本周精选12篇CV领域前沿论文,覆盖医学影像分析、视频理解与生成、3D场景理解与定位、视觉安全与实用场景应用等核心方向。全部200多篇论文感兴趣的自取。

一、医学影像分析方向
1、Surpassing state of the art on AMD area estimation from RGB fundus images through careful selection of U-Net architectures and loss functions for class imbalance
作者:Valentyna Starodub, Mantas Lukoševičius
亮点:以U-Net为基础框架,通过优化预处理技术、编码器骨干网络及类别不平衡损失函数,在AMD病变多类别分割任务中超越ADAM挑战赛所有先前提交结果,为非侵入式RGB眼底图像诊断提供高效方案。

论文:https://arxiv.org/abs/2510.26778
Comments:无明确会议标注,聚焦年龄相关性黄斑变性病变检测的语义分割优化
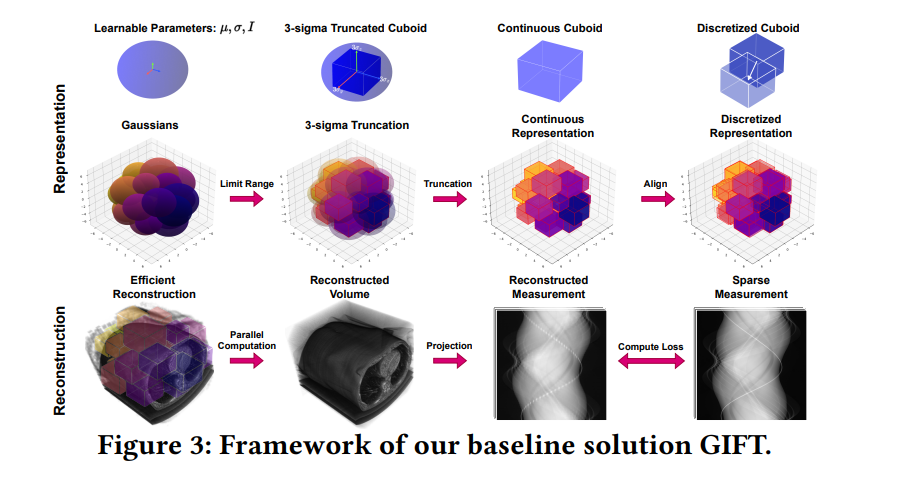
2、MORE: Multi-Organ Medical Image REconstruction Dataset
作者:Shaokai Wu, Yapan Guo, Yanbiao Ji, Jing Tong, Yuxiang Lu, Mei Li, Suizhi Huang, Yue Ding, Hongtao Lu
亮点:提出包含9类解剖结构、15种病变类型的多器官CT重建数据集MORE,解决现有模型泛化性不足问题,建立强基线方案,验证了异质数据对模型鲁棒性提升的关键作用。
论文:https://arxiv.org/abs/2510.26759
开源代码:无(数据集公开于https://more-med.github.io/)
Comments:Accepted to ACMMM 2025
3、BRIQA: Balanced Reweighting in Image Quality Assessment of Pediatric Brain MRI
作者:Alya Almsouti, Ainur Khamitova, Darya Taratynova, Mohammad Yaqub
亮点:针对儿科脑部MRI伪影严重程度评估的类别不平衡问题,提出梯度损失重加权与旋转批处理方案,平均宏F1分数从0.659提升至0.706,在多种伪影类型分类中取得显著性能提升。

论文:https://arxiv.org/abs/2510.26661
开源代码:https://github.com/BioMedIA-MBZUAI/BRIQA
Comments:无明确会议标注,聚焦低场MRI系统伪影自动化质量评估
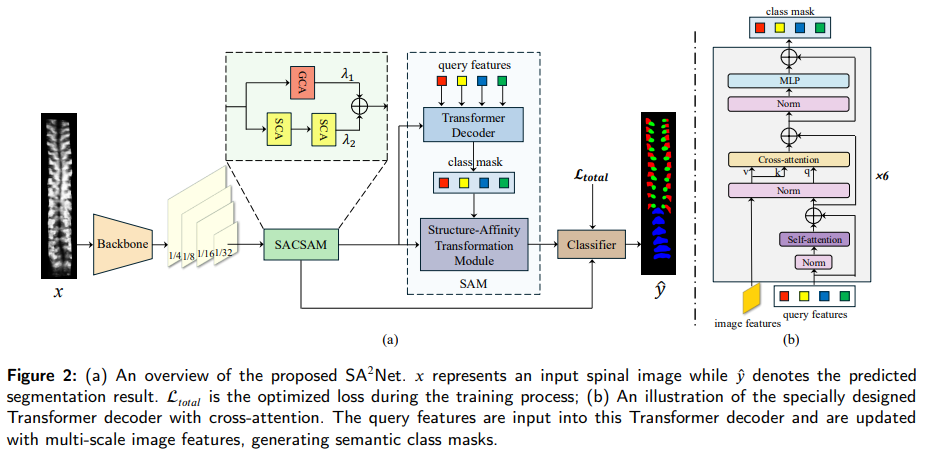
4、SANet: Scale-Adaptive Structure-Affinity Transformation for Spine Segmentation from Ultrasound Volume Projection Imaging
作者:Hao Xie, Zixun Huang, Yushen Zuo, Yakun Ju, Frank H. F. Leung, N. F. Law, Kin-Man Lam, Yong-Ping Zheng, Sai Ho Ling
亮点:提出尺度自适应结构感知网络SANet,通过跨维度长距离关联学习与结构亲和性转换机制,结合特征混合损失聚合,实现超声容积投影图像中脊柱分割性能超越现有SOTA方法。
论文:https://arxiv.org/abs/2510.26568
开源代码:https://github.com/taetiseo09/SA2Net
Comments:Accepted by Computerized Medical Imaging and Graphics (CMIG)
二、视频理解与生成方向
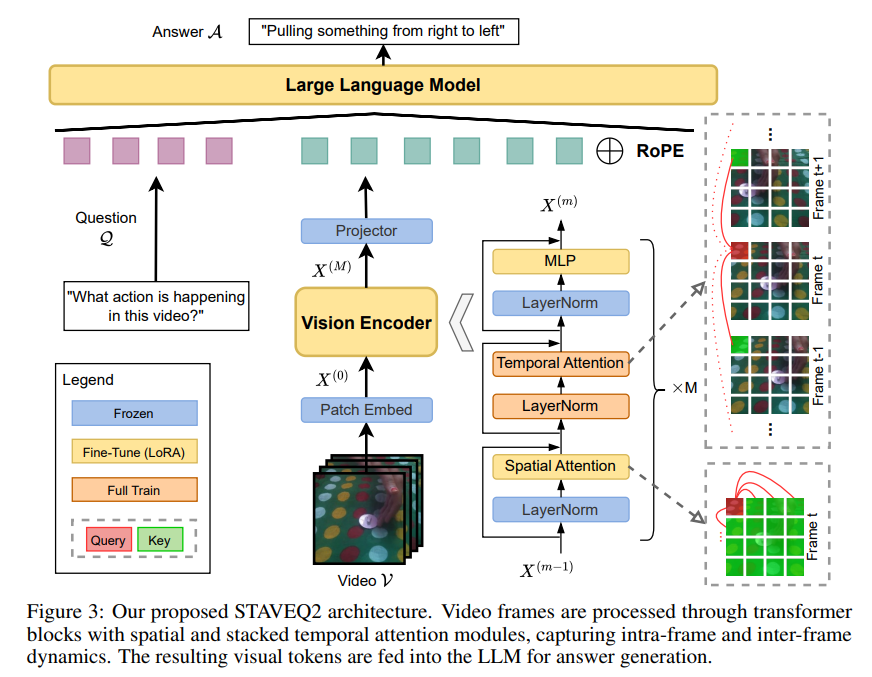
1、Enhancing Temporal Understanding in Video-LLMs through Stacked Temporal Attention in Vision Encoders
作者:Ali Rasekh, Erfan Bagheri Soula, Omid Daliran, Simon Gottschalk, Mohsen Fayyaz
亮点:在视觉编码器中引入堆叠时序注意力模块,解决Video-LLM对动作序列和时间进展的理解缺陷,在VITATECS、MVBench等基准测试中性能提升高达5.5%,显著增强视频问答与动作识别能力。
论文:https://arxiv.org/abs/2510.26027
开源代码:https://alirasekh.github.io/STAVEQ2/
Comments:Accepted to NeurIPS 2025
2、VC4VG: Optimizing Video Captions for Text-to-Video Generation
作者:Yang Du, Zhuoran Lin, Kaiqiang Song, Biao Wang, Zhicheng Zheng, Tiezheng Ge, Bo Zheng, Qin Jin
亮点:提出面向文本到视频生成的字幕优化框架VC4VG,构建多维度细粒度评估基准VC4VG-Bench,通过优化字幕质量显著提升T2V模型生成的连贯性与指令对齐度。

论文:https://arxiv.org/abs/2510.24134
开源代码:https://github.com/alimama-creative/VC4VG
Comments:Accepted by EMNLP 2025
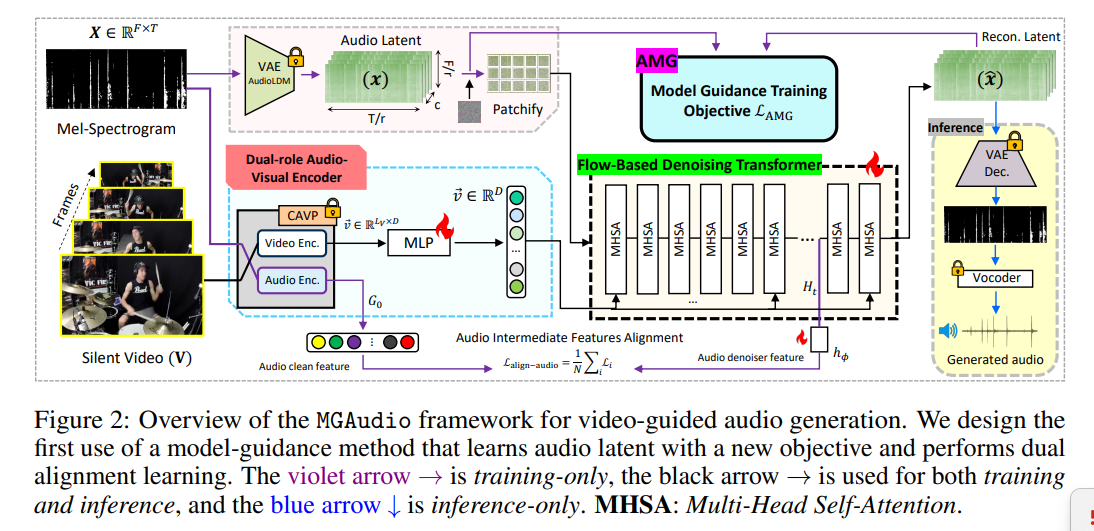
3、Model-Guided Dual-Role Alignment for High-Fidelity Open-Domain Video-to-Audio Generation
作者:Kang Zhang, Trung X. Pham, Suyeon Lee, Axi Niu, Arda Senocak, Joon Son Chung
亮点:提出流基框架MGAudio,通过模型引导的双角色对齐机制,实现生成模型自引导优化,在VGGSound数据集上将FAD降至0.40,显著超越现有方法,且在UnAV-100基准中表现出强泛化性。
论文:https://arxiv.org/abs/2510.24103
开源代码:https://github.com/pantheon5100/mgaudio
Comments:accepted by NeurIPS 2025
三、3D场景理解与定位方向
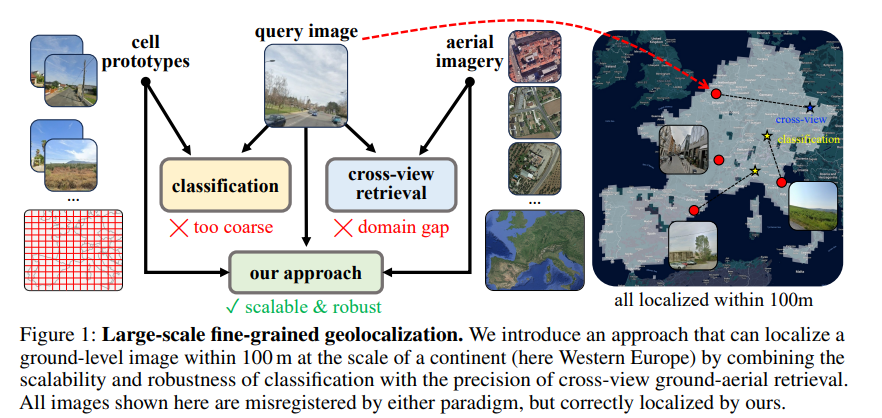
1、Scaling Image Geo-Localization to Continent Level
作者:Philipp Lindenberger, Paul-Edouard Sarlin, Jan Hosang, Matteo Balice, Marc Pollefeys, Simon Lynen, Eduard Trulls
亮点:提出混合地理定位方法,通过代理分类任务学习位置编码特征,结合航空影像嵌入解决地面数据稀疏问题,实现欧洲大范围区域内68%以上查询的200米精度定位,突破大陆级细粒度定位瓶颈。
论文:https://arxiv.org/abs/2510.26795
开源代码:https://scaling-geoloc.github.io
Comments:NeurIPS 2025
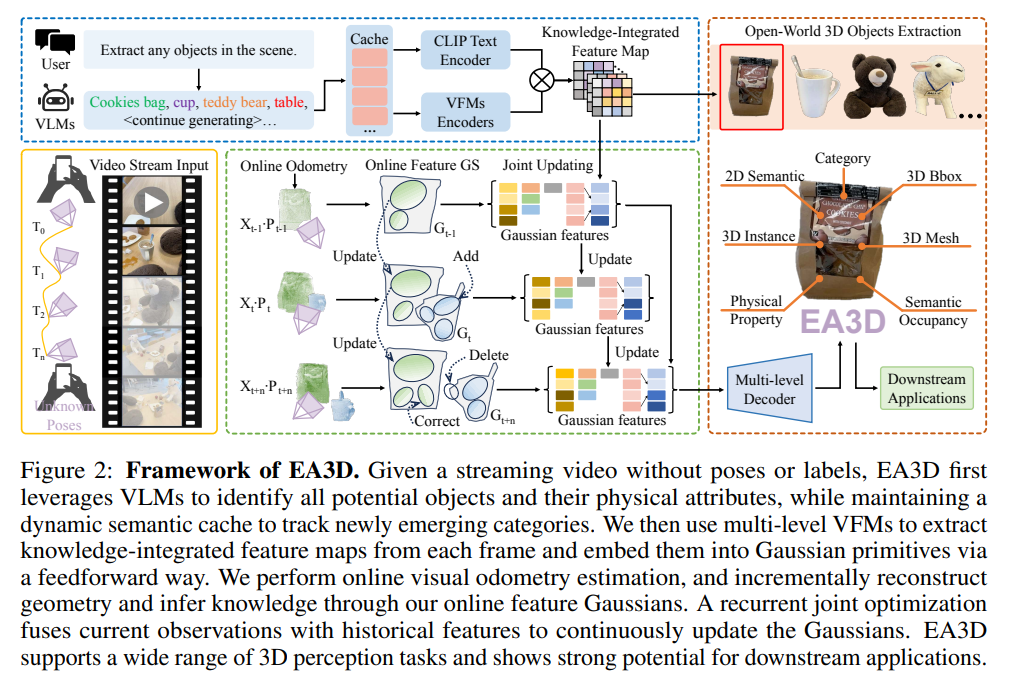
2、EA3D: Online Open-World 3D Object Extraction from Streaming Videos
作者:Xiaoyu Zhou, Jingqi Wang, Yuang Jia, Yongtao Wang, Deqing Sun, Ming-Hsuan Yang
亮点:提出统一在线框架EA3D,融合视觉-语言与2D视觉基础编码器,通过高斯特征图在线更新与循环联合优化,实现流式视频中3D目标提取、几何重建与语义理解的同步完成,支持多下游任务。
论文:https://arxiv.org/abs/2510.25146
开源代码:https://github.com/VDIGPKU/EA3D
Comments:The Thirty-Ninth Annual Conference on Neural Information Processing Systems(NeurIPS 2025)
四、视觉安全与实用场景应用方向
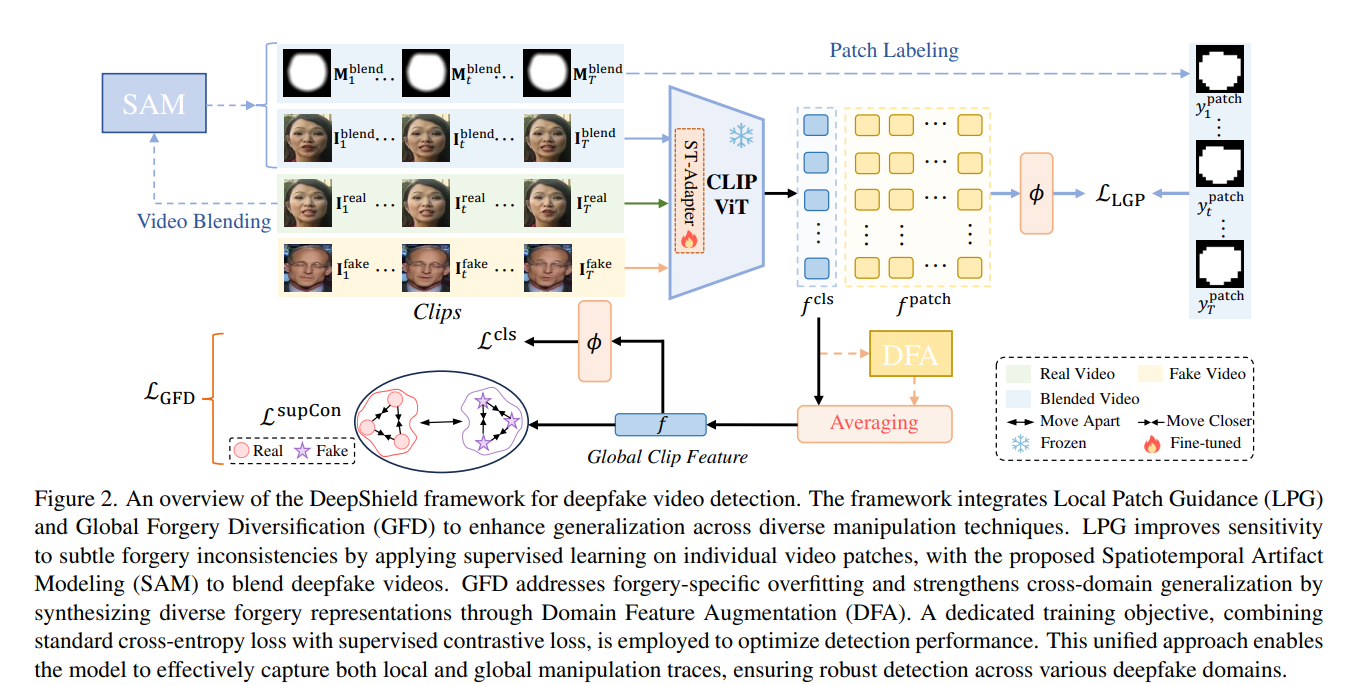
1、DeepShield: Fortifying Deepfake Video Detection with Local and Global Forgery Analysis
作者:Yinqi Cai, Jichang Li, Zhaolun Li, Weikai Chen, Rushi Lan, Xi Xie, Xiaonan Luo, Guanbin Li
亮点:提出深度伪造检测框架DeepShield,通过局部补丁引导捕捉细粒度伪影,结合全局伪造多样化增强跨域适应性,在跨数据集和跨操纵场景中表现超越现有SOTA方法,提升对未知伪造攻击的鲁棒性。
论文:https://arxiv.org/pdf/2510.25237
Comments:ICCV 2025
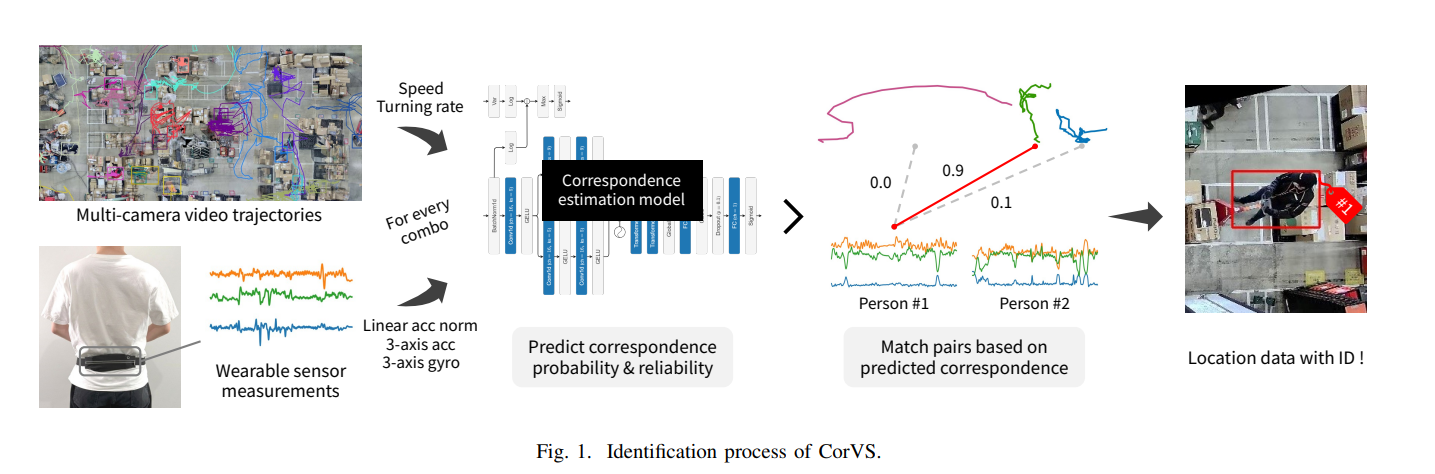
2、CorVS: Person Identification via Video Trajectory-Sensor Correspondence in a Real-World Warehouse
作者:Kazuma Kano, Yuki Mori, Shin Katayama, Kenta Urano, Takuro Yonezawa, Nobuo Kawaguchi
亮点:提出基于视觉轨迹与传感器数据对应的人员识别方法CorVS,通过深度学习预测对应概率与可靠性,实现真实仓库场景下的高效匹配,解决纯视觉识别在工业环境中的实用性问题。
论文:https://arxiv.org/abs/2510.26369
Comments:7 pages, 3 figures, accepted to IPIN 2025
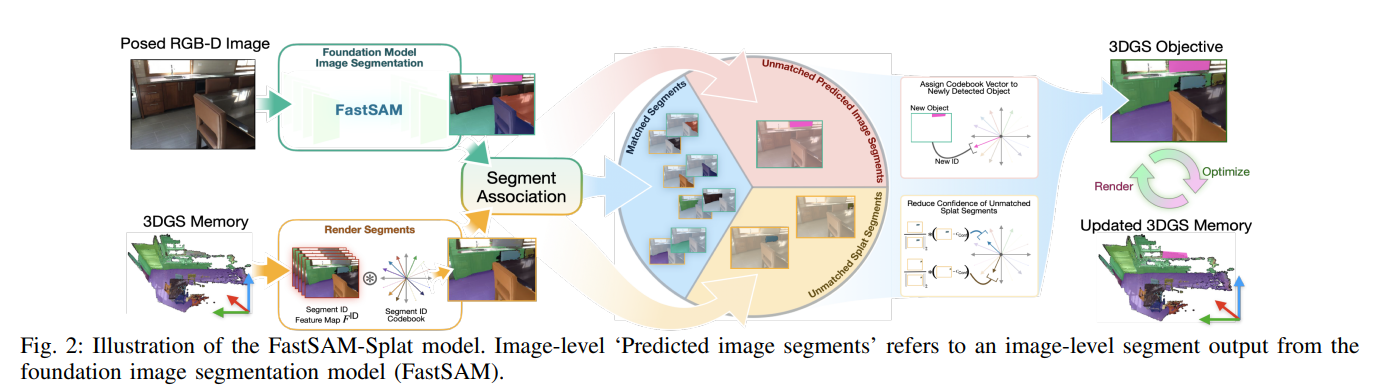
3、Explicit Memory through Online 3D Gaussian Splatting Improves Class-Agnostic Video Segmentation
作者:Anthony Opipari, Aravindhan K Krishnan, Shreekant Gayaka, Min Sun, Cheng-Hao Kuo, Arnie Sen, Odest Chadwicke Jenkins
亮点:通过在线3D高斯溅射技术构建显式记忆,提出FastSAM-Splat和SAM2-Splat融合方案,解决无记忆或隐式记忆模型的分割一致性问题,显著提升真实与模拟场景下的类别无关视频分割精度。
论文:https://arxiv.org/abs/2510.23521
开源代码:https://topipari.com/projects/FastSAM-Splat/
Comments:Accepted in IEEE Robotics and Automation Letters September 2025