Mysql 读书笔记
索引失效
对索引字段进行条件字段表达式、函数操作
-
where a + 1 = 1000
-
where month(create_time) = 7
隐式类型转换,例如 ZT 是 varchar,会将字段转为数字比较,无法转为数字的是 0
- where ZT = 03
字符集编码转换
- utf8 -> utf8mb4,在进行 on 连接查询时会把关联字段的值从 utf8 转为 utf8mb4,造成索引失效
or 前有索引,or 后没有
- where userId = 1001 or age = 18
模糊前缀查询
- where name like '%abc'
索引 null 值,因为索引并不存储空值,需要单独判断
- where userId is NULL
联合索引的最左匹配 index(name,age)
- where age = 5
怎么对字符串建立索引
前缀索引,优点节省空间,缺点无法利用索引覆盖,增加回表次数
倒排索引,解决前缀区分度的问题,业务需要倒叙查询或展示
哈希索引,增加了新的字段,近似o(1) 的查询复杂度
Mysql 抖动
平时操作可能大多在内存中,所以性能快,但需要 flush 脏页到磁盘的时候速度就会变慢,flush 脏页一般有 4 种情况
- write 追上了 checkpoint,需要向前推进进而 flush 脏页
这种情况是要尽可能避免的,此时所有的更新都会被阻塞。
- 内存不够用,需要淘汰旧的页面引入新页,LRU 算法 flush 替换页面
这种情况是常态,InnoDB 缓冲池中的内存页一般三种状态,未被使用的,被使用但不需要刷盘的,使用了的脏页,当选择出的是脏页,就需要刷盘。
所以一次查询如果需要淘汰的脏页很多或者 redo log 写满,都会导致响应时间明显变长。
innodb_io_capacity 设置数据库磁盘的 IO 能力,即全力刷新磁盘时的速度,一般设置为磁盘的 IOPS,磁盘的 IOPS 可以利用以下指令测试:
bash
# 注意 -filename = $ filename,使用时需要自己找一个文件
fio -filename=$filename -direct=1 -iodepth 1 -thread -rw=randrw -ioengine=psync -bs=16k -size=500M -numjobs=10 -runtime=10 -group_reporting -name=mytest这个配置如果过低,会表现出服务器 IO 压力不大,但 TPS 很低。
sql
show variables like 'innodb_io_capacity'InnoDB 的刷盘速度还要参考这两个因素:一个是脏页比例,一个是 redo log 写盘速度。
innodb_max_dirty_pages_pct 脏页比例上限,默认值 75,代表 75%
sql
show variables like 'innodb_max_dirty_pages_pct' 查询当前的脏页比例
sql
select VARIABLE_VALUE into @a from global_status where VARIABLE_NAME = 'Innodb_buffer_pool_pages_dirty';
select VARIABLE_VALUE into @b from global_status where VARIABLE_NAME = 'Innodb_buffer_pool_pages_total';
select @a/@b;至于刷盘速度,系统会根据当前的脏页比例和 redo log 当前位置与 checkpoint 位置的差值计算一个值 R,按照 R% * innodb_io_capacity 的速度进行刷盘。
- Mysql 认为负载很低,主动刷脏页
由于在系统认为空闲时进行,所以一般不影响性能,但需要注意系统认为空闲的时机。
- Mysql 关闭,刷新所有脏页到硬盘
在数据库进行 flush 脏页的时候,如果脏页的旁边也是脏页,会进行"连坐",一起刷到磁盘,在机械硬盘时代能减少很多随机 IO。如果是SSD,则可以关闭这个选项,因为刷磁盘一般不是瓶颈,只刷自己反而能更快响应。
innodb_flush_neighbors 即刷新的时候是否"连坐"邻居,在 Mysql8.0 后,已经默认是 0 了。
sql
show variables like 'innodb_flush_neighbors'删除一部分数据后表大小为什么不变
数据被删除后记录所在位置会被标记为可复用,但并没有彻底释放,一个数据页上的数据都删除了,那么这个数据页就是可复用,因此表大小不变。
例如现在主键是 1 3 5 的数据,删除数据 3 后,插入一个 4, 4其实有概率复用 3 当时所在的空间,同时删除或者新增也都会导致"空洞"的情况,例如一直没有 1-5 之间的数据,那么空间就一直闲置,插入的时候如果一个数据页满了,新增数据页也会产生"空洞"。
innodb_file_per_table 每一个表数据单独存放在一个 .ibd 的文件中,5.6 之后默认开启,对于表的删除、创建逻辑更加简单。
sql
show variables like 'innodb_file_per_table'那么如果想要消除这些空洞,创建一个临时表,按照原表的顺序插入即可,以下这个命令就可以达到这个效果,逻辑也基本一致,只是这个临时表不需要我们手动建了。
sql
alter table A engine=InnoDB只是在 5.6 版本后,对流程进行了优化,之前是执行的过程中无法进行其他更新操作,即不是 online 的,后来通过生成临时文件和 redo log 重放日志实现了在线更新。
count(?) 的执行流程
先说结论: count(字段)<count(主键 id)<count(1)≈count(*)
count(字段) 返回该字段不为 null 的结果数,因此需要给 server 层返回字段并进行判断,效率最低, count(主键)同理
count(1) 遍历整张表找到 1 行,认为肯定不是 null,就+1,按行累加
count(*) 做了特殊的优化
因此平时我们使用 count(*) 即可
Order By 排序流程
以 select city,name,age from user where city = 'hangzhou' order by name 为例,city 字段有索引
全字段排序
在 sql 执行时,会根据 city 索引找到第一个值为 hangzhou 的,取出对应的 city、name、age 字段作为一条记录放入内存 sort_buffer 中,同时继续扫描到 city 不是 hangzhou的,接着对内存中的数据按照 name 排序并返回。
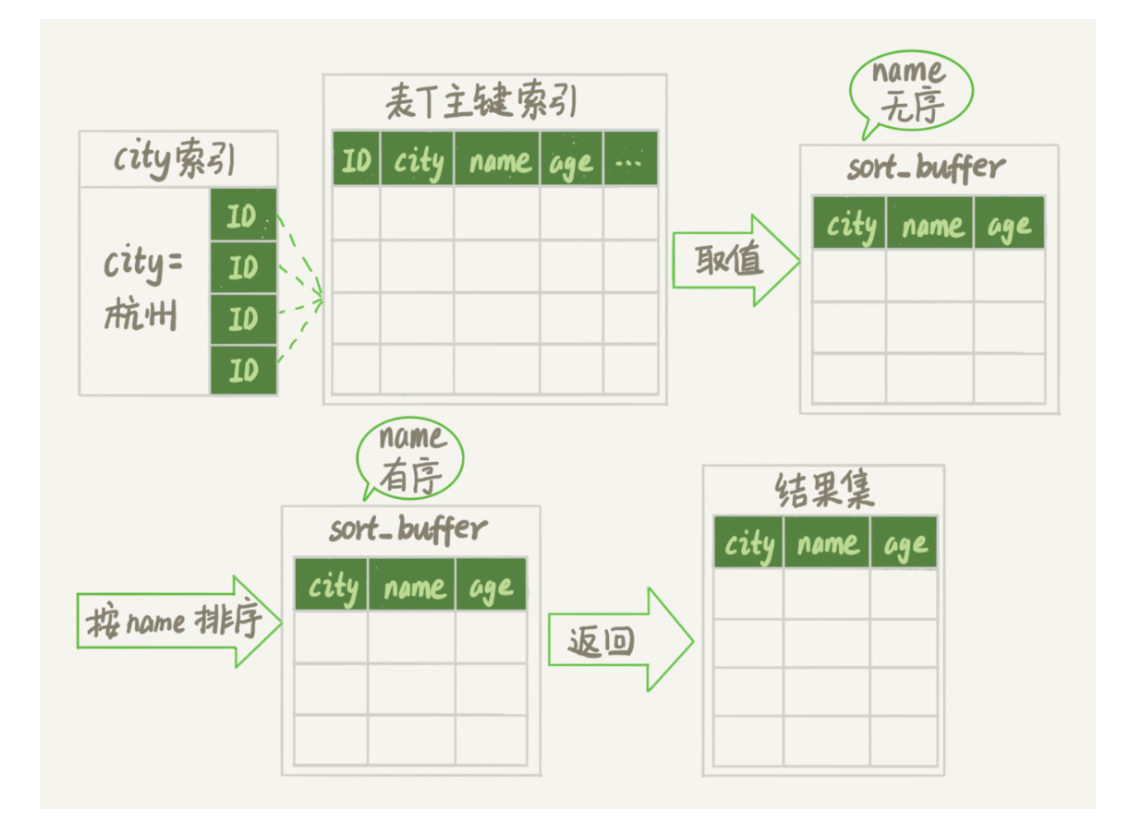
如果 sort_buffer_size 太小,内存中无法完成排序,就需要用到多个临时文件归并排序。
sql
show variables like 'sort_buffer_size'全字段排序会减少磁盘访问,因此被优先选择。
Row_ID 排序
全字段排序在需要返回的字段很多时往往需要使用临时文件,还有一种排序方式即只取 name 和 id,接着针对 name 进行排序,按照排序后的结果取 id 查 city、age 的值,这种方式排序所需要的字段只有 sort_key 和 id,sort_buffer 能存下更多的数据了。即使仍然可能用到临时文件,用的数量也比之前要少。
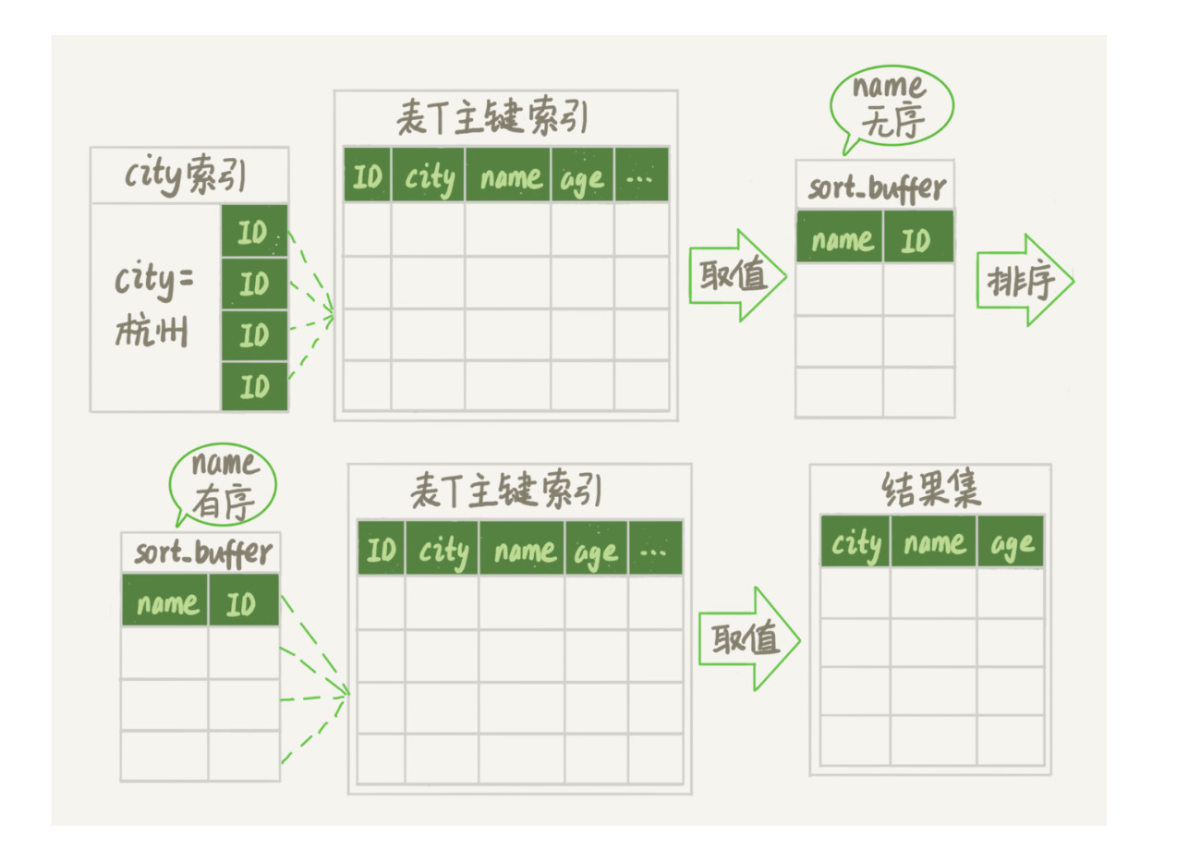
这两种算法的使用取决于 max_length_for_sort_data 参数的值,当单条记录的大小超出这个值,就使用 row_id 排序,否则使用全字段排序。
sql
show variables like 'max_length_for_sort_data'不过如果当前有一个联合索引(city,name),那么就完全不用排序,索引覆盖直接返回。
自增主键为什么不连续
自增主键不连续的本质是,当事务来申请主键时,返回一个当前的记录最大值+1后就释放锁,并不能保证事务真正执行成功,例如遇到了一个 unique 字段的重复错误,插入失败,但当前值最大已经被改了。
假设有两个并行执行的事务,在申请自增值的时候,为了避免两个事务申请到相同的自增 id,肯定要加锁,然后顺序申请。
- 假设事务 A 申请到了 id=2, 事务 B 申请到 id=3,那么这时候表 t 的自增值是 4,之后继续执行。
- 事务 B 正确提交了,但事务 A 出现了唯一键冲突。
- 如果允许事务 A 把自增 id 回退,也就是把表 t 的当前自增值改回 2,那么就会出现这样的情况:表里面已经有 id=3 的行,而当前的自增 id 值是 2。
- 接下来,继续执行的其他事务就会申请到 id=2,然后再申请到 id=3。这时,就会出现插入语句报错"主键冲突"。
而为了解决这个主键冲突,有两种方法:
- 每次申请 id 之前,先判断表里面是否已经存在这个 id。如果存在,就跳过这个 id。但是,这个方法的成本很高。因为,本来申请 id 是一个很快的操作,现在还要再去主键索引树上判断 id 是否存在。
- 把自增 id 的锁范围扩大,必须等到一个事务执行完成并提交,下一个事务才能再申请自增 id。这个方法的问题,就是锁的粒度太大,系统并发能力大大下降。
可见,这两个方法都会导致明显的性能问题。