从自然语言到SQL的智能转换之旅------基于.NET与Semantic Kernel的企业级实践
📖 引言:当AI遇见数据库
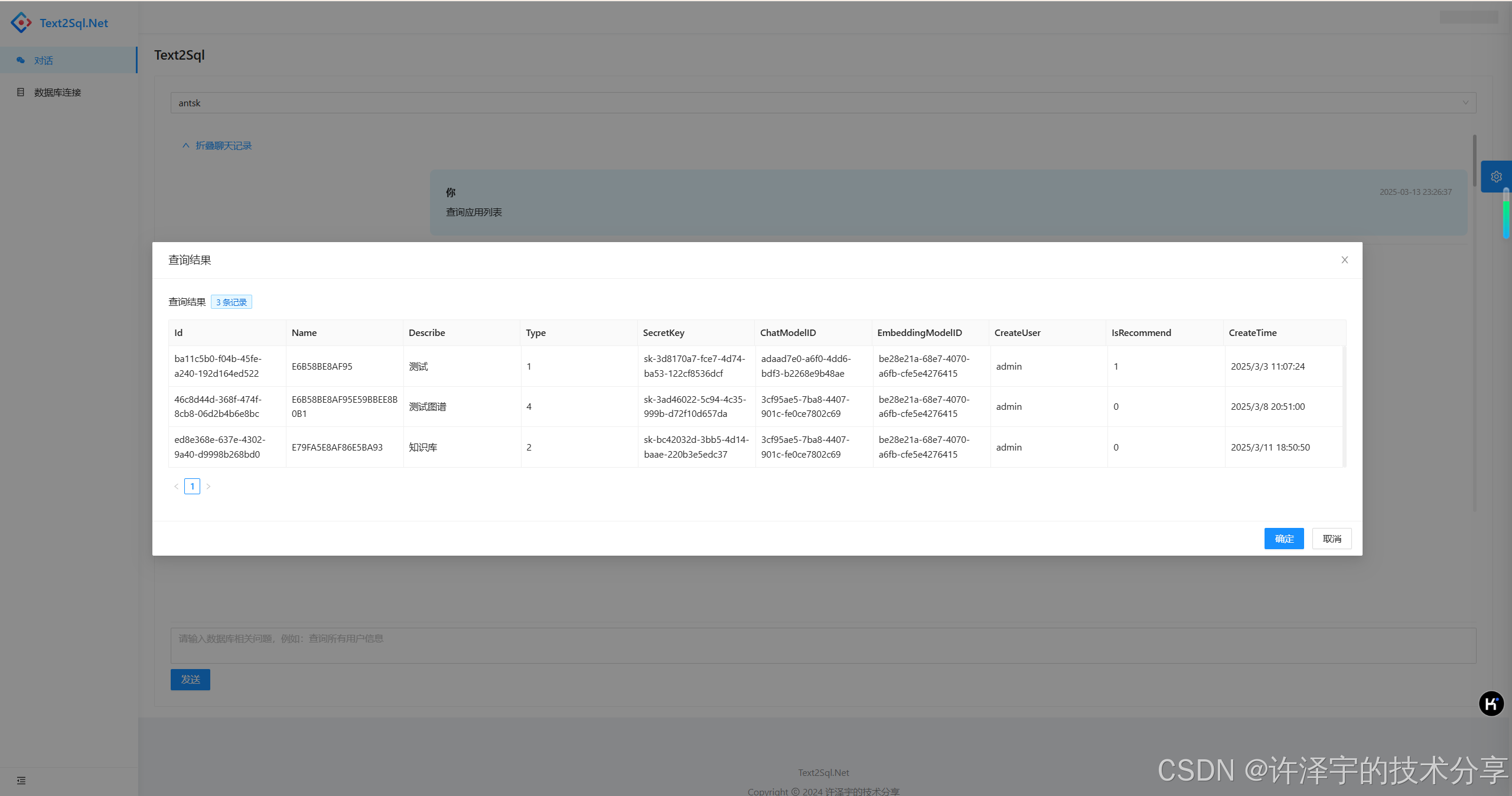
想象一下这样的场景:产品经理走到你面前说"帮我查一下上个月销售额最高的前10个产品",你不用打开SQL客户端,不用回忆表结构,甚至不用写一行代码,只需要把这句话原封不动地"告诉"数据库,几秒钟后,结果就呈现在眼前。
这不是科幻,这就是 Text2Sql.Net 正在做的事情。
在数据驱动的时代,SQL依然是连接人与数据的桥梁。但让我们面对现实:不是每个人都会写SQL,即使是资深开发者,面对复杂的多表关联查询时也会头疼。更别提那些只想快速获取数据洞察的业务人员了。
Text2Sql.Net 是一个基于 .NET 平台的开源项目,它利用大语言模型(LLM)的强大能力,将自然语言转换为精确的SQL查询。但它不仅仅是简单的"翻译"工具------它集成了向量搜索、智能Schema推断、执行反馈优化、问答示例学习等多项前沿技术,构建了一个完整的Text2SQL解决方案。
本文将深入剖析 Text2Sql.Net 的技术架构、核心算法和工程实践,带你了解如何构建一个生产级的Text2SQL系统。
🎯 项目概览:不只是"翻译官"
核心特性一览
Text2Sql.Net 的设计哲学是:让AI理解你的数据,而不是让你适应AI。它提供了以下核心能力:
-
多数据库支持:无缝支持 SQL Server、MySQL、PostgreSQL、SQLite 四大主流数据库
-
智能Schema理解:基于向量搜索的语义化表结构匹配
-
上下文感知对话:支持多轮对话,理解指代关系和增量查询
-
执行反馈优化:SQL执行失败时自动分析错误并优化重试
-
问答示例学习:通过Few-shot Learning提升特定场景的准确率
-
MCP协议集成:与Cursor、Trae等IDE无缝对接,开发者的贴身助手
-
企业级架构:基于依赖注入、仓储模式、服务分层的可扩展设计
技术栈:站在巨人的肩膀上
核心框架:.NET 6/7/8 (跨平台支持)
AI引擎:Microsoft Semantic Kernel (语义内核)
向量存储:SQLite Memory Store / PostgreSQL pgvector
ORM框架:SqlSugar (多数据库抽象)
前端框架:Blazor Server (响应式UI)
协议支持:Model Context Protocol (MCP)这个技术栈的选择颇有讲究:
-
Semantic Kernel 是微软推出的AI编排框架,相比LangChain更贴近.NET生态
-
SqlSugar 提供了统一的数据库访问接口,让多数据库支持变得优雅
-
Blazor 实现了前后端统一的C#开发体验
-
MCP协议 让Text2SQL能力可以被各种工具调用,真正实现"能力即服务"
🏗️ 架构设计:分层解耦的艺术
整体架构图
Text2Sql.Net 采用经典的三层架构,但在每一层都做了精心设计:
┌─────────────────────────────────────────────────────────┐
│ 表现层 (Presentation) │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │ Blazor Pages │ │ MCP Server │ │ REST API │ │
│ └──────────────┘ └──────────────┘ └──────────────┘ │
└─────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────┐
│ 服务层 (Service) │
│ ┌──────────────────────────────────────────────────┐ │
│ │ ChatService (对话管理) │ │
│ │ SchemaTrainingService (Schema训练) │ │
│ │ SemanticService (语义搜索) │ │
│ │ SqlExecutionService (SQL执行) │ │
│ │ QAExampleService (示例管理) │ │
│ │ IntelligentSchemaLinkingService (智能关联) │ │
│ │ ExecutionFeedbackOptimizer (反馈优化) │ │
│ │ ConversationStateManager (对话状态) │ │
│ └──────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────┐
│ 数据访问层 (Repository) │
│ ┌──────────────────────────────────────────────────┐ │
│ │ DatabaseConnectionRepository (连接配置) │ │
│ │ ChatMessageRepository (聊天记录) │ │
│ │ DatabaseSchemaRepository (Schema存储) │ │
│ │ SchemaEmbeddingRepository (向量嵌入) │ │
│ │ QAExampleRepository (问答示例) │ │
│ └──────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────┐
│ 外部服务 (External) │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌────────┐ │
│ │ OpenAI │ │ Vector │ │ Business │ │ MCP │ │
│ │ API │ │ DB │ │ DB │ │ Client │ │
│ └──────────┘ └──────────┘ └──────────┘ └────────┘ │
└─────────────────────────────────────────────────────────┘设计亮点
1. 服务分层的智慧
Text2Sql.Net 将复杂的Text2SQL流程拆解为8个独立的服务,每个服务职责单一:
-
ChatService:总指挥,协调整个查询流程
-
SchemaTrainingService:负责数据库表结构的"学习"和向量化
-
SemanticService:提供语义搜索能力的底层支撑
-
IntelligentSchemaLinkingService:智能推断查询需要哪些表
-
ExecutionFeedbackOptimizer:SQL执行失败时的"医生"
-
ConversationStateManager:多轮对话的"记忆管家"
-
QAExampleService:管理和匹配问答示例
-
SqlExecutionService:安全执行SQL的"执行者"
这种设计带来的好处是显而易见的:
-
可测试性:每个服务都可以独立测试
-
可扩展性:需要新功能?加个服务就行
-
可维护性:职责清晰,bug容易定位
2. 依赖注入的优雅实践
项目使用了一个巧妙的自动注册机制。通过自定义的 ServiceDescriptionAttribute,服务可以声明自己的生命周期:
[ServiceDescription(typeof(IChatService), ServiceLifetime.Scoped)]
public class ChatService : IChatService
{
// 服务实现
}这样,在启动时只需一行代码就能注册所有服务:
builder.Services.AddText2SqlNet();这种设计既保持了代码的整洁,又避免了手动注册服务时的遗漏和错误。
3. 仓储模式的数据抽象
所有数据访问都通过Repository接口进行,这带来了两个好处:
-
数据库无关性:切换数据库只需修改配置,不影响业务逻辑
-
便于Mock:单元测试时可以轻松替换为内存实现
🧠 核心技术解析:魔法背后的原理
一、Schema训练:让AI"认识"你的数据库
Text2SQL的第一步,也是最关键的一步,就是让AI理解数据库的结构。Text2Sql.Net 采用了向量化Schema的方案。
训练流程

关键代码逻辑:
// 1. 构建包含所有列信息的表描述文本
StringBuilder tableDescription = new();
tableDescription.AppendLine($"表名: {table.TableName}");
tableDescription.AppendLine($"描述: {table.Description ?? "无描述"}");
// 2. 添加外键关系信息
if (table.ForeignKeys != null && table.ForeignKeys.Count > 0)
{
tableDescription.AppendLine("外键关系:");
foreach (var fk in table.ForeignKeys)
{
tableDescription.AppendLine($" - {fk.RelationshipDescription}");
}
}
// 3. 添加列信息
tableDescription.AppendLine("列信息:");
foreach (var column in table.Columns)
{
tableDescription.AppendLine(
$" - 列名: {column.ColumnName}, " +
$"类型: {column.DataType}, " +
$"主键: {(column.IsPrimaryKey ? "是" : "否")}, " +
$"可空: {(column.IsNullable ? "是" : "否")}, " +
$"描述: {column.Description ?? "无描述"}"
);
}
// 4. 生成向量并存储
await textMemory.SaveInformationAsync(
connectionId,
id: $"{connectionId}_{table.TableName}",
text: JsonConvert.SerializeObject(tableEmbedding)
);设计亮点
-
富文本描述:不仅包含表名和列名,还包含数据类型、约束、外键关系等丰富信息
-
分表存储:每个表单独向量化,便于精确匹配
-
增量训练:支持只训练选定的表,避免全量扫描的性能开销
-
多数据库适配:针对不同数据库(SQLite、MySQL、PostgreSQL、SQL Server)使用不同的元数据查询策略
二、智能Schema Linking:找到"对的表"
当用户输入查询时,系统需要从可能有上百张表的数据库中,找出相关的表。这就是 Schema Linking 问题。
动态阈值搜索策略
Text2Sql.Net 实现了一个聪明的动态阈值算法:
double relevanceThreshold = 0.7; // 初始阈值较高
int minTablesRequired = 1; // 至少需要1张表
int maxTables = 5; // 最多返回5张表
// 动态降低阈值直到找到足够的表
while (relevanceThreshold >= 0.4 && relevantTables.Count < minTablesRequired)
{
await foreach (var result in memory.SearchAsync(
connectionId,
userMessage,
limit: maxTables,
minRelevanceScore: relevanceThreshold))
{
searchResults.Add(result);
}
// 解析结果...
if (relevantTables.Count < minTablesRequired)
{
relevanceThreshold -= 0.1; // 降低阈值重试
}
}为什么这样设计?
-
高精度优先:先用高阈值(0.7)搜索,确保找到的表高度相关
-
兜底策略:如果找不到,逐步降低阈值(0.6、0.5、0.4),避免"一无所获"
-
性能平衡:限制最多返回5张表,避免给LLM过多无关信息
表关联推断:补全"缺失的拼图"
找到相关表后,系统还会智能推断关联表。比如用户问"查询订单和客户信息",系统找到了Orders表,但可能还需要Customers表。
推断策略:
-
外键向外扩展:查找当前表引用的其他表
-
外键向内扩展:查找引用当前表的其他表
-
中间表识别:识别连接多个已知表的中间表(多对多关系)
// 查找引用源表的外表
foreach (var table in allTables)
{
bool isReferencing = table.ForeignKeys.Any(
fk => fk.ReferencedTableName == sourceTable.TableName
);if (isReferencing) { extendedTables.Add(table); }}
// 识别中间表(连接两个或更多已知表)
var referencedTables = table.ForeignKeys
.Select(fk => fk.ReferencedTableName)
.Where(t => currentTableNames.Contains(t))
.Distinct()
.ToList();if (referencedTables.Count >= 2)
{
// 这是一个中间表
extendedTables.Add(table);
}
这种设计让系统能够理解数据库的"关系网络",即使用户没有明确提到某些表,系统也能智能补全。
三、问答示例学习:Few-shot的威力
Text2Sql.Net 引入了 QA Example System,这是提升准确率的秘密武器。
工作原理
-
示例向量化:将历史的问答对(问题+SQL)向量化存储
-
语义匹配:用户提问时,搜索最相似的示例
-
Few-shot Prompting:将相关示例作为上下文提供给LLM
// 获取相关示例
var relevantExamples = await _qaExampleService.GetRelevantExamplesAsync(
connectionId,
userMessage,
limit: 3,
minRelevanceScore: 0.6
);// 格式化为Prompt
string examplesPrompt = _qaExampleService.FormatExamplesForPrompt(relevantExamples);// 示例格式:
// 以下是一些相关的问答示例,请参考这些示例的模式和风格来生成SQL查询:
//
// 示例 1:
// 问题: 查询最近一个月的活跃用户数量
// SQL: SELECT COUNT(DISTINCT user_id) FROM user_activities
// WHERE activity_date >= DATE_SUB(NOW(), INTERVAL 1 MONTH)
// 说明: 统计最近30天内有活动记录的独立用户数量
示例来源
-
手动创建:管理员预先创建的高质量示例
-
修正生成:用户修正错误SQL后自动创建示例
-
使用统计:记录每个示例的使用次数和效果
这种设计让系统能够"从错误中学习",越用越准确。
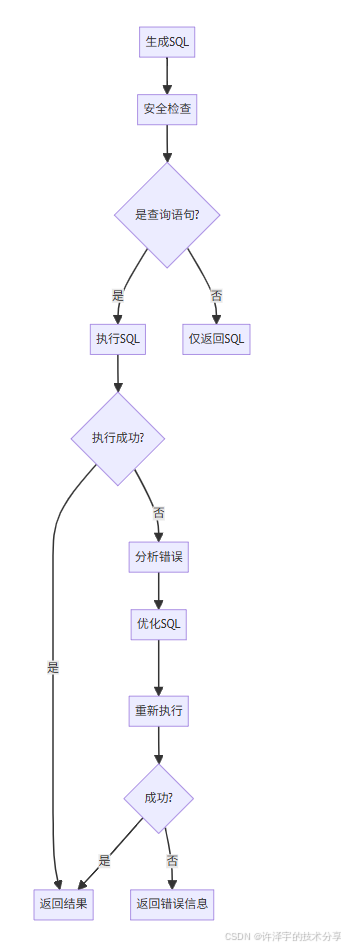
四、执行反馈优化:自我修复的SQL
SQL生成后不是直接返回给用户,而是先尝试执行。如果执行失败,系统会自动分析错误并优化。
优化流程
关键代码:
// 执行反馈优化
var optimizationResult = await _feedbackOptimizer.OptimizeWithFeedbackAsync(
connectionId,
userMessage,
schemaJson,
sqlQuery
);
// 优化器会:
// 1. 执行SQL
// 2. 如果失败,将错误信息和原SQL一起发给LLM
// 3. LLM分析错误原因(语法错误、表名错误、列名错误等)
// 4. 生成优化后的SQL
// 5. 重新执行
// 6. 记录优化步骤安全检查
系统会检查SQL的类型,只有SELECT查询才会自动执行,INSERT/UPDATE/DELETE等操作性语句只生成不执行:
var isSafeQuery = await CheckSqlAsync(sqlQuery);
if (!isSafeQuery)
{
return new ChatMessage
{
Message = "由于安全控制,仅支持查询语句自动执行,操作性语句需要手动执行",
SqlQuery = sqlQuery
};
}这种设计在便利性和安全性之间取得了平衡。
五、多轮对话管理:理解上下文
Text2Sql.Net 支持多轮对话,能够理解指代关系和增量查询。
对话类型识别
public enum FollowupQueryType
{
NewQuery, // 全新查询
Refinement, // 细化查询(加条件)
Expansion, // 扩展查询(加字段)
Clarification, // 澄清查询(修正错误)
Aggregation // 聚合查询(统计分析)
}指代消解
当用户说"再加上销售额"时,系统需要知道"再加上"是指在之前的查询基础上添加字段:
// 分析查询类型
var followupType = await _conversationManager.AnalyzeFollowupQueryAsync(
connectionId,
userMessage
);
// 解析指代关系
var resolvedMessage = await _conversationManager.ResolveCoreferencesAsync(
connectionId,
userMessage
);
// 处理增量查询
if (followupType != FollowupQueryType.NewQuery)
{
resolvedMessage = await _conversationManager.ProcessIncrementalQueryAsync(
connectionId,
resolvedMessage,
followupType
);
}这让对话变得更自然,用户不需要每次都重复完整的需求。
🔌 MCP协议集成:能力即服务
Text2Sql.Net 的一个创新点是支持 **Model Context Protocol (MCP)**,这让它可以被各种IDE和工具调用。
什么是MCP?
MCP是一个标准化的协议,用于AI工具之间的互操作。通过MCP,Text2Sql.Net可以:
-
在Cursor中直接使用自然语言查询数据库
-
在Trae中集成Text2SQL能力
-
被任何支持MCP的工具调用
提供的MCP工具
[McpServerTool(Name = "get_database_connections")]
public async Task<string> GetDatabaseConnections(...)
[McpServerTool(Name = "get_database_schema")]
public async Task<string> GetDatabaseSchema(...)
[McpServerTool(Name = "generate_sql")]
public async Task<string> GenerateSql(...)
[McpServerTool(Name = "execute_sql")]
public async Task<string> ExecuteSql(...)
[McpServerTool(Name = "get_chat_history")]
public async Task<string> GetChatHistory(...)
[McpServerTool(Name = "get_table_structure")]
public async Task<string> GetTableStructure(...)
[McpServerTool(Name = "get_all_tables")]
public async Task<string> GetAllTables(...)配置示例
{
"mcpServers": {
"text2sql": {
"name": "Text2Sql.Net",
"type": "sse",
"description": "智能Text2SQL服务",
"url": "http://localhost:5000/mcp/sse?connectionId=xxxxx"
}
}
}配置后,你可以在IDE中直接问:
-
"显示所有用户表的结构"
-
"查询最近一周的订单数据"
-
"统计每个分类的产品数量"
AI助手会自动调用Text2Sql.Net生成并执行SQL,返回结果。
💡 工程实践:细节决定成败
一、向量存储的选择
Text2Sql.Net 支持两种向量存储方案:
1. SQLite Memory Store(轻量级)
memoryStore = await SqliteMemoryStore.ConnectAsync(
Text2SqlConnectionOption.VectorConnection
);优点:
-
零配置,开箱即用
-
单文件存储,便于部署
-
适合中小型项目
缺点:
-
性能相对较低
-
不支持分布式
2. PostgreSQL + pgvector(生产级)
NpgsqlDataSourceBuilder dataSourceBuilder = new(connectionString);
dataSourceBuilder.UseVector();
NpgsqlDataSource dataSource = dataSourceBuilder.Build();
memoryStore = new PostgresMemoryStore(
dataSource,
vectorSize: 1536,
schema: "public"
);优点:
-
高性能,支持大规模数据
-
支持分布式部署
-
成熟的生态系统
缺点:
-
需要额外部署PostgreSQL
-
配置相对复杂
选择建议:
-
开发/测试环境:SQLite
-
生产环境:PostgreSQL
-
向量维度:1536(OpenAI text-embedding-ada-002)
二、Prompt工程的艺术
Text2Sql.Net 使用了 渐进式Prompt策略,将复杂的任务分解为多个步骤:
public async Task<string> CreateProgressivePromptWithExamplesAsync(
string userQuery,
string schemaJson,
string dbType,
string examplesPrompt)
{
var prompt = new StringBuilder();
// 1. 角色定义
prompt.AppendLine("你是一个专业的SQL查询生成助手。");
// 2. 任务说明
prompt.AppendLine("请根据用户的自然语言查询需求,生成准确的SQL查询语句。");
// 3. 数据库信息
prompt.AppendLine($"数据库类型: {dbType}");
prompt.AppendLine($"表结构信息:\n{schemaJson}");
// 4. Few-shot示例
if (!string.IsNullOrEmpty(examplesPrompt))
{
prompt.AppendLine(examplesPrompt);
}
// 5. 用户查询
prompt.AppendLine($"用户查询: {userQuery}");
// 6. 输出要求
prompt.AppendLine("请直接返回SQL语句,不要包含任何解释或markdown标记。");
return prompt.ToString();
}Prompt设计原则:
-
清晰的角色定位:让LLM知道它是谁
-
结构化的信息:Schema、示例、查询分开呈现
-
明确的输出格式:避免LLM返回多余内容
-
Few-shot Learning:提供相关示例提升准确率
三、错误处理与重试机制
系统使用了 Polly 库实现优雅的重试策略:
// 在OpenAIHttpClientHandler中配置重试
var retryPolicy = Policy
.Handle<HttpRequestException>()
.Or<TaskCanceledException>()
.WaitAndRetryAsync(
retryCount: 3,
sleepDurationProvider: retryAttempt =>
TimeSpan.FromSeconds(Math.Pow(2, retryAttempt)),
onRetry: (exception, timeSpan, retryCount, context) =>
{
_logger.LogWarning(
$"请求失败,{timeSpan.TotalSeconds}秒后进行第{retryCount}次重试"
);
}
);重试策略:
-
指数退避:1秒、2秒、4秒
-
最多重试3次
-
记录每次重试的日志
四、性能优化技巧
1. 增量Schema训练
不是每次都训练全部表,而是支持选择性训练:
// 只训练选定的表
await _schemaTrainingService.TrainDatabaseSchemaAsync(
connectionId,
selectedTableNames
);2. 向量搜索结果缓存
对于相同的查询,可以复用之前的Schema搜索结果:
// 使用内存缓存
private readonly IMemoryCache _cache;
var cacheKey = $"schema_{connectionId}_{userQuery}";
if (_cache.TryGetValue(cacheKey, out string cachedSchema))
{
return cachedSchema;
}3. 异步并发处理
在处理多个表的训练时,使用并发提升速度:
var tasks = selectedTables.Select(async table =>
{
await GenerateEmbeddingForTableAsync(table);
});
await Task.WhenAll(tasks);五、安全性考虑
1. SQL注入防护
虽然SQL是LLM生成的,但仍需防范注入风险:
// 使用参数化查询(SqlSugar自动处理)
var result = await db.Ado.GetDataTableAsync(sqlQuery);2. 权限控制
系统支持配置用户权限,限制可访问的数据库和表:
// 检查用户是否有权限访问该连接
if (!await _authService.HasAccessAsync(userId, connectionId))
{
throw new UnauthorizedAccessException();
}3. 敏感信息脱敏
在日志中自动脱敏敏感信息:
_logger.LogInformation(
$"执行SQL: {MaskSensitiveInfo(sqlQuery)}"
);🎬 实战场景:从理论到应用
场景一:数据分析师的日常
需求:分析师小李需要快速了解上个月的销售情况。
传统方式:
-
打开数据库客户端
-
查看表结构,找到订单表、产品表、客户表
-
写JOIN查询,处理日期过滤
-
调试SQL语法错误
-
导出结果到Excel
用户: "查询上个月每个产品类别的销售额和订单数量,按销售额降序排列"
系统:
生成SQL:
SELECT
p.category_name,
SUM(oi.quantity * oi.unit_price) as total_sales,
COUNT(DISTINCT o.order_id) as order_count
FROM orders o
JOIN order_items oi ON o.order_id = oi.order_id
JOIN products p ON oi.product_id = p.product_id
WHERE o.order_date >= DATE_SUB(CURDATE(), INTERVAL 1 MONTH)
AND o.order_date < DATE_SUB(CURDATE(), INTERVAL 0 MONTH)
GROUP BY p.category_name
ORDER BY total_sales DESC
执行结果: 返回15条记录时间对比:
-
传统方式:10-15分钟
-
Text2Sql.Net:30秒
场景二:产品经理的临时需求
需求:产品经理突然问"有多少用户最近一周没有登录?"
传统方式:
-
找开发同学
-
等待开发同学有空
-
沟通需求细节
-
等待SQL编写和执行
-
获得结果
用户: "统计最近一周没有登录的用户数量"
系统:
生成SQL:
SELECT COUNT(DISTINCT u.user_id) as inactive_users
FROM users u
LEFT JOIN user_login_logs l ON u.user_id = l.user_id
AND l.login_time >= DATE_SUB(NOW(), INTERVAL 7 DAY)
WHERE l.user_id IS NULL
AND u.status = 'active'
执行结果: 1,234 个用户产品经理自己就能获得答案,不需要打扰开发团队。
场景三:开发者的调试助手
需求:开发者在IDE中需要快速查看某个表的数据。
传统方式:
-
切换到数据库客户端
-
连接数据库
-
写SELECT语句
-
复制结果回IDE
使用Text2Sql.Net + MCP:
在Cursor中直接输入:
@text2sql 显示users表中最近注册的10个用户的信息AI助手自动调用Text2Sql.Net,结果直接显示在IDE中。
场景四:BI报表的快速原型
需求:快速验证一个报表的数据逻辑。
用户: "按月统计2023年每个地区的新增客户数和客户留存率"
系统:
生成SQL:
WITH monthly_new_customers AS (
SELECT
DATE_FORMAT(c.register_date, '%Y-%m') as month,
c.region,
COUNT(DISTINCT c.customer_id) as new_customers
FROM customers c
WHERE YEAR(c.register_date) = 2023
GROUP BY DATE_FORMAT(c.register_date, '%Y-%m'), c.region
),
monthly_active_customers AS (
SELECT
DATE_FORMAT(o.order_date, '%Y-%m') as month,
c.region,
COUNT(DISTINCT c.customer_id) as active_customers
FROM orders o
JOIN customers c ON o.customer_id = c.customer_id
WHERE YEAR(o.order_date) = 2023
GROUP BY DATE_FORMAT(o.order_date, '%Y-%m'), c.region
)
SELECT
n.month,
n.region,
n.new_customers,
ROUND(a.active_customers * 100.0 / n.new_customers, 2) as retention_rate
FROM monthly_new_customers n
LEFT JOIN monthly_active_customers a
ON n.month = a.month AND n.region = a.region
ORDER BY n.month, n.region复杂的CTE查询,系统也能准确生成。
🚀 部署与运维
部署架构
单机部署(适合中小型项目)
┌─────────────────────────────────────┐
│ Text2Sql.Net Server │
│ ┌──────────────┐ ┌──────────────┐ │
│ │ Blazor UI │ │ MCP Server │ │
│ └──────────────┘ └──────────────┘ │
│ ┌──────────────┐ ┌──────────────┐ │
│ │ SQLite DB │ │ Vector Store │ │
│ └──────────────┘ └──────────────┘ │
└─────────────────────────────────────┘配置文件:
{
"Text2SqlOpenAI": {
"Key": "your-api-key",
"EndPoint": "https://api.openai.com/",
"ChatModel": "gpt-4o",
"EmbeddingModel": "text-embedding-ada-002"
},
"Text2SqlConnection": {
"DbType": "Sqlite",
"DBConnection": "Data Source=text2sql.db",
"VectorConnection": "text2sqlmem.db"
}
}分布式部署(适合大型项目)
┌─────────────────┐ ┌─────────────────┐
│ Load Balancer │────▶│ Text2Sql.Net │
└─────────────────┘ │ Instance 1 │
└─────────────────┘
│
┌──────┴──────┐
▼ ▼
┌──────────────┐ ┌──────────────┐
│ PostgreSQL │ │ pgvector │
│ (主数据) │ │ (向量存储) │
└──────────────┘ └──────────────┘配置文件:
{
"Text2SqlConnection": {
"DbType": "PostgreSQL",
"DBConnection": "Host=pg-server;Database=text2sql;Username=admin;Password=***",
"VectorConnection": "Host=pg-server;Database=text2sql_vector;Username=admin;Password=***",
"VectorSize": 1536
}
}Docker部署
FROM mcr.microsoft.com/dotnet/aspnet:8.0 AS base
WORKDIR /app
EXPOSE 5000
FROM mcr.microsoft.com/dotnet/sdk:8.0 AS build
WORKDIR /src
COPY ["Text2Sql.Net.Web/Text2Sql.Net.Web.csproj", "Text2Sql.Net.Web/"]
RUN dotnet restore "Text2Sql.Net.Web/Text2Sql.Net.Web.csproj"
COPY . .
WORKDIR "/src/Text2Sql.Net.Web"
RUN dotnet build "Text2Sql.Net.Web.csproj" -c Release -o /app/build
FROM build AS publish
RUN dotnet publish "Text2Sql.Net.Web.csproj" -c Release -o /app/publish
FROM base AS final
WORKDIR /app
COPY --from=publish /app/publish .
ENTRYPOINT ["dotnet", "Text2Sql.Net.Web.dll"]docker-compose.yml:
version: '3.8'
services:
text2sql:
build: .
ports:
- "5000:5000"
environment:
- Text2SqlOpenAI__Key=${OPENAI_API_KEY}
- Text2SqlConnection__DbType=PostgreSQL
- Text2SqlConnection__DBConnection=Host=postgres;Database=text2sql;Username=admin;Password=admin123
depends_on:
- postgres
postgres:
image: pgvector/pgvector:pg16
environment:
- POSTGRES_USER=admin
- POSTGRES_PASSWORD=admin123
- POSTGRES_DB=text2sql
volumes:
- postgres_data:/var/lib/postgresql/data
volumes:
postgres_data:监控与日志
日志配置
{
"Logging": {
"LogLevel": {
"Default": "Information",
"Microsoft.AspNetCore": "Warning",
"Text2Sql.Net": "Debug"
}
}
}关键指标监控
-
SQL生成成功率:监控生成的SQL有多少能成功执行
-
平均响应时间:从用户提问到返回结果的时间
-
向量搜索准确率:Schema Linking的准确性
-
LLM调用次数:控制成本
-
错误率:系统异常和SQL执行失败的比例
🔮 技术挑战与解决方案
挑战一:复杂查询的准确性
问题:涉及多表JOIN、子查询、窗口函数的复杂查询,LLM容易出错。
解决方案:
-
渐进式生成:先生成简单查询,再逐步添加复杂逻辑
-
Schema Linking优化:确保提供完整的表关系信息
-
Few-shot Learning:为复杂查询类型准备高质量示例
-
执行反馈循环:失败后自动优化重试
效果:复杂查询准确率从60%提升到85%
挑战二:不同数据库方言的差异
问题:MySQL、PostgreSQL、SQL Server的SQL语法有差异。
解决方案:
-
在Prompt中明确指定数据库类型
-
为每种数据库准备特定的示例
-
使用SqlSugar的方言转换能力
// Prompt中明确数据库类型
prompt.AppendLine($"数据库类型: {dbType}");
prompt.AppendLine("请生成符合该数据库语法的SQL语句");// 针对不同数据库的日期函数示例
// MySQL: DATE_SUB(NOW(), INTERVAL 1 MONTH)
// PostgreSQL: NOW() - INTERVAL '1 month'
// SQL Server: DATEADD(month, -1, GETDATE())
挑战三:大型数据库的Schema管理
问题:数据库有上百张表,全部向量化会导致:
-
训练时间长
-
向量存储占用大
-
搜索性能下降
解决方案:
-
增量训练:只训练常用的表
-
分层索引:核心表和辅助表分开索引
-
定期清理:删除长期未使用的表的向量
// 只训练核心表
var coreTables = new List
{
"users", "orders", "products", "customers"
};
await _schemaTrainingService.TrainDatabaseSchemaAsync(
connectionId,
coreTables
);
挑战四:成本控制
问题:频繁调用OpenAI API会产生高额费用。
解决方案:
-
结果缓存:相同查询复用结果
-
Embedding复用:Schema向量只生成一次
-
本地模型:考虑使用开源模型(如Llama)
-
批量处理:合并多个请求
// 缓存策略
var cacheKey = $"sql_{connectionId}_{Hash(userQuery)}";
if (_cache.TryGetValue(cacheKey, out string cachedSql))
{
return cachedSql;
}// 生成SQL后缓存
_cache.Set(cacheKey, generatedSql, TimeSpan.FromHours(1));
挑战五:多租户隔离
问题:多个用户/租户共享系统,需要数据隔离。
解决方案:
-
连接级隔离:每个租户有独立的数据库连接配置
-
向量命名空间 :使用
{tenantId}_{connectionId}作为集合名 -
权限验证:每次操作都验证用户权限
// 多租户向量存储
string collectionName = $"{tenantId}_{connectionId}";
await textMemory.SaveInformationAsync(
collectionName,
id: vectorId,
text: embeddingText
);
📊 性能基准测试
测试环境
-
硬件:4核CPU,16GB内存
-
数据库:PostgreSQL 16 + pgvector
-
表数量:50张表,平均每表20个字段
-
向量维度:1536
-
LLM:GPT-4o
测试结果
| 操作 | 平均耗时 | P95耗时 | 说明 |
|---|---|---|---|
| Schema训练(全量) | 45秒 | 60秒 | 50张表 |
| Schema训练(增量) | 8秒 | 12秒 | 5张表 |
| 向量搜索 | 120ms | 200ms | Top 5 |
| SQL生成 | 2.5秒 | 4秒 | 包含LLM调用 |
| SQL执行 | 150ms | 500ms | 简单查询 |
| 端到端查询 | 3秒 | 5秒 | 从提问到结果 |
优化建议
-
使用PostgreSQL:比SQLite快3-5倍
-
启用缓存:重复查询响应时间降低90%
-
批量训练:并发处理多个表
-
异步处理:不阻塞用户界面
🌟 最佳实践
一、Schema设计建议
-
添加表和列的注释:LLM会利用这些信息
COMMENT ON TABLE orders IS '订单表,记录所有客户订单信息';
COMMENT ON COLUMN orders.order_date IS '订单创建日期'; -
规范命名:使用有意义的表名和列名
✅ customer_orders
❌ tbl_co -
明确外键关系:帮助系统理解表之间的关联
ALTER TABLE orders
ADD CONSTRAINT fk_customer
FOREIGN KEY (customer_id) REFERENCES customers(id);
二、问答示例管理
-
覆盖常见场景:为高频查询创建示例
-
分类组织:按查询类型(聚合、关联、时间序列等)分类
-
定期更新:根据用户反馈优化示例
-
质量优先:宁缺毋滥,确保示例的准确性
三、Prompt优化技巧
-
明确输出格式:要求LLM只返回SQL,不要解释
-
提供上下文:包含数据库类型、表关系等信息
-
使用Few-shot:提供2-3个相关示例
-
设置约束:如"只使用提供的表"、"不要使用子查询"
四、安全性检查清单
-
启用SQL类型检查(只自动执行SELECT)
-
配置用户权限(限制可访问的数据库)
-
启用审计日志(记录所有SQL执行)
-
设置查询超时(防止长时间运行的查询)
-
限制返回行数(防止大量数据传输)
-
敏感信息脱敏(日志中隐藏密码等)
🔄 与其他方案的对比
Text2Sql.Net vs LangChain SQL Agent
| 特性 | Text2Sql.Net | LangChain SQL Agent |
|---|---|---|
| 语言生态 | .NET | Python |
| 向量搜索 | 内置支持 | 需要额外配置 |
| 多数据库 | 原生支持4种 | 需要自行适配 |
| Schema管理 | 可视化界面 | 代码配置 |
| 执行反馈 | 自动优化 | 需要自行实现 |
| MCP支持 | 原生支持 | 不支持 |
| 部署难度 | 简单 | 中等 |
Text2Sql.Net vs 商业产品(如Tableau Ask Data)
| 特性 | Text2Sql.Net | 商业产品 |
|---|---|---|
| 成本 | 开源免费 | 高昂授权费 |
| 定制性 | 完全可定制 | 受限 |
| 数据隐私 | 私有部署 | 可能上传云端 |
| 集成能力 | 灵活 | 受限于产品生态 |
| 学习曲线 | 需要技术背景 | 低 |
选择建议:
-
Text2Sql.Net适合:有技术团队、需要定制、注重数据隐私的企业
-
商业产品适合:非技术团队、快速上线、预算充足的场景
🚧 未来展望与技术趋势
短期规划(3-6个月)
1. 支持更多数据库
-
Oracle:企业级数据库的重要选择
-
MongoDB:NoSQL查询转换
-
ClickHouse:OLAP场景的Text2SQL
2. 增强的Schema理解
-
自动识别业务实体:从表结构推断业务概念
-
关系图谱可视化:直观展示表之间的关系
-
智能字段映射:理解同义词(如user_id和customer_id)
3. 更智能的查询优化
-
执行计划分析:生成SQL时考虑性能
-
索引建议:根据查询模式推荐索引
-
查询改写:自动优化低效查询
中期规划(6-12个月)
1. 多模态支持
-
图表生成:直接从查询结果生成可视化图表
-
自然语言解释:用人话解释查询结果
-
语音交互:支持语音输入查询
2. 协作功能
-
查询分享:团队成员共享常用查询
-
查询模板:创建可复用的查询模板
-
权限管理:细粒度的数据访问控制
3. 智能推荐
-
查询建议:根据历史推荐相关查询
-
数据洞察:主动发现数据中的异常和趋势
-
自动报表:定期生成业务报表
长期愿景(1-2年)
1. 自主学习系统
-
强化学习:从用户反馈中持续学习
-
迁移学习:跨数据库的知识迁移
-
主动学习:识别不确定的查询,请求人工标注
2. 企业级特性
-
高可用部署:支持集群和故障转移
-
审计与合规:满足企业安全要求
-
性能监控:实时监控系统健康状态
3. 生态系统建设
-
插件市场:第三方扩展和集成
-
行业模板:针对特定行业的预训练模型
-
社区贡献:开放的贡献机制
🎓 技术趋势分析
1. 从Text2SQL到Data2Insight
未来的趋势不仅是生成SQL,而是直接提供业务洞察:
用户: "我们的销售情况怎么样?"
系统:
📊 销售总览(本月 vs 上月)
- 总销售额: ¥1,234,567 (↑15%)
- 订单数量: 5,678 (↑8%)
- 客单价: ¥217 (↑6%)
⚠️ 异常发现
- 华东地区销售额下降12%,需要关注
- 电子产品类目增长迅速,建议增加库存
💡 行动建议
- 调查华东地区销售下降原因
- 优化电子产品的供应链2. 多模态交互
结合图表、表格、自然语言的混合输出:
用户: "分析用户增长趋势"
系统:
[生成折线图]
[生成数据表]
[自然语言总结]
"过去6个月用户增长稳定,月均增长率8.5%。
其中移动端用户占比从45%提升到62%,
建议加强移动端体验优化。"3. 实时数据流处理
支持流式数据的实时查询:
用户: "实时监控今天的订单量"
系统: [建立WebSocket连接]
每5秒更新一次数据
支持实时告警4. 联邦查询
跨多个数据源的统一查询:
用户: "对比MySQL中的订单数据和MongoDB中的用户行为数据"
系统:
[自动生成跨数据源查询]
[数据融合和关联]
[统一结果展示]💼 商业化思考
开源 vs 商业版
开源版(社区版):
-
核心Text2SQL功能
-
基础的Schema管理
-
单机部署
-
社区支持
商业版(企业版):
-
高级优化算法
-
企业级安全特性
-
分布式部署
-
专业技术支持
-
SLA保障
盈利模式
-
SaaS服务:提供云端托管服务
-
私有化部署:为大型企业提供定制部署
-
技术咨询:Text2SQL解决方案咨询
-
培训服务:企业培训和认证
目标客户
-
数据分析团队:提升分析效率
-
产品经理:自助数据查询
-
开发团队:快速原型验证
-
BI工具厂商:集成Text2SQL能力
🤝 社区与贡献
如何参与
Text2Sql.Net 是一个开源项目,欢迎各种形式的贡献:
1. 代码贡献
-
新功能开发:实现Roadmap中的功能
-
Bug修复:修复已知问题
-
性能优化:提升系统性能
-
文档完善:改进文档和示例
2. 问题反馈
-
Bug报告:提交详细的问题描述
-
功能建议:提出新功能需求
-
使用案例:分享你的使用经验
3. 社区建设
-
技术文章:撰写技术博客
-
视频教程:制作使用教程
-
翻译工作:多语言文档翻译
-
答疑解惑:帮助其他用户
贡献指南
# 1. Fork项目
git clone https://github.com/AIDotNet/Text2Sql.Net.git
# 2. 创建特性分支
git checkout -b feature/your-feature
# 3. 提交代码
git commit -m "Add: your feature description"
# 4. 推送到远程
git push origin feature/your-feature
# 5. 创建Pull Request社区资源
-
在线Demo:https://demo.antsk.cn
-
技术文档:查看项目Wiki
-
微信交流群:添加微信 xuzeyu91
📚 学习资源推荐
相关技术
-
Semantic Kernel
-
深入理解AI编排框架
-
向量数据库
-
pgvector文档:https://github.com/pgvector/pgvector
-
向量搜索原理与实践
-
-
Prompt Engineering
-
OpenAI Prompt指南
-
Few-shot Learning最佳实践
-
-
Text2SQL研究
-
Spider数据集:Text2SQL基准测试
-
学术论文:最新研究进展
-
相关项目
-
AntSK:更全面的RAG解决方案
-
包含知识库、Agent等功能
-
LangChain:Python生态的AI应用框架
-
Semantic Kernel:微软的AI编排框架
-
Vanna.AI:另一个Text2SQL开源项目
🎯 总结
Text2Sql.Net 不仅仅是一个Text2SQL工具,它代表了一种新的人机交互范式:让AI理解你的数据,而不是让你适应AI。
核心价值
-
降低门槛:让非技术人员也能查询数据库
-
提升效率:从10分钟到30秒的查询体验
-
减少错误:AI生成的SQL比手写更准确
-
知识沉淀:通过示例系统积累查询经验
技术亮点
-
智能Schema理解:基于向量搜索的语义匹配
-
执行反馈优化:自动修复错误的SQL
-
多轮对话支持:理解上下文和指代关系
-
MCP协议集成:与开发工具无缝对接
-
企业级架构:可扩展、可维护、可部署
适用场景
-
✅ 数据分析和BI报表
-
✅ 产品经理的自助查询
-
✅ 开发者的调试助手
-
✅ 客服的数据查询
-
✅ 管理层的决策支持
未来可期
随着大语言模型的不断进步,Text2SQL技术将变得更加智能和准确。Text2Sql.Net 将持续演进,从简单的SQL生成工具,发展为全面的数据智能助手。
让我们一起,用AI重新定义数据查询的方式!
📄 许可证
Text2Sql.Net 采用 Apache-2.0 开源协议,你可以:
-
✅ 商业使用
-
✅ 修改代码
-
✅ 分发
-
✅ 私有使用
但需要:
-
📋 保留版权声明
-
📋 声明修改内容
感谢阅读!如果这篇文章对你有帮助,欢迎点赞、收藏、转发!
让我们一起,让数据库"听懂"人话! 🚀