2025年,智能体(AI Agent)已成为人工智能领域最具前瞻性的技术方向与产业焦点。各行各业对企业级 Agent 的研发与应用持续深入,其核心目标在于显著提升业务运营效能与决策智能化水平。在此背景下,火山引擎数智平台推出的 Data Agent(数据智能体),已在多个行业的实践中取得了可验证的成效。
然而,将一个通用的对话工具升级为能够进行精准决策并深度理解业务的专业智能体,面临着系统性挑战。这一转变强烈依赖于高质量数据、深厚的行业知识、结构化的上下文管理以及实时的用户反馈闭环。这些要求对底层数据基础设施的技术能力、灵活性及可靠性提出了全新的、更高的标准。

随着 AI Agent 时代的到来,数据基础设施正在经历一场深刻变革。数据的使用方式已从单一的结构化模态,扩展为多种模态的融合运用,这也带来了不同模态数据之间转换与管理的全新挑战。据 IDC 预测,中国的非结构化数据将呈现爆发式增长,预计未来五年内,数据总量将从51 ZB攀升至129 ZB,其中非结构化数据占比高达80%,年复合增长率预计超过30%至40%,整体规模增长将超过十倍。在此背景下,面向 Agent 的数据基础设施主要面临以下三大核心挑战:
-
数据存储格式的挑战。传统的数据存储格式难以有效满足多模态数据的处理需求。无论是小数据时代普遍使用的 TXT、CSV 格式,还是大数据时代为分析场景设计的 ORC、Parquet 格式,在应对视频、音频、文本等多种模态混合存储时,均显现出局限性。因此,迫切需要一种新的存储范式来适应这一变化。
-
数据计算引擎的挑战。过去的计算引擎(如Spark、Flink)主要围绕 CPU 进行架构设计,并分别成为离线和实时数据处理的标准方案。然而,在 AI 时代,通过 GPU 对数据处理,算力规模和速度要求呈现爆发式增长;因此,亟需新一代能够更好满足 GPU 计算需求的计算引擎。
-
数据管理范式的挑战。传统的数据管理范式同样以结构化数据为核心。非结构化数据通常零散地存储在个人设备或独立目录中,形成了严重的数据孤岛。随着非结构化数据量的急剧增长,构建统一的管理平台、治理工具与手段,并将其与既有的结构化数据体系打通,已成为当前的重要任务。

为应对 AI Agent 时代数据基础设施的上述挑战,火山引擎推出了一系列创新的产品与解决方案。这包括正式发布新一代多模态数据湖解决方案,并对 EMR、ByteHouse、Flink 等核心数据产品进行升级,使其全面具备处理多模态数据的能力。同时,方案引入了专为 AI 场景设计的 Lance 格式作为数据湖的存储基础。
本文将重点探讨火山引擎多模态数据湖解决方案的整体架构与核心技术特性,并分享火山引擎在多模态数据处理和推理框架方面的实践与见解。

火山引擎推出的多模态数据湖解决方案,旨在提供一个从存储、计算到管理的全方位平台。该方案主要由五个核心部分构成:
方案的基石是多模态数据存储层,火山引擎采用 Iceberg 和 Lance 作为核心的数据湖格式。同时,为了兼容各类应用场景,还支持具身智能领域常用的 MCAP 和 LeRobot 格式,以及其他视频、音频、文本等多种文件格式。
在存储层之上,方案构建了训推一体的数据处理平台。该平台覆盖了从数据摄入、分布式处理、离线/在线推理到实时入湖和高性能检索的全链路。同时对 Spark 进行了升级,并集成了 Ray、Daft、Bytehouse 和 Flink 等计算引擎。在模型推理方面,则深度整合了豆包和 Deepseek 等先进模型。
为了简化非结构化数据的处理流程,方案开发了一层丰富的数据处理算子。这些算子旨在通过标准化的操作大幅提升开发效率,让非结构化数据处理更轻松,涵盖了 PDF 内容提取、图片 Embedding、音频人声分离与文字提取、视频关键帧抽取等常用功能。通过这些算子,不同模态数据间的转化与处理变得更加高效。
针对 Agent 时代的数据管理需求,多模态数据湖提供了一套完善的管理工具。这套工具支持对数据版本、数据探查、数据共享进行精细化控制,并提供了针对文本、图片等不同源数据的丰富管理手段。此外,它还围绕 Lance 和 Iceberg 格式,提供了先进的数据湖治理模式。
在最顶层,多模态数据湖方案推出了 Processing Agent。它允许用户通过自然语言轻松调用底层的算子和计算框架,从而极大地降低了非结构化数据处理的门槛,让开发工作更加直观和便捷。

在数据湖存储方面,Agent 时代的数据湖存储呈现出若干与以往显著不同的特征。
多模态数据中不同数据链的大小差异极大,例如视频文件与文本之间的单列存储空间差异可能达到数百甚至数千倍。而早期的格式如 Iceberg 和 ORC 在设计时,底层采用的 Parquet 格式,是基于不同列之间大小差异在几倍到几十倍的假设下进行设计的,尽管它们也采用了列式存储结构,但在面对极不均匀的多模态数据时,仍会面临数据访问和读写过程中的单点查询性能问题,以及数据查询时的读写 IO 瓶颈。
另一个关键问题是,不同模态的数据最好能够通过统一的检索、存储和查询机制进行管理。以往用户在处理多模态数据时,通常将文本和数值型数据以二维表形式存储,而非结构化数据则通过 URL 链接到对象存储或文件存储中的具体地址进行访问。
传统做法存在若干明显弊端:其一,系统架构不够灵活简洁;其二,增加列操作不便,读取原始文件流程繁琐。以过去常用的 WebDataset 格式为例,读取时需对对象存储中的原始文件解压,使用完毕后再重新压缩,导致显著的读写放大问题,严重制约处理效率。随着数据规模持续增长,此类架构复杂、效率低下的问题日益凸显。其三,随机点查性能面临挑战。尽管部分存储方案可将数据置于内存中以提升点查性能,但在数据量极大时扩展性不足,难以满足训练场景下的高并发点查需求。其四,业务对数据 Schema 的灵活性要求日益提高。由于常需为不同场景生成标注信息或调整数据规则,业务迭代频繁,数据评价体系也不断拓展,因而对存储格式的 Schema 扩展能力提出了更高要求。
为解决上述痛点,火山引擎多模态数据湖引入 Lance 作为其存储格式的基础。
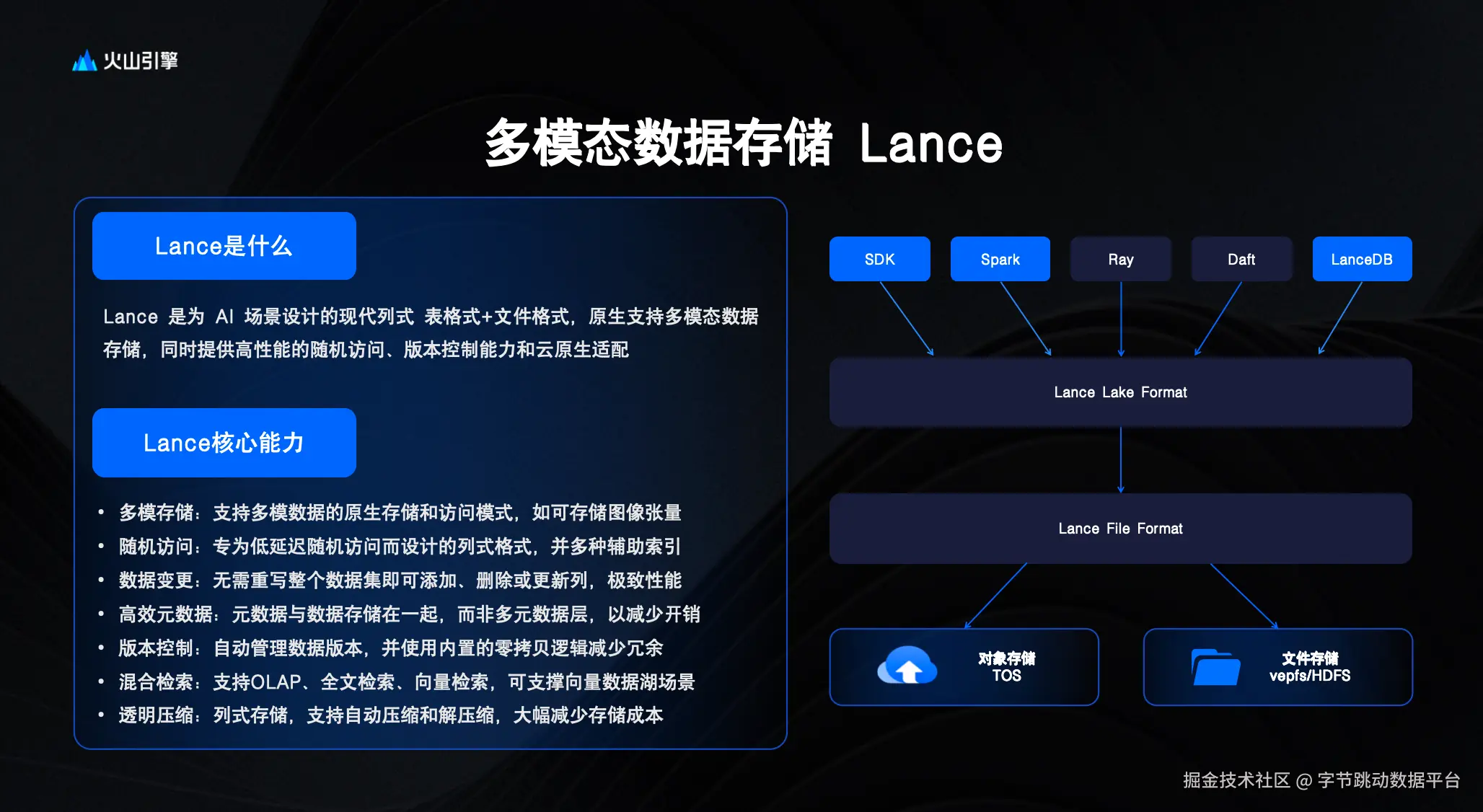
Lance 是一种专为 AI 场景设计的列式表格存储格式,其架构包含两个核心层面:Lance Table Format 与 File Format。在火山引擎的实践中,Lance 格式可部署于对象存储 TOS,同时也支持 HDFS 和 vePFS 文件存储系统。该格式支持数据的冷热分层管理,例如在模型训练阶段将热数据存放于高性能的 vePFS,而冷数据则根据策略沉降至成本更优的 TOS 对象存储,此机制已在大型客户的实际业务中得到应用。
其次,Lance 具备出色的多模态数据存储与高性能随机访问能力,其灵活的加列操作(ADD COLUMN)和良好的Schema 扩展机制,能够高效应对动态标注等场景需求。火山引擎团队已与 Lance 开发方在 Schema 管理方面进行了深度集成,并增强了数据版本控制能力。此外,Lance 还支持多模态混合检索与透明压缩技术;实践案例表明,通过有效的数据压缩,有火山客户的数据存储容量可降低一半以上。

火山引擎多模态数据湖中 Lance 格式的发展,始于2024年初应对客户在多模态数据存储上的迫切需求,特别是在高效点查询与灵活增减列操作方面存在的显著痛点。经过深入的用户调研、技术路径分析以及与多家客户的联合概念验证(PoC),火山引擎于2024年正式推出了支持 Lance 格式的解决方案,并针对对象存储进行了读写性能优化。
至2025年,火山引擎进一步将 Lance 深度集成至其新产品 LAS 中。用户可在 LAS 平台内选择 Lance 作为存储格式,进行多模态数据湖的管理以及AI数据集的构建,该格式尤其擅长支撑超大规模的多模态数据管理场景。同时,Lance 也已成为字节跳动内部模型训练所采用的数据湖存储格式,并积极开展了开源社区的推广工作。
目前,火山引擎多模态数据湖已实现了 Lance 在数据计算、存储、模型训练与推理全链路中的端到端贯通。在实际应用中,用户部署的最大数据规模已达到数十 PB 级别。

在计算层面,多模态数据处理面临着比存储更为复杂的挑战,主要体现在以下四个关键方面:首先,GPU 与 CPU 的协同计算的需求日益凸显。当前,越来越多的批量推理任务,如图像打标、文本 Schema 提取以及数据合成与生成,都依赖于 GPU 完成。这些任务通常需要 GPU 与 CPU 之间紧密协同,形成包含不同处理环节的完整工作流。因此,如何精准感知 GPU 使用率,并实现 GPU 与 CPU 之间的高效资源协同,对于保证整体资源利用率和成本优化至关重要。
其次,数据加载过程中的 CPU 效率瓶颈。在使用 Python 等进行数据读写时,如何高效地加载数据,避免 CPU 出现空闲等待,是计算引擎需要解决的核心问题之一,这直接影响着整个处理流程的效率。
第三,大规模数据 Shuffle 带来的性能挑战。在图文混合重排等常见场景中,处理过程往往涉及大规模的数据交换,这对计算引擎的 Shuffle 能力提出了很高的要求。
第四,多模态数据的联合检索、查询与系统化管理。多模态数据的联合检索与查询是一大挑战。早期许多用户采用自行编写的 Python 脚本进行分布式处理,这在数据规模较小时可行。但随着数据量激增,用户更希望屏蔽复杂的作业执行细节(如处理内存溢出 OOM、作业中断与重试等问题),而只关注最终结果。此外,如何通过模型对数据质量进行有效评判,并将这些多模态数据作为资产系统地管理起来,也成为了普遍需求。
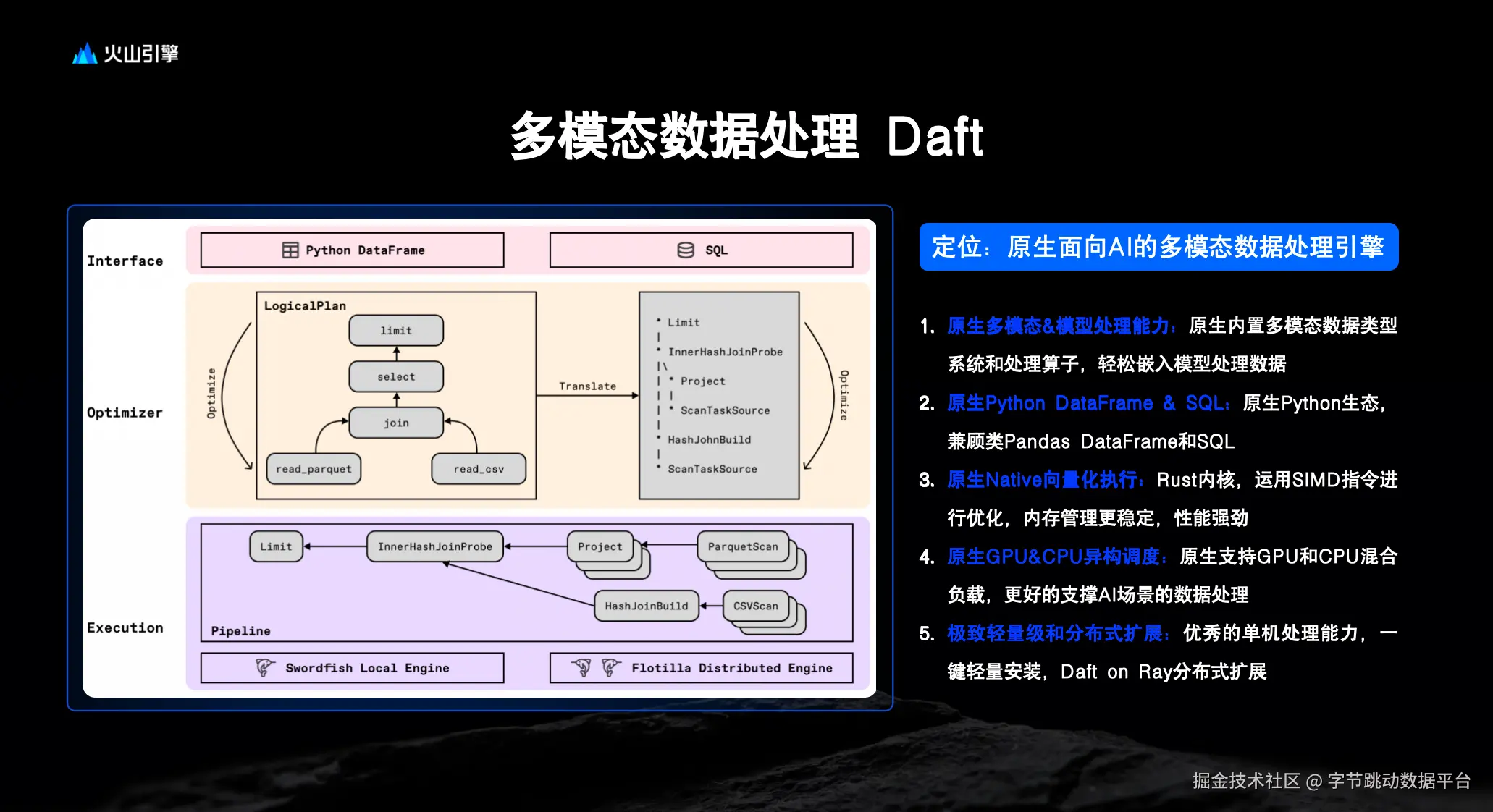
为解决多模态数据在计算层面面临的复杂挑战,火山引擎多模态数据湖引入 Daft 作为核心计算引擎。Daft 具备以下关键特性,使其特别适合 AI 场景下的多模态数据处理:
第一,Daft 具备原生的多模态数据与调用模型能力。其内置多模态数据类型系统及相应处理算子,可便捷地将模型推理嵌入数据处理流程中,实现对图像、文本等非结构化数据的直接操作。
第二,提供原生的 Python DataFrame 与 SQL 双重接口。在延续 Pandas 类 DataFrame 操作习惯的同时,也支持 SQL 查询,兼顾了数据科学家与工程师的使用习惯,便于在 Python 生态中快速集成与开发。
第三,执行层采用 Rust 编写的原生向量化执行引擎。通过运用 SIMD 指令优化计算效率,并在内存管理方面表现稳定,从而提供强劲的数据处理性能。
第四,Daft 支持原生的 GPU 与 CPU 异构资源调度。能够有效协调 GPU 与 CPU 的混合负载,更好地适应 AI 场景下对异构计算资源的调度需求。
第五,系统设计兼具极致轻量性与分布式扩展能力。在具备优秀单机处理性能的基础上,支持一键轻量安装,并可基于 Ray 框架实现无缝的分布式扩展,构成其底层所依赖的 Flotilla 分布式执行引擎。
基于 Daft 的能力,该方案在 LAS 平台上构建了丰富的数据处理算子框架。此框架提供了上百种针对多模态数据的处理算子,其底层实现深度集成了 Daft,从而实现了 Daft 计算引擎与火山引擎生态系统的有效融合。

在开源生态建设方面,火山引擎在项目早期阶段便持续投入,包括提升作业 Checkpoint 与容错能力、优化模型调用支持、实现资源弹性调度等,并将这些改进成果回馈至开源社区。同时,团队也对 SQL 性能与功能进行了优化,增强了对智能驾驶、具身智能等多种专用数据源的接入能力,并实现了与 LAS Catalog 的深度集成。
以上内容系统性地分享了 Lance 与 Daft 两项前沿技术栈的核心特性,以及其在火山引擎多模态数据湖方案中的实践历程与思考。火山引擎诚挚邀请大家体验多模态数据湖解决方案及数据中台系列引擎产品。