今天给大家演示一个基于 Wan2.2 模型 的 ComfyUI 视频工作流,主打"丝滑变装与首尾衔接效果"的生成方案。通过起始图与结束图的融合处理,结合 VAE 解码与特效控制,最终实现一个自然过渡的视频片段。本工作流重点围绕多模型协同、动画插帧控制与 Lora 微调技术展开,不仅适合视觉平滑动画生成,也为角色换装与转场提供了新方式。以下将详细解析本次工作流所使用的模型、节点与核心结构。
文章目录
工作流介绍
本工作流围绕"起始图像"与"结束图像"构建起一个首尾连接的视频合成框架。使用 Wan2.2 系列的多模型组件,包括 VAE、主模型和文本编码器,以实现图像生成与特效控制的精细化调度。系统利用 SLGArgs 与 ExperimentalArgs 调整帧生成与扩展行为,同时通过 WanVideoVACEStartToEndFrame 实现从起点图到终点图的动画合成。整体流程串联了推理模型加载、图像增强、尺寸调节、节点拼接等操作,最终生成一段流畅过渡、无缝首尾衔接的视频帧序列。
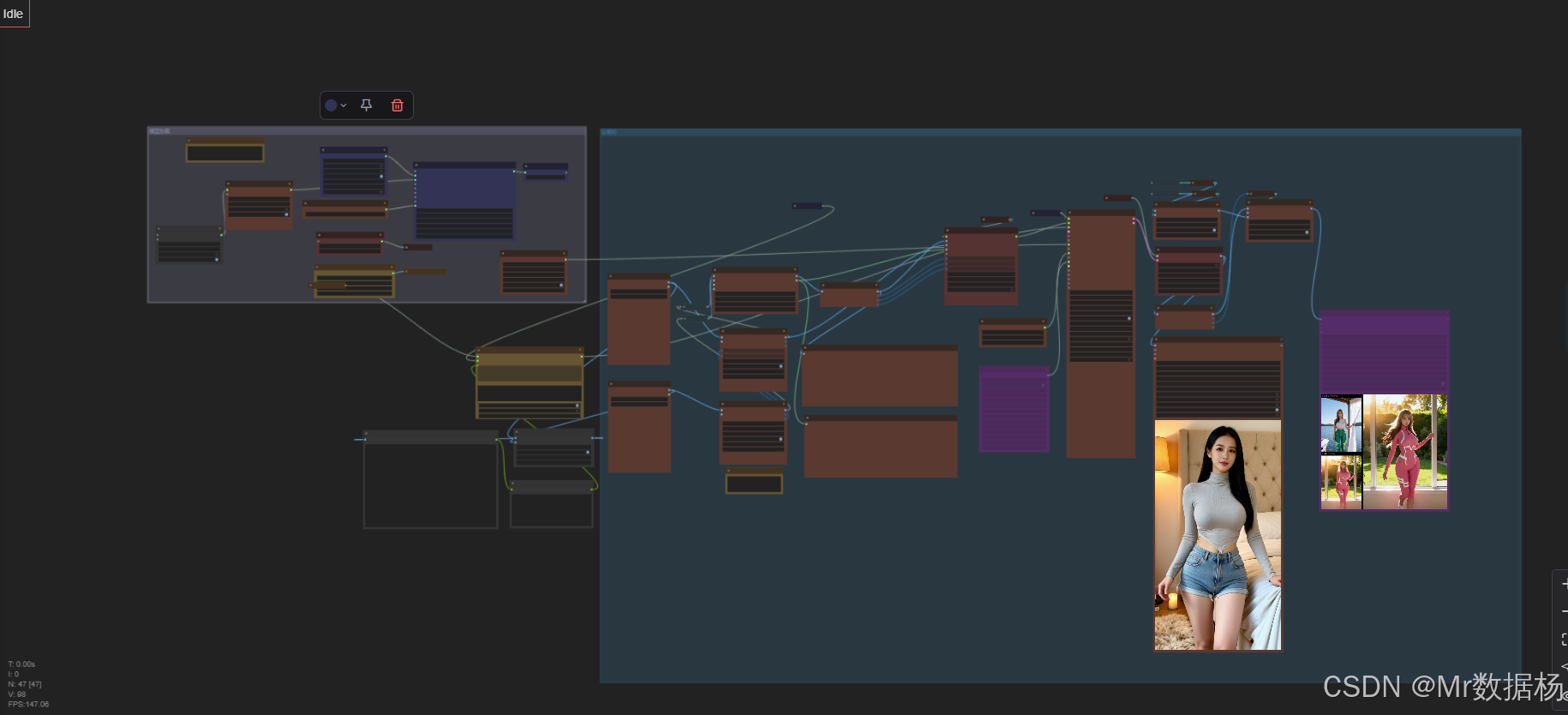
核心模型
核心模型采用的是 Wan2.2 系列的高精度视频生成组件,包括 aniWan2114BFp8E4m3fn_t2v 主模型、Wan2_1_VAE_bf16 解码器以及 umt5-xxl-enc-bf16 文本编码器。它们共同支撑起视频生成中的图像理解、潜变量解码和文本语义控制,确保了画面质量与变装逻辑的契合度。
| 模型名称 | 说明 |
|---|---|
| aniWan2114BFp8E4m3fn_t2v.safetensors | 主模型,用于生成视频帧的图像基础内容 |
| Wan2_1_VAE_bf16.safetensors | VAE 模型,负责将潜变量转化为可视图像 |
| umt5-xxl-enc-bf16.safetensors | 文本编码器,对提示词语义编码,为图像生成提供语义指导 |
| 百变H-gfbz-050.safetensors | Lora 模型,用于变装主题微调 |
| Wan2_1-VACE_module_14B_bf16.safetensors | VACE 控制模块,用于实现变装逻辑与结构控制 |
Node节点
本工作流依托多个高阶节点模块协作,确保生成图像在样式过渡与结构控制方面达到丝滑连贯的视觉效果。WanVideoSampler 为生成核心,配合 WanVideoBlockSwap 控制加载策略;WanVideoSLG 控制中段帧平滑生成;AddLabel 节点用于图像标记说明;而 ImageResizeKJ 与 ImageConcatMulti 负责图像尺寸匹配与拼接输出,形成首尾衔接的闭环。
| 节点名称 | 说明 |
|---|---|
| WanVideoModelLoader | 加载主模型,支持多参数自定义推理流程 |
| WanVideoVAELoader | 加载 VAE 模型,将潜变量转换为图像 |
| LoadWanVideoT5TextEncoder | 加载提示词文本编码器 |
| WanVideoSampler | 控制图像生成的关键推理器,核心处理单元 |
| WanVideoSLG | 设置图像帧插值区间,提升过渡流畅度 |
| WanVideoExperimentalArgs | 设置生成策略,如采样方式、增强方案等 |
| WanVideoBlockSwap | 控制内存策略与模块交换机制 |
| WanVideoVACEStartToEndFrame | 生成首帧与尾帧之间的动画帧集合 |
| ImageResizeKJ | 图像尺寸调整,保持兼容性 |
| AddLabel | 给图像添加标签,方便调试或结果展示 |
| ImageConcatMulti | 多图拼接节点,用于组合对比输出图像 |
工作流程
本工作流的整体流程分为四个主要阶段:模型加载、输入准备、动画生成与图像拼接。首先加载核心组件,包括主模型、VAE、文本编码器与 LoRA 微调模块,确保变装与推理逻辑完整。随后,获取起始图与结束图,并使用 WanVideoVACEStartToEndFrame 节点生成中间过渡帧,形成基本的视频结构。接着,使用 Sampler 节点结合多参数控制策略(如 SLGArgs、ExperimentalArgs)进行高质量图像采样。最后,通过 ImageConcatMulti 和 AddLabel 形成对比输出,展示丝滑变装与首尾无缝衔接的效果。
| 流程序号 | 流程阶段 | 工作描述 | 使用节点 |
|---|---|---|---|
| 1 | 模型加载 | 加载 Wan2.2 主模型、VAE 解码器与 T5 文本编码器,并注入 LoRA 变装模块 | WanVideoModelLoader、WanVideoVAELoader、LoadWanVideoT5TextEncoder、WanVideoLoraSelect |
| 2 | 输入准备 | 提取起始图与结束图,生成中间帧动画;并提取图像尺寸信息 | Get_start_image、Get_end_image、WanVideoVACEStartToEndFrame、GetImageSizeAndCount |
| 3 | 图像生成 | 使用 Sampler 节点执行高质量推理生成,结合控制参数调节过渡效果 |
WanVideoSampler、WanVideoSLG、WanVideoExperimentalArgs、WanVideoTeaCache |
| 4 | 图像拼接输出 | 将首帧、中帧与尾帧拼接,添加标签用于展示;输出最终视频帧序列 | AddLabel、ImageConcatMulti、ImageResizeKJ、PreviewImage |
大模型应用
文本语义编码节点:WanVideoT5TextEncoder
该节点负责将输入的提示词 Prompt 进行语义编码,为后续的图像生成模块提供语言指导信息。在该流程中,虽然 Prompt 本身未直接显式设置在节点中,但 umt5-xxl-enc-bf16 文本编码模型的角色非常明确:将文字提示编码成文本嵌入向量,作为生成引导依据。因此,它是驱动变装动画方向与风格变化的"语言控制中枢"。
| 节点名称 | Prompt信息 | 说明 |
|---|---|---|
| umt5-xxl-enc-bf16 | 节点未设置显式Prompt | 该模型将外部提示词(如"变装"、"风格转换"等)转化为语义向量,用于指导图像生成模块进行内容与风格控制。 |
图像潜变量解码节点:WanVideoVAE
该节点在生成阶段的末尾,将模型输出的潜变量图像进行解码,转化为可视图像。其核心职责是确保从高维特征空间恢复出清晰、结构完整的图像帧,是视频渲染质量的基础保障。
| 节点名称 | Prompt信息 | 说明 |
|---|---|---|
| Wan2_1_VAE_bf16 | 无需Prompt,仅处理图像潜变量 | 将潜在空间中的图像数据解码成最终的图像帧,是视频成品图像的输出关键步骤。 |
主模型推理节点:WanVideoSampler
WanVideoSampler 是整个生成流程的核心推理模块。它将图像嵌入、文本嵌入、采样参数与控制指令(如 SLG 插值、Cache 优化)集成为一次推理任务。该节点的职责是:根据输入提示生成连续帧画面,使变装过程自然、无明显跳帧或突兀变化。
| 节点名称 | Prompt信息 | 说明 |
|---|---|---|
| aniWan2114BFp8E4m3fn_t2v | Prompt嵌入来源于TextEncoder节点 | 根据语义提示与控制信号合成目标动画帧,是主导变装动态生成的关键模块。 |
使用方法
开始节点
开始节点以多个 GetNode 与 SetNode 节点形式存在,用于准备模型、图像、参数等初始输入内容。包括获取起始/结束图、设置模型路径等。以下是代表性的开始节点字段说明:
| 字段名 | 含义 | 数据类型 |
|---|---|---|
| start_image | 起始帧图像输入 | IMAGE |
| end_image | 结束帧图像输入 | IMAGE |
| WanModel | 视频主模型路径设置 | WANVIDEOMODEL |
| WanVAE | VAE模型路径设置 | WANVAE |
| WanTextEncoder | 文本编码器路径设置 | WANTEXTENCODER |
结束节点
结束部分输出的核心是生成的视频图像序列,可视作草稿级产出内容,便于导出或接入后处理链路。
| 字段名 | 含义 | 数据类型 |
|---|---|---|
| images | 动画视频帧图像输出 | IMAGE |
应用场景
该工作流特别适用于视觉风格需要"变装 + 转场"并行控制的任务场景,尤以短视频创作、角色转换演示、穿搭视频生成、虚拟人设切换等为代表。创作者可通过起始图与结束图定义视觉两端,系统自动生成中间动画过程,最大限度减少人工干预,同时确保画面质量与逻辑一致性。通过使用不同的 LoRA 模型,可轻松适配风格化需求,如二次元、写真、复古、科幻等。
| 应用场景 | 使用目标 | 典型用户 | 展示内容 | 实现效果 |
|---|---|---|---|---|
| 穿搭视频生成 | 自动化角色变装过程,生成丝滑过渡动画 | 视频创作者 / 虚拟人设博主 | 起始与结束装扮 + 中间动画过程 | 起始→中间→结束动画丝滑过渡,无需逐帧处理 |
| 虚拟角色换装演示 | 展示角色风格转换过程 | 二次元内容创作者 | 同一角色不同装扮 | 风格变化自然平滑 |
| 虚拟人设转场 | 从一个角色平滑切换至另一个角色 | AI 数字人设计者 | 连续视频段落 | 角色视觉逻辑一致,衔接流畅 |
| 短视频剪辑生成 | 节奏型视频段动画过渡 | 抖音/B站创作者 | 特效视频衔接 | 无缝场景衔接,提升视觉体验 |
| 图像到视频创作 | 从图像过渡生成视频 | AIGC 开发者 | 输入图像+动画输出 | 图转视频一体化处理,提升效率 |
开发与应用
更多 AIGC 与 ComfyUI工作流 相关研究学习内容请查阅:
更多内容桌面应用开发和学习文档请查阅:
AIGC工具平台Tauri+Django环境开发,支持局域网使用
AIGC工具平台Tauri+Django常见错误与解决办法
AIGC工具平台Tauri+Django内容生产介绍和使用
AIGC工具平台Tauri+Django开源ComfyUI项目介绍和使用
AIGC工具平台Tauri+Django开源git项目介绍和使用