每日更新教程,评论区答疑解惑,小白也能变大神!"

目录
[1. 同源分道:从通用到专用](#1. 同源分道:从通用到专用)
[2. 核心设计差异](#2. 核心设计差异)
[1. 双通道架构:效率跃升的引擎](#1. 双通道架构:效率跃升的引擎)
[2. 电压与工艺:能效比突破](#2. 电压与工艺:能效比突破)
[3. 封装创新:180球BGA的精密布局](#3. 封装创新:180球BGA的精密布局)
[三、实战检验:GDDR6 vs. 前代的性能代差](#三、实战检验:GDDR6 vs. 前代的性能代差)
[1. 游戏帧率:带宽敏感型场景碾压](#1. 游戏帧率:带宽敏感型场景碾压)
[2. 成本效益:中端显卡的隐形升级](#2. 成本效益:中端显卡的隐形升级)
[1. 自动驾驶:实时决策的算力基座](#1. 自动驾驶:实时决策的算力基座)
[2. AI推理:替代HBM的性价比之选](#2. AI推理:替代HBM的性价比之选)
[1. GDDR7:PAM3信号的技术跃进](#1. GDDR7:PAM3信号的技术跃进)
[2. 存算一体:打破"内存墙"](#2. 存算一体:打破“内存墙”)

一、分水岭:GDDR与DDR的技术分野
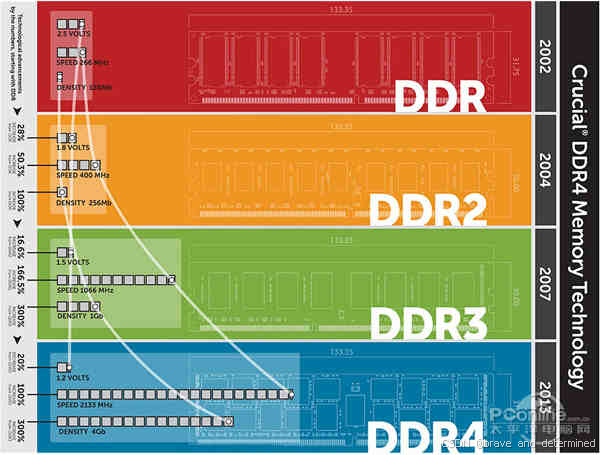
1. 同源分道:从通用到专用
-
早期融合期(2000-2004):
GDDR1/2与DDR1/2共享技术规范(如2bit预取、TSOP封装),显卡可直接使用DDR2颗粒,二者差异仅在频率调优。
-
专用化转折点:
GPU并行计算需求爆发,显存需更高带宽(纹理/帧缓冲数据量达GB级),而DDR受限于主板布线与通用性设计,无法满足GPU的实时渲染带宽需求。
例:2004年GeForce FX 5800的GDDR2显存带宽仅16GB/s,而同期的DDR2内存带宽不足6GB/s。
2. 核心设计差异
| 特性 | DDR(内存) | GDDR(显存) |
|---|---|---|
| 目标 | CPU顺序指令处理 | GPU万级核心并行计算 |
| 带宽优先级 | 延迟敏感(ns级) | 吞吐量敏感(TB/s级) |
| 封装 | DIMM插槽(兼容性优先) | 直接焊接于PCB(缩短信号路径) |
| 电压演进 | DDR4 1.2V → DDR5 1.1V | GDDR5 1.5V → GDDR6 1.35V |
物理本质 :二者均基于DRAM,但GDDR通过优化信号完整性 (如差分时钟)、增加Bank数量(GDDR6支持32 Bank)实现频率跃升。
二、GDDR6的三重技术革命
1. 双通道架构:效率跃升的引擎
-
通道独立性:
每个通道独立控制32字节数据流,读写操作可并行(如:GPU渲染时同时写入新帧+读取上一帧)。
-
带宽公式升级:
带宽 = 频率 × 位宽 × 通道数 ÷ 8以RTX 4090为例:24Gbps × 384bit × 2 ÷ 8 = 1152GB/s(GDDR5同规格仅768GB/s)。
2. 电压与工艺:能效比突破
-
1.35V→1.1V的进化:
三星通过动态电压切换(DVS) 技术,在待机时降压至1.1V,功耗降低40%(笔记本显卡续航提升关键)。
-
制程红利:
-
三星1Y nm工艺:晶体管密度提升30%,漏电率下降50%
-
海力士21nm工艺:单颗粒容量达16Gb(2GB),4颗实现8GB显存。
-
3. 封装创新:180球BGA的精密布局
-
信号干扰抑制:
球间距缩小至0.75mm(GDDR5为0.8mm),通过数据总线反转(DBI) 减少同步开关噪声(SSN)。
-
空间利用:
尺寸14×12mm²,允许显卡PCB集成12颗颗粒(如RTX 3090的24GB显存)。
三、实战检验:GDDR6 vs. 前代的性能代差
1. 游戏帧率:带宽敏感型场景碾压
| 显卡型号 | 显存类型 | 《赛博朋克2077》4K帧率 | 带宽利用率 |
|---|---|---|---|
| RTX 2080 Ti (11GB) | GDDR6 | 58 FPS | 98% |
| GTX 1080 Ti (11GB) | GDDR5X | 42 FPS | 89% |
| 性能差距 | → +38% |
数据来源:RTX 20系实测(),高分辨率下GDDR6减少贴图延迟卡顿。
2. 成本效益:中端显卡的隐形升级
-
GTX 1650案例:
GDDR6版显存频率12Gbps(GDDR5版8Gbps),192GB/s带宽提升50%,游戏帧率平均提高5.5% (售价不变)。
关键机制:GDDR6的双通道预取缓解了GPU核心与显存间的数据淤塞。
四、超越游戏:GDDR6的泛化应用
1. 自动驾驶:实时决策的算力基座
-
数据洪流挑战:
激光雷达+摄像头每秒生成4GB数据,需在100ms内完成路径规划。
-
GDDR6解决方案:
512GB/s带宽满足L4级自动驾驶算力需求(如NVIDIA Orin芯片)。
2. AI推理:替代HBM的性价比之选
-
边缘设备优化:
GDDR6的1.25V低功耗版本(海力士)使AI推理卡功耗降至35W(HBM2方案需80W+)。
-
成本对比:
方案 带宽 成本($/GB) HBM2e 1.2TB/s 18 GDDR6 768GB/s 6
五、未来战场:GDDR6的技术延展与挑战
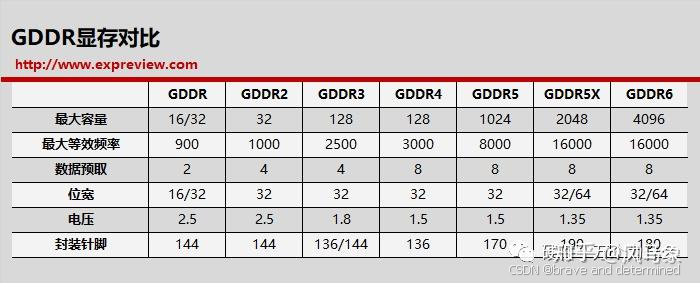
1. GDDR7:PAM3信号的技术跃进
-
编码革命:
抛弃传统NRZ(非归零编码),采用PAM3(三电平脉冲幅度调制),单周期传输1.5bit数据(GDDR6仅1bit)。
-
速度目标:
美光36Gbps版本带宽达1.5TB/s(RTX 5090预期规格)。
2. 存算一体:打破"内存墙"
-
近存计算架构:
三星将AI算子嵌入GDDR6控制器(如矩阵乘加速),减少数据搬运能耗(较传统架构降60%)。
-
CXL显存池化:
多GPU通过CXL协议共享GDDR6显存池,解决大模型训练显存碎片化问题。
结语:显存技术的哲学启示
GDDR6的演化揭示专用化与通用化的辩证法则:
-
需求倒逼创新 :GPU万级核心并发催生双通道架构,使显存带宽十年提升15倍(DDR同期仅3倍);
-
技术下沉普惠 :从RTX 2080 Ti旗舰到GTX 1650入门卡,GDDR6完成垂直市场覆盖,印证"高端技术终将平民化";
-
跨界反哺生态 :自动驾驶与AI推理的二次应用,凸显底层技术突破的跨域辐射力。
正如GDDR6的180球BGA封装------以精密布局换取空间与效率------计算体系的进步,永远在基础物理与顶层需求间寻找动态平衡点。