- 此外,我们利用小样本学习方法,通过上下文学习来增强LLM对指令的理解。???
标题
MAC-SQL: A Multi-Agent Collaborative Framework for Text-to-SQL
MAC-SQL:面向 Text-to-SQL 的多智能体协同框架
作者团队
1Bing Wang, Changyu Ren, Jian Yang, Xinnian Liang, Jiaqi Bai, Linzheng Chai
1Beihang University(北京航空航天大学)
2Zhao Yan, Qian-Wen Zhang, Di Yin, Xing Sun
2Tencent Youtu Lab(腾讯优图实验室)
†通讯作者:Zhoujun Li(北航)
发表会议
The 31st International Conference on Computational Linguistics(第 31 届国际计算语言学大会,COLING 2025)ACL
发表时间
会议日期:2025 年 1 月 19--24 日
论文集出版:2025 年 1 月(COLING 2025 Proceedings)
摘要
当前的 LLM-based Text-to-SQL 方法在面对=="海量"数据库以及需要多步推理的复杂用户提问时,性能会显著下降;此外,现有方法普遍忽视了大模型调用外部工具以及多模型协同的重要性==。为此,我们提出 MAC-SQL,一种全新的基于大模型的多智能体协同框架。该框架包含一个用于 Text-to-SQL 生成的核心"分解器(Decomposer)"智能体,用于文本到 SQL 的生成,具有少量的思想链推理,辅以两个辅助智能体:"选择器(Selector)"利用外部工具或模型抽取最小相关子数据库,"精炼器(Refiner)"对错误 SQL 进行修正。分解器与按需激活的辅助智能体协同工作,且框架可灵活扩展以集成新功能或工具(可插拔扩展),从而实现更高效的 Text-to-SQL 解析。实验首先以 GPT-4 作为统一骨干,为所有智能体任务设定性能上界;随后基于 Code Llama 7B 微调得到开源指令模型 SQL-Llama,使其能够像 GPT-4 一样完成全部任务。结果显示,SQL-Llama 在 BIRD 测试集上执行准确率达 43.94,与原始 GPT-4 的 46.35 相当。截至撰稿时,MAC-SQL+GPT-4 在 BIRD 隐藏测试集取得 59.59% 的执行准确率,刷新该榜单最佳成绩(SOTA)。
1 引言
Text-to-SQL 旨在将自然语言文本自动转换为面向数据库的结构化查询语言(SQL)。这一长期存在的研究课题对于提升数据库的可访问性至关重要,使用户无需掌握 SQL 知识即可检索数据(Qin 等,2022;Sun 等,2023)。
过去十年间,该领域的研究大致经历了三个阶段。初期工作借助预训练模型对输入序列进行编码,再通过抽象语法树(Xu 等,2017;Guo 等,2019;Wang 等,2021)或预设的查询草图(He 等,2019)解码生成 SQL。随后,更多系统转向序列到序列的建模方式(Raffel 等,2023;Xie 等,2022;Scholak 等,2021)。最新研究(Ouyang 等,2022;OpenAI,2023;Rozière 等,2023)则展现了大语言模型(LLM)在该任务上的卓越表现,其成功源于 LLM 涌现出的新能力(Wei 等,2023;Brown 等,2020)以及固有的强健推理能力。
近期,基于大语言模型的 Text-to-SQL 研究(Dong 等,2023;Pourreza 和 Rafiei,2023;Gao 等,2023)主要集中在上下文学习(In-Context Learning)提示策略以及利用目标领域数据进行的监督微调。然而,如图 1 所示,这些方法在面对=="海量"数据库以及需要多步推理的复杂用户提问时==,性能通常会显著下降。此外,现有方法普遍忽视了大语言模型调用外部工具以及实现模型间协同的重要性。
为缓解上述挑战,我们提出 MAC-SQL------一种全新的基于大语言模型的多智能体协同框架。该框架将 LLM 赋予不同角色,使其成为具备专门功能的智能体,以实现高效的 Text-to-SQL 解析。核心是一个"分解器(Decomposer)"智能体,负责生成 SQL;另外两个辅助智能体分别为"选择器(Selector)"和"精炼器(Refiner)",分别承担工具调用与 SQL 修正职责。具体而言,分解器利用思维链推理将复杂问题拆分为更简单的子问题,并逐步求解;当必要时,选择器会把大型数据库缩减为更小的子数据库,以降低无关信息带来的干扰;精炼器则借助外部工具执行 SQL,获取反馈并自动修正错误的查询语句。
此外,我们利用 MAC-SQL 产生的智能体指令数据,基于 Code Llama 7B 微调出指令跟随模型 SQL-Llama,使其具备数据库简化、问题分解、SQL 生成与 SQL 修正等能力。
在实验中,我们首先以 GPT-4 == 作为统一的强骨干大模型==,驱动所有智能体任务,以探明 MAC-SQL 框架在广泛使用的 BIRD 与 Spider 数据集上的性能上界。实验结果显示,MAC-SQL+GPT-4 在 BIRD 隐藏测试集上取得 59.59% 的执行准确率,创下截至撰稿时的最新最佳成绩(SOTA)。进一步,我们用参数量仅为 7B 的 SQL-Llama 替代 GPT-4 完成全部任务。令人惊喜的是,尽管 SQL-Llama 的参数量比 GPT-4 低一个数量级,其执行准确率仍达到 == 43.94%,与 GPT-4 的 46.35% 极为接近==。
贡献 本文的主要贡献与结果总结如下:
- 提出 MAC-SQL------一种全新的 Text-to-SQL 多智能体协同框架,通过集成外部工具并促进模型间协作,有效应对复杂场景。
- 发布指令微调模型 SQL-Llama,填补开源社区在"具备智能体指令跟随能力"的 Text-to-SQL 模型空白。
- 实验表明,MAC-SQL 在 BIRD 测试集上取得 59.59% 的执行准确率,创下截至撰稿时的最新最佳成绩(SOTA)。
好的,这是论文从 2. 预备知识 开始到 3. MAC-SQL 框架 之前的中文翻译。
2 预备知识
2.1 Text-to-SQL 的问题定义
给定一个三元组
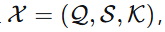
其中 (\mathcal{Q})、(\mathcal{S}) 和 (\mathcal{K}) 分别是自然语言问题、数据库模式和外部知识(可选)。数据库模式 (\mathcal{S}) 被定义为 ({\mathcal{T},\mathcal{C}}),其中 (\mathcal{T}) 代表多个表 ({\mathcal{T}{1},\mathcal{T} {2},\ldots,\mathcal{T}{|\mathcal{T}|}}),而 (\mathcal{C}) 代表列 ({\mathcal{C} {1},\mathcal{C}{2},\ldots,\mathcal{C}{|\mathcal{C}|}})。Text-to-SQL 任务的目的是生成与问题 (\mathcal{Q}) 对应的正确 SQL 语句 (\mathcal{Y})。
2.2 用于 Text-to-SQL 的大型语言模型
最近的 Text-to-SQL 任务被表述为一种生成任务(Dong et al., 2023; Pourreza and Rafiei, 2023),即设计合适的提示来大型语言模型 (\mathcal{M}) 逐词生成 SQL 查询。该生成过程可以表述如下:
P_{\\mathcal{M}}(\\mathcal{Y}\|\\mathcal{X})=\\prod_{i=1}\^{\|\\mathcal{Y}\|}P_{\\mathcal {M}}(\\mathcal{Y}*{i}\|\\mathcal{Y}*{\
其中 (\mathcal{Y}{<i}) 是 SQL 查询 (\mathcal{Y}) 的前缀,(P {\mathcal{M}}(\mathcal{Y}{i}|\cdot)) 是在给定前缀 (\mathcal{Y}{<i}) 和三元组 (\mathcal{X}=(\mathcal{Q},\mathcal{S},\mathcal{K})) 的条件下,SQL 查询 (\mathcal{Y}) 中第 (i) 个词的条件概率。
3. MAC-SQL 框架
3.1 概述
在图2中,我们介绍了 MAC-SQL ,这是一个新颖的、基于LLM的多智能体协作框架。该框架利用大型语言模型作为具有不同功能的智能体,以实现高效的 Text-to-SQL 解析。MAC-SQL 包含一个用于生成 Text-to-SQL 的核心 分解器 智能体,并辅以两个辅助智能体------选择器 和 修正器 ,分别用于工具使用和 SQL 优化。在算法1中,我们展示了 MAC-SQL 中三个智能体的协作流程。在接下来的章节中,将详细介绍这三个智能体。
好的,这是论文从 3.2 Selector 开始到 3.3 Decomposer 之前部分的中文翻译:
3.2 选择器
给定一个输入三元组 (\mathcal{X}=(\mathcal{Q},\mathcal{S},\mathcal{K})),其中数据库的模式为 (\mathcal{S}={\mathcal{T},\mathcal{C}}),选择器 智能体的目标是定位能够回答问题 (\mathcal{Q}) 并利用知识 (\mathcal{K}) 的最简模式 (\mathcal{S}{\prime}={\mathcal{T}{\prime},\mathcal{C}^{\prime}}),其中 (T^{\prime}\subseteq T) 且 (C^{\prime}\subseteq C)。选择器智能体的功能可以描述为:
\\mathcal{S}\^{\\prime}=f_{selector}(\\mathcal{Q},\\mathcal{S},\\mathcal{K}\|\\mathcal {M})
其中 (f_{selector}(\cdot|\mathcal{M})) 表示通过提示大型语言模型 (\mathcal{M}) 来实现选择器的功能。
设计选择器背后的动机主要涉及两个关键因素。首先,在提示中引入过多不相关的模式项会增加LLM在输出SQL时生成不相关模式项的可能性。其次,使用完整的数据库模式会导致文本长度过长,从而产生不必要的API成本,并且可能超过LLM的最大上下文长度。
需要指出的是,选择器只有在数据库模式提示的长度超过长度阈值时才会被激活;否则,后续流程将使用原始数据库模式 (\mathcal{S})。关于智能体变量和提示的更多细节可以在附录A中找到。
database schema prompt 指的是用于告知模型数据库结构的提示文本,包含数据库中的表名、列名、列描述、字段示例值、外键关系等关键信息,是模型生成 SQL 时理解数据结构的核心输入。
简单说,它是模型 "读懂" 数据库的说明书,会被嵌入到给 LLM 的提示中,帮助模型关联自然语言问题与数据库结构。
以论文附录中提到的 banking_system 数据库为例,其 database schema prompt 如下(简化版)
这个文本就是完整的 database schema prompt,包含了数据库 ID、表结构(表名、列名、描述、示例值)和外键关系,会作为提示的一部分传给 LLM。
三、阈值判断逻辑
论文中明确了激活 Selector 的判断标准:
以模型的最大序列长度为基准,当 database schema prompt 的 Token 数超过 0.8 * 模型最大序列长度 时,判定为 "大型数据库"。
示例:使用 GPT-4-32k(最大序列长度 32k Token)时,阈值为 25k Token,若上述 banking_system 的 schema prompt Token 数超过 25k,Selector 会被激活,筛选出相关表和列(保留每个表前 6 个相关列),生成简化后的 schema prompt;若未超过阈值,则直接使用原始 schema prompt 进行后续 SQL 生成。
3.3 分解器
分解器的目的是通过生成一系列中间步骤(即子问题和对应的SQL语句)来增强LLM的推理能力,然后再预测最终的SQL。如图3所示,分解器指导LLM将原始的复杂问题 (\mathcal{Q}) 分解为推理步骤,并在单次过程中获得最终的SQL查询 (\mathcal{Y})。这可以描述如下:
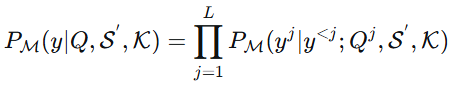
其中 (Q^{j}) 和 (y^{j}) 是由LLM (\mathcal{M}) 在给定先前的子SQL (y^{<j})、过滤后的数据库模式 (\mathcal{S}^{'}) 和知识 (\mathcal{K}) 的条件下生成的第 (j) 个子问题和子SQL,(L) 是子问题的数量。
分解器模式可以通过两种提示方法来实现Text-to-SQL解析:思维链提示 和从简到繁提示 。前者涉及一次性生成思考和推理以获得答案,而后者由于是迭代过程,生成每个SQL查询会带来更高的计算成本。
考虑到迭代方法的低效性以及确定停止标准的必要性,我们采用思维链方法 来生成子问题及其相应的SQL查询。具体实现如下:动态判断用户问题的难度------如果可以通过简单的SQL查询回答,则直接生成SQL;如果问题更复杂,则从最简单的子问题开始生成相应的SQL,然后逐步分解以获得渐进的子问题,直到得到与问题相对应的最终SQL。此外,我们利用小样本学习方法,通过上下文学习来增强LLM对指令的理解。