目录
其中

第一章:AI智算模型基础与网络配置
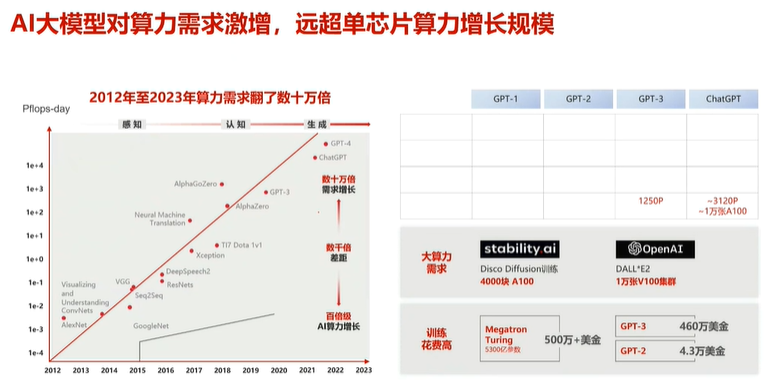
由于大模型算力需求变大,单个算力节点无法满足。
故需要网络架构进行匹配和加持。
1.集群计算(局域网)
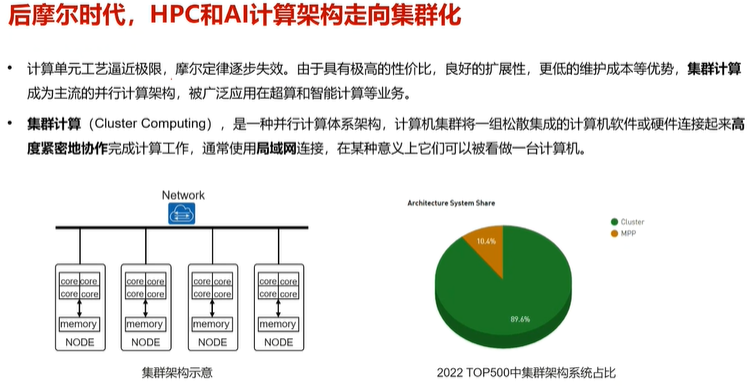
2.算力分类
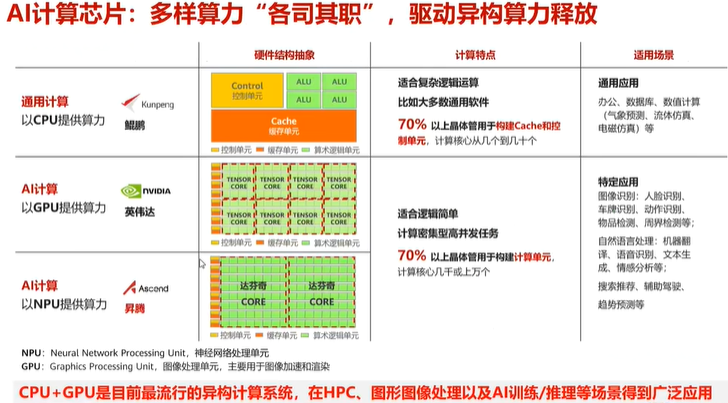
任务类型:
CPU:擅长逻辑控制和串行运算(如系统指令)。
GPU:优化并行图形渲染与通用计算。
NPU:专精矩阵运算,加速神经网络推理。
DPU:数据处理加速,加速网络通信、存储、加密解密等基础功能。
3.单台AI服务器架构
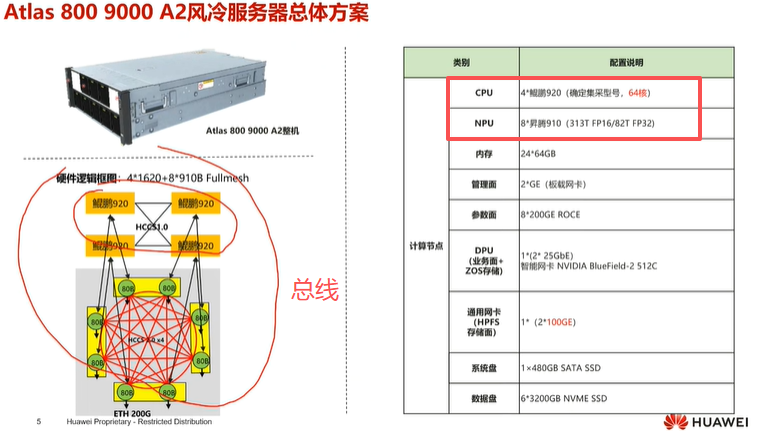
名词解释
高速通信总线(hccs) :
单台AI服务器架构内的4个CPU、8个NPU,使用内部的高速通信总线 连接

样本面网络,又称为存储面网络
注:
DPU(数据处理器):
在AI训练集群中,DPU负责数据处理加速。DPU主要用于加速网络通信、存储、加密解密等基础功能,释放CPU算力用于业务计算。
NPU(神经网络处理器):
是专为人工智能计算设计的芯片,专精矩阵运算,加速神经网络推理。
4.工作流程
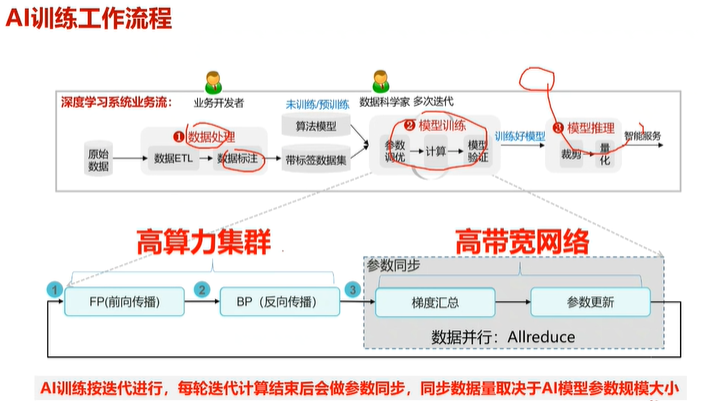
每次AI(迭代计算)训练结束后,进行一次参数同步。
此时需要高带宽网络进行通信,其中通信的数据量取决于模型参数规模大小。
模型参数规模越大,算力越高,效果越好。但对高带宽网络负载压力就越大。
且AI(迭代计算)训练通常是周期性反复进行,对网络带宽也有一定要求。
5.模型并行与数据并行(太杂不深入)
1.MP 是 Model Parallelism(模型并行) !! 不常用!!
将模型的不同部分(例如不同的层)分布到不同的GPU上
TP和PP是 MP的特殊形式
2.TP是 Tensor Parallelism (张量并行)
TP是MP的一种特殊形式
TP:将整个模型复制到不同的GPU上,每个GPU上都有相同的模型
3.PP是 Pipeline Parallelism(流水线并行)
它是对MP的改进
PP:跨服务器。
4.数据并行(DP)
数据并行的核心思想:
"同一个模型,在不同的数据上" 。
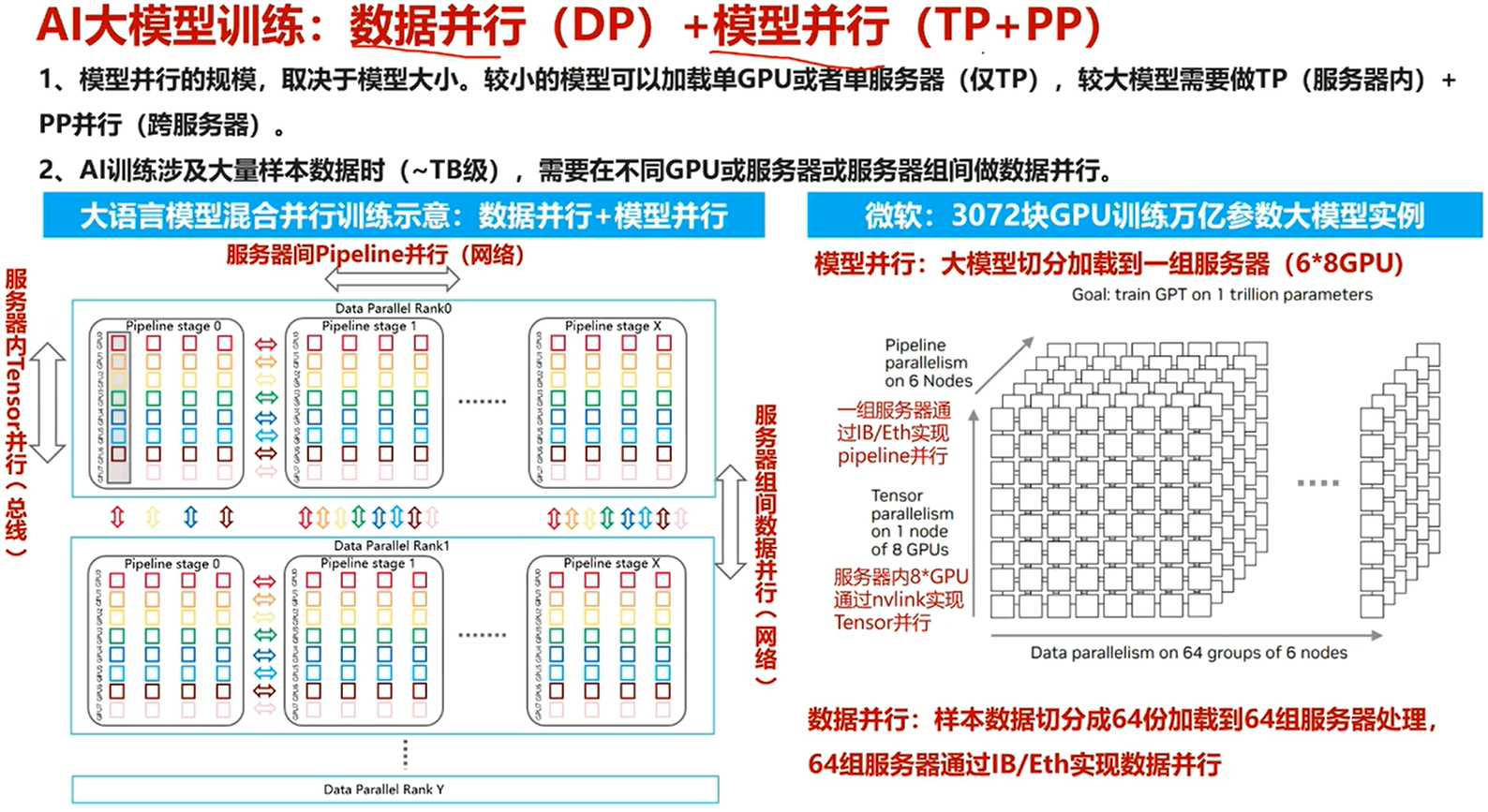
注:

一个竖着的长方形为,单个服务器中的数据
其中每个方块为数据拆分后的一小份样本数据,以不同颜色进行标识。(数据拆分为8小份)
其核心思想非常简单:
-
将完整的模型 复制到服务器的多个计算节点上(例如多个GPU)。
-
将训练数据集分割成多个小批次(Mini-batches) ,然后将这些小批次分发给各个设备。
-
每个计算节点都有完整的模型副本,它用分到的那一小批数据独立地进行迭代计算,计算出本地梯度。
-
将所有设备的梯度进行聚合(通常是求平均),然后用聚合后的梯度来同步更新 所有设备上的模型参数。
这样,每一个训练步骤(Step)都利用了多个设备的数据,大大加快了训练速度。
6.总线通信与同轨通信
1.当参数同步时,优先使用服务器内的高速总线通信。先进行第一次参数同步
2.当每一台服务器内的参数同步完成,服务器内的各个节点模型参数一致
3.进行同轨通信,同一个Rail下的节点再进行第二次参数同步
特点在于不需要进行全连接通信且架构稳定,保证通信的相对高效与稳定
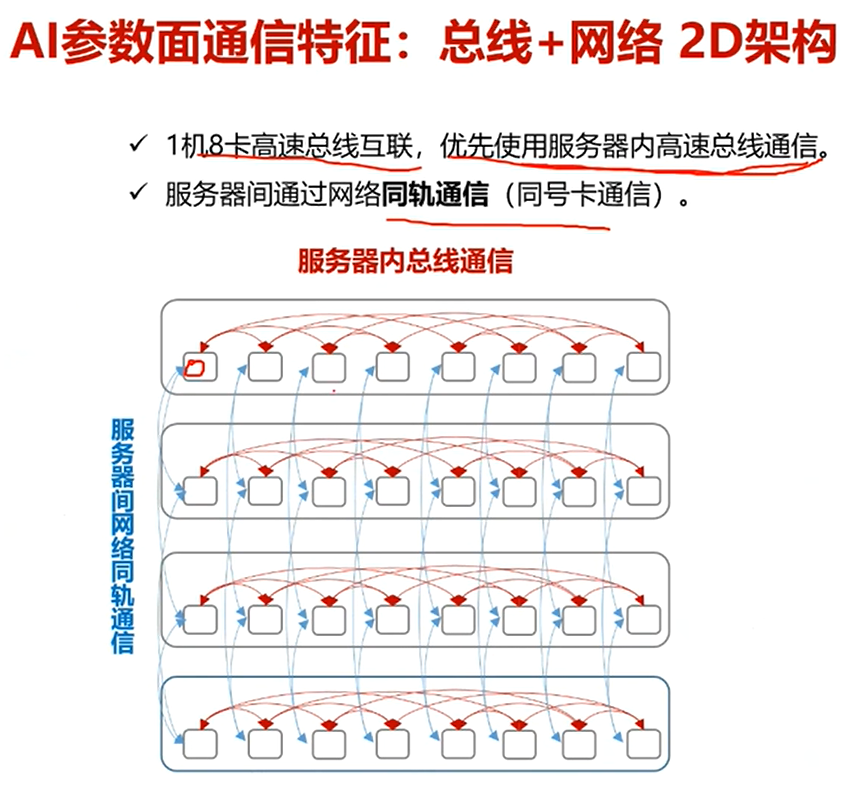
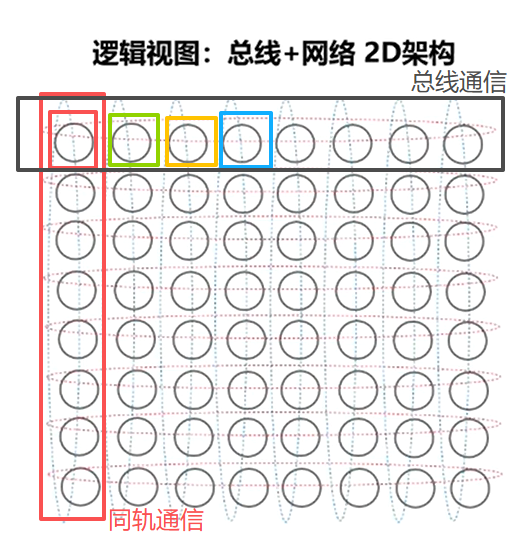
Rail 0 Rail 1 Rail 2 Rail 3 Rail 4 Rail 5 Rail 6 Rail 7
缩小来看:
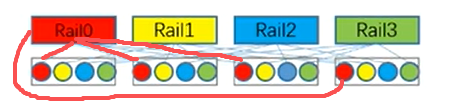
注:
同轨通信(轨内通信):"Rail"为一条独立的网络数据路径。
-
物理上 :一个"Rail"通常对应服务器上的一组物理网卡、交换机端口和线缆。
-
逻辑上:它是一个独立的、高带宽的通信通道。
7.大模型通信特点
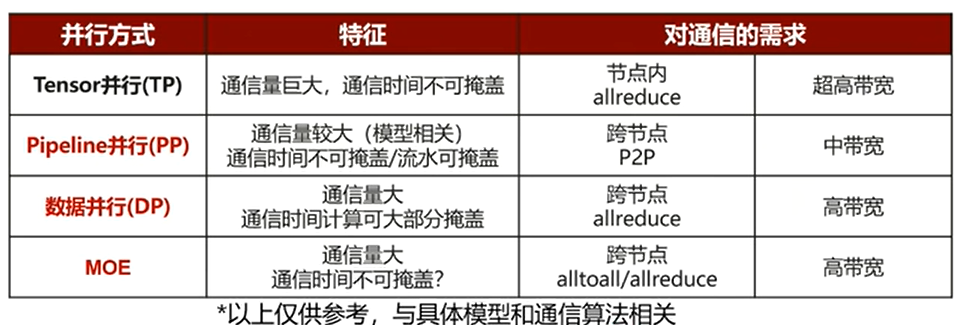
在实际训练万亿参数级别的大模型时,没有哪种策略是单独使用的,而是将它们组合起来,形成混合并行策略。
-
TP +PP + DP:这是最常见的组合。
-
在一个服务器节点内部 ,使用TP来切分一个巨大的数据,使得它能够放入节点内的多个GPU。
-
再加入流水线并行(PP):对于极大规模的模型,还会引入流水线并行(PP),来加快运算效率。
-
在多个服务器节点之间 ,使用DP来进行数据并行训练。每个节点就像一个"超级GPU",节点内部用TP解决内存问题,节点之间用DP加速训练。
-

同步突发:模型计算时都在计算,但需要参数同步时所有节点都在通信。
简单来说就是短时峰值大,对带宽有严苛要求
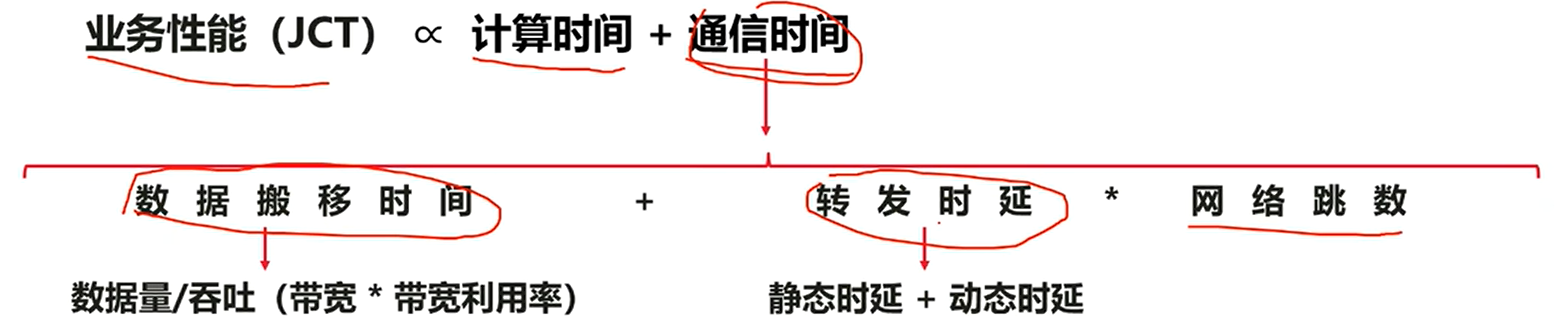
第二章:AI智算中心网络系统架构
1.网络系统架构特点

简单来说:
网络架构稳定不需要收敛(变大变小),但对带宽有严苛要求。其带宽越大,计算效率更高。
通常是局域网,时间延迟几乎不考虑
支持多租户
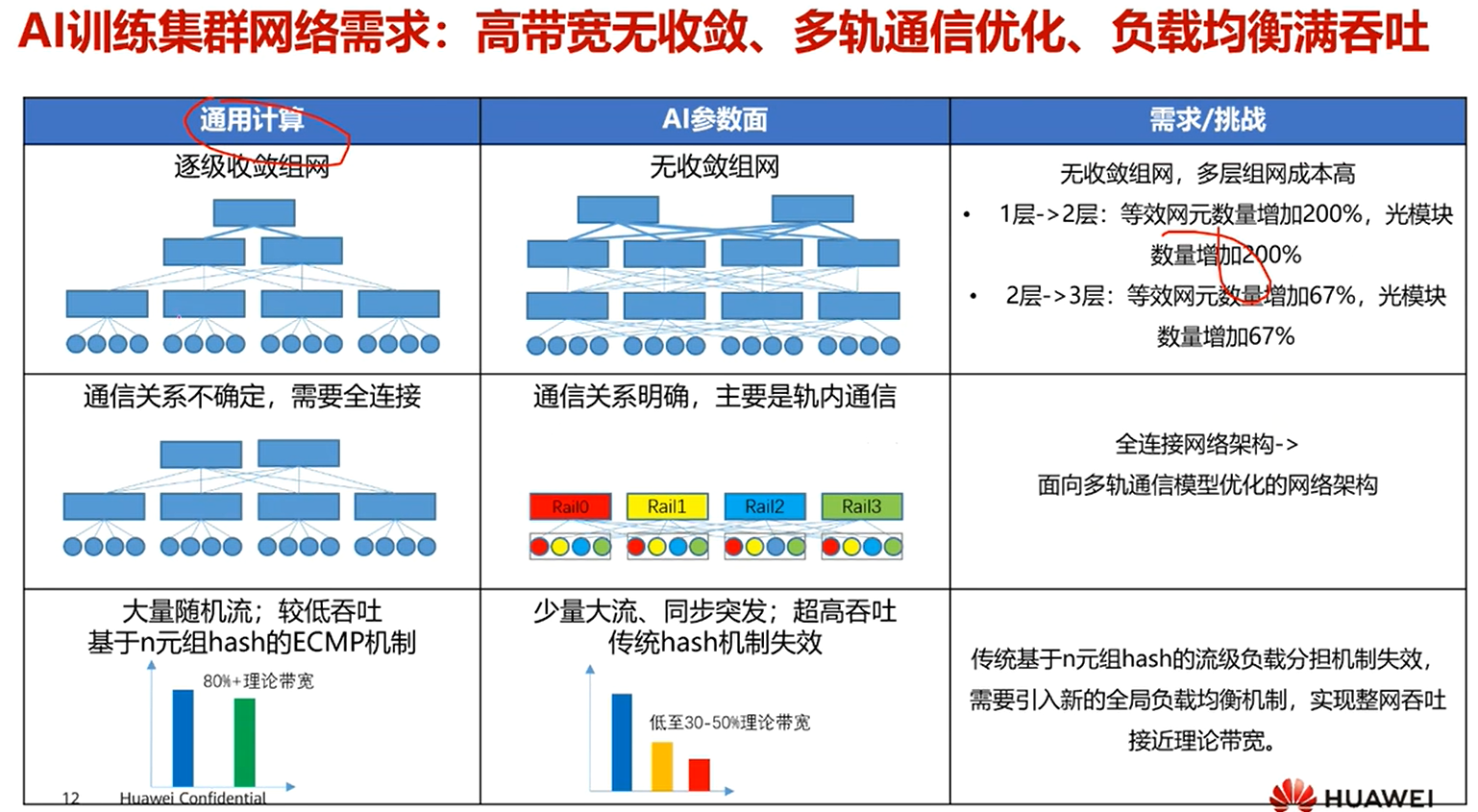
2.网络系统架构规划
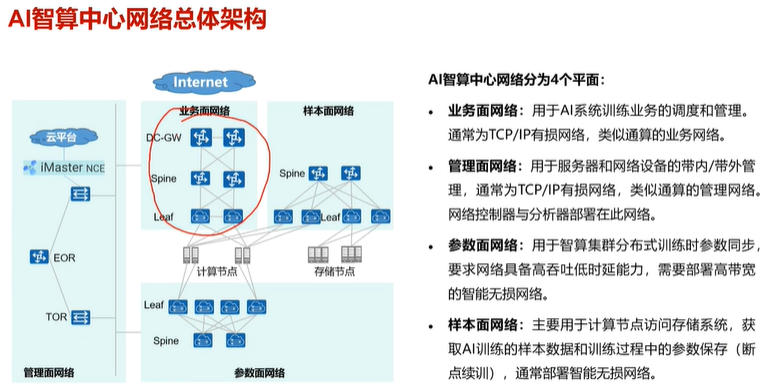
样本面网络,又称为存储面网络
注:AI智算中心架构比通算架构,多了两个平面:参数面网络、样本面网络(存储面网络)
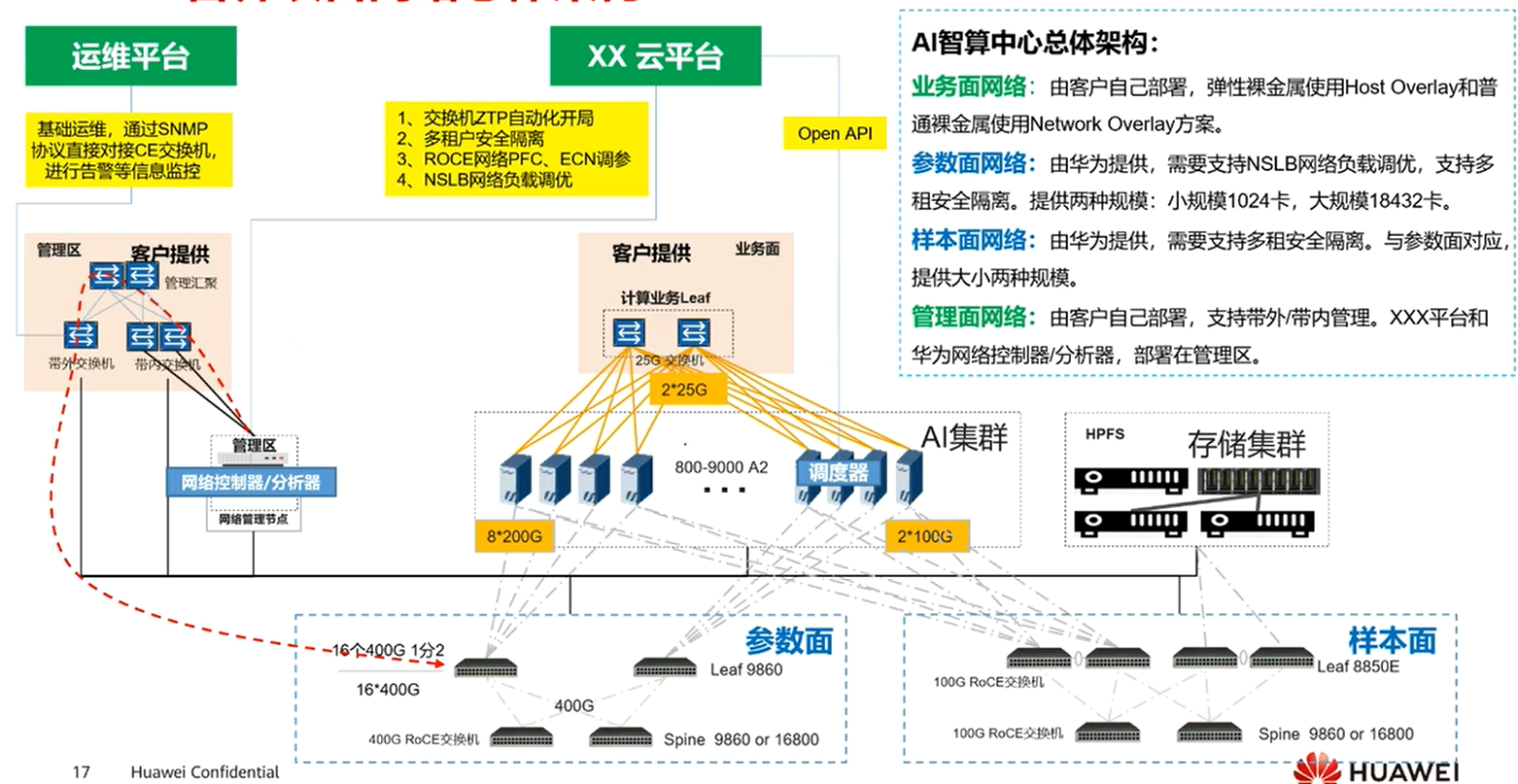
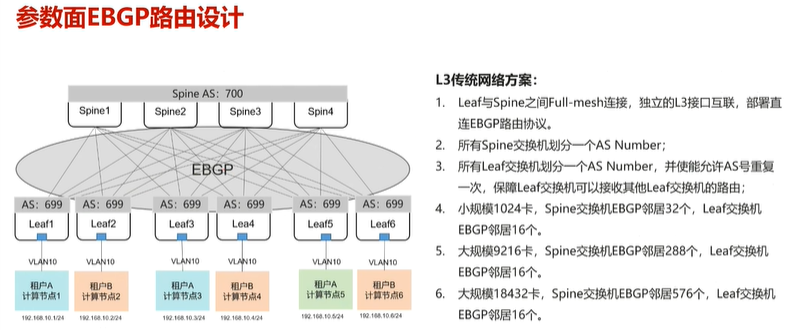
3.参数面网络负载调优
前面提到AI智算中心网络系统架构与传统网络架构不同,使用的是无收敛组网。
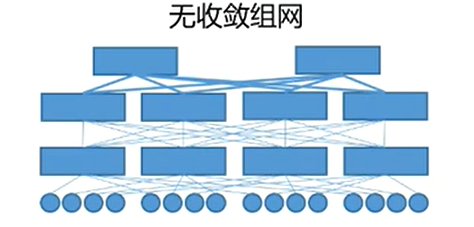
上图为逻辑架构,其实际部署架构为
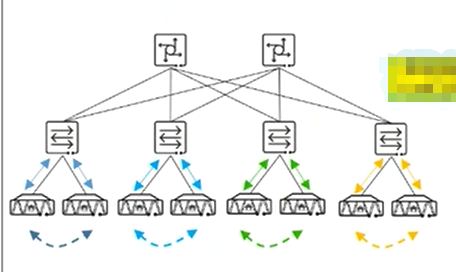
其中上层为Spine交换机:作为核心层交换机设备
其中中层为Leaf交换机:作为接入服务器的交换机设备
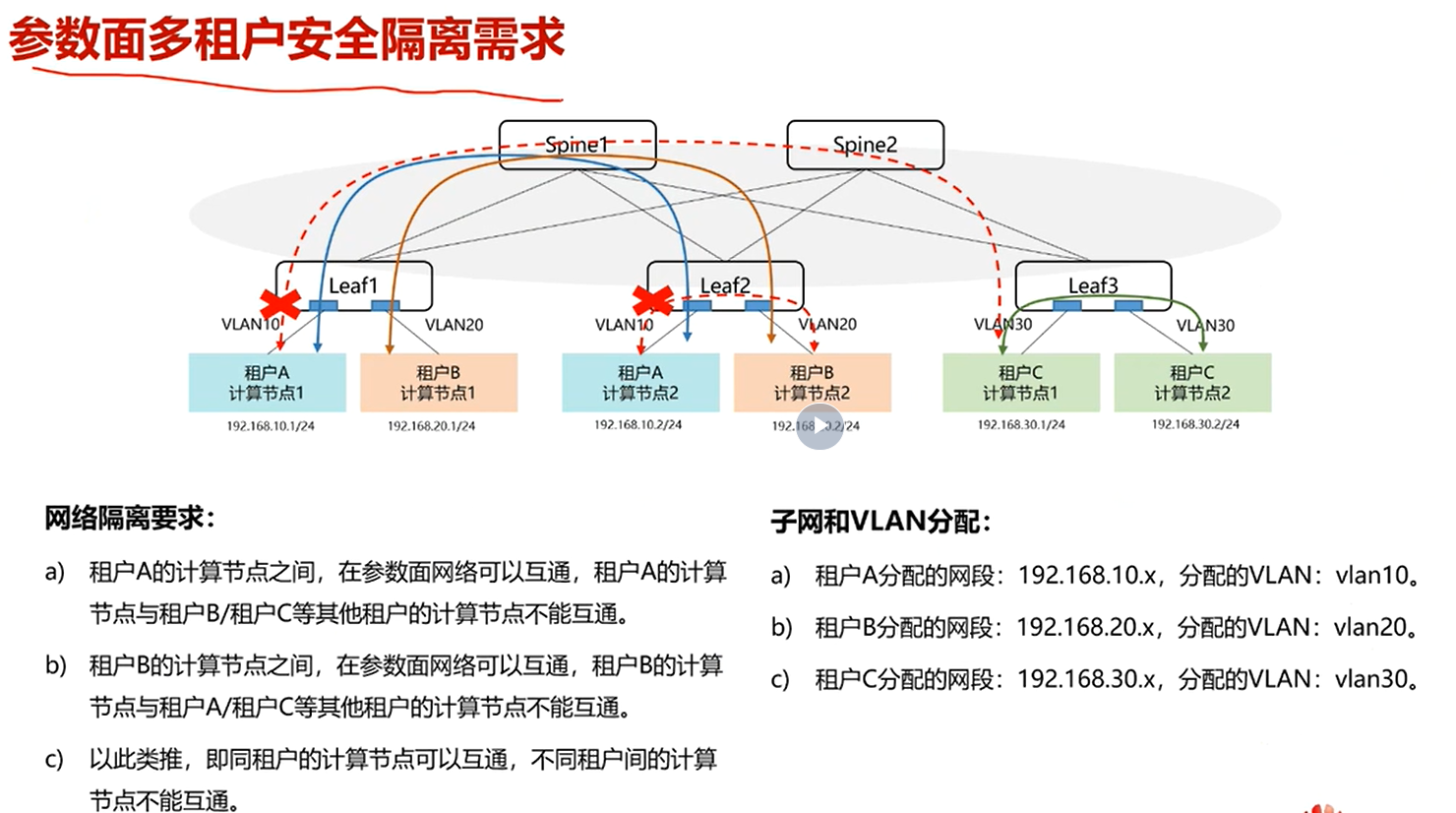
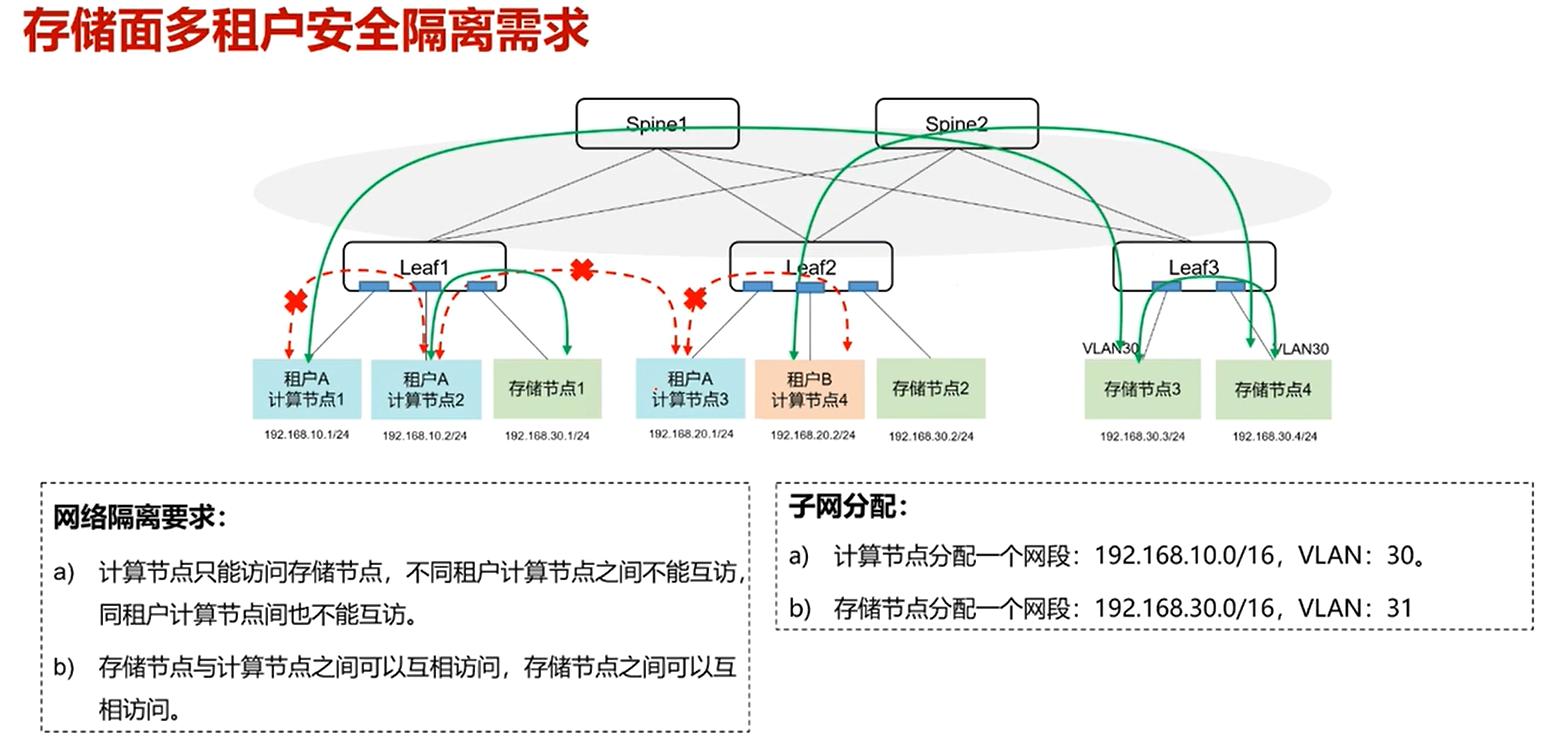
.安全隔离
当有多租户的情况下,优先将同一用户的计算节点,放在一个服务器内。可以使用高速总线通信。
其次再考虑下面情况
.网络协议?
leaf?
spine?
leaf与spine之间,使用BGP协议通信。