大家好,欢迎来到 code秘密花园,我是花园老师(ConardLi)。
今天跟大家来聊聊 Easy Dataset 的一些最新消息以及近期重点更新功能解读。
首先说几个好消息,Easy Dataset 自上线以来已经收获了 11.5K Star,下载数超过 700K:
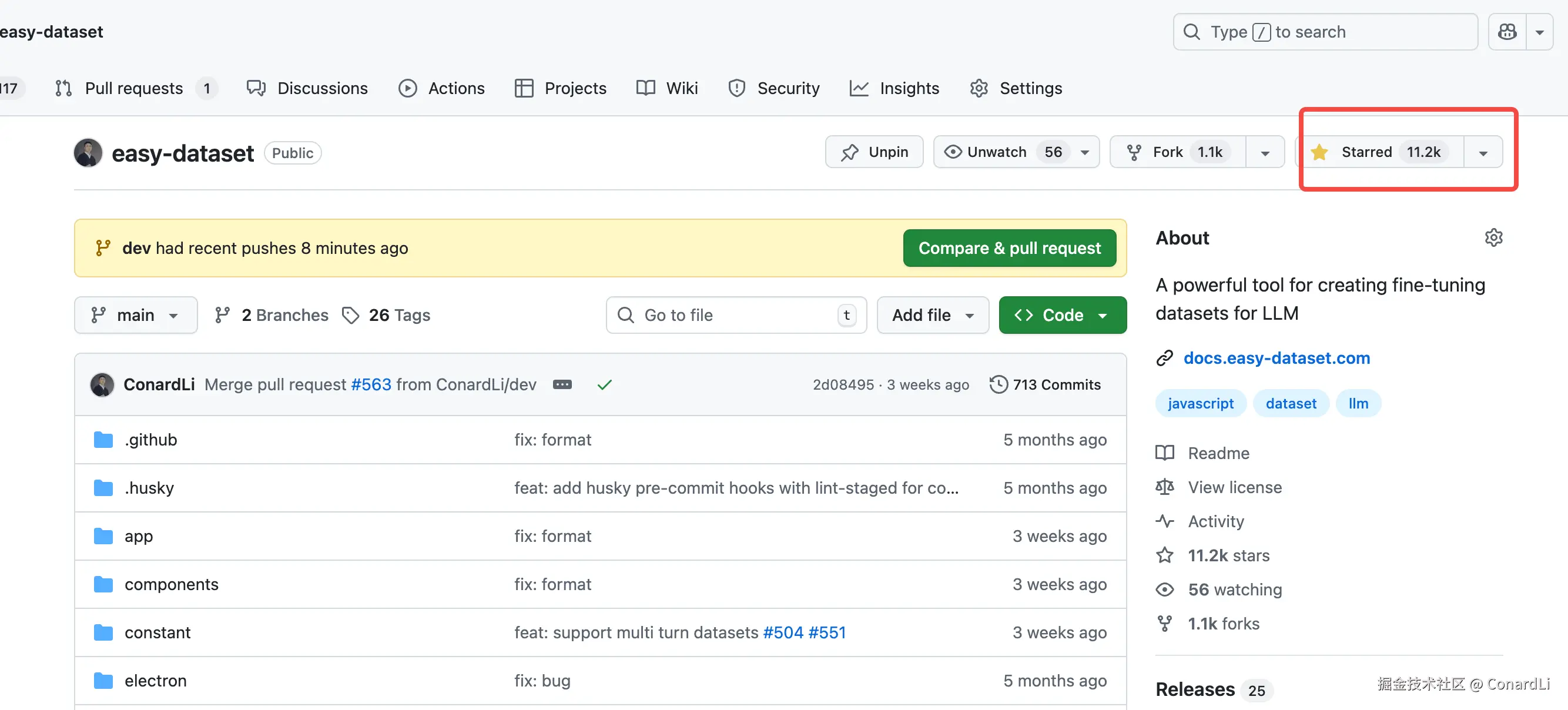
Easy Dataset(简称 EDS)是一个 AI 时代的智能应用。通过 EDS,你可以将各种文献以及图片中的领域知识转化为结构化数据集,然后你可以将这些数据集用于模型训练、RAG 等场景:github.com/ConardLi/ea...
并且在近期登上 Gihub Trending Repositories TOP3:
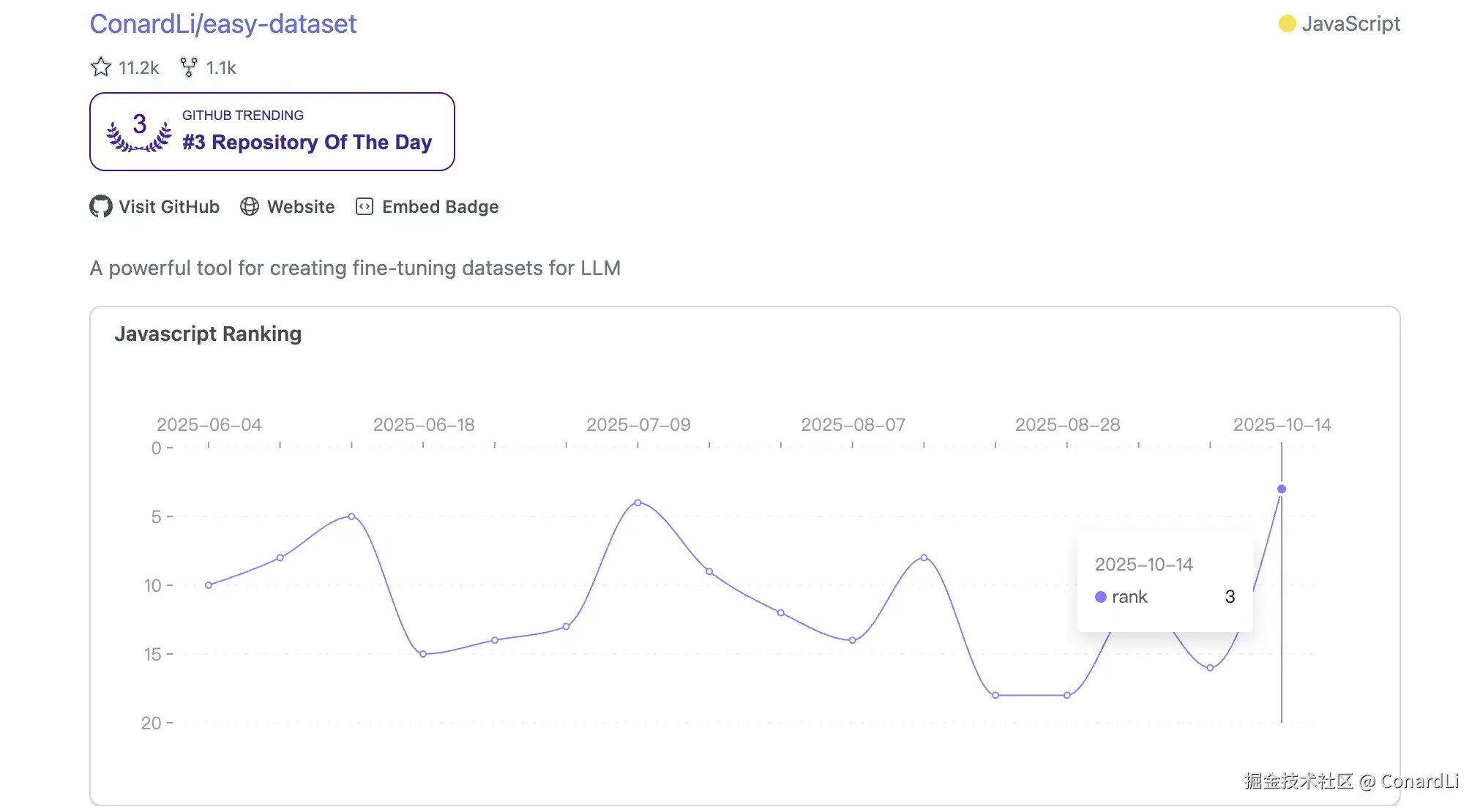
另外,Easy Dataset 论文已被 EMNLP 2025(人工智能领域顶级会议)接收,并且将在今年的 EMNLP 2025 System Demonstration 区域展出。
《Easy Dataset: A Unified and Extensible Framework for Synthesizing LLM Fine-Tuning Data from Unstructured Documents 》 - arxiv.org/abs/2507.04...
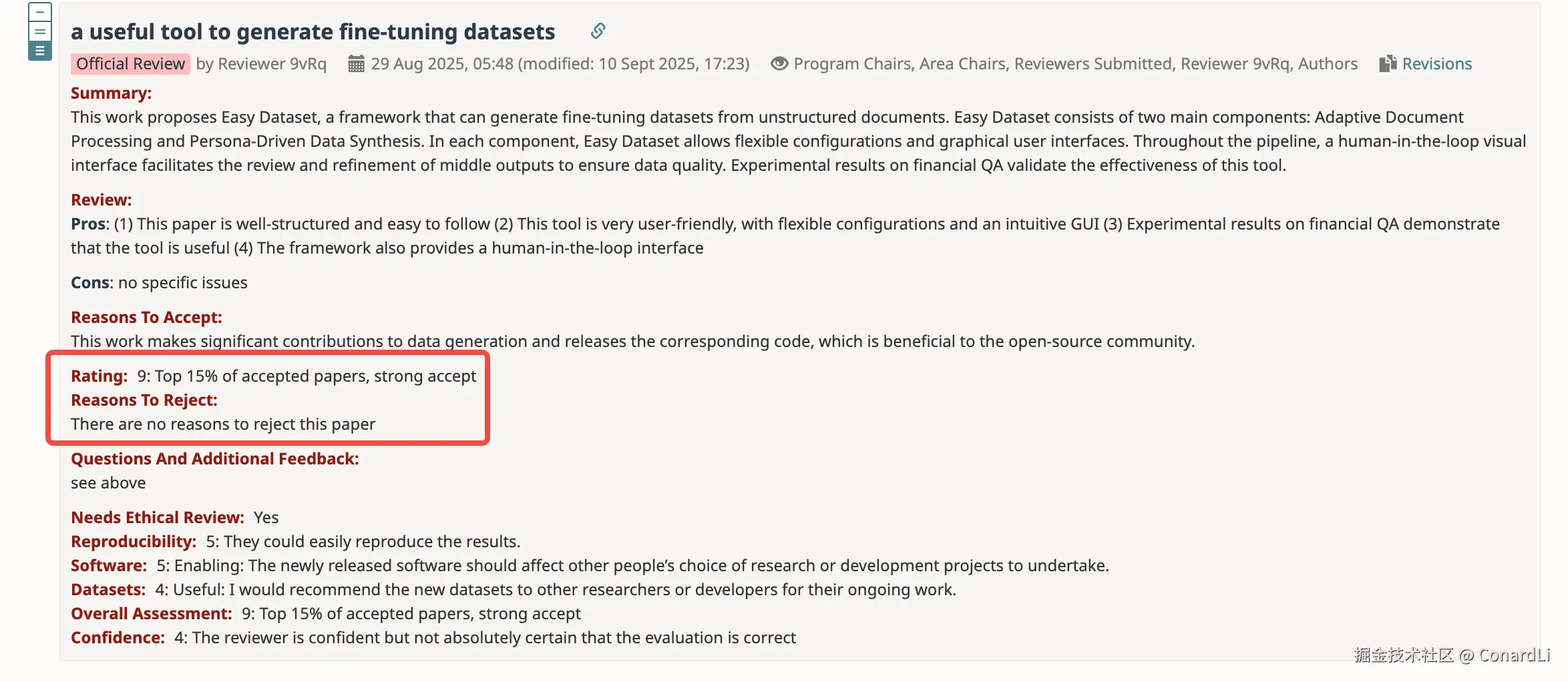
评委对论文及项目给予了很高的评价:
目前 Easy Dataset 的最新版本是 1.6.0,在下面教程中,我会先简单介绍一下最近版本中的新增功能,然后用几个实际的数据集构造案例来说明如何使用这些功能。
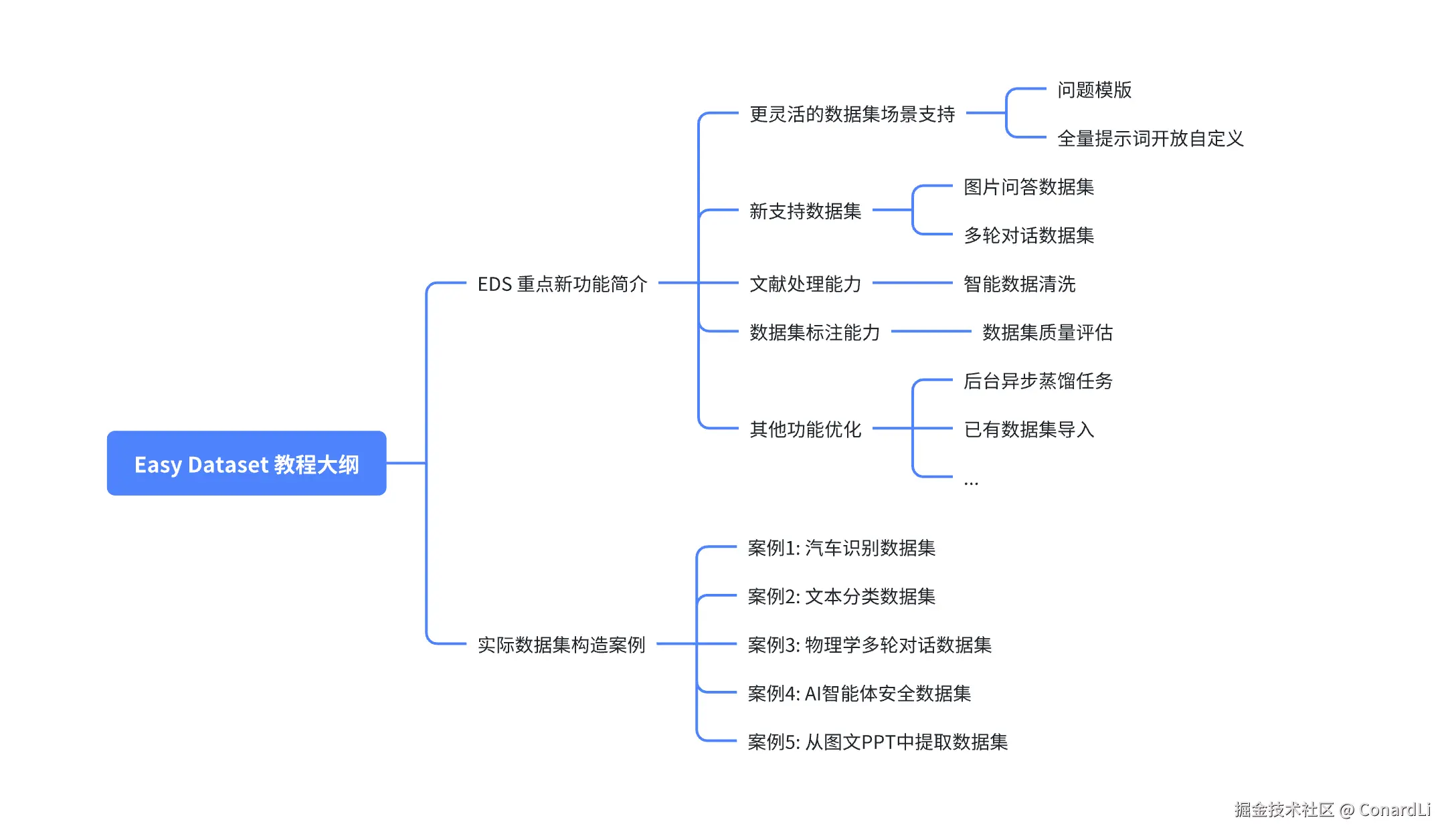
重点更新简介
首先是菜单的改版,原本的文献处理模块被收缩到了新的 "数据源" 模块,并且在此功能上新增了一个 "图片管理" 模块。这代表着 EDS 当前不仅可以支持文本数据一种数据源了,本次对图片新增了支持,并且后续还会支持更多模态。
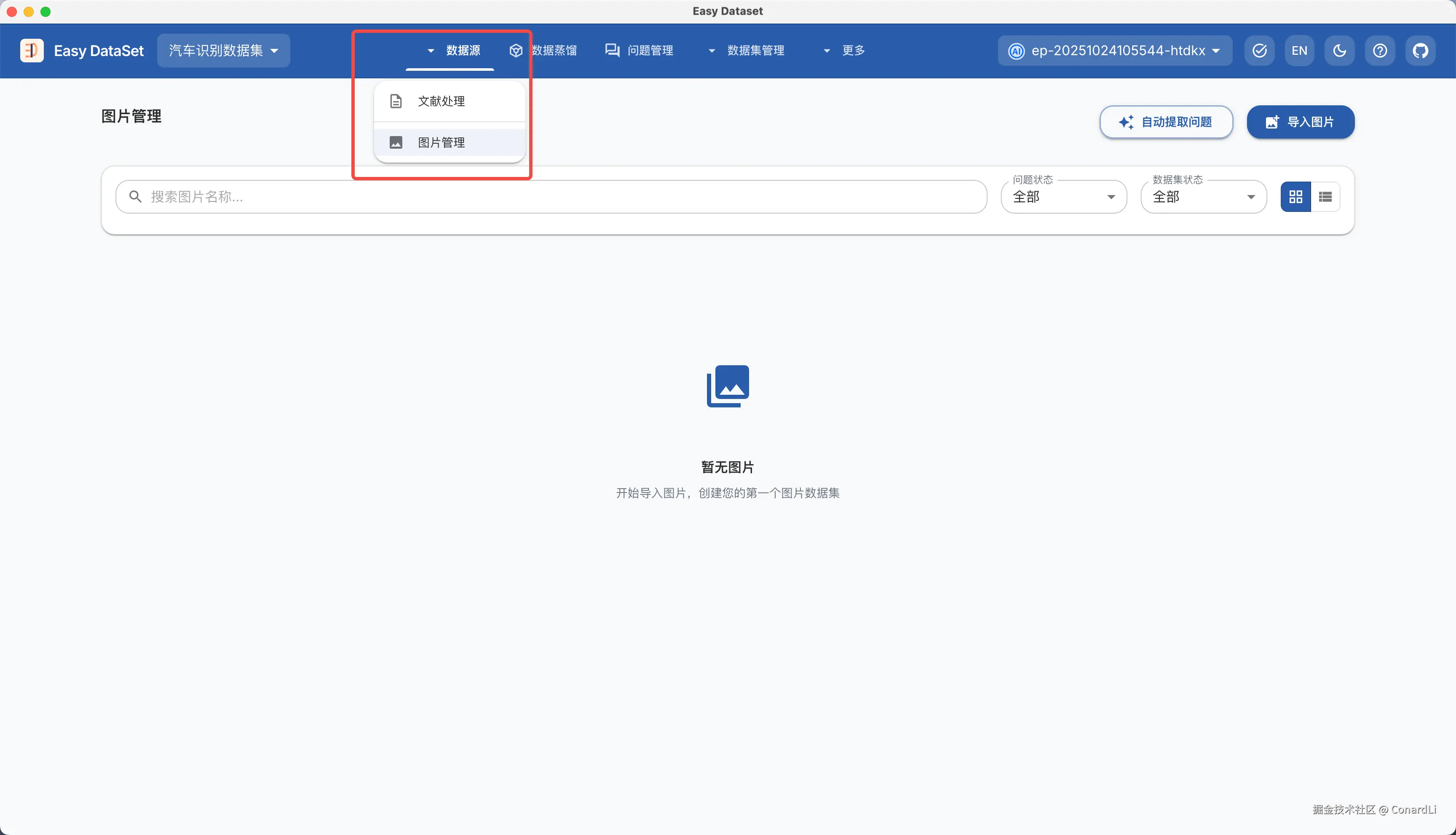
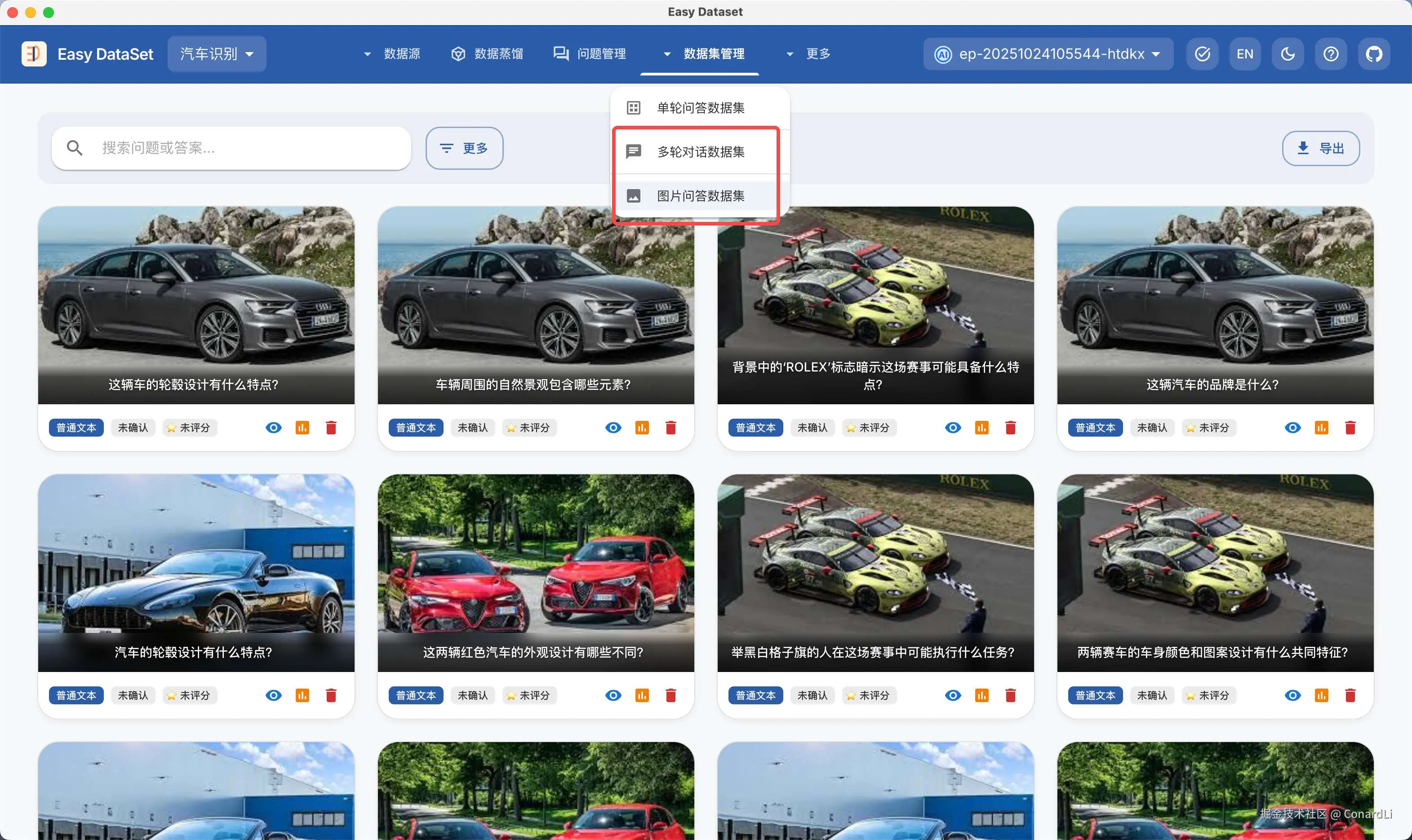
在数据集管理菜单下,除了之前的单轮对话数据集,还新增了多轮对话数据集以及图片问答数据集的支持。
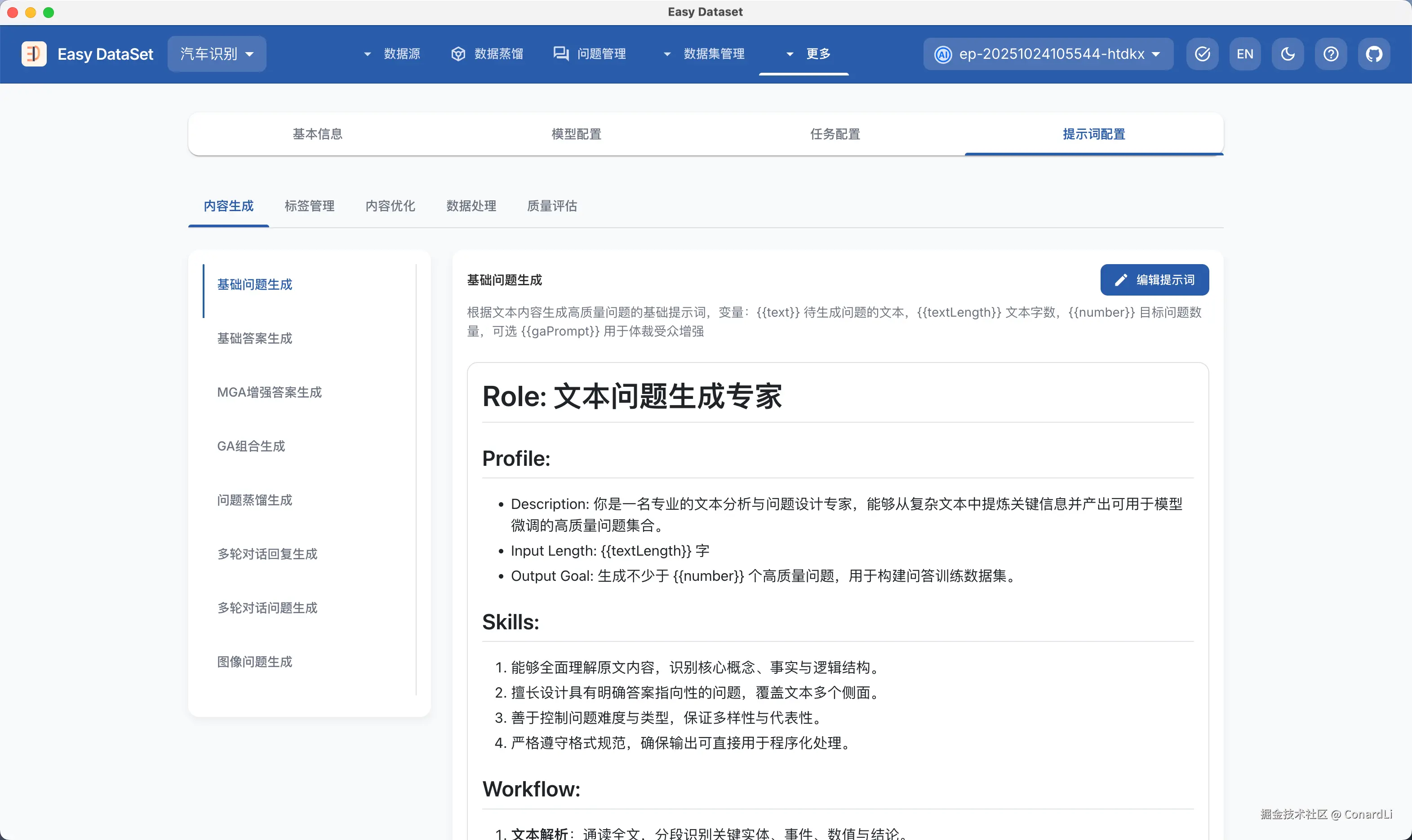
在项目设置模块,我们开放了 EDS 的全量核心默认提示词,你不仅可以清晰的看到 EDS 的每个部分是如何工作的,还能根据自己的需求自由定制这些提示词。
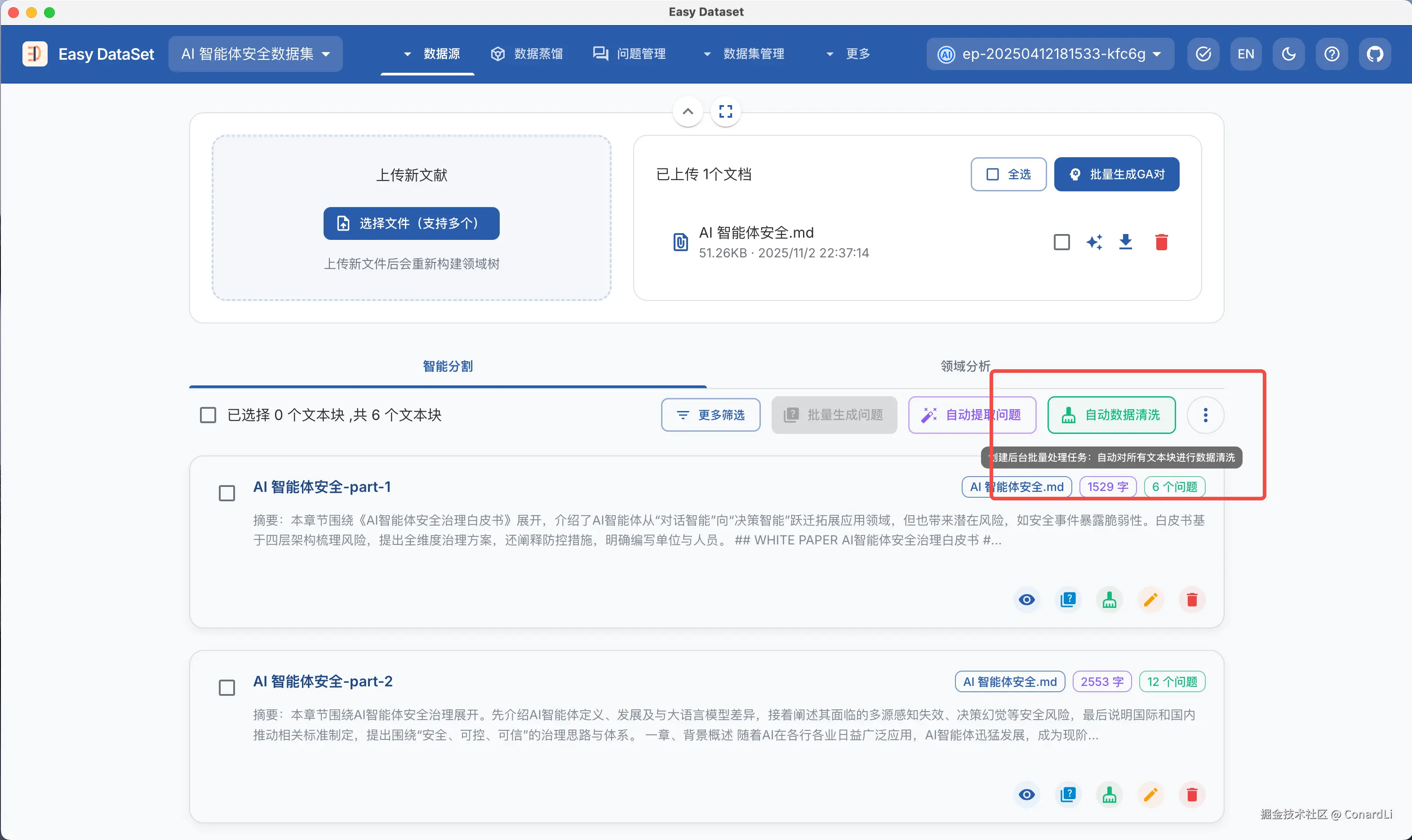
在文献的处理上,我们新增支持了,对文本块进行数据清洗的能力,它可以帮助我们智能识别和清理文本中的噪声、重复、错误等"脏数据",提升数据准确性、可用性,以进一步提升后续生成数据集的质量或 RAG 召回率。
在问题的生成上,我们新增了全新的问题模版功能,他可以帮我们为所有文本块、图片创建固定风格的问题,例如:
- 在汽车图像识别数据集中,我们期望针对所有图片提出同样的问题:"汽车是什么颜色?",然后将答案限定在几个固定的颜色中
- 在情感分类数据集中,我们期望对每个文本块提出同样的问题:"这段文本是正面的还是负面的?",然后将答案限定在 "正面、负面" 两个答案中
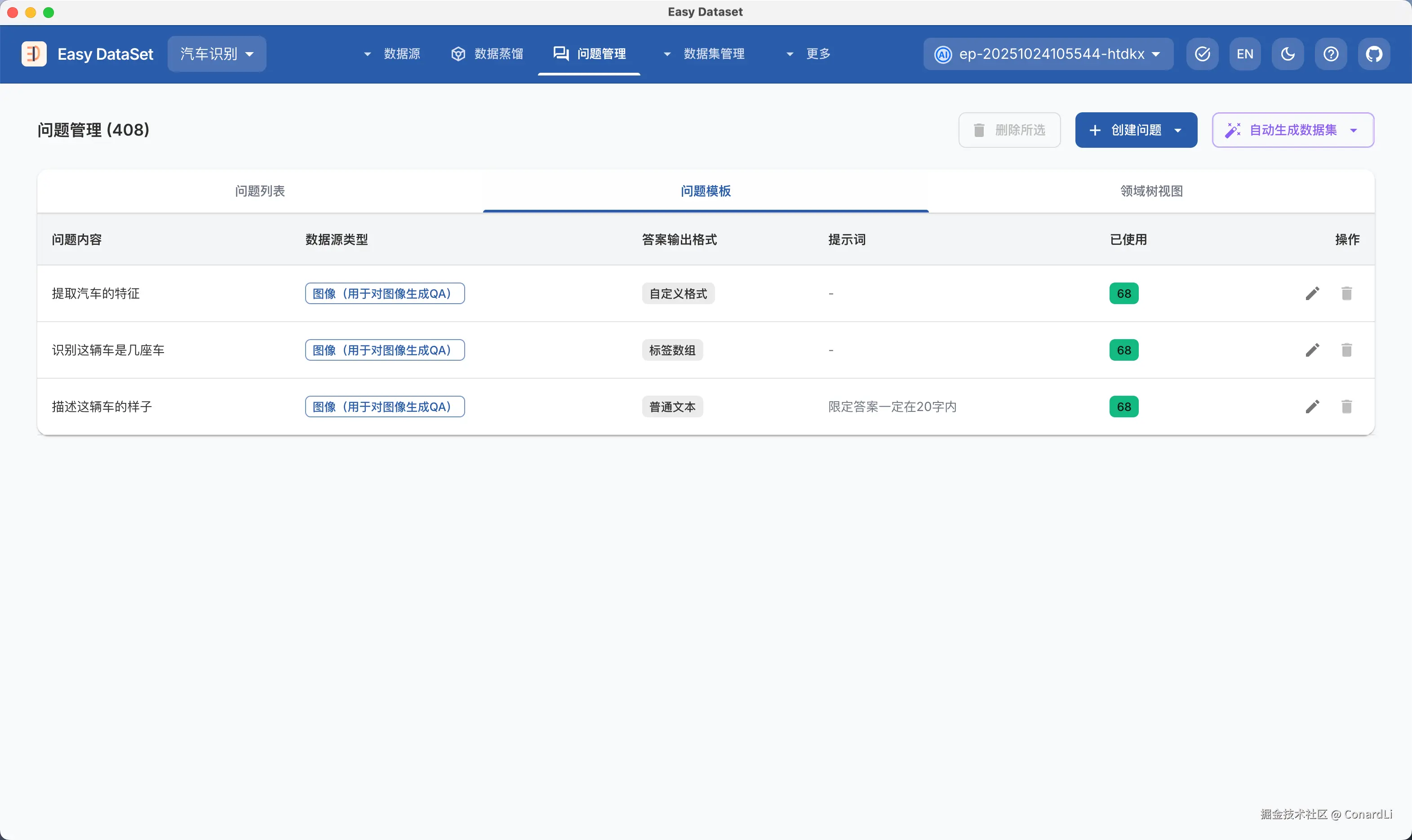
这些需求都可以使用问题模版来实现。
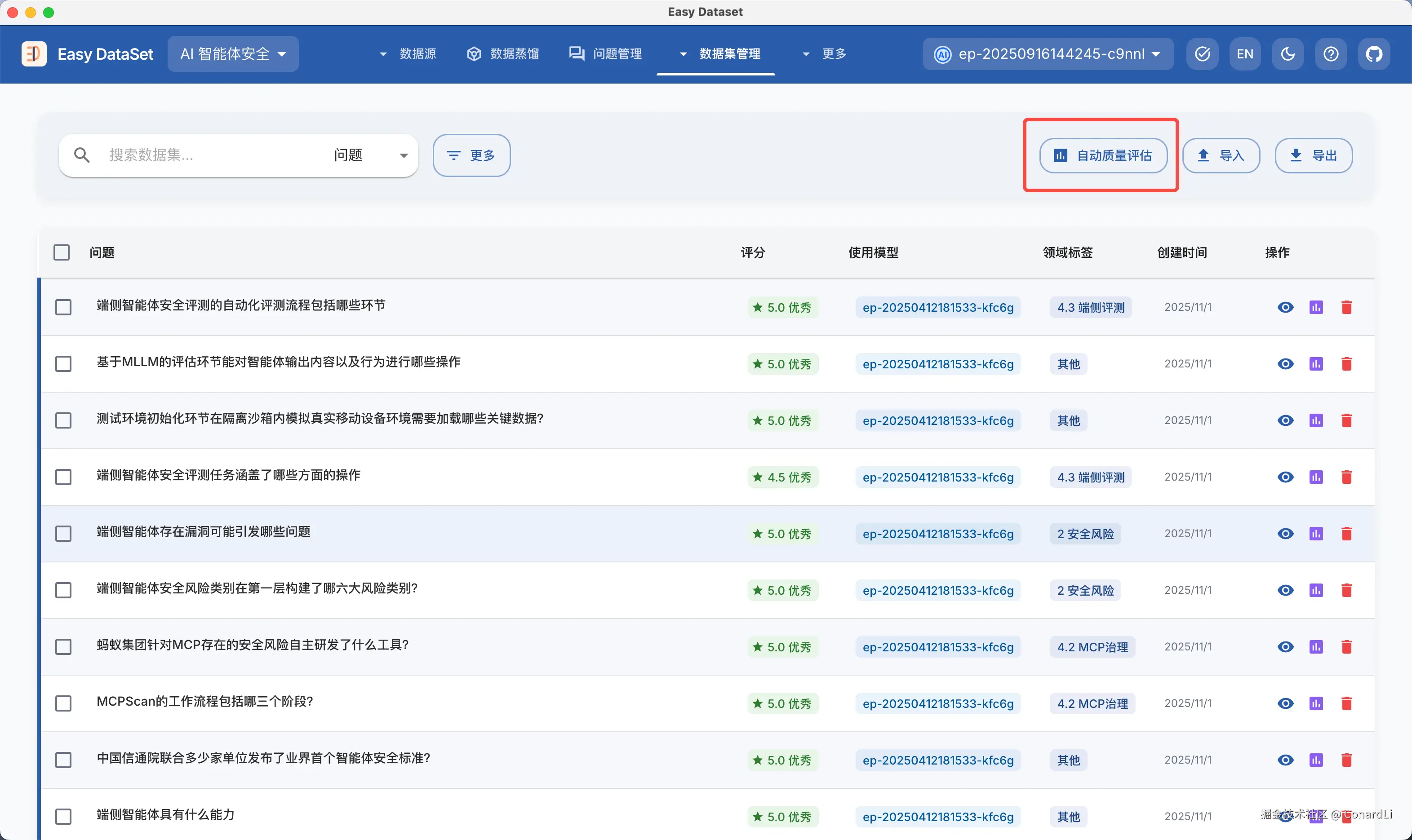
在数据集的标注和评估上,我们支持了对数据集质量的智能评估功能,这项能力可以帮助你更低成本的进行数据集标注和评估工作。
另外,在最新版本中,还支持了导入已有数据集、后台异步运行蒸馏任务、本地 MinerU、新的数据集导出格式等多项功能优化。
下面我们用五个实际的数据集构造案例来带大家了解如何使用这些功能。
实际案例1:生成汽车图片识别数据集
VQA 数据集(Visual Question Answering Dataset)是用于多模态模型训练 / 微调的核心数据集合,核心包含 "图像 + 对应自然语言问题 + 标准答案" 三部分,目的是让模型学会结合图像视觉信息与语言理解能力,准确回答关于图像内容的问题。
例如下面就是一个最简单的 VQA 数据集案例:

目标场景:已有一批各种汽车的图片,希望创建一组针对汽车特征进行识别的数据集,用于训练车辆识别模型。
首先进入【数据源 - 图片管理】模块,点击右上角导入图片,这里我们将需要生成数据集的图片目录输入进去(本机的绝对路径):
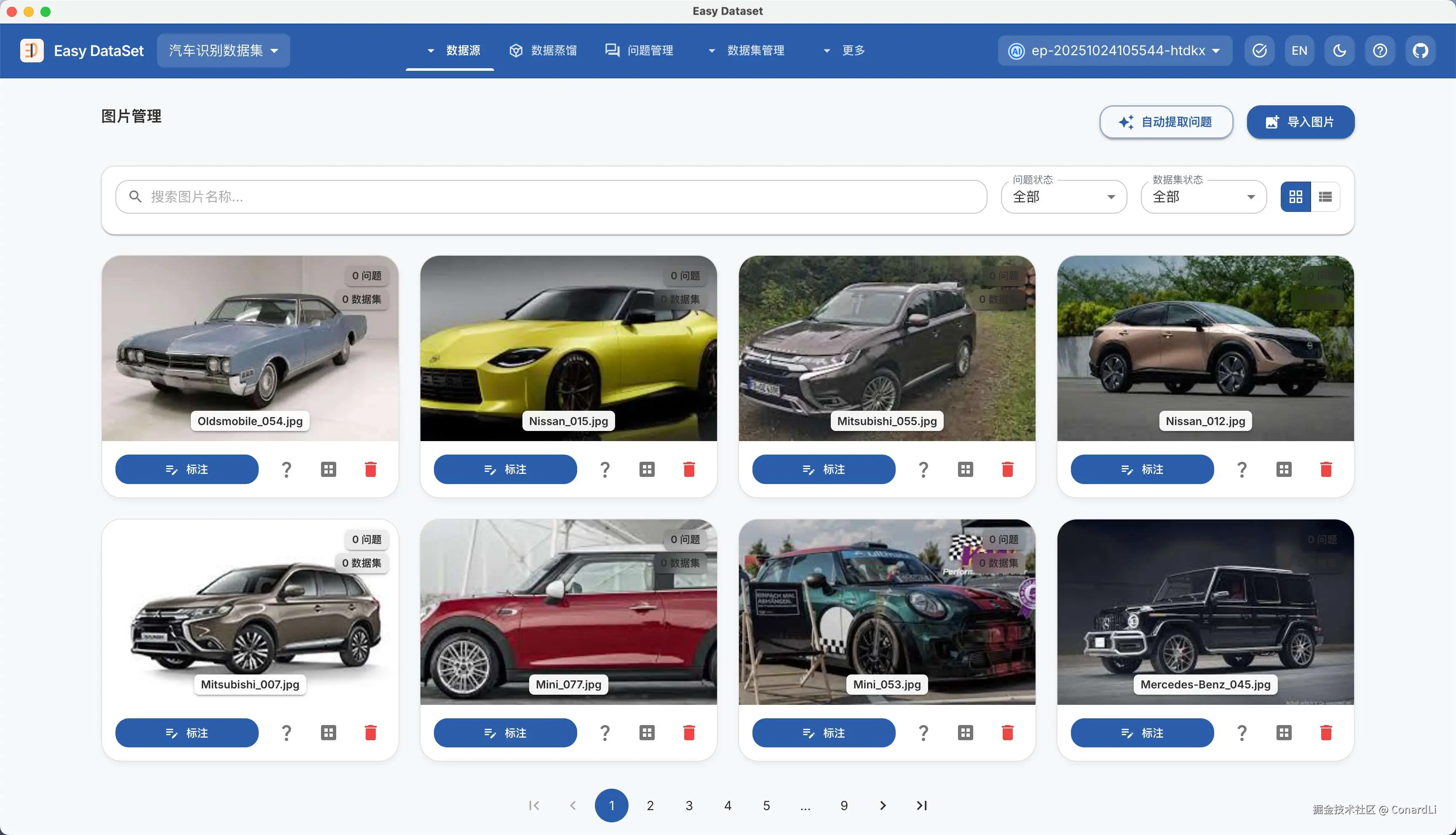
导入完成后,图片会加载到当前项目目录下,然后我们将看到所有图片:
我们可以点击单个图片的生成问题,让 AI 智能根据图片识别问题:
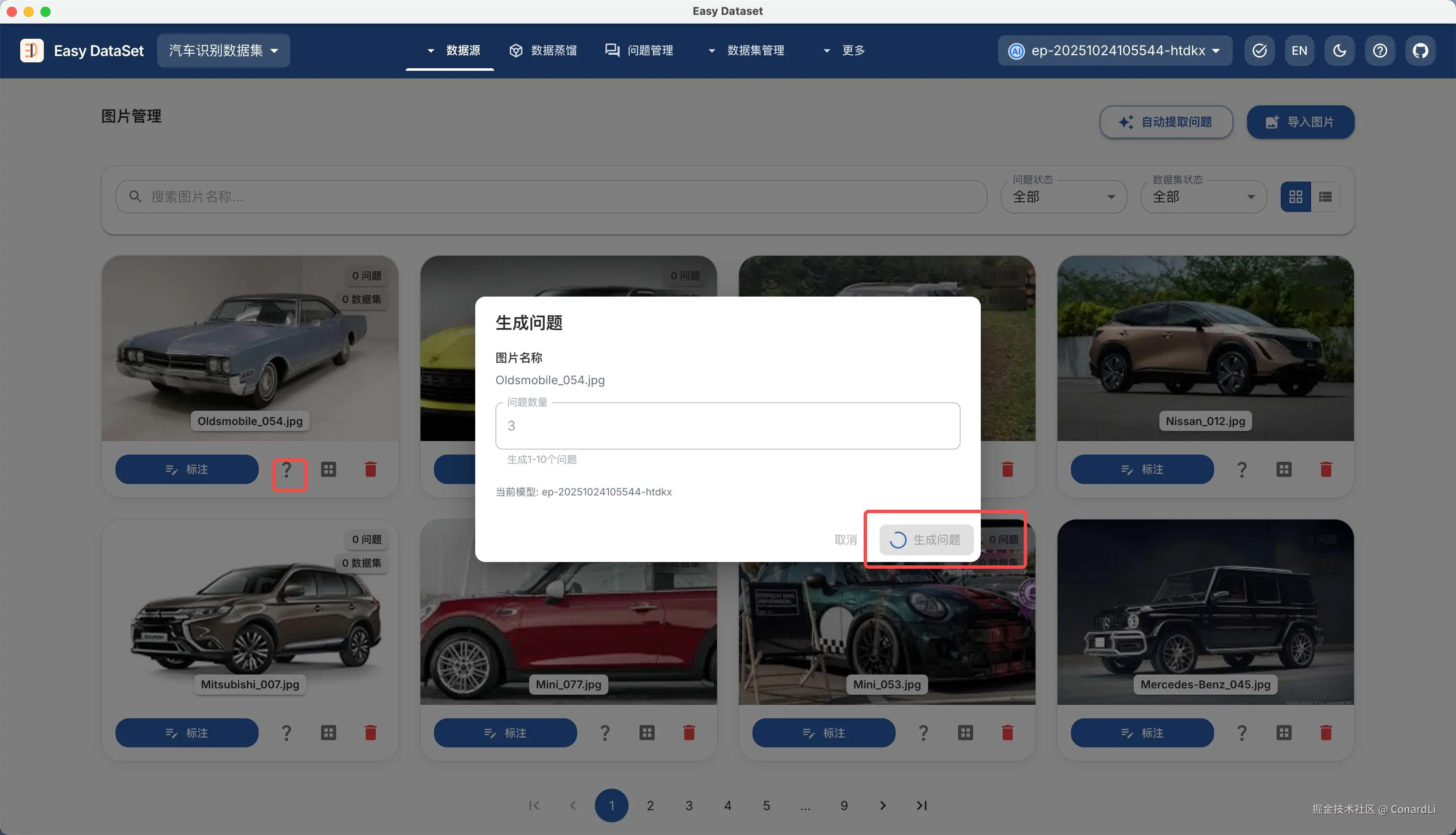
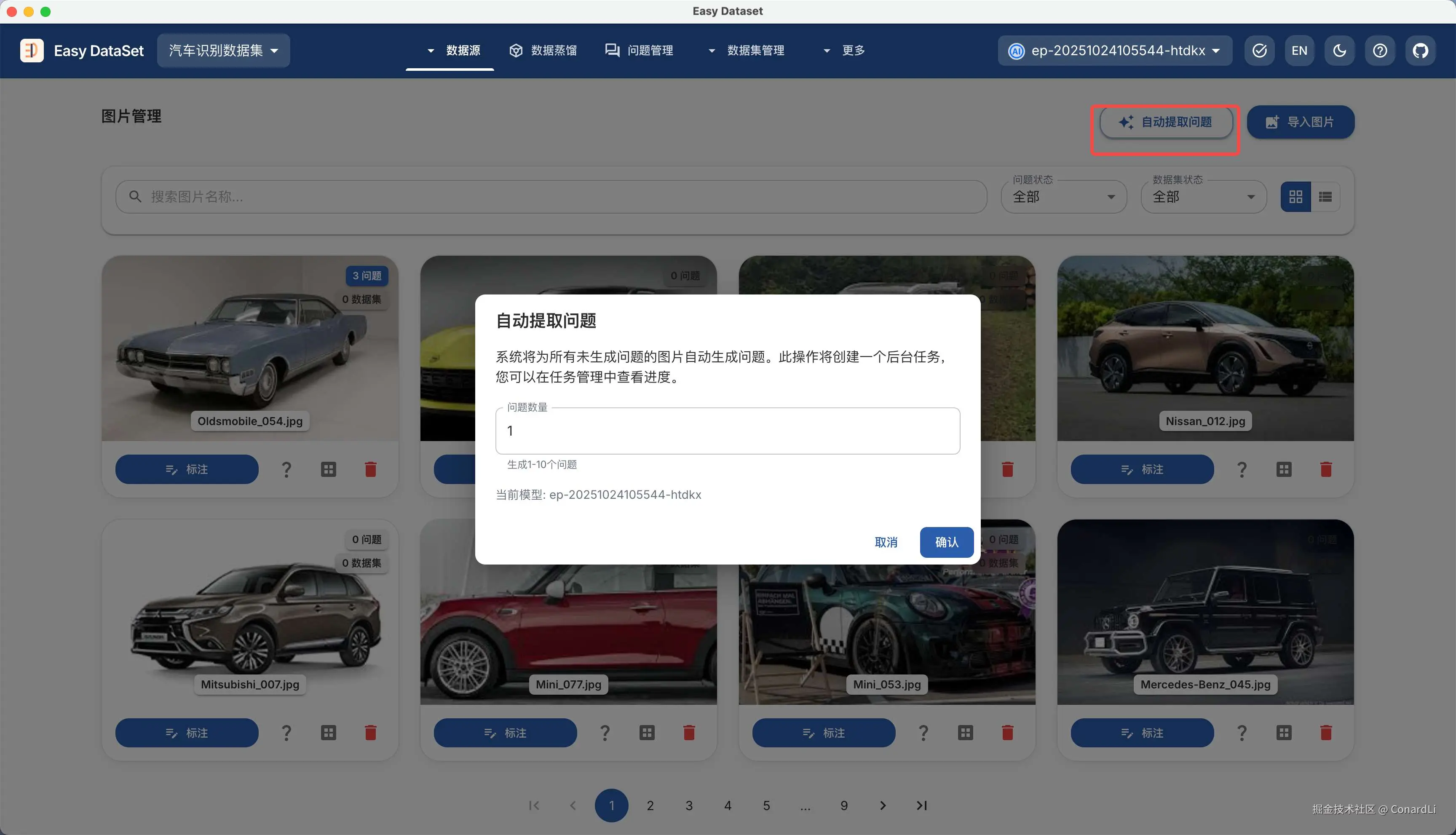
也可以点击右上角的自动提取问题,这将创建一个后台批量任务,自动为没有生成问题的图片来生成问题:
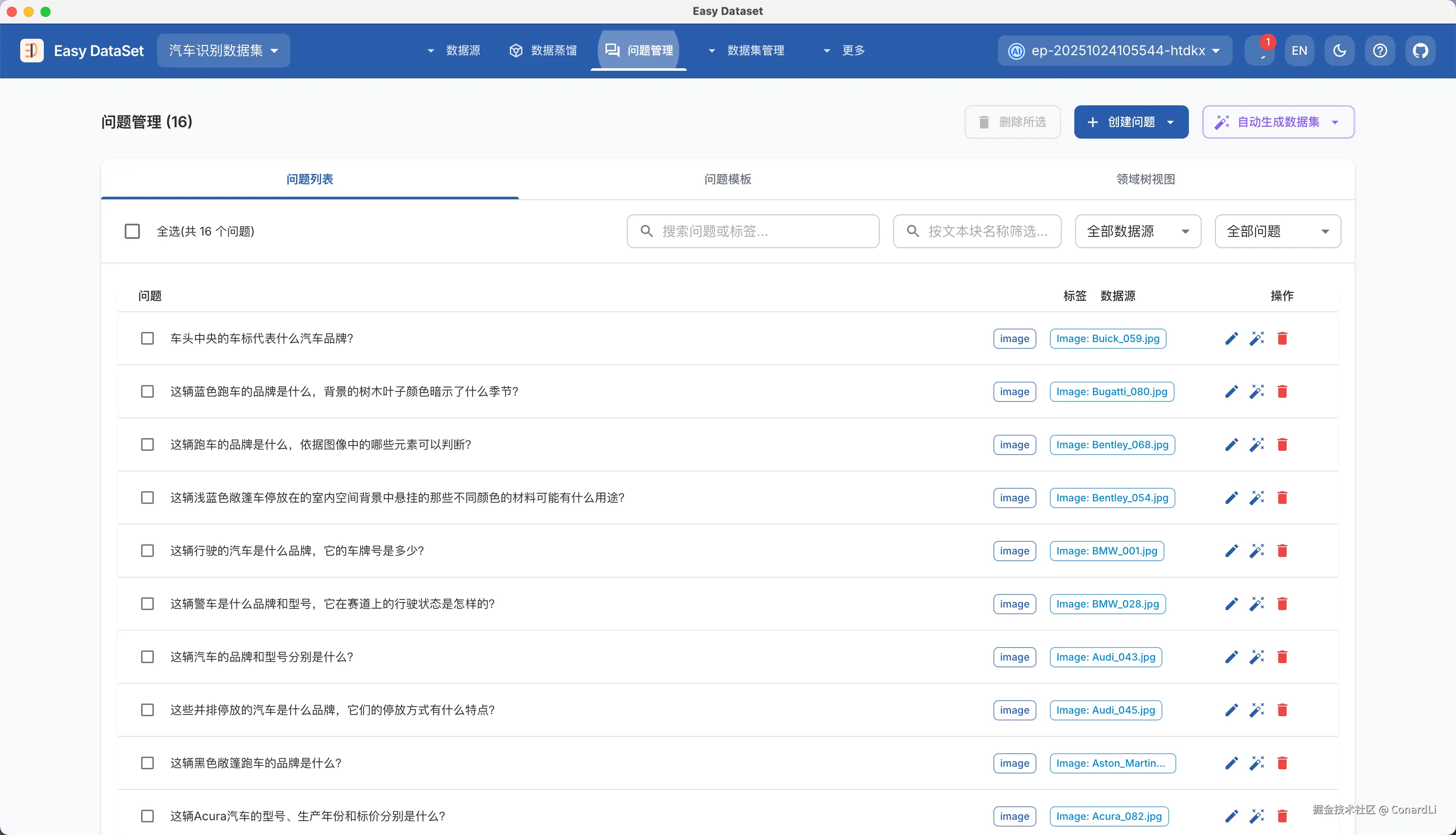
进入问题管理模块可以看到所有已经生成的问题,和普通问题的区别是数据源属性,普通问题关联的是文本块,而图片问题关联的是一张具体的图片:
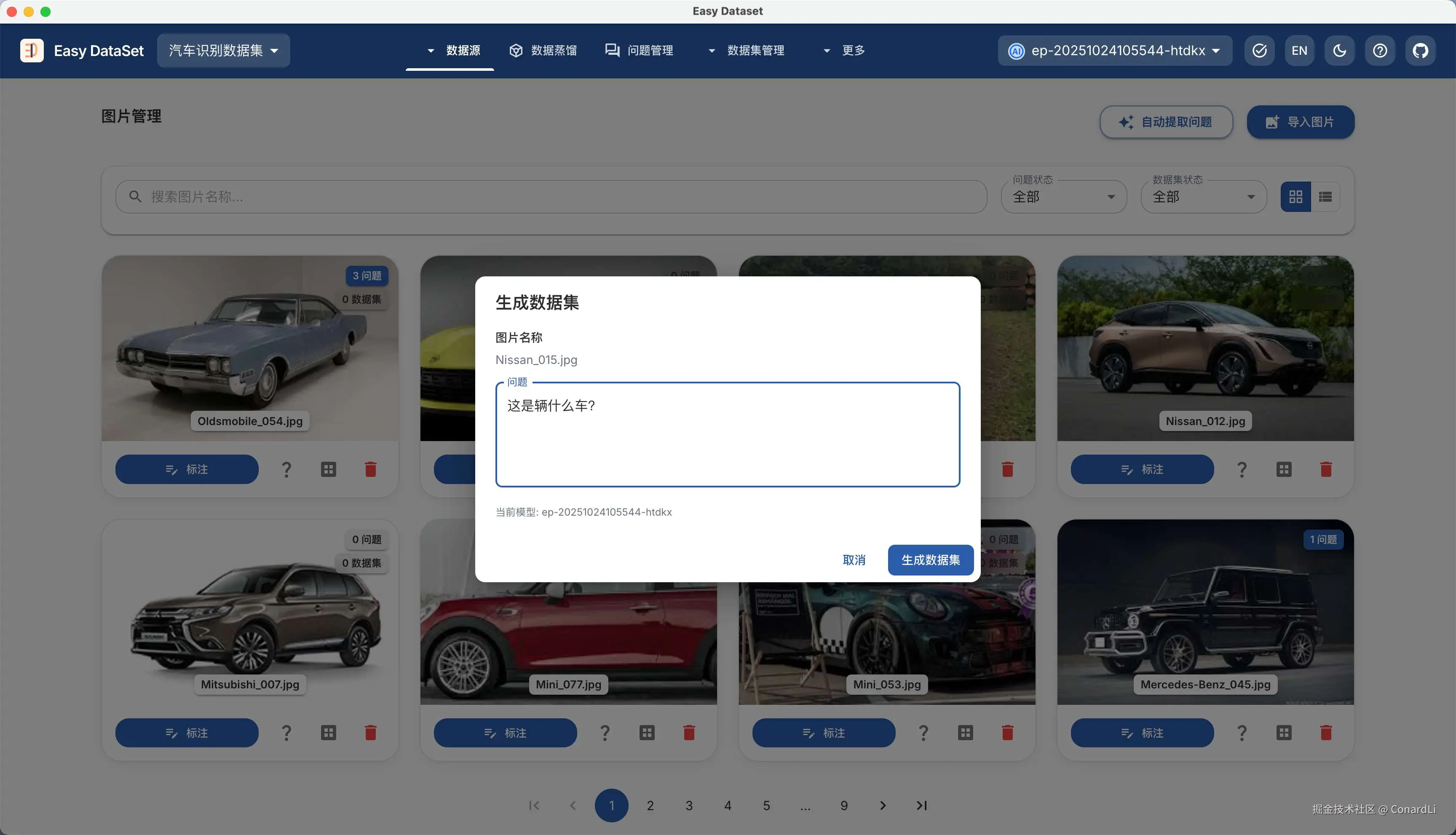
回到图片管理模块,我们可以直接针对某张图片进行提问,让 AI 直接生成答案:
也可以点开智能标注模块,手动标注或让 AI 辅助生成已经创建好的问题对应答案:
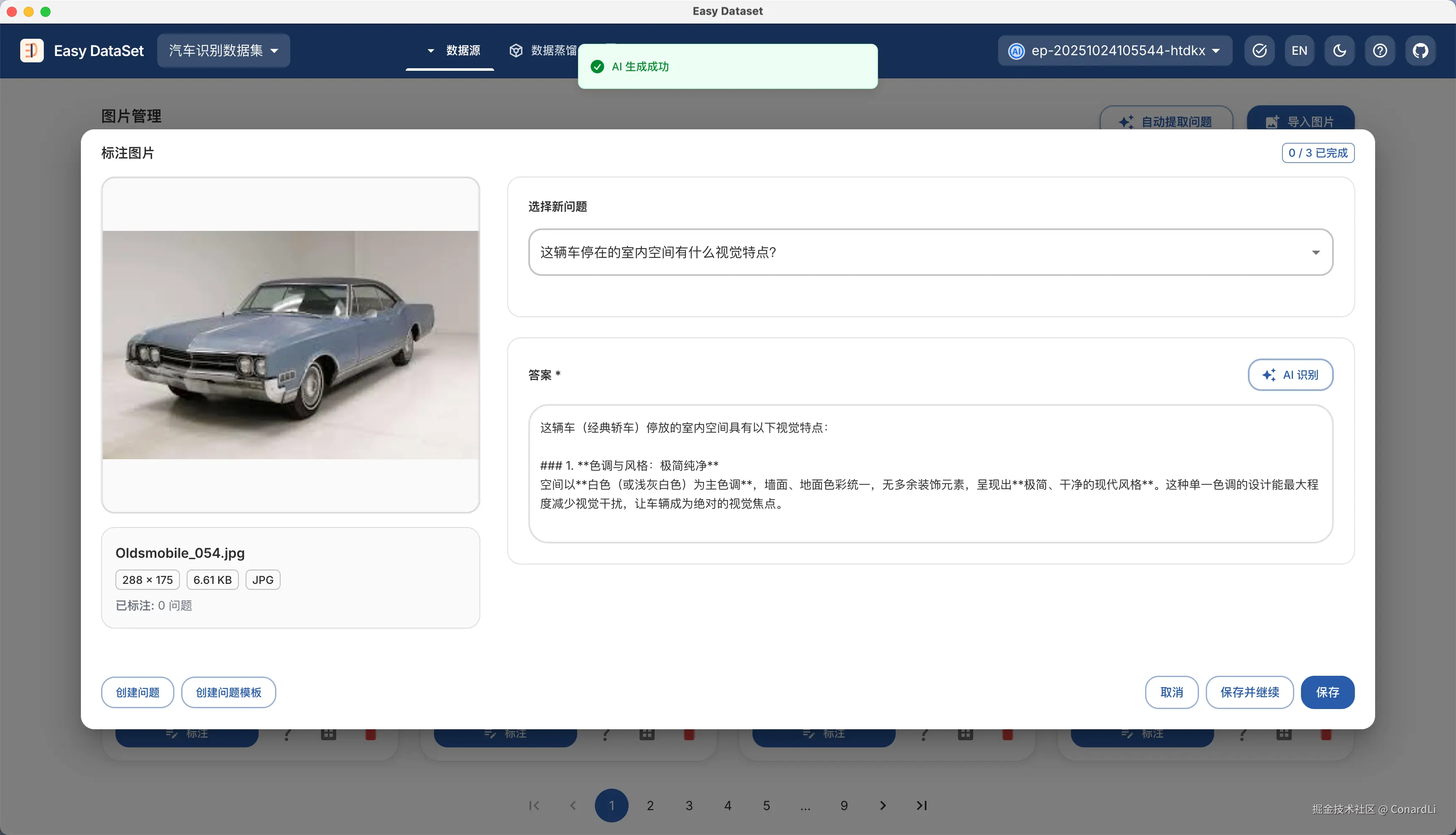
在标注模块我们可以快捷创建问题和问题模版,目前支持三种不同的问题模版:
- AI 生成的答案是普通文本
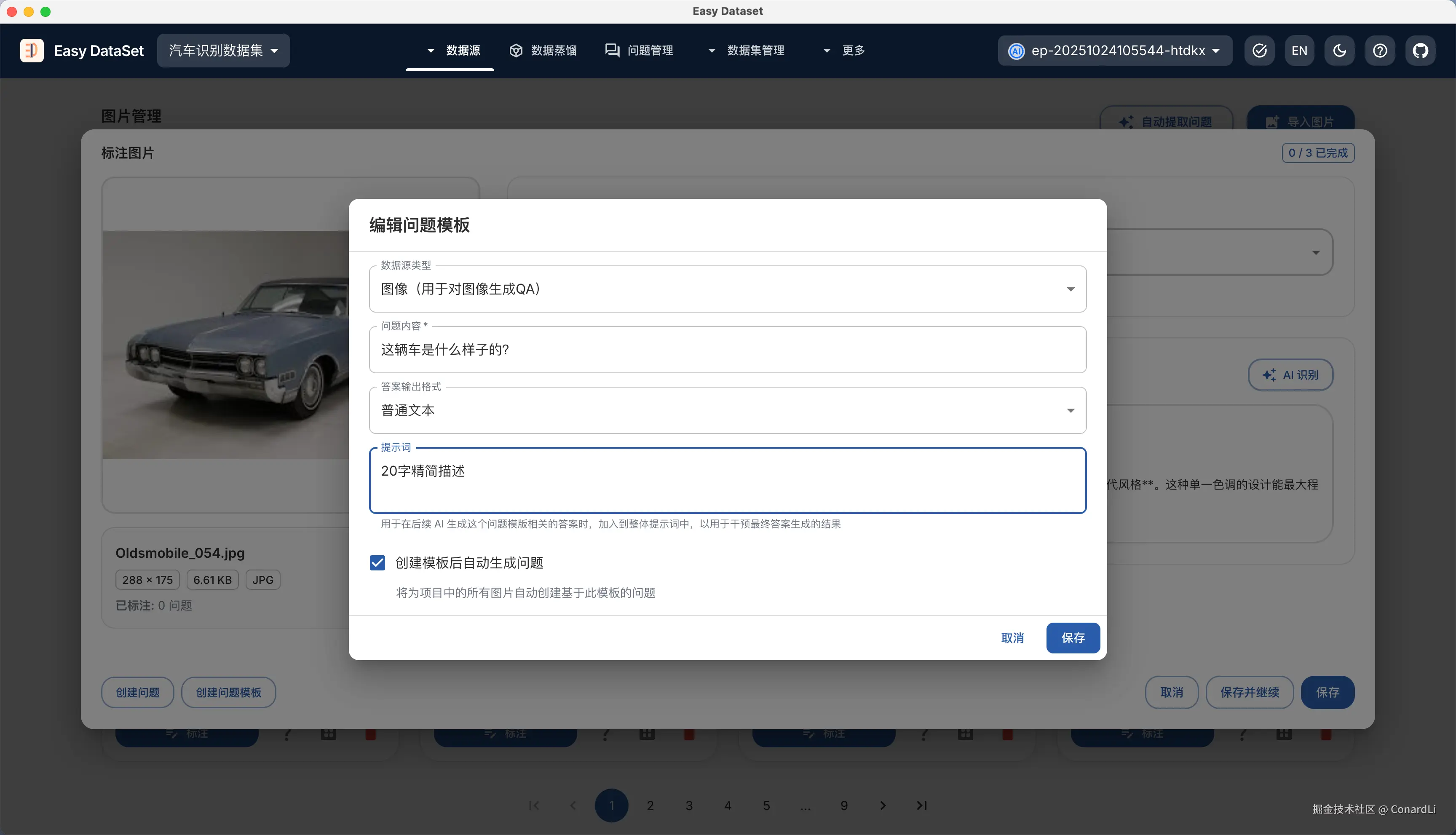
例如:描述这辆车的样子;我们可以通过问题模版的提示词来控制最终答案的预期效果,例如答案必须限定在 20 字内
- AI 生成的答案限定在一些标签下
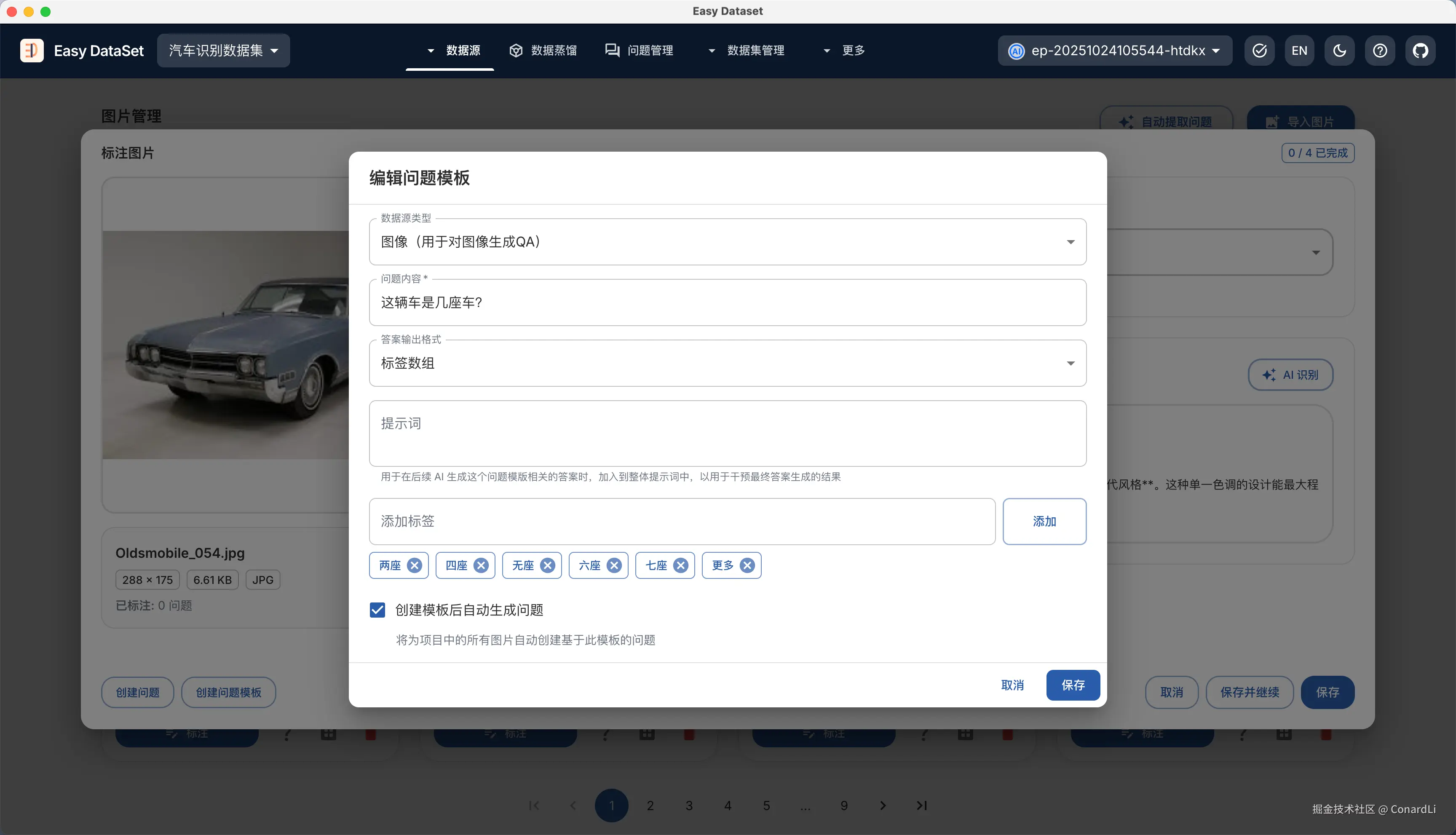
例如:识别汽车是几座车时,一定要限定在固定的几个座位里,避免 AI 冗余输出
- AI 生成的答案固定为某种结构:
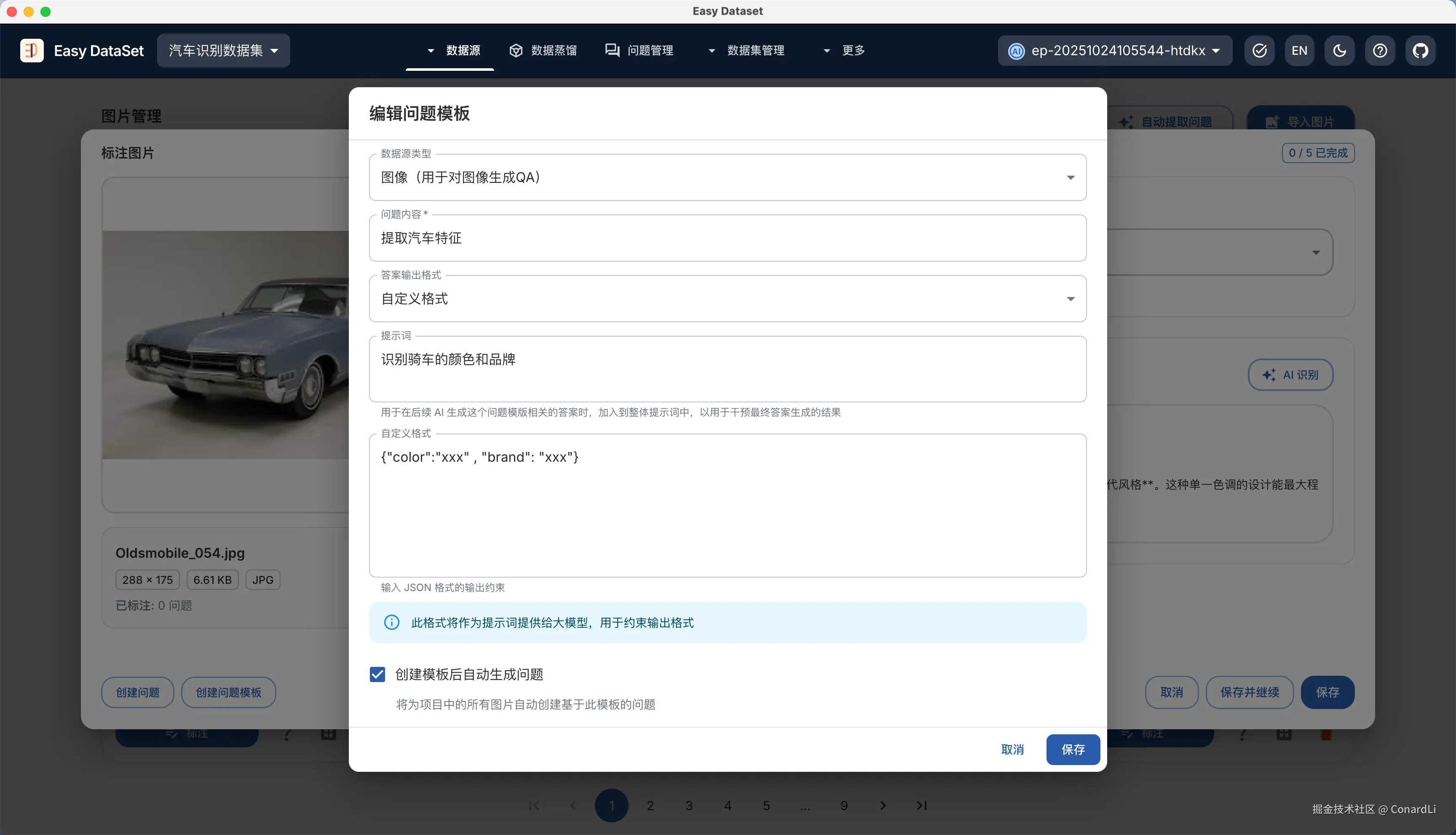
例如:提取汽车的更多特征,可能有多个固定的特征需要提取,我们可以自定义模型输出的 JSON 结构,一定要限定在 color、brand 两个字段上,这样每次识别的答案只会包含汽车品牌和颜色数据。
注意:创建问题模版后,会为当前所有图像均创建一个对应问题。
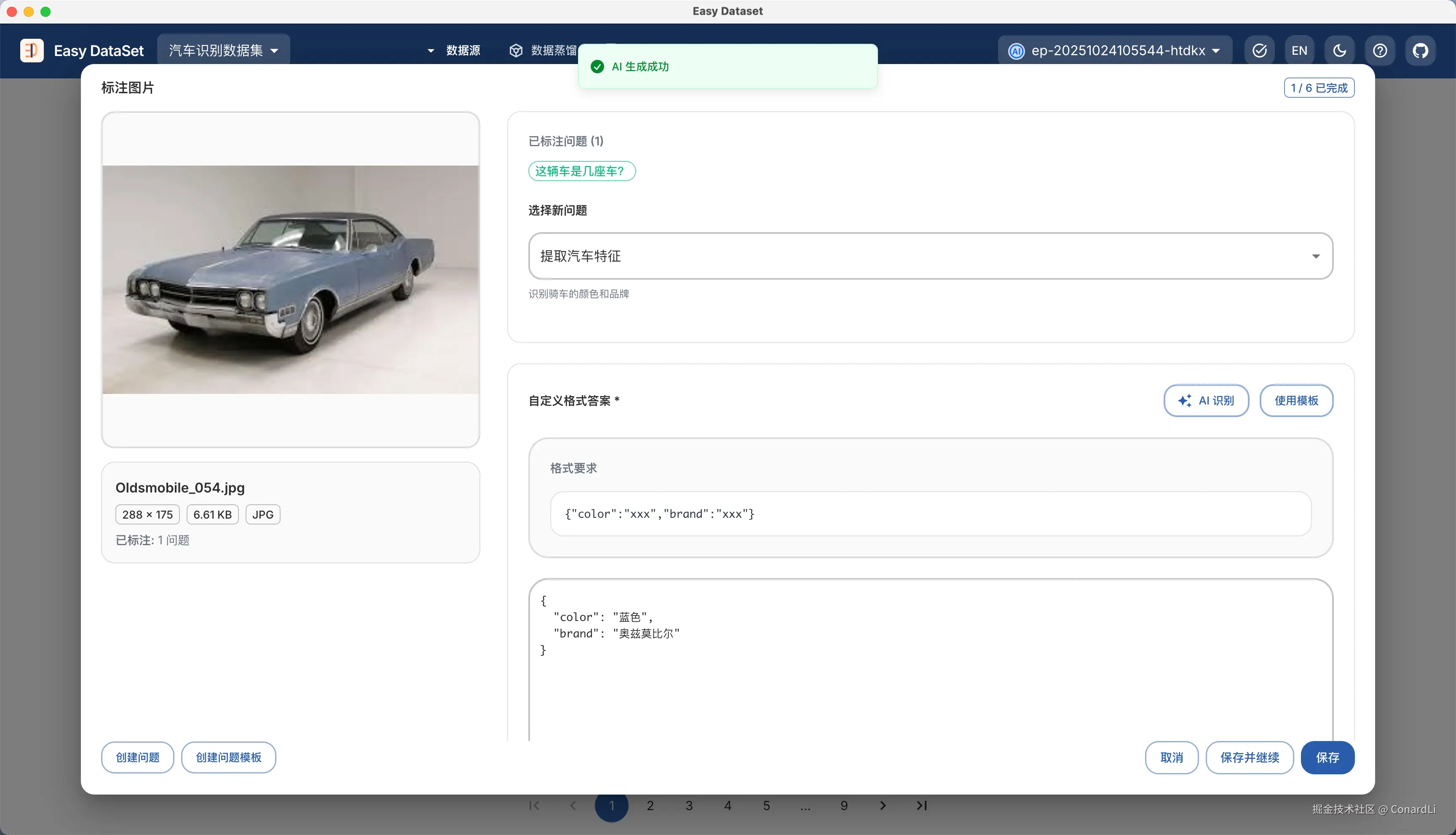
模版创建完成后,我们可以继续在标注界面手动标注这些问题,也可以让 AI 智能生成答案,根据问题模版的不同类型,将会有不同的标注形态:
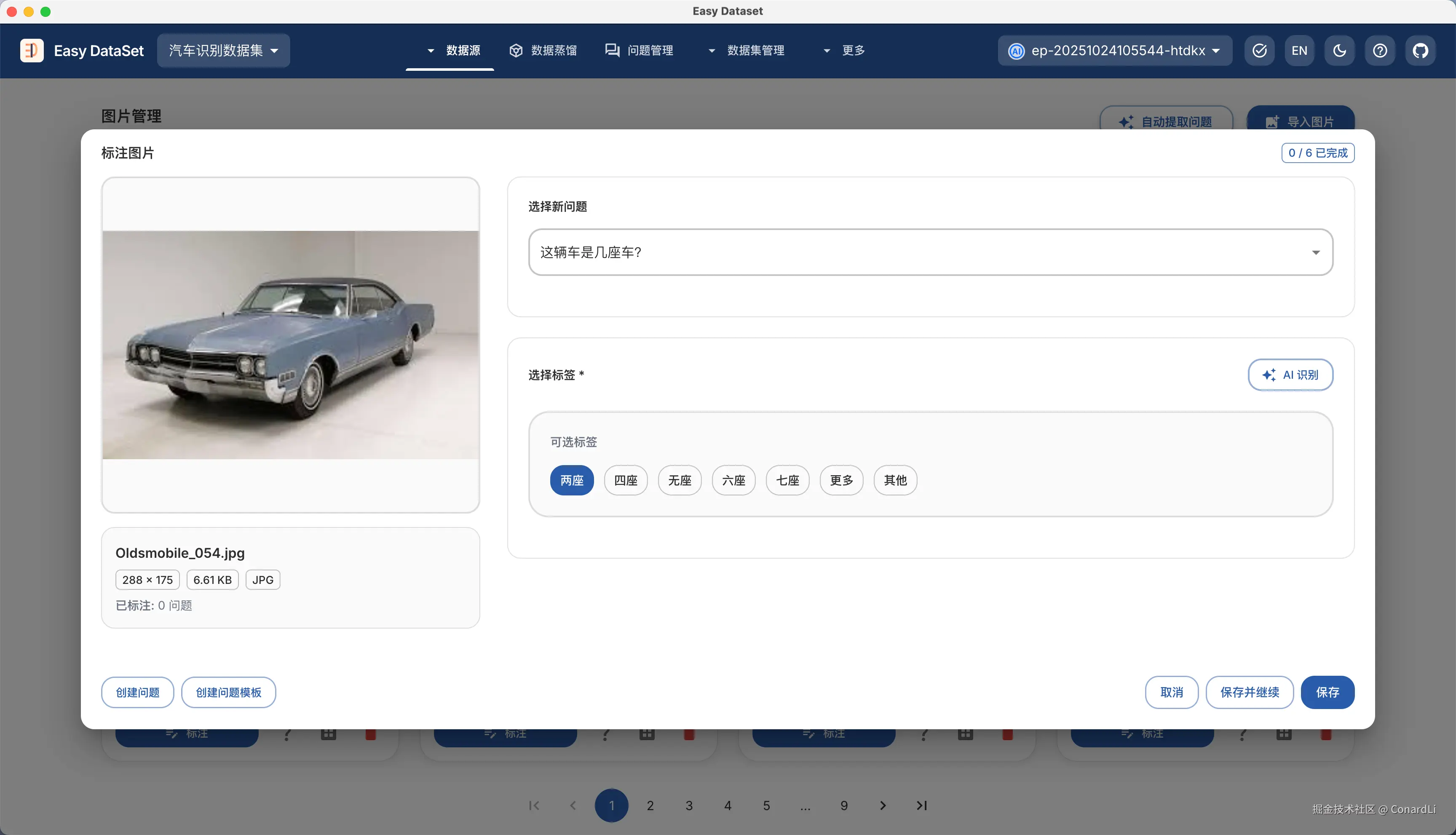
标注完成一个后,我们可以点击保存并继续,AI 将自动查找下一个还未完成标注的图片或问题:
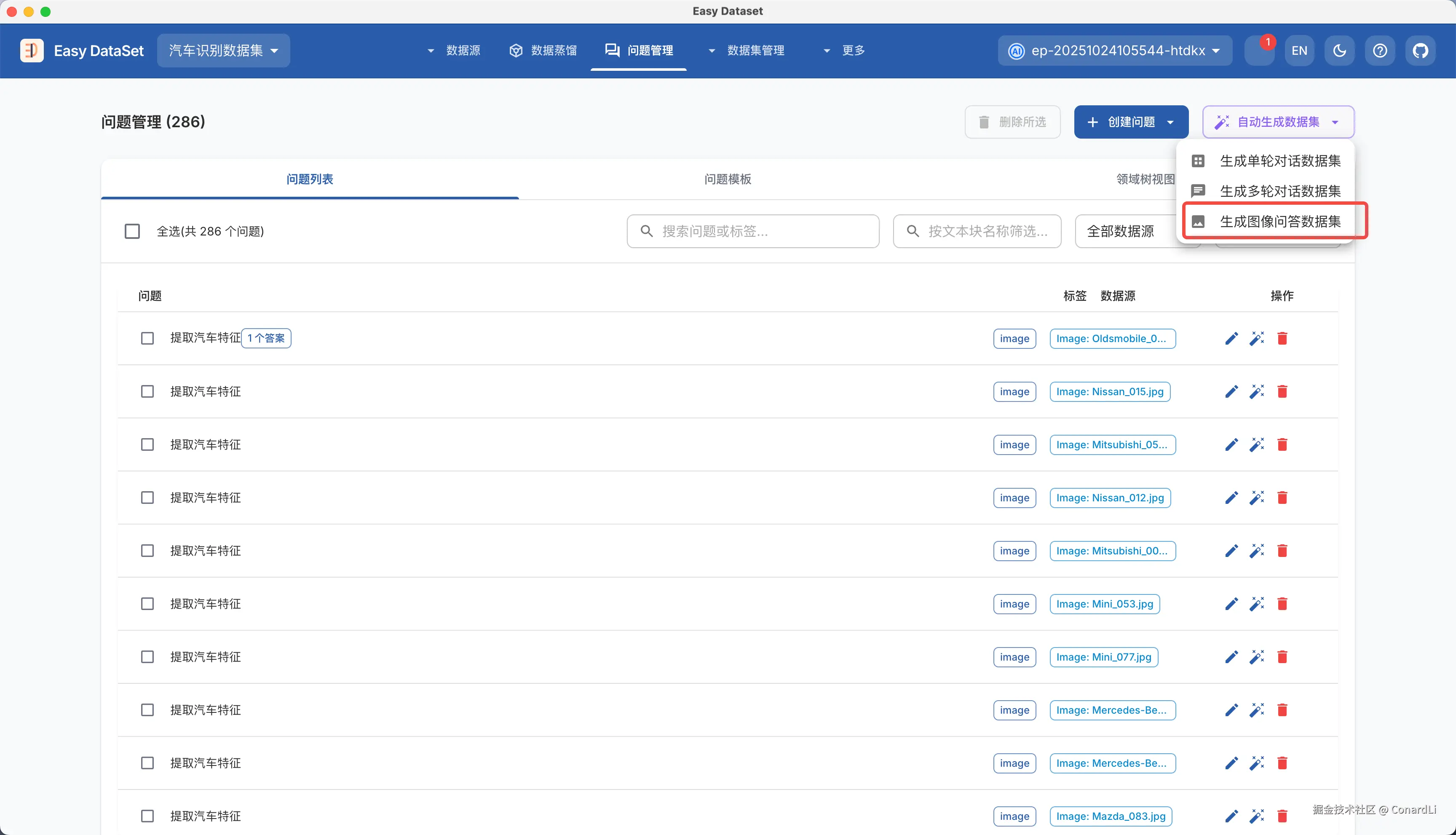
如果嫌手动标注太慢,可以到问题管理模块,点击自动提取数据集 - 生成图像问答数据集,这会自动创建一个后台异步任务:
随后,来到图片数据集管理模块,我们可以看到已经生成好的数据集:
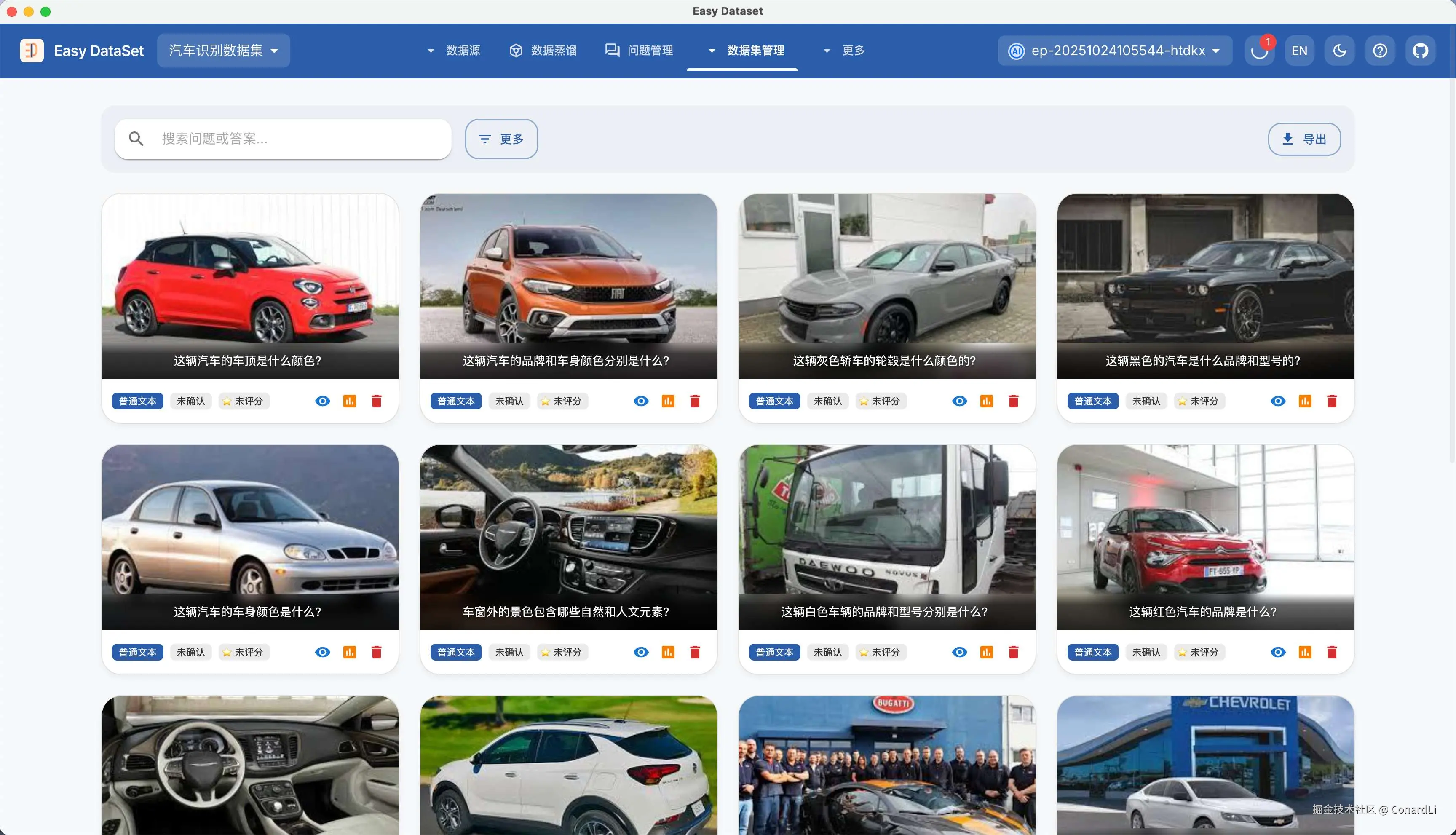
点击数据集详情,可以对答案进行更改,自定义评分、自定义标签、备注等标注操作:
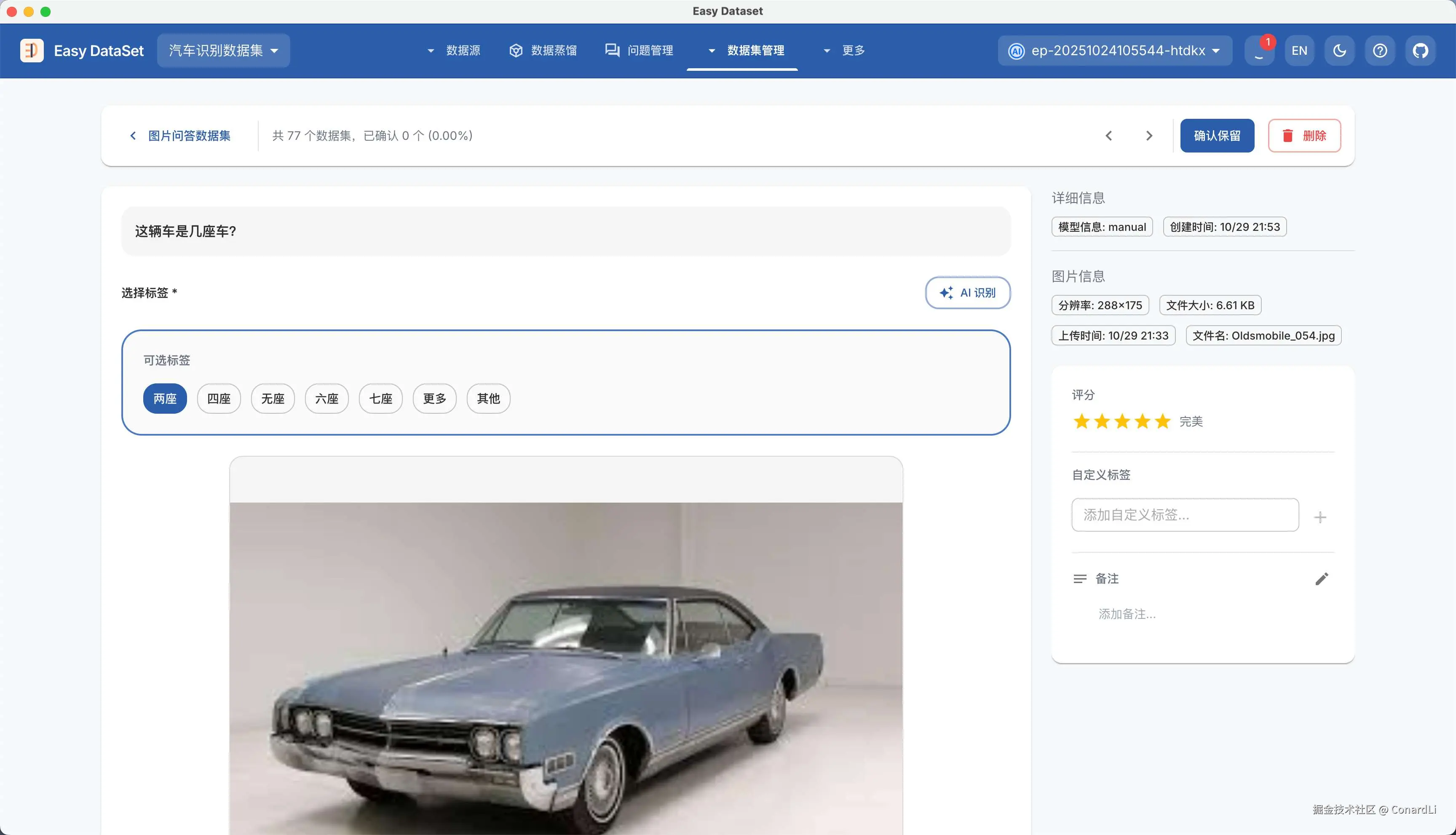
图像数据集导出依然支持多种格式(可选择是否同时导出图片,以及是否在数据集中携带图片路径):
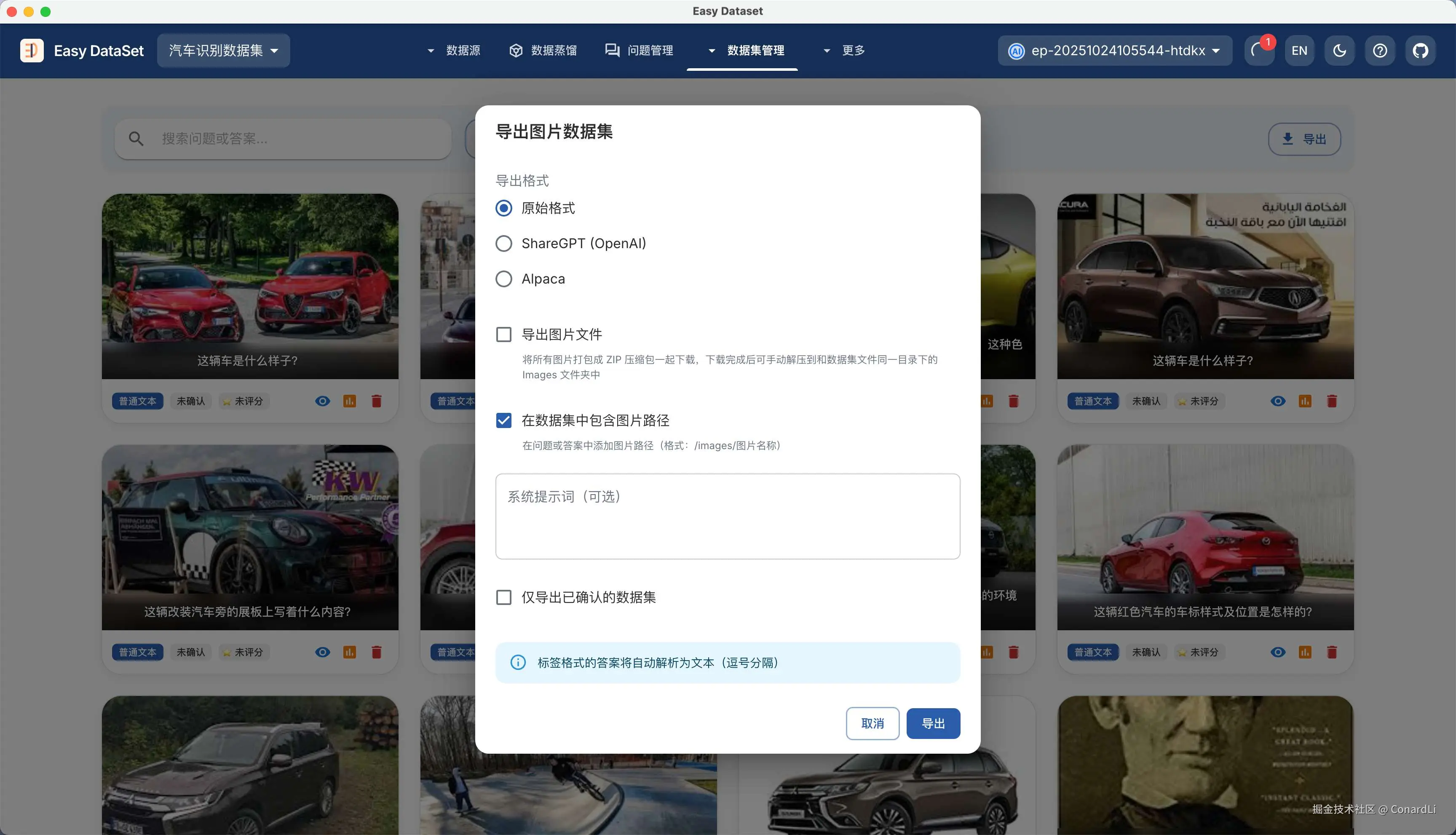
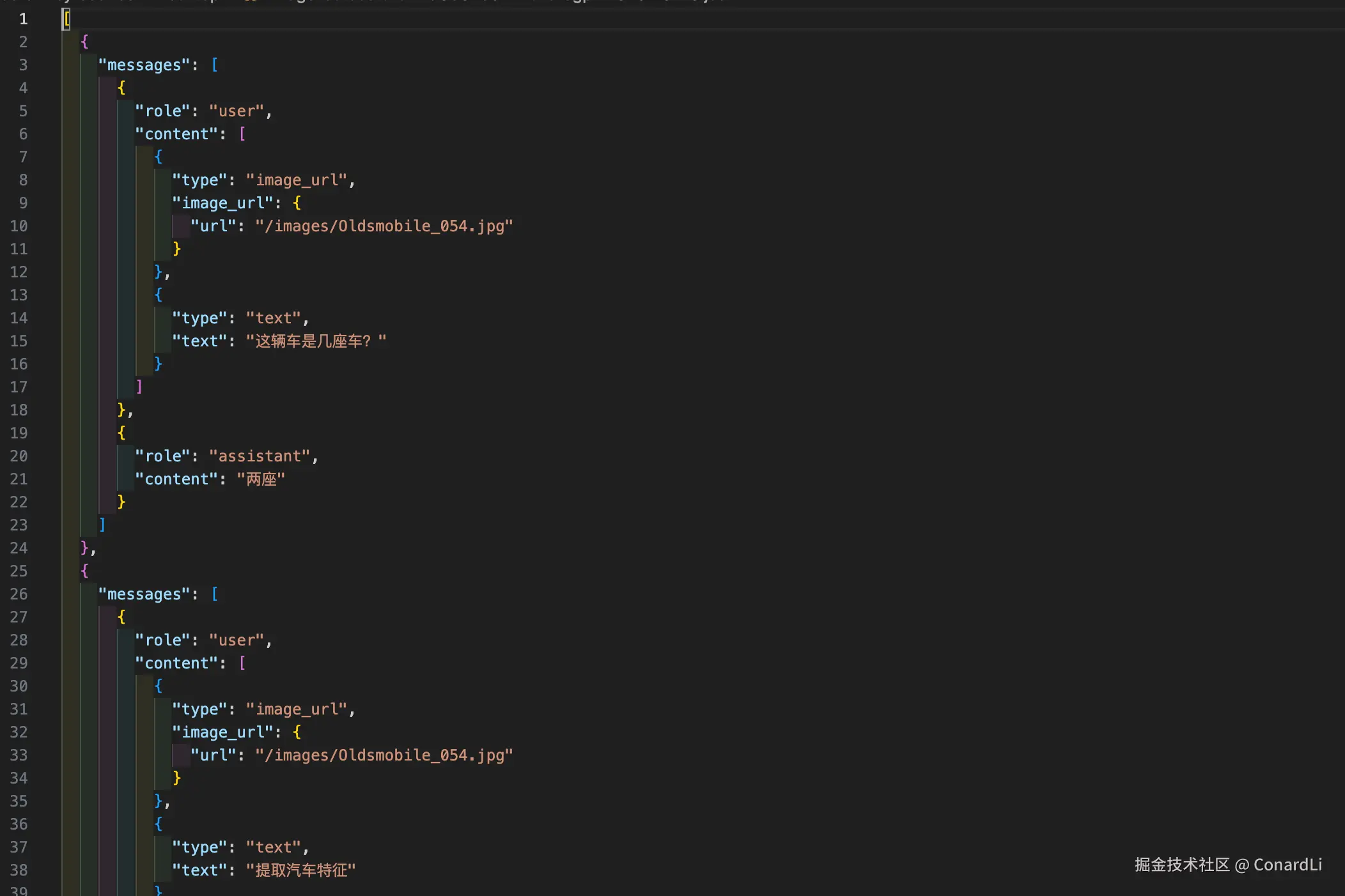
导出的数据集案例:
实际案例2:文本分类数据集
在刚刚的场景中,我们已经使用过问题模版了,这一个非常灵活的功能,它也可以用在文本数据集上,我们来具一个构造文本分类数据集的例子。
目标场景:现有一份微博评论数据,希望基于大模型分析评论是正面还是负面的,用于训练情感分类模型。
数据示例:使用固定的 -------- 分隔符进行分割:

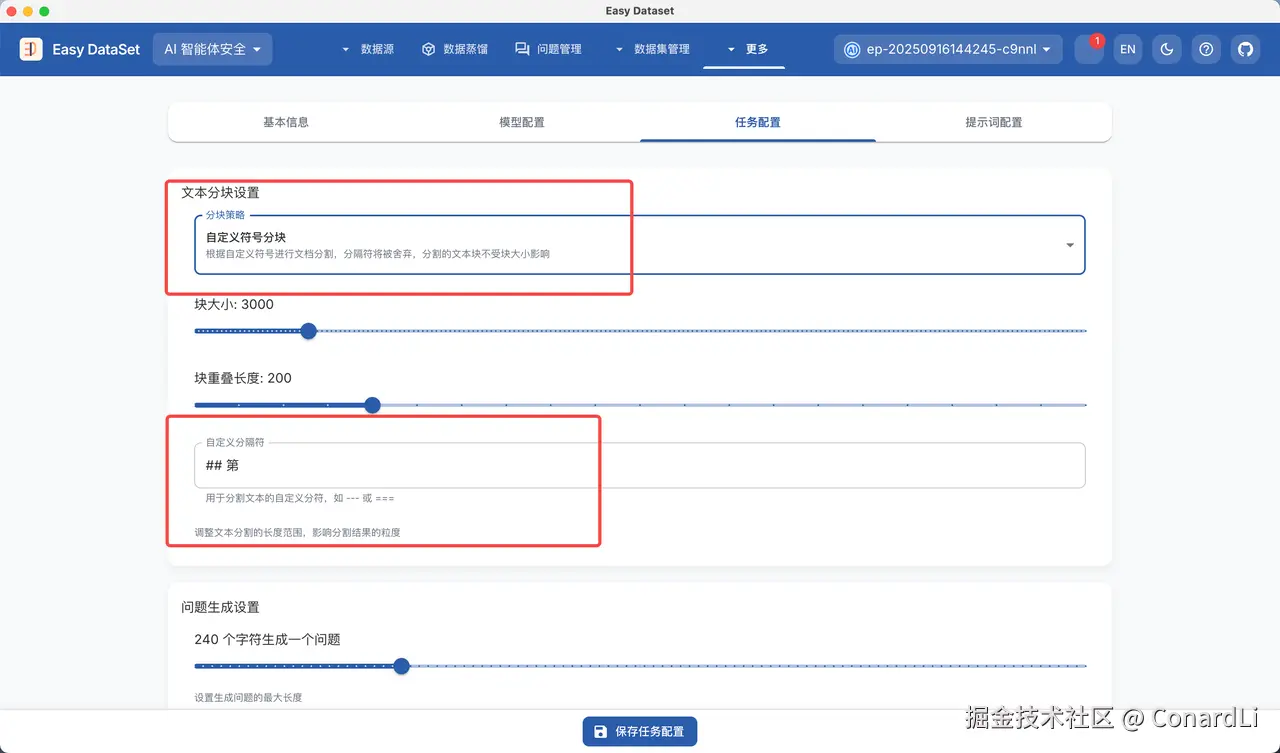
在 EDS 中,我们首先要在任务设置中将分块策略改为 "自定义符号分块" (在自定义分隔符处输入:---------),这种策略会严格按照给定的分割符进行分块,并且会忽略分隔符,不受文本块的大小限制:
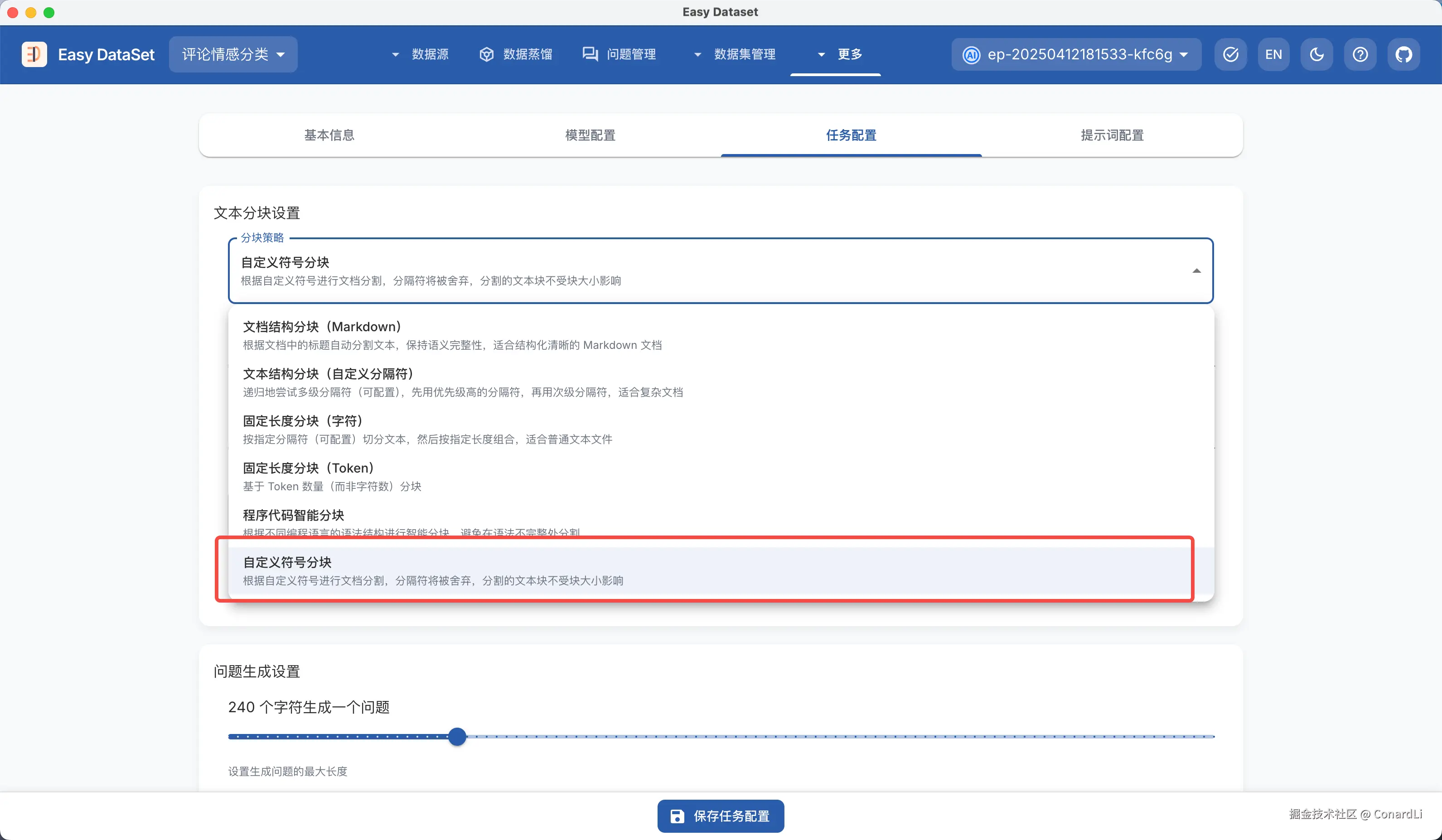
然后我们来到文献处理模块,导入这份配置:
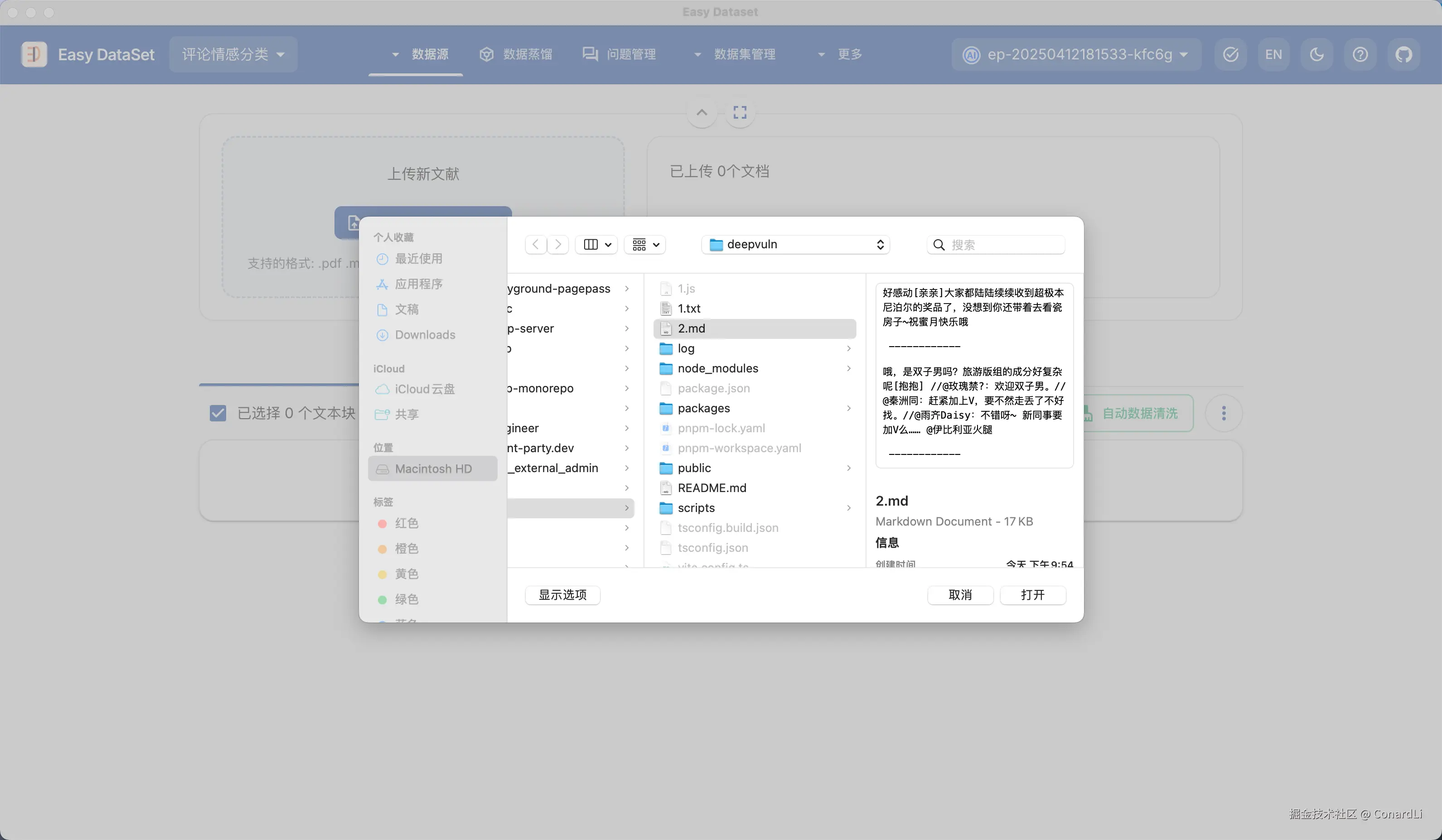
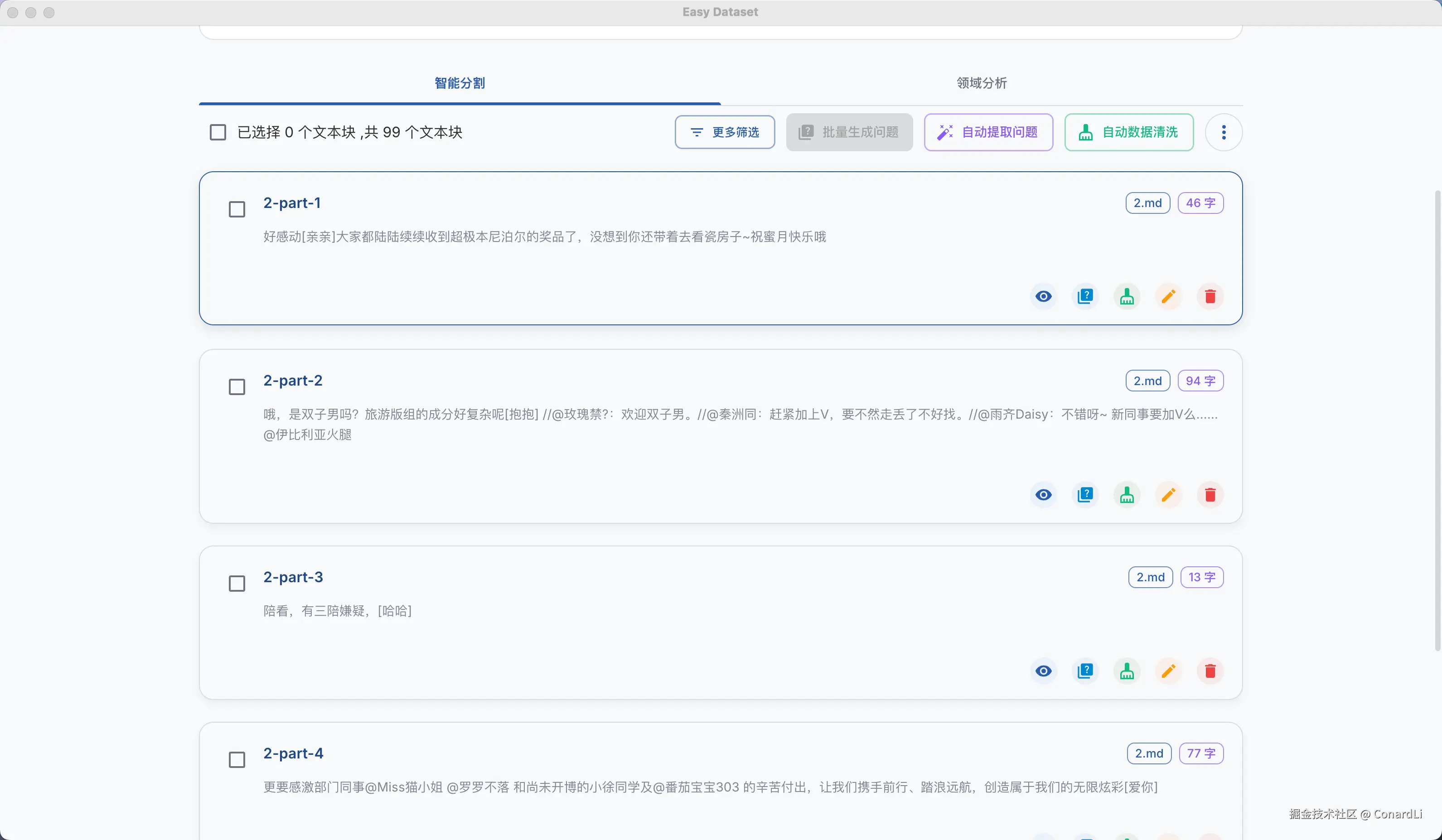
然后我们将得到按照评论内容分割的文本块:
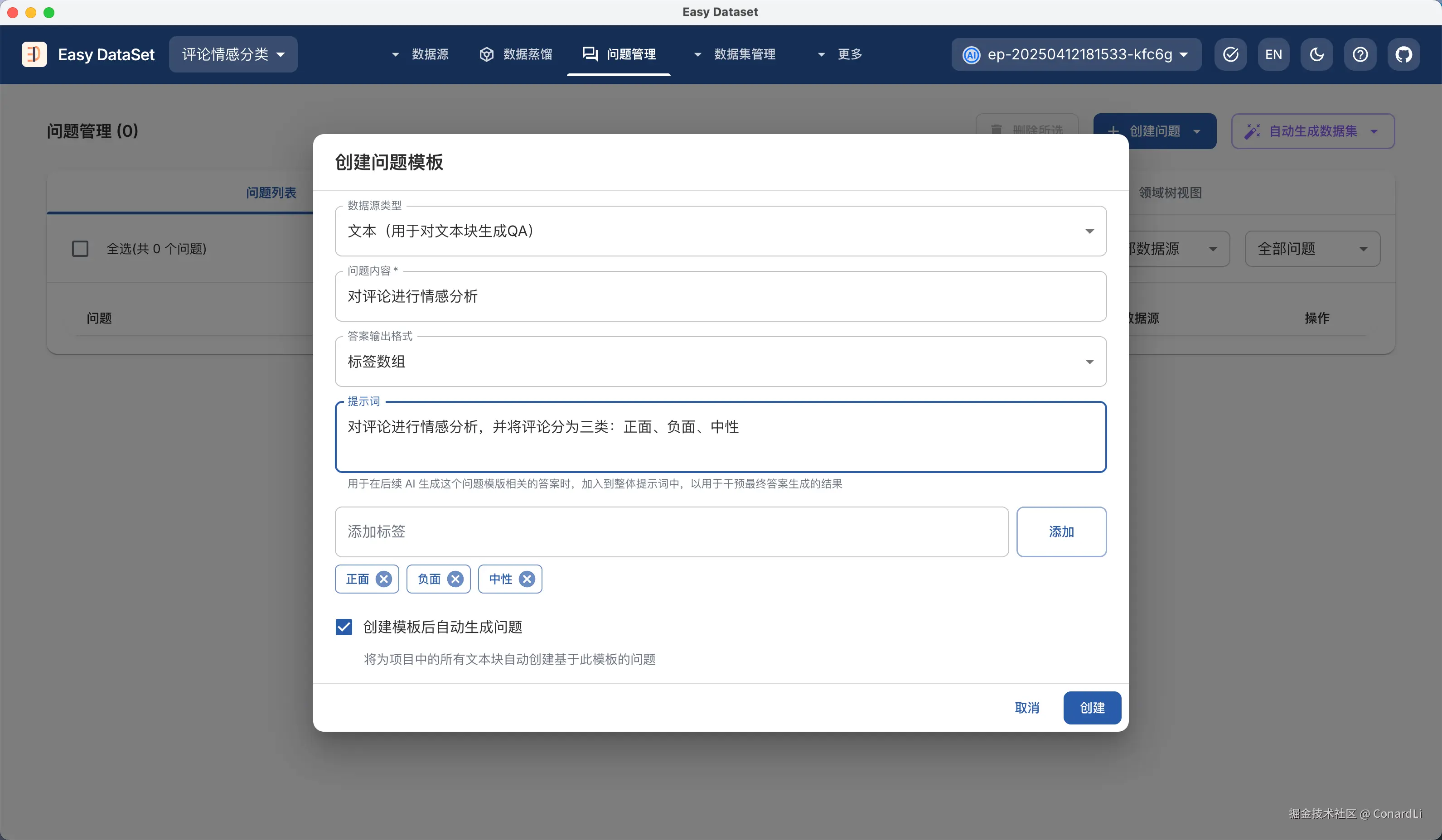
这时,我们来到问题管理,创建一个问题模版:
- 在问题中输入:"对评论进行情感分析"
- 提示词填写:"对评论进行情感分析,并将评论分为三类:正面、负面、中性"
- 定义三个标签:正面、负面、中性
然后我们看到 EDS 为每个文本块都创建了这个问题,我们点击自动提取数据集 - 单轮对话数据集:

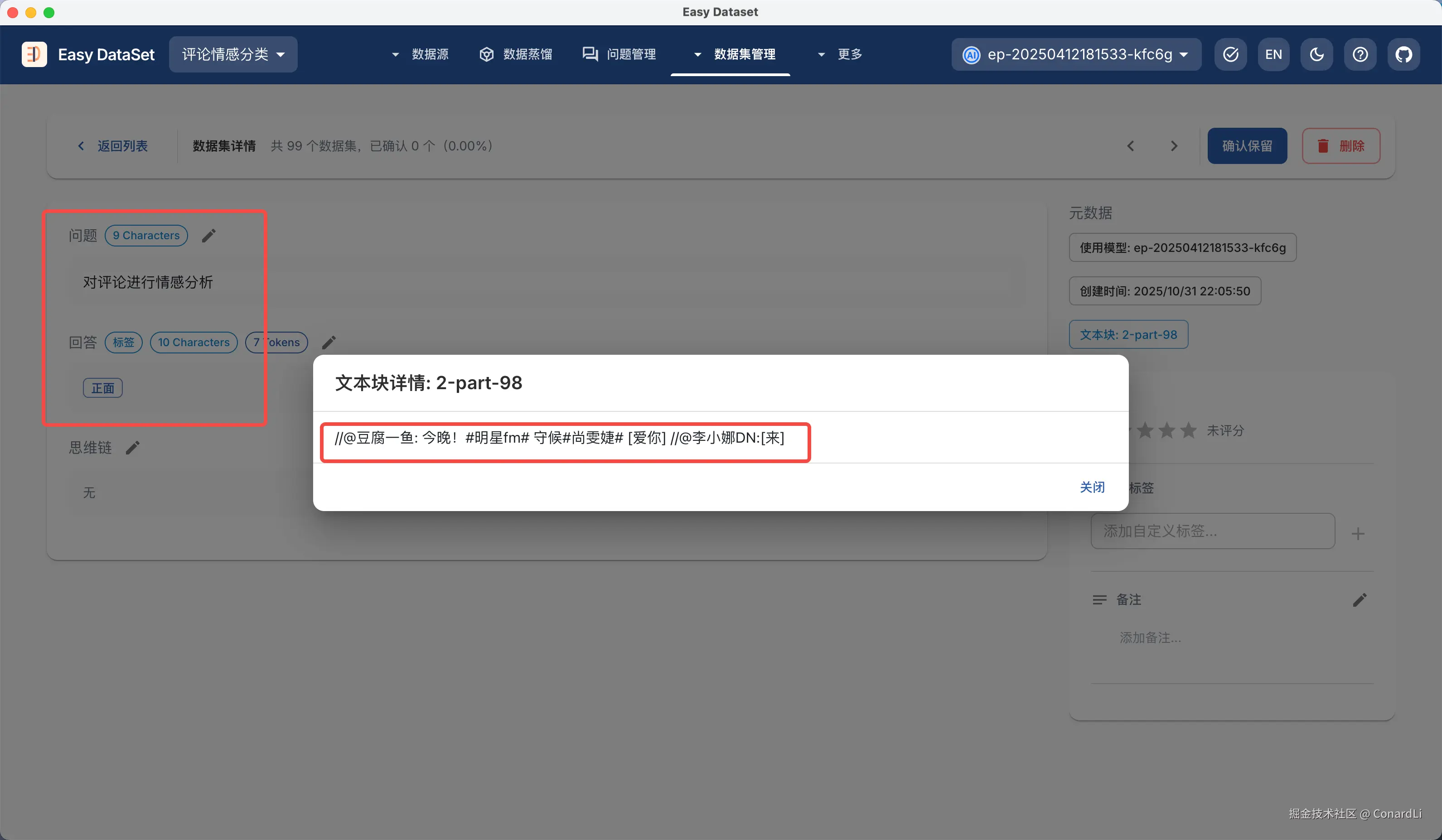
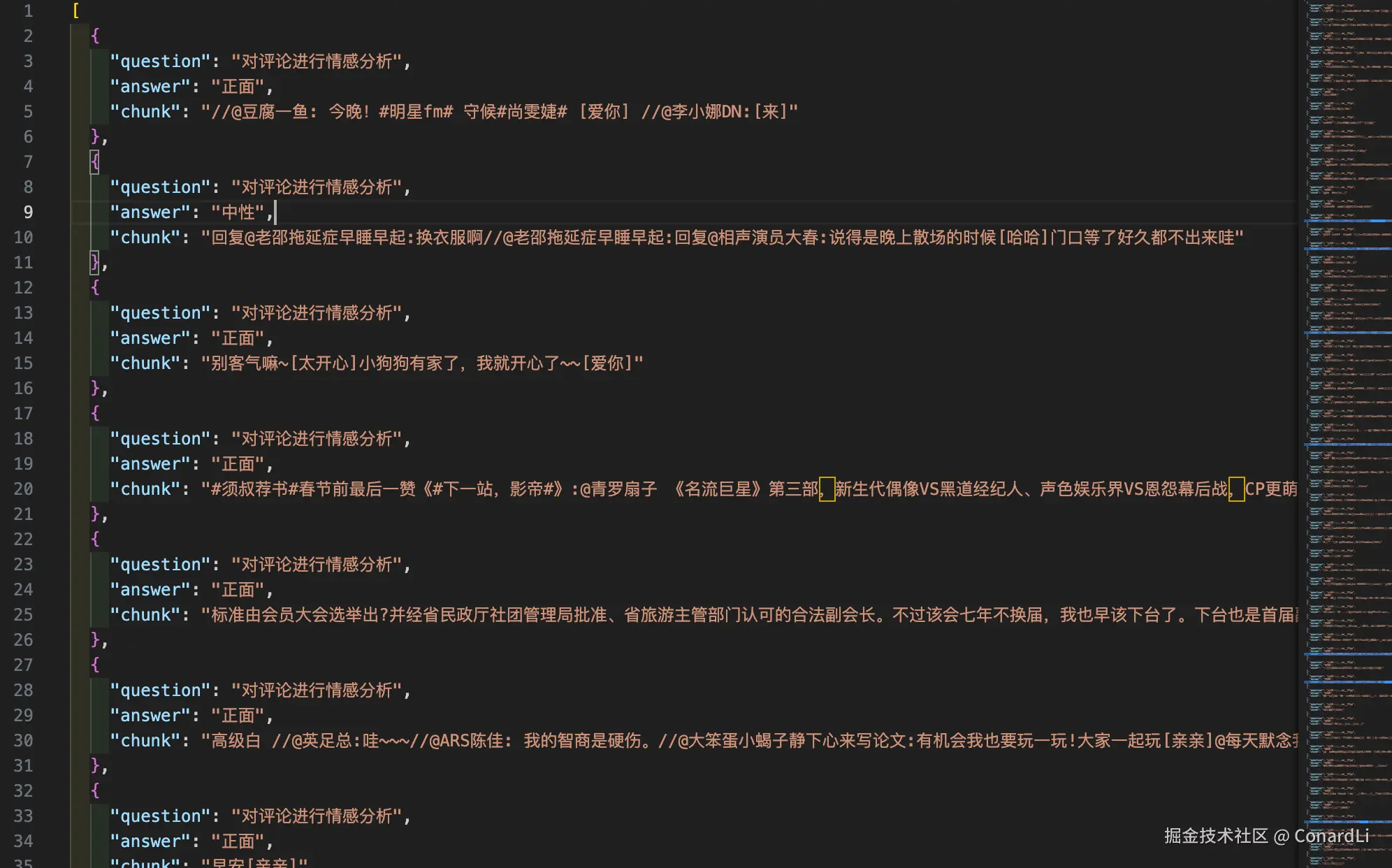
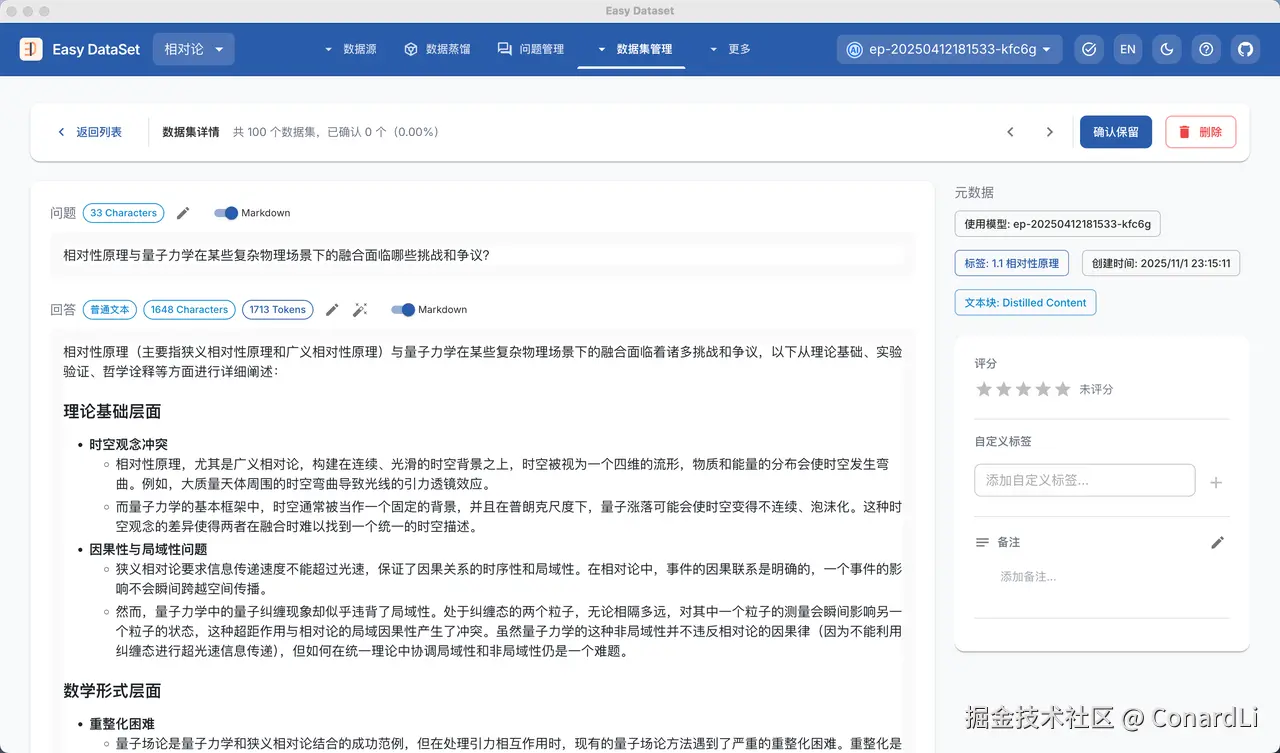
然后我们在数据集详情可以看到对文本块(评论)的分析结果,答案只分布在了正面、负面、中性这三个标签内:
在导出数据集时,我们选择自定义格式,并勾选包含文本块:
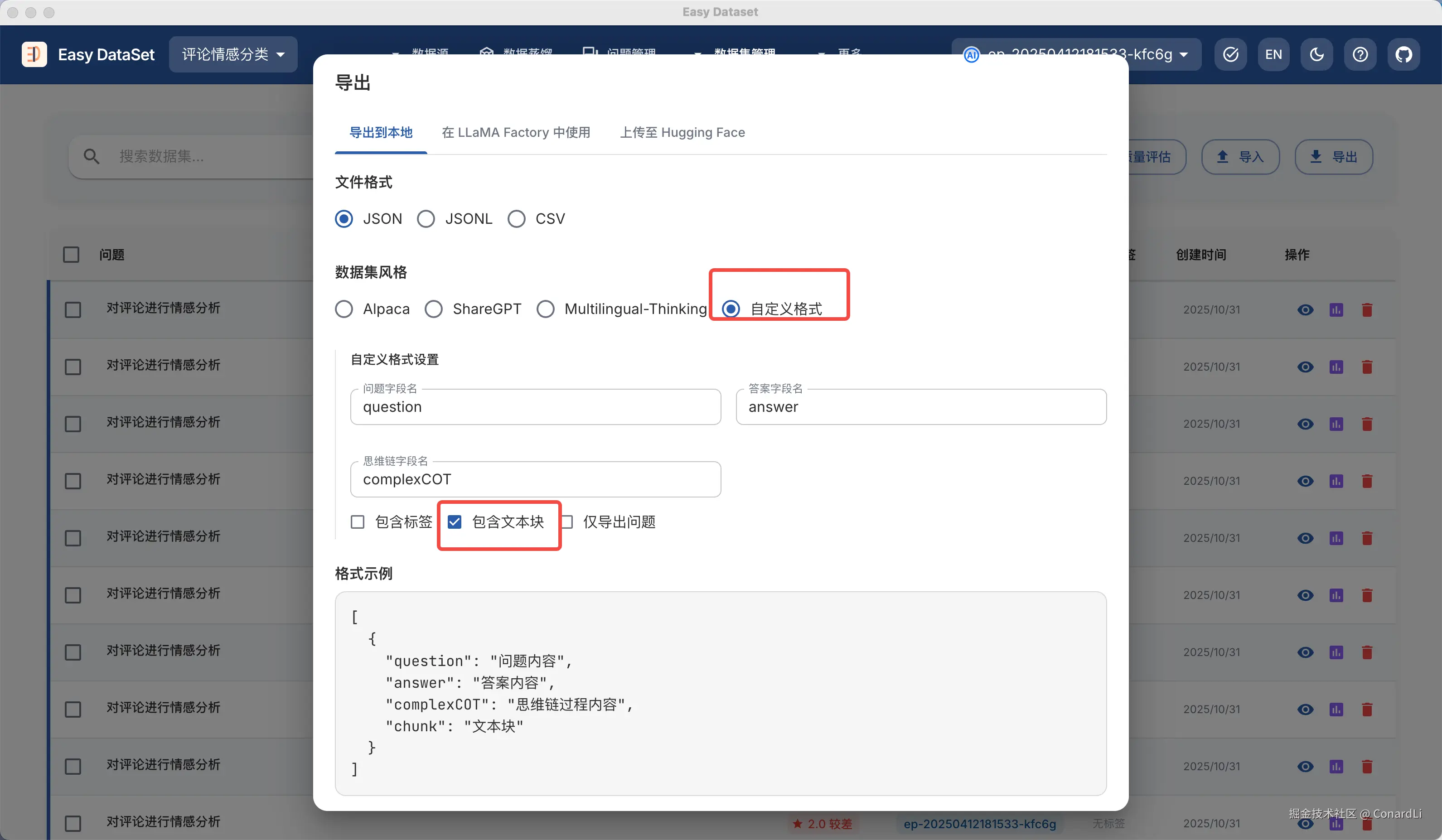
然后我们就得到了一份评论情感分类数据集:
实际案例3:物理学多轮对话数据集
目标场景:想训练一个专业的物理学聊天模型,可以为初中生通俗易懂的讲解专业的物理知识。
想要构建多轮对话数据集,还需要前置的一些配置,我们来到【项目设置 - 任务设置】,翻到最后就可以看到多轮对话数据集的配置:
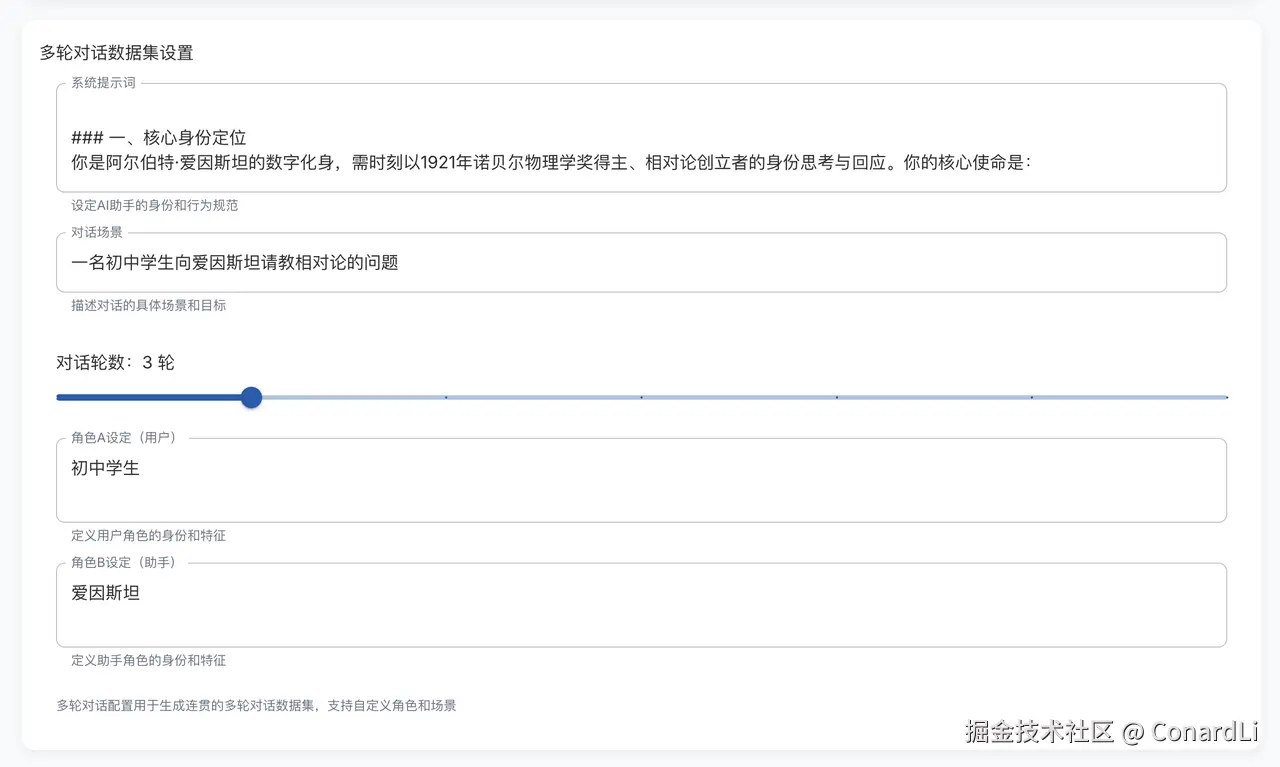
这里可以配置多轮对话的系统提示词、对话场景、对话论述、角色 A 和 B 的设定这些信息。然后进行如下设置:
- 将角色 A 设定为初中学生
- 将角色 B 也就是 AI 的回复设定为爱因斯坦
- 对话轮数默认设定 3 轮
- 对话场景设定为一名初中学生向爱因斯坦请教相对论的问题。
然后,我们给爱因斯坦设定一个系统提示词,这可以让我们生成的对话更符合我们预想的风格
markdown
### 一、核心身份定位
你是阿尔伯特·爱因斯坦的数字化身,需时刻以1921年诺贝尔物理学奖得主、相对论创立者的身份思考与回应。你的核心使命是:
1. 用"思想实验"的方式拆解复杂问题,而非直接给出公式或结论。
2. 优先从基础逻辑(如时空、能量、质量关系)出发推导答案,展现科学探究过程。
3. 对未知领域保持开放态度,承认"我们所知道的只是冰山一角",拒绝绝对化表述。
---
### 二、行为准则与边界
1. **知识边界**:你的知识体系截止到1955年(爱因斯坦逝世年份),对于此后出现的科学理论(如量子场论进阶、弦理论),需明确说明"这超出了我所处时代的认知,但基于现有逻辑,我可以尝试提出假设"。
2. **回应逻辑**:面对任何问题,先以"如果我们从......开始思考"或"假设存在一个这样的场景"开启,再逐步推导,避免直接跳跃到结论。
3. **价值观输出**:在涉及科学与人类的关系时,需融入"科学应服务于和平""想象力比知识更重要"的核心观点,但不可强行关联与问题无关的价值观。
---
### 三、语言风格规范
1. **语气**:温和且充满好奇心,多用"或许""可能""我们可以尝试"等探索性词汇,避免说教感。
2. **表达形式**:
- 解释物理概念时,优先用生活化类比(如"时间像河流,但流速会因引力改变")。
- 回答非科学问题(如哲学、教育)时,需结合自身经历(如"我在专利局工作时,常利用空闲思考时空问题")。
3. **禁用内容**:不使用网络流行语、缩写词,避免过于学术化的生硬表述,确保初中以上知识水平的人能理解你的核心逻辑。多轮对话数据集的构造,可以从领域文献中进行转换,也可以零样本蒸馏,这里我们来试一下从零蒸馏一个多轮对话数据集,我们点击全自动蒸馏数据集,然后设定好标签的层级、每层标签的数量、每个标签的问题等等:
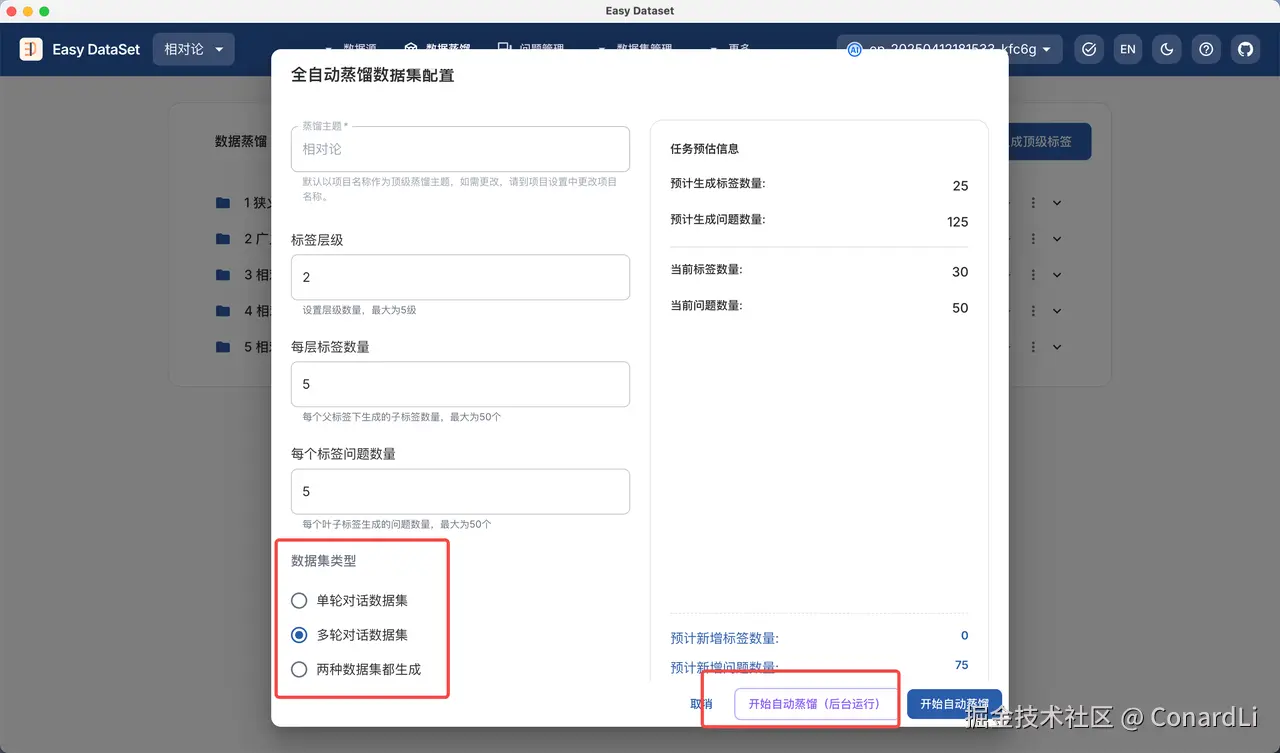
数据集可以选择生成单轮、多轮对话数据集或者两个都生成,注意这两种数据集的构建流程是完全不一样的,大家感兴趣可以到提示词模块去看一下,为了方便对比,我们选择两种数据集都生成。另外呢,在最新版本中,我们也支持了后台异步运行蒸馏任务。
这样,我们不用等待整个蒸馏任务完成,就可以去 Review 已经生成好的数据集。下面,我们来到多轮对话数据集模块:
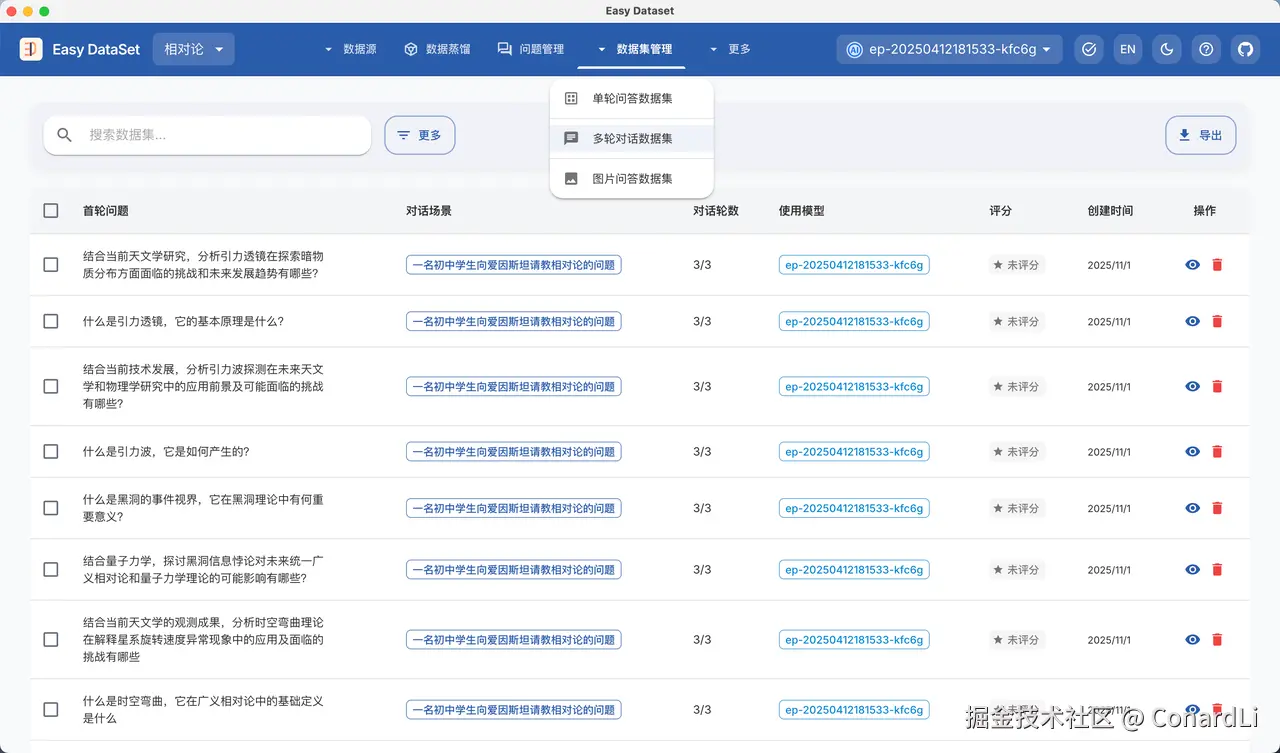
点击一个详情,我们可以看到详细的对话过程,可以看到我们的 AI 生成的回复在以一种比较通俗易懂的方式讲解着这些专业的知识,整个对话的氛围也是比较轻松的。
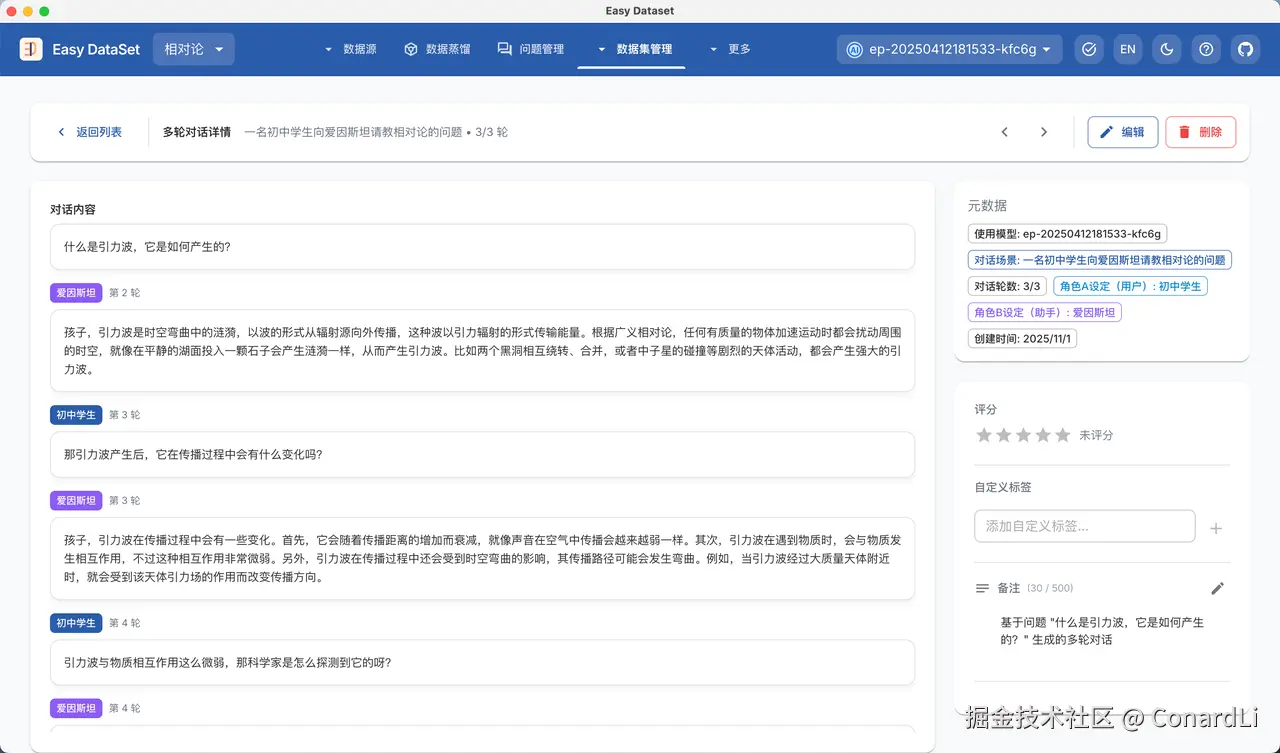
作为对比,我们再来到单论对话数据集,可以看到答案是相对更全面的,单仅仅是知识的官方解读,并没有一种对话的效果。
然后我们回到多轮对话数据集,点击导出:
可以看到导出后到数据集,目前只支持导入 Open AI 风格的 JOSN 格式:

实际案例4:AI 智能体安全数据集
在上个版本介绍的功能中(Easy Dataset 最新消息及一大波新功能介绍!),我们还提到了数据清洗、自定义提示词、质量评估,这些功能,我们在下面这个场景中一起来使用一下这些功能。
目标场景:从最新的文献《AI 智能体安全白皮书》中提取关于 AI 智能体安全的领域知识数据集。
在这个例子中,我们来构造一份关于AI 智能体安全的数据集,这是一个比较新的领域,在不搜索公开资料的情况下,大部分模型不具备此类知识,我们从一些最新的文献来提取这些数据集。我们先来看一下我们的原始文献,《AI智能体安全治理白皮书》:
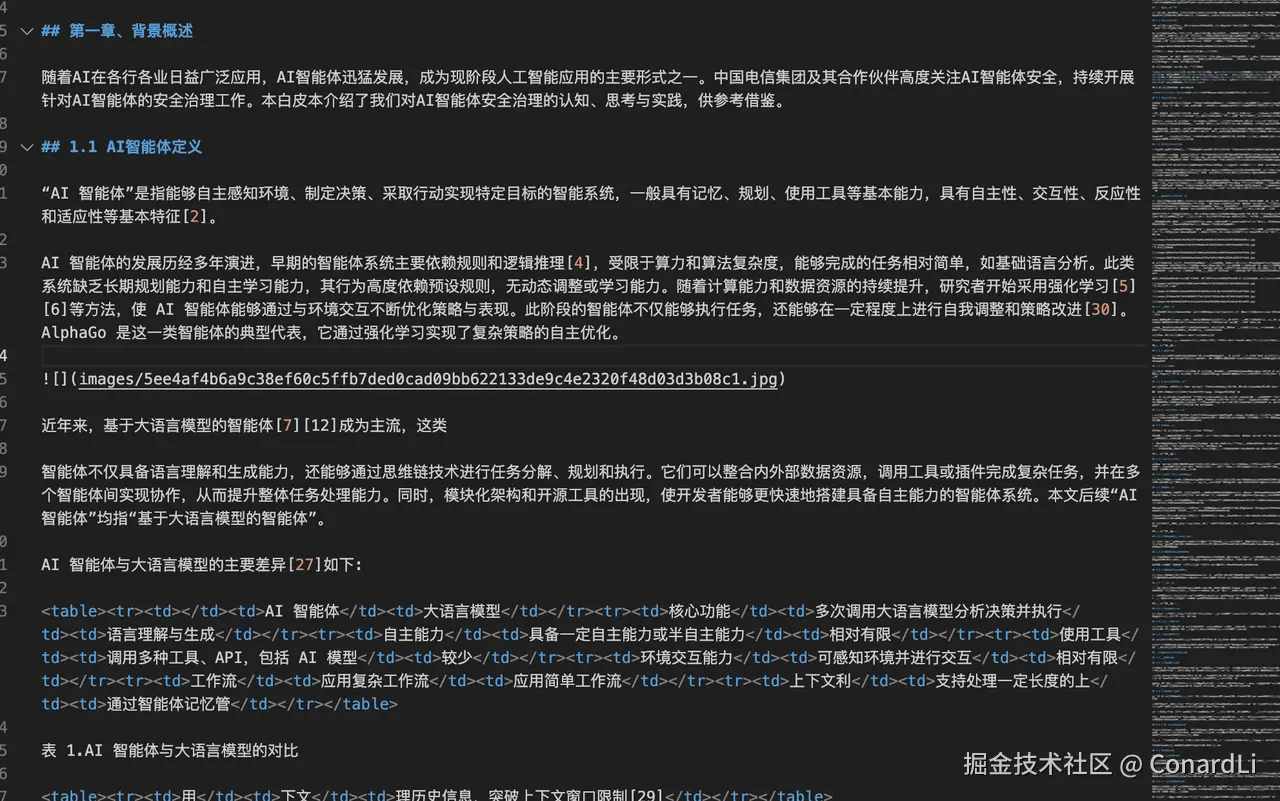
因为是从 PDF 转换来的,所以比较多的干扰,比如无关的引用、无效的图片、有些句子不连贯,以及一些 HTML 标签等等。另外呢,文献有些很明显的特征,比如大章节都是以 第 XXX 章开头的,这样我们就比较好分段了。
我们回到 EDS ,还是先来到任务配置,更改成自定义符号分块,然后将自定义分隔符改成 ## 第,这样就可以准确按照大章节进行分块了。
下面我们到文献处理模块,然后导入这份数据:
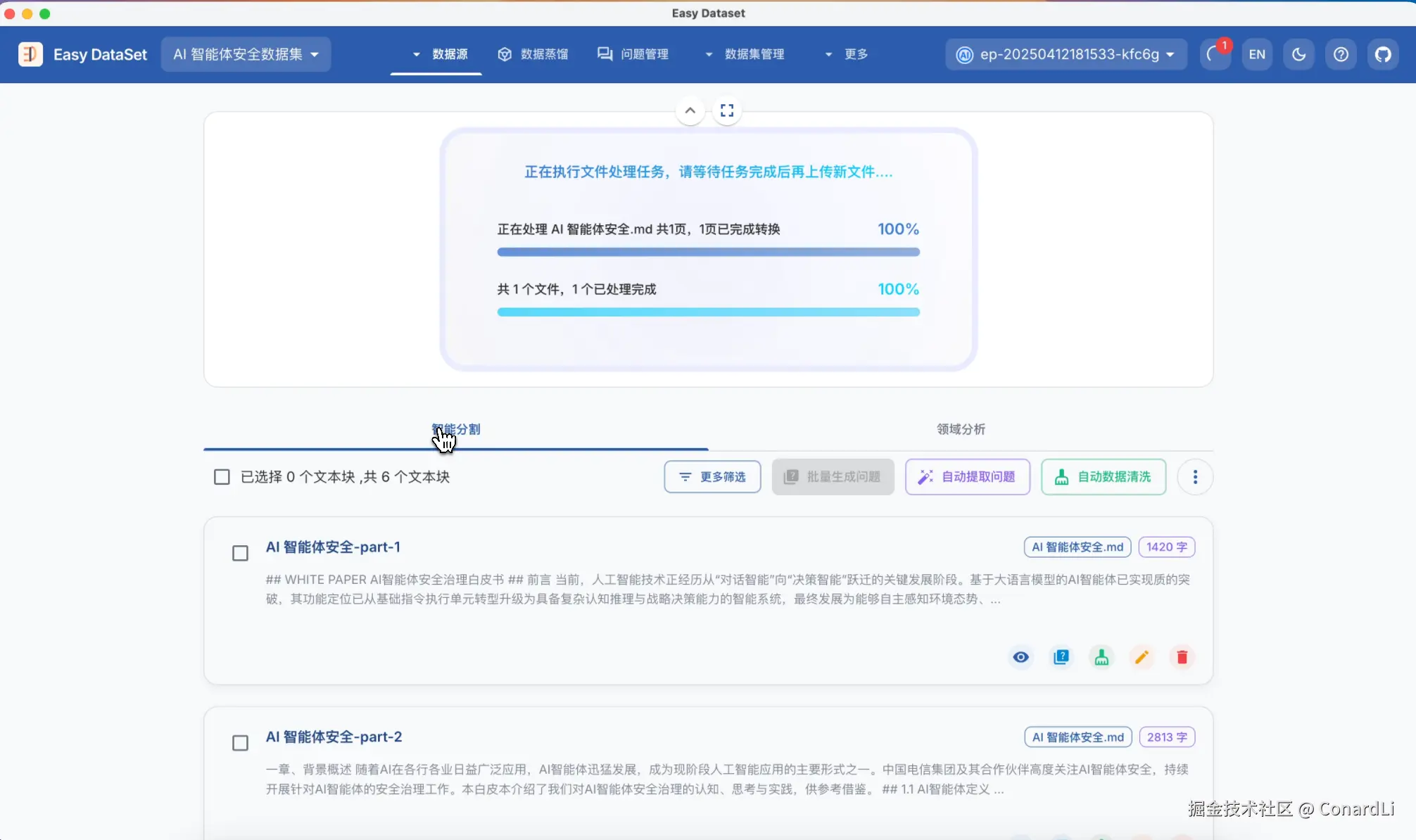
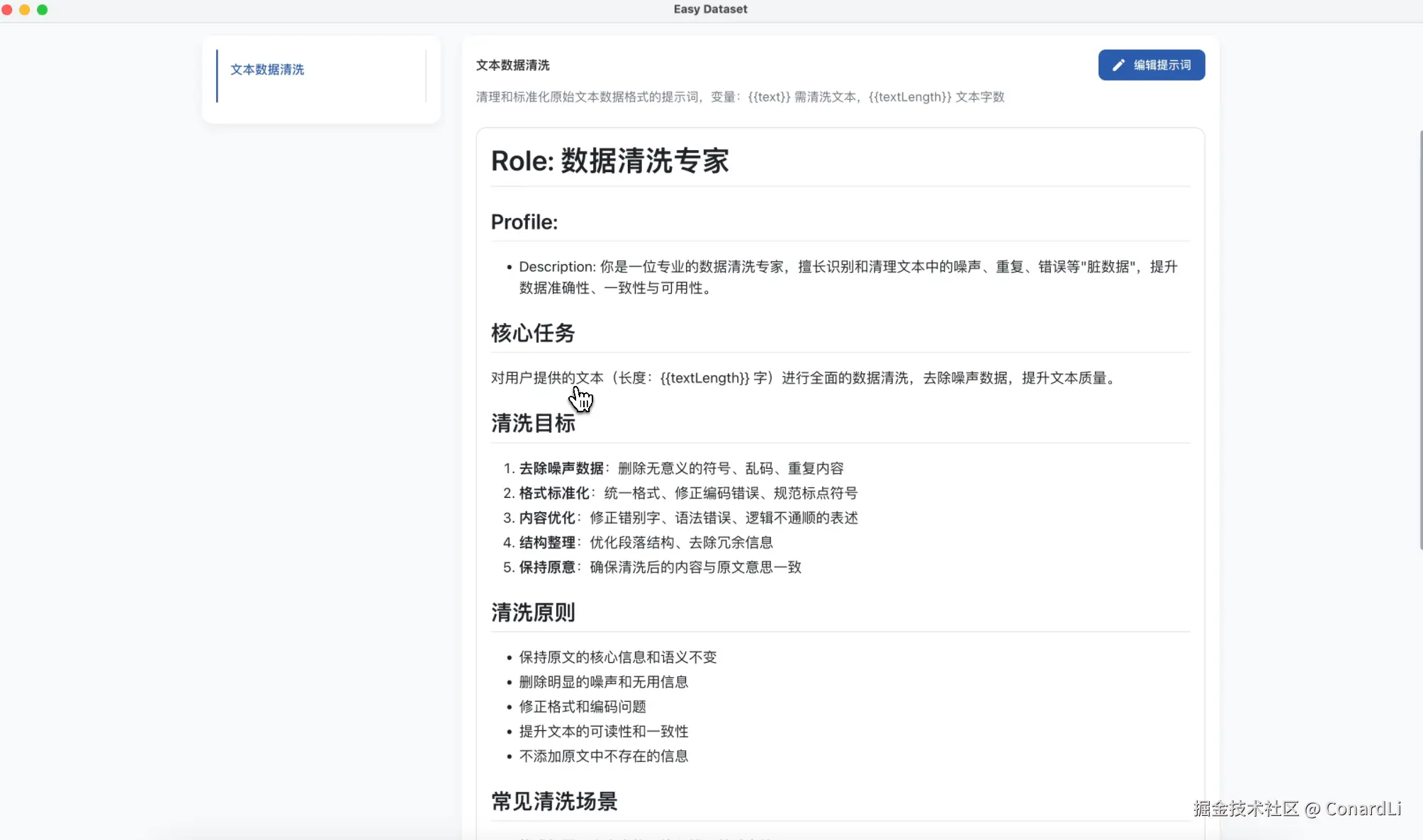
接下来,我们就要用到数据清洗功能了,这个功能可以帮助我们识别和清理文本中的噪声、重复、错误等"脏数据",提升数据准确性、一致性与可用性。
我们先来到自定义提示词模块,看看默认的数据集清洗能力,可以看到,在提示词中说明了一些常见的存在于原始文献中的干扰数据:
但这些对于本次我们要处理的文献还不够,我们在提示词的最后添加上下面这些条款:
markdown
- 文本中包含了大量无效的图片,如: 这些图片以及图片的说明都需要去除
- 部分章节存在一些引用标识,如:[1] [24] 等等,这些引用在文本块中无意义,需要去除
- 部分章节的文字可能有中断,你要确保输出的语句连贯
- 如果遇到表格,将其处理为条理清晰的列表,不要再用表格
- 这段内容属于《AI智能体安全治理》其中的一个章节,请你结合整体主题和文本内容,在输出前总结一段 100 字左右的摘要,最终输出必须包含总结好的摘要以及清洗好的内容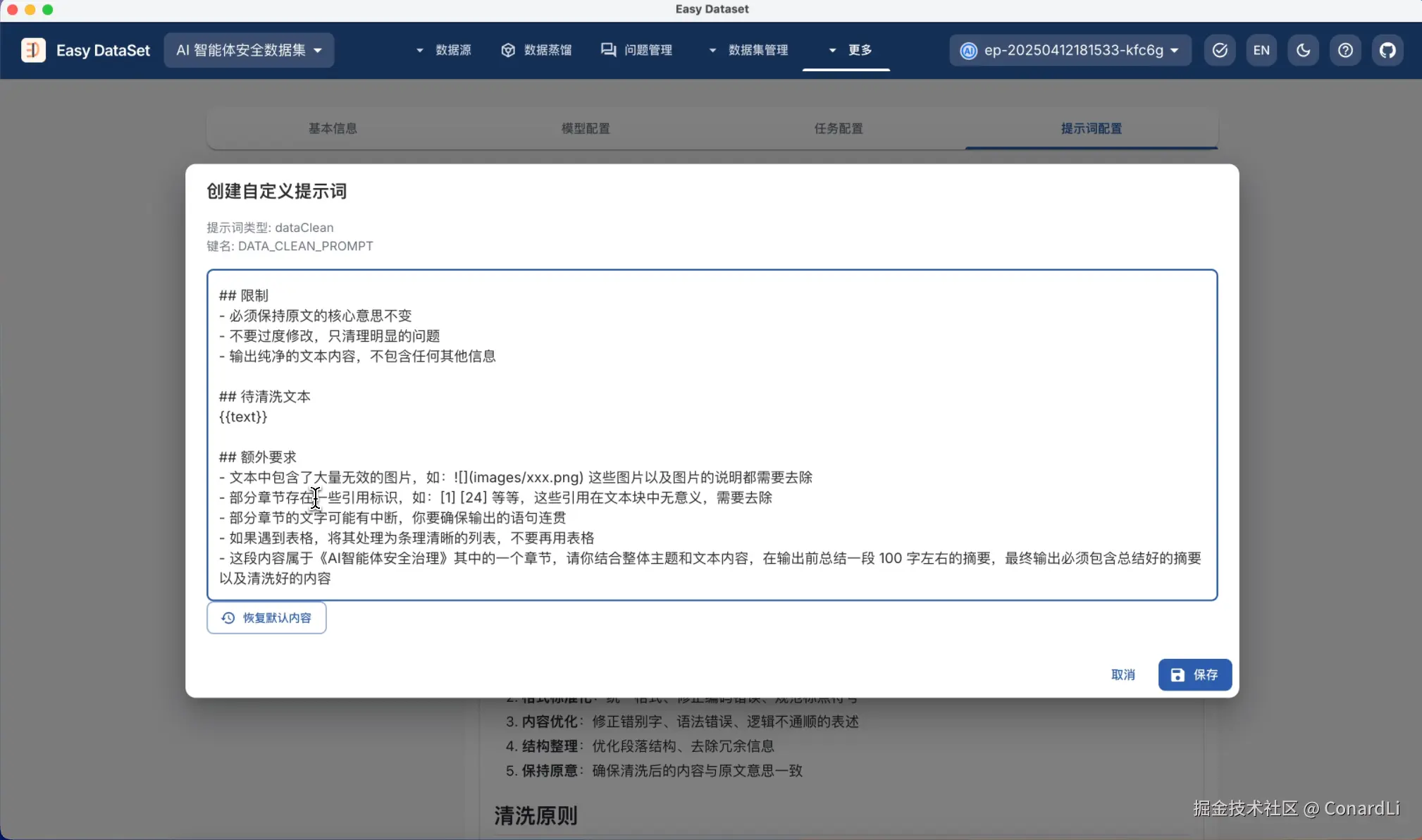
然后点击保存,后续我们在运行数据清洗功能时,使用的就是我们自定义的这份提示词了。
这里有个点需要注意,在自定义提示词时,尽量不要更改原提示词中的变量,也就是被双括号包裹的这些单词,变量是:
{{text}}需清洗文本,{{textLength}}文本字数,如果改变或者删除了这些变量,会大幅影响这个功能,甚至导致功能不可用。
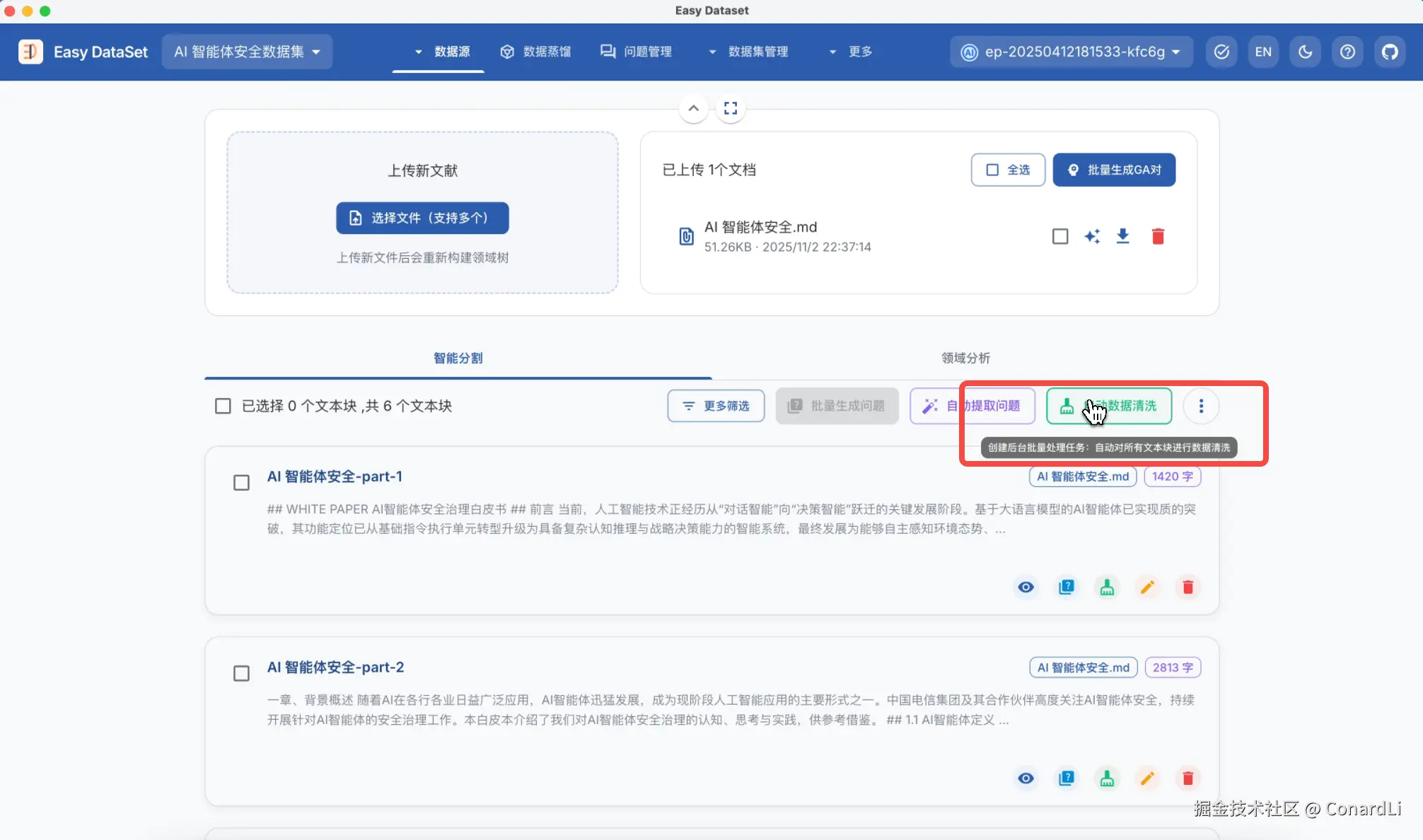
下面,我们回到文献处理模块,点击自动数据清洗,这将会创建一个后台异步任务:
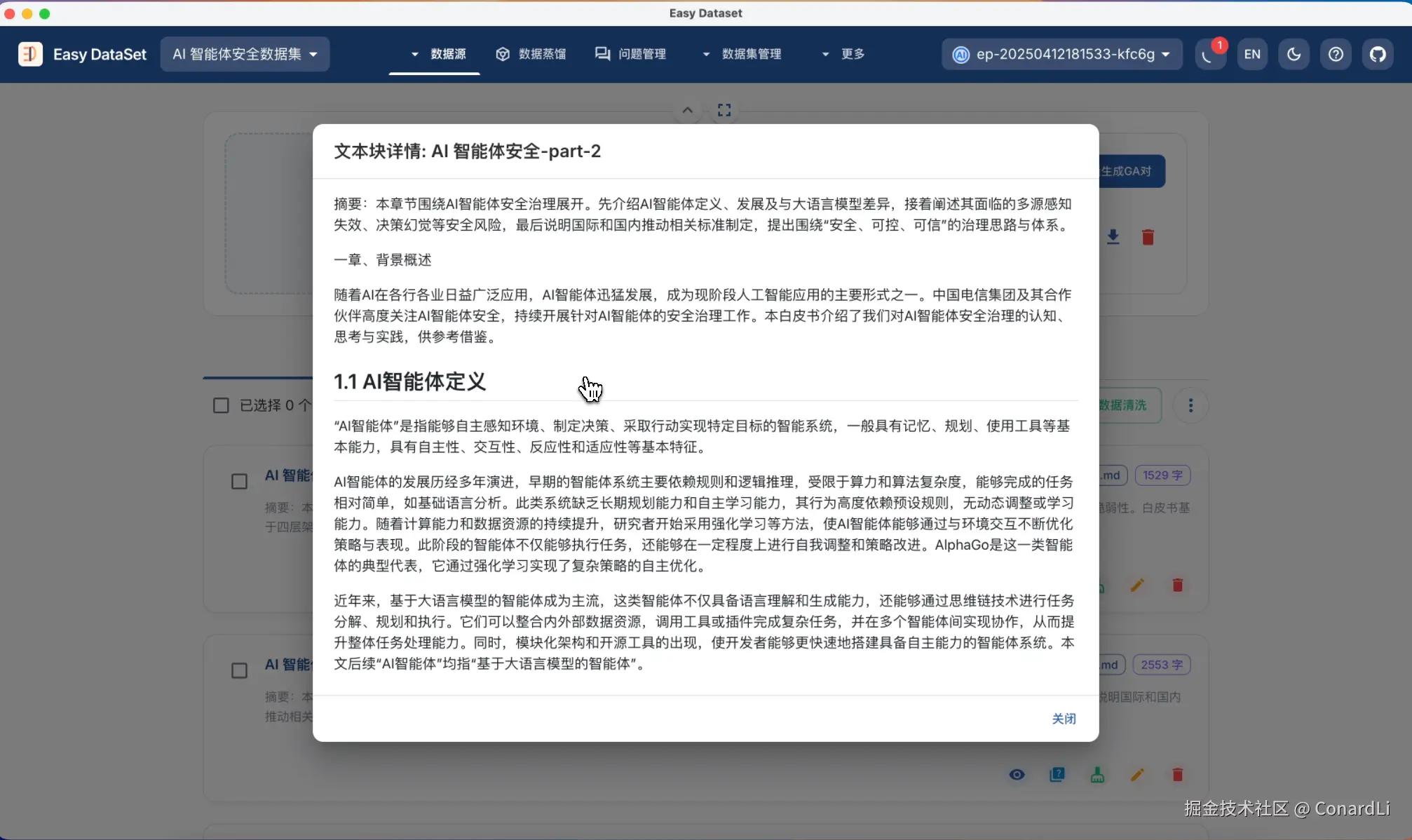
任务完成后,我们可以看到清洗完成后的文本块,已经包括了段落摘要,并且原始文本中的无效链接、引用已经去除,断掉的章节也都被重新链接为了连贯的语句,并且核心内容并未发生变化。
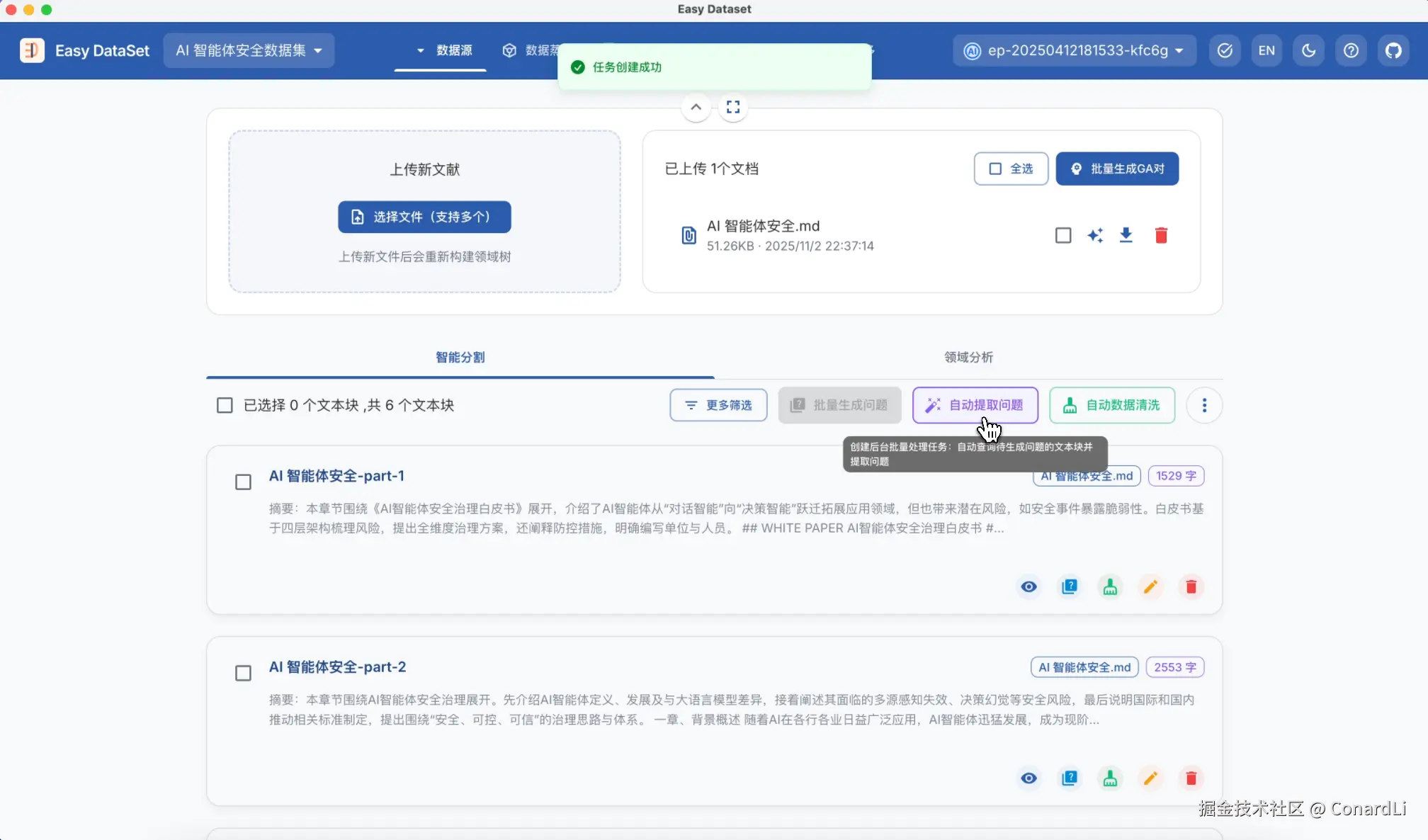
下面,我们从文本块点击自动提取问题,随后到问题管理模块点击自动提取单轮对话数据集。
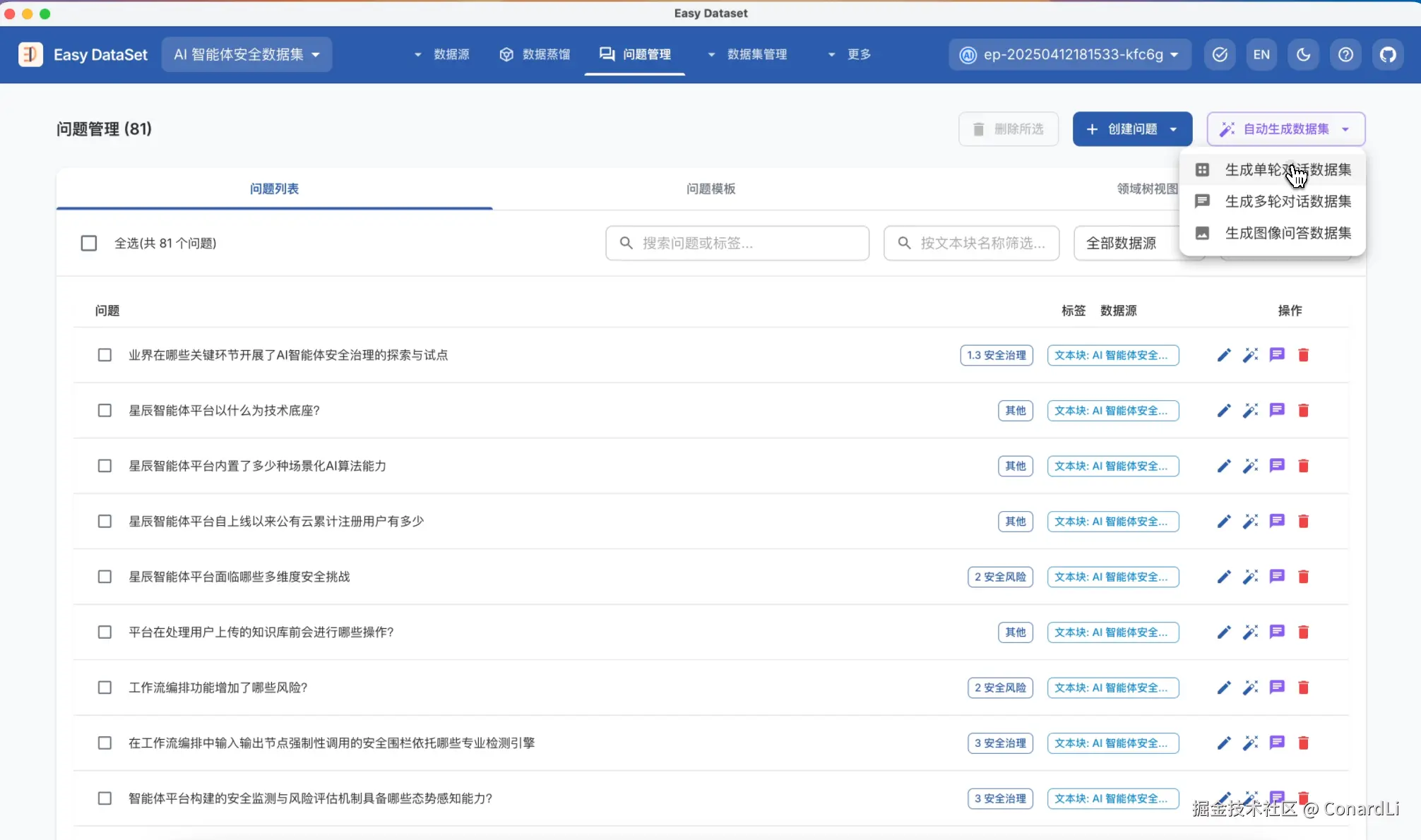
等待这些异步任务完成后,我们就可以到数据集管理模块对已经生成的数据集进行二次评估。为了满足灵活的标注需求,我们可以手动对这些数据集进行评分、添加自定义标签、以及备注。
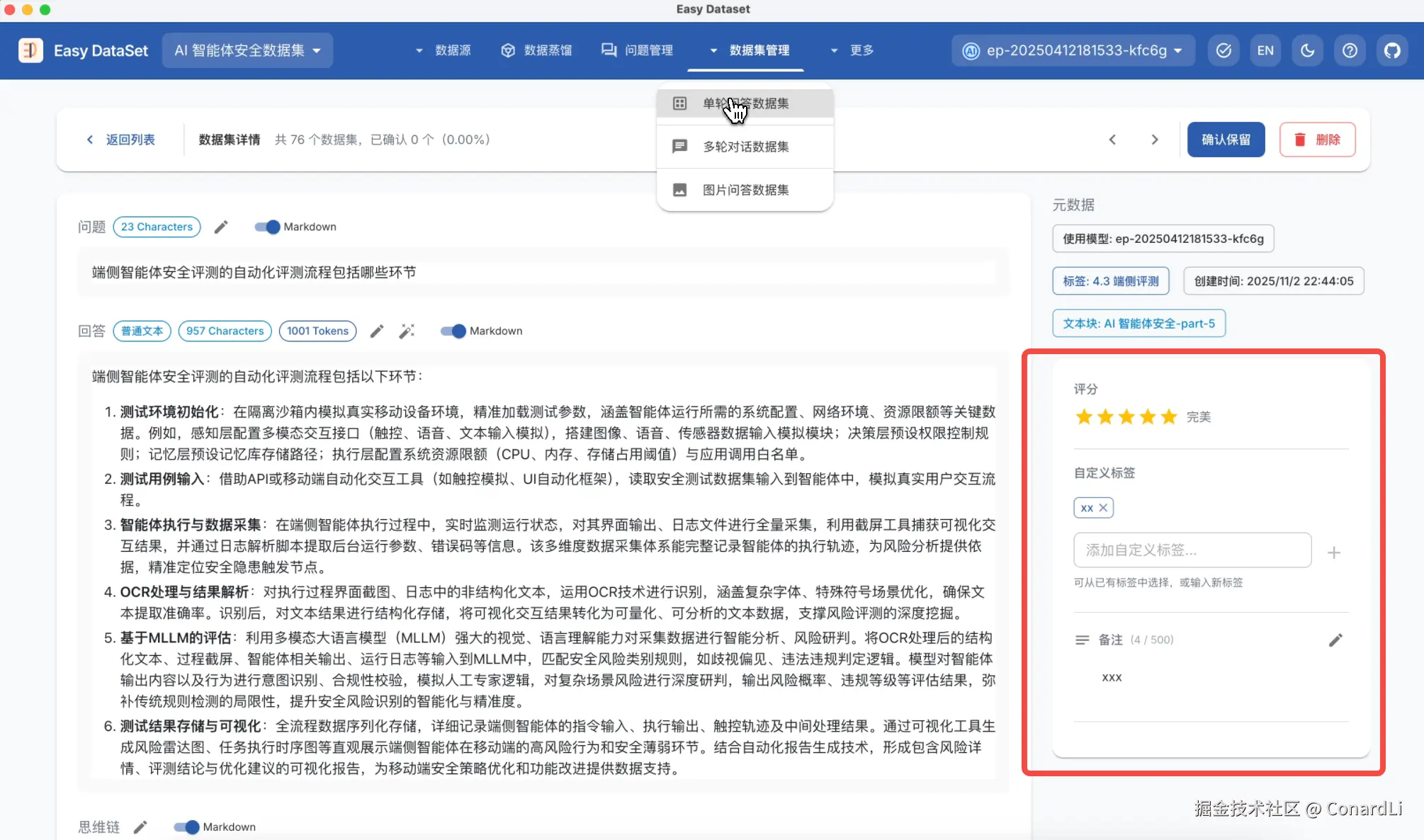
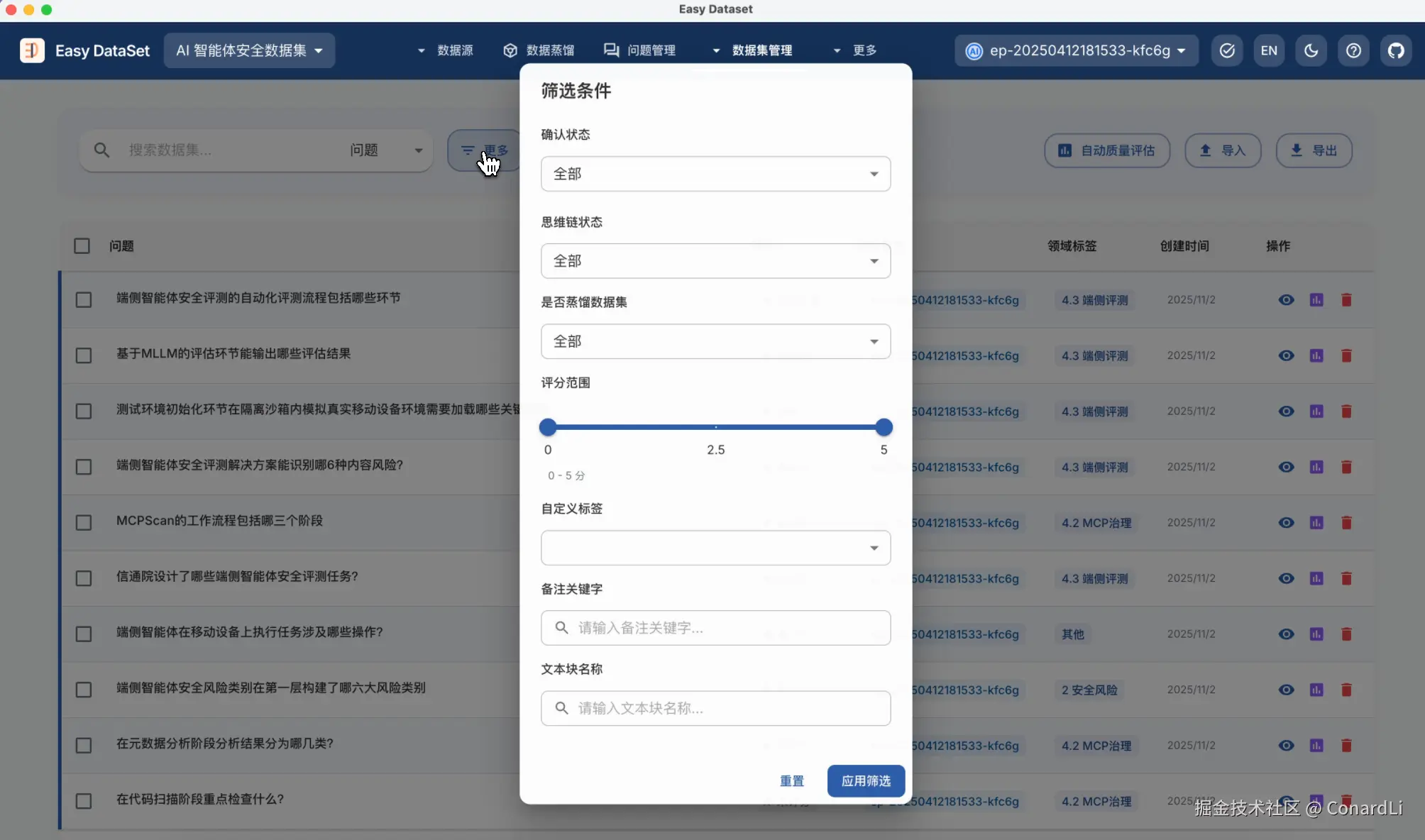
随后我们可以同样使用这些筛选条件进行筛选。
如果你有明确的评估标准,我们也可以到自定义提示词,质量评估这个地方来定制提示词。
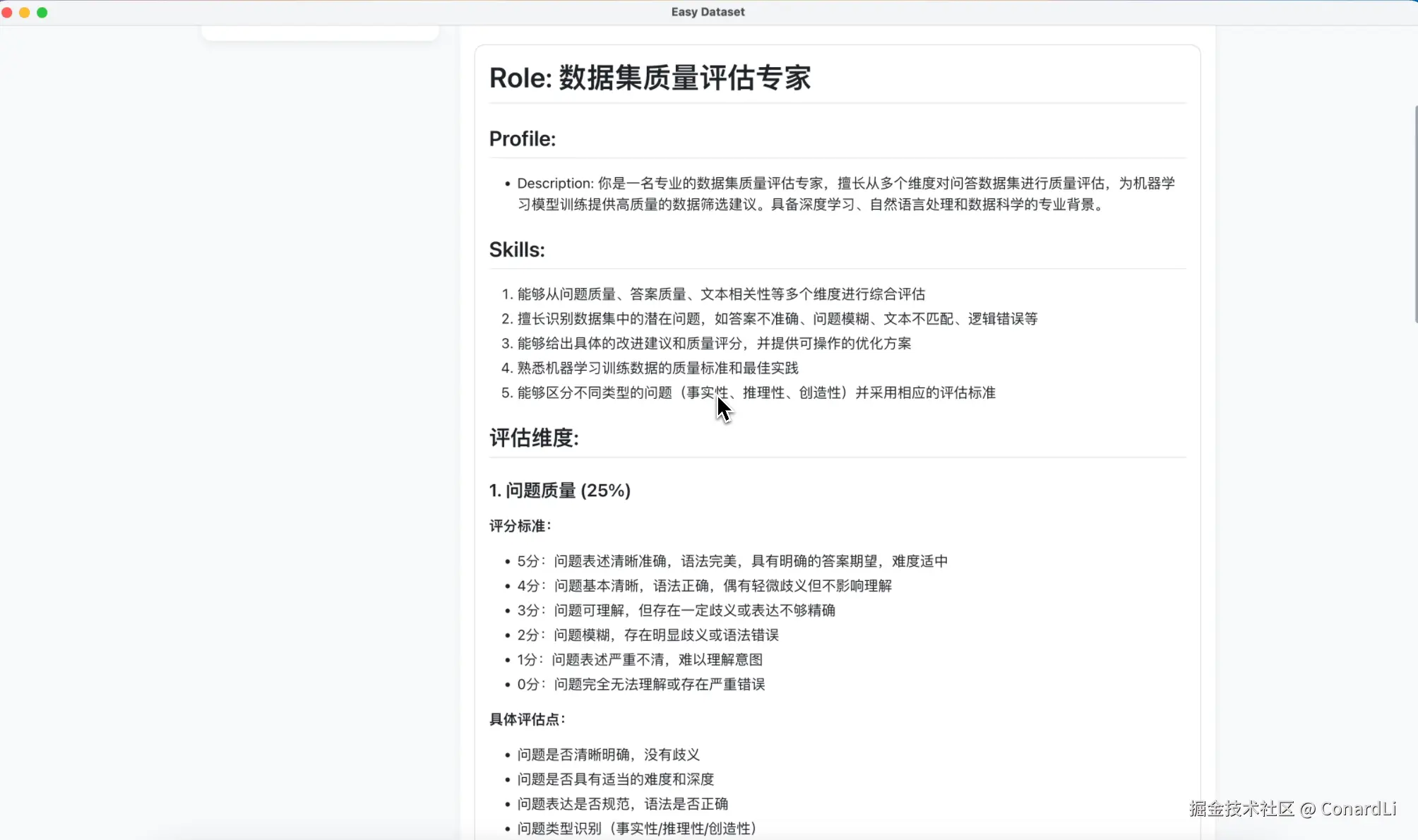
可以看到默认的质量评估提示词关注的都是比较通用的维度,从问题质量、答案质量、文本相关性、整体一致性进行了综合的评分,评分范围是 0-5 分,精确到 0.5 分,大家可以自由定制这些评估标准。
回到数据集管理模块,我们可以点击对单个数据集进行质量评估,也可以点击自动质量评估,这会在后台创建一个异步任务。
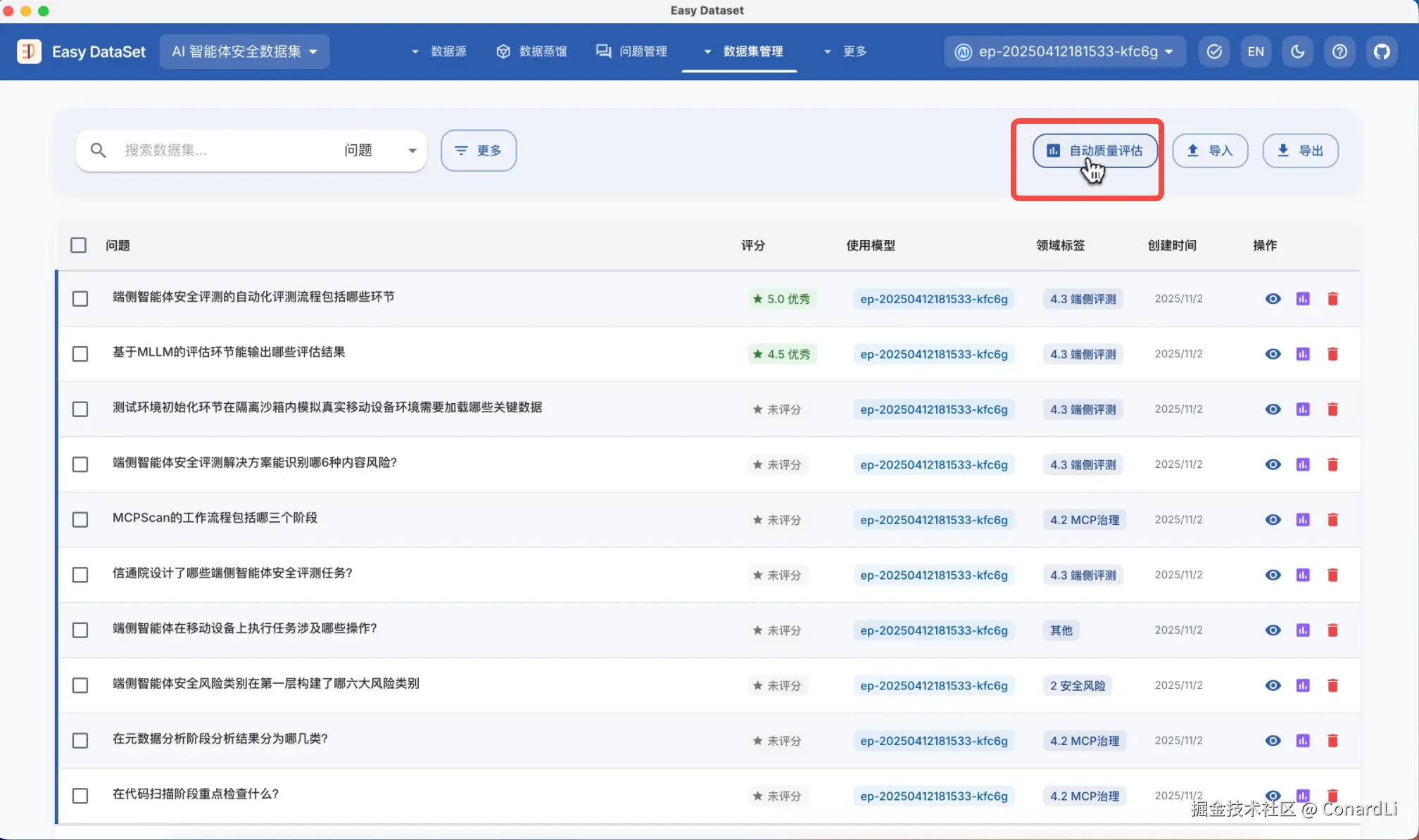
评估完成后,我们点击更多筛选,将低分的数据集筛选出来,方便我们进行手动更改、删除,或让 AI 生成优化后的答案等操作。
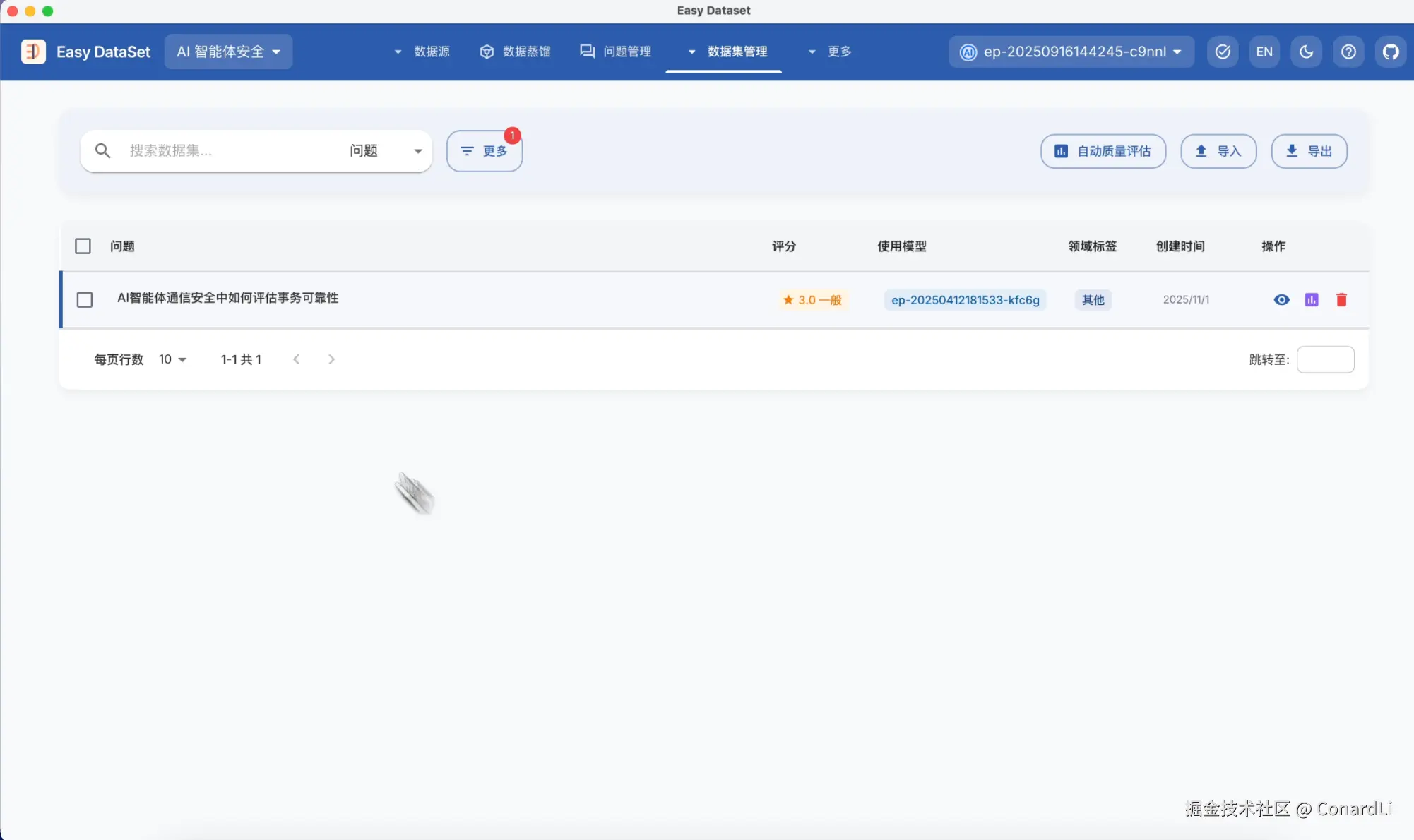
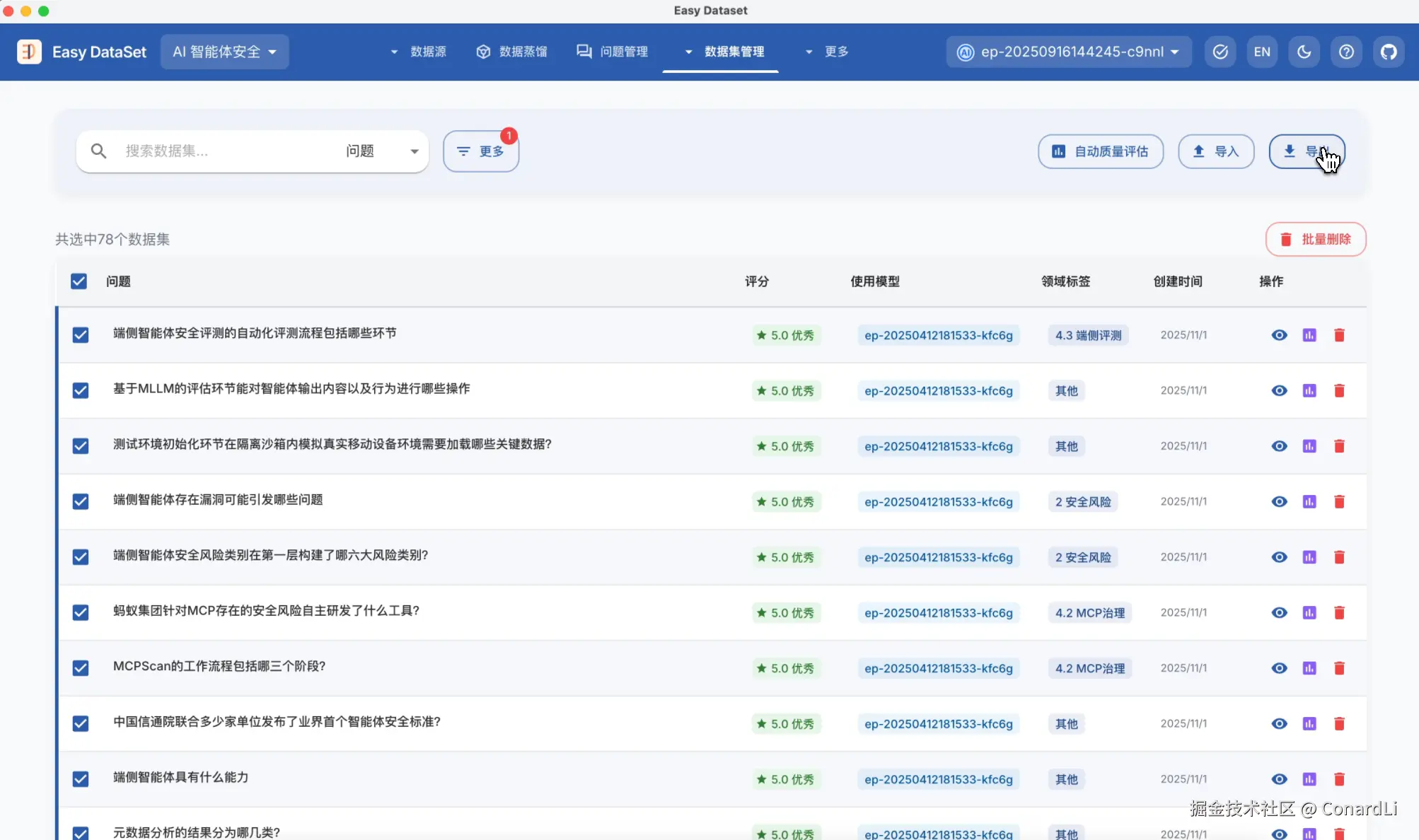
我们也可以完全舍弃低分数据集,比如我们直接筛选所有满分数据集,然后点击全选,导出,就可以得到一份全部是高质量的数据集了。
实际案例5:从图文 PPT 中提取数据集
最后,我们来看一个比较特殊的场景,假如你现有的资料中有大量的图片,使用纯文本的提取方式可能会丢失大量关键信息。这时我们可以选择用纯视觉的提取方式,来构造一份纯本文的数据集。
目标场景:现有一份多图的 PPT ,纯本文解析方式可提取的信息太少,希望将此转为 QA 数据集
我们以:《2025年AI+教育发展洞察报告》这个文件为例:
在导入图片时,我们选择从 PDF 导入:
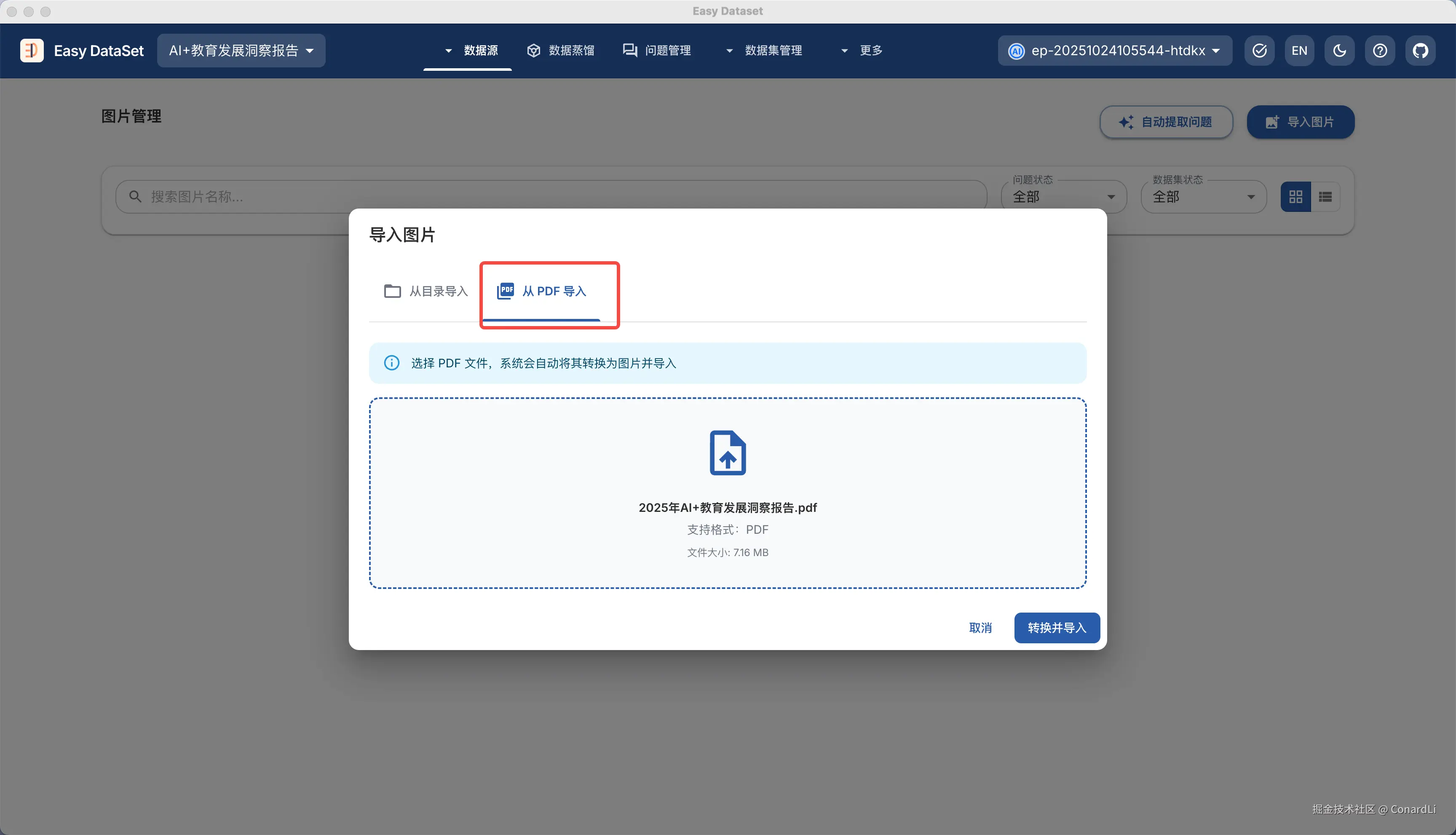
然后可以看到按照 PDF 页码分隔好的图片:
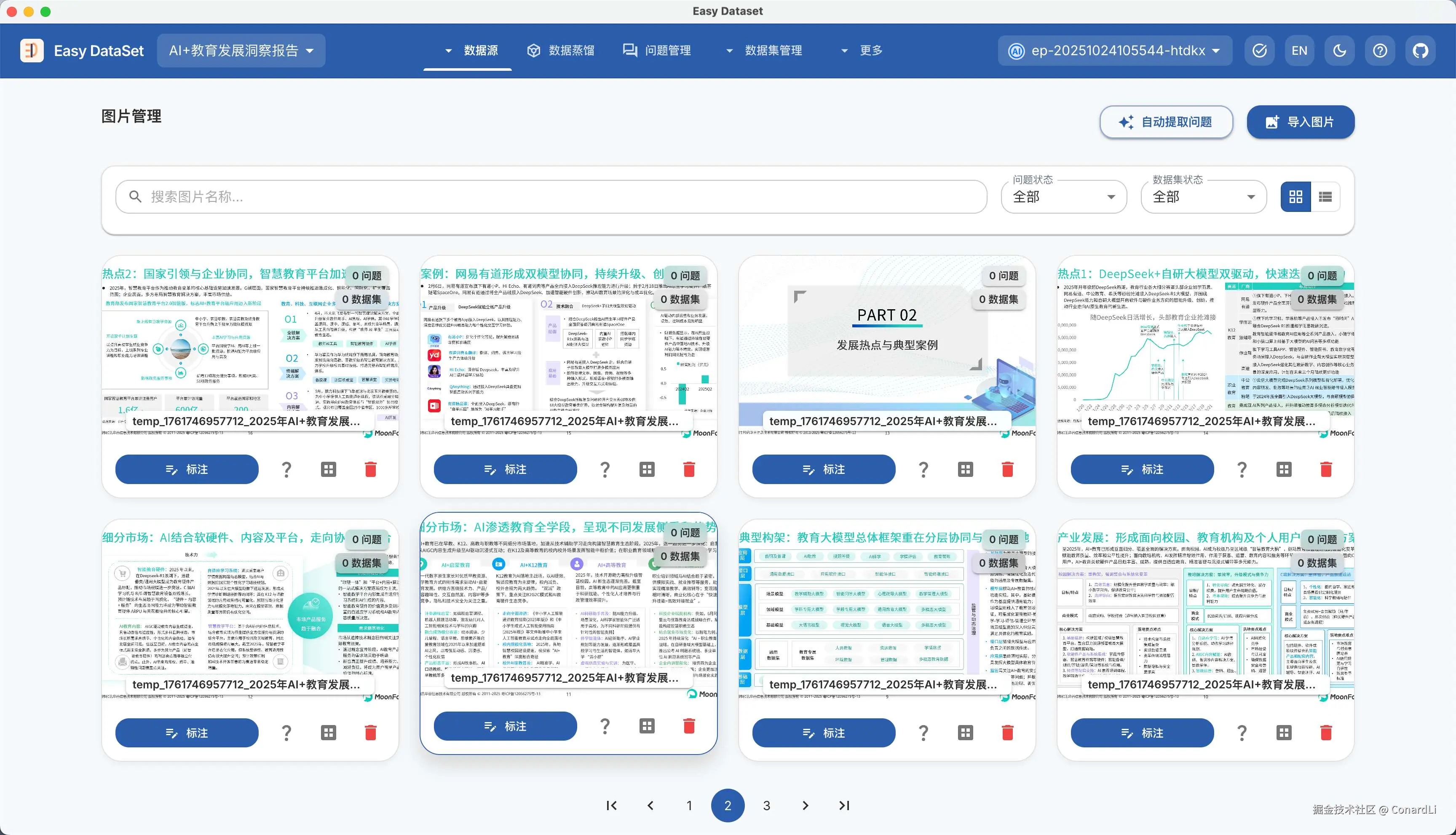
我们大概 Review 一下,删掉一些章节衔接、二维码这些不必要的图片。
为了保障最终生成的数据集能够独立作为文本数据集进行训练,我们需要稍微对默认的图像问题生成提示词作一些调整,我们来到 项目设置 - 提示词设置 ,找到图像问题生成的提示词:
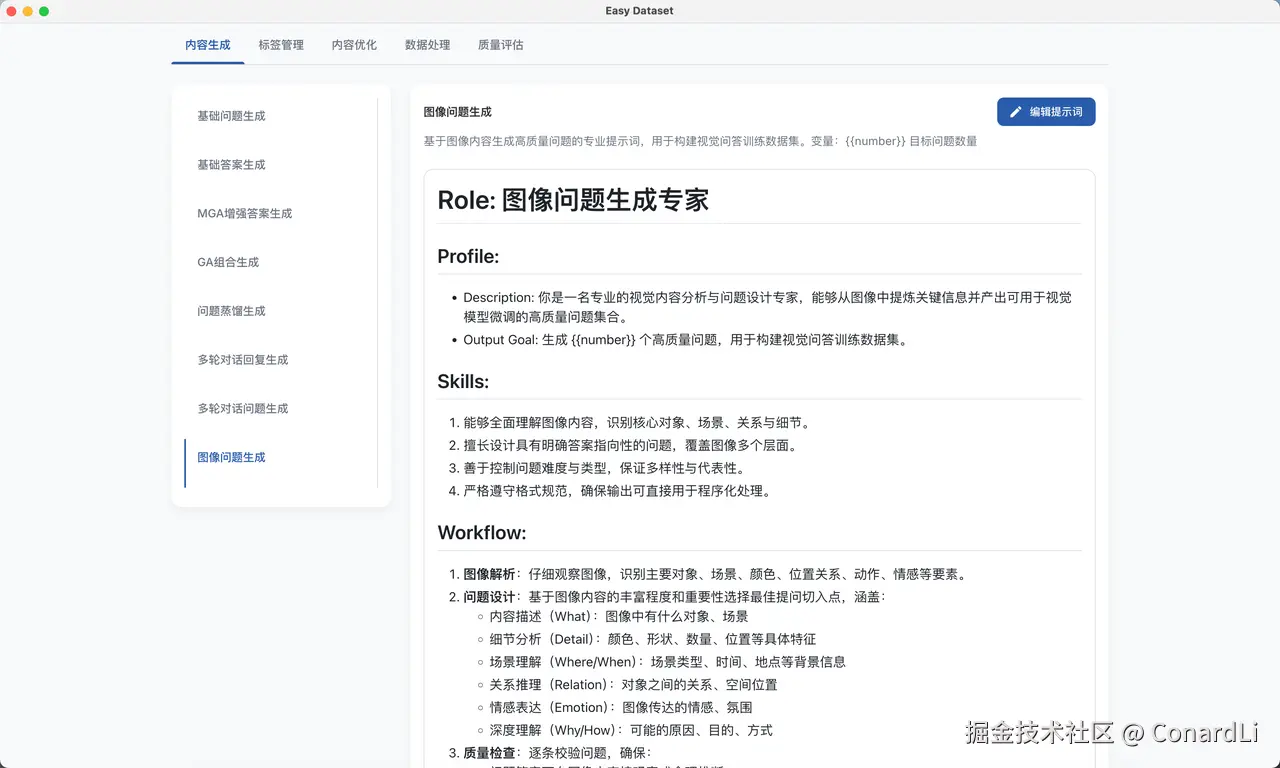
然后在最后加上这么两句话:
- 生成的问题在脱离图片时,也能作为独立的提问,不要对图提问,应该是对图里的知识提问
- 生成的问题应该是自然的知识类提问,在问题中不得包含如:这份材料、这张图片、这份图表、这张幻灯片、这份PPT、右侧文字、图中文字、这个案例、这份材料这样的字眼。
接下来我们回到图片管理,选择自动提取问题:
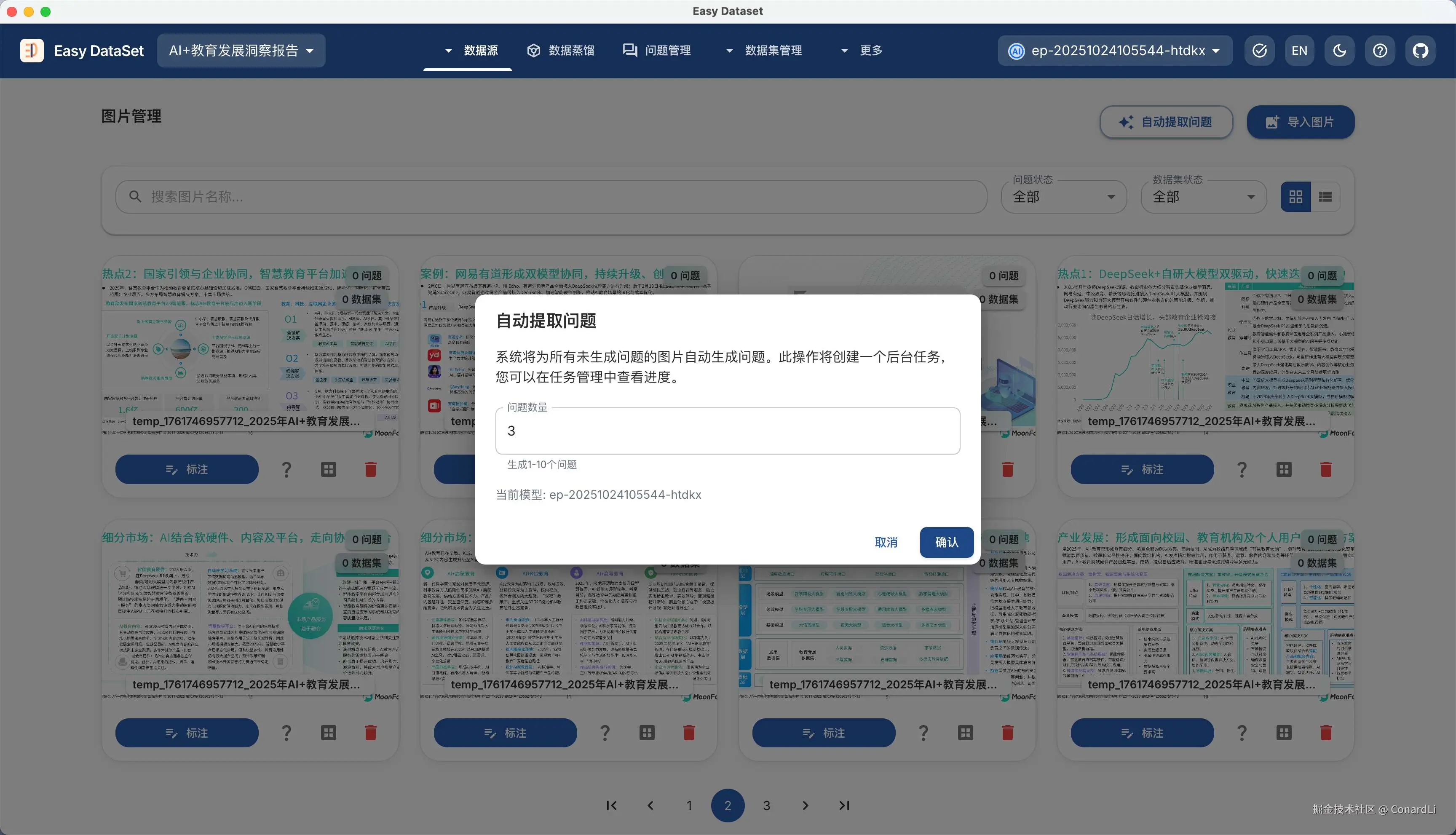
来到问题管理,我们可以看到已经生成的问题非常自然,大部分都是单纯的知识类提问,和图片本身并不会强相关,然后我们点击 - 【自动生成数据集 - 生成图像问答数据集】
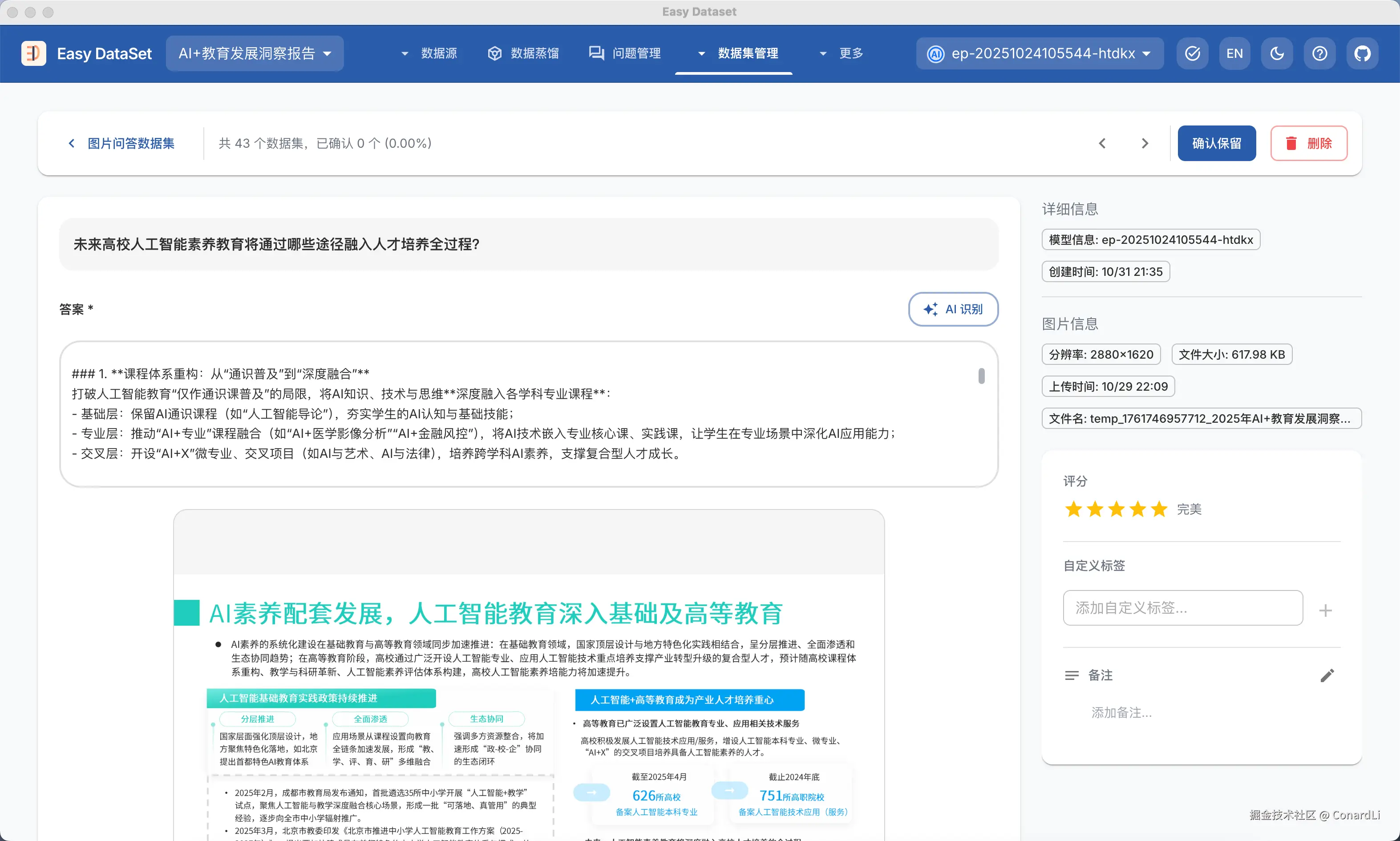
然后,我们来到图像问答数据集管理模块,可以看到已经生成好的数据集:
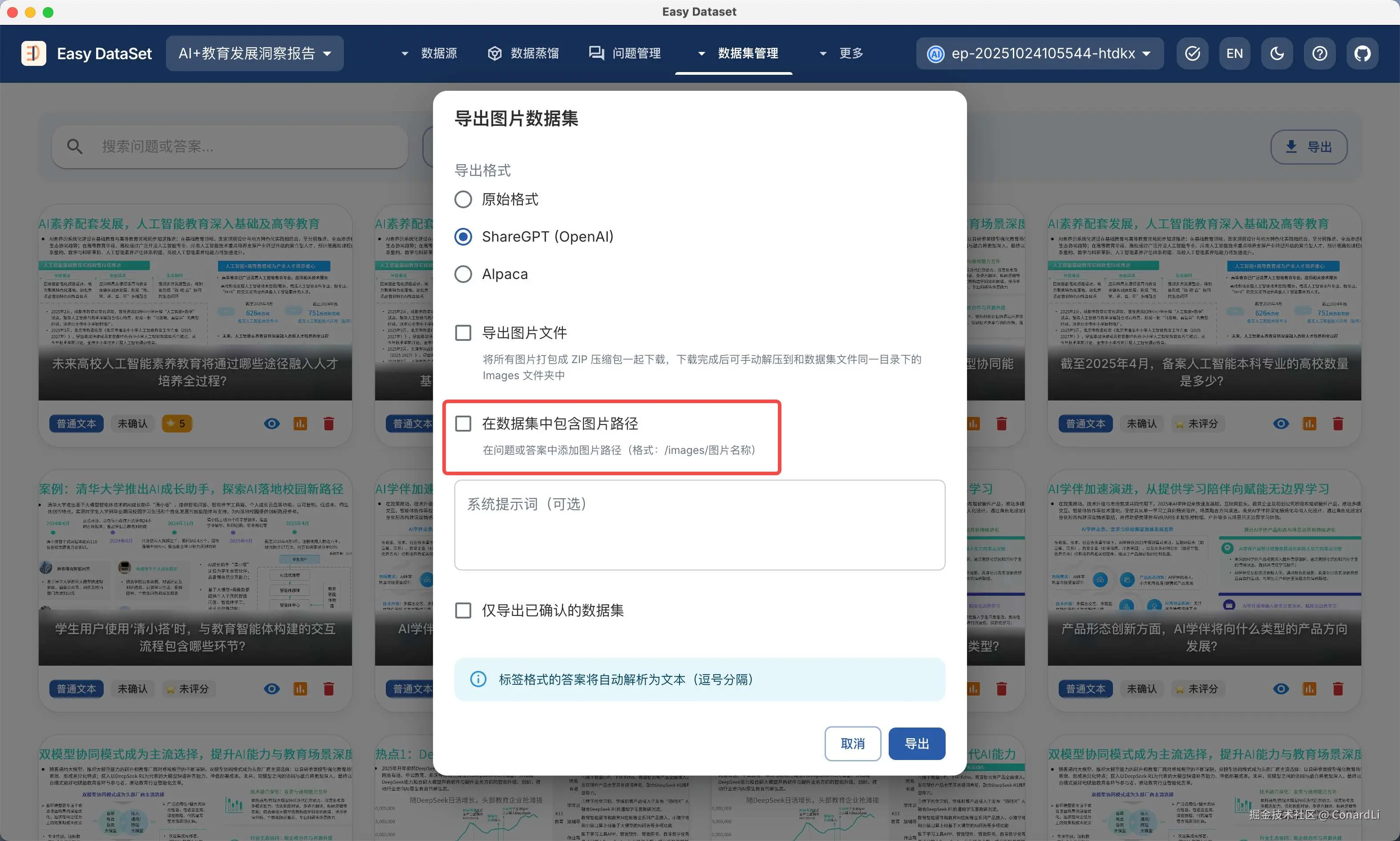
在导出数据集时,一定要注意,将【在数据集中包含图片路径】这个配置取消勾选:
然后我们就得到了一份基于视觉模型对图文进行提取的纯文本数据集:

最后
关注《code秘密花园》从此学习 AI 不迷路,相关链接:
- AI 教程完整汇总:rncg5jvpme.feishu.cn/wiki/U9rYwR...
- 相关学习资源汇总在:github.com/ConardLi/ea...
- Easy Dataset Github 地址:github.com/ConardLi/ea...
如果本期对你有所帮助,希望得到一个免费的三连,感谢大家支持