到目前为止,我们已经设计了一个智能规划器,并为我们的文档添加了元数据。现在,我们准备构建系统的核心:一个复杂的检索管道。
简单的一次性语义搜索已经不够用了。对于生产级别的智能体,我们需要一个既自适应 又多阶段的检索过程。
我们将把检索过程设计成一个漏斗,每个阶段都对前一阶段的结果进行优化:
多阶段漏斗(作者: 法里德·汗 )
-
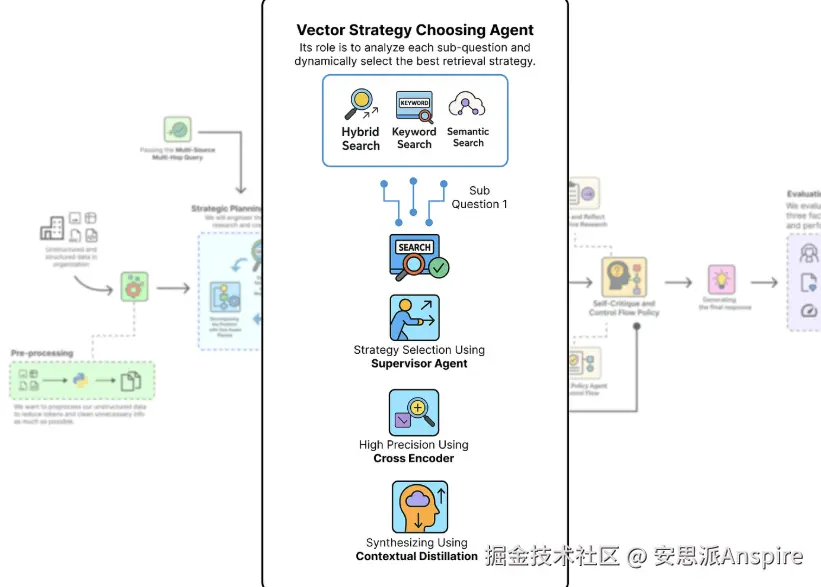
检索主管:我们将构建一个新的主管代理,它将作为动态路由器,分析每个子问题并选择最佳搜索策略(向量、关键词或混合)。
-
**第一阶段(广泛召回):**我们将实施主管可以选择的不同检索策略,重点是撒大网以捕获所有潜在相关的文档。
-
**阶段2(高精度):**我们将使用交叉编码器模型对初始结果进行重新排序,剔除噪声,并将最相关的文档提升到顶部。
-
第三阶段(综合):最后,我们将创建一个蒸馏器代理,将排名靠前的文档压缩成一个简洁的上下文段落,供下游代理使用。
使用Supervisor动态选择策略
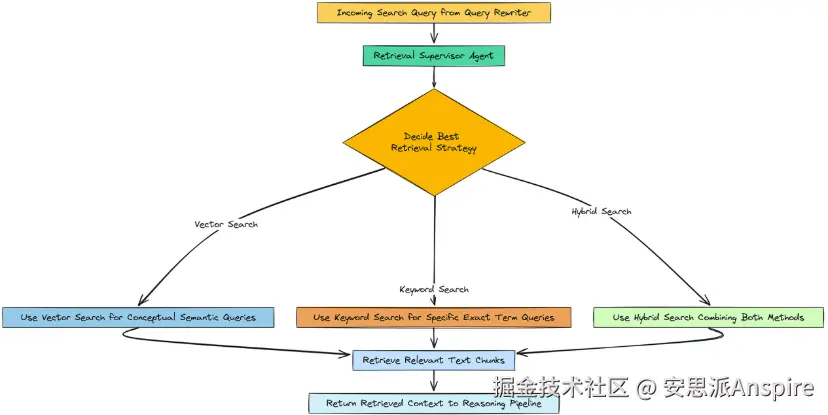
所以,基本上,并非所有搜索查询都是相同的。像"'计算与网络'部门的收入是多少?"这样的问题包含特定、确切的术语。基于关键词的搜索非常适合这类问题。
但像......这样的问题
公司对市场竞争的看法是什么?这是概念性的。基于向量的语义搜索会好得多。
主管代理(作者: 法里德·汗 )
我们不会硬编码一种策略,而是要构建一个小型的智能代理,检索主管来为我们做这个决策。它唯一的工作就是查看搜索查询,并决定哪种检索方法最合适。
首先,我们需要定义我们的监督者可能做出的决策。我们将使用 Pydantic 的BaseModel来构建其输出结构。
python
class RetrievalDecision(BaseModel):
# The chosen retrieval strategy. Must be one of these three options.
strategy: Literal["vector_search", "keyword_search", "hybrid_search"]
# The agent's justification for its choice.
justification: str监管者必须选择这三种策略之一,并解释其理由。这使得其决策链路透明且可靠。
现在,让我们来创建一个提示,以指导这个智能体的行为。
ini
retrieval_supervisor_prompt = ChatPromptTemplate.from_messages([
("system", """You are a retrieval strategy expert. Based on the user's query, you must decide the best retrieval strategy.
You have three options:
1. `vector_search`: Best for conceptual, semantic, or similarity-based queries.
2. `keyword_search`: Best for queries with specific, exact terms, names, or codes (e.g., 'Item 1A', 'Hopper architecture').
3. `hybrid_search`: A good default that combines both, but may be less precise than a targeted strategy."""),
("human", "User Query: {sub_question}") # The rewritten search query will be passed here.
])我们在这里创建了一个非常直接的提示,它告诉大语言模型(LLM)其角色是检索策略专家,并清楚地解释了其可用的每种策略在何时最为有效。
最后,我们可以组装我们的监督代理了。
python
# Create the agent by piping our prompt to the reasoning LLM and structuring its output with our Pydantic class
retrieval_supervisor_agent = retrieval_supervisor_prompt | reasoning_llm.with_structured_output(RetrievalDecision)
print("Retrieval Supervisor Agent created.")
# Let's test it with two different types of queries to see how it behaves
print("\n--- Testing Retrieval Supervisor Agent ---")
query1 = "revenue growth for the Compute & Networking segment in fiscal year 2023"
decision1 = retrieval_supervisor_agent.invoke({"sub_question": query1})
print(f"Query: '{query1}'")
print(f"Decision: {decision1.strategy}, Justification: {decision1.justification}")
query2 = "general sentiment about market competition and technological innovation"
decision2 = retrieval_supervisor_agent.invoke({"sub_question": query2})
print(f"\nQuery: '{query2}'")
print(f"Decision: {decision2.strategy}, Justification: {decision2.justification}")现在我们把所有东西连接在一起。
我们的.with_structured_output(RetrievalDecision)再次承担了主要工作,确保我们从大语言模型(LLM)那里得到一个清晰、可预测的RetrievalDecision对象。让我们来看看测试结果。
vbnet
#### OUTPUT ####
Retrieval Supervisor Agent created.
# --- Testing Retrieval Supervisor Agent ---
Query: 'revenue growth for the Compute & Networking segment in fiscal year 2023'
Decision: keyword_search, Justification: The query contains specific keywords like 'revenue growth', 'Compute & Networking', and 'fiscal year 2023' which are ideal for a keyword-based search to find exact financial figures.
Query: 'general sentiment about market competition and technological innovation'
Decision: vector_search, Justification: This query is conceptual and seeks to understand sentiment and broader themes. Vector search is better suited to capture the semantic meaning of 'market competition' and 'technological innovation' rather than relying on exact keywords.我们可以看到,它正确地识别出第一个查询中充满了特定术语,并选择了关键词搜索。
对于第二个查询,它是概念性和抽象性的,系统正确选择了向量搜索。在检索漏斗开始时进行这种动态决策,相较于一刀切的方法是一个很好的改进。
通过混合、关键词和语义搜索实现广泛召回
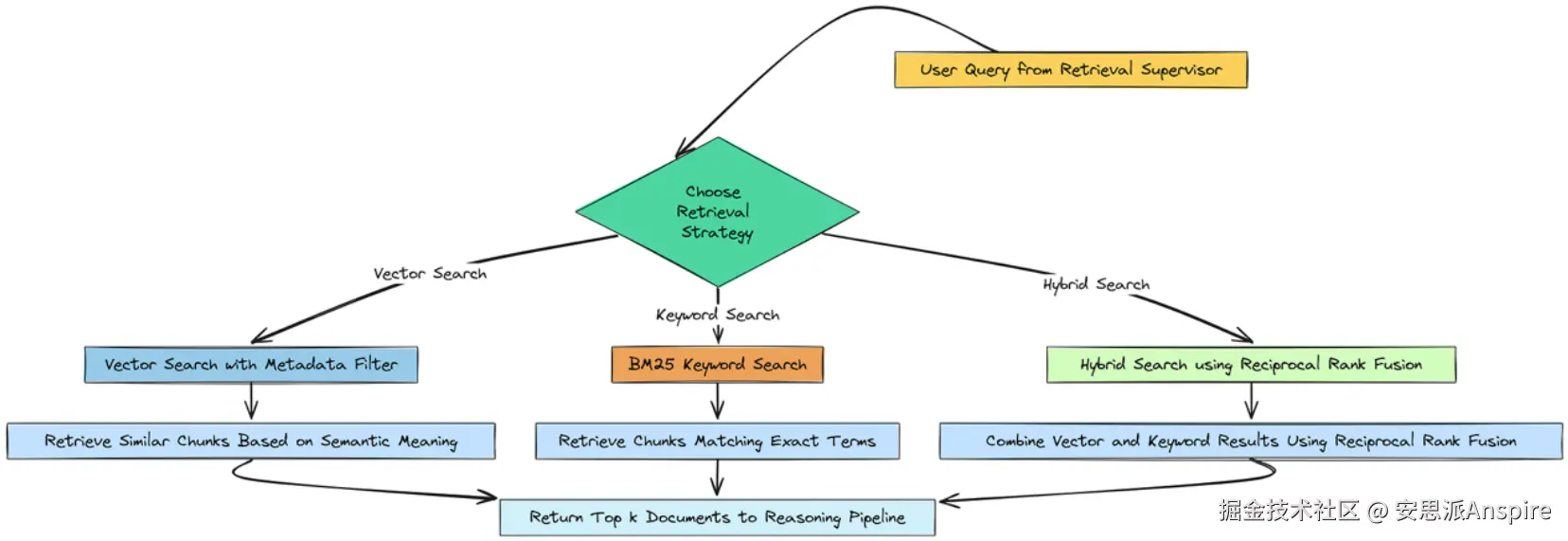
既然我们有了一个监督者来选择我们的策略,我们就需要构建检索策略本身。我们漏斗的第一阶段完全是关于召回率我们的目标是撒大网,捕捉每一个可能相关的文档,即使在此过程中会捕捉到一些噪音。
广泛召回(作者: 法里德·汗 )
为了实现这一点,我们将实现三个不同的搜索功能,供我们的主管调用:
-
**向量搜索:**我们的标准语义搜索,现在已升级为使用元数据过滤器。
-
**关键词搜索(BM25):**一种经典且强大的算法,擅长查找包含特定、精确术语的文档。
-
混合搜索:一种两全其美的方法是使用一种称为互逆排名融合(RRF)的技术将向量搜索和关键词搜索的结果结合起来。
首先,我们需要使用上一节中创建的富含元数据的块来创建一个新的高级向量存储。
python
import numpy as np # A fundamental library for numerical operations in Python
from rank_bm25 import BM25Okapi # The library for implementing the BM25 keyword search algorithm
print("Creating advanced vector store with metadata...")
# We create a new Chroma vector store, this time using our metadata-rich chunks
advanced_vector_store = Chroma.from_documents(
documents=doc_chunks_with_metadata,
embedding=embedding_function
)
print(f"Advanced vector store created with {advanced_vector_store._collection.count()} embeddings.")这是一个简单但关键的步骤。这个高级向量存储现在包含与我们的基线相同的文本,但每个嵌入的文本块都标记了其章节标题,从而使我们能够执行过滤搜索。
接下来,我们需要为关键词搜索做准备。BM25算法的工作原理是分析文档中单词的出现频率。为了实现这一点,我们需要对语料库进行预处理,将每个文档的内容拆分为单词列表(词元)。
ini
print("\nBuilding BM25 index for keyword search...")
# Create a list where each element is a list of words from a document
tokenized_corpus = [doc.page_content.split(" ") for doc in doc_chunks_with_metadata]
# Create a list of all unique document IDs
doc_ids = [doc.metadata["id"] for doc in doc_chunks_with_metadata]
# Create a mapping from a document's ID back to the full Document object for easy lookup
doc_map = {doc.metadata["id"]: doc for doc in doc_chunks_with_metadata}
# Initialize the BM25Okapi index with our tokenized corpus
bm25 = BM25Okapi(tokenized_corpus)我们基本上是在为BM25索引创建必要的数据结构。分词语料库是算法将搜索的对象,而文档映射将使我们在搜索完成后能够快速检索完整的文档对象。
现在我们可以定义我们的三个检索函数了。
ini
# Strategy 1: Pure Vector Search with Metadata Filtering
def vector_search_only(query: str, section_filter: str = None, k: int = 10):
# This dictionary defines the metadata filter. ChromaDB will only search documents that match this.
filter_dict = {"section": section_filter} if section_filter and "Unknown" not in section_filter else None
# Perform the similarity search with the optional filter
return advanced_vector_store.similarity_search(query, k=k, filter=filter_dict)
# Strategy 2: Pure Keyword Search (BM25)
def bm25_search_only(query: str, k: int = 10):
# Tokenize the incoming query
tokenized_query = query.split(" ")
# Get the BM25 scores for the query against all documents in the corpus
bm25_scores = bm25.get_scores(tokenized_query)
# Get the indices of the top k documents
top_k_indices = np.argsort(bm25_scores)[::-1][:k]
# Use our doc_map to return the full Document objects for the top results
return [doc_map[doc_ids[i]] for i in top_k_indices]
# Strategy 3: Hybrid Search with Reciprocal Rank Fusion (RRF)
def hybrid_search(query: str, section_filter: str = None, k: int = 10):
# 1. Perform a keyword search
bm25_docs = bm25_search_only(query, k=k)
# 2. Perform a semantic search with the metadata filter
semantic_docs = vector_search_only(query, section_filter=section_filter, k=k)
# 3. Combine and re-rank the results using Reciprocal Rank Fusion (RRF)
# Get a unique set of all documents found by either search method
all_docs = {doc.metadata["id"]: doc for doc in bm25_docs + semantic_docs}.values()
# Create lists of just the document IDs from each search result
ranked_lists = [[doc.metadata["id"] for doc in bm25_docs], [doc.metadata["id"] for doc in semantic_docs]]
# Initialize a dictionary to store the RRF scores for each document
rrf_scores = {}
# Loop through each ranked list (BM25 and Semantic)
for doc_list in ranked_lists:
# Loop through each document ID in the list with its rank (i)
for i, doc_id in enumerate(doc_list):
if doc_id not in rrf_scores:
rrf_scores[doc_id] = 0
# The RRF formula: add 1 / (rank + k) to the score. We use k=61 as a standard default.
rrf_scores[doc_id] += 1 / (i + 61)
# Sort the document IDs based on their final RRF scores in descending order
sorted_doc_ids = sorted(rrf_scores.keys(), key=lambda x: rrf_scores[x], reverse=True)
# Return the top k Document objects based on the fused ranking
final_docs = [doc_map[doc_id] for doc_id in sorted_doc_ids[:k]]
return final_docs
print("\nAll retrieval strategy functions ready.")我们现在已经实现了自适应检索系统的核心。
-
vector_search_only函数是我们升级后的语义搜索。关键的新增功能是filter=filter_dict参数,它使我们能够传递规划器document_section中的步骤,并强制搜索仅考虑包含该元数据的块。
-
bm25_search_only函数是我们的纯关键词检索器。它速度极快,对于查找语义搜索可能遗漏的特定术语非常有效。
-
混合搜索函数会并行运行这两种搜索,然后使用RRF智能地合并结果。RRF是一种简单但强大的算法,它根据文档在每个列表中的位置对其进行排名,有效地为在
两个
搜索结果中排名靠前的文档赋予更多权重。
让我们快速测试一下,看看我们的关键词搜索是如何运作的。我们将搜索我们的规划者确定的准确章节标题。
python
# Test Keyword Search to see if it can precisely find a specific section
print("\n--- Testing Keyword Search ---")
test_query = "Item 1A. Risk Factors"
test_results = bm25_search_only(test_query)
print(f"Query: {test_query}")
print(f"Found {len(test_results)} documents. Top result section: {test_results[0].metadata['section']}")
#### OUTPUT ####
Creating advanced vector store with metadata...
Advanced vector store created with 381 embeddings.
Building BM25 index for keyword search...
All retrieval strategy functions ready.
# --- Testing Keyword Search ---
Query: Item 1A. Risk Factors
Found 10 documents. Top result section: Item 1A. Risk Factors.输出结果正是我们想要的。以关键词为重点的BM25搜索,仅通过搜索标题,就能完美且即时地从第1A项:风险因素部分中检索到相关文档。
当查询包含特定关键词(如章节标题)时,我们的主管现在可以选择这个精确的工具。
随着我们广泛的召回阶段现已构建完成,我们拥有了一个强大的机制来查找所有潜在相关的文档。然而,这张大网也可能会引入不相关的噪声。我们漏斗的下一阶段将专注于高精度地过滤掉这些噪声。
使用交叉编码器重排器实现高精度
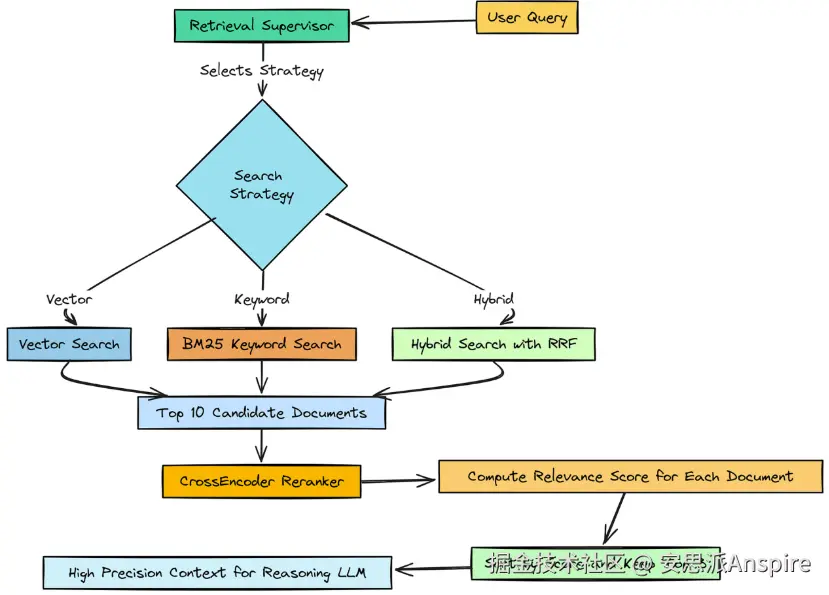
因此,我们的第一阶段检索在召回率方面表现出色。它提取了10篇可能与我们的子问题相关的文档。
但问题在于,它们仅仅是
潜在
相关的。将这10个数据块全部直接输入到我们的主要推理大语言模型中既低效又有风险。
它会增加令牌成本,更重要的是,它可能会用嘈杂、半相关的信息使模型产生混淆。
高精度(作者: 法里德·汗 )
我们现在需要的是一个精筛阶段 。我们需要一种方法来检查这10份候选文档,并挑选出绝对最佳的文档。这就是重排器发挥作用的地方。
关键区别在于这些模型的工作方式。
-
我们的初始检索使用了双编码器(嵌入模型),它会分别为查询和文档创建向量。它速度快,非常适合在数百万个项目中进行搜索。
-
A交叉编码器则将查询和单个文档作为一对输入,进行更深入、更细致的比较。它速度较慢,但准确性要高得多。
所以,基本上,我们要构建一个函数,该函数接收我们检索到的10篇文档,并使用交叉编码器模型为每篇文档赋予一个精确的相关性得分。然后,我们将只保留前3篇,这在我们的配置中已有定义。
首先,让我们初始化我们的交叉编码器模型。我们将使用sentence-transformers库中的一个小型但非常有效的模型,这在我们的配置中已经指定。
python
from sentence_transformers import CrossEncoder # The library for using cross-encoder models
print("Initializing CrossEncoder reranker...")
# Initialize the CrossEncoder model using the name from our central config dictionary.
# The library will automatically download the model from the Hugging Face Hub if it's not cached.
reranker = CrossEncoder(config["reranker_model"])我们基本上是将预训练的重排序模型加载到内存中。这只需要做一次。我们选择的模型ms-marco-MiniLM-L-6-v2在这项任务中非常受欢迎,因为它在速度和准确性之间取得了很好的平衡。
现在我们可以创建执行重排序的函数了。
ini
def rerank_documents_function(query: str, documents: List[Document]) -> List[Document]:
# If we have no documents to rerank, return an empty list immediately.
if not documents:
return []
# Create the pairs of [query, document_content] that the cross-encoder needs.
pairs = [(query, doc.page_content) for doc in documents]
# Use the reranker to predict a relevance score for each pair. This returns a list of scores.
scores = reranker.predict(pairs)
# Combine the original documents with their new scores.
doc_scores = list(zip(documents, scores))
# Sort the list of (document, score) tuples in descending order based on the score.
doc_scores.sort(key=lambda x: x[1], reverse=True)
# Extract just the Document objects from the top N sorted results.
# The number of documents to keep is controlled by 'top_n_rerank' in our config.
reranked_docs = [doc for doc, score in doc_scores[:config["top_n_rerank"]]]
return reranked_docs此函数rerank_documents_function是我们精确阶段的主要部分。它接收查询和来自我们召回阶段的10个文档列表。最重要的步骤是reranker.predict(pairs)。
在这里,模型不是在创建嵌入向量,而是将查询与每个文档内容进行全面比较,为每个文档生成一个相关性得分。
获取分数后,我们只需对文档进行排序并截取列表,仅保留排名前三的文档。此函数的输出将是一个简短、简洁且高度相关的文档列表,这是我们下游代理的理想上下文。
这种从高召回率的第一阶段过渡到高精度的第二阶段的漏斗式方法,是生产级RAG系统的一个组成部分。它确保我们在尽量减少噪声和成本的同时,获得尽可能最佳的证据。
使用上下文蒸馏进行合成
所以,我们的检索漏斗发挥了很好的作用。我们从广泛搜索入手,得到了10篇潜在相关的文档。然后,我们的高精度重排器将其筛选到了前3个最相关的片段。
我们现在的情况已经好很多了,但在将这些信息交给我们的主要推理代理之前,我们仍然可以做最后一次改进。目前,我们有三个独立的文本块。
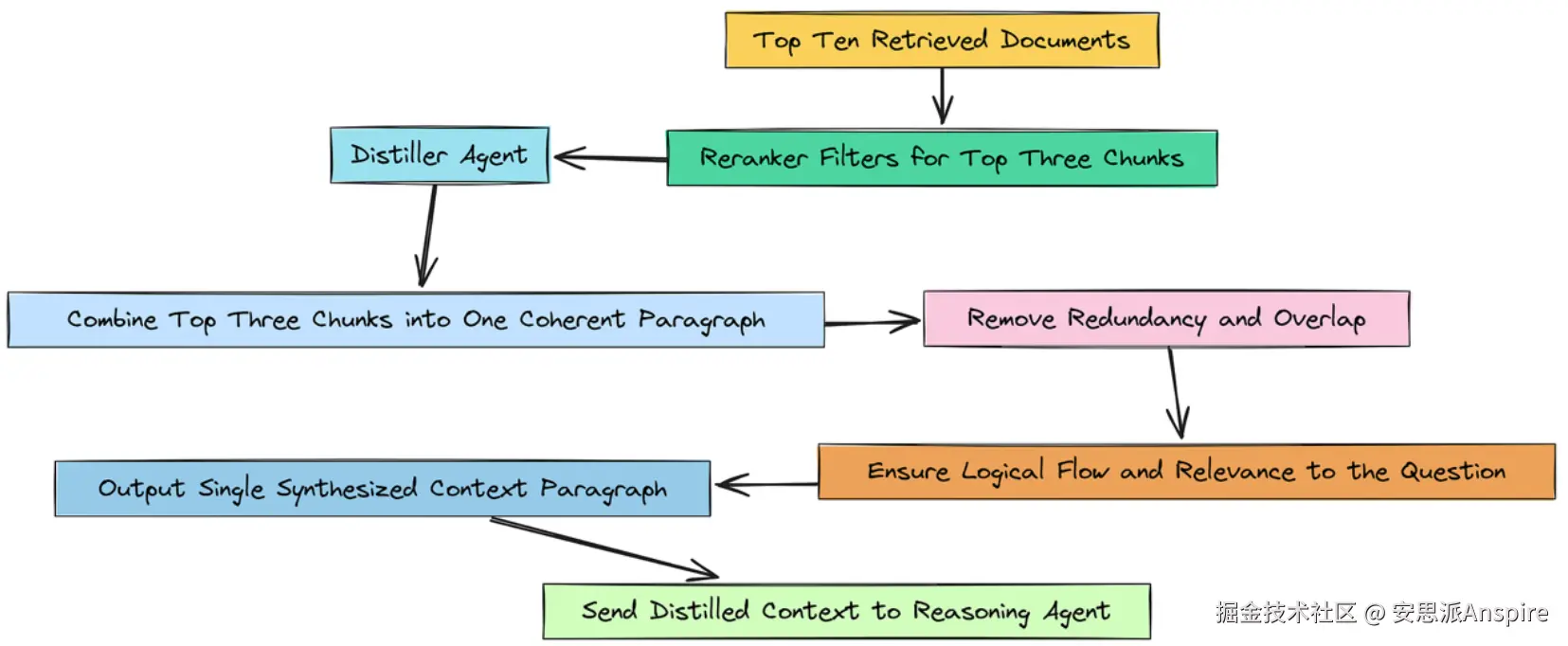
高精度(作者: 法里德·汗 )
虽然它们都相关,但可能包含冗余信息或重复的句子。将它们呈现为三个不同的部分,对于大语言模型(LLM)来说,处理起来可能仍然有点笨拙。
我们检索漏斗的最后阶段是上下文提炼。目标很简单:选取我们排名前三的高度相关文档片段,将它们提炼成一个简洁明了的段落。这样可以消除任何最后的冗余,并为我们的下游代理呈现一个完美合成的证据片段。
这一蒸馏步骤充当最终的压缩层。它确保输入到我们更昂贵的推理代理中的上下文尽可能密集且信息丰富,从而最大化信号并最小化噪声。
为此,我们将创建另一个小型的、专门的代理,我们将其称为蒸馏器代理。
首先,我们需要设计一个提示,以引导其行为。
ini
# The prompt for our distiller agent, instructing it to synthesize and be concise
distiller_prompt = ChatPromptTemplate.from_messages([
("system", """You are a helpful assistant. Your task is to synthesize the following retrieved document snippets into a single, concise paragraph.
The goal is to provide a clear and coherent context that directly answers the question: '{question}'.
Focus on removing redundant information and organizing the content logically. Answer only with the synthesized context."""),
("human", "Retrieved Documents:\n{context}") # The content of our top 3 reranked documents will be passed here
])我们基本上是在给这个智能体一个非常明确的任务。我们告诉它:"这里有一些文本片段。你的唯一任务是将它们合并成一个连贯的段落,以回答这个特定的问题"。**"仅用合成的上下文回答"**这一指令很重要,它可以防止智能体添加任何对话式的冗余内容,或试图自行回答问题。它纯粹是一个文本处理工具。
现在,我们可以组装我们简单的蒸馏器代理了。
ini
# Create the agent by piping our prompt to the reasoning LLM and a string output parser
distiller_agent = distiller_prompt | reasoning_llm | StrOutputParser()
print("Contextual Distiller Agent created.")这是另一个简单直接的LCEL链。我们将蒸馏器提示输入到强大的推理大语言模型中进行合成,然后使用字符串输出解析器来获取最终的、简洁的文本段落。
随着这个蒸馏器代理的创建,我们的多阶段检索漏斗现在已经完成。在我们的主要代理循环中,每个研究步骤的流程将是:
-
**主管:**选择一种检索策略(向量、关键词或混合)。
-
**召回阶段:**执行所选策略以获取前10个文档。
-
**精确阶段:**使用rerank_documents_function获取前3个文档。
-
**蒸馏阶段:**使用蒸馏器代理将前3篇文档压缩成一个简洁的段落。
这个多阶段的过程确保了我们的智能体所处理的证据具有尽可能高的质量。下一步是赋予我们的智能体超越其内部知识并在网络上进行搜索的能力。