今天给大家演示一个基于 ComfyUI 的 Hunyuan3D v2 工作流,它能够通过多视角输入图像,结合模型推理完成三维重建,并最终生成可视化的网格文件。整个流程涵盖了模型加载、图像编码、多视角条件生成、采样推理、体素解码与网格转换,最后输出为可直接使用的三维模型。通过这一工作流,可以直观地看到从二维图像到三维模型的生成过程,非常适合三维创作、虚拟展示和建模学习的应用场景。
文章目录
- 工作流介绍
-
- 核心模型
- Node节点
- 工作流程
- 应用场景
- 开发与应用
工作流介绍
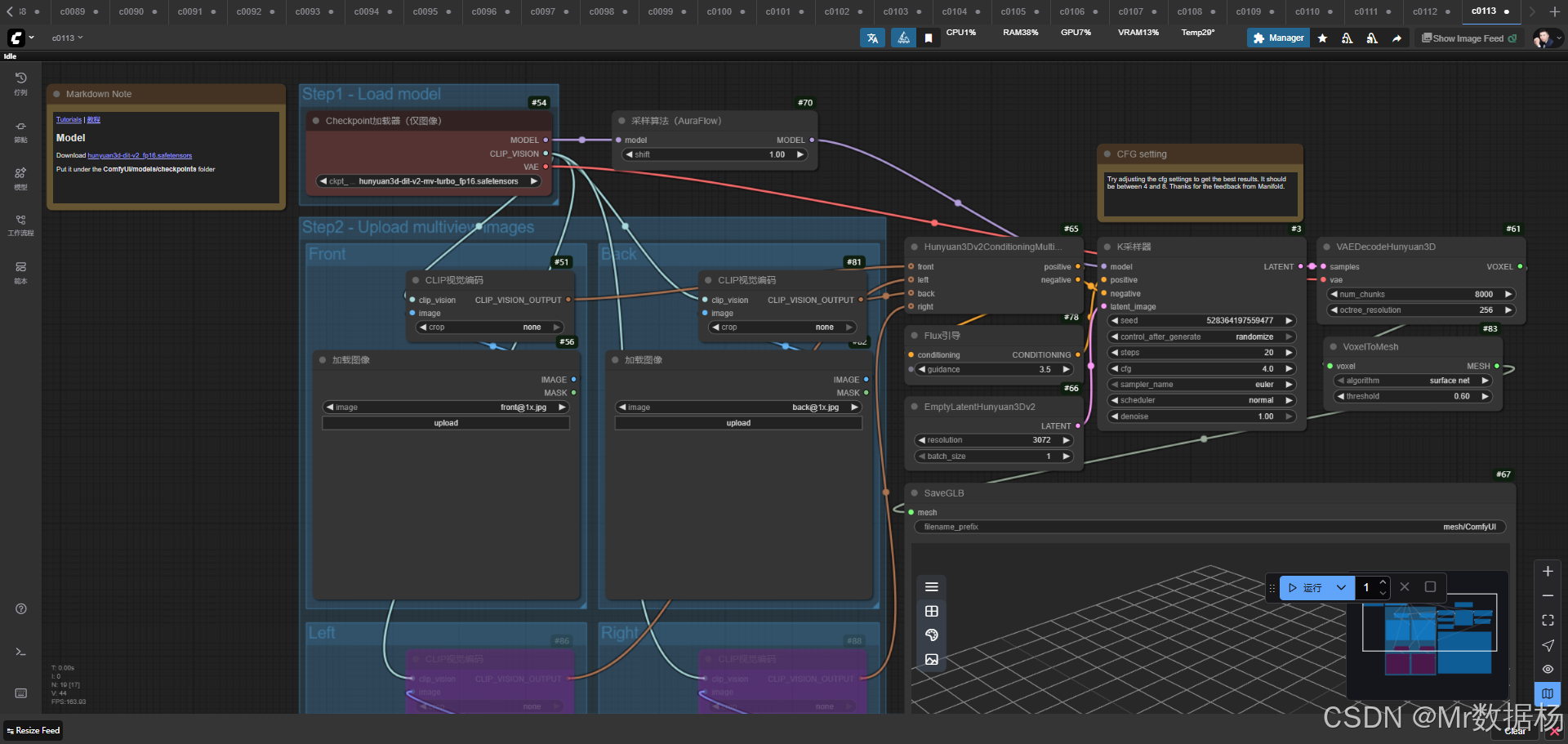
本工作流以 Hunyuan3D v2 作为核心模型,结合 CLIP 图像特征编码与多视角条件输入,实现了从正面、背面、左侧和右侧的图像输入到完整三维模型的自动化生成。工作流中的核心环节包括模型与 VAE 的加载、FluxGuidance 提示引导、多视角编码条件输入,以及 KSampler 的推理采样。配合 VAEDecodeHunyuan3D 和 VoxelToMesh,生成结果能够顺利转换为标准的 GLB 格式网格模型,方便在各类三维场景中使用。
核心模型
本工作流核心依赖 Hunyuan3D v2 多视角重建模型,其权重通过 ImageOnlyCheckpointLoader 节点加载,并搭配 VAE 解码器完成体素到三维模型的还原。该模型结合了多视角输入的图像特征,确保在三维生成中能够获得较高的细节还原度和空间一致性。
| 模型名称 | 说明 |
|---|---|
| hunyuan3d-dit-v2-mv-turbo_fp16.safetensors | 来自 HuggingFace 的 Hunyuan3D v2 模型,支持多视角条件输入与三维重建 |
Node节点
在节点层面,工作流涵盖了从图像加载、特征提取、条件输入到结果生成的完整环节。LoadImage 节点用于导入前后左右多视角的参考图像,CLIPVisionEncode 负责图像特征编码,Hunyuan3Dv2ConditioningMultiView 节点则融合这些特征以构建正负条件输入。FluxGuidance 节点进一步调整生成结果的引导强度,KSampler 完成采样推理,而 VAEDecodeHunyuan3D 与 VoxelToMesh 则依次实现体素解码与网格化。最后通过 SaveGLB 节点将结果保存为通用的 GLB 文件。
| 节点名称 | 说明 |
|---|---|
| LoadImage | 加载多视角参考图像 |
| CLIPVisionEncode | 提取输入图像的视觉特征 |
| Hunyuan3Dv2ConditioningMultiView | 融合多视角特征生成正负条件输入 |
| FluxGuidance | 控制生成引导强度,优化输出结果 |
| KSampler | 执行扩散采样推理 |
| EmptyLatentHunyuan3Dv2 | 创建初始潜空间以供采样 |
| VAEDecodeHunyuan3D | 将潜空间解码为三维体素 |
| VoxelToMesh | 将体素数据转换为三维网格 |
| SaveGLB | 保存最终生成的三维模型文件 |
| ImageOnlyCheckpointLoader | 加载核心模型与 VAE 权重 |
| ModelSamplingAuraFlow | 模型采样方式调整,优化生成表现 |
工作流程
整个工作流程围绕多视角输入图像到三维模型生成的完整路径展开。首先通过 LoadImage 节点分别导入前、后、左、右的多视角图像,再利用 CLIPVisionEncode 节点将这些图像转化为视觉特征。随后,Hunyuan3Dv2ConditioningMultiView 节点整合这些特征,形成正负条件输入,并交由 FluxGuidance 节点进行引导强度调节。在模型采样阶段,KSampler 结合 EmptyLatentHunyuan3Dv2 生成的潜空间完成推理采样,得到初步的三维潜在表示。之后,VAEDecodeHunyuan3D 将潜空间解码为体素结构,VoxelToMesh 则将体素转化为网格,最终由 SaveGLB 节点导出为通用三维格式文件。整体流程环环相扣,确保从输入图像到三维输出的高效转换。
| 流程序号 | 流程阶段 | 工作描述 | 使用节点 |
|---|---|---|---|
| 1 | 模型加载 | 加载核心 Hunyuan3D v2 模型与 VAE 权重 | ImageOnlyCheckpointLoader, ModelSamplingAuraFlow |
| 2 | 多视角图像输入 | 分别导入正面、背面、左侧和右侧参考图像 | LoadImage |
| 3 | 图像特征提取 | 将输入图像转化为可用于条件生成的视觉特征 | CLIPVisionEncode |
| 4 | 多视角条件构建 | 融合不同方向的特征,生成正负条件 | Hunyuan3Dv2ConditioningMultiView |
| 5 | 引导调节 | 通过引导参数影响生成效果 | FluxGuidance |
| 6 | 采样推理 | 在潜空间中完成扩散采样生成 | KSampler, EmptyLatentHunyuan3Dv2 |
| 7 | 体素解码 | 将潜空间解码为三维体素结构 | VAEDecodeHunyuan3D |
| 8 | 网格转换 | 将体素转换为标准网格数据 | VoxelToMesh |
| 9 | 模型输出 | 保存生成的三维模型文件 | SaveGLB |
应用场景
该工作流能够将二维图像快速转化为三维模型,在多个应用场景中都具有广泛价值。例如在三维创作与艺术设计中,用户可以通过提供多视角的参考图像快速生成高保真模型,减少建模时间;在虚拟展示和电商行业,商家能够利用该方法为商品快速生成可旋转的三维展示效果;在教育与科研中,则可用于辅助三维重建与空间理解的教学实验。通过 GLB 格式的输出,生成模型可以直接嵌入网页、VR/AR 环境或三维设计软件中,极大提高了使用灵活度与展示效果。
| 应用场景 | 使用目标 | 典型用户 | 展示内容 | 实现效果 |
|---|---|---|---|---|
| 三维艺术创作 | 快速生成三维模型原型 | 艺术家、设计师 | 多视角输入生成的三维对象 | 提高创作效率,快速迭代 |
| 虚拟展示与电商 | 商品三维展示 | 电商平台、品牌商家 | 可旋转交互的商品模型 | 提升用户体验与商品表现力 |
| 教育科研 | 三维重建与空间理解 | 教师、研究人员 | 三维结构实验与演示 | 辅助教学,直观理解三维原理 |
| 游戏与虚拟世界 | 角色或物品建模 | 游戏开发者、3D 创作者 | 场景或角色三维模型 | 快速生成素材,加速开发流程 |
开发与应用
更多 AIGC 与 ComfyUI工作流 相关研究学习内容请查阅:
更多内容桌面应用开发和学习文档请查阅:
AIGC工具平台Tauri+Django环境开发,支持局域网使用
AIGC工具平台Tauri+Django常见错误与解决办法
AIGC工具平台Tauri+Django内容生产介绍和使用
AIGC工具平台Tauri+Django开源ComfyUI项目介绍和使用
AIGC工具平台Tauri+Django开源git项目介绍和使用