一、背 景
你是否曾在社区搜索时遇到这样的困扰:想找一双"平价学生党球鞋",结果出现的多是限量联名款?或者输入"初冬轻薄通勤羽绒服",却看到厚重登山款?这类"搜不准"的情况,正是搜索相关性技术要解决的核心问题------让搜索引擎更准确地理解用户意图,返回真正匹配的结果。今天,我们就来揭秘得物如何用大模型技术让搜索变得更"聪明"。
搜索相关性,即衡量搜索结果与用户查询的匹配程度,通俗来说就是"搜得准不准"。作为搜索体验的基石,良好的相关性能够帮助用户更顺畅地从种草走向决策,同时也对购买转化率和用户留存具有重要影响。
二、传统相关性迭代痛点
从算法层面看,搜索相关性模型需要计算用户查询与内容(包括下挂商卡)之间的相关程度。系统需要理解几十种用户意图,如品牌、系列、送礼、鉴别等,识别几十种商品属性,如人群、颜色、材质、款式,还要覆盖平台上数千个商品类目,从跑步鞋、冲锋衣到咖啡机、吹风机等等。
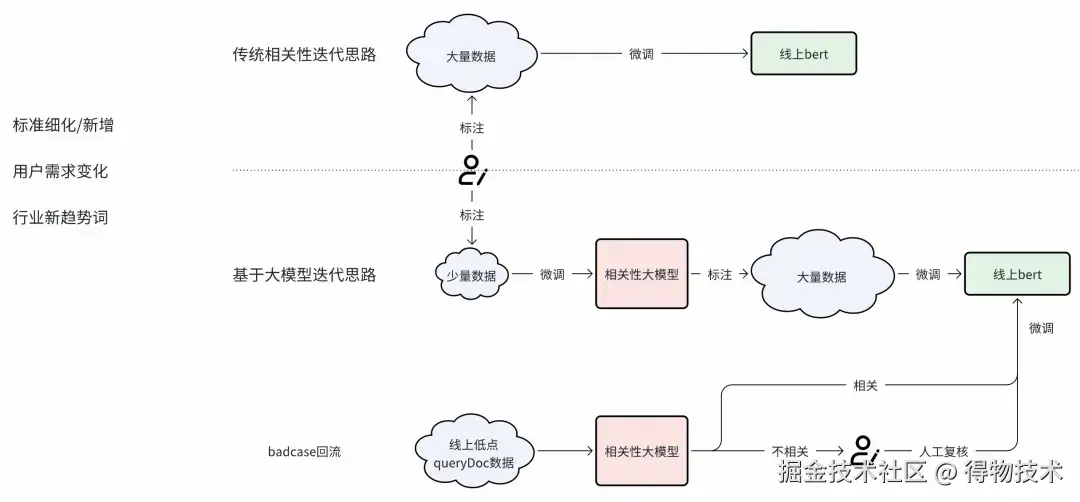
我们早期主要采用基于BERT的交互式模型,结合大量人工标注数据,来构建搜索相关性系统。然而,随着业务发展,传统方法在迭代过程中逐渐暴露出以下痛点:
- 资源消耗大,标注成本高昂:模型效果严重依赖海量人工标注数据,需千万级的查询-商品配对样本。粗略估算,完成千万级数据标注,约需几十人全年无休投入,耗时费力且成本居高不下。
- 扩展性不足,迭代响应缓慢:高度依赖人工标注的模式,导致模型难以灵活适应业务标准的频繁更新。每当新增商品类目或优化判断标准,往往需要重新标注,迭代周期长、响应速度慢。
- 泛化能力有限,长尾场景表现不佳:模型对训练集中的常见品类效果尚可,但面对新品类或小众场景时表现明显下降。例如,用户从习惯搜索"鞋服"转向"旅行攻略""美食景点"等场景时,搜索结果的相关性会大打折扣。
三、基于大模型的迭代流程
近年来,以GPT、Qwen为代表的大语言模型迅速发展,正在逐渐渗透和重塑搜索领域的各个环节。在搜索相关性任务上,大模型相比传统方法体现出三方面优势:
- 理解能力更强,效果天花板显著提升:百亿甚至千亿级别的参数量,使大模型能够捕捉更复杂的语言表达和微妙语境,且具备不错的逻辑推理能力,这在多个权威评测中得到验证,为相关性效果突破提供了新的可能性。
- 知识储备丰富,泛化能力大幅增强:基于海量互联网数据的预训练,让大模型内置了丰富的世界知识。面对未见过的新查询或内容类型,区别于小模型的"死记硬背",大模型可以灵活的"举一反三",提升系统在长尾场景下的鲁棒性。
- 数据需求降低,迭代效率成倍提升:大模型本身就是一座"知识宝库",通过提示词工程或少量样本微调,即可达到理想的业务效果。这降低了对大规模人工标注的依赖,为算法快速迭代奠定了基础。
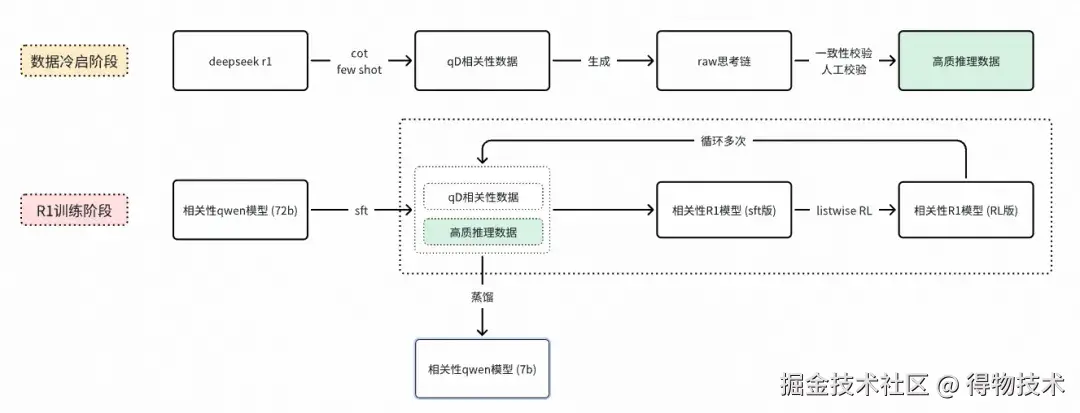
基于这些特性,我们围绕大模型优化了相关性迭代的整个流程。首先是知识蒸馏新路径,传统BERT模型训练需要千万级人工标注,成本高周期长。现在,我们仅用万级数据训练大模型,再通过数据蒸馏的方式将其能力迁移至线上小模型。这一转变不仅提升了效果上限,也实现了算法的低成本快速迭代。
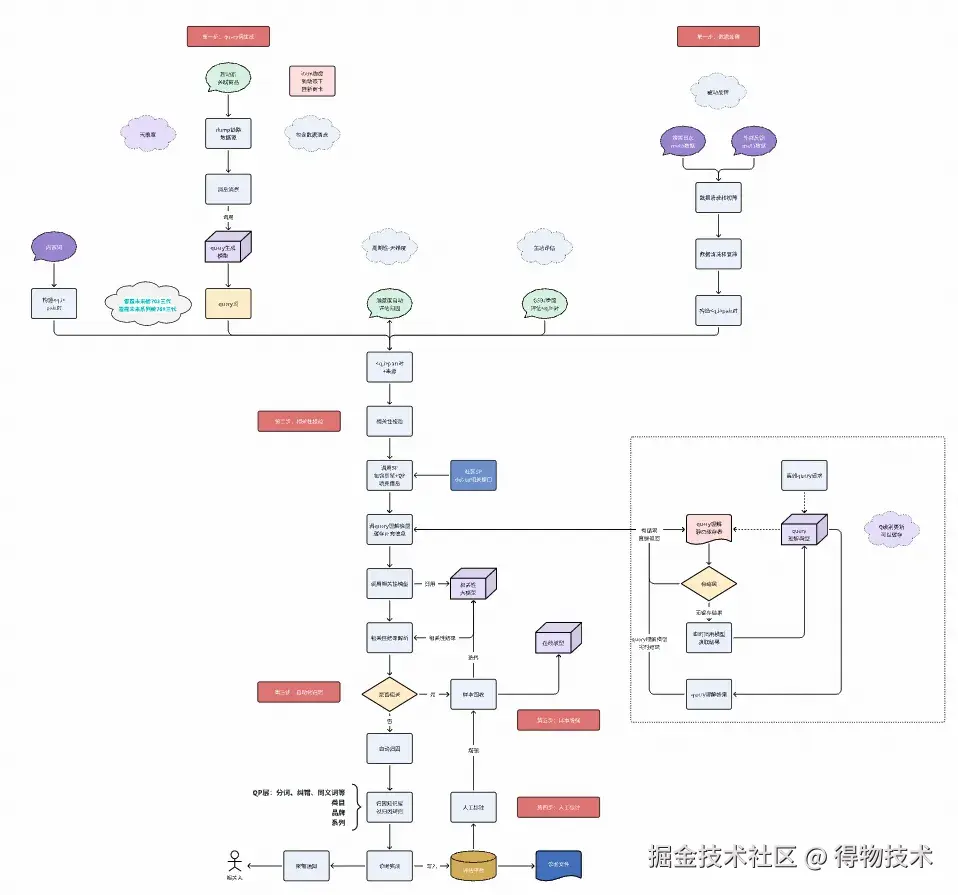
其次,我们将大模型深度融入"相关性问题发现 -> 解决"的闭环,覆盖新词诊断、badcase监控回流、GSB评估等环节。以每日badcase回流为例:对于低点查询,我们调用大模型进行相关性判断,经人工复核后进入线上bert模型训练池,形成持续优化闭环。这一流程重构,更大范围降低了对人工标注的依赖,提升了算法迭代效率。下图展示了新词生成 -> 相关性校验 -> 自动化归因 -> 人工标注 -> 样本增强的具体流程。
四、大模型建模搜索相关性
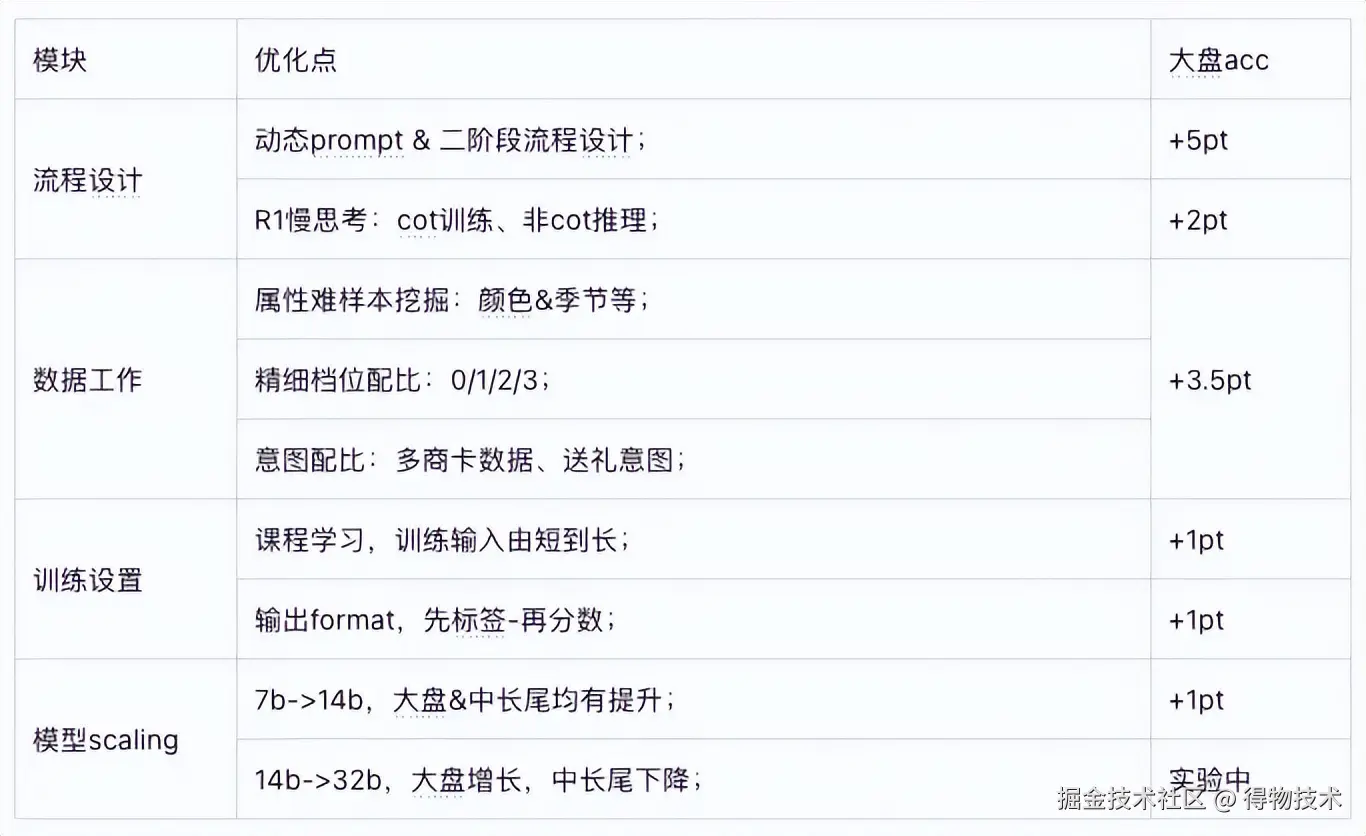
项目初期,大模型技术在搜索领域的应用尚处探索阶段,缺乏可借鉴的成熟方案。基于对算法原理与业务场景的理解,我们围绕"如何让大模型更接近人类的思考方式"这一目标,设计并实践了两项核心优化:
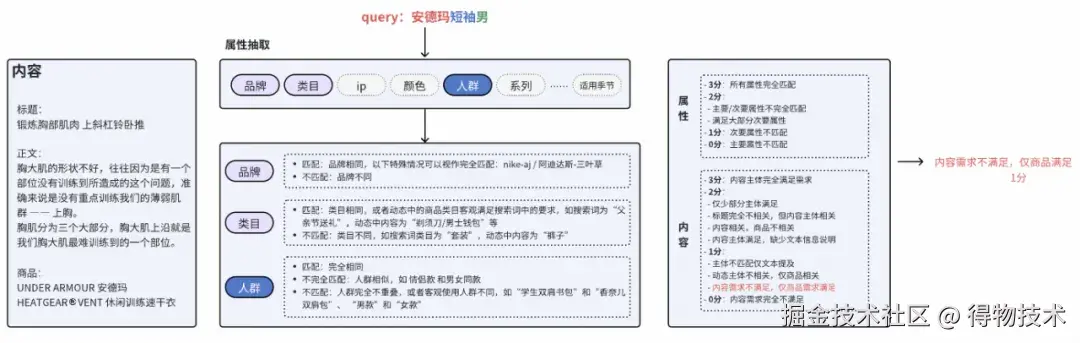
二阶段流程 :我们观察到,人类判断相关性时通常遵循"先理解意图,再验证匹配"的认知过程。基于这一洞察,我们将端到端的相关性判断拆分为两个阶段。一阶段侧重理解用户查询,从中抽取出品牌、系列、适用人群等关键属性。二阶段则对内容进行属性解析,并逐一判断其与查询意图的一致性。最终综合多属性判断结果,输出相关性分档及对应依据。这一结构化的判断方式使模型大盘准确率从75%提升至80.95%,在理解能力上取得了可验证的进展。
R1慢思考 :随着年初DeepSeek R1的发布,我们将其"慢思考"机制引入相关性建模,使模型能够生成思维链进行分步推理,例如:"用户搜索'夏季运动鞋'→内容提及商品为跑步鞋→材质透气→符合夏季需求→判定相关"。在数据冷启阶段,我们调用开源推理模型,生成原始思考链,通过结果一致性校验&人工校验,过滤出少量高质cot推理数据。训练阶段,我们通过混合少量cot推理数据和大量常规数据的方式微调模型,使模型能将少量cot推理路径泛化到更多常规数据上。推理阶段,这种混合训练方式,也使模型能省略思维链的输出,同时保持分档准确性,从而在效果与效率之间取得平衡。该方法使大盘准确率从80.95%进一步提升至83.1%,中长尾场景准确率从76.98%大幅提升到81.45%,显示出良好的泛化能力。
以下是两个思维链示例:


基于大模型的技术演进并非一蹴而就,最初我们基于BERT训练数据,构建的初版相关性大模型效果有限,甚至略逊于线上BERT小模型基线(准确率 75% vs 75.2%)。通过后续一系列优化,如精细调整数据配比、引入课程学习等策略,模型效果逐步提升,最终大盘准确率提升约10个百分点,达到86.67%,验证了大模型在搜索相关性任务上的潜力。具体消融实验如下:
五、效果
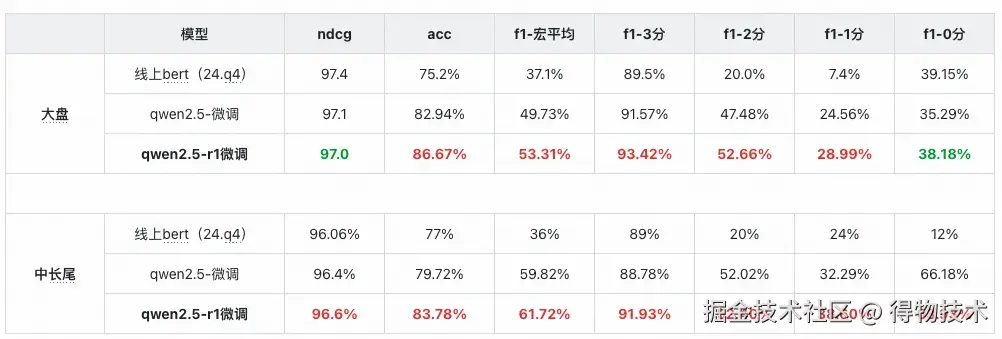
经过两个季度的迭代优化,相关性大模型在效果上已稳定超过线上bert模型,在大盘测试集上,准确率提升11.47%,宏平均F1值提升16.21%。在样本量较少的档位上提升更为显著,2分档F1提升32.66%,1分档F1提升21.59%。目前,模型在NDCG和0分F1两个指标上仍有提升空间,这也将是下一阶段的优化重点。在中长尾场景下,大模型展现出更好的泛化能力,测试集准确率提升6.78%,宏平均F1提升25.72%,其中0分档F1提升达51.93%,表现全面优于线上基线模型。详情指标如下表:
六、落地
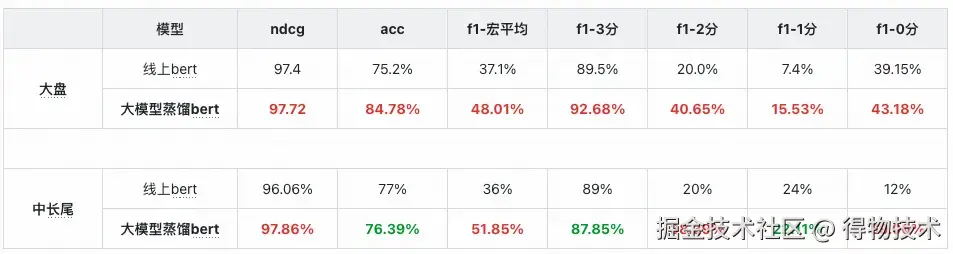
通过大模型标注千万级数据,并结合多版数据蒸馏策略进行A/B实验,线上相关性badcase率实现显著下降:大盘降低5.39个百分点,中长尾场景降低10.82个百分点,累计节约标注成本达百万级别。
离线评估方面,经过蒸馏后的线上BERT模型在大盘准确率上提升9.58%,宏平均F1提升10.91%;中长尾场景下准确率略有波动(-0.61%),但宏平均F1仍提升15.85%,体现出良好的泛化稳定性。
线上bert指标对比
后续方向
- 当前大模型在分档能力上优于BERT,但在NDCG排序指标上仍有差距。我们正在探索基于生成式Listwise强化学习方法,建模内容间的偏序关系,以提升同一查询下的排序质量。
- 基于大模型的数据蒸馏策略已逐步接近瓶颈。我们正尝试更高ROI的落地方案,包括logits蒸馏策略,并推进大模型直接承接部分线上流量的可行性验证。
- 大模型本身的能力边界仍随开源基座模型和生成式搜推技术的发展而不断拓展,我们将持续跟进,探索效果上限的进一步突破。
七、结语
搜索相关性的优化,是一场没有终点的长跑。通过引入大模型技术,我们在理解用户意图、提升匹配精度上取得了阶段性进展,也为后续的迭代开辟了新的路径。未来,我们将紧跟大模型技术发展趋势,同时紧密结合业务场景,推动搜索体验向更智能、更精准的方向稳步演进。
往期回顾
-
RAG---Chunking策略实战|得物技术
-
告别数据无序:得物数据研发与管理平台的破局之路
-
从一次启动失败深入剖析:Spring循环依赖的真相|得物技术
-
Apex AI辅助编码助手的设计和实践|得物技术
-
从 JSON 字符串到 Java 对象:Fastjson 1.2.83 全程解析|得物技术
文 /若水、兰溪
关注得物技术,每周更新技术干货
要是觉得文章对你有帮助的话,欢迎评论转发点赞~
未经得物技术许可严禁转载,否则依法追究法律责任。