TL;DR
- 场景:在 3 节内跑通 ClickHouse 的建库、建表、分区、ALTER 与分区生命周期管理。
- 结论:按本文命令即可完成从 0 到 1 的全流程,并能对分区做 Drop/Clear/Detach/Attach 等操作。
- 产出:一套可直接复制的命令序列 + 操作截图位。
基本介绍
ClickHouse 是一种用于 OLAP(在线分析处理)的列式数据库,因其高速数据处理能力在大数据分析中备受青睐。ClickHouse 的 SQL 语法与标准 SQL 类似,但由于其专注于分析场景,有一些特殊的扩展。ClickHouse 默认不支持直接 DELETE 或 UPDATE 操作,但可以通过分区管理和合并机制间接清理数据。ClickHouse 提供了很多专门为高效分析而设计的功能。ClickHouse 提供了丰富的聚合函数,如 sum()、avg()、min()、max()、count()。
基本 SQL 语法
ClickHouse 的 SQL 语法与标准 SQL 类似,但由于其专注于分析场景,有一些特殊的扩展。 创建表的时候:
sql
CREATE TABLE table_name (
column1 DataType,
column2 DataType,
...
) ENGINE = MergeTree()
ORDER BY (primary_key_columns);- ENGINE:表引擎,最常用的是 MergeTree 系列。
- ORDER BY:必须指定排序键,支持对大数据集高效查询。
- PARTITION BY:按列进行分区(可选)。
- SAMPLE BY:用于大数据量下的采样查询(可选)。
删除或清理表数据的时候: ClickHouse 默认不支持直接 DELETE 或 UPDATE 操作,但可以通过分区管理和合并机制间接清理数据。
sql
ALTER TABLE table_name DROP PARTITION partition_expr;特殊功能
聚合函数
ClickHouse 提供了丰富的聚合函数,如 sum()、avg()、min()、max()、count()。此外,还有以下特殊聚合函数:
sql
SELECT uniqExact(column) FROM table_name; -- 精确去重计数
SELECT quantiles(0.5, 0.9)(column) FROM table_name; -- 分位数计算窗口函数
ClickHouse 支持窗口函数,但语法略有不同。常见窗口函数有 row_number()、rank() 等:
sql
SELECT column, rowNumber() OVER (PARTITION BY partition_column ORDER BY sort_column)
FROM table_name;数组和嵌套类型
ClickHouse 支持数组和嵌套类型,适合处理复杂的数据结构:
sql
SELECT arrayJoin(array) FROM table_name;- arrayJoin:将数组展开为多行
MergeTree 引擎
MergeTree 是 ClickHouse 最常用的引擎之一,具备排序、索引和分区的特性,能够高效处理海量数据。
- ORDER BY:定义主键,数据按照该字段排序。
- PRIMARY KEY:可以和 ORDER BY 一致,用于快速定位。
- PARTITION BY:用于数据按逻辑分片,减少查询范围。
- TTL:设置数据过期时间,自动清理历史数据。
基本状况
目前我是ClickHouse的集群环境:
- h121.wzk.icu
- h122.wzk.icu
- h123.wzk.icu
建立连接
我们随机找一台建立链接
shell
clickhouse-client -m --host h121.wzk.icu --port 9001 --user default --password clickhouse@wzk.icu新建库
sql
CREATE DATABASE mydatabase;执行结果如下图所示: 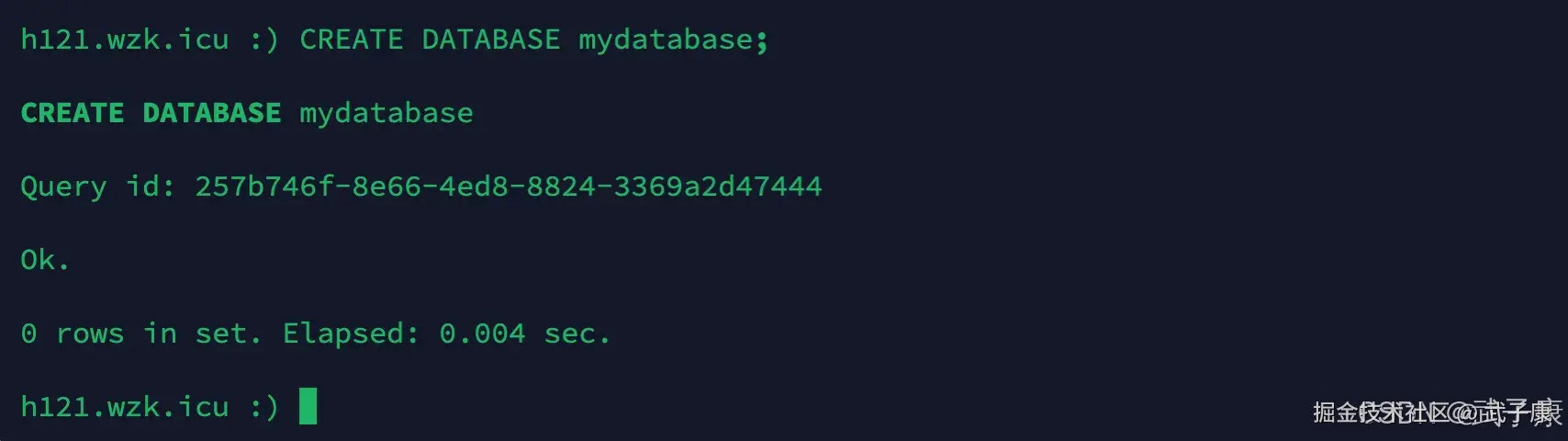
可以看到对应的路径如下所示:
shell
cd /var/lib/clickhouse/data
ls执行结果如下图,可以看到我们刚才创建的数据库: 
查看数据库
sql
SHOW DATABASES;运行结果如下图: 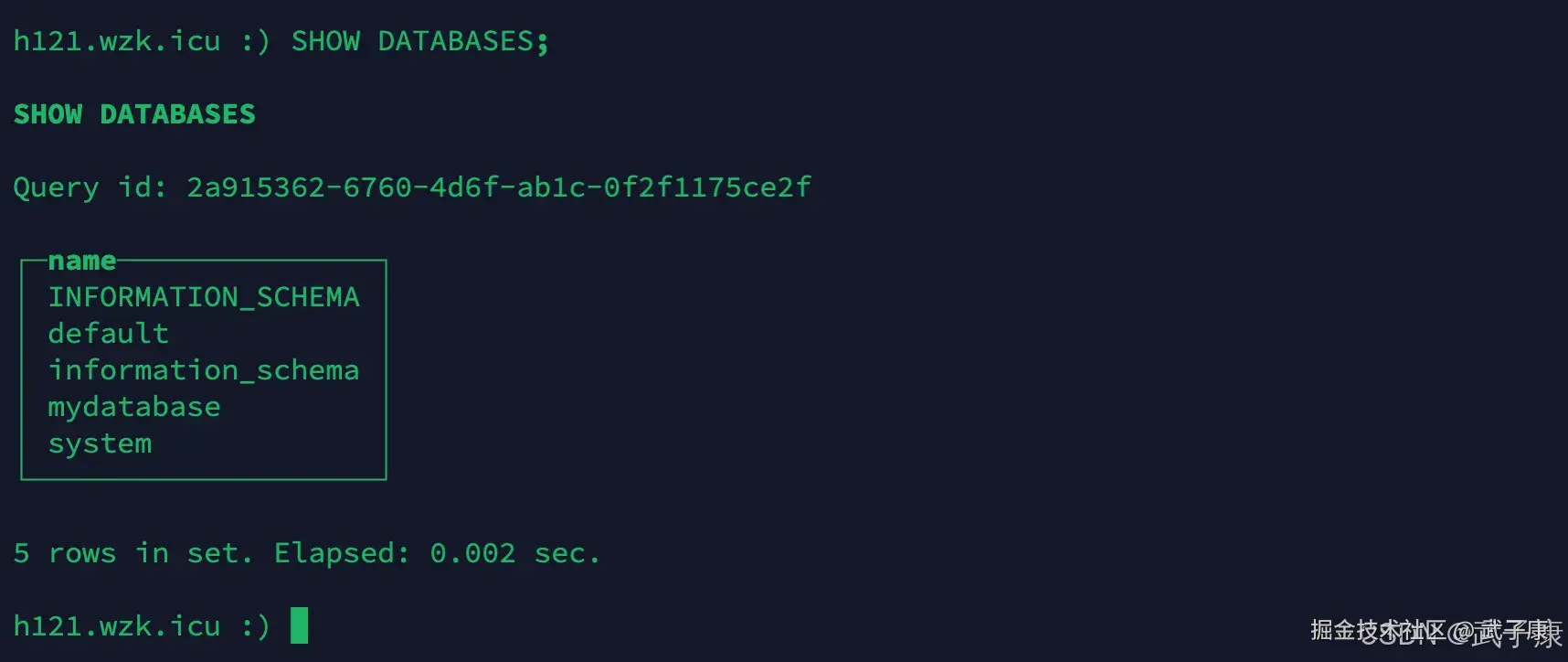
新建表
sql
# 方式1
CREATE TABLE my_table(
title String,
url String,
eventTime DateTime
) ENGINE = Memory;
# 方式2
CREATE TABLE mydatabase.my_table(
title String,
url String,
eventTime DateTime
) ENGINE = Memory;
# 方式3
CREATE TABLE mydatabase.my_table_2(
title String,
url String,
eventTime DateTime
) ENGINE = Memory AS SELECT * FROM mydatabase.my_table;执行结果如下图所示: 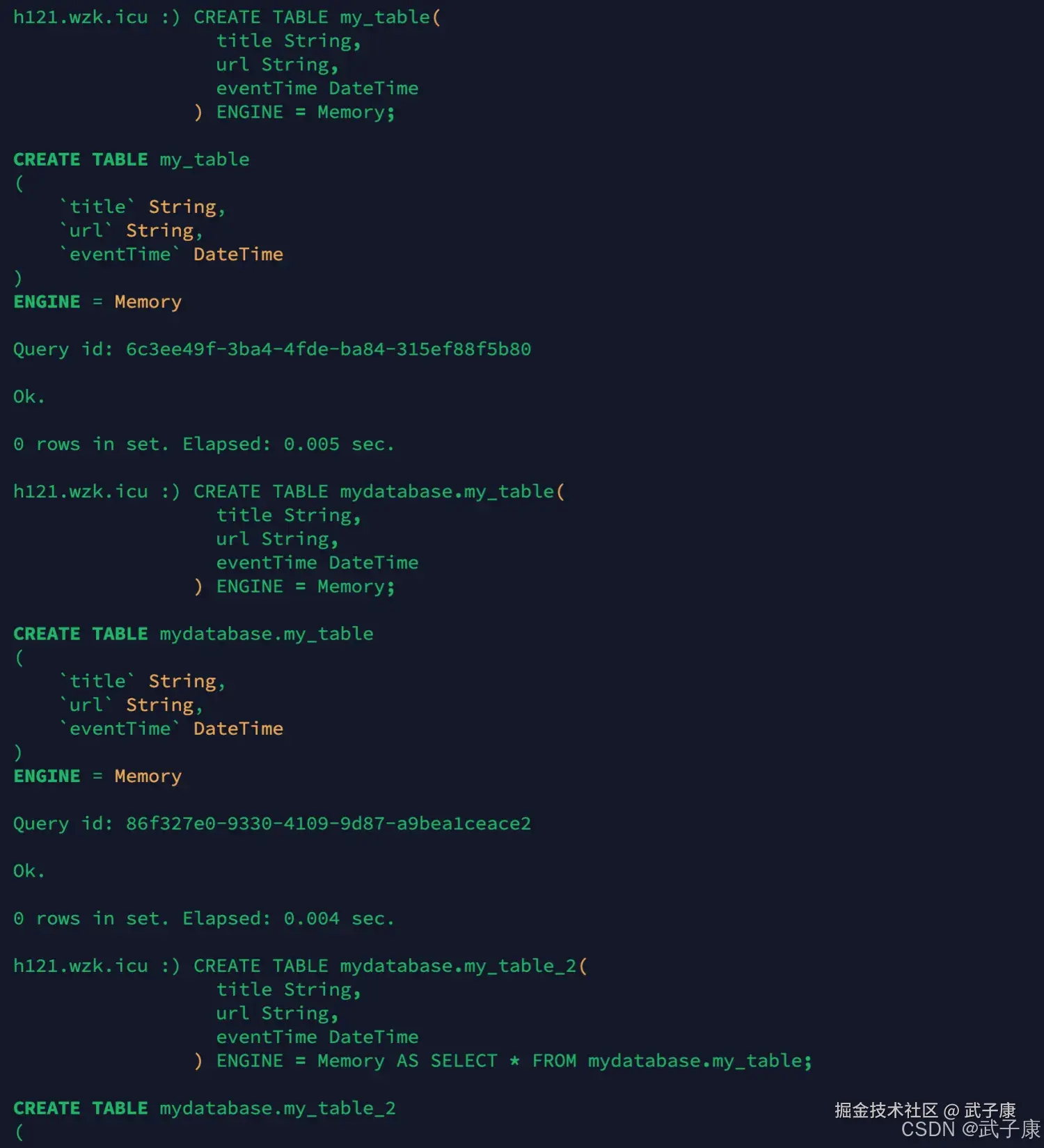
查表结构
sql
DESC my_table;执行结果如下图: 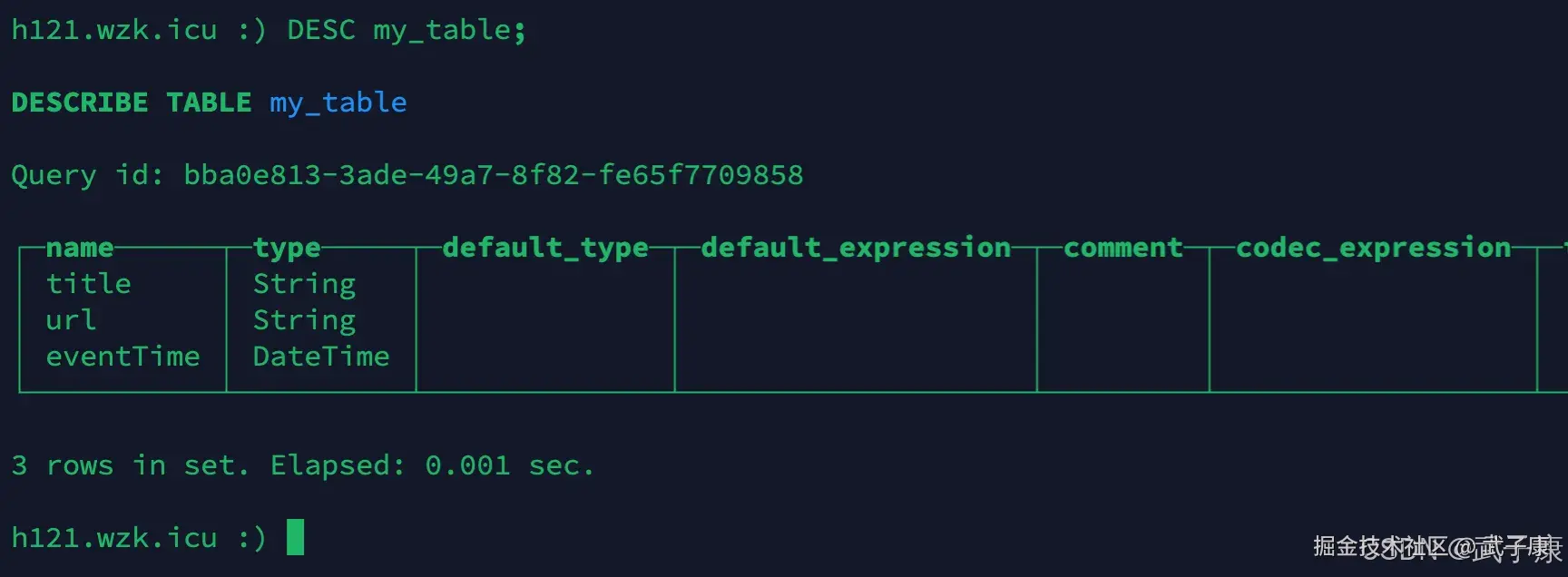
插入数据
sql
INSERT INTO my_table VALUES ('wzk', '123', now());执行的结果如下所示: 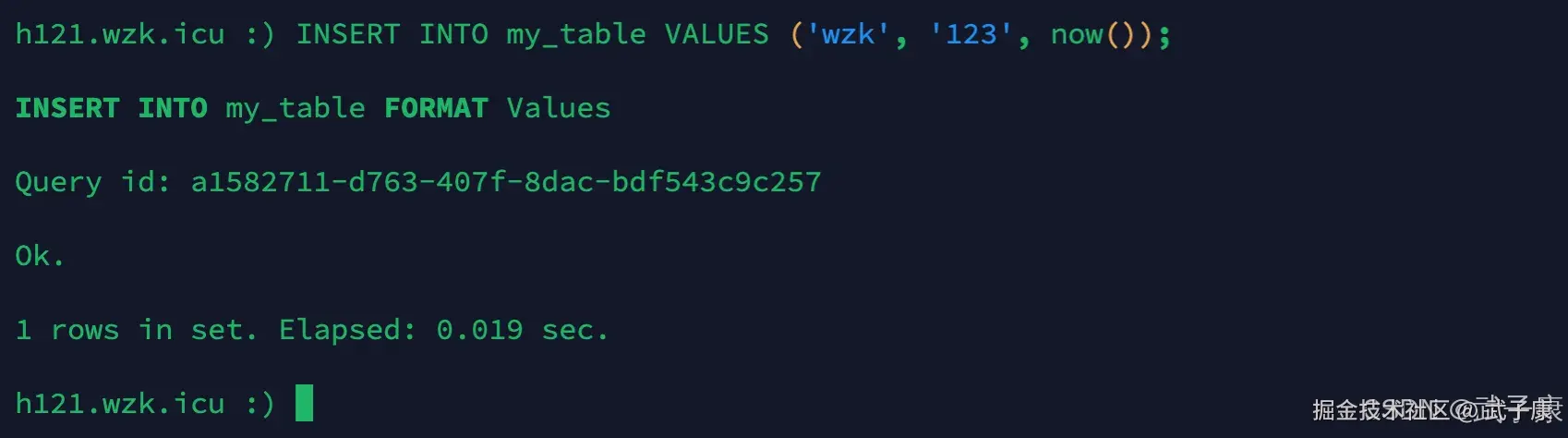
临时表
sql
CREATE TABLE tmp_v1 (
title String,
create_time DateTime
) ENGINE = Memory;如果临时表与正常表名字相同,临时表优先。 临时表的引擎只能是Memory,数据是临时的,断点数据就没了。 更多的是在ClickHouse内部,是数据在集群间传播度的载体。
分区表
创建新表
sql
CREATE TABLE partition_v1 (
`id` String,
`url` String,
`eventTime` Date
) ENGINE = MergeTree()
PARTITION BY toYYYYMM(eventTime)
ORDER BY id;执行结果如下所示: 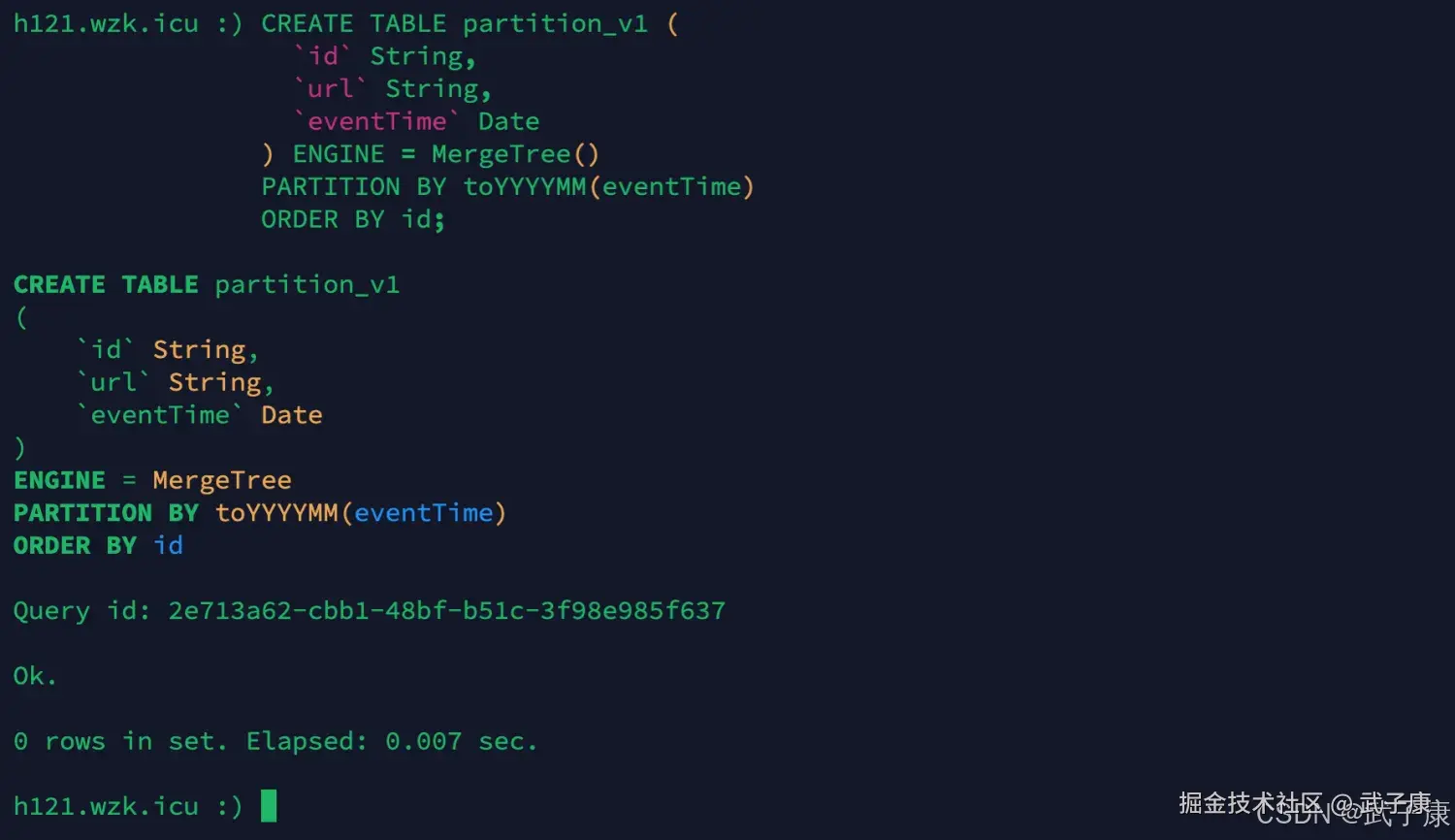
只有合并树(MergeTree)家族的表引擎支持分区表,可以利用分区表,做定位查询,缩小查询范围。分区字段不易设置的太小。
插入数据
sql
INSERT INTO partition_v1 (id, url, eventTime) VALUES
('1', 'http://example.com/page1', '2024-01-01'),
('2', 'http://example.com/page2', '2024-01-15'),
('3', 'http://example.com/page3', '2024-02-01'),
('4', 'http://example.com/page4', '2024-02-15'),
('5', 'http://example.com/page5', '2024-03-01'),
('6', 'http://example.com/page6', '2024-03-15');执行结果如下图所示: 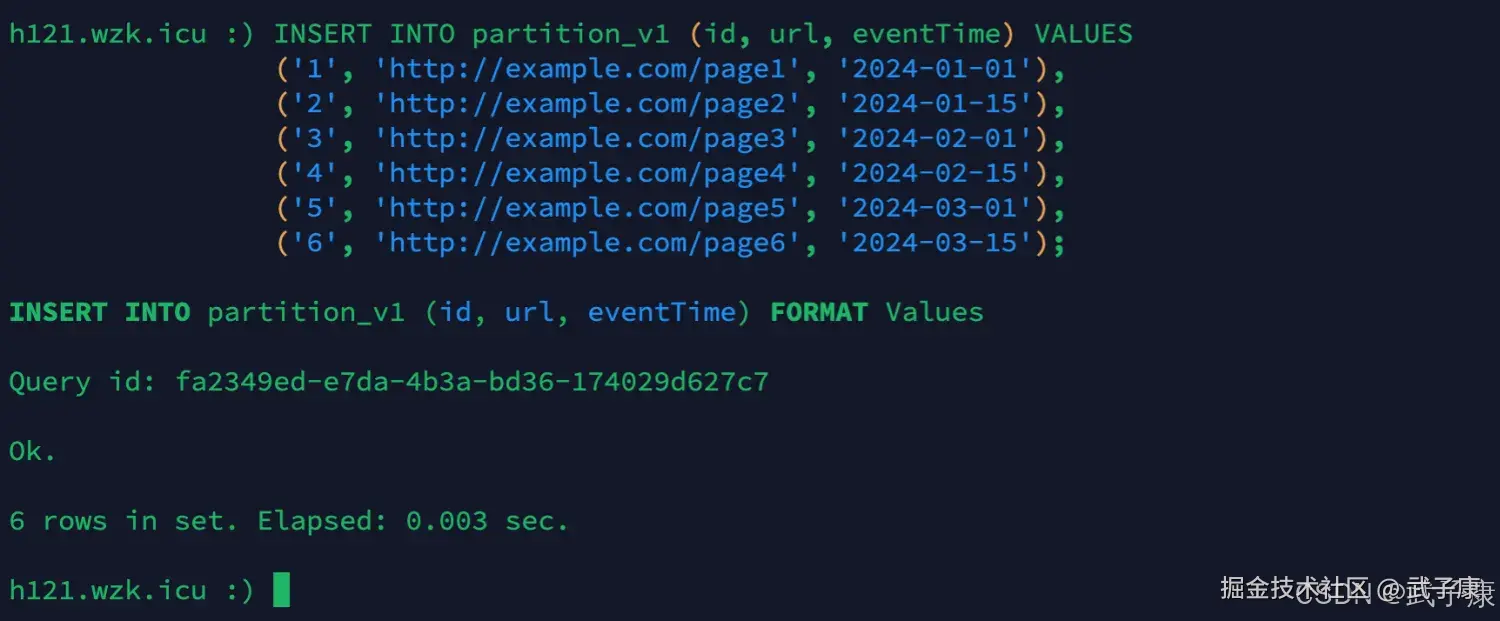
查询数据
sql
SELECT * FROM partition_v1;执行结果如下所示: 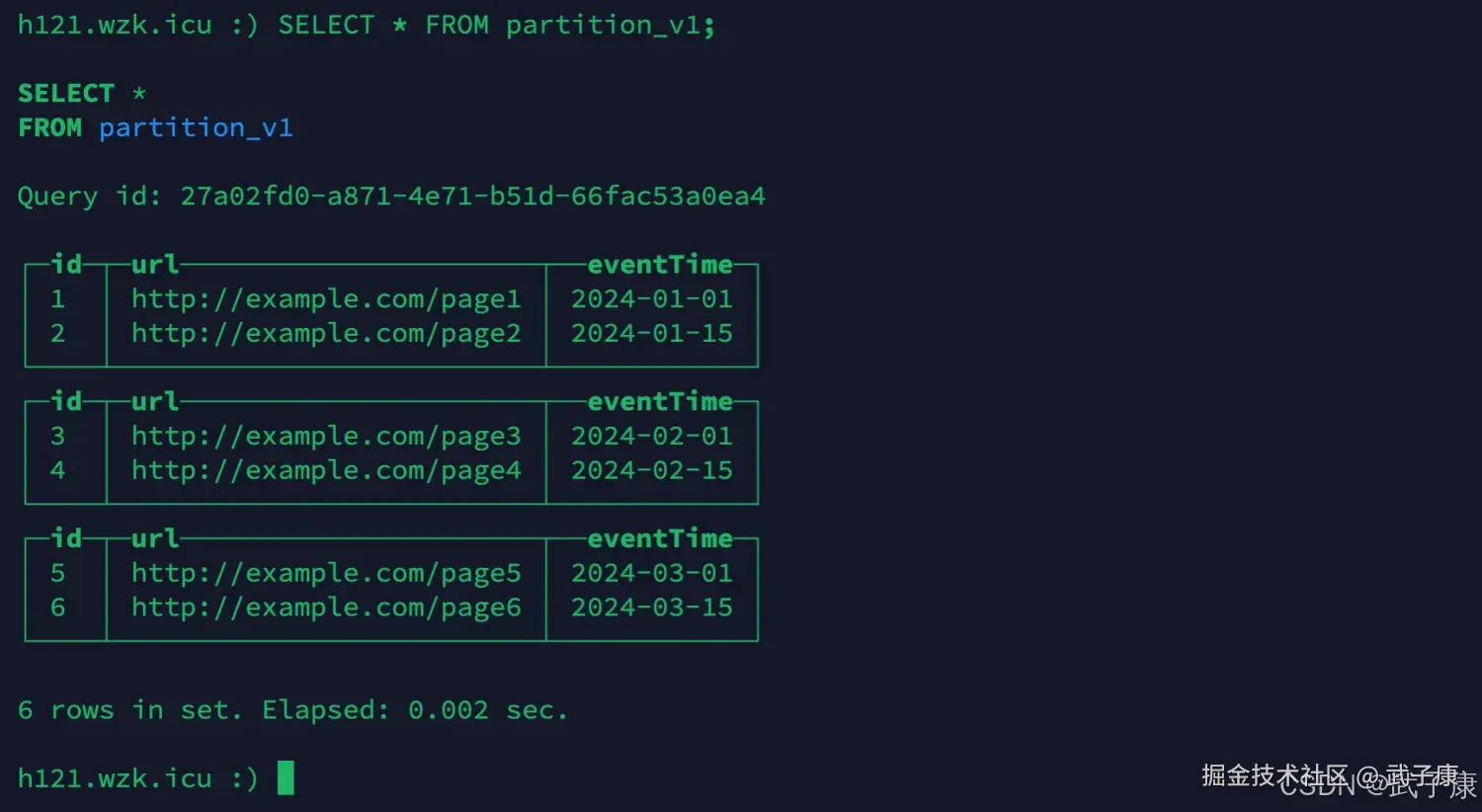
查看分区
sql
SELECT table, partition, path FROM system.parts WHERE table = 'partition_v1';执行结果如下图所示: 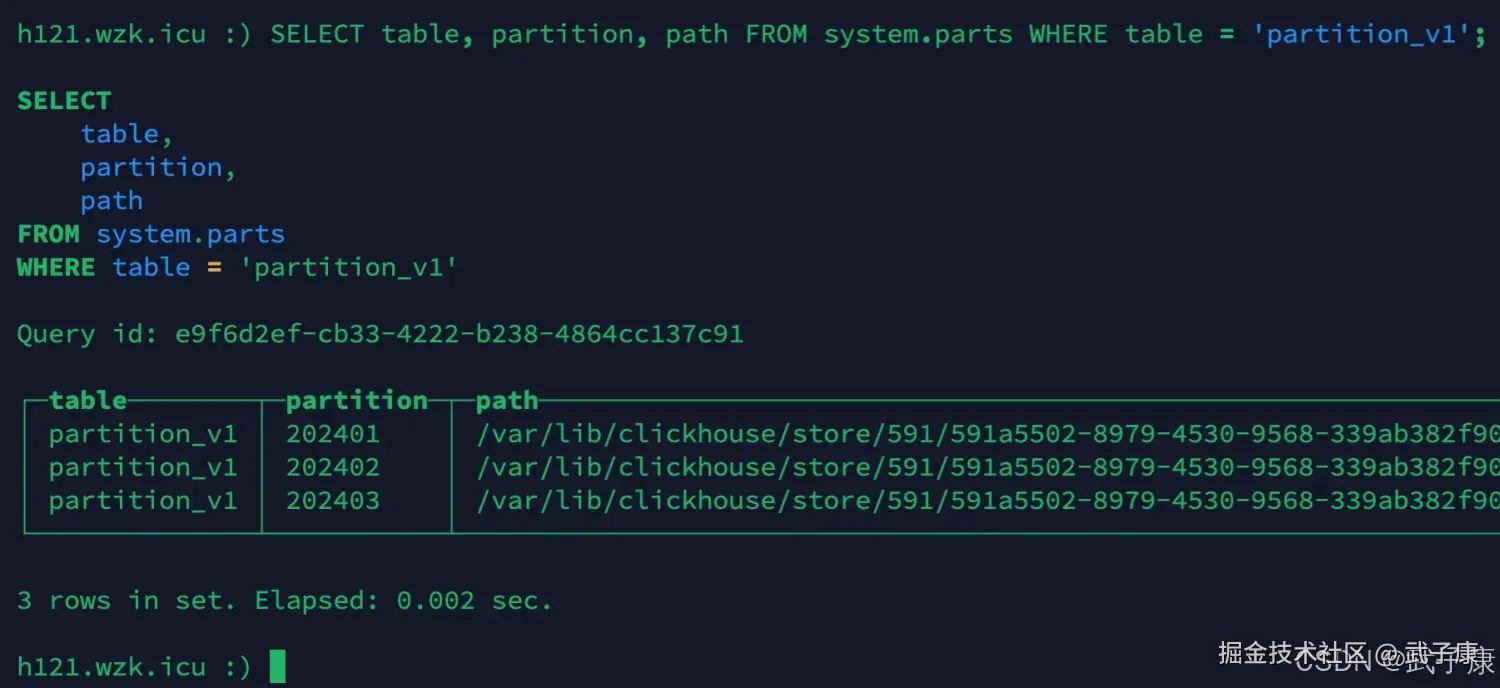
视图表
- 普通视图:不保存数据,只是一层单纯的SELECT查询映射,起着简化查询的作用
- 物化视图:保存数据,源表被写入数据,物化视图也会同步更新
- POPULATE修饰符:决定在创建物化视图的过程中是否将源表的数据同步到物化视图。
表基本操作
只有 MergeTree、Merge、Distribution这三类表引擎支持ALTER操作!!!
追加字段
sql
ALTER TABLE partition_v1 ADD COLUMN os String default 'mac';
ALTER TABLE partition_v1 ADD COLUMN ip String after id;
DESC partition_v1;执行结果如下: 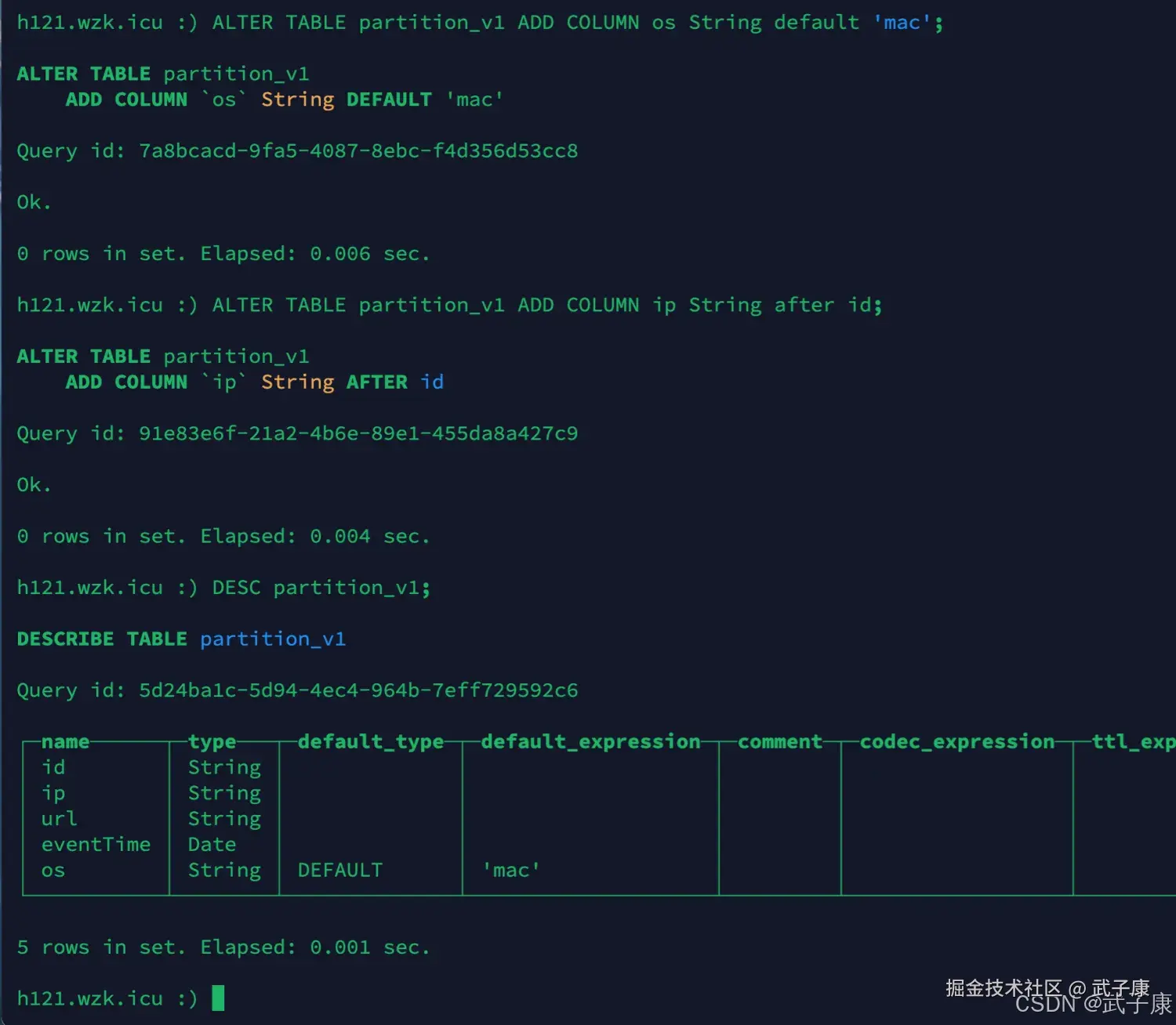
修改类型
注意:类型需要互相兼容
sql
ALTER TABLE partition_v1 modify column ip IPv4;
DESC partition_v1;执行结果如下图所示: 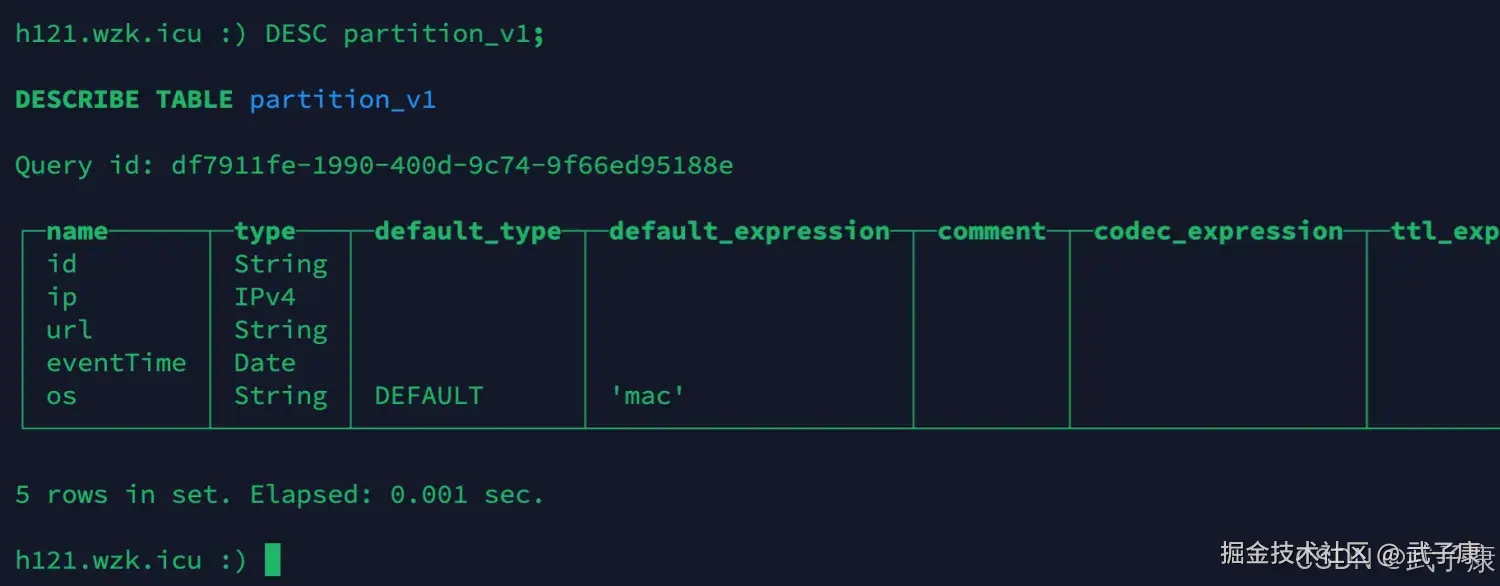
修改备注
sql
ALTER TABLE partition_v1 COMMENT COLUMN id '主键ID';
DESC partition_v1;执行结果如下图所示: 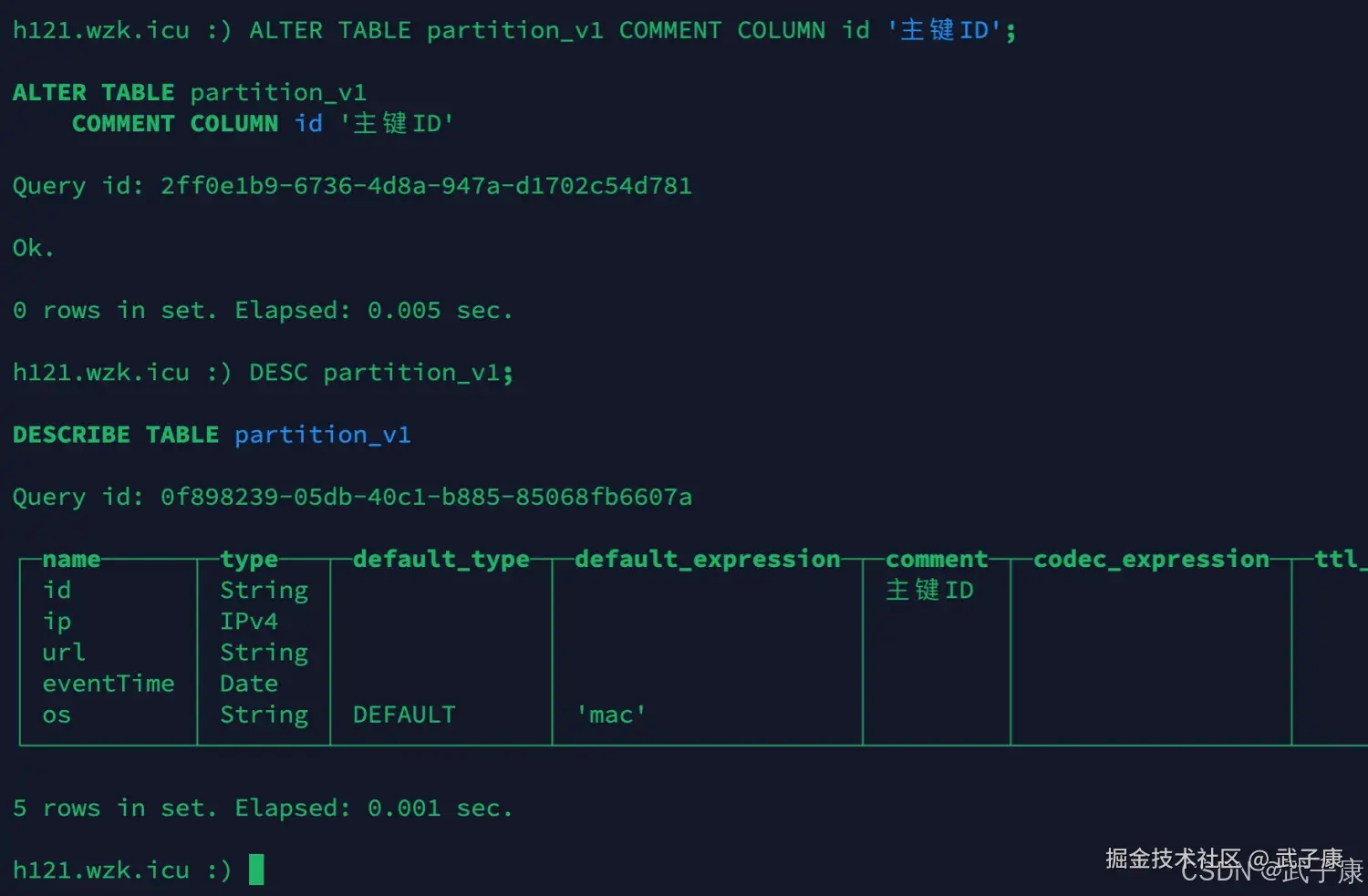
删除字段
sql
ALTER TABLE partition_v1 DROP COLUMN url;
DESC partition_v1;注意,删除字段会把该字段下的数据一起删除: 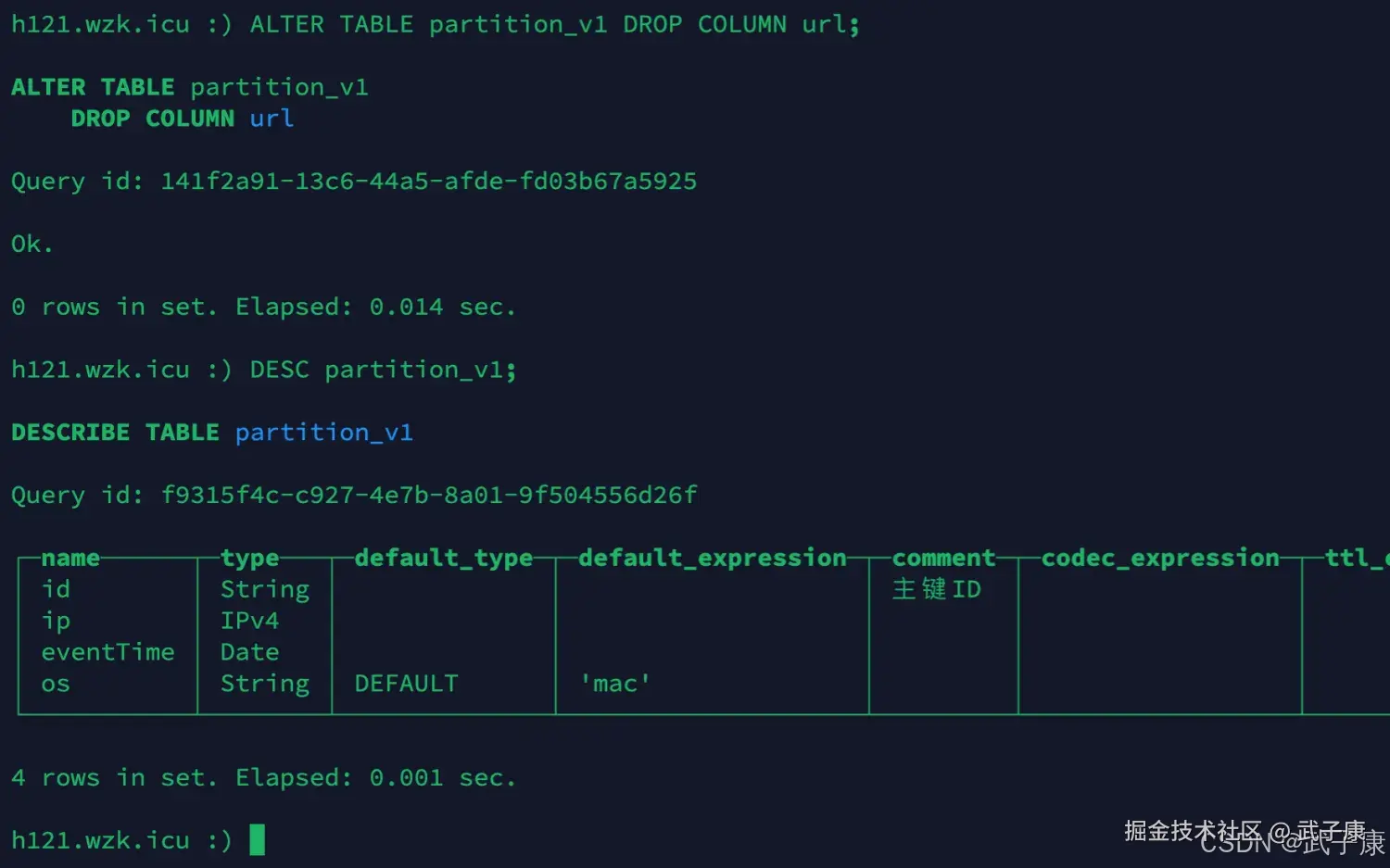
移动表
sql
rename TABLE default.partition_v1 to mydatabase.partition_v1;
USE mydatabase;
SHOW TABLES;执行结果如下图所示: 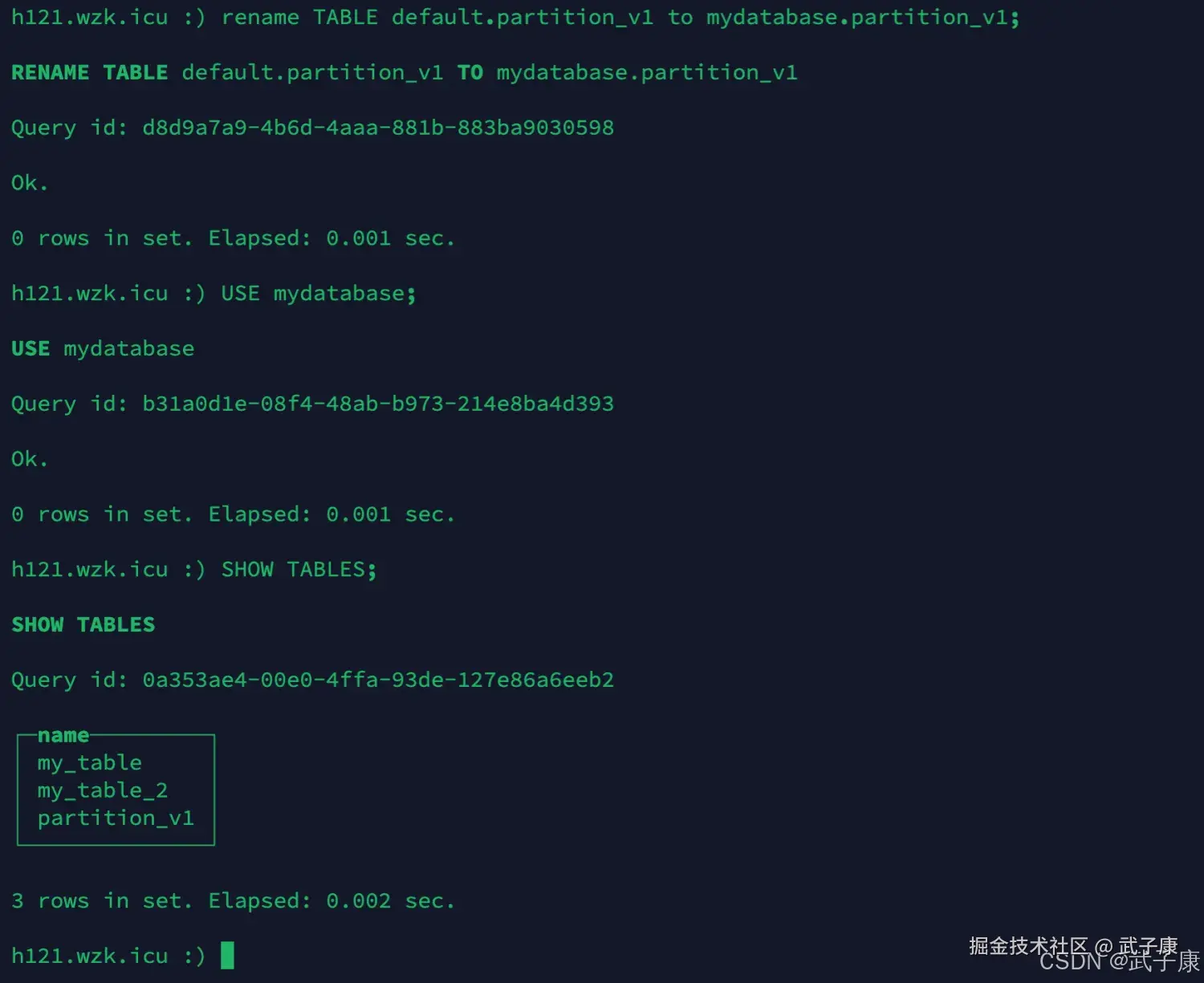
分区操作
查看分区
sql
SELECT partition_id, name, table, database FROM system.parts where table = 'partition_v1';执行结果如下所示: 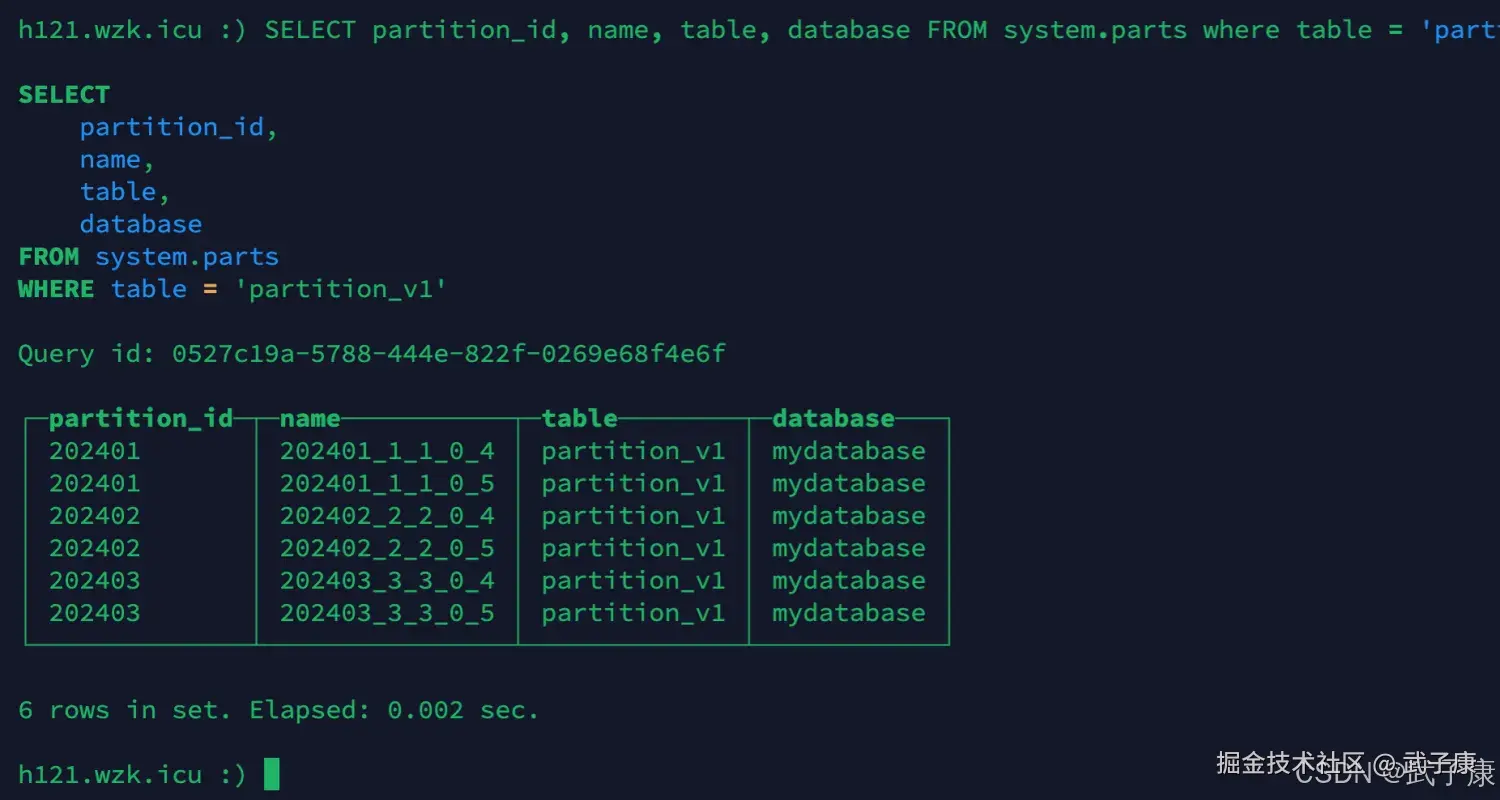
删除分区
sql
ALTER TABLE partition_v1 DROP PARTITION 202401;
SELECT partition_id, name, table, database FROM system.parts where table = 'partition_v1';执行结果如下图所示: 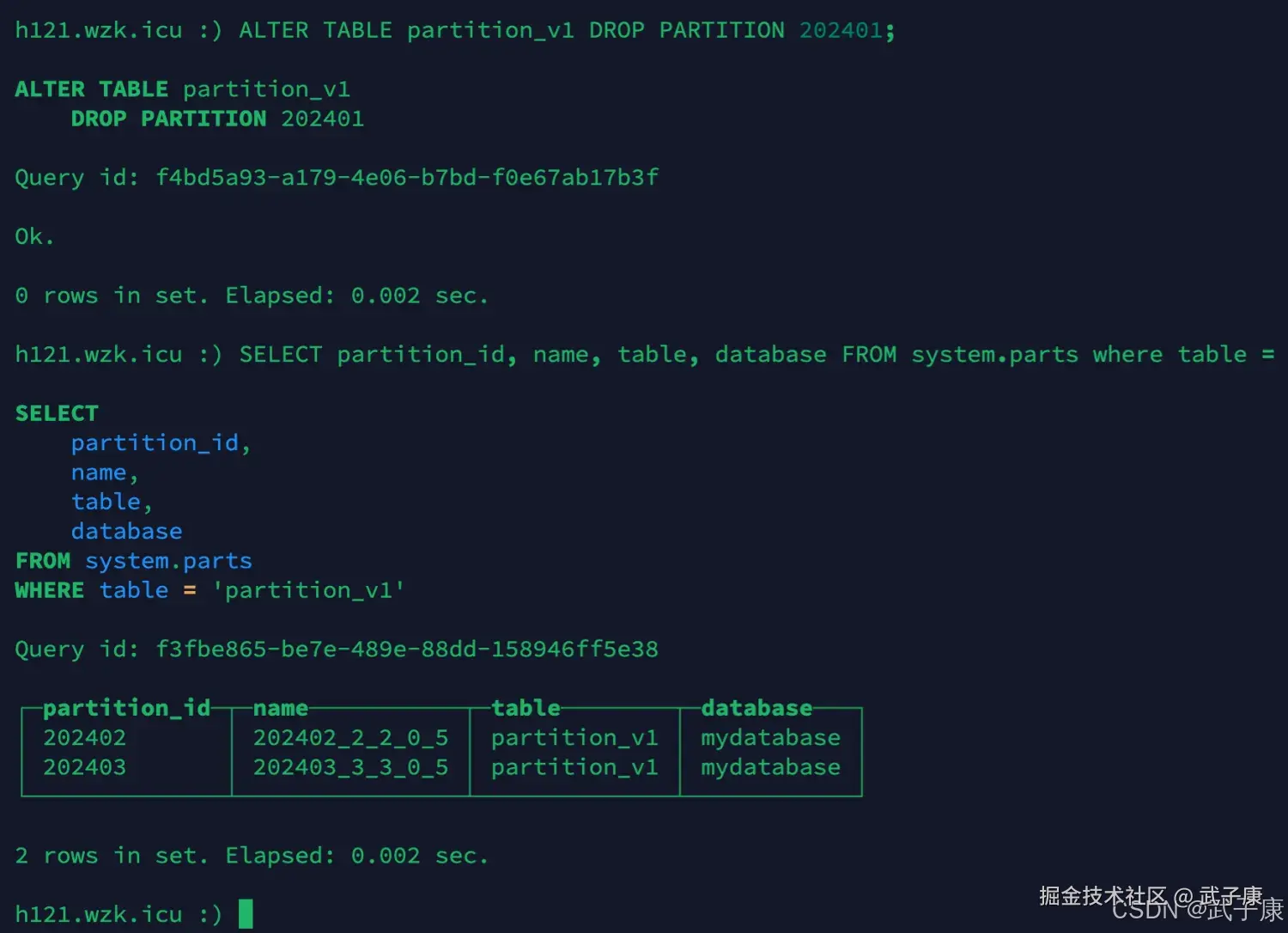
复制分区
sql
ALTER TABLE partition_v2 replace partition 202402 FROM partition_v1;重置分区
sql
ALTER TABLE partition_v1 CLEAR COLUMN ip in partition 202402;- 将 ip 列的值清空(设置为默认值)。
- 清空操作不会删除记录,而是将指定列的值设置为默认值(如 0 或 NULL,具体取决于列的默认设置)。
执行结果如下图所示: 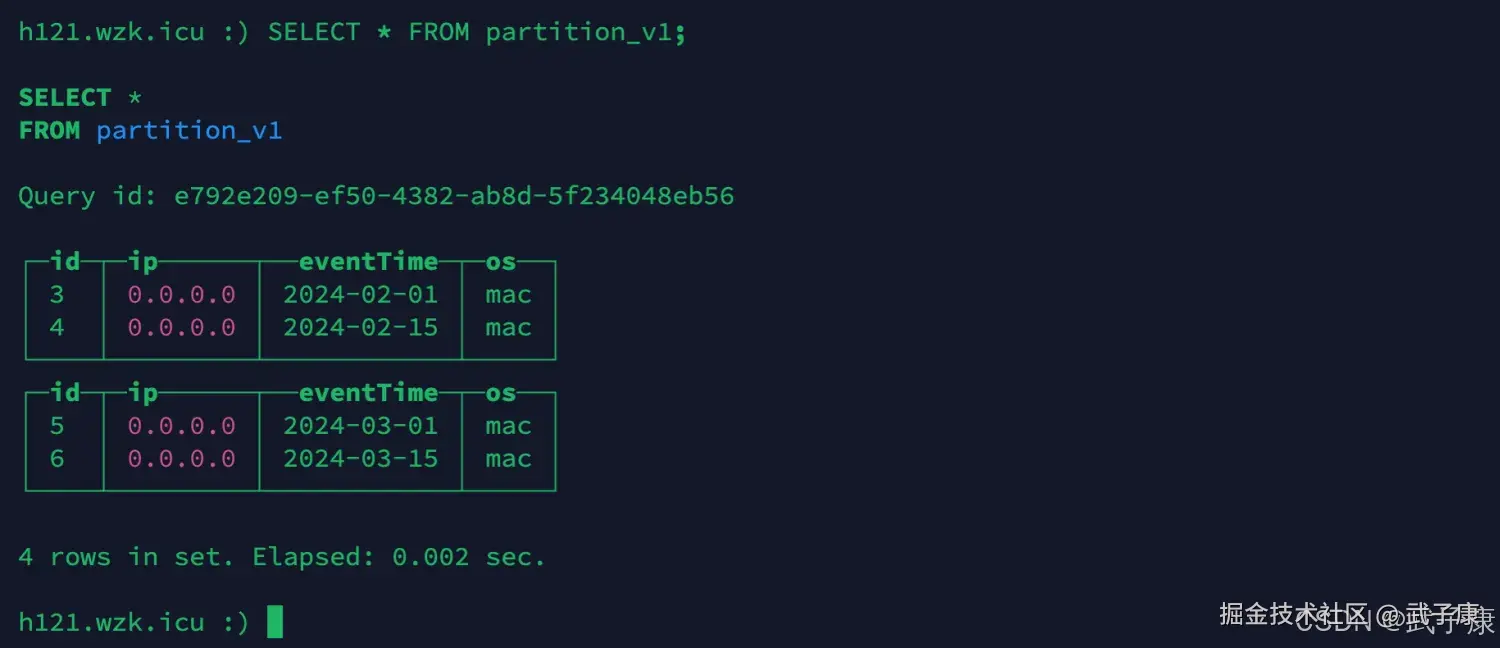
卸载分区
sql
ALTER TABLE partition_v1 DETACH partition 202402;
SELECT partition_id, name, table, database FROM system.parts where table = 'partition_v1';执行结果如下图所示: 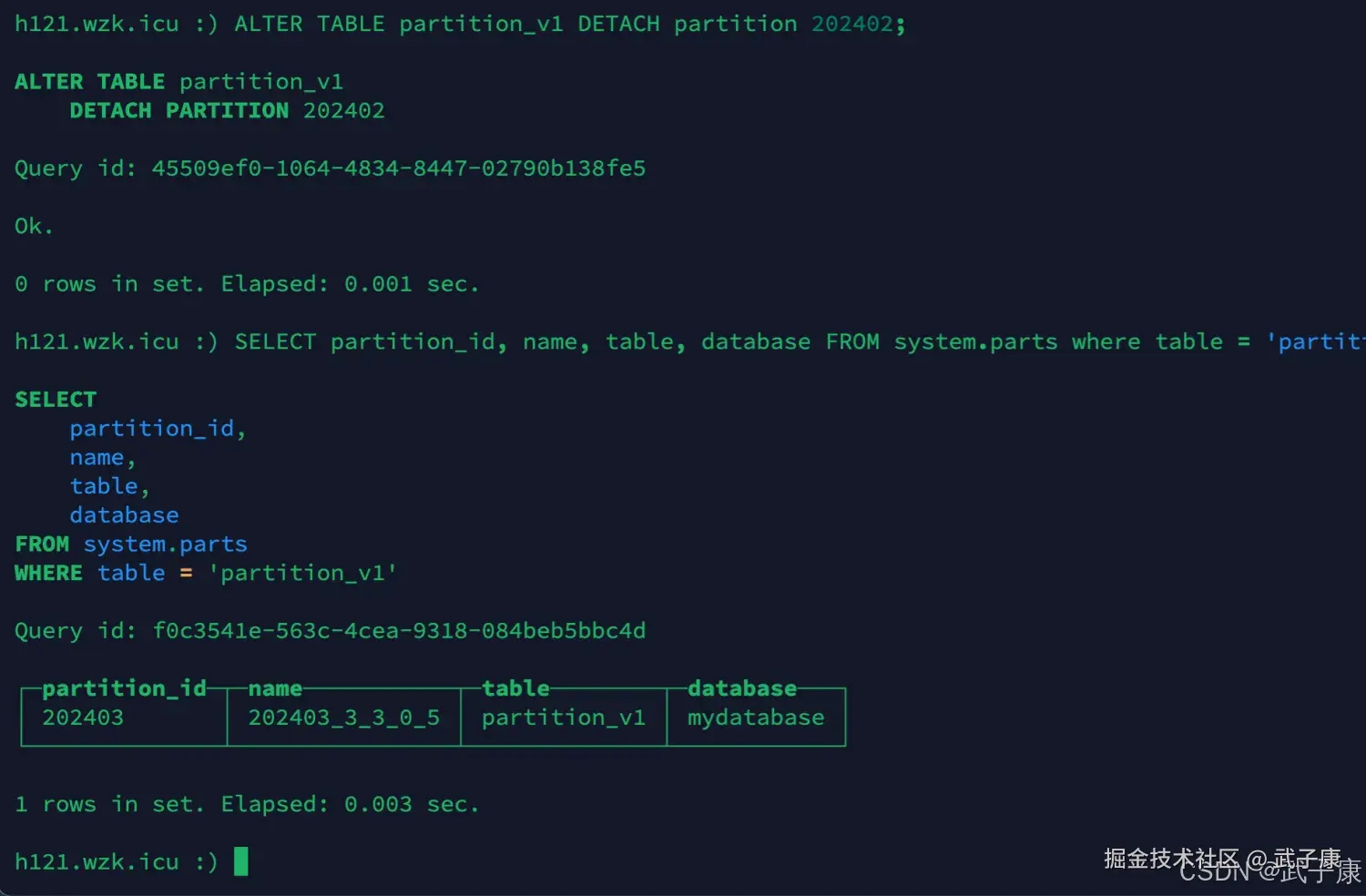
转载分区
sql
ALTER TABLE partition_v1 ATTACH partition 202402;
SELECT partition_id, name, table, database FROM system.parts where table = 'partition_v1';执行结果如下图所示: 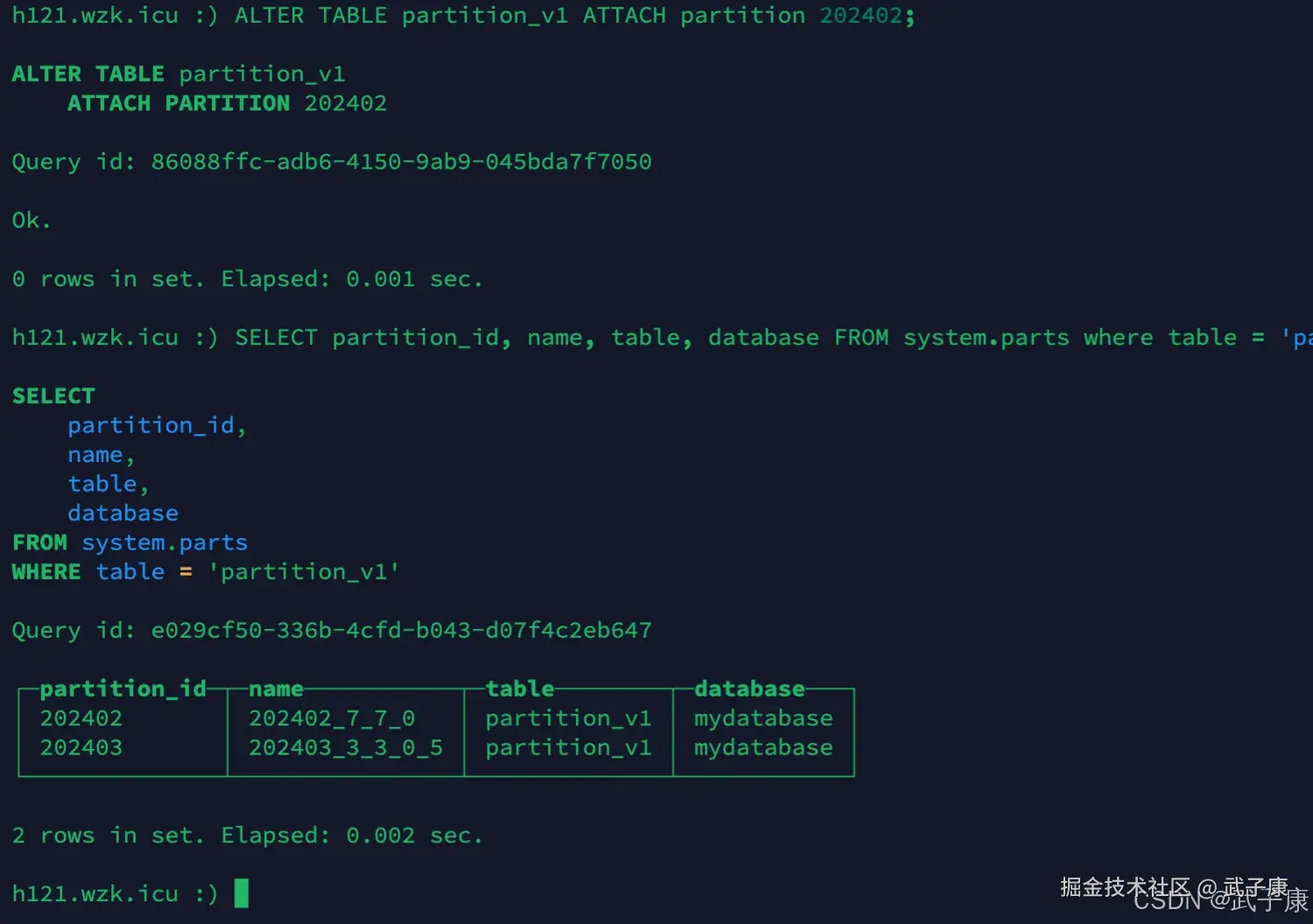
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI-调查研究-108-具身智能 机器人模型训练全流程详解:从预训练到强化学习与人类反馈 🔗 AI模块直达链接
💻 Java篇持续更新中(长期更新)
Java-154 深入浅出 MongoDB 用Java访问 MongoDB 数据库 从环境搭建到CRUD完整示例 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础! 🔗 Java模块直达链接
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解 🔗 大数据模块直达链接