一、模型的准备
这次我们使用的数据集是一共有20种的食物图片
其中各种食物文件夹中食物图片
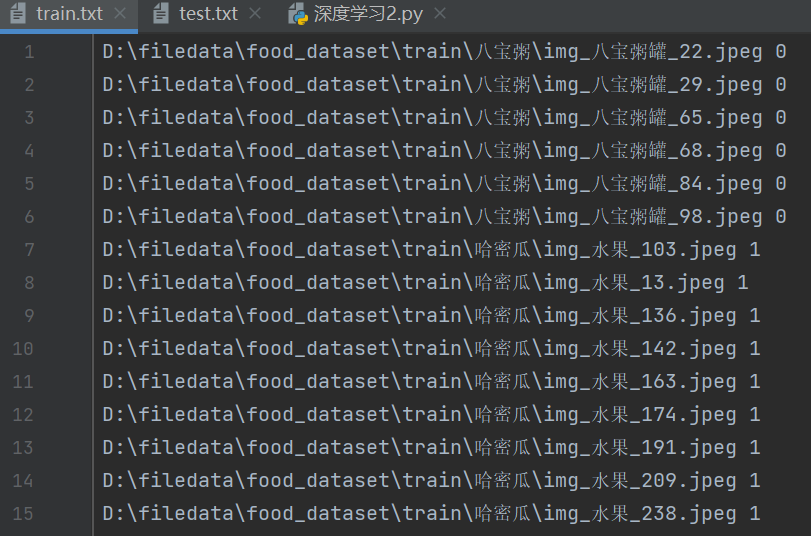
现在我们对这个文件生成对应的train.txt和test.txt
python
'''功能:创建训练集/测试集的标签文件
参数:
root:数据集根目录
dir:子目录名
'''
import os#导入操作系统模块,用于处理文件和路径
def train_test_file(root,dir):
file_txt = open(dir+'.txt','w')#创建txt文件,w表示写入,会覆盖原有内容
path=os.path.join(root,dir)#拼接完整路径
for roots,directories,files in os.walk(path):#遍历目录树,os.walk返回三个值,当前目录路径,子目录列表,文件列表
if len(directories) !=0:#如果第一层有子目录,记录所有类别名
dirs=directories
else:
now_dir=roots.split('\\')#到达图片文件所在层,最底层,分割路径获取当前类别文件夹名,用反斜杠分割路径
for file in files:#拼接图片完整路径
path_1=os.path.join(roots,file)
print(path_1)#打印路径(调试能用到)
file_txt.write(path_1+' '+str(dirs.index(now_dir[-1]))+'\n')#写入txt文件
#dirs.index(now_dir[-1]):获取当前类别的数字标签,也就是类别
file_txt.close()
root=r"D:\filedata\food_dataset"#数据集根目录
train_dir='train'#训练集文件夹名
test_dir='test'#测试集文件夹名
train_test_file(root,train_dir)#生成训练集标签文件train.txt
train_test_file(root,test_dir)#生成测试集文件训练集文件
二、数据预处理和数据增强
数据预处理就是对所有数据进行数据增强,标准化,归一化,去噪等操作,而其中的数据增强指增加数据多样性,是对数据裁剪,大小变换,旋转,亮度调整等操作。
数据增强是数据预处理的一部分,数据增强专门用来产生一些新的数据。
这些操作能让机器学会一张图片的几种呈现状态而不是只认识原图,这样模型在现实中遇到各种情况的图片时,都能正确识别。
数据预处理不宜少也不宜多,不做数据预处理,模型就会比较死板,也就是泛化能力差。过度的数据增强会让模型过拟合,所以需要自己调整添加适量的预处理。
预处理(特别是 Resize 和 ToTensor)能省很多麻烦,不然图片大小不一、格式不对,模型根本没法训练。
python
class USE_getitem():
def __init__(self,text):
self.text=text
def __getitem__(self, index):
result=self.text[index].upper()
return result
def __len__(self):
return len(self.text)
p= USE_getitem("pytorch")
print(p[0],p[1])
print(len(p))
#让对象能像列表一样用下标访问和获取长度
import torch
from torch.utils.data import Dataset,DataLoader
import numpy as np
from PIL import Image
from torchvision import transforms
import torch.nn as nn
#导入会用到的库
'''数据预处理'''
data_transforms={
'train':
transforms.Compose([#数据增强
transforms.Resize([280,280]),#先把图片缩放到280x280
transforms.RandomCrop(256),#随机裁剪到256x256
transforms.RandomHorizontalFlip(p=0.5),#50%概率水平翻转
transforms.ColorJitter(brightness=0.1,contrast=0.1),#调整亮度#,saturation=0.1,hue=0.1
transforms.ToTensor(),#转成张量
]),
'valid':
transforms.Compose([
transforms.Resize([256,256]),#测试时就直接缩放到256x256
transforms.ToTensor(),#转成张量
]),
}
#数据集,读取食物图片
class food_dataset(Dataset):
def __init__(self,file_path,transform=None):#从train.txt或test.txt读取图片路径和标签
self.file_path=file_path
self.imgs=[]
self.labels=[]
self.transform=transform
with open(self.file_path) as f :
samples=[x.strip().split() for x in f.readlines()]
for img_path,label in samples:
self.imgs.append(img_path)
self.labels.append(label)
def __len__(self):#返回数据集大小
return len(self.imgs)
def __getitem__(self, idx):#读取图片,如果有transform就处理,返回图片和标签
image=Image.open(self.imgs[idx])
if self.transform:
image=self.transform(image)
label=self.labels[idx]
label=int(label)
label=torch.from_numpy(np.array(label,dtype=np.int64))
return image,label
#数据加载
training_data=food_dataset(file_path=r'.\train.txt',transform=data_transforms['train'])
test_data=food_dataset(file_path=r'.\test.txt',transform=data_transforms['valid'])
train_dataloader=DataLoader(training_data, batch_size=64,shuffle=True)
test_dataloader=DataLoader(test_data, batch_size=64,shuffle=True)
#自定义cnn模型
class CNN(nn.Module):
def __init__(self):
super(CNN,self).__init__()
self.conv1=nn.Sequential(
nn.Conv2d(
in_channels=3,
out_channels=16,
kernel_size=5,
stride=1,
padding=2,
),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2),
)
self.conv2=nn.Sequential(
nn.Conv2d(16,32,5,1,2),
nn.ReLU(),
nn.Conv2d(32,32,5,1,2),
nn.ReLU(),
nn.MaxPool2d(2),
)
self.conv3=nn.Sequential(
nn.Conv2d(32,128,5,1,2),
nn.ReLU(),
)
self.dropout=nn.Dropout(0.3)
self.out=nn.Linear(128*64*64,20)#三层卷积层,最后输出20个类别
def forward(self,x):#前向传播:卷积->展平->全连接
x=self.conv1(x)
x=self.conv2(x)
x=self.conv3(x)
x=x.view(x.size(0),-1)
output=self.out(x)
return output
#设备设置和模型初始化
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else 'cpu'
model = CNN().to(device)
#训练函数
def train(dataloader,model,loss_fn,optimizer):
model.train()
batch_size_num=1#统计训练的batch数量
for X,y in dataloader:
X,y = X.to(device),y.to(device) # 把训练数据集和标签传入cpu或GPU
pred = model.forward(X)#前向计算
loss = loss_fn(pred,y)#计算损失
optimizer.zero_grad()#梯度清零
loss.backward()#反向传播
optimizer.step()#更新参数
loss_value = loss.item()
# if batch_size_num %10==0:
print(f"loss:{loss_value:>7f} [number:{batch_size_num}]")
batch_size_num +=1
#测试函数
def test (dataloader,model,loss_fn):
size=len(dataloader.dataset)
num_batchs=len(dataloader)
model.eval()
test_loss, correct = 0,0
with torch.no_grad():
for X,y in dataloader:
X,y = X.to(device),y.to(device)
pred = model.forward(X)
test_loss += loss_fn(pred,y).item() # test_loss是会自动累加每一个批次的损失值
correct +=(pred.argmax(1)== y).type(torch.float).sum().item() # 标量
test_loss /= num_batchs
correct /= size
accuracy = 100*correct
print(f"Test result: \n Accuracy :{(accuracy)}%,Avg loss:{test_loss}")
return accuracy
#损失函数
loss_fn=nn.CrossEntropyLoss()
#优化器
# optimizer = torch.optim.SGD(model.parameters(),lr=0.001)#尝试不同的值可以确保最后的准确率
optimizer = torch.optim.Adam(model.parameters(), lr=0.0001)
#训练循环
best_acc = 0
epochs=50
for t in range(epochs):
print(f"Epoch{t+1}\n------")
train(train_dataloader,model,loss_fn,optimizer)
current_acc=test(test_dataloader, model, loss_fn)
if current_acc > best_acc:
best_acc = current_acc
torch.save(model.state_dict(),'best_model.pth')
print(f'最佳模型:准确率{best_acc:.2f}%')
print("Dnoe!")
print(f'最佳模型:准确率{best_acc:.2f}%')结果:
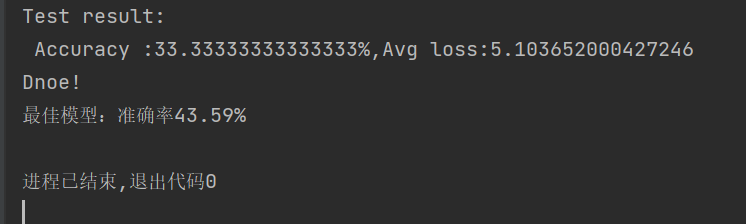
此外有两个小点也会影响准确率,可以微调模型。
1)优化器中学习率值,也就是这里的lr=0.0001,可以尝试其他值。太大正确率波动大,可能错过最优点;太小训练慢,可能卡在局部最优点
2)epoch值,是训练循环次数。次数少模型可能没学够,正确率低;太多可能过拟合,训练集正确率高,测试集反而低。
四、调整学习率(调度器)
1.固定步长调度器StepLR
在优化器后边加上:
有时候这个导入可能是呈灰色的,可能是编码工具的原因,代码是能运行的。
python
from torch.optim.lr_scheduler import StepLR
scheduler=torch.optim.lr_scheduler.StepLR(optimizer,step_size=10,gamma=0.5)在训练循环中if current_acc > best_acc:前面加上三行,如下:
python
best_acc = 0
epochs=50
for t in range(epochs):
print(f"Epoch{t+1}\n------")
train(train_dataloader,model,loss_fn,optimizer)
current_acc=test(test_dataloader, model, loss_fn)
scheduler.step()
current_lr=optimizer.param_groups[0]['lr']
print(f'当前学习率:{current_lr:.6f}')
if current_acc > best_acc:
best_acc = current_acc
torch.save(model.state_dict(),'best_model.pth')
print(f'最佳模型:准确率{best_acc:.2f}%')
print("Dnoe!")
print(f'最佳模型:准确率{best_acc:.2f}%')这里学习率没有提升,可以修改里面的参数进行对比,但有时候可能是模型已经收敛,所以调度器对它影响不大,需要知道的是调度器也是优化模型的一种方法。

2.ReduceLROnPlateau调度器
也是在优化器后边加上:
python
from torch.optim.lr_scheduler import ReduceLROnPlateau
# scheduler = ReduceLROnPlateau(optimizer, patience=5, factor=0.1)
#这样写我们需要修改训练函数,让他有个返回值,比较麻烦
scheduler = ReduceLROnPlateau(optimizer, mode='max', patience=5, factor=0.1, verbose=True)
#这样就不需要修改训练函数了
# mode='max' 表示监控指标越大越好(如准确率),如果监控 loss 就用 mode='min'
#这里用了max我们后边就监控准确率,用min就监控损失函数
#监控的指标不同,结果也是不同的不过都是为了增加模型准确率,既然是更高准确率,那用max就更直接和上一个调度器不一样的是这里我们需要填一个参数,根据上面所述,我们使用了max就填入准确率
python
scheduler.step(current_acc)调度器的选择也需要我们自己去尝试,哪个更合适模型
