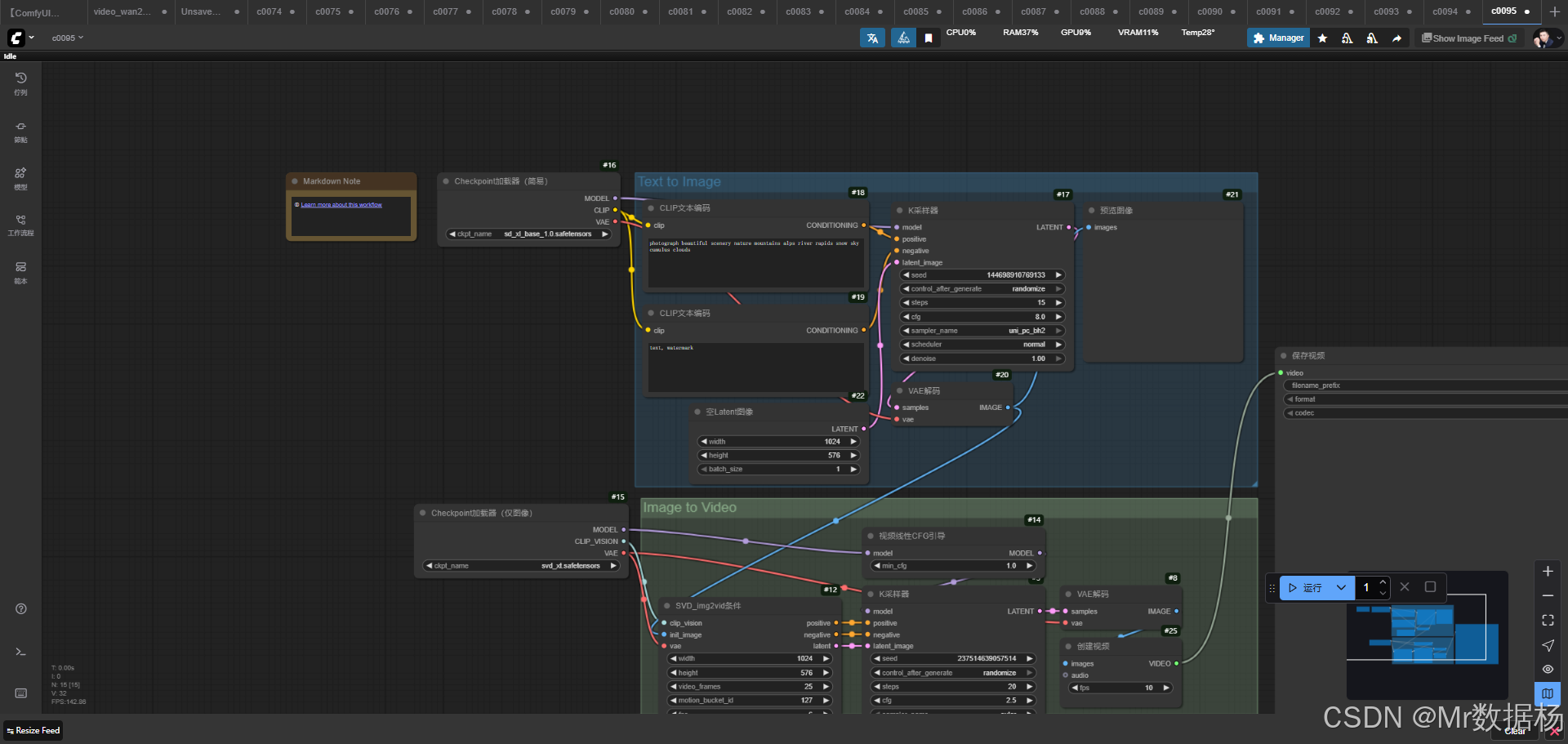
今天给大家演示一个 ComfyUI 图像生成与图像转视频工作流。整个流程的设计围绕"先图像、后视频"的思路展开,先通过 Stable Diffusion XL 模型完成高质量的图像生成,再借助 Stable Video Diffusion 将静态图像转化为动态视频。工作流中,文本提示经过编码后被转化为条件输入,随后在潜空间内通过扩散采样生成初始结果,并在 VAE 解码器的作用下得到清晰的静态图像。接着,这些图像被送入视频扩散环节,结合视频条件化与引导机制逐帧生成画面,最终通过合成与保存节点导出完整的视频文件。整个流程实现了从文本到图像,再从图像到视频的完整闭环,既保证了生成画面的细节表现力,又确保了视频的连贯性与风格统一,为多模态内容的创作提供了流畅而实用的方案。
文章目录
- 工作流介绍
-
- 核心模型
- Node节点
- 工作流程
- 应用场景
- 开发与应用
工作流介绍
本工作流将 文生图与图生视频 有机结合,构建了一个双阶段的生成体系。在第一阶段,Stable Diffusion XL 模型负责生成分辨率高、细节丰富的图像,为后续视频生成提供坚实基础;在第二阶段,Stable Video Diffusion 模型则承接前一阶段的输出,对静态图像进行运动扩展,使画面获得时间维度上的延展。通过节点间的紧密衔接,文本编码、潜空间采样、解码输出与视频条件化处理被有效串联在一起,最终得到从提示词到视频成片的全自动化生成结果。
核心模型
本工作流的核心模型采用"双模型互补"的方式,一方面利用 Stable Diffusion XL 强化图像生成的质量与细节表现,另一方面通过 Stable Video Diffusion 将静态结果转化为动态视频,从而在内容生成的完整性上实现突破。前者提供了清晰写实的图像画面,后者则赋予其时间上的连贯性,使静态创作具备动态呈现的能力。
| 模型名称 | 说明 |
|---|---|
| sd_xl_base_1.0.safetensors | 基于 Stable Diffusion XL 的文生图模型,适合高质量图像生成 |
| svd_xt.safetensors | 基于 Stable Video Diffusion 的图生视频模型,用于静态图转视频 |
Node节点
节点的配置展现了工作流的整体逻辑性与层层递进关系。文本提示首先通过 CLIPTextEncode 节点被转化为条件信息,随后结合潜空间初始化与 KSampler 的扩散采样过程,生成初步的潜空间结果,再由 VAE 解码器转换为可见图像,并可通过 PreviewImage 节点进行预览。在进入视频生成阶段后,工作流调用 ImageOnlyCheckpointLoader 加载视频扩散模型,并通过 SVD_img2vid_Conditioning 设置正负向条件与潜空间约束,再经由 VideoLinearCFGGuidance 与 KSampler 的采样引导,逐帧生成符合条件的视频序列。最后,CreateVideo 将帧序列合成为视频,SaveVideo 完成导出。这一系列节点的协作使得文本驱动、图像生成与视频合成实现了无缝衔接。
| 节点名称 | 说明 |
|---|---|
| CheckpointLoaderSimple | 加载 Stable Diffusion XL 文生图模型 |
| CLIPTextEncode | 文本编码为正向 / 负向条件提示 |
| EmptyLatentImage | 初始化潜空间图像容器 |
| KSampler | 执行扩散采样生成潜空间结果 |
| VAEDecode | 将潜空间结果解码为图像 |
| PreviewImage | 中间结果预览,便于调试 |
| ImageOnlyCheckpointLoader | 加载 Stable Video Diffusion 图生视频模型 |
| SVD_img2vid_Conditioning | 设置视频扩散条件,提供正负向引导及潜空间 |
| VideoLinearCFGGuidance | 视频引导控制,调节条件一致性 |
| CreateVideo | 将生成的帧序列合成视频 |
| SaveVideo | 保存最终视频文件 |
工作流程
整个工作流的运行机制可以理解为一个从文本到视频的逐层演化过程。首先在文本到图像阶段,输入的提示词经过 CLIPTextEncode 编码形成条件约束,并与 CheckpointLoaderSimple 所加载的 Stable Diffusion XL 模型结合,利用 KSampler 在潜空间中采样生成结果。潜空间数据再通过 VAEDecode 解码成高清图像,用户可以借助 PreviewImage 节点检查效果。随后,图像被引入到视频生成阶段,ImageOnlyCheckpointLoader 加载 Stable Video Diffusion 模型并配合 SVD_img2vid_Conditioning 提供视频扩散所需的条件,VideoLinearCFGGuidance 对生成过程施加一致性约束,确保画面风格连贯。在完成逐帧采样后,CreateVideo 将图像帧合成为完整的视频文件,并由 SaveVideo 节点输出。整个流程环环相扣,实现了从文字描述到视频成片的全链条生成。
| 流程序号 | 流程阶段 | 工作描述 | 使用节点 |
|---|---|---|---|
| 1 | 文本提示编码 | 将正向与负向提示词转化为条件信息 | CLIPTextEncode |
| 2 | 模型加载与潜空间初始化 | 加载 Stable Diffusion XL 模型并创建潜空间输入 | CheckpointLoaderSimple / EmptyLatentImage |
| 3 | 扩散采样与解码 | 通过 KSampler 采样并由 VAE 解码为图像 | KSampler / VAEDecode |
| 4 | 图像预览 | 对生成图像进行中间结果检查 | PreviewImage |
| 5 | 视频模型加载与条件设定 | 加载 Stable Video Diffusion 模型并设定扩散条件 | ImageOnlyCheckpointLoader / SVD_img2vid_Conditioning |
| 6 | 视频引导与逐帧采样 | 应用一致性控制生成动态画面 | VideoLinearCFGGuidance / KSampler |
| 7 | 视频合成与导出 | 将生成帧序列合成为完整视频并保存 | CreateVideo / SaveVideo |
应用场景
该工作流的应用场景集中在多模态创作与内容生成中,尤其适合需要从文字创意直接生成动态视觉内容的用户。在实际应用中,设计师可以通过它快速获得具有细节表现力的画面并转化为视频,影视从业者能够利用其在分镜设计或动态概念呈现上获得高效支持,个人创作者则可以借助其低门槛特性实现从灵感到成片的快速迭代。无论是创意营销、短视频制作还是 AI 艺术探索,该工作流都能提供便捷而完整的解决方案,保证画面生成的质量与视频输出的连贯性。
| 应用场景 | 使用目标 | 典型用户 | 展示内容 | 实现效果 |
|---|---|---|---|---|
| 创意设计 | 将文本灵感转化为动态图像素材 | 设计师 / 插画师 | 高质量图像与短视频 | 快速生成视觉参考 |
| 影视前期 | 制作分镜或动态概念演示 | 导演 / 动画师 | 连贯的动态画面 | 提高前期创作效率 |
| 自媒体创作 | 将创意内容快速生产为短视频 | 内容博主 / 独立创作者 | 图文结合的视频 | 提升内容产出效率 |
| 教育与展示 | 用于课程演示或视觉讲解 | 教师 / 讲师 | 可视化讲解视频 | 增强教学互动效果 |
开发与应用
更多 AIGC 与 ComfyUI工作流 相关研究学习内容请查阅:
更多内容桌面应用开发和学习文档请查阅:
AIGC工具平台Tauri+Django环境开发,支持局域网使用
AIGC工具平台Tauri+Django常见错误与解决办法
AIGC工具平台Tauri+Django内容生产介绍和使用
AIGC工具平台Tauri+Django开源ComfyUI项目介绍和使用
AIGC工具平台Tauri+Django开源git项目介绍和使用