TL;DR
- 场景:企业厌倦 "HBase 实时 + Parquet 分析" 双存储与 ETL 延迟。
- 结论:Kudu 以列式 + Raft 提供毫秒级随机写与高吞吐扫描,适合实时分析/时序/HTAP,事务能力有限。
- 产出:2025 年版本选型与兼容矩阵、部署要点与常见故障速查卡。

版本矩阵
| 组件/模块 | 建议版本(2025) | 已验证 | 说明 |
|---|---|---|---|
| Kudu | 1.18.0 | 是(官方发布) | 2025-07 发布;新增分段 LRU Block Cache、RocksDB 元数据(实验)。 |
| Kudu | 1.17.1 | 是(维护分支) | 2024-11 维护版,1.16/1.17 客户端兼容性说明见官方文档。 |
| Spark 集成 | Spark 3.5 + kudu-spark3_2.12:1.18.0 | 是(中央仓库) | 对齐 1.18 依赖,适配 Spark 3 系列。 |
| Flink 集成 | Kudu Connector 2.0.0(Flink 1.19/1.20) | 是(官方博文) | 外部化连接器,Table/DataStream 新栈。 |
| Impala 集成 | Impala ≥3.3 + HMS 同步 | 是(官方文档) | Kudu-HMS 自动同步;适合低延迟 SQL 读写。 |

官方网站
Apache Kudu 基本介绍
Apache Kudu 是由 Cloudera 公司开发并贡献给 Apache 软件基金会的开源存储引擎。它旨在解决大数据处理中的一个关键问题 - 如何在同一个存储系统中同时支持低延迟的随机读写和高效的分析能力。
核心特性
Kudu 具有以下几个显著特点:
-
混合存储模型:
- 支持随机读写(类似 HBase)
- 支持批量扫描分析(类似 HDFS)
- 典型读写性能可达毫秒级
-
分布式架构:
- 采用水平扩展架构,可通过增加服务器来提升容量和性能
- 使用 Raft 一致性协议保证数据可靠性和一致性
- 自动分区和数据复制
-
列式存储:
- 采用列式存储格式,提高分析查询效率
- 支持压缩和编码优化
-
生态系统集成:
- 与 Apache Spark 深度集成,支持 Spark SQL 和 DataFrame API
- 支持 Impala、Hive 等查询引擎
- 提供 Java、C++ 和 Python 客户端
市场定位
在大数据存储领域,Kudu 填补了现有技术的一些空白:
- HDFS/Parquet/ORC:适合批量分析,但随机写入性能差
- HBase/Cassandra:适合随机访问,但分析效率低
Kudu 特别适合以下场景:
- 需要实时更新的分析应用(如用户行为分析)
- 时序数据存储(如物联网传感器数据)
- 需要同时支持事务和分析的混合工作负载
性能表现
在典型配置下,Kudu 可以做到:
- 单行读取延迟:<10ms
- 批量扫描吞吐:GB/s 级别
- 支持每秒数千次的写入操作
Kudu 目前已被许多大型互联网公司采用,用于构建实时数据分析平台和操作型分析系统。
背景和设计目标
传统的大数据存储解决方案(如 HDFS 和 HBase)通常在读写性能、查询延迟和数据模型等方面有所取舍。Kudu 则试图平衡这些需求,结合了 HDFS 的高吞吐量和 HBase 的快速随机读写能力,支持如下需求:
- 快速随机读写:支持近实时的数据写入与更新,适用于时间序列数据、传感器数据、交易数据等场景。
- 高效批量查询:通过列式存储设计,提升大规模数据的分析性能。
- 低延迟查询:支持低延迟的 OLAP(在线分析处理)查询,适用于实时分析场景。
架构和数据模型
Kudu 是一个分布式系统,采用主从架构:
- Master节点:负责全局元数据的管理,如表的创建、删除、分区等元数据操作。它还负责协调数据副本的分配。
- Tablet Server节点:负责表格数据的存储和查询。每个 Tablet Server 管理多个数据片(Tablet),这些数据片是数据分区后的单元。
数据模型
Kudu 的数据模型类似于传统的关系数据库,支持表、行、列的结构:
- 表:每个表有一个或多个列,可以定义主键。
- 行:每一行由一组列组成,每一行在插入时通过主键唯一标识。
- 列:Kudu 中的列可以支持多种数据类型,包括整数、浮点数、字符串等。
Kudu 表支持分区和副本,分区策略可以基于范围(Range)或哈希(Hash)进行配置,而副本机制确保了数据的高可用性和容错能力。
列式存储和压缩
Kudu 采用列式存储格式,这意味着表中的数据按列存储,而非按行。这种设计在大规模数据分析中极具优势,因为它可以减少磁盘 I/O 并提高查询性能。例如,在分析数据时,如果只查询特定列,Kudu 只需要读取这些列的数据,而不必读取整行。
Kudu 支持多种压缩算法,如 LZ4、Snappy 和 Zlib,用户可以根据需要选择合适的压缩方式来优化存储空间和性能。
与 Hadoop 和 Spark 集成
Kudu 与大数据生态系统中的其他组件有很好的集成能力:
- 与 Apache Hadoop:Kudu 可以与 Hadoop 的 HDFS、YARN 等组件集成。Kudu 的数据可以通过 MapReduce 和其他 Hadoop 工具进行处理。
- 与 Apache Spark:Kudu 提供了 Spark 连接器,允许用户在 Spark 中直接读写 Kudu 表。用户可以利用 Spark 进行复杂的实时数据处理和分析。
此外,Kudu 还可以与 Apache Impala 集成,提供类似 SQL 的低延迟查询接口,使得用户能够对存储在 Kudu 中的数据执行高性能的 SQL 查询。
使用场景
由于 Kudu 同时支持快速随机读写和高效批量分析,适合以下几类应用场景:
- 实时分析:如点击流分析、物联网传感器数据分析等需要近实时数据处理的场景。
- 时间序列数据存储:Kudu 对时间序列数据的存储和查询有很好的支持,可以为金融、监控、日志等领域提供解决方案。
- 混合工作负载:一些需要同时支持 OLTP(在线事务处理)和 OLAP(在线分析处理)的应用,可以利用 Kudu 实现既快速更新数据,又能进行高效批量查询。
优点
- 低延迟的随机读写性能:Kudu 适用于需要频繁更新或插入数据的场景,并且支持快速的随机读取。
- 高效的批量查询:列式存储提升了批量查询的性能,尤其是大规模数据分析。
- 与 Spark、Impala 的良好集成:Kudu 与大数据生态系统集成紧密,用户可以方便地利用这些工具进行数据分析。
- 灵活的数据模型:Kudu 支持关系型数据模型,提供了与传统关系数据库相似的操作接口。
缺点
- 事务支持有限:Kudu 的事务支持较为简单,可能不适合复杂的事务场景。
- 不适合冷数据:由于 Kudu 主要针对快速读写的场景,因此对存储长期不访问的冷数据并不理想。
- 依赖内存较多:Kudu 在处理高并发写入时,对内存的依赖较大,系统需要较高的硬件配置以获得最佳性能。
基于HDFS
- 数据分析:Parquet,具有高吞吐量连续读取数据的能力
- 实时读写:HBase和Cassandra等技术适用于低延迟的随机读写场景
在Kudu之前,大数据主要是以两种方式存储:
- 静态数据:以HDFS引擎作为存储引擎,适用于高吞吐量的离线大数据分析场景,这类存储的局限性是数据无法随机读写
- 动态数据:以HBase、Cassandra作为存储引擎,适用于大数据随机读写场景,这类存储的局限性就是批量读取吞度量远远不及HDFS,不适用于批量数据的分析的场景。
目前痛点
所以现在的企业中,经过会存储两套数据分别用于实时读写和数据分析。 先将数据写入HBase中,再定期ETL到Parquet进行数据同步。 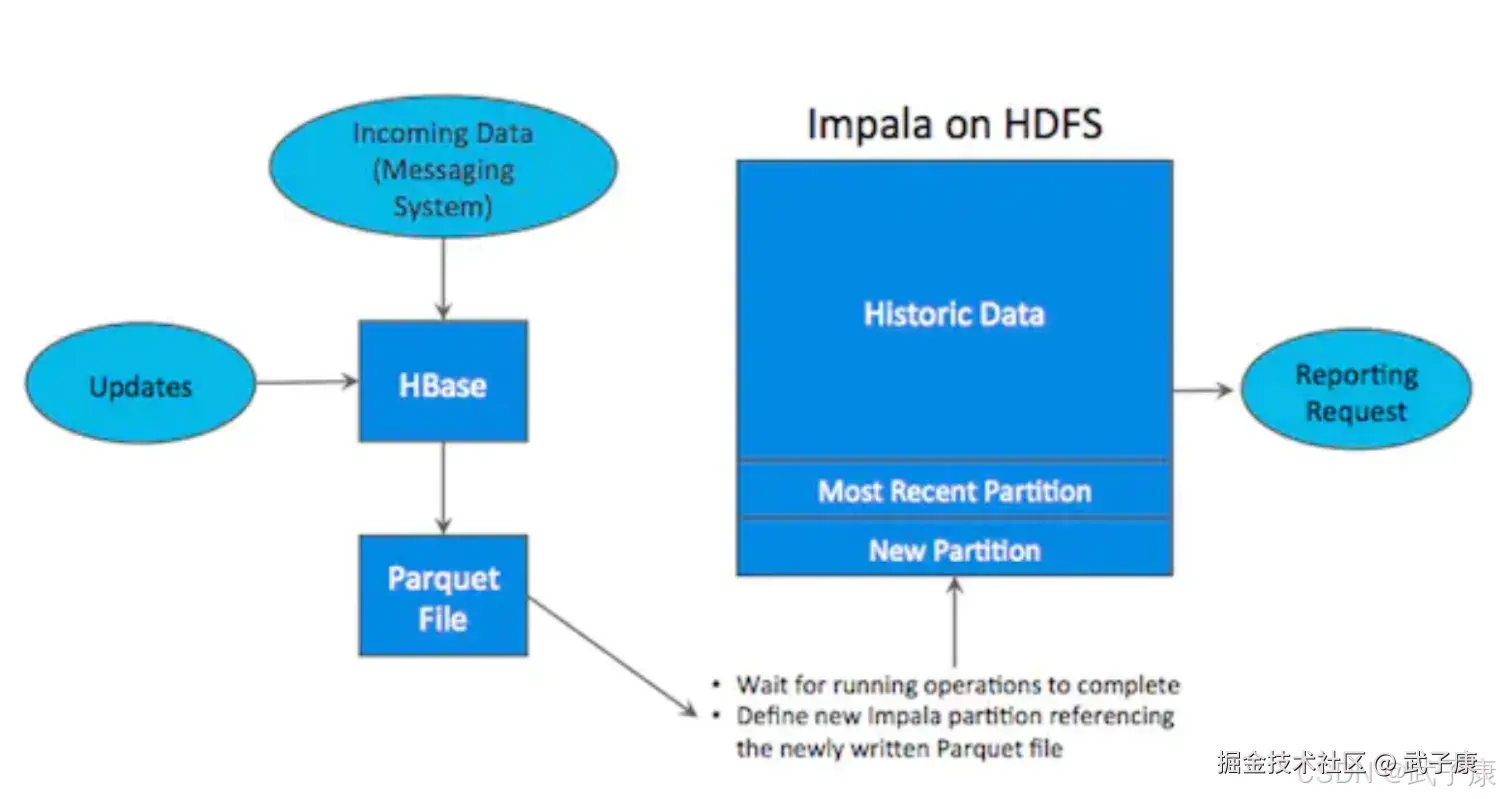
数据架构的潜在问题分析
1. 系统复杂度与维护成本
这种双重架构要求用户在两套系统间建立复杂的ETL(Extract-Transform-Load)流程。例如:
- 需要开发专门的抽取程序从源系统获取数据
- 编写复杂的数据转换逻辑来处理格式差异
- 实现定期加载机制来同步数据
- 为处理异常情况需要额外的监控和修复机制
随着业务发展,这些ETL作业会变得越来越复杂,维护成本呈指数级增长。团队需要持续投入资源来保证数据流程的正常运行。
2. 数据处理时效性问题
典型ETL流程的延迟情况:
- 小时级ETL:数据延迟至少1小时
- 日批处理:数据延迟24小时
- 特殊场景下可能延迟更久
这种延迟会导致:
- 实时决策缺乏最新数据支持
- 监控系统无法及时发现异常
- 用户看到的数据与实际状况脱节
- 错失商业机会的时间窗口
3. 数据更新挑战
当需要更新已有数据时面临的问题:
- Parquet文件的不可变特性要求重写整个文件
- 大规模历史数据更新需要消耗大量计算资源
- 更新操作可能导致下游依赖的报表或模型失效
- 缺乏原子性保证,可能存在数据不一致风险
实际业务场景中,数据更正、维度变化等需求频繁出现,这种架构难以灵活应对。
4. 资源利用效率低下
双重存储带来的资源浪费体现在:
- 相同数据在两套系统中各存一份
- 需要维护两套基础设施(服务器、网络等)
- 双倍的人力运维成本
- 计算资源重复消耗(两次数据处理)
- 存储空间占用翻倍
例如,一个1TB的数据集,在两套系统中可能实际占用2TB以上的存储空间,加上备份和冗余,成本更加可观。
Kudu优势
我们知道,基于HDFS,比如Parquet,具有高吞吐量连续读取数据的能力,而HBase和Cassandra等技术适用于低延迟的随机读写场景,那么有没有一种技术,结合二者。 Kudu提供了一种 Happy Medium 的选择: 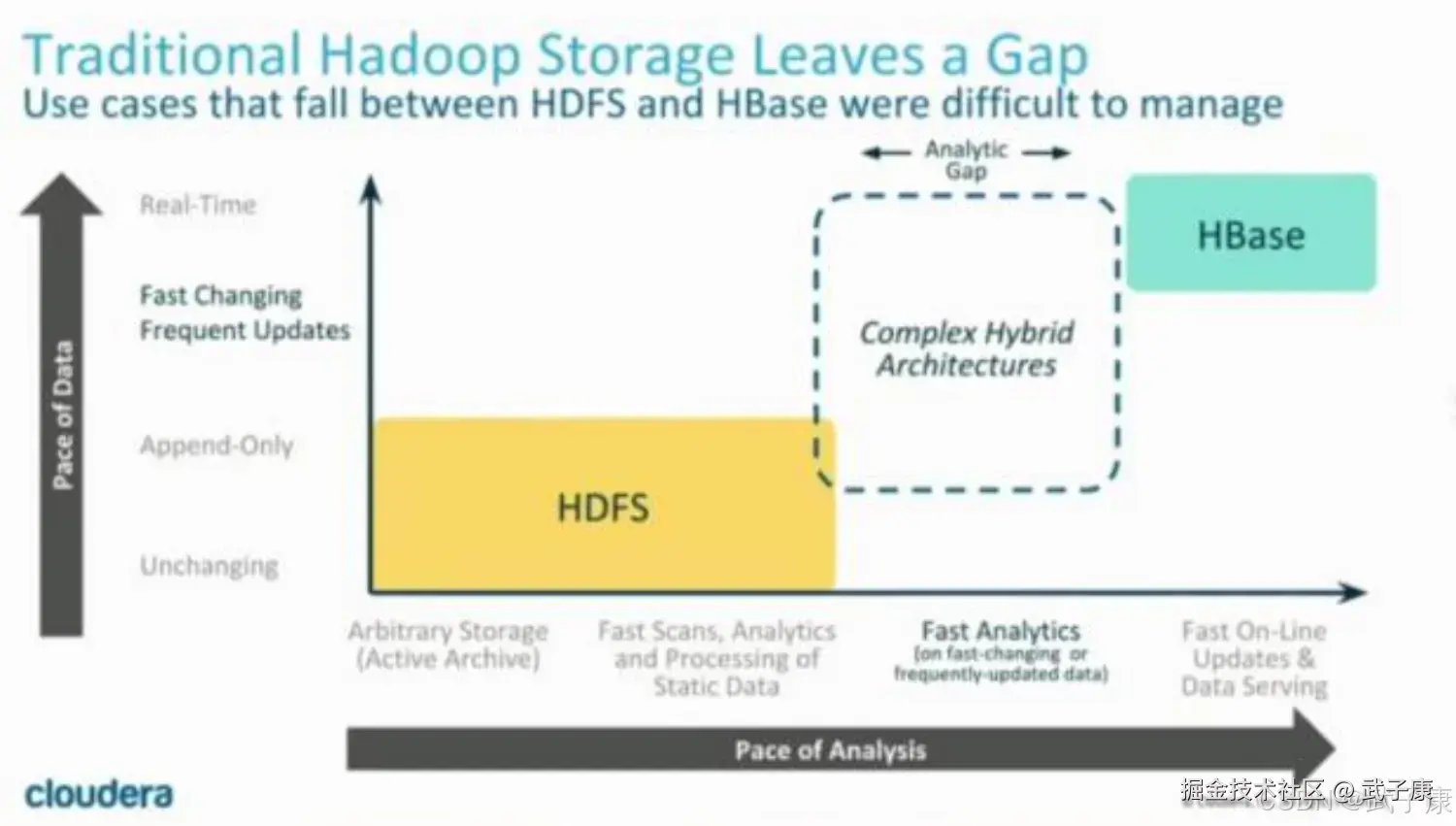
Kudu不但提供了行级的插入,更新,删除,同时也提供了接近Parquet性能的批量扫描操作。使用同一份存储,既能随机读写,也可以满足数据分析的需求。
数据模型
Kudu的数据模型与传统的关系型数据库类似,一个Kudu集群由多个表组成,每个表由多个字段组成,一个表必须指定若干个字段组成主键: 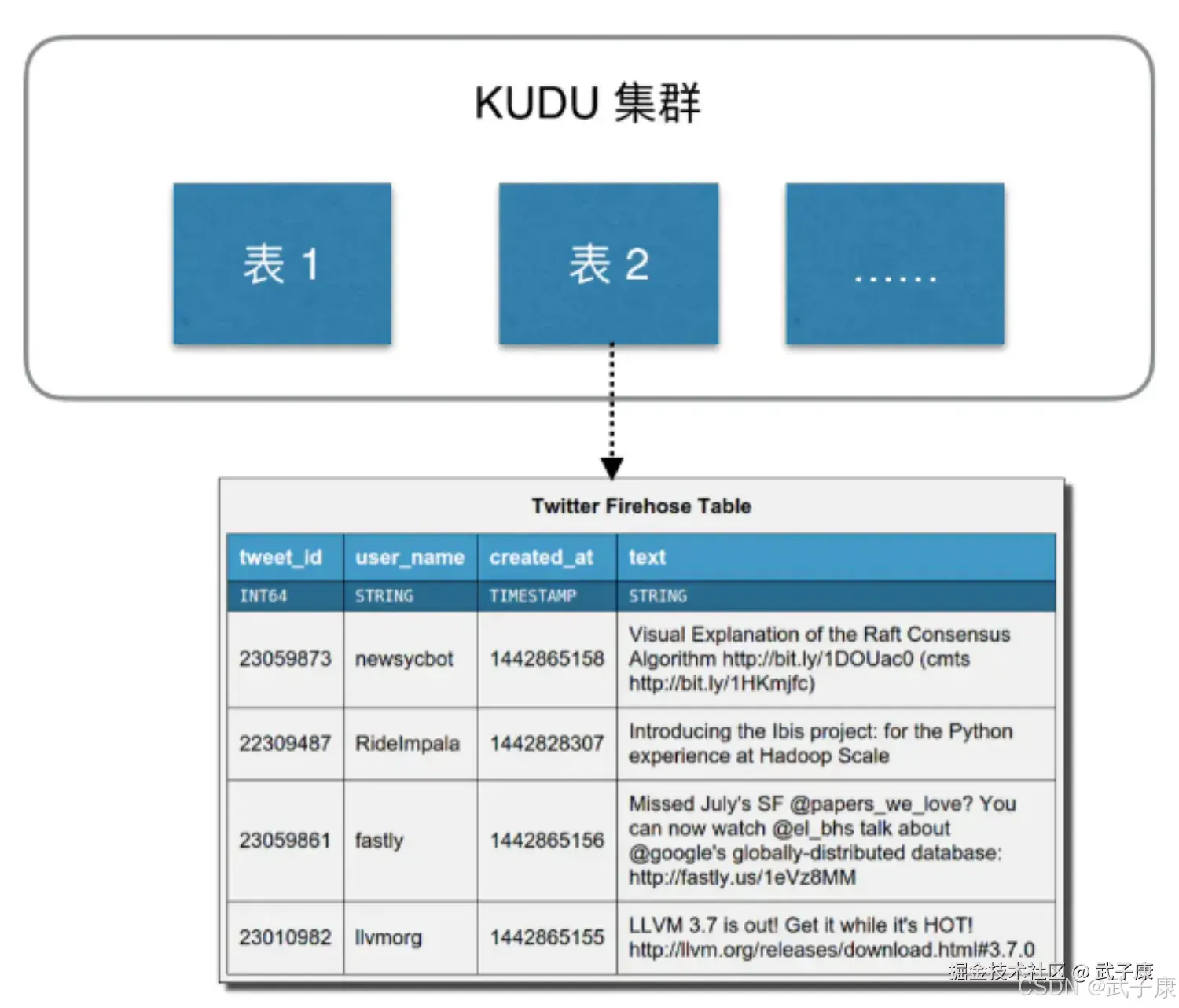 从用户角度看,Kudu是一种存储结构化数据的存储系统。在一个Kudu集群中可以定义任意数量的table,每个table都需要预先定义好Schema。 每个Table的列数是确定的,每一列都需要有名字和类型,每个表中可以把其中一列或者多列定义为主键。 这么看来,Kudu更像关系型数据库,而不是HBase、Cassandra、MongoDB这些NoSQL数据库,不过Kudu目前还不能像关系型数据库一样支持二级索引。 Kudu使用确定的列类型,字段是强类型的,而不是NoSQL那种 Everything is Byte。可以带来好处如下:
从用户角度看,Kudu是一种存储结构化数据的存储系统。在一个Kudu集群中可以定义任意数量的table,每个table都需要预先定义好Schema。 每个Table的列数是确定的,每一列都需要有名字和类型,每个表中可以把其中一列或者多列定义为主键。 这么看来,Kudu更像关系型数据库,而不是HBase、Cassandra、MongoDB这些NoSQL数据库,不过Kudu目前还不能像关系型数据库一样支持二级索引。 Kudu使用确定的列类型,字段是强类型的,而不是NoSQL那种 Everything is Byte。可以带来好处如下:
- 确定的列类型使Kudu可以进行类型特有的编码,节省空间。
- 可以提供SQL-like元数据给其他上层查询工具,比如BI工具。
- Kudu的场景是OLAP分析,有一个数据类型对下游的分析工具也更加友好。
用户可以使用INSERT、UPDATE、DELETE等对表进行操作。不论使用那种API,都必须指定主键,但批量的删除和更新操作依赖更高层次的组件(比如Impala、Spark)。 Kudu目前不支持多行事务。在读操作方面,Kudu只提供了Scan操作来获取数据,用户可以通过指定过滤条件来获取自己想要读取的数据,但目前只提供了两种类型的过滤条件:主键范围和列值与常数比较。 由于Kudu在硬盘中的数据采用列式存储,所以只需要扫描的列将极大的提高读取性能。
一致性模型
Kudu为用户提供了两种一致性模型,默认的一致性模型是:snapshot consistency。 这种模型保证用户每次读取出来的都是一个可用的快照,但这种一致性模型只能保证单个Client可以看到最新的数据,但不能保证多个Client每次取出的都是最新的数据。
另一种一致性模型是external consistency可以在多个Client之间保证每次取到的都是最新数据,但是Kudu没有提供默认的实现,需要用户做一些额外的工作:
- 在Client之间传播Timestamp Token,在一个Client完成一次写入后,会得到一个TimestampToken,然后这个Client把这个Token传播到其他Client,这样其他的Client就可以通过Token取到最新的数据了,不过这个方式的复杂度很高。
- 通过commit-wait方式,这有类似于Google的Spanner,但是目前基于NTP的commit-wait方式延迟实在有点高,不过Kudu相信,随着Sapanner的出现,未来基于real-time lock的技术会逐渐的成熟。
错误速查
| 症状 | 根因定位 | 修复 |
|---|---|---|
| 写入报 NOT_THE_LEADER/间歇超时 | 访问到非 Leader;选举抖动 | 查看 tserver/master 日志与 ksck;观测选举频率稳定集群心跳与故障域;客户端启用重试与较长 RPC 超时 |
| Clock unsynchronized/时钟拒绝 | NTP/Chrony 未对齐,时钟漂移 | chronyc sources/ntpstat;Master 警告全节点统一时间源;限制最大时钟偏移;容器场景挂载宿主机时钟 |
| Failed to write batch: Timed out/Service unavailable | WAL 盘饱和/网络抖动/写放大 | iostat/sar/WAL 指标;网络丢包将 WAL 上 NVMe;批量写入;限流大扫描;优化副本放置 |
| No tablet covering the requested range | 分区键与数据不匹配;Range 切分不当 | kudu table describe 查看分区纠正分区策略(预切分/Hash+Range);必要时新表重导 |
| 读取吞吐低、CPU 空转 | 小 Tablet 过多,热点被驱逐 | 统计 tablet 数/每 tablet 行数;检查 Block Cache 命中控制分区数量;批量导入后再切分;1.18 评估分段 LRU(实验) |
| Spark 报 Table not found/编码异常 | kudu-spark3 与 Spark/Scala 版本不匹配;HMS 未同步 | 校验 kudu-spark3_2.12 版本与 Spark 3.5;检查 HMS统一到 kudu-spark3_2.12:1.18.0;开启 Kudu-HMS 同步并刷新元数据 |
| Impala 建表失败:要求主键 | Kudu 必须定义主键,无法直接把普通表改为 Kudu 表 | 审核 DDL以主键重建 Kudu 表并 INSERT INTO ... SELECT ... 迁移数据 |
| Not authorized: invalid authn(Kerberos) | 票据过期/Principal 不匹配 | kinit -kt 刷新票据;核对 SPN/realm;确保 SASL/Kerberos 配置一致 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI-调查研究-108-具身智能 机器人模型训练全流程详解:从预训练到强化学习与人类反馈
💻 Java篇持续更新中(长期更新)
Java-154 深入浅出 MongoDB 用Java访问 MongoDB 数据库 从环境搭建到CRUD完整示例 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解