
「【新智元导读】银河通用联合多所大学发布了全球首个跨本体全域环视导航基座大模型 NavFoM,让机器人能自己找路,而不再依赖遥控,从而推动具身智能向规模化商业落地演进。」
今年 6 月,一支机器狗的视频在社交平台上刷屏------它在未训练过的真实场景(如人流密集的商场里)Zero-Shot 地跟随用户,完成自主移动、避障、转向,并能能听懂「跟着妈妈」、「去陪孩子」的语音指令。
那背后,是银河通用发布的导航大模型 TrackVLA**(「 「让机器人「满大街跑」走进现实:银河通用发布产品级端到端导航大模型 TrackVLA」」)**。
该模型由仿真大数据训练,在真实复杂场景中实现 Sim2Real,完成智能的用户跟随,展现了极强的 C 端应用落地潜力。
「最近,银河通用的导航大模型技术又迎来了质的飞跃。」
银河通用联合北京大学、阿德莱德大学、浙江大学等团队,推出了**「全球首个跨本体全域环视的导航基座大模型------NavFoM」**(Navigation Foundation Model)。
如果说 TrackVLA 让机器人学会「跟着人走」,那么 NavFoM 的意义在于------让机器人掌握全栈「移动的基础知识」。作为基座大模型,其自身可以做到:
- **「全场景」****:**同时支持室内和室外场景,未见过的场景 Zero-Shot 运行,无需建图和额外采集训练数据;
- **「多任务」****:**支持自然语言指令驱动的目标跟随和自主导航等不同细分导航任务;
- **「跨本体」****:**可快速低成本适配机器狗、轮式人形、腿式人形、无人机、甚至汽车等不同尺寸的异构本体。
除此之外,该模型允许开发人员以之为基座,通过后训练,进一步进化成满足特定导航要求的应用模型。
下面将从技术视角,解析其技术特点,介绍以此为基石衍生出的应用模型具身和对应的产业应用价值。

「「导航」是具身智能的」
「基础能力之一」
导航是所有机器人移动操作的基础,也是感知、理解、决策、行动的综合体现。
然而在过去很长一段时间里,具身导航的技术体系是相对碎片化的------不同任务(如跟随、搜索、驾驶)各用一套算法,不同机器人(如四足、人形、无人机)又各自训练模型。每换一个任务或本体,模型就得重新开发。
这样的割裂不仅使得具身导航模型训练时效率低,二次开发难度大,还造成具身模型商用落地周期长,在不同本体上、不同场景中规模化商业应用的边际成本高等问题。
对此,银河通用的研发团队认为,让机器人具备可迁移智能、迈向大规模商用的第一步是让具身导航模型技术凝聚成一个通用的具身大脑,**即构建一个能多任务、全场景、跨本体的具身导航大模型基座,**实现让具身导航模型从「学会完成一条导航智能」到「真正理解机器人移动」的跨越。
「从 TrackVLA 到 NavFoM」
「不仅能「跟着走」更能「自己找路」」
基于这一思考,银河通用联合北京大学、阿德莱德大学、浙江大学等团队共同发布了新一代导航基座大模型------NavFoM(****「Navigation」 「Foundation Model)」。

这是全球首个跨本体全域环视导航基座大模型,把 Vision-and-Language Navigation、Object-goal Navigation、Visual Tracking 和 Autonomous Driving 等不同机器人的导航任务统一到相同的范式。
如果说 TrackVLA 是让机器人能听懂人类语言、跟随目标前进,那么 NavFoM 的目标是**「让机器人能够自主感知世界,在完全未知的环境中自己决定去哪、怎么走。」**
「统一范式」
「让不同机器人「掌握同一种语言」」
「NavFoM 重新定义了导航的底层逻辑」。
过去,导航任务往往被拆分成识别、定位、规划等独立模块,模型之间缺乏统一语言。
而 NavFoM 建立了一个全新的通用范式:「视频流 + 文本指令 → 动作轨迹」。
无论是「跟着那个人走」,还是「找到门口的红车」,在 NavFoM 里都是同一种输入输出形式。模型不再依赖模块化拼接,而是端到端地完成 "看到---理解---行动" 的全过程。

这意味着,「曾经割裂的任务经过统一的数据对齐和任务建模可以互相迁移;不同形态的 「「机器人」 」能共享学习经验和运动知识」。
例如,四足机器人在商场里学到的「避让人群」经验,可能会帮助无人机在空中理解「动态障碍」;自动驾驶模型中的「道路预测」,也能反哺轮式机器人在室内路径规划中的判断。
统一的输入与决策机制,让机器人真正具备了跨任务的「认知迁移」能力。
「体系升维」
「从「任务模型」到「智能基座」」
NavFoM 通过两项关键技术创新构建统一学习范式,让机器人不仅看得懂、记得住、学得会,还能联合利用不同本体、不同任务和不同场景的数据实现知识共享,最终成为一个基座模型,衍化出针对不同应用需求优化的产品级应用模型矩阵。
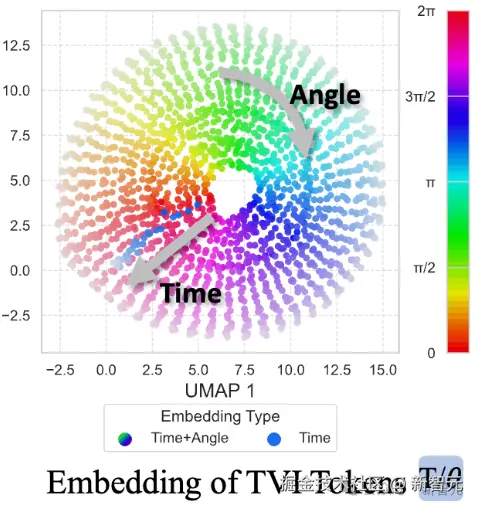
「第一,TVI Tokens(Temporal-Viewpoint-Indexed Tokens)------让模型理解时间与方向。」
不同相机、不同角度、不同时间拍到的画面,常常让模型「迷失」。
「TVI Tokens 就像时间轴与方向罗盘,给每一帧画面加上时间和视角的标记,让模型知道这幅图像来自哪个角度、哪个时刻,从而理解空间的连续变化。」
它让模型同时兼容单目、环视、无人机等多种视觉输入方式,真正具备「世界在变化」的时空理解能力。
「第二,BATS 策略(Budget-Aware Token Sampling)------让模型在算力受限下依然聪明。」
导航时的视频数据极其庞大,不可能每一帧都处理。
BATS 策略像人类的注意力系统,会动态判断哪些画面是「关键帧」,哪些可以略过。
越靠近当前时刻、越重要的场景,采样概率越高,从而节省算力又不损失判断准确性。
这一机制让 NavFoM,这一 7B 参数级别的基座模型也能在真实机器人上毫秒级响应,兼顾实时性与精度。
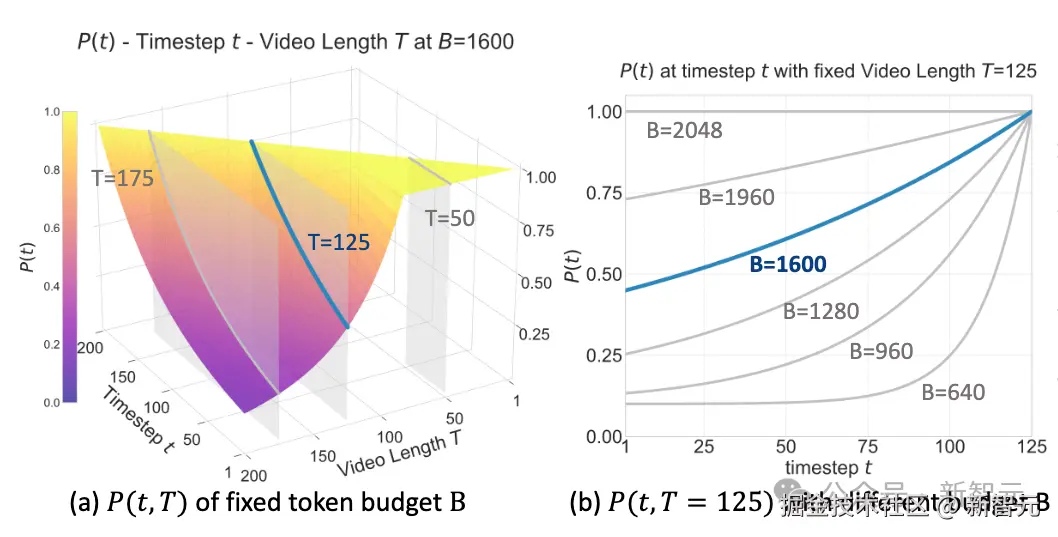
给定 Token 上限,在不同帧数下的采样分布(左图);给定视频帧数,在不同 Token 上限下的采样分布(右图)
它们共同构成了从室内到城市、从汽车到机器人再到无人机的完整具身智能导航体系,让以导航大模型为驱动的具身智能机器人真正开始走向现实世界。
「体系再再再升维」
「从「模型矩阵」到「规模化商业落地」」
从单一任务模型到统一智能基座;以统一智能基座构建全栈模型矩阵;依托全栈模型矩阵实现规模化商业落地。
「银河通用正推动导航技术从「局部功能」进化为「智能基础设施」,让机器人真正具备「理解空间、适应变化、自主行走」的能力。」
这种体系化模型能力,是未来具身智能大规模落地的关键。
从学习特定任务到理解通用知识,NavFoM 作为业内首个跨本体全域环视的导航基座大模型,第一次让机器人拥有了类似人类的通用「方向感」------在陌生街区中找路、在人群中穿行、在复杂空间中预测障碍等等。
而本次 NavFoM 的发布也标志着银河通用完成了从机器人导航从单一功能创新到智能基座建设的跨越,其将和银河通用的操作基座大模型 GraspVLA、GroceryVLA 等一起支撑起银河通用让具身大模型机器人走进千家万户、服务千行百业的宏大商业理想。