在大型互联网公司中,分布式系统的设计和优化往往是面试的核心内容,尤其是在处理高并发、大规模数据、高可用性的场景下。本文将对一些常见的分布式面试问题进行详细解析,帮助大家更好地准备这类技术面试。
高并发系统大量请求如何优化? 编辑
编辑
高并发场景下,优化系统的目标是保证高吞吐量和低延迟,同时确保系统的稳定性。以下是一些优化措施:
-
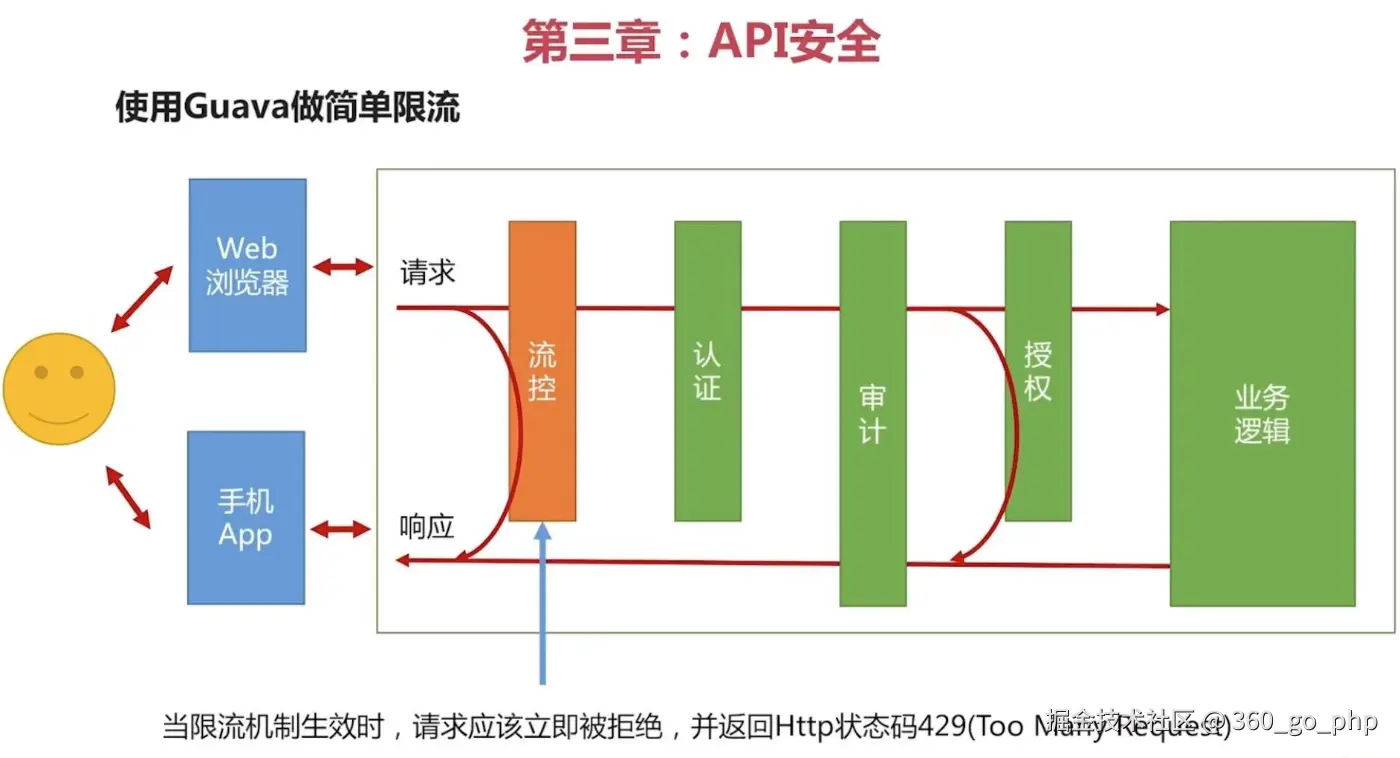
限流和流量控制 :
-
使用 令牌桶 或 漏桶算法 进行流量控制,避免短时间内大量请求集中到服务器,造成系统崩溃。
-
在高并发情况下,可以通过 API Gateway 层来进行流量控制,保证后端服务不被压垮。
 编辑
编辑
-
-
缓存 :
-
使用缓存(如 Redis 或 Memcached )将频繁访问的数据保存在内存中,减少数据库的读写压力,提升响应速度。
-
常见的缓存策略有 LRU(最近最少使用) 和 TTL(时间过期)。
-
-
异步处理和消息队列 :
-
对于一些需要耗时的操作(如发送邮件、处理图片等),可以使用异步处理,将任务推送到消息队列(如 Kafka 或 RabbitMQ )中,由后台服务异步消费。
-
消息队列能够有效缓解系统高并发情况下的压力。
-
-
数据库优化 :
-
读写分离 :通过主从复制,将读请求分散到多个从库,减轻主库压力。
-
分库分表:通过数据库分片来减少单一数据库的负载,提高数据查询的效率。
-
-
负载均衡 :
- 使用 Nginx 或 LVS 等负载均衡器,合理分配请求到不同的服务器,避免单台服务器过载。
分布式系统CAP理论
CAP理论 (Consistency, Availability, Partition tolerance)指出,在分布式系统中,不能同时满足以下三者: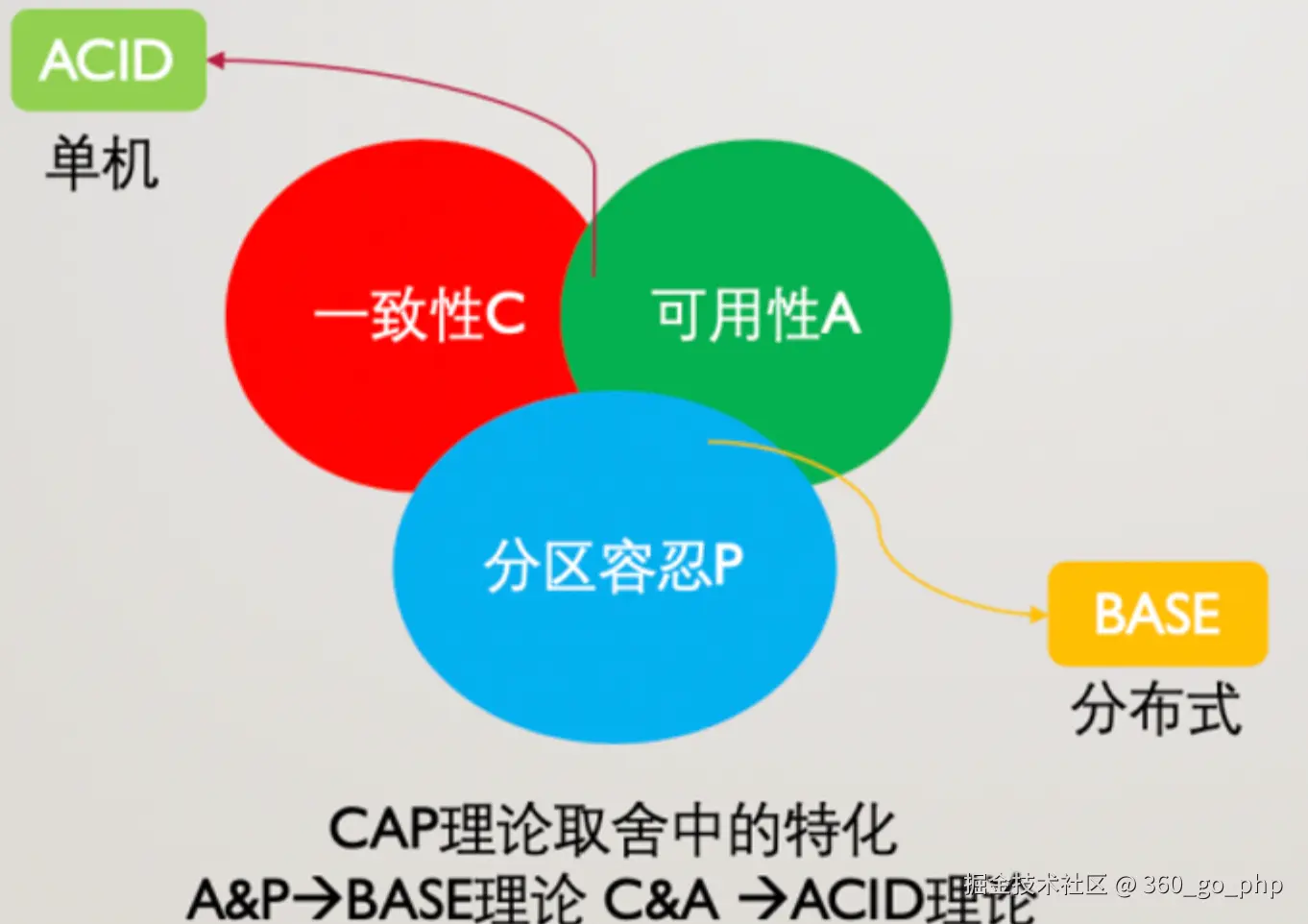 编辑
编辑
- 一致性(Consistency):所有节点的数据在同一时刻保持一致,即在某一时刻,所有客户端都能看到相同的数据。
- 可用性(Availability):每个请求都会在有限时间内得到响应,无论是否能保证返回的数据是最新的。
- 分区容忍性(Partition Tolerance):即使系统出现网络分区,系统仍然能够继续工作,并且保证节点间的通信。
CAP理论表明,分布式系统最多只能同时满足两者。具体选择哪个属性,取决于业务的需求:
- CP(Consistency + Partition tolerance) :如 Zookeeper。
- AP(Availability + Partition tolerance) :如 Cassandra 、Couchbase。
- CA(Consistency + Availability):这种情况下系统不容忍分区,适合局部系统,不适用于大规模分布式系统。
秒杀系统解决超卖问题(数据库排它锁和乐观锁CAS版本号机制) 编辑
编辑
秒杀系统的超卖问题通常出现在高并发的情况下,即多个用户同时购买同一商品,导致库存不足。常见的解决方案有:
-
数据库排它锁 :
-
使用数据库的 排它锁(Exclusive Lock) 来保证同一时间只有一个用户能够操作库存,其他请求会被阻塞,直到该请求完成。这种方式可以有效避免超卖问题,但会降低系统并发处理能力。
-
示例:
SELECT * FROM product WHERE id = ? FOR UPDATE;,这条 SQL 语句可以在读取数据时加上排他锁,避免其他请求修改库存。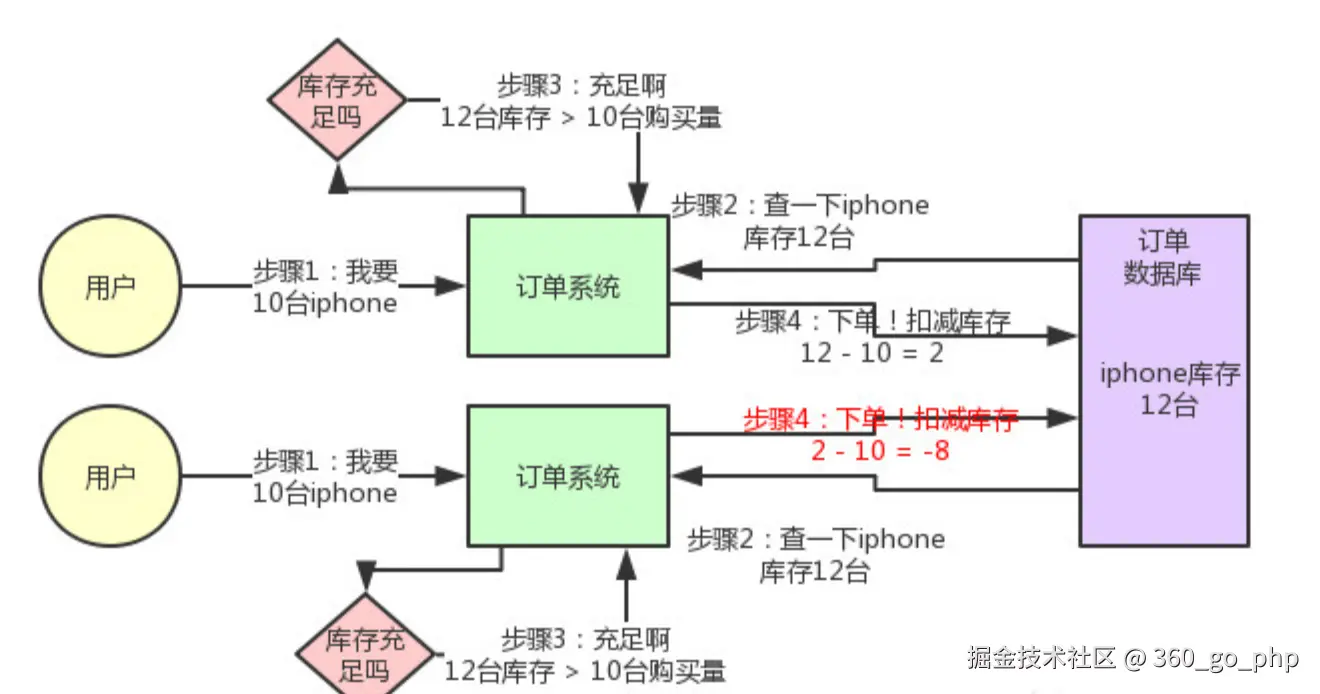 编辑
编辑
-
-
乐观锁(CAS版本号机制) :
-
使用 乐观锁 机制,通过在数据库中增加一个版本号字段,每次修改库存时都先检查版本号是否与当前一致,若一致则更新库存和版本号,否则认为发生了冲突。
-
具体实现:在更新库存时,采用
UPDATE product SET stock = stock - 1, version = version + 1 WHERE id = ? AND version = ?的方式。如果版本号不一致,表示其他用户已经修改过库存,当前请求会被拒绝。
-
BASE理论
BASE理论 是分布式系统的一种理论,它相对于传统的 ACID(原子性、一致性、隔离性、持久性)理论,提出了一种更适合分布式环境的处理方法。BASE的含义是:
- Basically Available:系统是基本可用的,即系统可以保证在大部分时间内可用,尽管可能会发生一些失效。
- Soft state:系统的状态可能是软状态,即不一定在任何时刻保持一致。分布式系统中的节点数据可能会存在短暂的不一致性。
- Eventual consistency:系统最终会保持一致性,在一定的时间窗口内,节点之间的数据会逐步同步,最终实现一致性。
BASE理论适用于 高可用性和高扩展性 的场景,特别是分布式数据库和大规模分布式系统中。
两阶段提交(2PC)
两阶段提交协议(2PC) 是分布式事务中的一种协议,目的是确保跨多个数据库或服务的事务一致性。其工作原理如下:
-
阶段一:准备阶段(Vote) :
-
事务协调者向所有参与者(即分布式节点)发送准备请求,询问它们是否能够提交事务。
-
每个参与者要么响应
YES,表示可以提交,要么响应NO,表示无法提交(如数据约束冲突或系统故障等)。
-
-
阶段二:提交阶段 :
-
如果所有参与者都响应
YES,则事务协调者向所有参与者发送提交请求,事务正式提交。 -
如果有任何一个参与者响应
NO,则协调者会向所有参与者发送回滚请求,所有事务都将回滚。
-
缺点:
- 阻塞问题:如果协调者在准备阶段后崩溃,参与者就会等待,导致阻塞。
- 单点故障:如果协调者失败,会影响整个事务的提交或回滚。
Redis分布式锁的注意事项及实现过程
Redis 分布式锁用于在多个进程或服务器间实现同步,避免并发操作导致数据的不一致性。以下是实现过程和注意事项: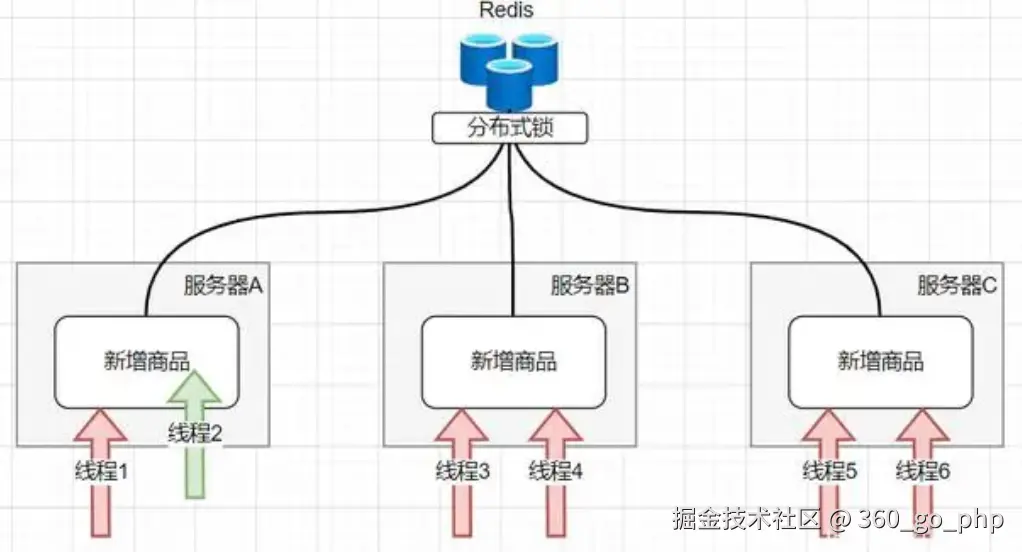 编辑
编辑
实现过程:
-
设置锁 :
使用 Redis 的
SETNX命令(Set if Not Exists)来设置锁。该命令只有在键不存在时才会设置成功。通常会设置一个超时时间,防止死锁。
bash SETNX lock_key unique_value EXPIRE lock_key 30 -
释放锁 :
释放锁时,首先需要确认锁的持有者是当前客户端。使用
GET命令验证锁的值是否与当前客户端的唯一标识一致,然后删除该键。
bash if (GET lock_key == unique_value) { DEL lock_key }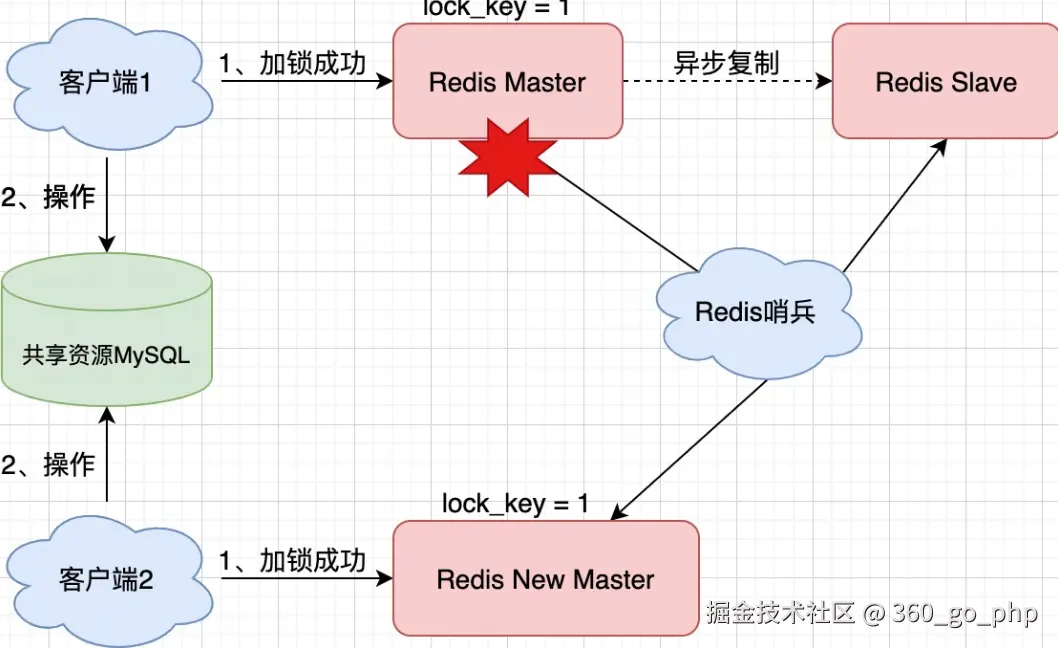 编辑
编辑
注意事项:
- 锁的超时:为了防止死锁,必须给锁设置合理的过期时间。如果客户端崩溃,锁会在超时后自动释放。
- 确保释放锁的原子性:在释放锁时要确保只有锁的持有者能够释放锁,否则可能会导致锁被错误释放。
- Redis主从同步的延迟:在高并发的环境下,Redis 的主从同步可能会有延迟,导致锁的获取和释放不及时,因此需要考虑这个因素。
总结
分布式系统的面试涉及多个方面的知识,涵盖了高并发优化、数据一致性、事务管理、分布式锁等多个技术点。深入理解这些核心概念,并能够在实际应用中灵活使用,将有助于你在大厂的技术面试中脱颖而出。