1. 字符串中只有公式
python
from docx import Document
from latex2word import LatexToWordElement
def strip_double_dollar(s: str) -> str:
"""
若字符串前后均有 '$$',则去掉它们;否则返回原字符串。
"""
if s.startswith('$$') and s.endswith('$$') and len(s) >= 4:
return s[2:-2]
return s
latex_input = "$$ P_{R418} = \frac{(36/2)^2}{4.5kΩ} = 72mW $$"
latex_to_word = LatexToWordElement(latex_input)
doc = Document('demo_test.docx')
paragraph = doc.add_paragraph()
latex_to_word.add_latex_to_paragraph(paragraph)
doc.save('demo_test.docx')运行结果:
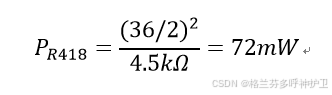
2. markdown字符串转Word
markdown中存在公式、表格、图片链接、段落文字等信息
需要将markdown转为html再转为word进行保存
对公式相关的处理如下:
首先将markdown转为html,为了保证中间的''等字符不被解析掉,需要将其进行转换:
python
import markdown
text = "$\\l_IH_max = 10/\\mu A$"
escaped = text.replace('$', '$').replace('\\', '\')
html = markdown.markdown(escaped, extensions=["tables", "fenced_code", "nl2br", "sane_lists", "extra"])
)接下来分别针对html不同的标签,对element中的文本提取,然后进行doc文本的添加即可;
其中公式调用标题1中的代码即可实现;