目录
Metastore部署模式
Hive Metastore存储所有表结构、分区信息等元数据。它的部署模式直接影响Hive的可用性、性能和扩展性。
内嵌模式
最简单的部署方式,适合学习和测试环境。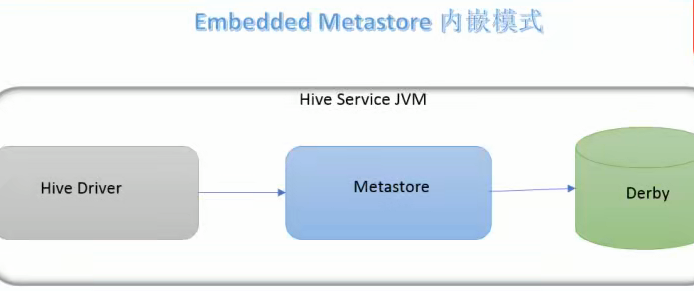
特点:
①使用内嵌的Derby数据库,只能单用户访问,不支持并发,所以不适合生产环境
②Metastore和Derby在同一个JVM进程中,元数据与服务耦合导致数据不易迁移
③无需额外配置,开箱即用
本地模式
使用了外部数据库。
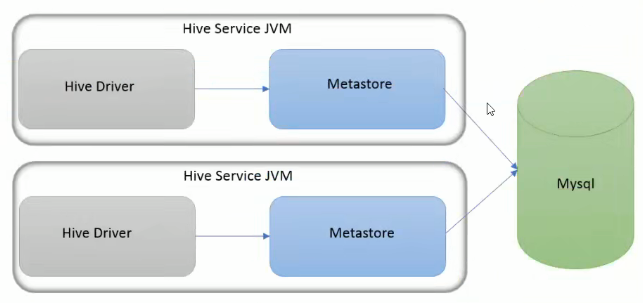
特点
①使用外部数据库
②Metastore在Hive进程内,通过JDBC连接外部数据库,比内嵌性能好
③每个Hive服务都需要连接数据库,容易单点故障和扩展瓶颈
远程模式
生产环境推荐模式。Metastore作为独立服务运行,多个Hive服务共享一个Metastore。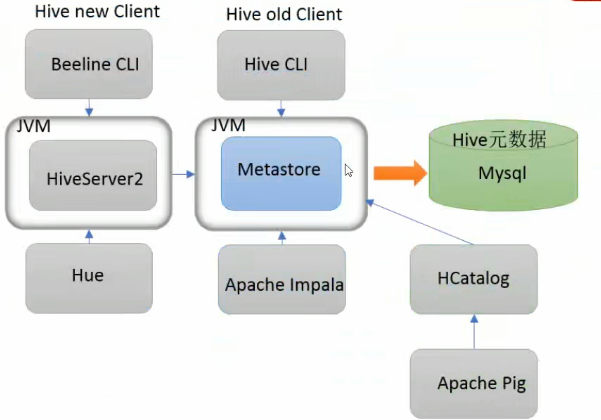
特点
①使用外部数据库,数据库连接信息集中管理,安全。
②Hive服务通过Thrift网络协议连接独立的Metastore服务。所有Hive服务共享一份元数据,便于集中管理; 可以部署多个Metastore可实现HA; 支持大量Hive客户端,扩展性好。
③部署复杂
Hive远程部署模式安装部署
一、环境说明
操作系统:Ubantu22.04(所有节点)
Hadoop 版本:3.4.1(已部署 3 节点集群:node1(NameNode)、node2(ResourceManager)、node3(DataNode),可参考 Hadoop 集群部署教程)
Hive 版本:3.1.3(与 Hadoop 3.x 兼容)
JDK 版本:1.8(所有节点需统一)
元数据库:MySQL 8.0(部署在 node1)
节点规划:Hive 仅需在主节点(node1) 安装(客户端可在其他节点部署)
二、Hadoop集群配置
①配置HDFS权限,允许Hive读写。修改hadoop/etc/hadoop/hdfs-site.xml,所有节点同步:
<property>
<name>dfs.permissions.enabled</name>
<value>false</value> <!-- 关闭权限检查,避免Hive读写HDFS时权限不足 -->
</property>②配置YARN资源,Hive 任务需 YARN 分配资源,根据虚拟机内存修改yarn-site.xml(所有节点同步)
<!-- 配置容器最小/最大内存(根据服务器内存调整,示例为4G内存节点) -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1024</value> <!-- 容器最小内存1G -->
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value> <!-- 容器最大内存2G -->
</property>
<!-- NodeManager可用内存(建议为服务器内存的80%) -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
<!-- 开启日志聚合(方便查看Hive任务日志) -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>③重启Hadoop集群,在主节点执行
# 停止集群
stop-all.sh
# 启动集群
start-all.sh三、安装配置MySQL
①安装MySQL
②下载MySQL JDBC驱动,Hive 需通过 JDBC 连接 MySQL,下载对应版本的驱动(MySQL 8.0 对应驱动 8.x)
wget https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.29/mysql-connector-java-8.0.29.jar四、安装Hive
①安装并解压Hive
# 下载Hive 3.13
# 华为镜像下载快,这是网址:https://repo.huaweicloud.com/apache/hive/
# 官方网址,慢一点就是
wget https://archive.apache.org/dist/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz
# 解压到/usr/local/目录
tar -zxvf apache-hive-3.1.3-bin.tar.gz -C /usr/local/
# 重命名为hive
mv /usr/local/apache-hive-3.1.3-bin /usr/local/hive②配置环境变量,编辑/etc/profile
vim /etc/profile
# 添加以下内容
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin
# 生效环境变量
source /etc/profile③修改Hive配置文件
-
重命名模板文件
进入配置目录
cd /usr/local/hive/conf
重命名模板文件
cp hive-env.sh.template hive-env.sh
cp hive-default.xml.template hive-site.xml
cp hive-log4j2.properties.template hive-log4j2.properties -
配置hive-env.sh,用于指定Hadoop安装路径
sudo vim hive-env.sh
添加以下内容
export HADOOP_HOME=/usr/local/hadoop # 你的Hadoop安装路径
export HIVE_CONF_DIR=/usr/local/hive/conf
export HIVE_AUX_JARS_PATH=/usr/local/hive/lib -
配置hive-site.xml
<property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://node1:3306/hive_metastore?createDatabaseIfNotExist=true&useSSL=false&serverTimezone=UTC&allowPublicKeyRetrieval=true</value> <!-- 注意& --> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.cj.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> <!-- MySQL用户名 --> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>@Ldryd1816</value> <!-- 你设置的用户的密码 --> </property> <!-- HDFS工作目录,会自动创建 --> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> <!-- HDFS路径,存储表数据 --> </property> <property> <name>hive.exec.scratchdir</name> <value>/tmp/hive</value> </property><property> <name>hive.metastore.event.db.notification.api.auth</name> <value>false</value> </property><property> <name>hive.server2.thrift.bind.host</name> <value>node1</value> <!-- 绑定到当前节点的主机名或IP --> </property> <property> <name>hive.server2.thrift.port</name> <value>10000</value> <!-- 默认端口,可自定义 --> </property> -
修改临时目录权限,避免启动报错
在Linux本地创建Hive日志目录
mkdir -p /usr/local/hive/tmp
chmod 777 /usr/local/hive/tmp在HDFS上创建Hive工作目录
hdfs dfs -mkdir -p /user/hive/warehouse
hdfs dfs -mkdir -p /tmp/hive
hdfs dfs -chmod 777 /user/hive/warehouse
hdfs dfs -chmod 777 /tmp/hive
④将之前下载的MySQL驱动复制到Hive的lib目录
cp mysql-connector-java-8.0.29.jar /usr/local/hive/lib/⑤初始化Hive元数据库
cd /usr/local/hive/bin
schematool -initSchema -dbType mysql -verbose
#若出现schemaTool completed,说明初始化成功五、启动并验证Hive
①启动Hive,并创建表(CLI模式)
# 后台开启metastore服务,jps查看进程RunJar,kill -9 杀死进程
nohup hive $HIVE_HOME/bin/hive --service metastore &
# 直接输入hive命令启动客户端(第一代客户端)
hive
# 成功启动后进入Hive交互界面,提示符为hive>
# 查看默认数据库(初始有default库)
hive> show databases;
# 创建测试数据库
hive> create database test;
# 切换到test库
hive> use test;
# 创建表,以","为分隔符
hive> create table student(id int, name string) row format delimited fields terminated by ','; ②为表添加内容
本地创建一个文件
vim ~/1.txt
#输入内容
1,Lown
2,Charles
# 上传到hdfs上之前创建好的test.db上
hdfs dfs -put ~/1.txt /user/hive/warehouse/test.db/student③验证HDFS数据存储
hive> show tables; # 查看表(应显示student)
hive> select * from student;
hive> quit; # 退出
# test.db是数据库目录,student是表目录
hdfs dfs -ls /user/hive/warehouse/test.db/student ④可以选择第二代客户端登录,启动HiveServer2(支持JDBC连接)
# 后台启动HiveServer2,jps查看进程,要先启动meatstore再启动HS2,此时应有两个RunJar
nohup $HIVE_HOME/bin/hive --service hivesever2 &
# 使用beeline客户端连接HiveServer2(推荐)
beeline -u jdbc:hive2://node1:10000 -n root # -n指定Linux用户名(测试环境用root)
# 连接成功后提示符为0: jdbc:hive2://node1:10000>,可执行HQL
0: jdbc:hive2://node1:10000> show databases;