口并调用方法
这是 MyBatis 最巧妙的地方:你只需要定义一个 Java 接口,而无需编写其实现类 。MyBatis 会使用 动态代理技术为你自动创建接口的代理实现。
幕后发生了什么?
当调用 userMapper.selectUser(1L)时,实际上调用的是 MyBatis 创建的一个代理对象的方法。这个代理对象会:
-
方法映射 :根据接口的全限定名(
UserMapper) 和方法名(selectUser) ,在步骤 2 中准备好的Configuration对象里找到一个唯一的MappedStatement。 -
MappedStatement:这是 MyBatis 内部一个非常重要的对象,它封装了一条 SQL 语句的所有信息:-
SQL 内容(
SELECT * FROM users WHERE id = ?) -
参数映射规则(如何将 Java 参数
1L设置到 SQL 的?中) -
结果映射规则(如何将 JDBC 返回的
ResultSet转换成User对象) -
缓存信息、执行类型(
SELECT,UPDATE等)
-
步骤 6, 7, 8: SqlSession执行底层操作
代理对象拿到 MappedStatement和参数后,会委托给 SqlSession去执行具体的方法(如 selectOne, insert, update)。
-
SqlSession将任务交给Executor(执行器):Executor是真正执行 SQL 的核心组件。它负责维护一级缓存和二级缓存,以及管理事务。 -
Executor将任务交给StatementHandler(语句处理器):StatementHandler负责创建JDBC的Statement对象(如PreparedStatement),并进行参数赋值。 -
参数处理 :
ParameterHandler负责将传入的 Java 参数(如1L)转换成 JDBC 所需的类型,并设置到PreparedStatement中。 -
执行 SQL :
StatementHandler执行PreparedStatement.execute(),与数据库交互。 -
结果集映射 :
ResultSetHandler负责将返回的ResultSet结果集,根据MappedStatement中定义的结果映射规则(ResultMap) ,转换成User对象。
步骤 9: 返回结果
最终,这个转换好的 User对象沿着调用链返回:
ResultSetHandler-> Executor-> SqlSession-> 代理对象 -> 你的代码。
这样,你就拿到了一个完整的 User对象,而整个过程你几乎没有编写任何 JDBC 样板代码。
| 步骤 | 核心组件 | 职责 |
|---|---|---|
| 启动阶段 | SqlSessionFactoryBuilder |
根据配置构建 SqlSessionFactory。 |
SqlSessionFactory |
生产 SqlSession的工厂,全局唯一。 |
|
Configuration |
配置信息的容器,MyBatis 的"大脑"。 | |
| 运行时阶段 | SqlSession |
一次数据库会话的抽象,提供 CRUD API。 |
Executor |
SQL 执行器,负责缓存和事务。 | |
MappedStatement |
封装了一条 SQL 的所有信息。 | |
StatementHandler |
处理 JDBC Statement。 | |
ParameterHandler |
处理 SQL 参数。 | |
ResultSetHandler |
处理结果集映射。 |
什么是MyBatis的接口绑定,有什么好处?
MyBatis 的接口绑定 是一种机制,它允许你只定义一个 Java 接口 ,然后 MyBatis 框架会在运行时自动为你创建这个接口的实现类。你无需编写任何接口的实现代码,就能直接调用接口的方法来执行数据库操作。
简单来说:你定义接口,MyBatis 提供实现。
它是如何工作的?
这背后的核心技术是 JDK 动态代理 。当你通过 SqlSession.getMapper(YourMapperInterface.class)方法获取一个 Mapper 接口的实例时,MyBatis 并没有返回一个真正的实现类对象,而是返回了一个实现了该接口的代理对象。
当你调用这个代理对象的方法时(如 userMapper.selectUser(1)),代理对象会拦截这个调用,并根据接口的全限定名 和方法名,去找到对应的 SQL 映射(定义在 XML 文件或注解中的 SQL 语句),然后执行它,最后将结果返回。
二、接口绑定的两种实现方式
方式 1:XML 文件绑定(最常用、最强大)
创建一个 Java 接口,然后创建一个同名的 XML 映射文件,在 XML 文件中编写 SQL。
1. 定义 Mapper 接口
java
// UserMapper.java
public interface UserMapper {
User selectUserById(Long id);
int insertUser(User user);
int updateUser(User user);
List<User> selectAllUsers();
}注意 :接口中只有方法声明,没有实现体。
2. 创建同名的 XML 映射文件 (UserMapper.xml)
XML
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!-- namespace 属性必须指向对应的 Mapper 接口的全限定名 -->
<mapper namespace="com.example.mapper.UserMapper">
<!--
id 属性必须和接口中的方法名一致。
resultType 属性定义了方法的返回类型。
-->
<select id="selectUserById" parameterType="long" resultType="com.example.entity.User">
SELECT * FROM users WHERE id = #{id}
</select>
<insert id="insertUser" parameterType="com.example.entity.User">
INSERT INTO users (name, email) VALUES (#{name}, #{email})
</insert>
<!-- 其他 SQL 语句 -->
</mapper>方式 2:注解绑定(适合简单 SQL)
直接在接口的方法上使用注解来编写 SQL。
java
public interface UserMapper {
@Select("SELECT * FROM users WHERE id = #{id}")
User selectUserById(Long id);
@Insert("INSERT INTO users (name, email) VALUES (#{name}, #{email})")
@Options(useGeneratedKeys = true, keyProperty = "id") // 获取自增主键
int insertUser(User user);
@Update("UPDATE users SET name=#{name}, email=#{email} WHERE id=#{id}")
int updateUser(User user);
}| 好处 | 说明 |
|---|---|
| 1. 类型安全(最重要的好处) | 方法调用、参数和返回值都是强类型 的。编译器会在编译期检查错误。如果你把 userMapper.selectUserById("abc")写成了字符串,编译器会直接报错。而传统方式 selectOne("statement", "abc")要等到运行时才会可能出错。 |
| 2. 代码清晰,易于维护 | 代码的可读性极高。userMapper.insertUser(user)的意图一目了然,远胜于 sqlSession.insert("com.example.mapper.UserMapper.insertUser", user)这种魔法字符串。方法名本身就是最好的文档。 |
| 3. IDE 支持极佳 | 你可以享受 IDE 提供的代码自动完成、重构(重命名方法名会自动更新 XML 的 id)、跳转到实现(虽然实现是动态的,但 IDE 能智能地关联到 XML 或注解)等功能,大大提升开发效率。 |
| 4. 简化单元测试 | 因为你的业务代码依赖于 UserMapper接口,而不是具体的 MyBatis 实现,你可以非常容易地使用 Mock 框架(如 Mockito)创建一个 UserMapper的模拟对象进行单元测试,而无需连接真实的数据库。 |
| 5. 解耦 | 你的业务逻辑代码与 MyBatis 的 API(如 SqlSession)解耦了。业务代码只依赖于一个纯粹的 Java 接口,这使得代码更干净,也更符合面向接口编程的原则。如果未来需要更换持久层框架,迁移成本也更低。 |
MyBatis 的接口绑定是一种革命性的设计,它将数据访问层的定义(接口)与实现(SQL 映射)清晰分离,并通过动态代理技术自动连接两者。它通过提供完全的类型安全性和卓越的 IDE 支持,彻底解决了传统 DAO 模式中字符串 Statement ID 的种种弊端,极大地提升了开发效率、代码质量和可维护性。
MyBatis的编程步骤?

JDBC编程有哪些不足之处,MyBatis是如何解决这些问题的?
| JDBC 的不足 | MyBatis 的解决方案 | 带来的好处 |
|---|---|---|
| 大量样板代码 | SqlSession模板化封装 |
代码简洁,开发效率高 |
| 手动资源管理 | 自动管理连接、语句、结果集 | 避免资源泄漏,更健壮 |
| 手动结果集映射 | 自动对象关系映射(ORM) | 避免繁琐操作,更专注业务 |
| SQL 硬编码 | SQL 与代码分离(XML/注解) | 易于维护,SQL 可优化 |
| 功能单一 | 提供缓存、插件等扩展 | 功能强大,企业级支持 |
| 事务管理复杂 | 与 Spring 集成声明式事务 | 事务控制简单可靠 |
MyBatis的优缺点?
| 优点 | 缺点 |
|---|---|
| 1. SQL 灵活可控,可深度优化 • 开发者拥有 SQL 的完全控制权,可编写任意复杂度的 SQL(如多表连接、存储过程、窗口函数)。 • 便于 DBA 进行 SQL 审核和性能调优,能应对高性能要求的场景。 | 1. 编码工作量较大 • 即使简单的 CRUD 操作,也需要编写 SQL 和结果映射配置,不如 JPA 的派生查询高效。 • 容易产生大量相似的 SQL 语句,造成重复劳动。 |
| 2. 学习曲线平缓,易于上手 • 对于熟悉 SQL 和 JDBC 的开发者非常友好,核心概念少(SqlSession, Mapper)。 • 理念简单:"怎么写 SQL,就怎么用 MyBatis"。 | 2. 数据库移植性差 • 由于直接编写原生 SQL,如果使用了数据库特有的函数或语法,更换数据库时需要重写大量 SQL。 |
| 3. 性能极高 • 是 JDBC 的轻量级封装,自身开销极小。 • 通过精确编写 SQL 可避免 ORM 框架常见的 "N+1 查询" 等性能问题。 • 提供可配置的一级和二级缓存。 | 3. 并非真正的全自动 ORM • 不支持自动脏数据检查 :更新时需要手动判断哪些字段变化。 • 级联操作支持弱 :需要手动处理关联对象的增删改,或编写复杂的 SQL。 • 对复杂对象图的持久化不如 JPA 方便。 |
4. 与复杂/遗留表结构兼容性好 • 通过显式的 ResultMap可以轻松映射数据库字段与对象属性不一致的情况,灵活性极高。 |
4. 代码生成和可维护性挑战 • SQL 写在 XML 中,IDE 的智能提示、重构(如重命名字段)支持相对较弱,容易出现运行时才能发现的拼写错误。 • 动态 SQL 的测试条件基于字符串,重构不友好。 |
| 5. 代码与 SQL 解耦 • SQL 集中在 XML 文件中,与 Java 代码分离,便于管理和评审。 • Mapper 接口使得数据访问层易于进行单元测试(Mock)。 | 5. 需要开发者熟悉 SQL • 性能优劣高度依赖于开发者的 SQL 编写能力,对团队技能有要求。 |
谈谈你对SpringMVC的理解?
| 理解维度 | 核心阐述 |
|---|---|
| 本质是什么 | Spring MVC 是一个基于 Java 的、实现了前端控制器模式 的请求驱动 型 Web 框架。它围绕一个核心的 DispatcherServlet来构建,将复杂的 Web 请求处理流程标准化、组件化。 |
| 核心设计理念 | "约定优于配置" 与 "分离关注点"。它将整个处理流程清晰地划分为不同的角色(控制器、视图解析器、处理器映射等),每个组件职责单一,通过接口抽象,实现了高度可插拔和可扩展的架构。 |
| 工作核心机制 | 1. 请求入口 :所有请求统一由 DispatcherServlet接收。 2. 委托协调 :DispatcherServlet不处理业务,而是协调一系列策略组件(如 HandlerMapping, HandlerAdapter)共同完成请求处理。 3. 视图渲染:最终将模型数据交由视图技术(JSP, Thymeleaf等)渲染,返回响应。 |
| 驱动方式 | 注解驱动 。这是现代 Spring MVC 的主要方式。通过 @Controller, @RequestMapping, @RequestParam等注解,极大地简化了配置,使代码意图清晰,开发效率高。 |
| 与 Spring 生态关系 | 无缝集成 。Spring MVC 是 Spring 家族的一部分,可天然享受 Spring 核心容器的所有优势,如强大的 依赖注入(IoC) 和 面向切面编程(AOP),能轻松集成安全(Spring Security)、数据访问(Spring Data)等其它模块。 |
| 主要优势 | 1. 灵活与松耦合 :组件皆可定制替换。 2. 强大的数据绑定、验证和类型转换 。 3. 卓越的 REST 支持 :通过 @RestController轻松构建 RESTful API。 4. 易于测试 :控制器作为 POJO,非常便于单元测试。 5. 丰富的视图技术支持。 |
| 传统 MVC 框架的超越 | 它超越了传统 MVC(如 Struts2)的"类级别"映射,提供了方法级别 的精细映射,并通过 POJO 开发模型,使控制器不需要实现特定接口或继承特定类,更加轻量。 |
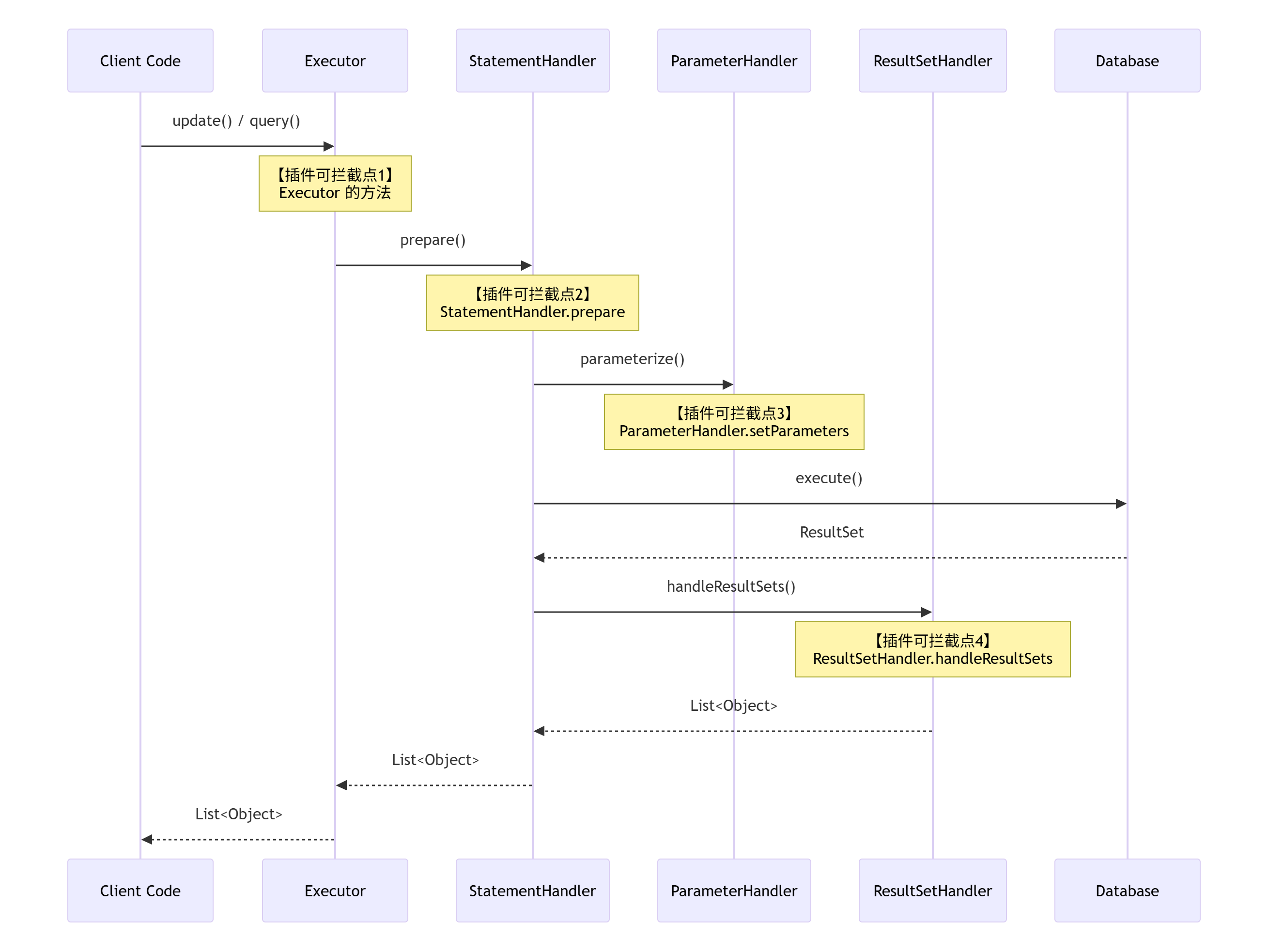
MyBatis 插件运行原理
核心思想:拦截器模式(Interceptor Pattern)
MyBatis 插件的本质是一个拦截器 。它允许你在 MyBatis 执行核心操作的过程中,**"拦截"**特定的方法调用,并在这些方法执行前后插入自定义的逻辑。
- 可拦截的目标
MyBatis 插件只能拦截四大核心接口的方法调用:
| 核心接口 | 作用 | 可拦截的方法举例 |
|---|---|---|
Executor |
执行器,负责增删改查操作、事务管理、缓存。 | update, query, commit, rollback |
ParameterHandler |
参数处理器,负责将 Java 对象转换为 JDBC 参数。 | setParameters |
ResultSetHandler |
结果集处理器 ,负责将 JDBC 返回的 ResultSet转换为 Java 对象。 |
handleResultSets, handleOutputParameters |
StatementHandler |
语句处理器 ,负责与 JDBC 的 Statement交互,包括设置参数。 |
prepare, parameterize, query, update |
这四大对象几乎涵盖了 MyBatis 一次数据库操作的全部关键步骤。下图清晰地展示了插件在 MyBatis 执行流程中的拦截点:
实现原理:动态代理
MyBatis 并不是通过继承或直接修改这些接口的实现类 来实现插件的。那样会破坏开闭原则。它采用的是更优雅的动态代理技术。
工作流程如下:
-
创建目标对象 :当 MyBatis 启动时,会创建上述四大接口的实例(如
SimpleExecutor,PreparedStatementHandler等)。 -
插件拦截:检查配置的插件是否声明要拦截该接口的方法。
-
生成代理对象 :如果需要拦截,MyBatis 会使用 JDK 动态代理 (因为接口都有实现类)为目标对象创建一个代理对象(
Plugin对象)。 -
责任链模式 :如果有多个插件拦截同一个方法,这些代理对象会形成一个拦截器链(Interceptor Chain)。
-
方法调用 :当外部调用目标对象的方法时,实际上调用的是代理对象的
invoke方法。 -
执行拦截 :在代理对象的
invoke方法中,会按顺序调用所有插件的intercept方法,最后再调用真实目标对象的方法。
简单比喻:
就像你去办事大厅(MyBatis)办业务(执行SQL),办事员(核心对象)直接为你服务。但现在有了插件机制,相当于在你和办事员之间增加了几个"预处理窗口"(插件代理)。你必须先经过这些窗口,它们可以审核你的材料(修改SQL)、记录你的需求(记录日志),然后再转交给真正的办事员。
二、如何编写一个 MyBatis 插件
编写一个插件需要三个步骤:
-
实现
Interceptor接口。 -
使用
@Intercepts和@Signature注解指定要拦截的方法。 -
在
mybatis-config.xml中配置插件。
示例:编写一个简单的 SQL 执行时间统计插件
第一步:创建插件类,实现 Interceptor接口
java
package com.example.plugin;
// 1. 导入必要的包
import org.apache.ibatis.executor.Executor;
import org.apache.ibatis.mapping.MappedStatement;
import org.apache.ibatis.plugin.*;
import org.apache.ibatis.session.ResultHandler;
import org.apache.ibatis.session.RowBounds;
import java.util.Properties;
// 2. 使用 @Intercepts 注解声明要拦截的方法签名
@Intercepts({
@Signature(
type = Executor.class, // 要拦截的接口
method = "query", // 要拦截的方法名
args = {MappedStatement.class, Object.class, RowBounds.class, ResultHandler.class} // 方法参数类型(确保唯一性)
),
@Signature(
type = Executor.class,
method = "update",
args = {MappedStatement.class, Object.class}
)
})
public class SqlCostTimePlugin implements Interceptor {
/**
* 这是插件的核心方法,每次被拦截的方法被执行时,都会调用这个方法。
*
* @param invocation 包含被拦截的目标对象、方法、参数等信息。
* @return 原始方法执行后的返回值。
* @throws Throwable
*/
@Override
public Object intercept(Invocation invocation) throws Throwable {
// 1. 获取拦截方法的参数
MappedStatement mappedStatement = (MappedStatement) invocation.getArgs()[0];
String sqlId = mappedStatement.getId(); // 获取执行的SQL语句的ID(如:com.example.mapper.UserMapper.selectById)
long startTime = System.currentTimeMillis();
try {
// 2. 执行原始方法(即继续执行后续拦截器或真正的目标方法)
Object result = invocation.proceed();
return result;
} finally {
// 3. 计算耗时并打印日志(在finally中确保一定执行)
long endTime = System.currentTimeMillis();
long costTime = endTime - startTime;
System.out.println("SQL执行耗时:[" + sqlId + "] => " + costTime + "ms");
// 实际项目中应使用日志框架,如 SLF4J
// log.info("SQL执行耗时:[{}] => {}ms", sqlId, costTime);
}
}
/**
* 用于包装目标对象,MyBatis 在创建核心组件时会调用此方法。
* 通常直接使用 MyBatis 提供的 Plugin.wrap 方法即可。
*
* @param target 被拦截的目标对象(如 Executor 的实例)
* @return 包装后的代理对象
*/
@Override
public Object plugin(Object target) {
// 关键代码:使用 Plugin.wrap 方法创建代理对象
// 它会判断 target 的类型是否在 @Intercepts 注解中声明了,如果是,则创建代理;否则直接返回 target。
return Plugin.wrap(target, this);
}
/**
* 用于接收插件配置参数。在 mybatis-config.xml 中配置插件时,可以传入参数。
*
* @param properties 配置的参数
*/
@Override
public void setProperties(Properties properties) {
// 例如,可以配置一个阈值,只打印超过阈值的慢SQL
String slowSqlThreshold = properties.getProperty("slowSqlThreshold", "1000");
System.out.println("慢SQL阈值设置为:" + slowSqlThreshold + "ms");
// 可以将配置保存为成员变量,在intercept方法中使用
}
}第二步:在 MyBatis 核心配置文件中注册插件
在 mybatis-config.xml中配置你的插件。
XML
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<settings>
<!-- 其他设置 -->
</settings>
<!-- 配置插件 -->
<plugins>
<plugin interceptor="com.example.plugin.SqlCostTimePlugin">
<!-- 可选的插件参数,在 setProperties 方法中接收 -->
<property name="slowSqlThreshold" value="500"/>
</plugin>
</plugins>
<!-- 其他配置 -->
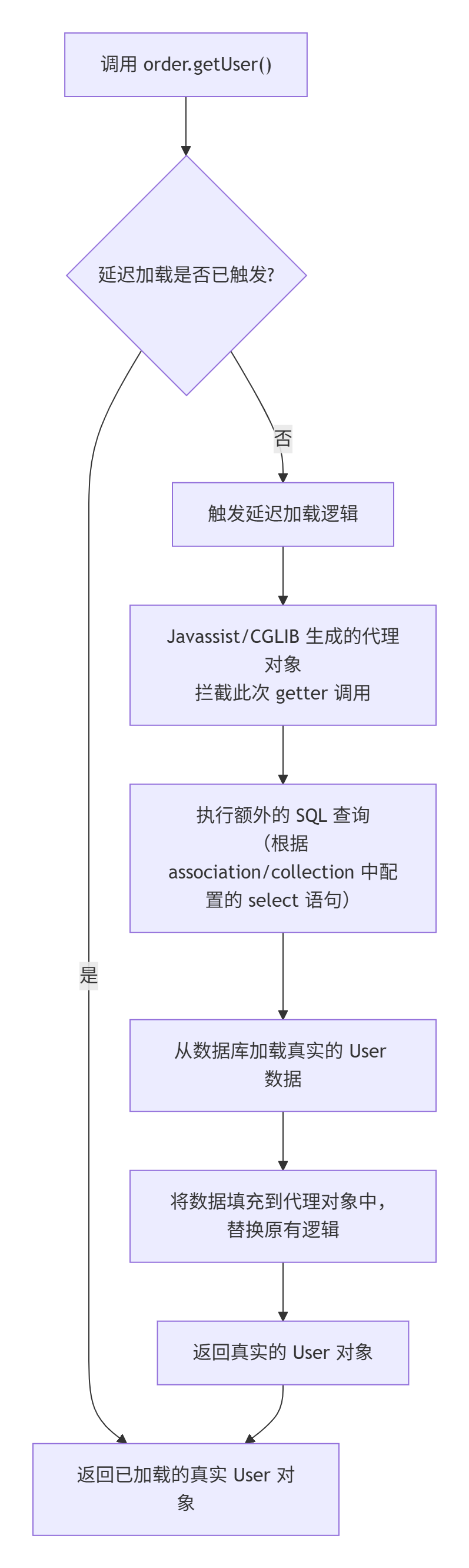
</configuration>Mybatis是否支持延迟加载?如果支持,它的实现原理是什么?
是的,MyBatis 支持延迟加载。
-
延迟加载 :也常被称为"懒加载"。它是一种按需加载数据的机制。对于关联对象(如一个
Order对象关联的User对象),只有在真正使用到这个关联对象时,MyBatis 才会执行第二条 SQL 语句去数据库查询它。 -
立即加载:与延迟加载相对。无论你是否使用关联对象,MyBatis 都会在加载主对象时,通过一条复杂的联表查询(JOIN)或额外的简单查询立即将关联数据加载出来。
延迟加载的优势:避免了不必要的数据库查询,从而提升性能。特别是在一个对象关联了大量数据,但本次业务逻辑并不需要用到所有这些数据时,优势非常明显。
实现原理
MyBatis 的延迟加载是通过动态代理技术实现的。其原理流程如下图所示:
Mybatis能执行一对一、一对多的关联查询吗?都有哪些实现方式,以及它们之间的区别?
是的,MyBatis 能够非常出色地执行一对一和一对多的关联查询。
它主要通过两种方式实现:
-
嵌套结果查询 :使用单条复杂的
JOINSQL 语句,一次性加载所有数据。 -
嵌套查询(N+1查询):执行一条主查询,然后为每个主对象执行额外的关联查询
| 特性 | 嵌套结果查询(JOIN) | 嵌套查询(分步查询) |
|---|---|---|
| 数据库交互次数 | 1次 | 1 + N 次(主查询1次,关联查询N次) |
| SQL 复杂度 | 复杂,需要写 JOIN |
简单,都是单表查询 |
| 性能倾向 | 大数据量关联时,单次复杂查询可能更高效 | N 很大时性能差(N+1问题),但可通过延迟加载和批量加载优化 |
| 数据冗余 | 有,JOIN可能导致重复数据传输 |
无,数据不冗余 |
| 延迟加载 | 不支持,一次性加载所有数据 | 支持 ,可配置 fetchType="lazy" |
| 代码可复用性 | 差,SQL 专为特定关联场景编写 | 好,简单查询(如 selectById)可被多处复用 |
| 适用场景 | 关联数据立即就需要,且关联数据量不大 | 关联数据可能不需要(延迟加载),或系统对数据库连接数敏感 |
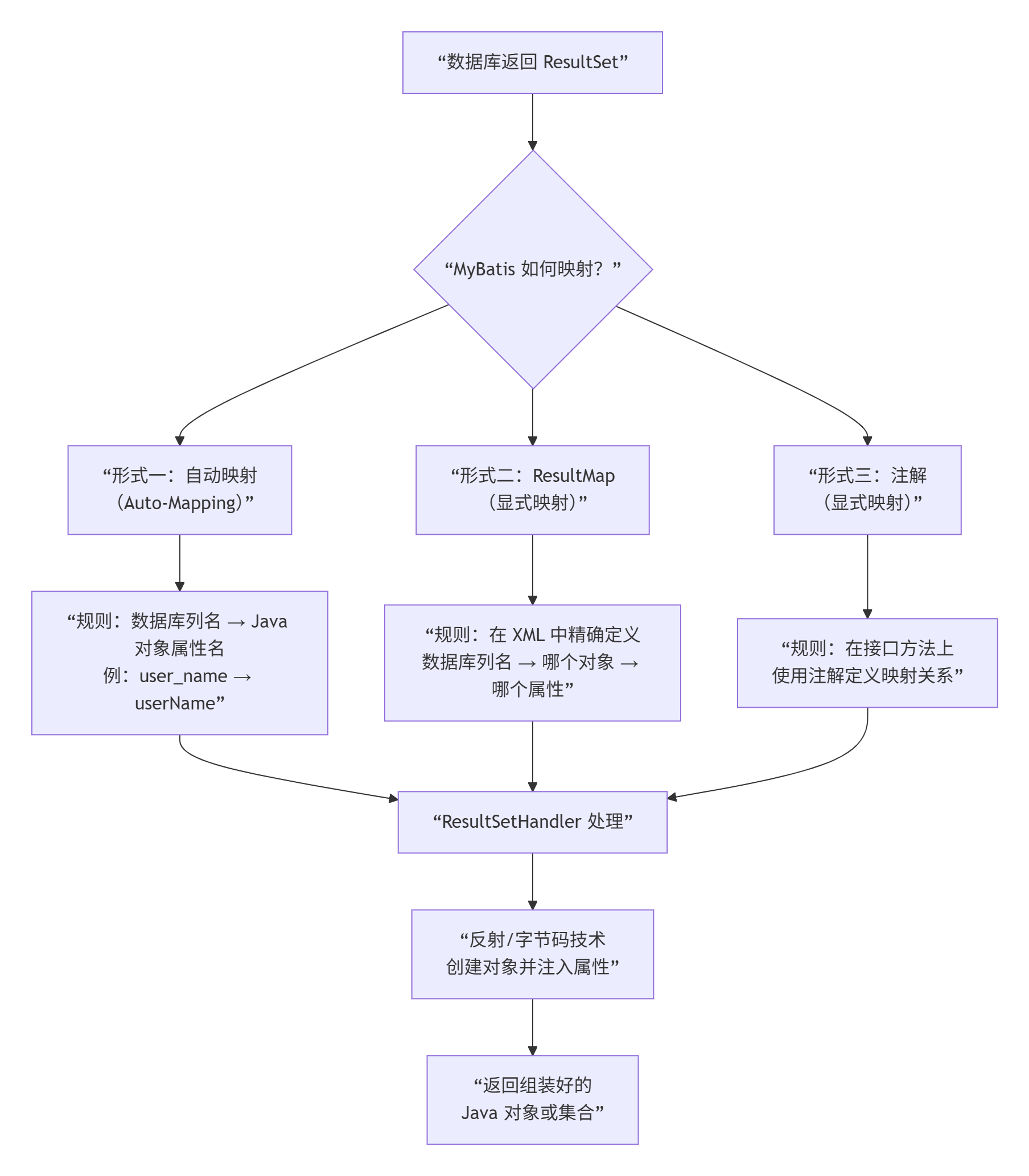
Mybatis是如何将sql执行结果封装为目标对象并返回的?都有哪些映射形式?
这是一个非常核心的问题,它触及了 MyBatis 的灵魂------ORM(对象关系映射) 。MyBatis 将 ResultSet转换为 Java 对象的过程既强大又灵活。
MyBatis 通过 ResultSetHandler 组件来完成结果映射。它会遍历查询结果集(ResultSet),并根据开发人员提供的映射规则 (自动映射、resultMap、注解等),通过反射 或字节码技术创建目标对象,并将数据库列的值设置到对象的属性中。
| 映射形式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 自动映射 | 配置简单,代码简洁 | 灵活性差,无法处理复杂映射 | 表字段与对象属性名高度一致,且无关联关系的简单场景 |
| ResultMap | 功能最强大,灵活性极高,可处理任意复杂的对象关系 | 需要编写额外的 XML 配置 | 绝大多数场景,尤其是有关联关系、继承关系或字段名差异大的情况 |
| 注解映射 | 避免了 XML 配置,代码集中 | 配置分散在代码中,复杂映射可读性差 | 简单的 CRUD 操作,且团队偏好注解而非 XML |
Mybatis映射文件中,如果A标签通过include引用了B标签的内容,请问,B标签能否定义在A标签的后面,还是说必须定义在A标签的前面?
B 标签可以定义在 A 标签的后面。
在 MyBatis 的映射文件(Mapper XML)中,<include>标签的引用是不要求 被引用的 <sql>片段在其之前定义的。MyBatis 在解析 XML 文件时,会先完整地读取并解析整个文档,构建一个内存中的文档对象模型(DOM),然后再处理其中的引用关系。
简单来说:MyBatis 不是像编译器一样"逐行"解析的,而是"整体"解析的。
MyBatis里面的动态Sql是怎么设定的?用什么语法?
MyBatis 的动态 SQL 功能是其最强大、最实用的特性之一。它允许你基于条件来动态地构建 SQL 语句,彻底摆脱了在 Java 代码中拼接 SQL 字符串的繁琐和危险。
核心思想
使用类似 JSTL 的 XML 标签来动态地生成 SQL,而不是在代码中拼接字符串。
| 标签 | 属性 | 作用描述 | 类比 Java 语法 |
|---|---|---|---|
<if> |
test |
条件判断 。如果 test表达式为 true,则将其中的 SQL 包含进来。 |
if (...) { ... } |
<choose>/<when>/<otherwise> |
test |
多路选择 。从多个条件中选择一个,类似 switch-case-default。 |
switch-case-default |
<where> |
无 | 智能 WHERE 子句 。1. 只有子元素有内容时才插入 WHERE。2. 自动去除子句开头的 AND或 OR。 |
智能处理 WHERE关键字 |
<set> |
无 | 智能 SET 子句。用于 UPDATE 语句,动态设置列。自动去除结尾的逗号。 | 智能处理 SET关键字和逗号 |
<trim> |
prefix, prefixOverrides, suffix, suffixOverrides |
万能修剪标签 。可以自定义字符串的添加和去除,实现 where或 set的功能。 |
更底层的字符串处理 |
<foreach> |
collection, item, index, open, close, separator |
循环遍历集合 。常用于 IN语句和批量操作。 |
for (... : ...) { ... } |
<bind> |
name, value |
创建一个变量并将其绑定到上下文 。可用于拼接 LIKE查询或复杂的表达式。 |
Mybatis都有哪些Executor执行器?它们之间的区别是什么?
MyBatis 主要有三种基本的执行器类型,它们通过模板方法模式 和装饰器模式组合,提供了不同级别的缓存和功能。
| 执行器类型 | 中文名 | 核心特征 | 适用场景 |
|---|---|---|---|
SimpleExecutor |
简单执行器 | 默认执行器 。每次执行完语句就关闭 Statement对象。 |
常规场景,无特殊要求。 |
ReuseExecutor |
复用执行器 | 复用 预处理语句 (PreparedStatement)对象。 |
存在大量相同SQL重复执行的场景,可提升性能。 |
BatchExecutor |
批处理执行器 | 将多个更新操作批量执行,显著提升性能。 | 需要进行大量 INSERT/UPDATE/DELETE操作的场景。 |
CachingExecutor |
缓存执行器 | 装饰器 ,为上述任何执行器添加二级缓存功能。 | 需要跨 SqlSession共享缓存数据的场景。 |
| 特性 | SimpleExecutor | ReuseExecutor | BatchExecutor | CachingExecutor |
|---|---|---|---|---|
| 核心功能 | 基本执行 | 复用 PreparedStatement |
批量执行 | 装饰器,提供二级缓存 |
| 默认启用 | 是 | 否 | 否 | 否(需配置 <cache/>) |
| 性能优势 | - | 高重复SQL场景 | 大批量更新场景 | 高重复查询场景 |
| 内存占用 | 低 | 中(维护Statement缓存) | 中(维护批处理缓存) | 取决于二级缓存大小 |
| 使用复杂度 | 简单 | 简单 | 复杂(需手动刷新) | 简单(透明) |
为什么说Mybatis是半自动ORM映射工具?它与全自动的区别在哪里?
-
全自动 ORM :开发者主要与对象 打交道,框架自动生成 SQL,并管理对象与数据库的同步。开发者让渡了 SQL 的控制权,换取极高的开发效率。
-
半自动 ORM(MyBatis) :开发者需要亲自编写和管理 SQL ,MyBatis 负责将结果集映射到对象,以及将对象参数映射到 SQL。开发者保留了 SQL 的绝对控制权,用一定的开发效率换取极致的性能和灵活性。
| 特性 | 全自动 ORM(JPA/Hibernate) | 半自动 ORM(MyBatis) |
|---|---|---|
| SQL 生成 | 框架自动生成,开发者不关心。 | 开发者手动编写,对 SQL 有完全控制权。 |
| 学习曲线 | 陡峭。需要理解 Session/Persistence Context、延迟加载、脏数据检查等复杂概念。 | 平缓。核心是 SQL 和结果映射,对熟悉 SQL 的开发者非常友好。 |
| 性能控制 | 优化需理解框架生成的 SQL,可能产生性能问题(如 N+1 查询),调优相对复杂。 | 性能由开发者掌控。可以直接编写和优化最高效的 SQL,避免不必要的查询。 |
| 灵活性 | 差。处理复杂查询、存储过程、数据库特定函数时,可能非常笨拙或需要原生 SQL。 | 极强。可以编写任意复杂度的 SQL,轻松利用所有数据库高级特性。 |
| 数据库移植性 | 好。使用 JPQL 或 API 操作,框架负责适配不同数据库的方言。 | 差。手写 SQL 与特定数据库耦合,更换数据库可能需要重写大量 SQL。 |
| 开发效率 | 简单 CRUD 效率极高。 | 简单 CRUD 有样板代码,但复杂操作效率可能更高(因直接优化)。 |
| 对象管理 | 强。有完整的持久化上下文(如一级缓存),能自动管理对象状态、延迟加载、级联操作。 | 弱。本质是 SQL 映射工具,对象生命周期简单,无脏检查,延迟加载需配置。 |
简单介绍下你对mybatis的理解?
MyBatis 是一个优秀的"半自动化"的持久层框架,它通过 XML 或注解配置 SQL,并自动将结果集映射为 Java 对象,在 SQL 的灵活性和开发效率之间取得了完美平衡。
SSM优缺点、使用场景?
SSM 是三个框架的集成,用于构建 Java Web 应用程序:
-
S pring:轻量级的控制反转(IoC)和面向切面(AOP)的容器框架。它是整个应用的基石,负责整合和管理所有组件。
-
S pring MVC:基于 MVC 设计模式的 Web 框架。用于替代传统的 Servlet/JSP,处理 HTTP 请求和响应。
-
M yBatis:半自动化的持久层框架。用于替代传统的 JDBC,简化数据库操作。
| 维度 | 优点 | 缺点 |
|---|---|---|
| 架构与设计 | 1. 分层清晰,解耦彻底 • 严格遵循 MVC 模式,各层职责单一,代码可维护性高。 • 接口导向编程,易于进行单元测试(如利用 Mock 测试)。 | 1. 配置非常繁琐 • 需要大量 XML/注解配置(Spring、Spring MVC、MyBatis 本身及整合配置),俗称"配置地狱"。 • 配置文件分散,后期维护成本高。 |
| 灵活性与控制 | 2. 灵活性强,掌控力高 • MyBatis 是"半自动化"ORM ,开发者可编写和优化任意复杂度的 SQL,适合高性能要求场景。 • 对技术的每一层都有精细的控制能力。 | 2. 项目整合与依赖管理复杂 • 需要开发者手动解决三个框架以及它们依赖的 JAR 包的版本兼容性问题。 • 容易产生 JAR 冲突。 |
| 性能 | 3. 性能优异 • Spring 本身是轻量级容器,开销小。 • MyBatis 直接使用 SQL,避免了 Hibernate 等全自动 ORM 框架的复杂 SQL 生成和性能开销。 | 3. 重复代码较多 • 需要为每个实体类编写对应的 Mapper 接口和 XML 文件,即使进行简单的 CRUD 操作。 |
| 生态与集成 | 4. 生态系统强大 • Spring 是整个 Java 生态的"基石",可轻松集成缓存、安全、任务调度等众多第三方组件。 | 4. 部署相对复杂 • 需要将项目打包成 WAR 文件,部署到外部的 Tomcat、Jetty 等 Servlet 容器中。 |
| 学习与社区 | 5. 学习资料丰富,社区活跃 • 作为经典组合,拥有海量的学习教程和解决方案,遇到问题容易找到答案。 | 5. 入门门槛较高 • 需要同时理解三个框架的概念、配置和整合方式,对新手不友好。 |
SSM 与现代框架(Spring Boot)的对比
要理解 SSM 的使用场景,必须将其与当前的主流选择 Spring Boot 进行对比。
| 特性 | SSM 框架 | Spring Boot |
|---|---|---|
| 核心理念 | 高度可配置,提供最大灵活性 | 约定优于配置,追求快速开发 |
| 配置方式 | 大量手动配置(XML/注解) | 自动配置 ,零 XML,通过 application.properties修改 |
| 项目搭建 | 复杂,需手动整合三个框架 | 极简,使用 Starter 依赖一键搭建 |
| 内嵌服务器 | 无,需依赖外部 Tomcat | 有,可直接打包成可执行 JAR 文件运行 |
| 部署 | 打包成 WAR,部署到外部容器 | 打包成可执行 JAR,java -jar直接运行 |
| 监控 | 需额外集成(如 Spring Actuator) | 自带强大的监控功能(Actuator) |
| 适用场景 | 需要深度定制、遗留系统、学习原理 | 现代应用开发、微服务、快速原型 |
使用场景
| 推荐度 | 使用场景 | 说明 |
|---|---|---|
| ⭐⭐⭐ | 学习和教学目的 | 最佳学习材料。通过手动整合 SSM,可以深入理解 Spring 容器的原理、MVC 工作流程、ORM 映射机制,为理解 Spring Boot 的自动化魔法打下坚实基础。 |
| ⭐⭐⭐ | 维护已有的遗留系统 | 很多现存的老项目基于 SSM 构建,需要开发者具备 SSM 技能进行维护、升级和二次开发。 |
| ⭐⭐ | 对技术栈有高度定制化需求的项目 | 当项目有非常特殊的架构需求,需要精细控制每一层,而 Spring Boot 的"约定"无法满足时。 |
| ⭐ | 全新项目开发 | 不推荐 。对于绝大多数新项目,Spring Boot + MyBatis是更优选择,它在保留 SSM 优点的同时,极大简化了配置和部署。 |
怎么样把数据放入Session里面?
将数据放入 Session 的本质是:通过 HttpServletRequest对象获取到当前请求的 HttpSession对象,然后像操作 Map一样,使用 setAttribute(String name, Object value)方法存储数据。
方法一:在 Controller 中直接操作 HttpSession(最直接)
这是最基础、最直观的方式。在 Controller 方法的参数中直接声明 HttpSession,Spring 会自动将其注入。
1 存储数据到Session
java
@Controller
public class UserController {
@PostMapping("/login")
public String login(@RequestParam String username,
HttpSession session,
Model model) {
// 1. 验证用户名和密码(这里省略了Service调用)
// ...
// 2. 验证通过后,将用户信息存入 Session
// setAttribute("键", 值)
session.setAttribute("currentUser", username);
session.setAttribute("loginTime", new Date());
session.setAttribute("userRole", "ADMIN");
// 也可以存入一个完整的对象
User user = new User(username, "Alice");
session.setAttribute("loggedInUser", user);
model.addAttribute("message", "登录成功!");
return "dashboard";
}
}2 从 Session 中读取数据
在同一个会话的后续请求中,你可以在任何 Controller 方法中读取 Session 中的数据。
java
@GetMapping("/profile")
public String getProfile(HttpSession session, Model model) {
// 使用 getAttribute("键") 读取数据
String currentUser = (String) session.getAttribute("currentUser");
User loggedInUser = (User) session.getAttribute("loggedInUser");
if (currentUser != null) {
model.addAttribute("username", currentUser);
model.addAttribute("user", loggedInUser);
return "profile";
} else {
model.addAttribute("error", "请先登录!");
return "login";
}
}- 移除 Session 中的数据(退出登录)
java
@GetMapping("/logout")
public String logout(HttpSession session) {
// 1. 清除特定的 Session 属性
session.removeAttribute("currentUser");
session.removeAttribute("loggedInUser");
// 2. 或者直接让整个 Session 失效(更彻底的退出)
session.invalidate();
return "redirect:/login?message=logout_success";
}方法二:使用 @SessionAttributes注解(Controller 级别)
这个注解是 Spring MVC 特有的 ,它用于在 同一个 Controller 内部的不同方法之间共享数据,并将数据自动从 Model 提升到 Session 中。
重要 :@SessionAttributes的用途相对特定,通常用于在多步骤的表单向导中暂存数据。
java
@Controller
@RequestMapping("/order")
@SessionAttributes("orderCart") // 声明名为 "orderCart" 的属性要存到 Session
public class OrderController {
// 第一步:添加商品到购物车
@PostMapping("/addToCart")
public String addToCart(Product product, Model model) {
// 从 Model 中获取购物车,如果 Session 中没有,则新建一个
ShoppingCart cart = (ShoppingCart) model.getAttribute("orderCart");
if (cart == null) {
cart = new ShoppingCart();
}
cart.addItem(product);
// 将购物车对象存入 Model。因为类上有 @SessionAttributes("orderCart"),
// Spring 会自动将其存入 Session
model.addAttribute("orderCart", cart);
return "cartPage";
}
// 第二步:结算页面,可以直接从 Session 中获取购物车
@GetMapping("/checkout")
public String checkout(Model model) {
// Spring 会自动从 Session 中取出 "orderCart" 并放入 Model
// 所以这里可以直接使用
ShoppingCart cart = (ShoppingCart) model.getAttribute("orderCart");
if (cart == null || cart.getItems().isEmpty()) {
return "redirect:/products";
}
model.addAttribute("cart", cart);
return "checkout";
}
// 清除 @SessionAttributes 声明的属性
@GetMapping("/complete")
public String completeOrder(SessionStatus status) {
// 调用 setComplete() 来清除通过 @SessionAttributes 存储的属性
status.setComplete();
return "orderComplete";
}
}注意 :@SessionAttributes的作用域仅限于当前 Controller。其他 Controller 无法通过它来共享数据
方法三:使用 @SessionAttribute注解(方法参数级别)
这个注解用于方便地从 Session 中获取已经存在的属性,并将其作为方法参数注入。它不用于存储,只用于读取。
java
@Controller
public class DashboardController {
// 使用 @SessionAttribute 将 Session 中的属性直接注入到方法参数中
@GetMapping("/dashboard")
public String getDashboard(@SessionAttribute("currentUser") String username,
@SessionAttribute("userRole") String role,
Model model) {
model.addAttribute("welcomeMessage", "你好, " + username + "! 你的角色是:" + role);
return "dashboard";
}
// 如果 Session 中可能没有该属性,可以设置 required = false
@GetMapping("/settings")
public String getSettings(@SessionAttribute(name = "userSettings", required = false) Settings settings) {
if (settings == null) {
settings = new Settings(); // 使用默认设置
}
// ... 处理设置
return "settings";
}
}| 方法 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
直接操作 HttpSession |
最常用、最通用。用户登录状态、全局用户信息等。 | 灵活直观,功能最全。 | 需要在每个方法参数中声明。 |
@SessionAttributes |
同一 Controller 内的多步骤流程,如向导式表单。 | 自动在 Model 和 Session 间同步数据。 | 作用域仅限于声明它的 Controller。 |
@SessionAttribute |
方便地读取已知的 Session 属性。 | 简化参数注入,代码简洁。 | 只能读取,不能存储。 |
MyBatis(IBatis)的好处是什么?
| 优势 | 说明 | 带来的价值 |
|---|---|---|
| 1. SQL 控制力与灵活性 | 开发者手写所有 SQL,可应对任意复杂查询、存储过程、数据库高级特性。 | 极致性能优化,DBA 友好,能处理复杂业务逻辑。 |
| 2. 学习曲线平缓 | 对熟悉 SQL 和 JDBC 的开发者非常友好,核心概念简单。 | 快速上手,降低团队学习成本。 |
| 3. 与代码解耦 | SQL 集中在 XML 或注解中,与 Java 代码分离。 | 易于维护,SQL 可调优而不影响代码逻辑。 |
| 4. 强大的动态 SQL | 提供智能标签动态生成 SQL,避免在代码中拼接字符串。 | 代码简洁 ,有效防止 SQL 注入。 |
| 5. 易于测试 | 数据访问层是接口,易于 Mock,可进行真正的单元测试。 | 提升软件质量,便于实施 TDD。 |
| 6. 轻量级与低侵入性 | 框架依赖少,你的 POJO 是纯净的,不依赖任何框架类。 | 系统启动快,代码干净,迁移成本低。 |
什么是bean的自动装配?
Bean 的自动装配(Auto-wiring)是 Spring 容器提供的一种依赖注入(Dependency Injection, DI)方式。它允许 Spring 自动识别和满足 Bean 之间的协作关系(即依赖),而无需开发者在 XML 或 Java 配置中显式地、逐个地指定这些依赖关系。
简单来说:你只需要告诉 Spring "某个 Bean 需要被注入",Spring 就会自动在容器中找到匹配的 Bean 并"装配"进去,你无需手动写 new或者通过配置明确指定注入哪个具体的 Bean。
什么是基于Java的Spring注解配置? 给一些注解的例子?
基于 Java 的 Spring 注解配置,指的是使用 Java 类和注解来定义 Spring 容器中的 Bean 以及它们之间的依赖关系,从而完全取代了传统的 XML 配置文件。
|----------------------|--------------------------------------------------------------------|--------------------------------|
| @Component | 通用注解,用于标记任何由 Spring 管理的组件。 | <bean id="..." class="..."/> |
| @Service | 标记服务层(业务逻辑层)的组件。 | 同上 |
| @Repository | 标记数据访问层(DAO)的组件。此外,它会将平台特定的异常(如 SQLException)转换为 Spring 的统一异常。 | 同上 |
| @Controller | 标记Web 控制层(MVC)的组件。 | 同上 |
| @Configuration | 标记一个类为配置类,其内部会包含创建 Bean 的定义。 | <beans> ... </beans> |
使用Spring通过什么方式访问Hibernate?
方式一:使用 HibernateTemplate(已过时,仅作了解)
这是 Spring 早期为了简化 Hibernate 的数据访问操作而提供的模板类。它封装了常见的样板代码(如会话管理、异常转换等),但现在已不推荐使用,因为更纯粹的方式(方式二)已经足够好。
工作原理 :HibernateTemplate在内部负责获取 Hibernate Session、处理事务、转换 Hibernate 异常为 Spring 的 DAO 异常等。
方式二:使用 SessionFactory+ 声明式事务(现代标准方式)
这是当前最主流、最推荐的方式。它的核心思想是:
-
数据访问 :在 DAO/Repository 中直接使用 Hibernate 的原生
SessionAPI。 -
事务管理 :利用 Spring 强大的声明式事务管理 (
@Transactional)来管理事务的边界。
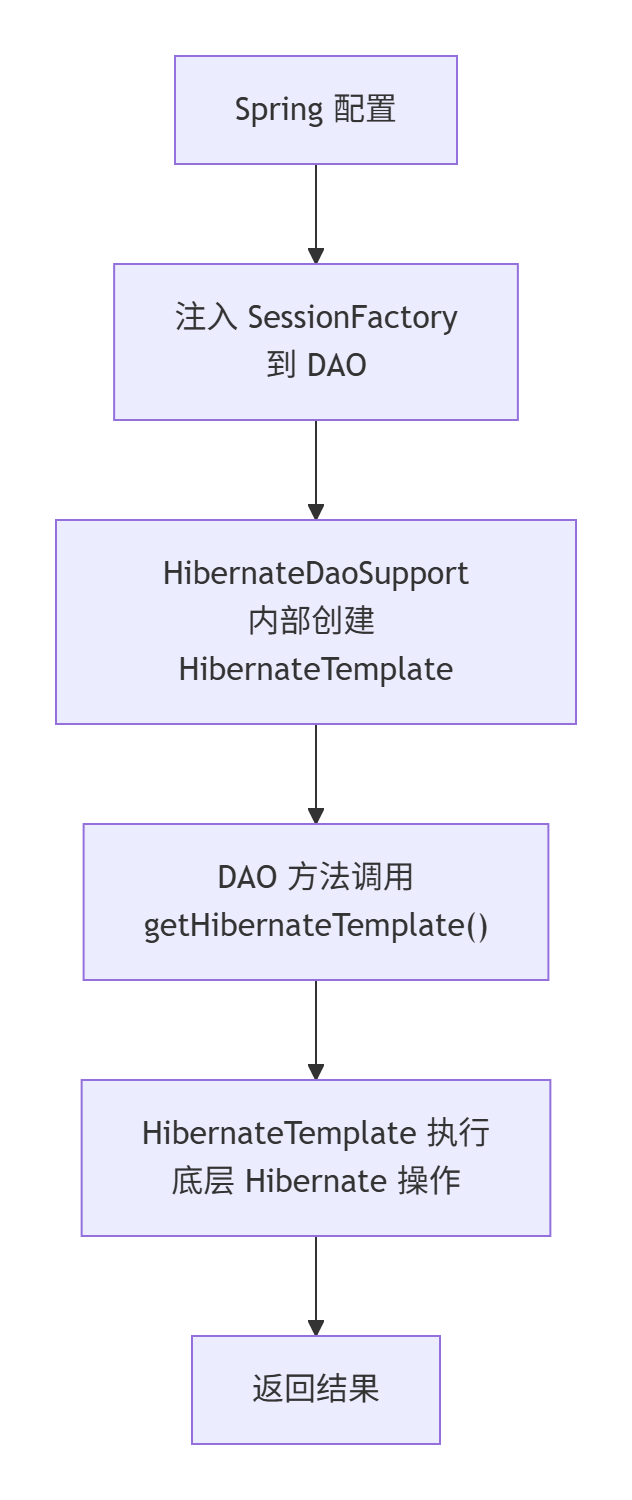
核心结论:HibernateDaoSupport是一个便利类,旨在简化 Hibernate DAO 的实现。它为 DAO 类提供了 HibernateTemplate的便捷访问,从而避免了直接管理 SessionFactory和模板的样板代码。
然而,重要提示 :这种方式在现代 Spring 开发中已被弃用(Deprecated) 。Spring 团队现在推荐更直接的方式(使用 @Repository+ @Autowired SessionFactory+ @Transactional)。但理解它对于维护遗留代码和了解 Spring 演进非常有帮助。
一、HibernateDaoSupport的工作原理
HibernateDaoSupport是一个抽象类,它充当了 DAO 类和 Spring-Hibernate 集成基础设施之间的桥梁。它的核心作用是注入和管理 HibernateTemplate。
它的工作方式如下:
-
你让你的 DAO 类继承
HibernateDaoSupport。 -
通过 Setter 方法(通常在 XML 中配置)将
SessionFactory注入到HibernateDaoSupport。 -
HibernateDaoSupport内部利用注入的SessionFactory自动创建一个HibernateTemplate实例。 -
你的 DAO 方法可以通过
getHibernateTemplate()方法轻松获取并使用这个模板。
下图直观地展示了基于 HibernateDaoSupport的集成架构中,各个组件间的协作关系:
在Spring AOP 中,连接点和切入点的区别是什么?
核心结论(一句话概括)
-
连接点(Join Point) :是程序执行过程中一个特定的点 (如方法调用、异常抛出),它是 AOP 理论上的**"可被增强的所有机会"**。
-
切入点(Pointcut) :是一个表达式或规则 ,它通过匹配连接点的特征(如方法签名)来筛选出我们真正想要增强的特定连接点。
AOP作用是什么,底层如何实现在哪些地方会用到,分别简述切面,切入点和通知?
一、AOP 的作用是什么?(解决什么问题?)
AOP 的核心作用是:将那些分散在应用程序多个模块中的"横切关注点"分离出来,实现集中管理和复用。
什么是"横切关注点"?
它们是与核心业务逻辑无关,但又必须存在的通用功能。例如:
-
日志记录:记录方法的入参、出参、执行时间。
-
事务管理:保证数据库操作的一致性(原子性)。
-
安全控制:检查用户权限后才能执行某些方法。
-
性能监控:统计方法的执行耗时。
-
异常处理:统一捕获和处理异常。
AOP 的底层实现原理
Spring AOP 主要通过动态代理技术来实现。根据目标对象是否实现接口,采用不同的代理策略:
| 代理方式 | 条件 | 实现机制 |
|---|---|---|
| JDK 动态代理(默认) | 目标类实现了至少一个接口 | 通过 java.lang.reflect.Proxy类创建接口的代理实例。 |
| CGLIB 动态代理 | 目标类没有实现任何接口 | 通过继承目标类,生成其子类的字节码作为代理。 |
AOP 的核心概念:切面、切入点、通知
| OP 概念 | 医院比喻 | 解释与代码示例 |
|---|---|---|
| 切面(Aspect) | 一个完整的检查项目,如"心电图检查套餐"。它包含了检查流程、检查部位和检查动作。 | 一个横切关注点的模块化实现。它是一个普通的 Java 类,用 @Aspect注解标记。 java<br>@Aspect<br>@Component<br>public class LoggingAspect { // 这是一个"日志记录"切面<br> // ... 内部定义切入点和通知<br>}<br> |
| 切入点(Pointcut) | 检查规则,如"为所有年龄超过40岁的病人进行此项检查"。它定义了在何处(哪些连接点)应用通知。 | 一个匹配连接点(Join Point,如方法执行)的谓词(表达式)。 java<br>@Pointcut("execution(* com.example.service.*.*(..))")<br>public void serviceLayer() {} // 规则:匹配service包下所有方法<br> |
| 通知(Advice) | 具体的检查动作,如"测量血压"。它定义了切面在何时、做什么。 | 在特定切入点"触发"时执行的代码。 java<br>@Before("serviceLayer()") // 在匹配的方法执行"前"做某事<br>public void logStart(JoinPoint jp) {<br> System.out.println("开始执行: " + jp.getSignature());<br>}<br> |
通知的类型(5种):
-
@Before:在目标方法执行之前执行。 -
@AfterReturning:在目标方法成功执行之后执行。 -
@AfterThrowing:在目标方法抛出异常后执行。 -
@After:在目标方法执行之后 执行(无论成功还是异常,类似于finally)。 -
@Around:最强大 的通知,它包围了目标方法,可以在方法调用前后执行自定义行为,并控制是否执行目标方法以及返回值。它接收一个ProceedingJoinPoint参数。
AOP 的实际应用场景(在哪里会用到?)
| 场景 | 实现方式 | 好处 |
|---|---|---|
| 声明式事务管理 | 使用 @Transactional注解。这是 Spring AOP 最经典、最广泛的应用。 |
只需一个注解,无需手动编写 beginTransaction()和 commit(),代码简洁,事务控制统一。 |
| 统一日志记录 | 使用 @Around或 @Before+ @After记录方法入口、出口、参数和耗时。 |
业务代码零侵入,日志格式统一,便于监控和调试。 |
| 权限校验与安全控制 | 使用 @Before,在方法执行前检查用户权限或角色。 |
将安全逻辑与业务逻辑解耦,易于管理和扩展。 |
| 全局异常处理 | 使用 @AfterThrowing拦截异常,并将其转换为统一的错误响应格式。 |
避免在 Controller 中重复写 try-catch,提供一致的 API 错误体验。 |
| 性能监控 | 使用 @Around统计方法执行时间,并上报给监控系统。 |
非侵入式地收集性能数据,不影响业务代码。 |
| 数据缓存 | 使用 @Around,在方法执行前检查缓存,执行后更新缓存。 |
减少数据库访问,提升性能,缓存逻辑集中管理。 |
Spring中AutoWired和,Resource之间区别是什么?
-
@Autowired:是 Spring 框架 提供的注解。它默认根据**类型(byType)**进行自动装配。 -
@Resource:是 Java 官方 提供的注解(来自javax.annotation包)。它默认根据**名称(byName)**进行自动装配。
| 特性 | @Autowired(Spring) |
@Resource(JSR-250) |
|---|---|---|
| 来源/提供商 | Spring 框架 | Java 标准规范(JSR-250),是 Java EE 的一部分 |
| 包名 | org.springframework.beans.factory.annotation.Autowired |
javax.annotation.Resource |
| 默认装配方式 | byType(按类型匹配) | byName(按名称匹配) |
| 解决歧义性 | 结合 @Qualifier("name")注解 |
使用 name属性(如 @Resource(name="myBean")) |
是否支持 required |
是 (@Autowired(required=false)) |
否 |
| 是否支持构造函数/Setter注入 | 是 | 否(仅能用于字段和 Setter 方法) |
@Autowired有一个 required属性,可以设置为 false。这意味着如果找不到匹配的 Bean,Spring 会跳过注入,而不是报错(字段会为 null)。
java
@Autowired(required = false)
private MessageService optionalService; // 如果找不到Bean,则保持为null@Resource只能用在:
-
字段上
-
Setter 方法上(但 Setter 方法注入不常用)
| 场景 | 推荐注解 | 理由 |
|---|---|---|
| 强耦合于 Spring 框架的项目 | @Autowired |
是 Spring 的"原生公民",与 Spring 生态(如 @Qualifier)集成最顺畅。 |
| 需要构造器注入时 | @Autowired |
@Resource不支持构造器注入。 |
| 希望代码减少对 Spring 的依赖,保持标准性 | @Resource |
基于 Java 标准(JSR-250),如需将应用迁移到其他遵循规范的框架,代码更具可移植性。 |
| 按名称注入的意图非常明确时 | @Resource |
其默认的 byName 行为非常直观,@Resource(name="myBean")意图清晰。 |
需要可选依赖(required=false)时 |
@Autowired |
@Resource不支持。 |