分布式系统的缓存一致性一直是后台架构师们绕不开的话题。
今天,我们就来深入聊聊"分布式环境下MySQL与Redis双写一致性"这件事。
一、为什么数据会不一致?
在典型的架构中,MySQL作为可靠数据源,Redis作为缓存层。
每一次数据写入(包括增删改)都需要同步到这两个存储点。但同步过程中可能出现:
-
写MySQL成功,写Redis失败,导致Redis中存的是旧数据。
-
写Redis成功,写MySQL失败,导致Redis中是"脏数据",数据库没有这份数据。
-
并发读写时,一个线程还没更新缓存,另一个线程读取了旧缓存,导致数据不一致。
这些问题本质上都源于多步骤写操作的原子性无法保证。
二、主流一致性策略与模式
1. Cache-Aside模式(旁路缓存)
最经典的缓存模式。应用直接与数据库和缓存交互,缓存不是写入的必经之路。
读流程:
-
查询Redis,命中则返回。
-
未命中则查MySQL,将结果写入Redis再返回。
写流程:
-
更新MySQL。
-
删除(Invalidate)Redis缓存,而非直接更新缓存。
为什么是删除(Invalidate)缓存,而不是更新缓存?
这是一个关键设计点!
性能:如果更新缓存,每次数据库写操作都要伴随一次缓存写操作,如果该数据并不经常被读取,那么这次缓存写入就是浪费资源的。
并发安全:在并发写场景下,更新缓存的顺序可能与更新数据库的顺序不一致,导致缓存中是旧数据。而删除操作是幂等的,更为安全。
这种模式通过"先更新数据库,再删除缓存"最大程度保证一致性。但在高并发场景仍可能出现极短暂的不一致窗口。
1,线程 A 更新数据库。
2,线程 B 读取数据,发现缓存不存在,从数据库读取旧数据(因为 A 还没提交或刚提交)。
3,线程 B 将旧数据写入缓存。
4,线程 A 删除缓存。
这种情况发生的概率较低,因为通常数据库写操作(步骤1)会比读操作(步骤2)耗时更长(因为涉及锁、日志等),所以步骤2在步骤1之前完成的概率很小。但这是一种理论上的可能。
2. Write-Through / Read-Through模式
缓存层负责与数据库同步。应用只和缓存交互。
-
写操作:先写缓存,缓存同步写入数据库,两者都成功才算写入成功。
-
读操作:读取缓存,未命中由缓存自动从数据库加载。
优点:逻辑对应用透明,一致性比 Cache-Aside 更好。
缺点:性能较差,因为每次写操作都必然涉及一次数据库写入。通常需要成熟的缓存中间件支持。
3. Write-Behind模式(异步写回模式)
应用写入缓存后立即返回,缓存层异步批量同步到数据库。
优点:写性能极高。
缺点:有数据丢失风险(缓存宕机),一致性最弱
适合对一致性要求不高、允许少量数据丢失的场景,比如点赞计数。
三、进阶方案:保证最终一致性
1. 延迟双删
在Cache-Aside基础上,写完数据库后,先删一次缓存,休眠一段时间后再删一次缓存。这样能清理掉并发读写场景下可能出现的旧数据。
1, 线程 A 更新数据库。
2, 线程 A 删除缓存。
3, 线程 A 休眠一个特定的时间(如 500ms - 1s)。
4, 线程 A 再次删除缓存。
第二次删除是为了清理掉在第1次删除后、其他线程可能写入的旧数据。这个休眠时间需要根据业务读写耗时来估算。
优点 :简单有效,能很大程度上解决并发读写导致的不一致。缺点:降低了写入吞吐量,休眠时间难以精确设定。
2. 消息队列异步删除
将删除缓存的操作通过消息队列(如RocketMQ、Kafka)异步处理。消息消费失败可重试,提高删除操作的可靠性。
更新数据库。
向消息队列发送一条删除缓存的消息。
消费者消费该消息,执行删除 Redis 的操作。如果删除失败,消息会重试。
3. Binlog同步(推荐)
这是目前最成熟、对业务侵入性最小、一致性最好的方案。其核心是利用 MySQL 的二进制日志(Binlog)进行增量数据同步。
利用MySQL的Binlog日志,借助如Canal、Debezium等中间件实时订阅数据库变更,自动同步到Redis。业务代码无需关心缓存一致性,性能和一致性都非常高,但实现复杂度也较大。
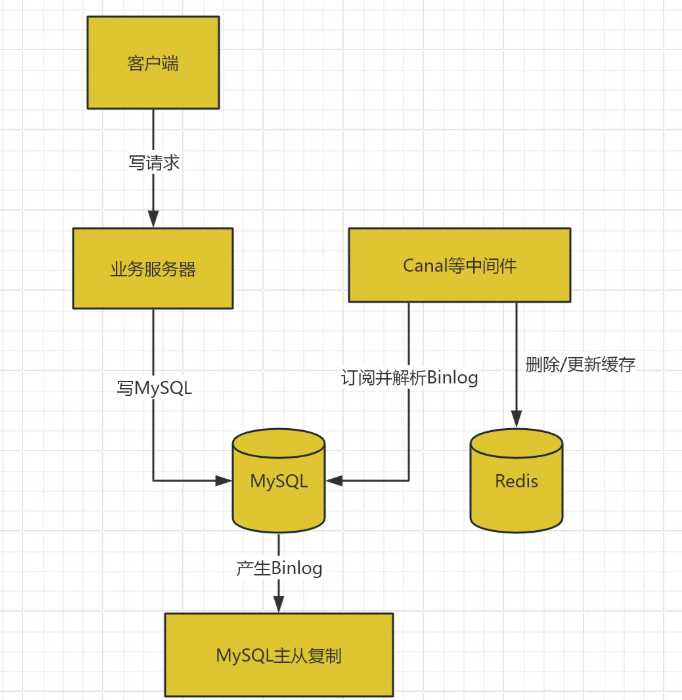
工作原理:
1, 业务系统正常写入 MySQL。 2, 由一个中间件(如 Canal, Debezium)伪装成 MySQL 的从库,订阅 Binlog。 3, 中间件解析 Binlog,获取数据的变更详情(增、删、改)。 4, 中间件根据变更,调用 Redis 的 API 来更新或删除对应的缓存。
优点:
-
业务无侵入:业务代码只关心写数据库,完全不知道缓存的存在。
-
高性能:数据库和缓存的同步是异步的,不影响主业务链路的性能。
-
强保证:由于基于 Binlog,它能保证只要数据库变了,缓存最终一定会被同步。顺序也与数据库一致。
缺点:
-
架构复杂,需要维护额外的同步组件。
-
同步有毫秒级到秒级的延迟。
四、策略选择与最佳实践
| 策略 | 一致性保证 | 性能 | 复杂度 | 适用场景 |
|---|---|---|---|---|
| Cache-Aside + 删除 | 最终一致性(微弱风险) | 高 | 低 | 读多写少,首选 |
| Cache-Aside + 延迟双删 | 更好的一致性 | 中 | 低 | 一致性要求高,且能接受一定延迟的写操作 |
| Write-Through | 强一致性 | 中 | 中 | 写多读少,且对一致性要求非常高的场景 |
| Binlog同步 | 最终一致性(推荐) | 高 | 高 | 大型项目最佳实践 |
通用建议:
-
多数应用推荐Cache-Aside(先数据库再删缓存)。
-
不一致窗口不可接受时,引入延迟双删或消息队列异步删除。
-
高要求项目采用Binlog同步。
-
一定给Redis缓存设置过期时间(TTL),保证旧数据自动失效。
-
与产品经理确认业务对一致性的容忍度,避免不必要的复杂架构。
好了,今天的分享就到这里了。大家对双写一致性有什么想法呢?欢迎评论区留言讨论哦~