在计算机视觉领域,图像分割是连接图像识别与图像理解的关键技术,它将图像从 "整体识别" 推向 "像素级分析",为众多行业应用提供了精准的技术支撑。本文将基于深度学习视角,系统梳理图像分割的基础概念、应用场景、技术层级、核心数据集、评估指标及典型网络结构。
一、什么是图像分割?
图像分割本质是像素级的细粒度分类任务------ 通过算法预测目标物体的轮廓,将图像中不同语义的像素划分到对应类别中。与图像分类(仅判断图像整体类别)、目标检测(仅定位目标边界框)不同,图像分割直接对每个像素的归属做出判断,实现 "哪里是什么" 的精准分析。
例如,在一张包含行人与车辆的街景图中,图像分割会将 "行人像素""车辆像素""路面像素""天空像素" 分别标注为不同类别,输出一张与原图尺寸一致的 "语义掩膜",直观呈现各目标的像素级分布。
二、图像分割的 "前景与背景" 定义
在图像分割任务中,通常将场景中的元素分为两类,明确任务的分析范围:
- 物体(Things) :指可数的前景目标,具有明确的个体边界,如行人、车辆、动物、家具等。这类目标的核心需求是 "区分个体"(如区分两个不同的行人)。
- 事物(Stuff) :指不可数的背景区域,通常是大面积连续分布的场景元素,如天空、草地、路面、墙壁等。这类目标的核心需求是 "区分类别"(如区分路面与草地)。
三、图像分割的三层技术境界
根据任务复杂度和输出精度,图像分割可分为三个层级:
1. 语义分割
- 核心目标 :将图像中每个像素分配到一个语义类别(如 "行人""车辆""天空"),不区分同一类别的不同个体。
- 关键特点:每个像素仅属于一个类别,输出 "类别掩膜"。例如,街景图中所有行人像素标注为 "行人" 类,不区分行人 A 与行人 B。
- 适用场景:仅需知道 "区域类别" 的场景,如遥感图像土地分类、医学影像器官分割。
2. 实例分割
- 核心目标 :仅针对前景目标(Things),同时输出 "类别属性" 和 "个体 ID",即区分同一类别的不同个体。
- 关键特点 :
- 不关注背景区域(Stuff)的分割;
- 同一类别的不同个体有独立的掩膜(如行人 A 的掩膜、行人 B 的掩膜)。
- 适用场景:需要区分个体的前景分析场景,如自动驾驶中行人 / 车辆计数、工业质检中缺陷个体定位。
3. 全景分割
- 核心目标 :融合语义分割与实例分割的优势,对图像中所有像素(包括前景 Things 和背景 Stuff)进行分析 ------ 背景像素分配 "语义类别",前景像素同时分配 "语义类别" 和 "个体 ID"。
- 关键特点:实现 "全场景覆盖 + 个体区分",是最全面的图像分割任务。例如,街景图中 "天空"(Stuff,仅类别)、"行人 A"(Things,类别 + ID)、"车辆 B"(Things,类别 + ID)的像素均被精准标注。
- 适用场景:需要完整场景理解的任务,如机器人导航、智慧城市监控。
四、图像分割的核心数据集
高质量数据集是图像分割算法训练与评估的基础,以下是三大主流数据集的关键信息:
- VOC 数据集:入门级首选,类别少、数据量适中,适合算法快速验证;
- Cityscapes 数据集:街景领域专用,场景针对性强,适合自动驾驶相关算法训练;
- COCO 数据集:场景复杂度高、类别多,更贴近真实世界应用,适合高性能算法研发。
五、语义分割的评估指标
评估指标是衡量分割算法性能的核心标准,常用指标包括以下五类:
1. 逐像素精度
每个类别被正确分类像素的比例:
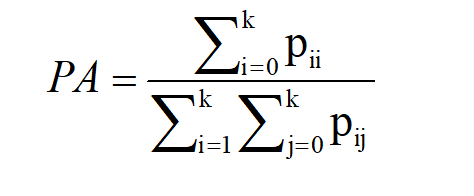
- 特点:计算简单,但易受 "背景像素占比高" 的影响(如天空占比大时,PA 可能偏高但前景分割精度低)。
2. 平均像素精度( MPA)
- 定义:每个类别被正确分类的像素数占该类别总像素数的比例,再求所有类别的平均值。
- 特点:避免了 PA 对 "大类" 的偏向性,更公平地反映每个类别的分割精度。
3. 交并比(IoU)
- 特点:分割任务的 "黄金指标",直接反映预测区域与真实区域的重叠程度,IoU 越高,分割越精准。
4. 平均交并比(Mean IoU, mIoU)
- 定义:所有类别的 IoU 值的平均值,是语义分割任务中最常用的综合指标。
- 特点:综合考虑所有类别的分割性能,尤其适合类别分布不均衡的场景。
5. 加权交并比(Frequency Weighted IoU, FWIoU)
- 定义:根据每个类别在图像中出现的频率(像素占比)为其 IoU 分配权重,再计算加权平均值。
- 特点:更注重 "高频类别" 的分割精度,适合对重要类别(如医学影像中的肿瘤)有更高要求的场景。
六、图像分割网络的核心模块与转置卷积
深度学习图像分割网络的核心逻辑是 "先下采样提取特征,再上采样恢复尺寸",对应的两个关键模块及核心技术如下:
1. 网络核心模块
- 卷积模块(编码器,Encoder):通过卷积层 + 池化层对图像进行下采样,逐步缩小特征图尺寸、扩大感受野,提取图像的高层语义特征。
- 反卷积模块(解码器,Decoder):通过反卷积(转置卷积)或上采样操作,逐步扩大特征图尺寸,最终恢复到与原图一致的尺寸,输出像素级的分割结果。
2. 转置卷积(反卷积):上采样的核心技术
转置卷积是实现 "从小特征图恢复到大尺寸" 的关键操作,其本质是卷积的逆过程(数学上为 "转置关系")。
(1)卷积与转置卷积的对比
| 操作 | 输入尺寸 | 输出尺寸 | 核心作用 | 示例(卷积核 3×3) |
|---|---|---|---|---|
| 卷积 | 4×4 | 2×2 | 下采样,提取特征 | 4×4 输入经 3×3 卷积核得到 2×2 输出 |
| 转置卷积 | 2×2 | 4×4 | 上采样,恢复尺寸 | 2×2 输入经 3×3 转置卷积核得到 4×4 输出 |
(2)转置卷积的实现逻辑
转置卷积通过 "稀疏矩阵乘法" 实现:
- 将输入特征图(如 2×2)展平为向量;
- 构造与 "原卷积矩阵" 转置对应的稀疏矩阵;
- 两者相乘得到展平的输出向量,再 reshape 为目标尺寸(如 4×4)。
通过转置卷积,网络可在扩大特征图尺寸的同时,保留高层语义特征,确保最终分割结果的精度。
七、典型图像分割网络结构
主流图像分割网络均遵循 "编码器 - 解码器" 架构,以 "卷积模块下采样 + 反卷积模块上采样" 为核心流程,典型结构的流程如下:
- 编码器(卷积网络):输入 224×224 图像 → 经多轮 "卷积 + Max Pooling" 下采样 → 特征图尺寸逐步缩小(224×224 → 112×112 → 56×56 → 28×28),同时提取高层特征。
- 解码器(反卷积网络):接收编码器输出的 28×28 特征图 → 经多轮 "反卷积 + Unpooling" 上采样 → 特征图尺寸逐步恢复(28×28 → 56×56 → 112×112 → 224×224) → 输出与原图尺寸一致的分割掩膜。
常见的分割网络(如 FCN、U-Net、Mask R-CNN)均基于此架构优化:
- FCN(全卷积网络):首个端到端的语义分割网络,用 "反卷积" 替代传统 CNN 的全连接层,实现像素级输出;
- U-Net:在编码器与解码器之间增加 "跳跃连接",将低层特征与高层特征融合,提升小目标分割精度(医学影像领域常用);
- Mask R-CNN:在 Faster R-CNN 基础上增加 "掩膜分支",同时实现目标检测与实例分割,是实例分割的经典算法。