hadoop-shaded-guava依赖问题
报错信息如下:
shell
java.lang.NoClassDefFoundError: org/apache/hadoop/thirdpart/com/goole/common/base/Preconditions
at org.apache.hadoop.fs.aliyun.oss.AliyunOssUtils.loginOPtion(AliyunOssUtils.java 221)从日志可以看出是因为缺失某个依赖导致。
我先说说我的排查方向,比较笨重
- 通过IDEA全局搜索这个类,发现没有这个类
- 最开始看到这个报错以为是guava包冲突了,就在pom.xml文件里面排除guava包,打包后发现还是不行,妥协了根据报错信息慢慢找
- 从报错的代码位置进行排查(发现AliyunOssUtils类import了org/apache/hadoop/thirdpart/com/goole/common/base/Preconditions这个类),
因为代码逻辑是利用spark读取S3文件用到了hadoop-aliyun的依赖,而adoop-aliyun依赖在AliyunOssUtils类中import了org/apache/hadoop/thirdpart/com/goole/common/base/Preconditions类,hadoop原生的依赖包并不会提供该依赖的支持所以在spark-submit时报错。知道问题就比较好解决了。
如果不了解 hadoop-shaded-guava 这个jar,可以去maven仓库下载,具体地址:https://mvnrepository.com/
搜索hadoop-shaded-guava
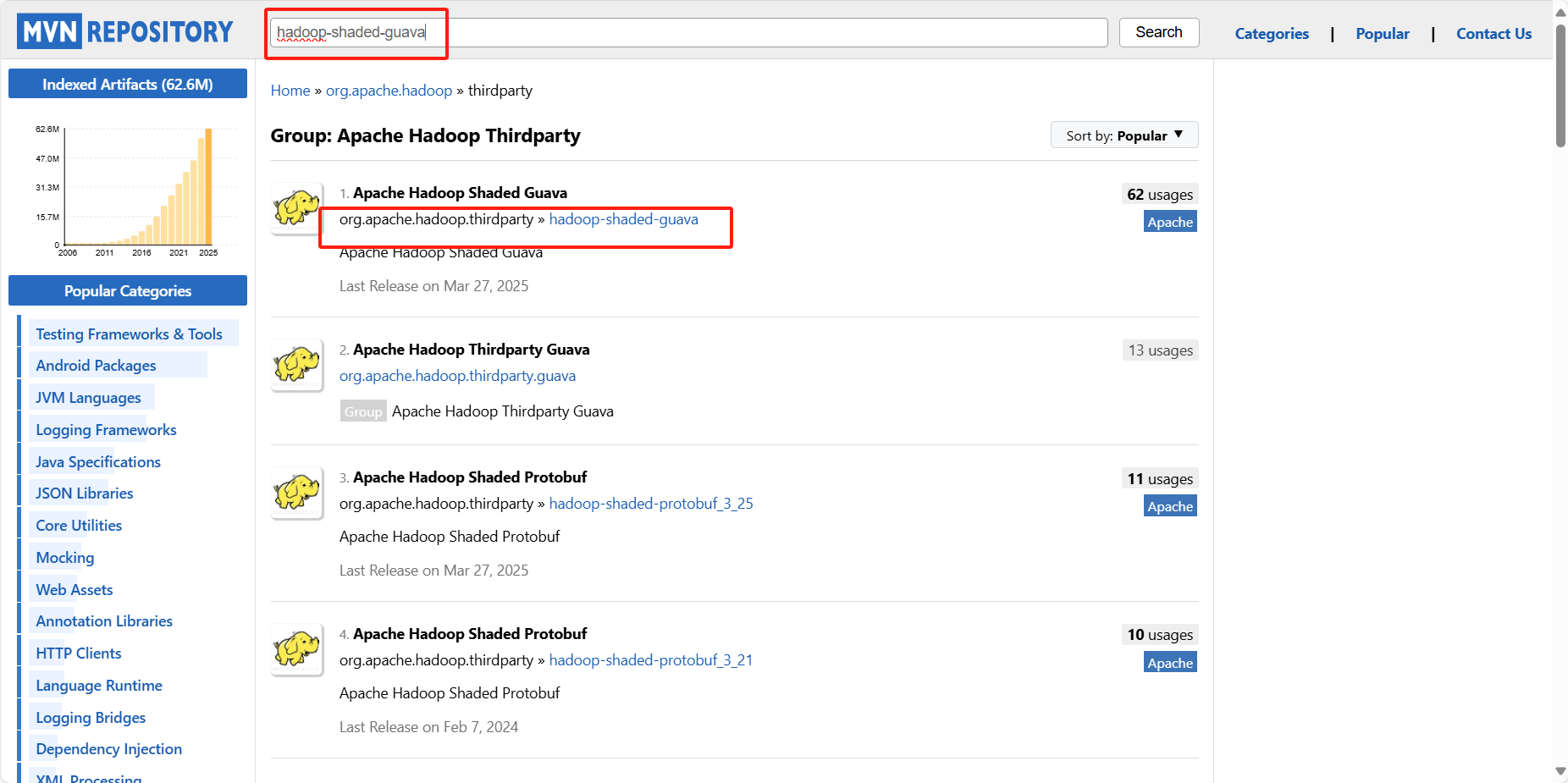
选择具体版本即可
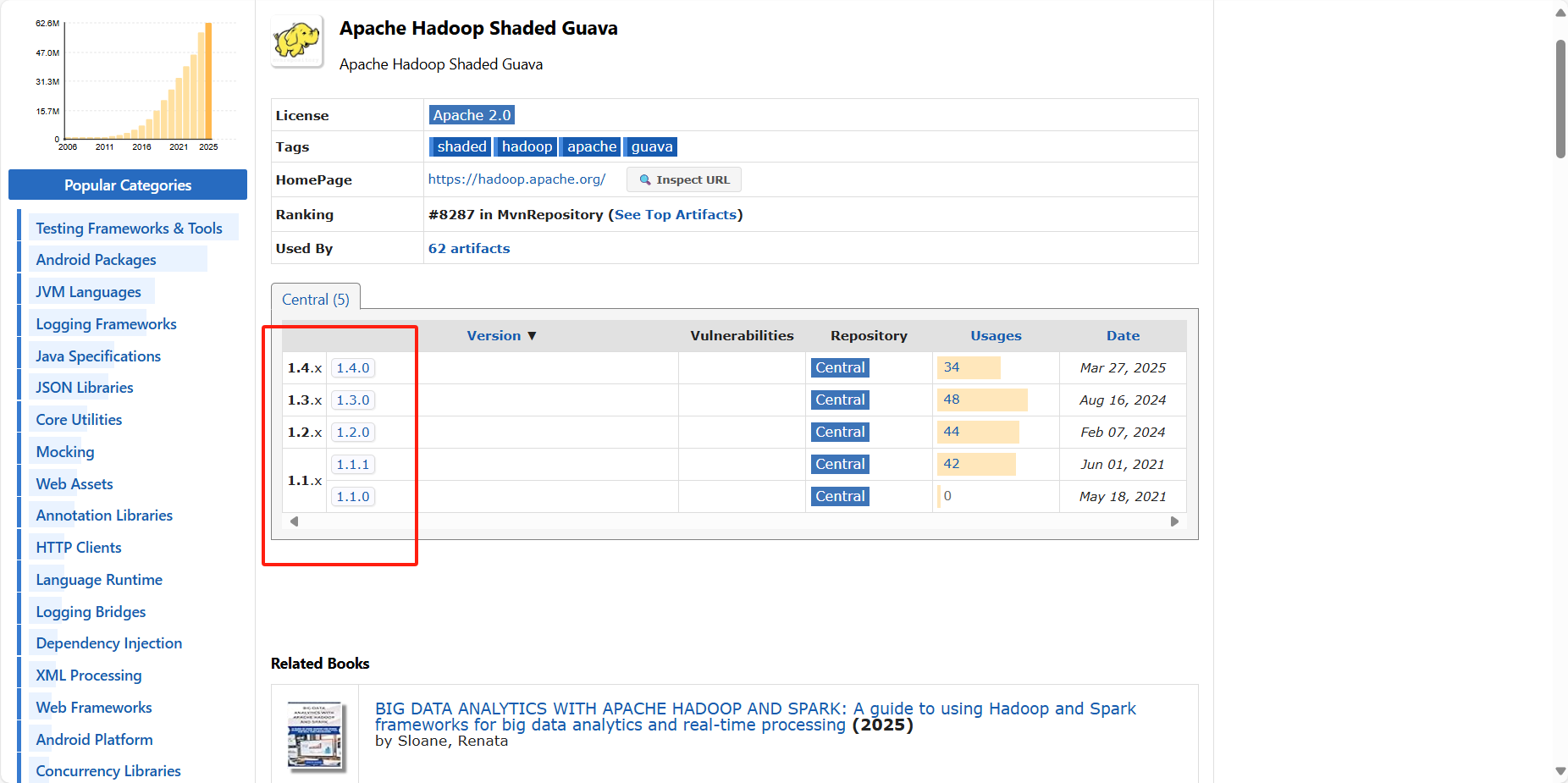
找到对应版本引入导pom.xml文件即可。
xml
<dependency>
<groupId>org.apache.hadoop.thirdparty</groupId>
<artifactId>hadoop-shaded-guava</artifactId>
<version>1.3.0</version>
</dependency>