
机器人、人工智能相关领域 news/events (专栏目录)
本文目录
- [一、DriveOS 软件架构](#一、DriveOS 软件架构)
- [二、DriveOS 优势特点](#二、DriveOS 优势特点)
-
- [2.1 可编程性](#2.1 可编程性)
- [2.2 安全性和可靠性](#2.2 安全性和可靠性)
- [2.3 高度优化](#2.3 高度优化)
- [2.4 加速应用程序开发](#2.4 加速应用程序开发)
- [2.5 虚拟化和容器化](#2.5 虚拟化和容器化)
- [三、安全关键系统 Vulkan SC](#三、安全关键系统 Vulkan SC)
- [四、边缘计算专用加速引擎 NVIDIA PVA](#四、边缘计算专用加速引擎 NVIDIA PVA)
-
- [4.1 PVA结构及工作原理](#4.1 PVA结构及工作原理)
- [4.2 PVA SDK 包含的算子](#4.2 PVA SDK 包含的算子)
-
- [4.2.1 图像处理相关算子](#4.2.1 图像处理相关算子)
- [4.2.2 线性代数相关算子](#4.2.2 线性代数相关算子)
- [4.2.3 深度学习相关算子](#4.2.3 深度学习相关算子)
- [4.2.4 雷达相关算子](#4.2.4 雷达相关算子)
- [五、构建高效数据处理 NvStreams](#五、构建高效数据处理 NvStreams)
-
- [5.1 核心功能与模块](#5.1 核心功能与模块)
-
- [5.1.1 缓冲区分配 (NvSciBuf)](#5.1.1 缓冲区分配 (NvSciBuf))
- [5.1.2 同步机制 (NvSciSync)](#5.1.2 同步机制 (NvSciSync))
- [5.1.3 流管道 (NvSciStream)](#5.1.3 流管道 (NvSciStream))
- [5.2 构建 NvStreams 流程](#5.2 构建 NvStreams 流程)
-
- [5.2.1 模块化](#5.2.1 模块化)
- [5.2.2 构建步骤](#5.2.2 构建步骤)
- 六、辅助驾驶平台数据脱敏
-
- [6.1 常用处理方法](#6.1 常用处理方法)
- [6.2 不同硬件引擎的脱敏方案](#6.2 不同硬件引擎的脱敏方案)
-
- [6.2.1 基于CUDA](#6.2.1 基于CUDA)
- [6.2.2 基于VIC(Video Image Compositor)/ NvMedia2D](#6.2.2 基于VIC(Video Image Compositor)/ NvMedia2D)
- [6.2.3 基于NVEAC](#6.2.3 基于NVEAC)
- [6.2.4 基于PVA](#6.2.4 基于PVA)
- [6.3 方案选择](#6.3 方案选择)
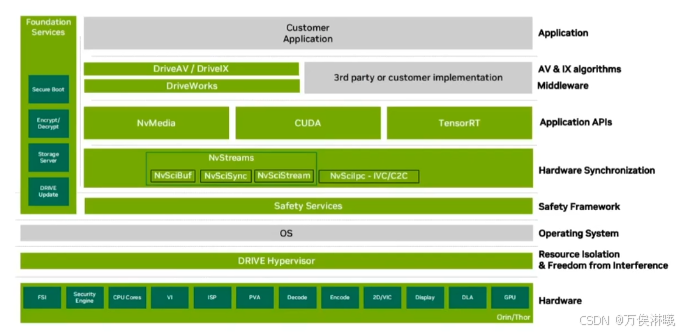
NVIDIA DRIVE OS 是专为在基于 DRIVE AGX 的硬件上开发和部署自主应用程序而设计的参考操作系统及相关软件栈。NVIDIA DRIVE OS 为安全关键型应用程序提供安全可靠的执行环境,并提供安全启动、安全服务、防火墙和空中升级等功能。
在瞬息万变的自动驾驶汽车领域,尖端技术是打造更安全、更高效、更智能的交通系统的驱动力。NVIDIA 正是这场变革的先锋,这家全球领先的技术公司以其在人工智能 (AI) 和深度学习领域的创新而闻名。NVIDIA 对自动驾驶汽车生态系统最具影响力的贡献之一是 NVIDIA Drive OS,这是一款旨在变革自动驾驶汽车运行方式的综合操作系统。在本篇博文中,我们将深入探讨 NVIDIA Drive OS,探索其关键特性、对自动驾驶汽车行业的深远影响以及重塑未来交通的潜力。
NVIDIA Drive OS 是构建自动驾驶系统的基石。这款先进的操作系统为开发者提供了一个强大而安全的平台,充分发挥 NVIDIA 尖端硬件和软件的全部潜力。其核心采用高性能 NVIDIA Orin SoC,该 SoC 配备 CUDA Tensor Core GPU 和 12 个 A78(Hercules)ARM64 CPU,专为满足自动驾驶应用的独特需求而设计。
一、DriveOS 软件架构
其包含的基础软件栈包括 Type-1 Hypervisor、NVIDIA CUDA® 库、NVIDIA TensorRT™、NvMedia 以及其他经过优化的组件,可直接访问 DRIVE AGX 硬件加速引擎。
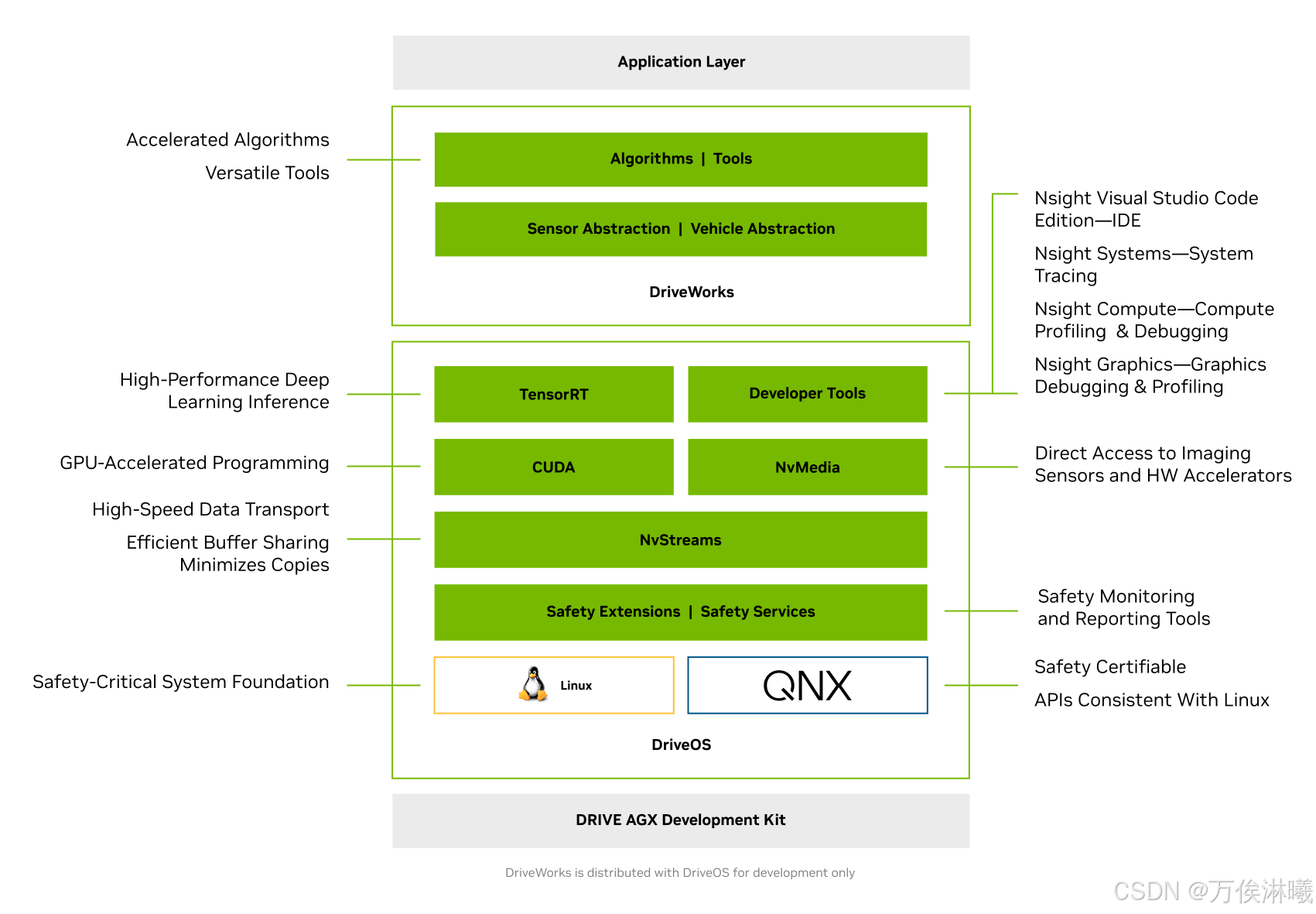
DriveOS 不只是一个操作系统内核,而是一个面向自动驾驶的 软件平台,提供端到端支持:从底层硬件驱动、加速库,到车载应用的运行环境。
二、DriveOS 优势特点
2.1 可编程性
实现从云或工作站到 SoC 的平稳过渡
- 支持广泛采用的编程模型 NVIDIA® CUDA® 和 TensorRT™,拥有庞大的开发者基础。
- 支持从云到目标的统一 API。
2.2 安全性和可靠性
专为安全关键型应用而设计
- 符合 ASPICE、ISO 26262 和 ISO/ SAE 21434。
- 支持计算工作负载的异构冗余。
2.3 高度优化
高效处理时间关键型工作负载
- 摄像头帧直接加载到 GPU 显存中,以便与 NvMedia 进行高性能传感器接口和处理。
- 支持 NvStreams 实现高效的数据传输,在硬件加速器之间实现零拷贝数据传输。
- 实现高度灵活的传感器处理流程。
2.4 加速应用程序开发
汽车软件的基础模组和工具
- DriveWorks 提供优化的算法和工具。
- NVIDIA Nsight 提供用于调试、分析和追踪的工具。
- 提供丰富的文档包括大量示例来演示特征,网络会议和 GTC 讲座来熟悉 DriveOS。
2.5 虚拟化和容器化
全面的可扩展性和隔离功能
- Hypervisor 可管理资源,并在底层硬件和操作系统之间提供抽象。
- 客户机操作系统提供额外的隔离和冗余。
- 主机端和目标端 Docker 容器支持实现高效开发。
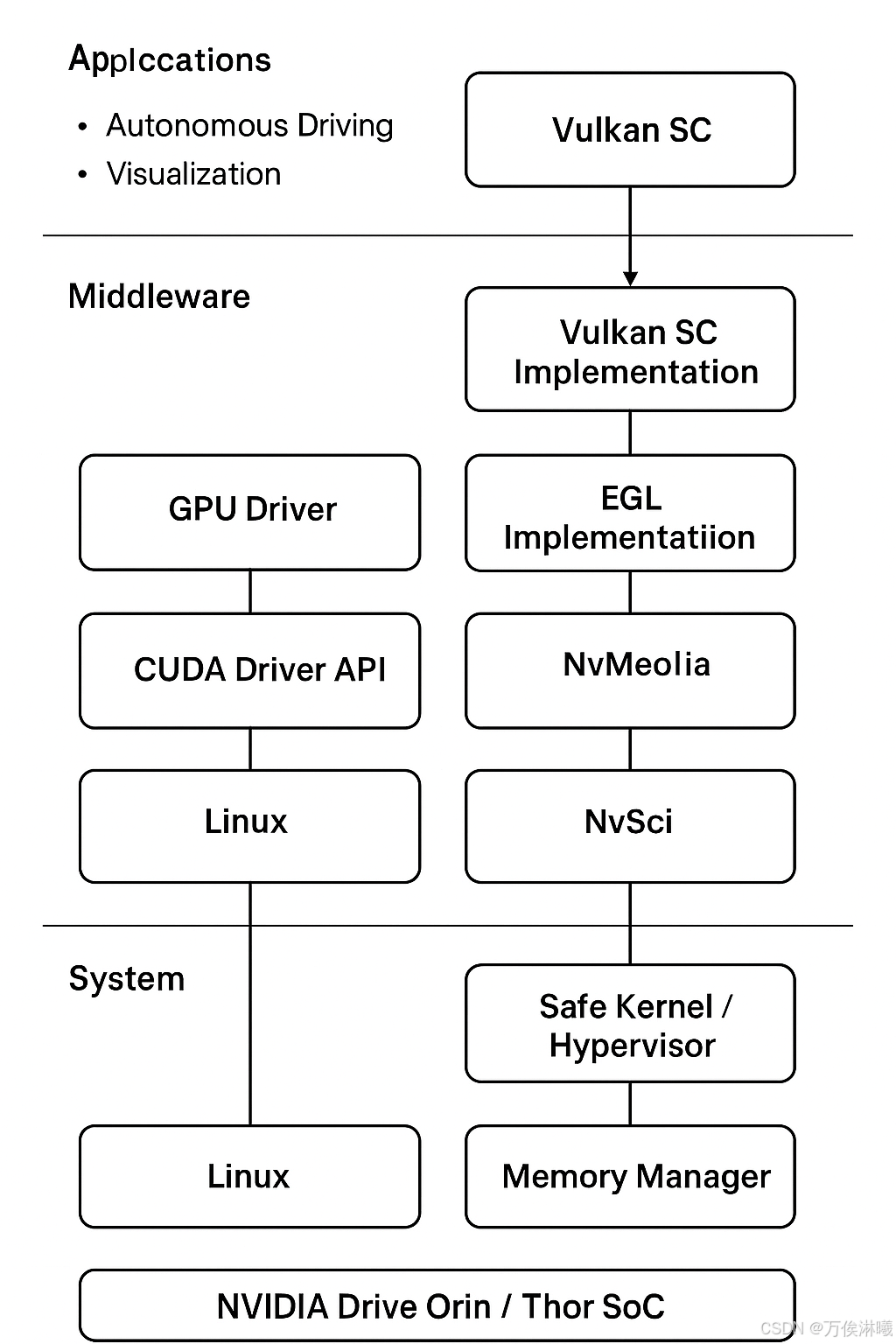
三、安全关键系统 Vulkan SC

Vulkan SC(Safety-Critical)是为 安全关键系统(如汽车、航空、工业控制)设计的 GPU 图形与计算 API。它基于 Vulkan 1.2,并专门精简、强化、以支持功能安全 (functional safety) 认证。
Vulkan SC 是 DriveOS 的安全关键图形 API 子系统。它运行在 DriveOS 的 GPU 驱动栈之上,为安全关键任务(如自动驾驶显示)提供可预测、可认证的 GPU 渲染与计算能力。
在 DriveOS 的安全设计中,GPU 参与安全关键任务,例如:自动驾驶的感知/环境建模可视化(Confidence View)、仪表盘显示、驾驶员监控系统(DMS)图像渲染、车载融合可视化等,这些场景都要求确定性执行、无动态资源分配、功能安全认证路径,而普通 Vulkan 或 OpenGL 无法满足这些要求,因此 NVIDIA 在 DriveOS 中采用Vulkan SC作为图形与计算的安全接口标准。DriveOS 中的 Vulkan SC 实现由 NVIDIA 官方维护,并通过了针对汽车级功能安全的验证。
简而言之,它的目标是在需要高可靠性、可预测行为的系统中使用 GPU 加速图形与计算;降低驱动/运行时的非确定性(如动态内存分配、运行时编译)所带来的风险;支持 ISO 26262(汽车)、IEC 61508(工业)、DO-178C(航空)等安全标准。
在传统的 GPU/图形 API(如 OpenGL、Vulkan)中,有大量运行时行为(动态内存分配、延迟不确定、驱动中有复杂状态机)可能导致在安全关键环境中难以验证和认证。Vulkan SC 针对这一点做了专门优化:
- 去除了或使可选许多运行时不可预测的功能。
- 强制或推荐使用离线编译管线 (offline pipeline compilation),在运行时不做或极少做动态工作。
- 提供故障报告 (fault reporting)、对象刷新 (object refresh) 等机制,以便检测并响应运行时的问题。
- 适合需要确定性执行(deterministic execution)和高可测性的系统。
四、边缘计算专用加速引擎 NVIDIA PVA
PVA 是 NVIDIA 在其车载及嵌入式 SoC(例如 NVIDIA Orin SoC / NVIDIA Drive AGX SoC 系列)中集成的一种 可编程视觉加速器(Programmable Vision Accelerator)。它专为图像处理、计算机视觉(CV)算法、传感器数据预处理等任务设计,具有低延迟、高效率、低功耗的特点。
简而言之,它的角色是在自动驾驶或嵌入式视觉系统中,辅助或替代 GPU/CPU 在视觉预处理/后处理环节的任务,从而释放这些资源执行更重的 AI 推理任务。
4.1 PVA结构及工作原理
PVA SDK 的结构及其工作原理:
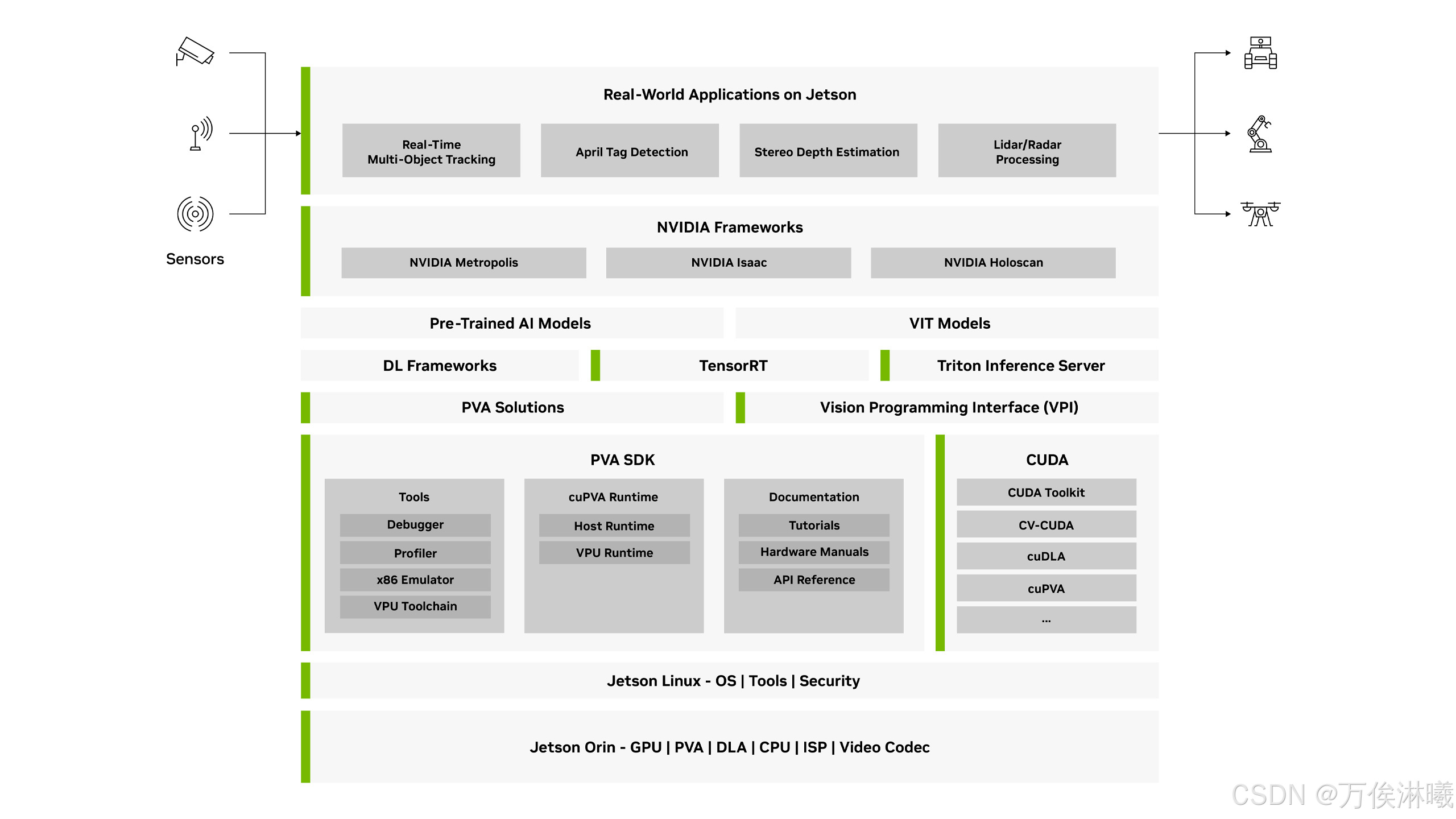
PVA组件架构图:
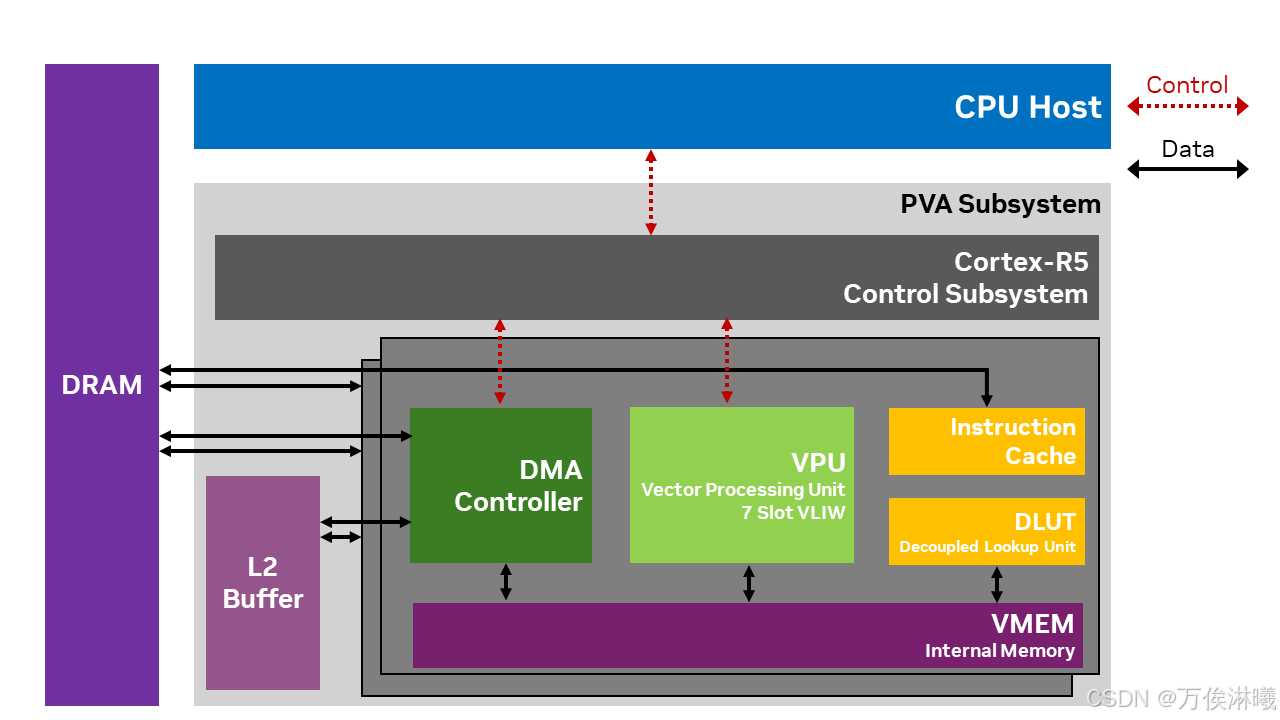
PVA处理器架构包含两个矢量处理子系统(VPS)和一个控制子系统(Cortex-R5)。每个VPS均可由用户独立编程。控制子系统负责调度两个VPS之间的工作,用户无法对其进行编程。
其中,向量处理单元(VPU)是PVA的主要处理引擎。VPU与VMEM、DLUT和指令缓存紧密结合,构成VPS(向量处理子系统)。VPU 向量存储器 (VMEM) 为 VPU 提供本地数据存储器,以便高效地实现各种图像处理和计算机视觉算法。VMEM 支持多种复杂的内存访问模式,包括不同长度的连续读/写、转置、查表、直方图和向量寻址存储。每个虚拟处理器 (VPS) 都包含一个解耦的查找表单元 (DLUT)。DLUT 可以与虚拟处理器 (VPU) 并行运行,从而分担虚拟内存 (VMEM) 的查找操作。DLUT 提供高吞吐量的查找操作,并利用硬件加速来最大限度地减少内存库冲突。VPU 可以通过采样器 API使用 DLUT 。
VPU 只能从其内部存储器 VMEM 加载或存储数据。VPU 需要直接内存访问 (DMA) 引擎在外部存储器、L2 存储器和 VMEM 之间移动数据。PVA 中的每个 VPS 块都有一个专用的 DMA 引擎,每个 DMA 引擎都有多个通道,可以并行地将数据从多个源位置移动到目标位置。内存读写操作可以与 VPU 进程并行执行,从而隐藏数据访问延迟。每个 VPU 和 DMA 对之间以 tile 粒度进行同步。Tile 通常是应用程序从外部存储器输入/输出数据集的子块,每个任务通常有几十到几百个 tile。Tile 的大小被设计为适合 VMEM,DMA 引擎用于将这些子块传输到 VMEM 以供 VPU 处理。
PVA采用两组VPS和DMA共享的L2内存。L2缓冲区容量大于VMEM,带宽高于外部DRAM。它可用于获取无法放入VMEM的数据块,或用作临时缓冲区。
每个 VPU 都具有一个基于 CoreSight/APB 的调试接口,该接口连接到系统级 JTAG 接口。可通过 JTAG 或 CPU 软件访问该接口。VPU 支持典型的符号调试功能,例如:读/写 VMEM、读/写处理器寄存器、单步、24 个硬件监视/断点、无限软件断点。要使用 VPU 调试硬件,请参阅片上调试。
制子系统 Cortex-R5 是 PVA 上运行的任务的主要协调器,也是其外部接口。它与主机 CPU、GPU、其他计算机视觉系统引擎(包括 ISP)以及硬件加速器(例如 NVENC)进行交互。
4.2 PVA SDK 包含的算子
NVIDIA PVA SDK 包含了一些常用的主流算子,旨在加速开发者开发进程,不用再重复造轮子。
4.2.1 图像处理相关算子


4.2.2 线性代数相关算子

4.2.3 深度学习相关算子

4.2.4 雷达相关算子

五、构建高效数据处理 NvStreams
NvStreams 是 NVIDIA 为其车规级平台(如 NVIDIA DriveOS Linux SDK)提供的一组库和接口,专门用于在不同软件模块/库之间安全、高效地分配/交换数据缓冲区 (buffers) 和同步对象 (fences/同步机制),以及构建"数据流 (streaming)"管道。
NvStreams 在 DriveOS 中的架构地位:
5.1 核心功能与模块
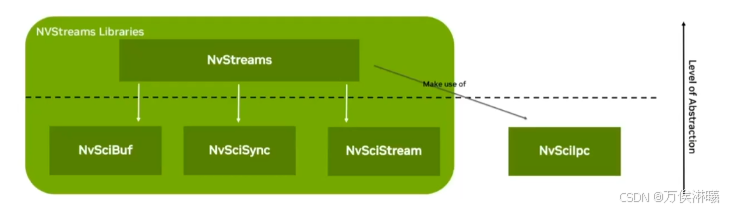
它主要由以下三个子库组成:
- NvSciBuf:用于缓冲区 (buffers) 的分配和管理。
- NvSciSync:用于同步对象 (fences, sync primitives) 的管理,以协调不同模块何时开始/结束操作。
- NvSciStream:建立在前两者之上,用于构造"数据包 (packets)"和"流水线 (streams)"模型,让生产者和消费者模块之间能够交换图像、张量、元数据等。
5.1.1 缓冲区分配 (NvSciBuf)
NvSciBuf 是一个缓冲区分配模块,它可以让应用程序分配一个可在 由不同引擎 API 管理的各种硬件引擎之间共享的缓冲区。
应用模块可查询所需缓冲区属性 (如维度、格式、内存域) 然后通过 NvSciBuf 创建。批量预分配能够避免运行时动态分配,从而提升安全系统的确定性。
5.1.2 同步机制 (NvSciSync)
NvSciSync 用于管理"何时一个缓冲区已被生产者写入可读"、"何时消费者完成读取可释放"等同步关系。支持事件、fence 等对象,与 GPU/CPU 等异构模块协作。
5.1.3 流管道 (NvSciStream)
构造生产者 (Producer) 和消费者 (Consumer) 模块之间的"流",一个 "包 (packet)" 可含多个"元素 (elements)"------如图像缓冲、张量、元数据。 支持多缓冲 (多 packet)、多消费者、FIFO 模式/Mailbox 模式(最新数据优先)等。支持跨进程 (IPC)、芯片-至-芯片 (chip-to-chip) 通信。
5.2 构建 NvStreams 流程
5.2.1 模块化
NvSciStream 本身采用模块化方法。它定义了一系列具有特定功能的构建块,应用程序可根据自身需求创建并连接这些模块。
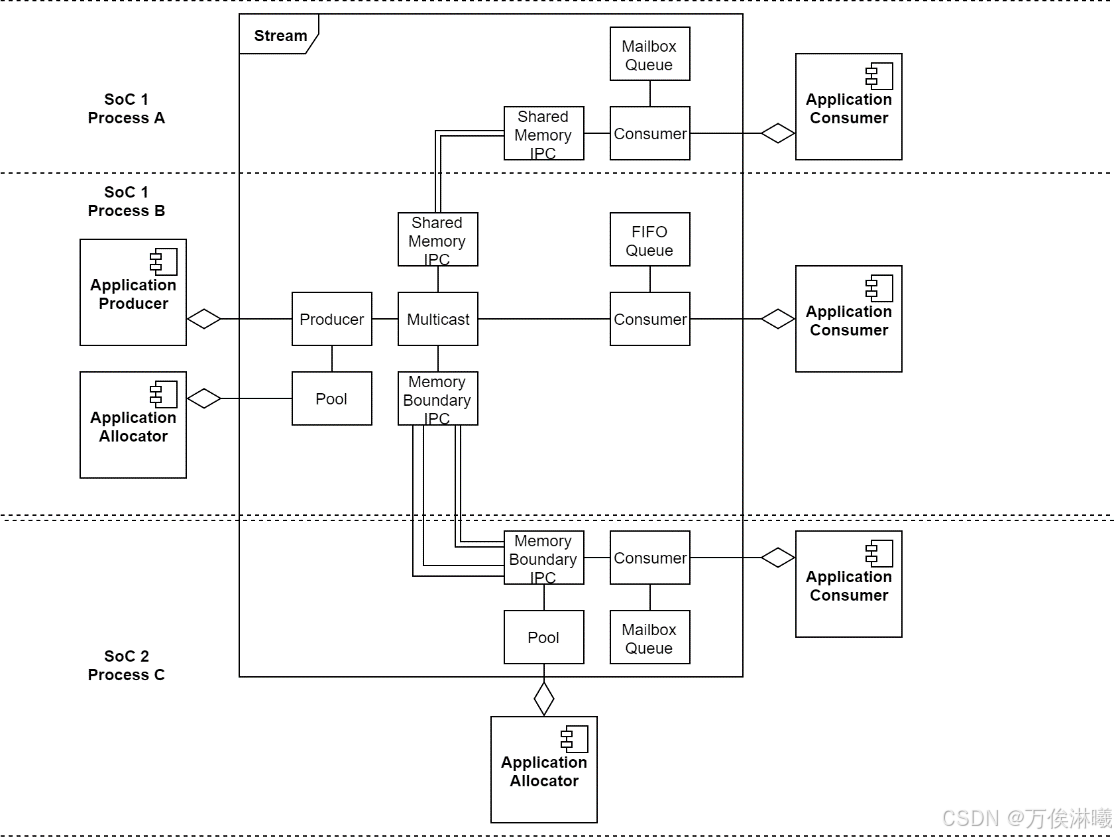
其中各模块说明如下:
- Producer:与生产者应用程序交互
- Pool:创建数据包并跟踪可供重用的数据包
- Multicast:将数据包分发给多个消费者
- Queue:连接到消费者模块的队列块负责跟踪等待消费者获取的有效载荷
- Consumer:与消费者应用程序交互
- IpcSrc/IpcDst:进程/虚拟机/片上系统间的通信与数据交换
- Limiter:限制允许向下游发送的数据包数量
- ReturnSync:通过多播流解决安全性和鲁棒性问题
- PresentSync:实现下游对数据包的同步访问
5.2.2 构建步骤
构建 NvStreams 包括三个阶段:

其中:
- Setup stage:创建并连接功能块;创建数据包和同步资源
- Streaming stage:通过同步机制进行数据交换
- Teardown stage:断开连接并销毁功能块
代码示例,一个简化版本的官方 NvSciStream 互操作 (interop) 示例代码片段(用于 PVA 或其他加速器场景)------主要用于说明如何使用 NvSciBuf、NvSciSync 与 NvSciStream 联动:
cpp
int main(int argc, char **argv)
{
NvSciSyncModule nvSciSyncModule = nullptr;
NvSciBufModule nvSciBufModule = nullptr;
NvSciSyncCpuWaitContext cpuWaitContext = nullptr;
NvSciBufObj image_nvsci = nullptr;
uint8_t *image_cpu = nullptr;
uint8_t *image_pva = nullptr;
NvSciBufObj stretchParams_nvsci = nullptr;
ContrastStretchParams *stretchParams_cpu = nullptr;
ContrastStretchParams *stretchParams_pva = nullptr;
NvSciSyncObj cpuStartSyncObj_nvsci = nullptr;
NvSciSyncObj cpuCompletionSyncObj_nvsci = nullptr;
NvSciSyncFence cpuStartFence_nvsci = NvSciSyncFenceInitializer;
NvSciSyncFence cpuCompletionFence_nvsci = NvSciSyncFenceInitializer;
// 打开模块
NVSCI_CALL(NvSciSyncModuleOpen(&nvSciSyncModule));
NVSCI_CALL(NvSciSyncCpuWaitContextAlloc(nvSciSyncModule, &cpuWaitContext));
NVSCI_CALL(NvSciBufModuleOpen(&nvSciBufModule));
// 创建缓冲区
CreateNvSciBuf(&image_nvsci, nvSciBufModule, IMAGE_SIZE * sizeof(uint8_t));
CreateNvSciBuf(&stretchParams_nvsci, nvSciBufModule, sizeof(ContrastStretchParams));
// ...(省略初始化、属性设置、导入到 PVA 或其他引擎)...
// 提交任务给 PVA, 等待同步
NVSCI_CALL(NvSciSyncObjWait(cpuWaitContext, cpuCompletionSyncObj_nvsci,
NVSCI_INFINITE_TIMEOUT));
// 清理
NVSCI_CALL(NvSciBufObjFree(image_nvsci));
NVSCI_CALL(NvSciBufObjFree(stretchParams_nvsci));
NVSCI_CALL(NvSciBufModuleClose(nvSciBufModule));
NVSCI_CALL(NvSciSyncCpuWaitContextFree(cpuWaitContext));
NVSCI_CALL(NvSciSyncModuleClose(nvSciSyncModule));
return 0;
}六、辅助驾驶平台数据脱敏
在开发、调试与模型训练流程中,保证摄像头、麦克风、日志、定位等数据在保存/传输/使用时不泄露可识别个人信息(PII),同时尽量保留对算法训练/验证有价值的信号(如交通标识、行人位置信息的相对特征)。
6.1 常用处理方法
- 模糊(高斯模糊/均值模糊/自定义滤波)
- 遮挡(叠加矩形框或马赛克)

6.2 不同硬件引擎的脱敏方案
6.2.1 基于CUDA

优势:灵活度高,可是实现遮挡、模糊、自定义滤波。
局限性:作为后处理的脱敏过程,该方案消耗GPU资源,需要评估整体的GPU资源使用。
6.2.2 基于VIC(Video Image Compositor)/ NvMedia2D
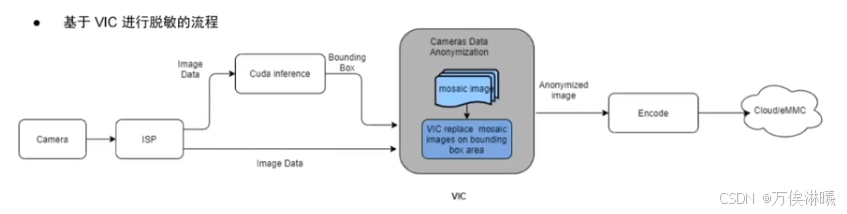
优势:开发友好,接口简单
局限性:ROI最小16*16像素
6.2.3 基于NVEAC
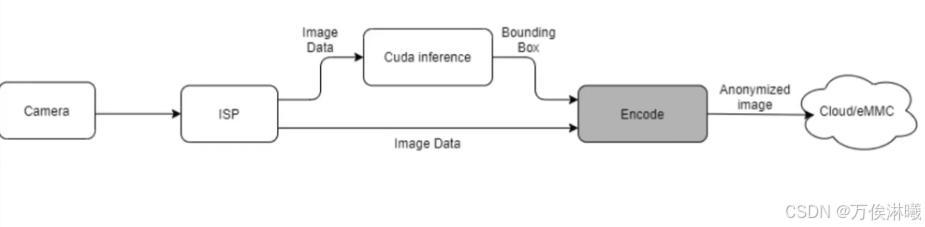
优势:直接在编码阶段对ROI进行模糊处理,无需消耗额外资源
局限性:编码格式目前只支持 H.264,16像素对齐,无法实现遮挡效果
6.2.4 基于PVA

优势:灵活度高,2个VPU并行执行,可实现模糊、马赛克、自定义滤波,支持和host之间的零buffer拷贝
局限性:需要SoC能够支持PVA,需要自行开发PVA算子实现模糊/填充
6.3 方案选择
