文章目录
- 摘要
- Abstract
- [一、OpenPrompt Demo解读](#一、OpenPrompt Demo解读)
-
- [1. 准备:下载一些基础包](#1. 准备:下载一些基础包)
- [2. 定义一个提示词模板template](#2. 定义一个提示词模板template)
- [3. 对已包裹(wrapped)的样本进行分词处理](#3. 对已包裹(wrapped)的样本进行分词处理)
- [4. 对所有数据进行输入处理](#4. 对所有数据进行输入处理)
- [5. 构造数据加载器](#5. 构造数据加载器)
- [6. 创建verbalizer表述器](#6. 创建verbalizer表述器)
- [7. 创建分类任务的prompt learning模型](#7. 创建分类任务的prompt learning模型)
- [8. 训练模型](#8. 训练模型)
-
- [8.1 核心组件](#8.1 核心组件)
- [8.2 参数更新流程](#8.2 参数更新流程)
- [9. 评估模型](#9. 评估模型)
- 总结
摘要
本周主要完成对OpenPrompt工具包的使用展开,整个流程为基础准备;定义提示词模板并包裹样本;对包裹样本分词;处理所有数据;构造数据加载器;创建表述器与分类任务的 prompt learning 模型,还说明模型训练的损失函数、优化器等,以及模型评估流程。并对代码参数进行说明及常见疑问解答以辅助理解工具包使用。
Abstract
This week I mainly focused on using the OpenPrompt toolkit. The entire process includes: basic preparation; defining the prompt template and wrapping samples; tokenizing the wrapped samples; processing all data; constructing a data loader; creating a verbalizer and a prompt learning model for classification tasks. Additionally, it also illustrates the loss function, optimizer, etc., in model training, as well as the model evaluation process. Furthermore, I explained the code parameters and answered common questions to assist in understanding the usage of the toolkit.
一、OpenPrompt Demo解读
1. 准备:下载一些基础包
python
!pip install transformers --quiet
!pip install datasets==2.0 --quiet
!pip install openprompt --quiet
!pip install torch --quiet(1)加载huggingface中的数据
数据格式为:

(2)加载模型和分词器
(3)搭建和输入
转换输入格式,并且按照训练集、验证集和测试集拆分存储,方便后面使用。
查看转换后的第一条训练集样本,输出的格式如下:

注:输入数据没有的内容填充null或者直接为空集。
2. 定义一个提示词模板template
将之前转换的 InputExample 样本按照模板格式进行包裹(wrap),生成可供模型输入的提示词结构。
案例使用template:基于文本令牌初始化的软提示
①模板的逻辑:将前提和假设拼接成一个完整的问题(如 "前提 Deduction: 假设. Is it correct? 答案"),引导模型判断假设是否能从前提中推出。
②wrap_one_example()将 dataset'train'0 这个InputExample 样本按照 template_text 进行填充,生成包含模板 + 数据的结构化对象。
③输出 wrapped_example 可直观查看模板如何与具体数据结合,便于调试模板是否符合预期。
最后输出结果如下:

对输出结果说明:
(1)文本片段列表
loss_ids 字段:标记该文本片段是否参与损失计算(即是否是模型需要预测的部分):
loss_ids=0:表示该片段是 "输入",不参与损失计算。
loss_ids=1:表示该片段是 "预测目标"(即位置),参与损失计算。
shortenable_ids 字段:标记该文本片段是否可被截断(用于控制输入长度,避免超出模型上下文窗口):
shortenable_ids=1:表示该片段(如text_a、text_b的长文本)可被截断。
shortenable_ids=0:表示该片段(如固定模板文本、)不可被截断,必须保留。
text 字段:拼接后的完整输入文本,对应模板的每个部分:
第一段 text 是 text_a 字段的内容(原始文本)。
第二段 text 是模板中的固定文本 "Deduction:"。
第三段 text 是 text_b 字段的内容(推导结论)。
第四段 text 是模板中的固定文本 ". Is it correct?"。
第五段 text 是 (模型需要预测的位置)。
第六段 text 是模板中的固定文本 "."。
(2) 元信息(任务与标签)
{'guid': 0, 'label': 0}
guid:数据的唯一标识(这里是第 0 条训练数据)。
label:该数据的真实标签(0 表示 "推导不正确",具体含义需结合任务定义,如0对应 "否",1对应 "是")。
3. 对已包裹(wrapped)的样本进行分词处理
将自然语言提示词转换为模型可识别的 token ID格式,同时适配 T5 等编码器 - 解码器模型的输入要求。
①初始化分词器包装器 (WrapperClass / T5TokenizerWrapper)
参数说明:
max_seq_length:限制编码器输入的长度(避免模型输入过长)。
decoder_max_length:限制解码器输入的长度(T5 生成任务中,解码器输入通常是标签的 token ID)。
truncate_method="head":当文本超长时,从开头(头部)截断(其他方式如 tail 从尾部截断)。
注:
在 Prompt Learning 中,预训练模型的原生分词器(Tokenizer)难以直接适配复杂提示结构,因此需要专门的编码机制(如 OpenPrompt 中的PromptTokenizer)来处理,而编码器的选择需与基础预训练模型(如 BERT、GPT 等)对齐。
疑问:
问题1:代码中哪里使用了预训练tokenizer?
使用了预训练 Tokenizer,并非直接单独使用,而是而是将其作为底层依赖,通过PromptTokenizer对其进行了封装和扩展。
PromptTokenizer(提示分词器)的核心功能依赖预训练模型的原生 Tokenizer(如 BERT 的BertTokenizer、GPT 的GPT2Tokenizer)。
问题2:本段代码中是使用的哪种tokenizer?
T5TokenizerWrapper 是 OpenPrompt 框架提供的封装类,它并非直接使用 OpenPrompt 自研的 Tokenizer,而是对 预训练的tokenizer( T5的原生 Tokenizer)进行了功能扩展
②对单个样本进行分词并查看结果
先对wrapped_example进行分词,接着将input_ids、decoder_input_ids转换为对应的token
input_ids、decoder_input_ids的说明:
input_ids 和 decoder_input_ids 是适配 T5 模型 "编码器 - 解码器(Encoder-Decoder)" 结构的关键输入,分别对应模型的编码器输入和解码器输入。
input_ids:包含经过 Prompt 模板处理后的完整文本序列(如任务指令、输入数据、提示词等),用于让编码器理解 "任务目标" 和 "输入信息"。
decoder_input_ids:用于引导解码器生成目标输出(如分类标签、推理结果等)。
teacher_forcing 属性说明:
teacher_forcing=True(训练阶段):在训练阶段强制模型使用 "真实标签(Ground Truth)" 作为下一时间步的输入,而非模型自身生成的预测值。
补充说明:
具体举例说明:训练 "生成句子'我喜欢机器学习'" 时:
Step 1 输入:< START >,模型预测 "我";
Step 2 输入:真实标签 "我"(而非模型预测的 "我"),模型预测 "喜欢";
Step 3 输入:真实标签 "喜欢",模型预测 "机器";以此类推
teacher_forcing=False(推理阶段):解码器输入可能是默认的起始符(如< pad > 或 < s >,用于推理时让模型自主生成)。
综合说明:
(1)训练阶段
若 teacher_forcing=True,decoder_input_ids 由 任务的真实标签经过分词得到,在 "自然语言推理" 任务中,若真实标签是 "是"(表示推导正确),则 decoder_input_ids 是 "是" 对应的 Token ID(可能还包含起始 Token < s >)。

(2)推理阶段
若 teacher_forcing=False,decoder_input_ids来自 "模型自身生成",仅包含起始 Token,解码器完全依赖自身生成后续内容,模拟真实推理场景。

最后整段代码输出结果:

对于decoder_input_ids输出结果的解读:
\< pad \>, \
其中 <extra_id_0> 是模型需要生成的核心标签(如 "是" 或 "否"),前后的< pad > 是为了满足 decoder_max_length=3 的长度要求(代码中设置了 decoder_max_length=3)。
补充:
< pad >:填充 Token,用于补齐序列长度(当实际序列短于 decoder_max_length 时),不携带语义信息。
4. 对所有数据进行输入处理
5. 构造数据加载器
PromptDataLoader 是为Prompt Learning设计的训练数据加载器,它在传统 PyTorch DataLoader 的基础上,增加了对 Prompt 模板处理、分词适配、特殊格式转换 的支持,最终输出模型可直接训练的批量数据(包含 input_ids、attention_mask、decoder_input_ids 等关键字段)。
Demo中的核心作用是将原始训练数据集(dataset"train")按照 Prompt 模板进行格式化处理,转化为可直接输入预训练模型(如 T5)的批量数据,为后续模型训练做准备
训练配置:
shuffle=True:训练时打乱数据集顺序,避免模型学习到数据的排列规律(减少过拟合)。
predict_eos_token=False:是否预测 "结束 Token"(</ s >),此处设为 False 表示无需生成结束 Token(因任务是短序列输出,如分类标签)。
输出结果:

6. 创建verbalizer表述器
(1)ManualVerbalizer:人工定义标签词与类别的映射。需要给出tokenizer(预训练模型的分词器),num_classes(任务的类别数量),label_words每个列别对应的标签表

(2)myverbalizer.label_words_ids:标签词的 Token ID 映射。将人类可理解的标签词(如 "yes")转化为模型可识别的 Token ID。
(3)myverbalizer.process_logits(logits):将 logits 映射到类别概率

7. 创建分类任务的prompt learning模型
(1)用于分类任务的提示学习模型(PromptForClassification)
核心组件说明:
PromptForClassification 是 OpenPrompt 专为分类任务设计的模型封装类,它将三个核心组件(PLM,template,verbalizer)串联成端到端的分类模型:
预训练语言模型(plm):如 BERT、T5、LLaMA 等,是模型的 "主体",负责理解输入文本的语义。
Prompt 模板(template):即之前定义的 mytemplate,负责将原始数据转化为带提示的输入格式(如 "文本 + 指令 + 掩码")。
标签映射器(verbalizer):即之前定义的 myverbalizer,负责将模型输出的词级 logits 映射为分类标签的概率(如将 "yes""no" 的概率转化为 "类别 0""类别 1" 的概率)。
参数说明:
freeze_plm=False/True:控制是否冻结预训练模型的参数:
False 表示 "微调预训练模型"(更新 PLM 的参数),适合数据量充足的场景,能让模型更好适配任务。
True表示仅训练模板中的软令牌(Soft Token)和 Verbalizer 的参数,适合小数据场景(减少过拟合风险)。
核心原则:
小数据、低资源、简单任务→冻结;
大数据、高资源、复杂任务→微调。
(2)设备配置
use_cuda = torch.cuda.is_available():检查当前环境是否有可用的 GPU(支持 CUDA)。
if use_cuda: prompt_model = prompt_model.cuda():若有 GPU,则将模型迁移到 GPU 上运行,利用 GPU 的并行计算能力加速训练和推理。
8. 训练模型
8.1 核心组件
1,损失函数 :交叉熵损失函数
2,优化器参数分组 (optimizer_grouped_parameters)
目的:对模型不同类型的参数应用不同的优化策略(主要是权重衰减,weight_decay),提升训练稳定性和模型性能。
分组逻辑:
第一组:weight_decay=0.01(应用权重衰减)包含所有非偏差、非 LayerNorm 权重的参数(如 Transformer 层的注意力权重、线性层权重)。权重衰减是一种正则化手段,通过惩罚大权重值减少过拟合。
第二组:weight_decay=0.0(不应用权重衰减)包含偏差参数(bias) 和LayerNorm 层的权重。这些参数对模型性能影响较敏感,通常不施加权重衰减,避免破坏模型的稳定性。
实现方式:通过 named_parameters() 遍历模型所有参数,根据参数名称(n)中是否包含 bias 或 LayerNorm.weight 进行分组。
代码语法分析:
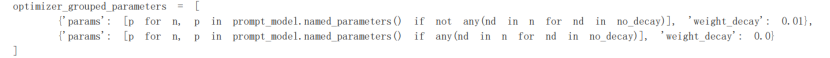
(1)named_parameters():返回模型中所有可训练参数的迭代器,每个元素是 (参数名称n, 参数值p)
(2)列表推导式语法规则:表达式 for 变量 in 迭代对象 if 条件,其中 "表达式" 定义了列表中每个元素的形式。
代码中具体使用:p for ...:列表推导式的最终目的是生成一个参数值的列表。
推导式的作用:筛选出满足条件(名称不含 bias 或 LayerNorm.weight)的参数,并将这些参数的值(p) 收集成一个列表,用于优化器的参数配置。
(3)参数说明
第一组参数(应用权重衰减)
筛选条件:if not any(nd in n for nd in no_decay)
①no_decay = 'bias', 'LayerNorm.weight':定义 "不应用权重衰减" 的参数名称关键词。
②any(nd in n for nd in no_decay):判断参数名称 n 中是否包含 no_decay 中的任何关键词(如参数名含 bias 或 LayerNorm.weight)。
③not any(...):筛选出名称中不含 bias 和 LayerNorm.weight 的参数。
第二组参数(不应用权重衰减)
筛选条件:if any(nd in n for nd in no_decay)
筛选出名称中包含 bias 或 LayerNorm.weight 的参数。
3,优化器
选择AdamW,它在 Adam 基础上改进了权重衰减的实现方式(更准确地对参数施加衰减),适合大规模参数的微调。
学习率的设置:
若冻结预训练模型(freeze_plm=True),仅训练软令牌等少量参数,学习率可设为 1e-4 ~ 5e-3(较大,加速收敛)。
若微调预训练模型(freeze_plm=False),学习率需减小(如 1e-5 ~ 5e-5),避免破坏预训练知识。
8.2 参数更新流程
- 数据准备(inputs = inputs.cuda())
将批量数据(inputs,包含 input_ids、labels 等)迁移到 GPU(若可用),与模型设备保持一致,避免计算错误。 - 模型前向传播(logits = prompt_model(inputs))
模型接收批量输入,经过 Prompt 模板处理、预训练模型编码、Verbalizer 映射后,输出类别 logits(形状为 (batch_size, num_classes),如 (4, 3) 表示 4 个样本、3 个类别)。 - 计算损失(loss = loss_func(logits, labels))
用 CrossEntropyLoss 计算 logits 与真实标签 labels 的损失值(标量),损失越大,模型预测与真实结果差异越大。 - 反向传播与参数更新
loss.backward():自动计算损失对所有可训练参数的梯度(链式法则)。
optimizer.step():根据梯度和优化器配置(如学习率、权重衰减)更新参数。
optimizer.zero_grad():清空当前梯度(避免与下一批数据的梯度累积,导致更新错误)。 - 训练日志(打印平均损失)
每 100 个 step 打印一次当前 epoch 的平均损失,用于监控训练过程:
若损失持续下降,说明模型在有效学习;
若损失趋于稳定或上升,可能出现过拟合或收敛问题,需调整学习率、批量大小等。
补充:
疑问一:为什么要使用item方法?
loss.item() 是 torch.Tensor(张量)对象的一个方法,用于将单元素张量转换为 Python 标量(如 float 或 int)。
如果直接写 tot_loss += loss,会导致 tot_loss 变成一个张量(而非 Python 标量),后续计算(如求平均 tot_loss/(step+1))会产生不必要的计算图跟踪(影响性能),甚至可能导致内存泄漏。
而 loss.item() 会剥离张量的计算图信息,做纯数值计算,也仅返回数值,既节省内存,又保证后续计算符合 Python 原生逻辑。
疑问二:什么是张量?什么是标量?
张量(Tensor) 和标量(Scalar) 是两种基础的数据形式,核心区别在于维度和存储的信息,具体如下:
一,标量(Scalar)
存储内容:0 维的单一数值
用途:损失值、准确率等单一指标
二,张量(Tensor)
存储内容:多维数组(>=1)
用途:输入数据、模型参数、中间特征等
核心特点:
1,张量不仅包含数值,还携带维度信息(shape)和设备信息(如 CPU/GPU)。
2,张量支持并行计算和自动求导(PyTorch 的核心功能).
9. 评估模型
流程:
(1)加载验证集数据,进行格式化处理
(2)验证流程:预测与指标计算
逐行解读代码:
迭代验证集,收集预测与标签:
python
for step, inputs in enumerate(validation_dataloader):
if use_cuda:
inputs = inputs.cuda() # 迁移数据到 GPU(若可用)
# 模型前向传播,输出预测值:类别 logits(形状:[batch_size, num_classes])
logits = prompt_model(inputs)
# 获取当前批次的真实标签(形状:[batch_size])
labels = inputs['label']
# 收集真实标签:将 GPU 张量转为 CPU 列表,存入 alllabels
alllabels.extend(labels.cpu().tolist())
# 收集预测结果:
# 1. torch.argmax(logits, dim=-1):对 logits 按最后一维取最大值索引(即预测的类别)
# 2. 转为 CPU 列表,存入 allpreds
allpreds.extend(torch.argmax(logits, dim=-1).cpu().tolist())疑问1:为什么要把GPU张量转为CPU列表?
模型在 GPU 上完成计算后,得到的预测结果(logits)和标签(labels)仍是 GPU 上的张量(torch.Tensor),而后续的结果存储、指标计算(如准确率)、可视化等操作通常依赖 Python 原生数据结构(如列表),且这些操作更适合在 CPU 上进行。核心目的:适配后处理需求。
疑问2:为什么一开始又要迁移到GPU?
为了让数据与模型在同一设备,利用 GPU 并行计算加速模型的前向 / 反向传播(核心目的:提升计算效率)。
(3)计算准确率(Accuracy)
zip(allpreds, alllabels)
zip() 是 Python内置函数 ,用于将两个列表(allpreds 和 alllabels)按位置一一配对,生成一个包含元组的迭代器。
具体举例说明:
- allpreds = 0, 1, 0, 2(模型对 4 个样本的预测类别)
- alllabels = 0, 1, 1, 2(4 个样本的真实类别)
zip(allpreds, alllabels) 生成的迭代器包含以下元组:
结果:(0, 0), (1, 1), (0, 1), (2, 2)
总结
本周主要围绕OpenPrompt工具包展开,在对工具包的使用过程中产生的疑问也通过大模型工具进行解决。本周停留在工具包的时间太长,因此下周将尽量加快速度,开启其他方面知识的学习。