import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snsfrom datetime import datetimeimport warningswarnings.filterwarnings('ignore')# 设置中文字体plt.rcParams['font.sans-serif'] = ['SimHei']plt.rcParams['axes.unicode_minus'] = Falseprint("✅ 环境设置完成")✅ 环境设置完成# 生成模拟销售数据np.random.seed(42)# 创建日期范围dates = pd.date_range('2023-01-01', '2024-01-31', freq='D')# 生成销售数据data = { '订单ID': range(1, len(dates) + 1), '日期': dates, '产品类别': np.random.choice(['电子产品', '服装', '家居', '食品', '图书'], len(dates), p=[0.3, 0.25, 0.2, 0.15, 0.1]), '销售额': np.random.normal(500, 200, len(dates)).clip(50, 2000), '数量': np.random.randint(1, 20, len(dates)), '客户类型': np.random.choice(['新客户', '老客户', 'VIP客户'], len(dates), p=[0.4, 0.5, 0.1]), '地区': np.random.choice(['北京', '上海', '广州', '深圳', '杭州', '成都'], len(dates))}df = pd.DataFrame(data)df['月份'] = df['日期'].dt.to_period('M')df['季度'] = df['日期'].dt.quarterdf['星期'] = df['日期'].dt.day_name()print("📊 数据概览:")print(f"数据形状: {df.shape}")print("\n前5行数据:")display(df.head())print("\n数据基本信息:")df.info()📊 数据概览:
数据形状: (396, 10)
前5行数据:| | 订单ID | 日期 | 产品类别 | 销售额 | 数量 | 客户类型 | 地区 | 月份 | 季度 | 星期 |
| 0 | 1 | 2023-01-01 | 服装 | 456.463759 | 5 | 老客户 | 深圳 | 2023-01 | 1 | Sunday |
| 1 | 2 | 2023-01-02 | 图书 | 719.755370 | 5 | 新客户 | 北京 | 2023-01 | 1 | Monday |
| 2 | 3 | 2023-01-03 | 家居 | 665.083270 | 6 | 老客户 | 北京 | 2023-01 | 1 | Tuesday |
| 3 | 4 | 2023-01-04 | 家居 | 662.701927 | 9 | 新客户 | 成都 | 2023-01 | 1 | Wednesday |
| 4 | 5 | 2023-01-05 | 电子产品 | 761.095761 | 2 | VIP客户 | 杭州 | 2023-01 | 1 | Thursday |
|---|
数据基本信息:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 396 entries, 0 to 395
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 订单ID 396 non-null int64
1 日期 396 non-null datetime64[ns]
2 产品类别 396 non-null object
3 销售额 396 non-null float64
4 数量 396 non-null int32
5 客户类型 396 non-null object
6 地区 396 non-null object
7 月份 396 non-null period[M]
8 季度 396 non-null int64
9 星期 396 non-null object
dtypes: datetime64[ns](1), float64(1), int32(1), int64(2), object(4), period[M](1)
memory usage: 29.5+ KB# 生成模拟销售数据np.random.seed(42)# 创建日期范围dates = pd.date_range('2023-01-01', '2024-01-31', freq='D')# 生成销售数据data = { '订单ID': range(1, len(dates) + 1), '日期': dates, '产品类别': np.random.choice(['电子产品', '服装', '家居', '食品', '图书'], len(dates), p=[0.3, 0.25, 0.2, 0.15, 0.1]), '销售额': np.random.normal(500, 200, len(dates)).clip(50, 2000), '数量': np.random.randint(1, 20, len(dates)), '客户类型': np.random.choice(['新客户', '老客户', 'VIP客户'], len(dates), p=[0.4, 0.5, 0.1]), '地区': np.random.choice(['北京', '上海', '广州', '深圳', '杭州', '成都'], len(dates))}df = pd.DataFrame(data)df['月份'] = df['日期'].dt.to_period('M')df['季度'] = df['日期'].dt.quarterdf['星期'] = df['日期'].dt.day_name()print("📊 数据概览:")print(f"数据形状: {df.shape}")print("\n前5行数据:")display(df.head())print("\n数据基本信息:")df.info()📊 数据概览:
数据形状: (396, 10)
前5行数据:| | 订单ID | 日期 | 产品类别 | 销售额 | 数量 | 客户类型 | 地区 | 月份 | 季度 | 星期 |
| 0 | 1 | 2023-01-01 | 服装 | 456.463759 | 5 | 老客户 | 深圳 | 2023-01 | 1 | Sunday |
| 1 | 2 | 2023-01-02 | 图书 | 719.755370 | 5 | 新客户 | 北京 | 2023-01 | 1 | Monday |
| 2 | 3 | 2023-01-03 | 家居 | 665.083270 | 6 | 老客户 | 北京 | 2023-01 | 1 | Tuesday |
| 3 | 4 | 2023-01-04 | 家居 | 662.701927 | 9 | 新客户 | 成都 | 2023-01 | 1 | Wednesday |
| 4 | 5 | 2023-01-05 | 电子产品 | 761.095761 | 2 | VIP客户 | 杭州 | 2023-01 | 1 | Thursday |
|---|
数据基本信息:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 396 entries, 0 to 395
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 订单ID 396 non-null int64
1 日期 396 non-null datetime64[ns]
2 产品类别 396 non-null object
3 销售额 396 non-null float64
4 数量 396 non-null int32
5 客户类型 396 non-null object
6 地区 396 non-null object
7 月份 396 non-null period[M]
8 季度 396 non-null int64
9 星期 396 non-null object
dtypes: datetime64[ns](1), float64(1), int32(1), int64(2), object(4), period[M](1)
memory usage: 29.5+ KBprint("📈 基础统计分析")print("=" * 50)# 总体统计print("总体销售统计:")print(f"总销售额: {df['销售额'].sum():,.2f}元")print(f"平均订单额: {df['销售额'].mean():.2f}元")print(f"总订单数: {df.shape[0]:,}笔")print(f"平均每单数量: {df['数量'].mean():.1f}件")print("\n月度销售趋势:")monthly_sales = df.groupby('月份')['销售额'].agg(['sum', 'count', 'mean']).round(2)display(monthly_sales)📈 基础统计分析
==================================================
总体销售统计:
总销售额: 196,690.15元
平均订单额: 496.69元
总订单数: 396笔
平均每单数量: 10.1件
月度销售趋势:| | sum | count | mean |
| 月份 | | | |
| 2023-01 | 16411.57 | 31 | 529.41 |
| 2023-02 | 13914.87 | 28 | 496.96 |
| 2023-03 | 16591.17 | 31 | 535.20 |
| 2023-04 | 15971.49 | 30 | 532.38 |
| 2023-05 | 13672.78 | 31 | 441.06 |
| 2023-06 | 14891.61 | 30 | 496.39 |
| 2023-07 | 14779.17 | 31 | 476.75 |
| 2023-08 | 13753.22 | 31 | 443.65 |
| 2023-09 | 14863.39 | 30 | 495.45 |
| 2023-10 | 16057.34 | 31 | 517.98 |
| 2023-11 | 15521.43 | 30 | 517.38 |
| 2023-12 | 14851.44 | 31 | 479.08 |
| 2024-01 | 15410.67 | 31 | 497.12 |
|---|
# 创建可视化图表fig, axes = plt.subplots(2, 3, figsize=(18, 12))fig.suptitle('销售数据多维度分析', fontsize=16, fontweight='bold')# 1. 月度销售趋势monthly_trend = df.groupby(df['日期'].dt.to_period('M'))['销售额'].sum()monthly_trend.plot(kind='line', ax=axes[0,0], marker='o', color='#2E86AB')axes[0,0].set_title('月度销售趋势')axes[0,0].set_ylabel('销售额(元)')axes[0,0].tick_params(axis='x', rotation=45)# 2. 产品类别销售分布category_sales = df.groupby('产品类别')['销售额'].sum().sort_values(ascending=True)category_sales.plot(kind='barh', ax=axes[0,1], color='#A23B72')axes[0,1].set_title('各产品类别销售额')axes[0,1].set_xlabel('销售额(元)')# 3. 地区销售分布region_sales = df.groupby('地区')['销售额'].sum().sort_values(ascending=True)region_sales.plot(kind='barh', ax=axes[0,2], color='#F18F01')axes[0,2].set_title('各地区销售额')axes[0,2].set_xlabel('销售额(元)')# 4. 客户类型分析customer_sales = df.groupby('客户类型').agg({ '销售额': ['sum', 'mean', 'count']}).round(2)customer_sales.columns = ['总销售额', '平均订单额', '订单数量']customer_sales['总销售额'].plot(kind='pie', ax=axes[1,0], autopct='%1.1f%%')axes[1,0].set_title('客户类型销售额分布')# 5. 星期销售分析weekday_sales = df.groupby('星期')['销售额'].mean()weekday_order = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']weekday_sales = weekday_sales.reindex(weekday_order)weekday_sales.plot(kind='bar', ax=axes[1,1], color='#C73E1D')axes[1,1].set_title('各星期平均销售额')axes[1,1].set_ylabel('平均销售额(元)')axes[1,1].tick_params(axis='x', rotation=45)# 6. 销售额分布直方图axes[1,2].hist(df['销售额'], bins=30, alpha=0.7, color='#3F7CAC', edgecolor='black')axes[1,2].set_title('销售额分布')axes[1,2].set_xlabel('销售额(元)')axes[1,2].set_ylabel('频次')plt.tight_layout()plt.show()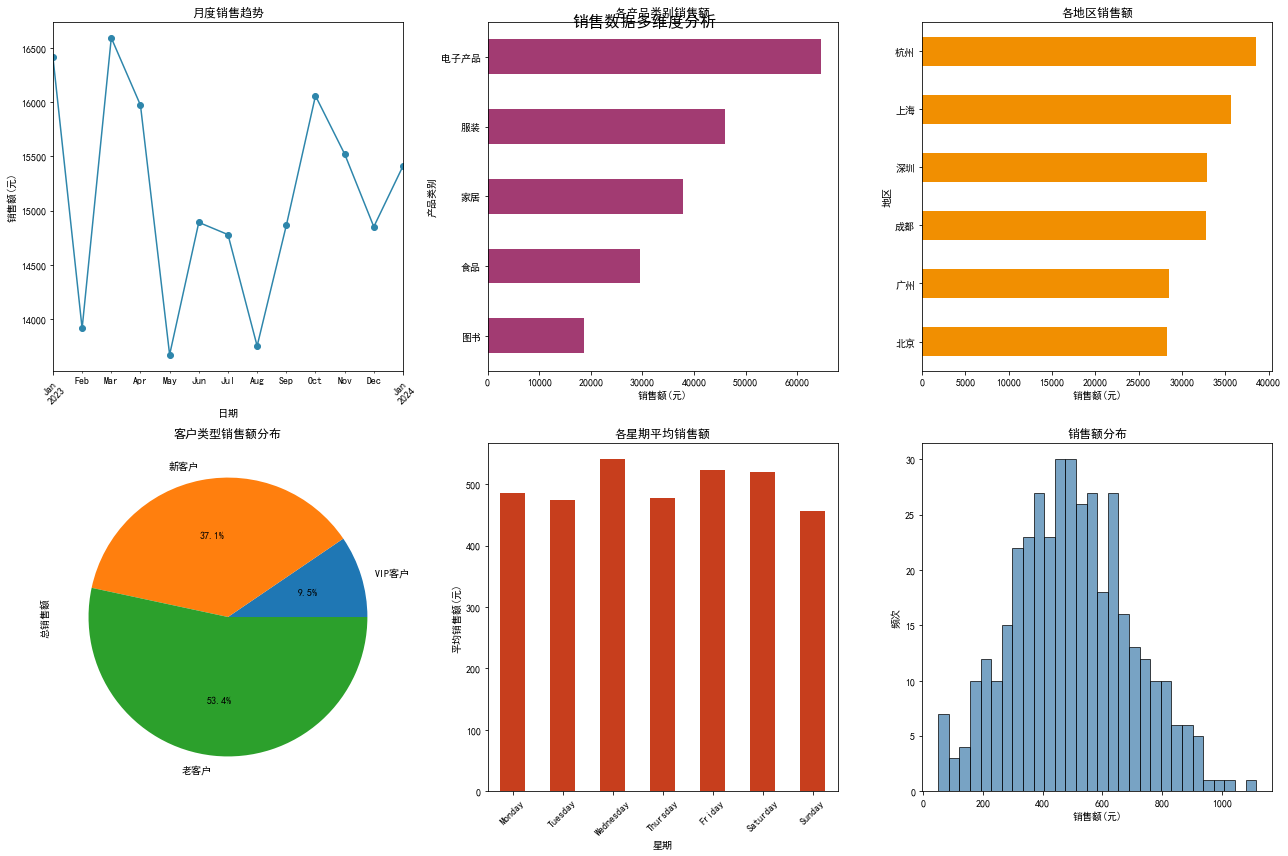
# 客户价值分析print("👥 客户价值分析")print("=" * 50)customer_analysis = df.groupby('客户类型').agg({ '销售额': ['sum', 'mean', 'count'], '数量': 'mean'}).round(2)customer_analysis.columns = ['总销售额', '平均订单额', '订单数量', '平均数量']display(customer_analysis)# RFM 分析(简化版)print("\n📊 RFM分析 (Recency, Frequency, Monetary)")print("=" * 50)# 假设最近日期为分析日期analysis_date = df['日期'].max()rfm = df.groupby('客户类型').agg({ '日期': lambda x: (analysis_date - x.max()).days, # 最近购买时间 '订单ID': 'count', # 购买频次 '销售额': 'sum' # 购买金额}).round(2)rfm.columns = ['最近购买天数', '购买频次', '总金额']display(rfm)👥 客户价值分析
==================================================| | 总销售额 | 平均订单额 | 订单数量 | 平均数量 |
| 客户类型 | | | | |
| VIP客户 | 18691.46 | 519.21 | 36 | 10.78 |
| 新客户 | 73050.71 | 490.27 | 149 | 9.93 |
| 老客户 | 104947.98 | 497.38 | 211 | 10.10 |
|---|
📊 RFM分析 (Recency, Frequency, Monetary)
==================================================| | 最近购买天数 | 购买频次 | 总金额 |
| 客户类型 | | | |
| VIP客户 | 2 | 36 | 18691.46 |
| 新客户 | 1 | 149 | 73050.71 |
| 老客户 | 0 | 211 | 104947.98 |
|---|
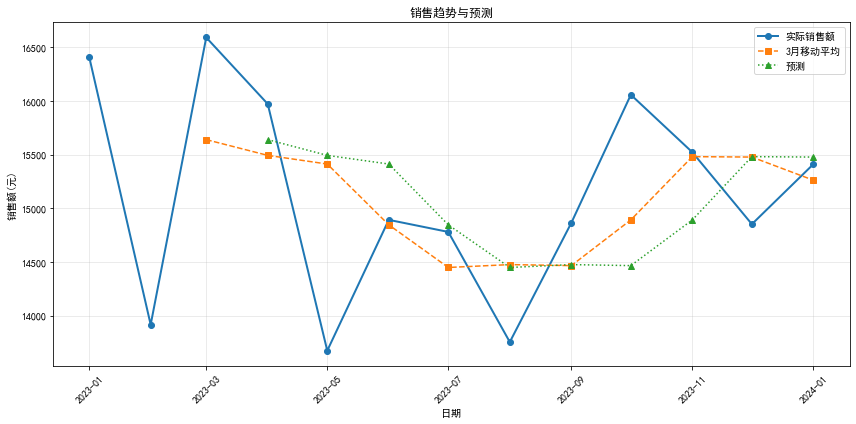
# 简单的移动平均预测print("🔮 销售预测分析")print("=" * 50)# 计算月度数据monthly_data = df.groupby(df['日期'].dt.to_period('M'))['销售额'].sum().reset_index()monthly_data['日期'] = monthly_data['日期'].dt.to_timestamp()# 计算移动平均monthly_data['3月移动平均'] = monthly_data['销售额'].rolling(window=3).mean()monthly_data['预测'] = monthly_data['3月移动平均'].shift(1)print("月度销售数据与预测:")display(monthly_data.tail(6))# 绘制预测图plt.figure(figsize=(12, 6))plt.plot(monthly_data['日期'], monthly_data['销售额'], marker='o', label='实际销售额', linewidth=2)plt.plot(monthly_data['日期'], monthly_data['3月移动平均'], marker='s', label='3月移动平均', linestyle='--')plt.plot(monthly_data['日期'], monthly_data['预测'], marker='^', label='预测', linestyle=':')plt.title('销售趋势与预测')plt.ylabel('销售额(元)')plt.xlabel('日期')plt.legend()plt.grid(True, alpha=0.3)plt.xticks(rotation=45)plt.tight_layout()plt.show()🔮 销售预测分析
==================================================
月度销售数据与预测:| | 日期 | 销售额 | 3月移动平均 | 预测 |
| 7 | 2023-08-01 | 13753.219574 | 14474.665291 | 14447.852675 |
| 8 | 2023-09-01 | 14863.387926 | 14465.258330 | 14474.665291 |
| 9 | 2023-10-01 | 16057.341556 | 14891.316352 | 14465.258330 |
| 10 | 2023-11-01 | 15521.429799 | 15480.719761 | 14891.316352 |
| 11 | 2023-12-01 | 14851.437307 | 15476.736221 | 15480.719761 |
| 12 | 2024-01-01 | 15410.666148 | 15261.177751 | 15476.736221 |
|---|
print("📋 销售分析总结报告")print("=" * 60)# 计算关键指标total_sales = df['销售额'].sum()avg_order_value = df['销售额'].mean()total_orders = df.shape[0]top_category = df.groupby('产品类别')['销售额'].sum().idxmax()top_region = df.groupby('地区')['销售额'].sum().idxmax()best_weekday = df.groupby('星期')['销售额'].mean().idxmax()print(f"""📈 销售绩效总结:• 总销售额: {total_sales:,.2f} 元• 总订单数: {total_orders:,} 笔• 平均订单价值: {avg_order_value:.2f} 元• 最畅销品类: {top_category}• 最佳销售地区: {top_region}• 销售最佳星期: {best_weekday}🎯 业务洞察:1. 销售最高的产品类别是 {top_category},建议加大该品类库存和营销投入2. {top_region} 地区表现最佳,可考虑在该地区开设新店或增加营销预算3. {best_weekday} 的客单价最高,适合在这天推出促销活动💡 建议行动:• 针对 {top_category} 品类进行深度营销• 在 {top_region} 地区扩大市场份额• 优化 {best_weekday} 的库存和人员安排• 加强客户关系管理,提高复购率""")📋 销售分析总结报告
============================================================
📈 销售绩效总结:
• 总销售额: 196,690.15 元
• 总订单数: 396 笔
• 平均订单价值: 496.69 元
• 最畅销品类: 电子产品
• 最佳销售地区: 杭州
• 销售最佳星期: Wednesday
🎯 业务洞察:
1. 销售最高的产品类别是 电子产品,建议加大该品类库存和营销投入
2. 杭州 地区表现最佳,可考虑在该地区开设新店或增加营销预算
3. Wednesday 的客单价最高,适合在这天推出促销活动
💡 建议行动:
• 针对 电子产品 品类进行深度营销
• 在 杭州 地区扩大市场份额
• 优化 Wednesday 的库存和人员安排
• 加强客户关系管理,提高复购率