Agentic AI 不只是一个概念;它是你可以构建、可以看到、也可以与之交互的东西。本章我们将从理论走向行动。如果你曾花几个小时复制粘贴 Nmap 输出,或手工给子域名做分流(triage),你一定知道那种"磨人"的重复劳动。从这里开始,我们要把这种痛点自动化掉。
我们将使用 n8n------一个开源、no-code 的工作流自动化平台,它擅长连接 API、处理逻辑,并作为智能体的编排层(orchestration layer)。我选择 n8n 而不是几十个替代方案的原因很简单:它在显著降低自动化门槛的同时,底层仍然具备相当硬核的能力。
我们将一步一步走完以下内容:
- 在你自己的机器或服务器上安全地安装与配置 n8n
- 将其连接到 OpenAI 或 HuggingFace 等 AI 服务
- 构建一个可用的侦察(recon)智能体:收集子域名、查询端口,甚至用 LLM 总结发现
- 为你的 bot 增强检索增强生成(RAG)能力,让智能体能从外部数据拉取上下文并做出更好决策
- 加固你的工作流,避免常见错误,例如 API key 泄露或逻辑炸弹(logic bombs)
你会看到 n8n 里的每一个节点(node)如何像智能体的一个决策点。它们不只是搬运数据;它们代表了定义 agentic AI 的逻辑、记忆与适应性。如果你写过那种嵌套了一堆 if-else、遇到一点意外情况就崩的脚本------这就是解药。这些节点无需你盯着每一个边界情况就能做决策、做适配并恢复。更重要的是,它们让你可以快速原型化、以极低摩擦迭代,并在不需要后端开发随时待命的情况下构建复杂工作流。
到本章结束时,你将跑起你的第一个面向安全的 AI 工作流:它能够执行侦察、总结数据,并以传统工具做不到的方式对输入做出适配。这不会是一个被动仪表盘,而会是一个"活的"、会推理的自动化智能体。
技术要求(Technical requirement)
要跟随本章示例,你需要具备以下条件:
- 操作系统: Windows 10/11、macOS 或 Linux(推荐 Ubuntu 20.04+)
- Node.js: 18 或更高版本
- Docker: 20.10 或更高版本(用于选项 2 安装)
- 内存: 至少 4 GB,推荐 8 GB
- 磁盘空间: n8n 及依赖需要 2 GB
- 网络: 用于 API 集成的互联网访问(OpenAI、Shodan 等)
- OpenAI API key(或兼容的 LLM 提供方)
为 agentic 工作流设置 n8n(Setting up n8n for agentic workflows)
本节将带你完成三个关键部分:
- 安装与配置 n8n
- 为智能体运行建立安全环境
- 以 agentic 视角理解 n8n 界面
安装选项(Installation options)
你可以用三种常见方式运行 n8n:
选项 1 ------ 本地安装(用于测试)(Option 1 -- Local installation (for testing))
这是本地快速测试的最快方式。启动后,n8n 会在 http://localhost:5678 提供服务:
npm install n8n -g
n8n选项 2 ------ Docker(推荐用于生产)(Option 2 -- Docker (recommended for production))
该选项使用 Docker 在隔离环境中运行 n8n,更适合生产使用:
bash
docker run -it --rm \
-p 5678:5678 \
-v ~/.n8n:/home/node/.n8n \
-e N8N_BASIC_AUTH_USER=admin \
-e N8N_BASIC_AUTH_PASSWORD=strongpassword \
n8nio/n8n出于本书目的,我们将使用选项 2,因为它为跟随示例与构建 agentic 工作流提供了最快、最简单的起步方式。
选项 3 ------ 可直接上手的构建环境(starter environment)(Option 3 -- Build-ready setup (starter environment))
为加速学习,这里提供一个 GitHub starter 仓库,包含:
- Docker Compose 配置
- 预配置的环境文件模板
- 一个基础 recon 工作流作为起点
要获取最新说明、官方部署指南与节点文档,请参考官方仓库:https://github.com/n8n-io/n8n。该仓库包含完整安装指南、示例工作流、支持的集成,以及能帮助你超越本书内容的社区扩展。
在继续之前,需要澄清安装选项与后续小节的关系。本节剩余部分我们将按选项 2(Docker) 推进。把 n8n 跑在隔离的 Docker 环境中,可以让配置与操作系统无关,并把所有所需组件打包进一个可复现的容器里。这也让我们更容易加入后续 agentic 工作流所需的额外依赖,统一由同一个 Docker Compose 环境管理。
为安全工作流构建自定义 Docker 镜像(Building a custom Docker image for security workflows)
这个自定义 Dockerfile 基于官方 n8nio/n8n:nightly 基础镜像构建。nightly build 是 n8n 更新最频繁的版本,确保容器包含最新功能、安全补丁与工作流引擎改进。就本书而言,nightly 镜像提供了一个稳定基础,能支撑所有 agentic 自动化,而无需额外手动更新。这个 Dockerfile 不会修改 n8n 本身;我们只是扩展基础镜像以加入安全工作流所需的额外工具。
创建一个名为 Dockerfile 的文件,并按下述内容定义,用所需依赖扩展官方 n8n 镜像:
bash
FROM n8nio/n8n:nightly
# Switch to root to install system packages
USER root
RUN apk update && apk add --no-cache \
python3 \
py3-pip \
py3-virtualenv \
gcc \
musl-dev \
libffi-dev \
openssl-dev
RUN python3 -m venv /opt/venv && \
/opt/venv/bin/pip install --upgrade pip && \
/opt/venv/bin/pip install \
pymongo \
requests
ENV PATH="/opt/venv/bin:$PATH"
RUN mkdir -p /home/node/.cache && chown -R node:node /home/node/.cache
USER node这个 Dockerfile 安装了若干 n8n 默认不包含的组件。由于后续章节会依赖 Python 脚本、外部 API 自动化、MongoDB 交互以及自定义 recon 逻辑,容器需要额外的系统包与 Python 库来支持这些能力。该镜像安装了 Python、pip、virtualenv、常见构建依赖(gcc、musl-dev、openssl-dev),以及 pymongo 与 requests 两个 Python 包。这些扩展让 n8n 工作流可以在同一个容器里执行 Python 代码、与数据库通信,并运行更高级的 agentic 任务。通过提前准备这些依赖,我们得到一个自包含环境:后续所有工作流都能一致运行,而无需宿主机上再装任何工具。
使用 Docker Compose 运行整套环境(Running it all with Docker Compose)
为了让 n8n 部署具备持久性并更接近生产可用,下面是我使用的 docker-compose.yml 配置:
ini
version: "3.7"
services:
n8n:
build:
context: .
dockerfile: Dockerfile
restart: always
ports:
- "5678:5678"
environment:
- N8N_HOST=n8n.cyprox.io
- N8N_PORT=5678
- N8N_PROTOCOL=https
- LANG=en_US.UTF-8
- LC_ALL=en_US.UTF-8
- NODE_ENV=production
- WEBHOOK_URL=https://n8n.cyprox.io/
- DB_TYPE=postgresdb
- DB_POSTGRESDB_HOST=${DB_HOST}
- DB_POSTGRESDB_PORT=${DB_PORT}
- DB_POSTGRESDB_DATABASE=${DB_NAME}
- DB_POSTGRESDB_USER=${DB_USER}
- DB_POSTGRESDB_PASSWORD=${DB_PASSWORD}
volumes:
- n8n_data:/home/node/.n8n
- n8n_cache:/home/node/.cache
- /local-files:/files
- /local-files:/home/node/
postgres:
image: postgres:13
restart: always
environment:
- POSTGRES_USER=${DB_USER}
- POSTGRES_PASSWORD=${DB_PASSWORD}
- POSTGRES_DB=${DB_NAME}
volumes:
- postgres_data:/var/lib/postgresql/data
ports:
- "${DB_PORT}:${DB_PORT}"
volumes:
n8n_data:
external: true
postgres_data:
external: true
n8n_cache:
external: false这个 docker-compose.yml 定义了一个生产就绪的 n8n 环境:通过两个核心容器与持久化 volume 的组合来支持 agentic 工作流。我们拆解一下:
-
n8n(主应用容器): 这是你的自动化工作流运行的主服务。它使用自定义镜像(由本地 Dockerfile 构建),在官方
n8nio/n8n:nightly上扩展了 Python、pymongo、requests 等工具。它们让你可以:- 在 n8n 工作流中执行自定义 Python 脚本
- 连接威胁情报数据库(例如 MongoDB)
- 用原生 Python 能力执行 API 调用
关键环境变量包括:
- N8N_HOST / N8N_PROTOCOL / N8N_PORT: 定义 n8n UI 与 webhook 端点如何对外暴露(例如
https://n8n.cyprox.io) - WEBHOOK_URL: 用于正确处理外部回调或集成
- 连接 PostgreSQL 的数据库凭据
-
postgres(数据库容器): 运行 PostgreSQL 13,n8n 用它存储:
- 工作流定义
- 执行日志
- 凭据(加密)
- 用户设置
将 PostgreSQL 作为独立服务运行可确保数据持久:即使 n8n 容器被重建或更新,数据也不会丢失。
用于持久化的重要 volumes:
- n8n_data: 存储 n8n 的内部状态,如工作流、凭据与日志。标记为 external,假设它已预先创建(例如
docker volume create n8n_data)。 - n8n_cache: 缓存用途,例如临时文件或 LLM 响应。该 volume 仅在本 stack 内部使用。
- /local-files:/files 与 /local-files:/home/node/ :用于导入/导出本地文件的 bind mount。对调试、日志、模型文件或宿主机与容器间共享数据很有用。
- postgres_data: 持久化 PostgreSQL 数据,同样标记为 external,以提高安全与稳定性。
在浏览器中访问 n8n(Accessing n8n in your browser)
容器启动并运行后,你可以通过环境变量中定义的 URL 访问 n8n 界面:
https://n8n.cyprox.io
该 URL 对应 docker-compose.yml 中的 N8N_HOST、N8N_PORT 与 N8N_PROTOCOL 设置。确保你的 DNS 配置正确,域名指向服务器的公网 IP。如果你在本地部署或使用反向代理,请确认 SSL 配置正确,以避免连接问题。
如果配置无误,在浏览器打开该 URL 会进入 n8n dashboard,它是你构建与管理 agentic AI 工作流的中心工作区。从这里你可以创建节点、导入模板,并把 AI 驱动的安全自动化工作流连起来。
当容器启动、服务可用后,访问配置的 URL 应该会展示如图所示的 n8n dashboard:
图 3.1 ------ n8n dashboard(Figure 3.1 -- n8n dashboard)
在继续之前,我们回顾一下当前进度。此时 n8n 环境已经完全可用:Dockerized stack 正在运行,自定义镜像已构建完成,并且可以在浏览器中访问 n8n dashboard。有了平台基础,我们现在可以开始集成驱动 agentic 工作流的外部服务。
下一步是把 n8n 连接到 OpenAI 与威胁情报 API,让我们的智能体能够在自动化工作流中进行推理、做数据富集,并作出有依据的决策。
连接 OpenAI 与威胁情报 API(Connecting OpenAI and threat intelligence APIs)
现在你的 n8n 实例已经跑起来了,是时候给它装上"大脑"了。本节我们会把它接到 OpenAI 的 GPT 模型,以及 Shodan、VirusTotal、Censys 等威胁情报平台。
这些连接会把静态自动化变成动态决策。你不再只是把数据在工具之间传来传去;你是在让你的智能体能够实时思考、推理,并进行上下文富集。
我们将覆盖:
- 如何在 n8n 中安全存储情报供应商的 API 凭据
- 如何使用原生节点或 HTTP Request 节点调用威胁情报 API
- 当把 LLM 输出与威胁情报数据结合时,如何结构化 prompt 输入
- 使用 AbuseIPDB、VirusTotal、GreyNoise、OTX 与 urlscan.io 等 API 的上手富集工作流
在开始集成威胁情报 API 之前,我们需要先配置 AI Agent 节点用于推理的 LLM 提供方。下图展示了 n8n 支持的聊天模型选项:
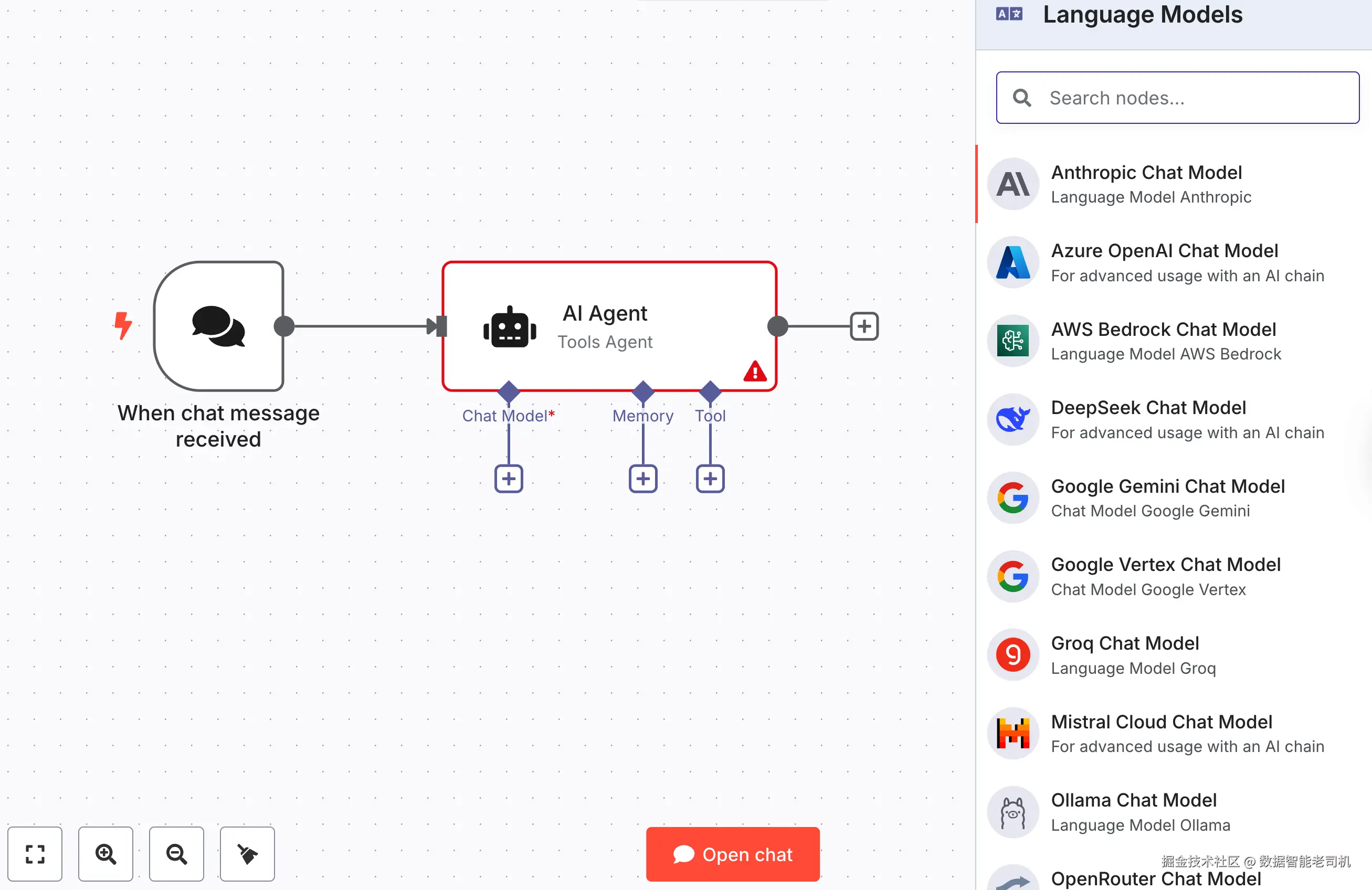
图 3.2 ------ n8n 中 AI Agent 节点可用的语言模型(Figure 3.2 -- Available language models for the AI Agent node in n8n)
n8n 目前支持范围广泛的 LLM 提供方,前面的截图展示了写作时可用的全部聊天模型。尽管本书所有工作流示例主要使用 OpenAI 的 GPT 模型,但你也可以选择任何受支持的提供方作为 AI Agent 节点的 Chat Model 输入。下面的列表简要总结了主要提供方及其特点。
下面是在 n8n 中目前可用的其他 LLM:
-
Anthropic Chat Model(Claude):
- 模型:Claude 3 Opus、Sonnet、Haiku
- 优势:长上下文推理(100K+ tokens)、更安全的对齐、多轮理解
- 用例:合规安全的响应、深度日志总结
-
Azure OpenAI Chat Model:
- 模型:通过 Azure 提供 GPT-3.5、GPT-4
- 优势:托管在 Azure;适用于有区域或监管托管要求的企业
- 用例:在受 Microsoft 监管的云环境中使用 OpenAI 能力
-
AWS Bedrock Chat Model:
- 模型:Claude、Mistral、Amazon Titan(通过 Bedrock)
- 优势:与 AWS 生态集成;适合已用 Bedrock 做 GenAI 的团队
- 用例:由 AWS 事件触发的智能体、分析云端威胁数据
-
DeepSeek Chat Model:
- 模型:DeepSeek-VL(视觉语言)、DeepSeek-LLM
- 优势:新兴开放模型,多任务表现强
- 用例:实验性智能体流水线、视觉-语言混合分析
-
Google Gemini Chat Model:
- 模型:Gemini 1.5 Pro(此前为 Bard)
- 优势:快、低延迟;擅长结构化数据与摘要
- 用例:安全 FAQ bot、漏洞总结、告警摘要
-
Google Vertex Chat Model:
- 模型:通过 Vertex AI 的 Gemini Pro
- 优势:运行在 Google Cloud;支持 prompt tuning 与托管端点
- 用例:已部署 Vertex AI 的企业场景
-
Groq Chat Model:
- 模型:Groq 超高速推理芯片托管的 LLaMA-2
- 优势:速度极快,适合低延迟自动化
- 用例:实时智能体决策(例如告警分类或 triage)
-
Mistral Cloud Chat Model:
- 模型:Mistral-7B、Mixtral(Mixture-of-Experts)
- 优势:开源;在许多任务上可与 GPT-3.5 竞争
- 用例:轻量推理、隔离环境部署、PoC 推理
-
Ollama Chat Model:
- 模型:LLaMA2、Mistral、Phi-2 等(本地运行)
- 优势:适合离线或自托管(笔记本或服务器)
- 用例:隐私优先自动化、断网红队工具链
-
OpenRouter Chat Model:
- 模型:多 LLM 的统一网关(GPT-4、Claude、Mixtral 等)
- 优势:用一个 API key 把 prompt 路由到不同提供方
- 用例:智能体 AB 测试、fallback 逻辑、模型对比
-
xAI Grok Chat Model:
- 模型:Grok(xAI / Elon Musk 团队)
- 优势:仍在成熟中,但对实验性智能体有趣
- 用例:暂不推荐用于生产,但可在兴趣项目中尝试
-
OpenAI Chat Model:
- 模型:GPT-4、GPT-3.5、GPT-4-turbo
- 优势:SOTA 性能与庞大生态支持
- 用例:几乎所有涉及总结、推理、triage、分类、PoC 解释的场景
在 n8n 中使用任何 LLM 之前,我们首先要配置 OpenAI 凭据。下图展示了在 n8n 里添加与测试 OpenAI API key 的位置:
图 3.3 ------ n8n 中的 OpenAI 凭据界面(Figure 3.3 -- The OpenAI credential screen in n8n)
我将使用 OpenAI 的 GPT 模型作为 AI Agent 工作流的主语言模型。OpenAI 的 API 稳定、文档完善、行业采用广泛,因此它是进攻性安全自动化的一个务实起点。当然,n8n 也支持 Claude、Gemini、Mistral、Groq 等多种 LLM,你可以基于用例、隐私要求或区域约束自由探索或替换。你甚至可以构建混合方案:不同智能体用不同模型,取决于任务的复杂度或性质。
连接 OpenAI 很简单:用你的 API key 创建一个 credential 条目(如前图所示)。可选地,如果你属于 OpenAI 组织账号,可以填写 Org ID,但对个人或单租户账号并非必需。Base URL 是 https://api.openai.com/v1,n8n 会在幕后用它路由所有模型交互。
一旦 OpenAI API key 配置并验证成功(如前例所示),AI Agent 节点就能在任何工作流中查询 GPT 模型:无论是总结端口扫描结果、生成 payload 逻辑,还是响应具备上下文意识的漏洞提示。
威胁情报 API(Threat intelligence APIs)
除了用 LLM 做推理与总结之外,agentic 工作流最强的能力之一,是它能从外部源拉取实时情报。作为安全从业者,我们每天都在依赖威胁 feed:验证一个 IP、富集可疑域名,或识别恶意软件分发基础设施。本节我们会把 n8n 接到多个广泛使用的公共威胁情报 API,包括 AbuseIPDB、VirusTotal、GreyNoise、OTX(AlienVault)与 urlscan.io。
这些服务各自提供不同视角。AbuseIPDB 与 VirusTotal 像是给任何可疑对象做"背景调查":你贴一个 IP、hash 或域名,它们会告诉你是否有"犯罪记录"。GreyNoise 与 urlscan.io 更偏行为情报:关注一个 IP 在互联网上的行为,或一个 URL 在沙箱浏览器里如何执行。OTX(AlienVault)则高度社区驱动,汇聚全球成千上万研究者贡献的妥协指标(IOC)。好消息是,这些平台通常都提供 rate limit 充裕的免费层,非常适合原型化富集工作流。注册通常只需几分钟,有了 API key 后,你就可以在 n8n 中用 HTTP Request 节点发请求,或通过自定义变量配置凭据。
开始之前你需要准备:
- AbuseIPDB: 在
https://www.abuseipdb.com/创建免费账号,并在 dashboard 生成 API key - VirusTotal: 在
https://www.virustotal.com/gui/home/upload注册,进入 profile | API key,复制你的个人 key(免费用户约 500 次/天) - GreyNoise: 访问
https://www.greynoise.io/,创建免费 Community 账号,并使用 Community API endpoint 的 API key - OTX(AlienVault): 在
https://otx.alienvault.com/注册,然后到 settings 页面找到 API key - urlscan.io: 访问
https://urlscan.io/,创建账号,并从用户 profile 获取 API key
拿到 API key 之后,n8n 集成会很简单。你可以用 HTTP Header 或 Query Parameter 字段把 key 注入请求;也可以把它们作为环境变量复用;或者通过 Credentials Manager 进行安全管理。
在接下来的小节里,我们会介绍几种常用威胁情报 API,并展示如何在 n8n 中把它们作为富集工作流的一部分进行查询。
第 1 步 ------ 使用 AbuseIPDB 做 IP 信誉分析(Step 1 -- Using AbuseIPDB for IP reputation analysis)
为开始我们的富集工作流,我们先从 AbuseIPDB 入手,构建一个简单的"两节点"配置,为任意 IP 地址获取信誉数据。
AbuseIPDB 是一个由社区驱动的恶意 IP 数据库。它是检查某个 IP 是否被报告为恶意行为的最简单、也最有效的服务之一。它基于垃圾邮件、分布式拒绝服务(DDoS)、暴力破解等报告给出信誉评分。
我们将在 n8n 中构建一个两节点工作流:
- 自定义 HTML 表单节点: n8n 出乎意料地容易用内嵌 HTML 表单收集用户输入。本例中我们让用户输入 IP 地址或域名。该输入稍后会作为变量传入 API 请求。
- HTTP Request 节点: 该节点向 AbuseIPDB API 发送 GET 请求。我们将用户提交的 IP 作为 query parameter 传入。关键点在于使用 n8n 的表达式编辑器,它允许我们动态引用表单输入并把它放进请求里。这里 n8n 的表达式语法真的很强:它让你把上一个节点的数据内联插入,不用写一行 JavaScript。
把这两个节点串起来,我们就得到了一个轻量的富集微服务:用户输入 IP → 智能体发给 AbuseIPDB → 结果(该 IP 是否被报告为滥用)可以被记录、可视化,甚至传给决策节点。
下图展示了该工作流:HTML 表单节点连接到 HTTP Request 节点,把 IP 地址发送给 AbuseIPDB:
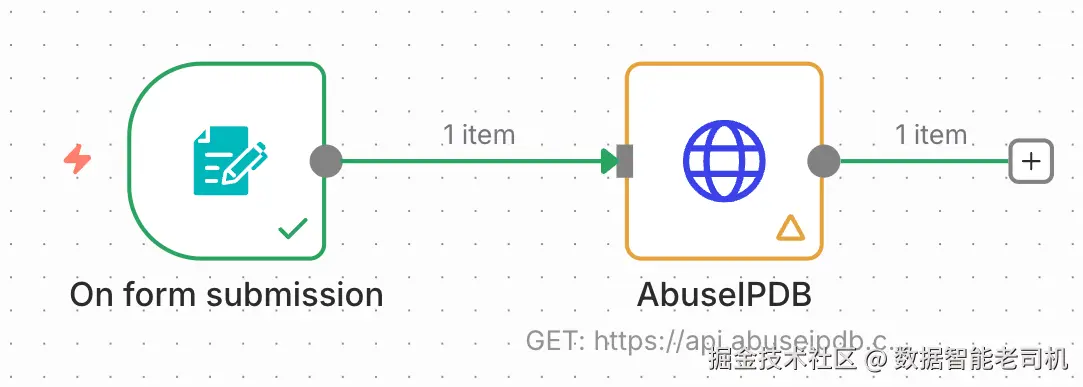
图 3.4 ------ AbuseIPDB 工作流(Figure 3.4 -- AbuseIPDB workflow)
在下面的截图中,你可以看到我们已完成的 HTTP Request 节点:它使用用户提交的 IP 地址向 AbuseIPDB 发起查询:
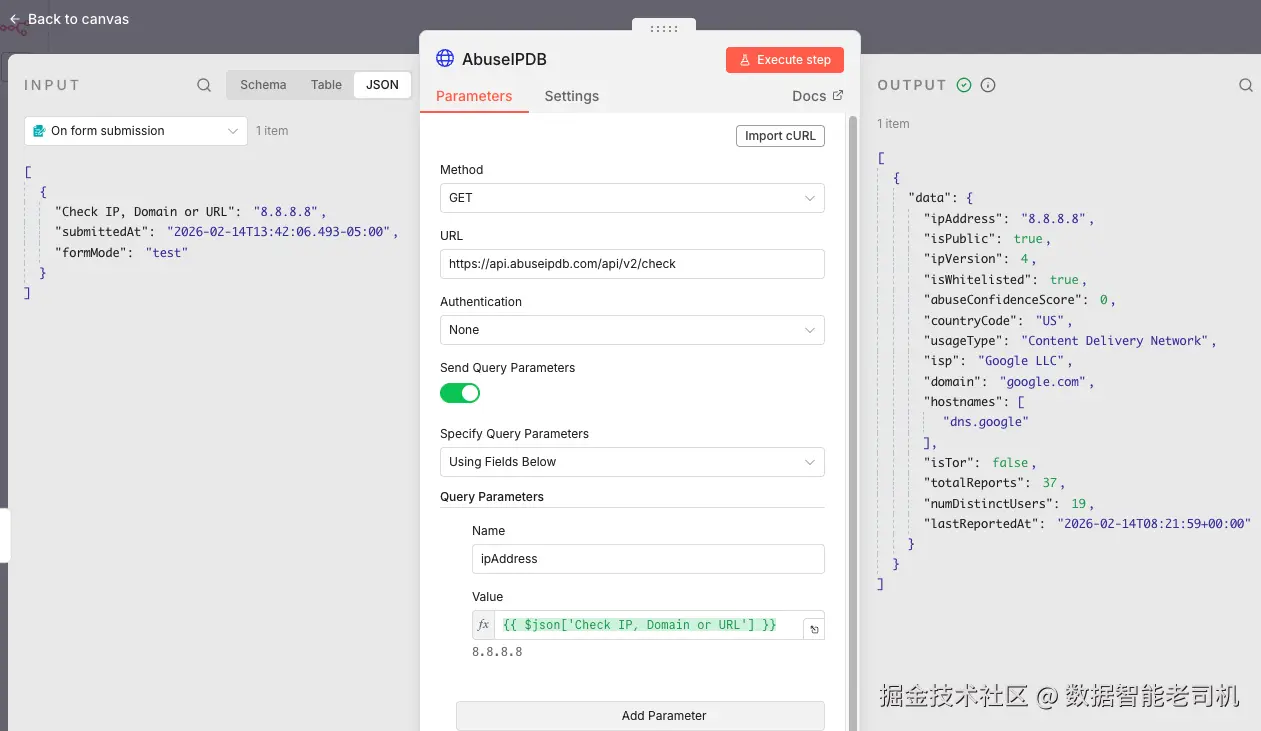
图 3.5 ------ AbuseIPDB HTTP Request 节点(Figure 3.5 -- AbuseIPDB HTTP Request node)
请特别注意 Value 字段下使用的表达式:
{{ $json["Check IP or Domain"] }}
这个动态语法就是 n8n 把前序节点的数据注入请求的方式。本例中,它从 HTML 表单里取出用户输入的 IP 或域名,并将其作为名为 ipAddress 的 query parameter 传给 API。
我们也在 headers 区域安全地加入了 API key,并设置了正确的 Accept 类型。
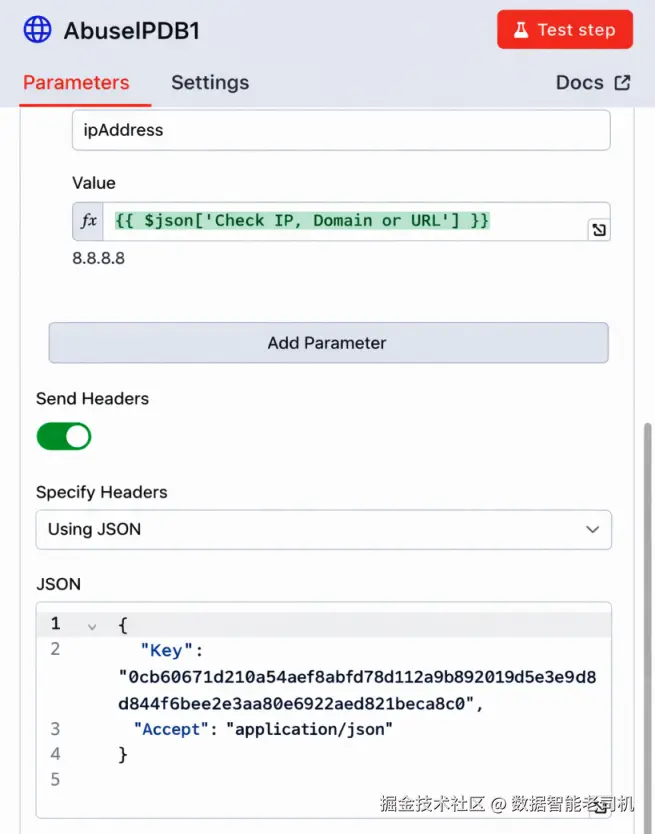
图 3.6 ------ AbuseIPDB API keys(Figure 3.6 -- AbuseIPDB API keys)
在本次测试中,我们提交了 IP 地址 8.8.8.8。如右侧所示,API 返回了一个信息丰富的 JSON payload,包含 abuseConfidenceScore、usageType、isp、countryCode,以及该 IP 最后一次被报告的时间戳等字段。
如果你觉得这些数据看起来有点"信息量爆炸",别担心;我们很快会构建 AI 驱动的智能体来帮你分析并解释这些结果。在后续章节里,你会用 LLM 把 raw JSON 变成可解释的洞察。这只是开始。
第 2 步 ------ 查询 VirusTotal 以获得更多上下文(Step 2 -- Querying VirusTotal for additional context)
接下来我们引入 VirusTotal。它可能是最知名的多引擎恶意软件分析与 URL/文件扫描平台之一。在这段工作流里,我们会把 IP、域名或 URL 发送给 VirusTotal,并取回检测计数、已知关联关系与关联基础设施等上下文数据。和 AbuseIPDB 一样,我们在 n8n 中用 HTTP Request 节点连接 VirusTotal API。
流程几乎相同:把 observable(例如 IP)作为 API 调用的 path parameter 传入,并在自定义 header 中包含 API key。无论你在排查恶意软件分发、钓鱼 URL,还是识别与恶意活动相关的基础设施,VirusTotal 都能提供一层扎实的富集。
下面的截图展示了 VirusTotal dashboard,你可以在这里获取 API key 并查看使用限制:
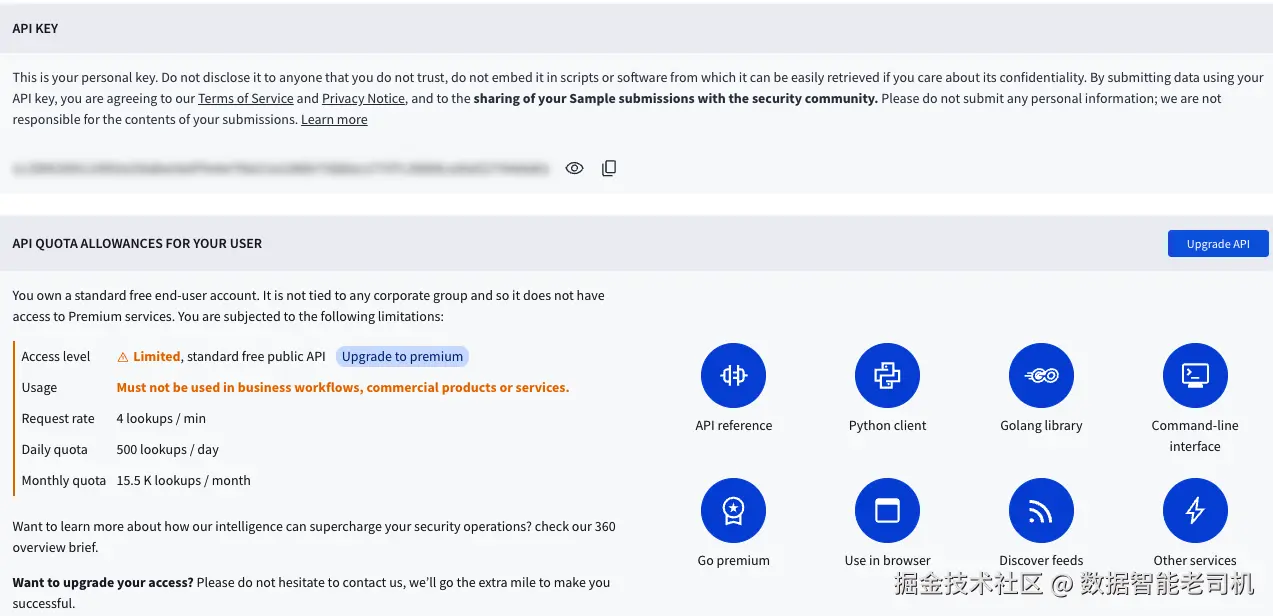
图 3.7 ------ Virustotal API key(Figure 3.7 -- Virustotal API key)
下图展示了我们在 n8n 中与 VirusTotal API 交互的整体工作流。它沿用了前面建立的模式:一个表单节点收集用户输入,随后一个 HTTP Request 节点把输入提交给 VirusTotal 做富集:
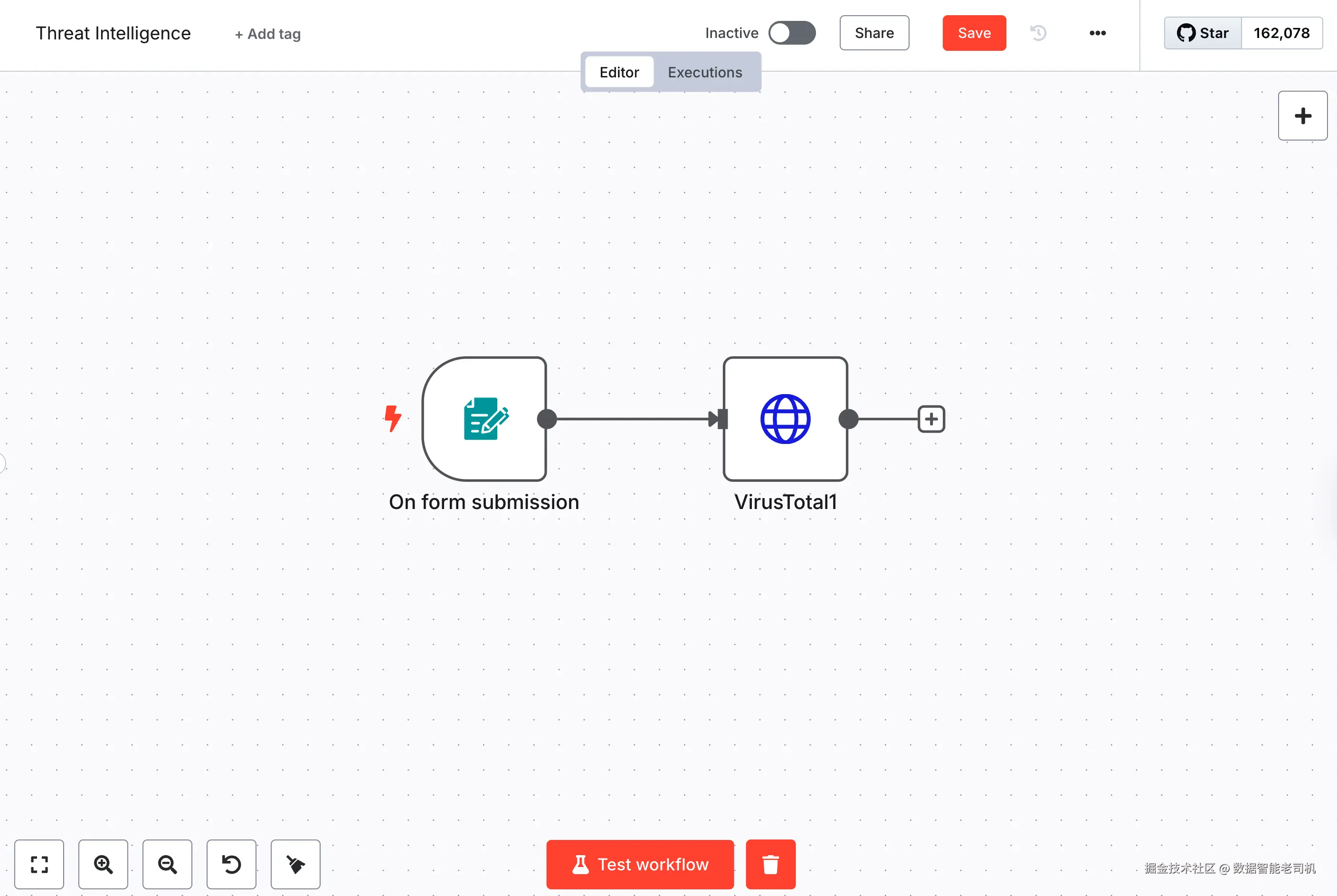
图 3.8 ------ VirusTotal 工作流(Figure 3.8 -- VirusTotal workflow)
在这个工作流中,表单节点是用户提交 observables 的入口。如截图所示,该节点提供了一个简单界面,接收用户的单个文本字段:
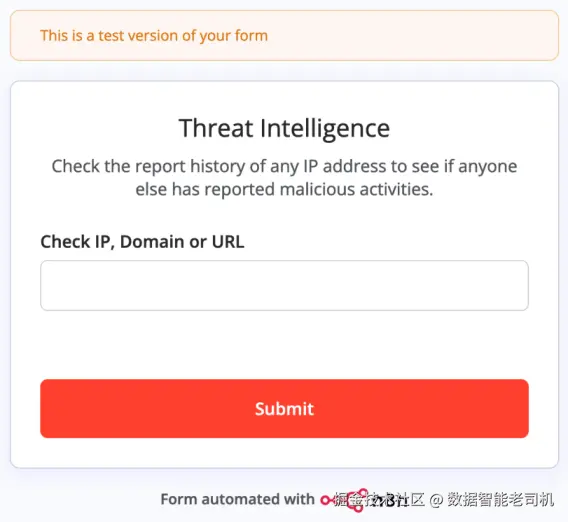
图 3.9 ------ 威胁情报表单(Figure 3.9 -- Threat Intelligence form)
展开表单节点后可以看到,它只包含一个表单元素:一个文本输入框,标签为 Check IP, Domain or URL。用户在这里输入要分析的 observable。保存后,n8n 会把该表单暴露在一个唯一 URL 上,你可以在节点配置面板中看到该 URL(见图 3.9)。通过该 URL 提交的任何值都会流入工作流下一个节点:
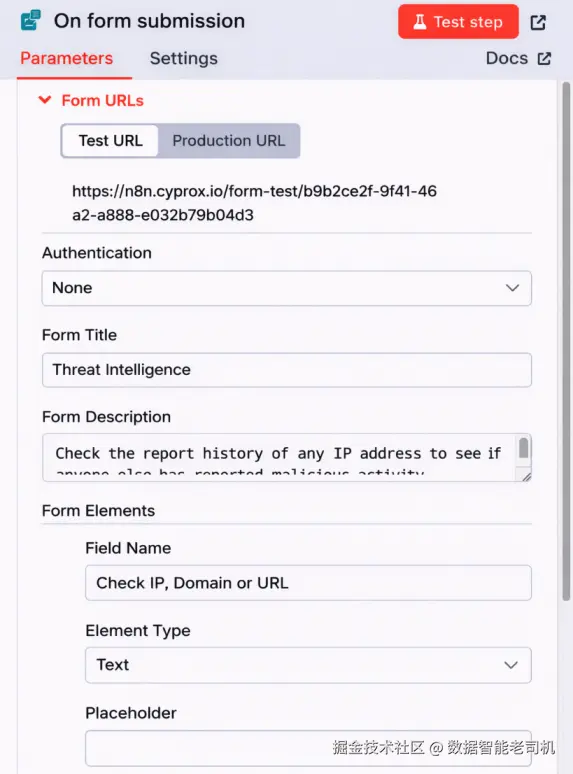
图 3.10 ------ 威胁情报表单配置(Figure 3.10 -- Threat Intelligence form configuration)
当用户通过表单提交 IP 地址后,n8n 会把它转发给 HTTP Request 节点,随后查询 VirusTotal API。对应截图展示了 VirusTotal 返回的 raw JSON 输出,包含检测计数、信誉属性、关联基础设施,以及与所提供 IP 地址相关的其他上下文指标。
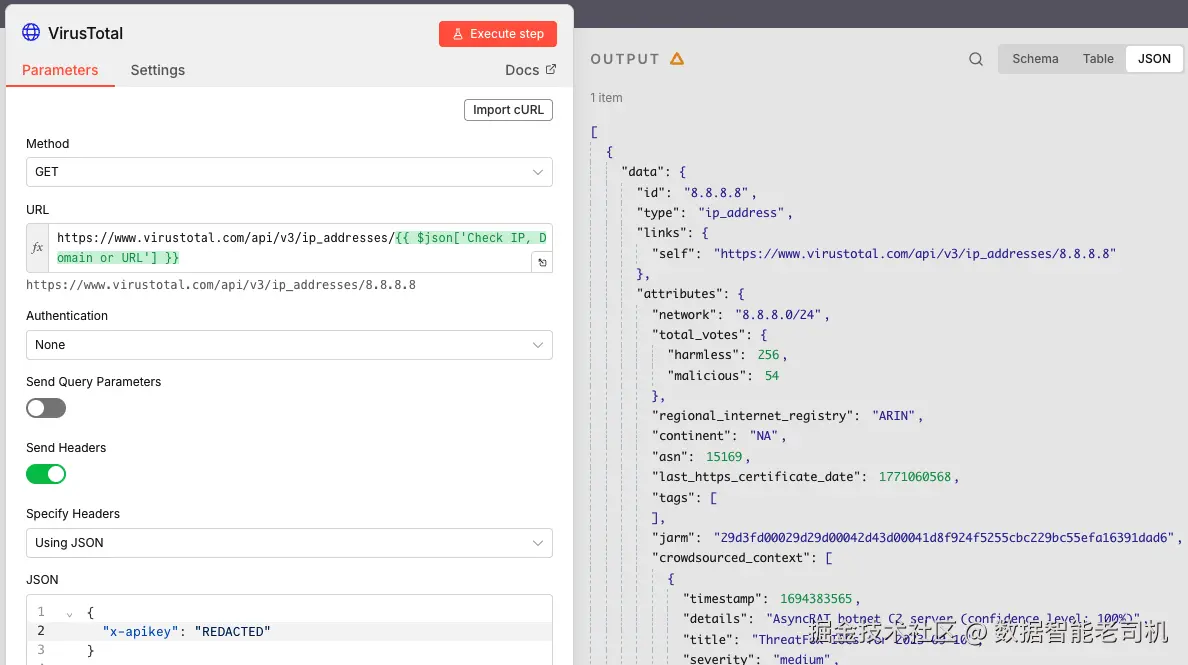
图 3.11 ------ VirusTotal API usage(Figure 3.11 -- VirusTotal API usage)
注意 URL 字段如何用表达式把表单输入动态插入:
https://www.virustotal.com/api/v3/ip_addresses/{{ $json["Check IP or Domain"] }}
{{ $json["Check IP or Domain"] }}
该表达式从上一个节点提取用户提交值,并将其拼接到 VirusTotal endpoint,从而动态构造请求 URL。正如 VirusTotal1 节点所示,n8n 会在运行时对表达式求值,让工作流对任意输入保持灵活可复用,无需手动修改节点配置。
在 VirusTotal1 节点里,HTTP Request 节点启用了 Send Headers 选项,这使我们能够为外发 API 调用附加自定义 headers。由于 VirusTotal 通过 x-apikey header 认证,我们在这里提供 API key,从而确保请求被接受,即使使用免费层。右侧你可以看到 8.8.8.8 的 JSON 响应,包含以下属性:
reputation:VirusTotal 基于聚合信号给出的评分- 国家、地区与注册机构信息
- 关于该 IP 分配与归属的 RDAP 数据
这种富集为你的工作流提供了更深一层上下文。虽然 raw JSON 现在看起来可能很"技术",但别担心,我们很快会用 LLM 来解释这些响应并生成可读摘要、建议,甚至自动 triage 决策。把它理解成:给你的智能体喂情报,让它有东西可以推理。
第 3 步 ------ 用 GreyNoise 过滤互联网噪声(Step 3 -- Filtering internet noise with GreyNoise)
现在我们引入 GreyNoise------一个独特的威胁情报提供方,用于区分互联网中的信号与噪声。VirusTotal 这类平台关注"某个 IP 是否恶意",GreyNoise 则从另一个角度切入:它告诉你一个 IP 是否属于互联网范围的大规模扫描或背景噪声(background noise)。这在你做告警分流或分析外部威胁时是一个关键区分点。
GreyNoise 在进攻工作流里也很有用,尤其是在你对外部基础设施做画像(profiling)时。例如,你在映射攻击面时发现一个暴露 IP,知道它是经常被全网扫描的噪声来源,还是正被用于恶意流量,可以帮助你确定优先级。
下图展示了 GreyNoise dashboard:你可以在集成 Community API 进 n8n 工作流之前获取 API key 并查看可用访问层级:
图 3.12 ------ GreyNoise dashboard(Figure 3.12 -- GreyNoise dashboard)
在这段工作流中,我们仍用 n8n 的 HTTP Request 节点。我们把用户提交 IP 传入 GreyNoise Community API,并接收一个信息丰富的 JSON 响应,指示:
- 该 IP 是否为 noise(被观测到的大规模扫描)
- IP 的分类(benign、malicious 或 unknown)
- 诸如操作系统、user agent、已知工具等元数据
没错,你猜对了:我们稍后会用 LLM 来解释这些元数据。但首先,我们先把 GreyNoise API 接起来,像资深分析师一样去富集输入。
如下图所示,我们配置了一个 HTTP Request 节点与 GreyNoise Community API 交互。目标是理解通过同一个 HTML 表单提交的 IP 地址,究竟被分类为 malicious、benign,还是只是互联网背景噪声的一部分:
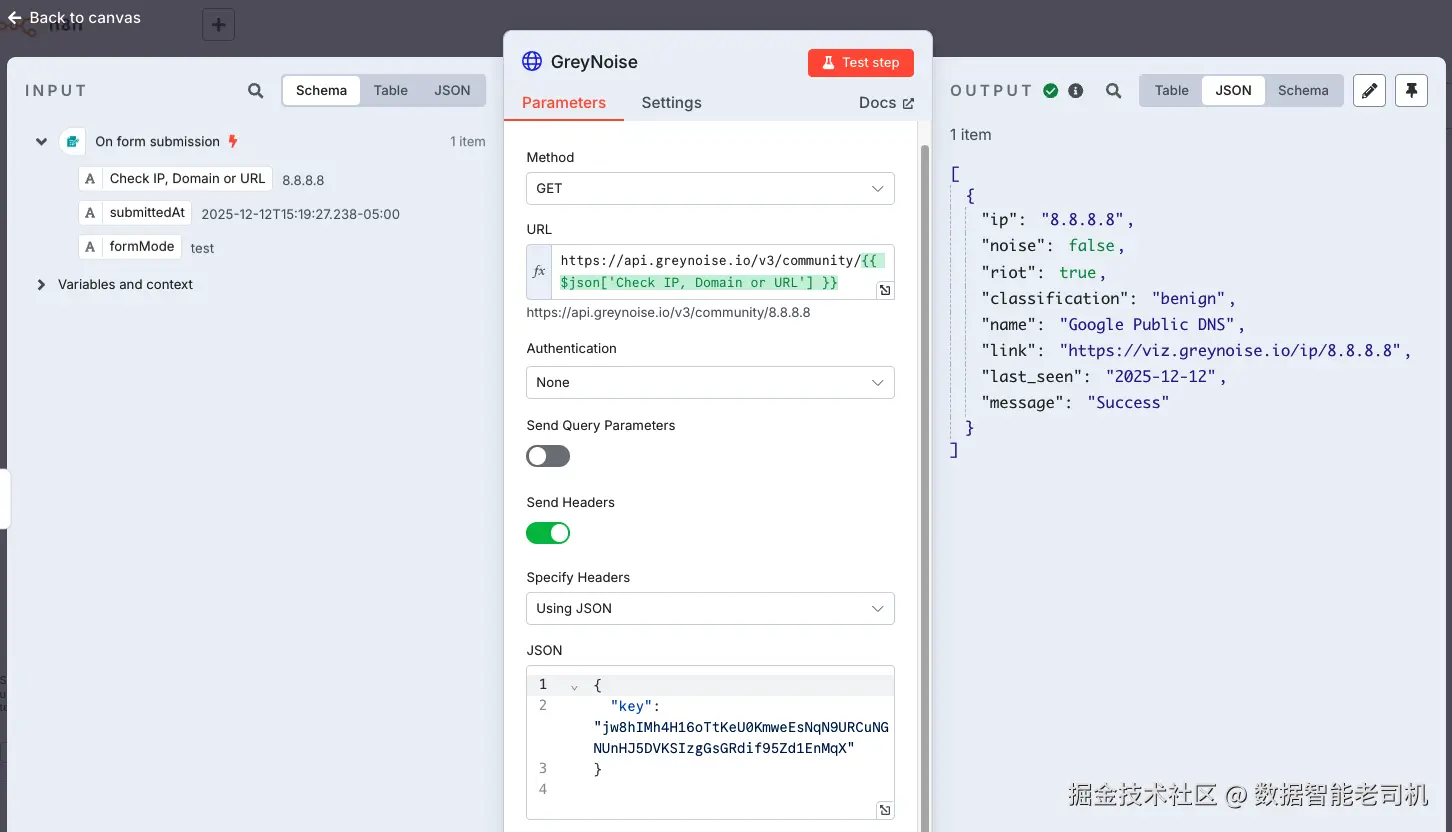
图 3.13 ------ GreyNoise Community API(Figure 3.13 -- GreyNoise Community API)
我们同样在 URL 字段使用 n8n 强大的表达式系统动态传入 IP:
https://api.greynoise.io/v3/community/{{ $json["Check IP or Domain"] }}
这保证同一个工作流可处理任意用户提交 IP,无需手动修改。我们也启用了 Send Headers toggle,通过 JSON header 注入 API key 来认证请求。
右侧输出展示了对 8.8.8.8 的查询结果:
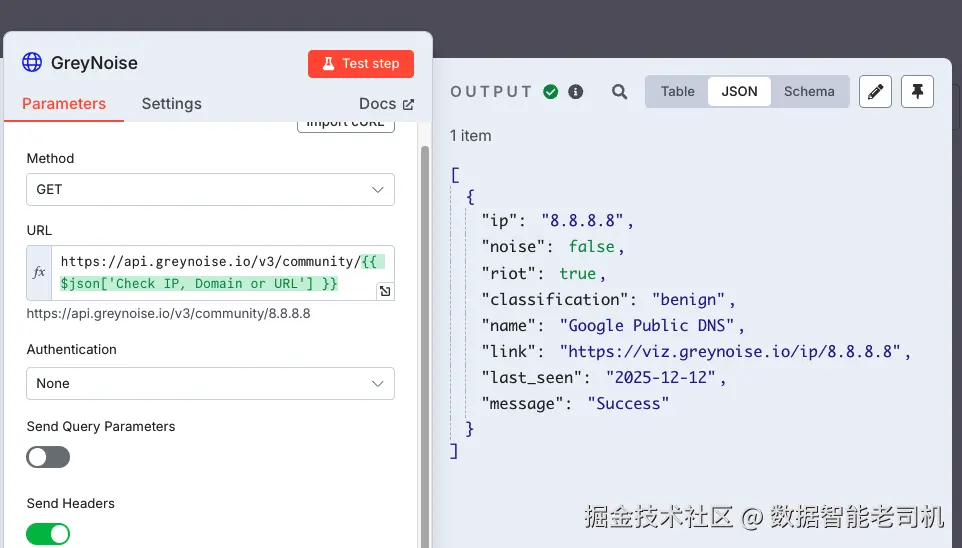
图 3.14 ------ Query to GreyNoise(Figure 3.14 -- Query to GreyNoise)
GreyNoise 的分类如下:
"noise": false:该 IP 不属于全球扫描噪声"riot": true:该 IP 属于已知、可信服务"classification": "benign":这表示没有与其相关的威胁活动
此外,响应还包含一个 public GreyNoise 可视化页面链接,以及最后一次观测时间戳。对智能体驱动工作流来说,这类"少但关键"的上下文非常有价值,因为是否升级处置或降级优先级往往就取决于这类元数据。
稍后我们会用 LLM 自动解析并总结这类富集数据,让你无需阅读 raw JSON 就能获得清晰结论。
第 4 步 ------ 使用 OTX(AlienVault Open Threat Exchange)富集指标(Step 4 -- Enriching indicators with OTX)
现在我们连接 AlienVault Open Threat Exchange(OTX):一个社区驱动的平台,以 pulses 的形式共享妥协指标(IOC)、战术技术与流程(TTPs),以及策划过的威胁情报。OTX 的独特之处在于其协作属性:安全研究者与从业者贡献威胁数据,然后我们可以通过 OTX API 以编程方式消费这些数据。
在我们的用例里,我们将查询 IP 信誉 endpoint,它会返回以下信息:
- 该 IP 是否出现在近期 pulses(威胁活动/攻击战役)中
- pulses 的数量与标题
- 地理位置、ASN 与被动 DNS 元数据
- 关联的恶意软件家族或标签
这些信号结合起来提供的不只是一次性的信誉检查。通过 OTX 富集 IP 与域名等 observables,你的工作流获得的是与野外真实攻击模式绑定的数据,而不仅是点查询(point-in-time lookups)。这使它成为上下文感知自动化与 CVE triage 的一层强力补充。
下图提供了 OTX pulses 与相关威胁情报的概览:
图 3.15 ------ OTX pulses(Figure 3.15 -- OTX pulses)
我们再次使用 n8n 的 HTTP Request 节点,把 IP 地址作为 path parameter 传入,并用你的个人 OTX API key 认证。实现很直接,但在给智能体决策过程提供"叙事层(narrative)"方面非常强大:
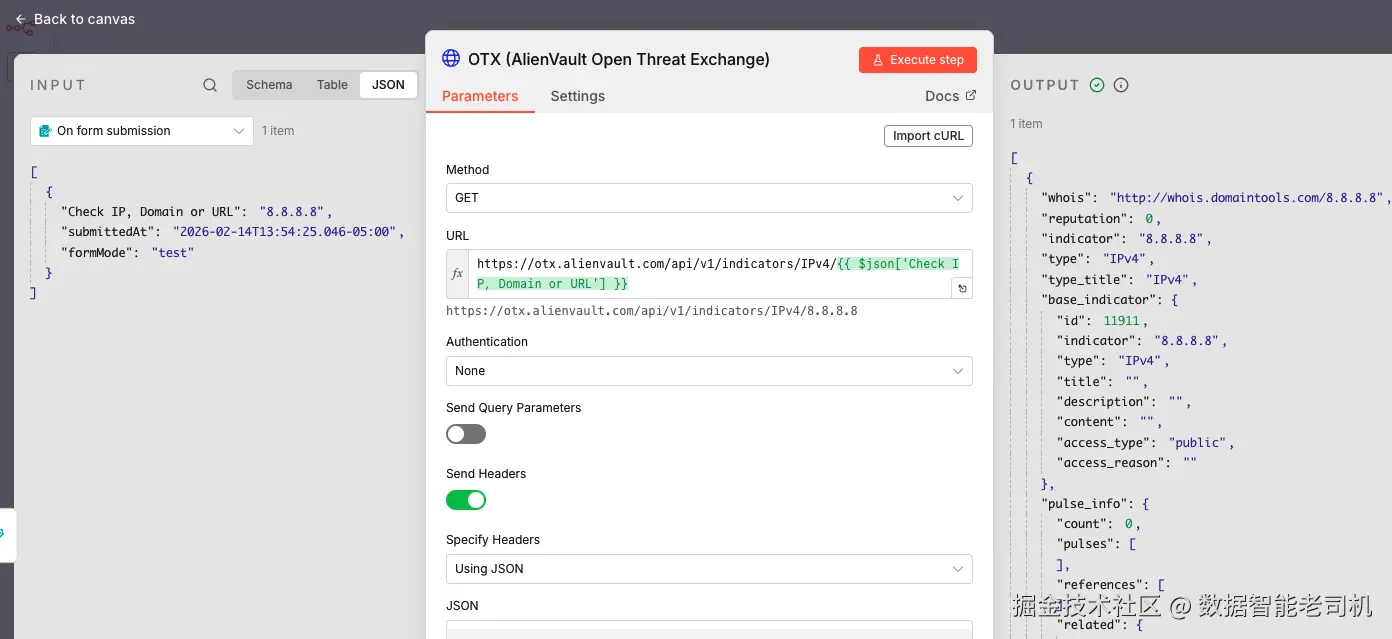
图 3.16 ------ Usage of the OTX API key(Figure 3.16 -- Usage of the OTX API key)
使用参数化的 HTTP Request 节点并通过 API key 认证,使得请求对任意 IP 输入都灵活可复用。认证通过 X-OTX-API-KEY header 完成,我们把个人 API key 放在那里,和之前用过的其他威胁服务一样。
从右侧输出(见图 3.17)看,8.8.8.8 的威胁上下文很少:
pulse_info的 count 为 0,意味着该 IP 未出现在近期社区提交的威胁活动中- 信誉分数为 0,表明没有与其相关的恶意行为
malware_families、industries、adversary等字段为空,进一步强化了"干净 IP"的判断
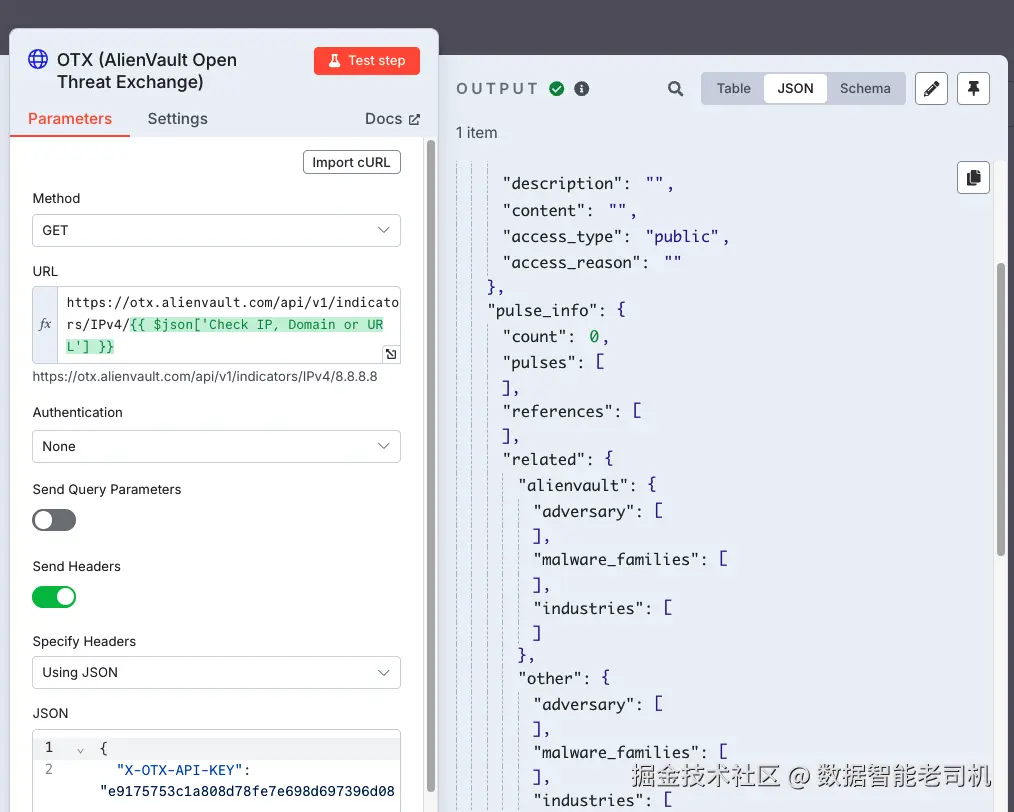
图 3.17 ------ Results for the IP address query(Figure 3.17 -- Results for the IP address query)
不过当 IP 是恶意的时,这个结构就会非常有用:OTX 能返回丰富情报,包括战役名称、关联恶意软件、对手组织,甚至指向威胁报告的链接。稍后我们构建 LLM 启用的富集逻辑时,这些字段会被自动解析与总结,从而帮助我们做优先级排序。
现在,你已经成功把另一块真实世界威胁情报接入你的 agentic pipeline。如下面截图所示,我们已经在 n8n 中把完整的富集流水线连好了:
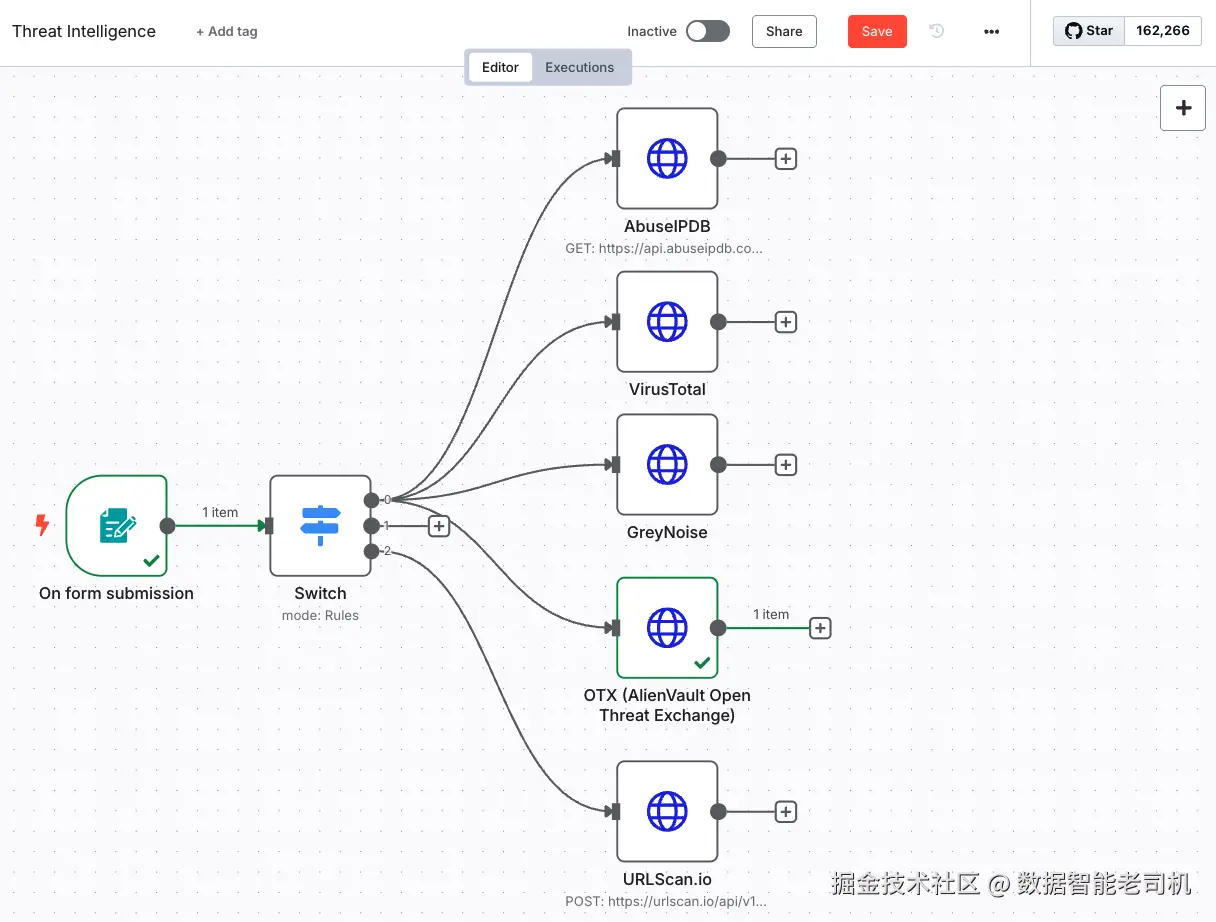
图 3.18 ------ Threat Intelligence workflow(Figure 3.18 -- Threat Intelligence workflow)
当用户提交 IP 或域名时,它会同时发送到多个威胁情报源:AbuseIPDB、VirusTotal、GreyNoise 与 OTX。这种并行执行不仅加快响应速度,也保证智能体能获得多样且具备上下文的数据,为后续阶段的智能分析打下基础。
第 5 步 ------ 使用 urlscan.io 做深度 URL 与行为分析(Step 5 -- Deep URL and behavior analysis with urlscan.io)
最后一个要接入的富集源是 urlscan.io:一个强大且免费的服务,既像 URL 的沙箱,也像 URL 的搜索引擎。不同于偏信誉的平台,urlscan 会在无头浏览器里加载提交的 URL 并记录一切:HTML 内容、网络连接、重定向链、JavaScript 行为等。这使它在检测钓鱼页面、恶意重定向、可疑第三方脚本,甚至"静默"命令控制 beacon 时非常有用。
下图展示了 urlscan.io dashboard 与我们工作流做深度 URL 与行为分析时会交互到的扫描上下文:
图 3.19 ------ urlscan.io dashboard(Figure 3.19 -- urlscan.io dashboard)
无论你在测试暴露的登录面板、可疑钓鱼域名,还是 OSINT 中发现的链接,urlscan 都能为调查加入动态深度。它提供:
- 渲染页面的截图
- 所有连接的域名与外部资源
- HTTP headers、TLS 证书信息与重定向逻辑
- 以及在适用时的分类标签(如 phishing、crypto、login 等)
在我们的工作流中,我们将通过 HTTP POST 请求把提交的域名或 URL 发送到 submit endpoint,使用免费的 public API。请求排队后,我们会收到一个 result URL,智能体稍后可以用它查看或拉取扫描输出用于分析。
现在把这个最后的节点也连上,让我们的富集智能体获得从静态元数据到实时 Web 行为的全视野。
在下面的截图中,我们配置了一个 HTTP Request 节点与 urlscan.io 的 submission API 交互。不同于前面主要面向 IP 的威胁情报平台,urlscan 用于分析完整域名与 URL。本例中提交值为 https://cyprox.io/,请求返回了 UUID、结果链接与扫描可见性元数据:
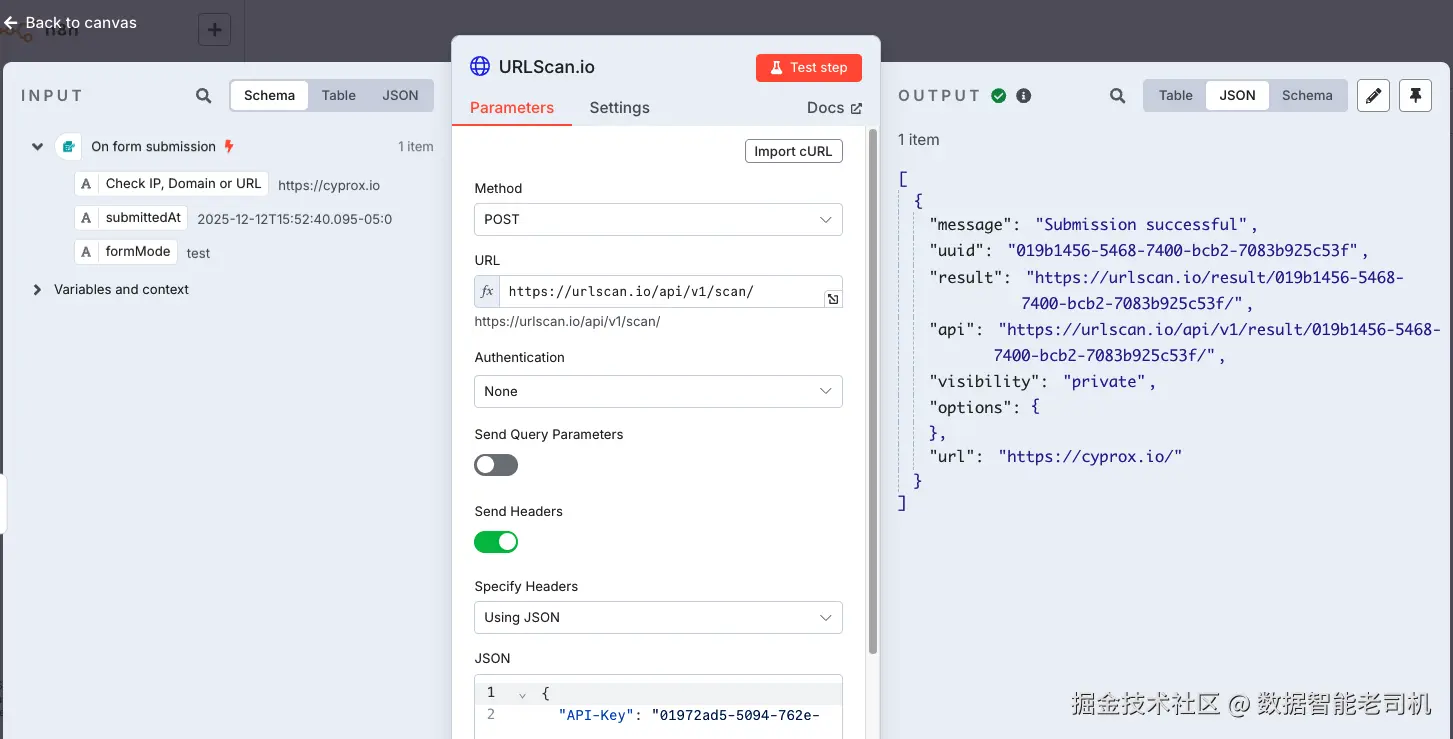
图 3.20 ------ HTTP node query results(Figure 3.20 -- HTTP node query results)
这里有一个重要细节:被扫描的值是 URL,而不是 IP 地址。
这将我们带到工作流中的一个关键分叉点:不同威胁 API 期望的输入格式不同(IP vs 域名 vs 完整 URL),我们需要一种方式在富集前对数据进行条件路由。这就是 n8n 的 Switch 节点登场的地方。
如果你来自传统脚本世界,这会让你想到 if-else 或 switch-case。但在 n8n 里,它是可视化、直观、且易实现的。如果你对这个概念还不熟也没关系:我会展示如何添加 Switch 节点、如何定义条件(例如输入包含 http → 当作 URL),并据此路由工作流。只需几次点击,你的自动化就能更聪明:自信地处理多样输入类型。下图展示了我们最终版本的威胁富集工作流:
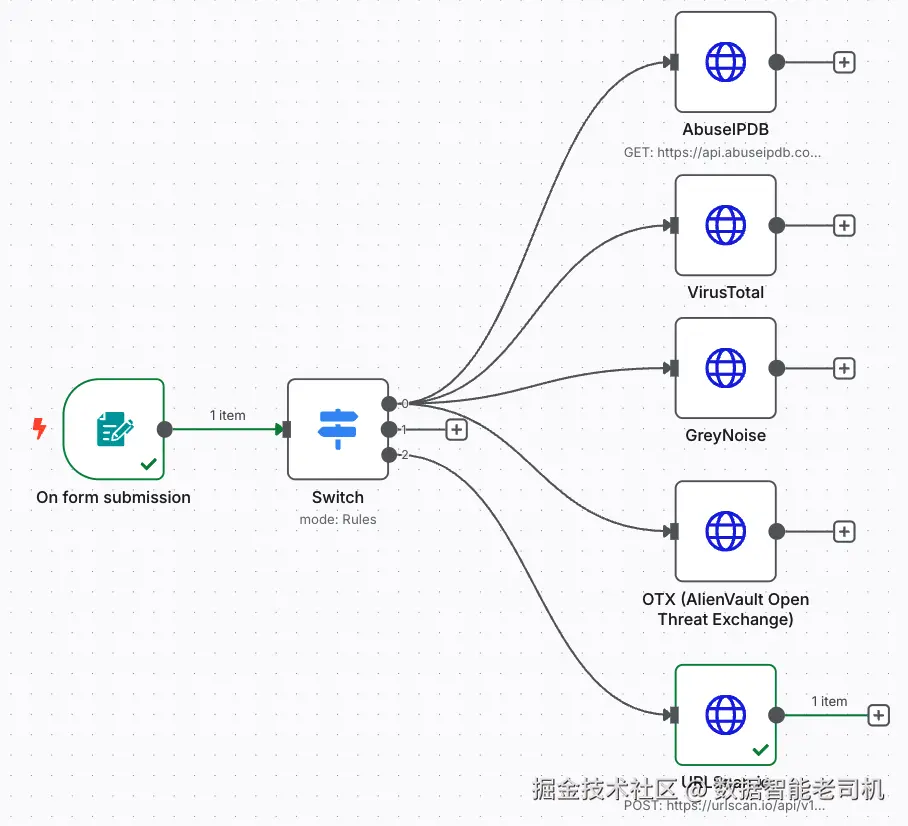
图 3.21 ------ Threat enrichment workflow(Figure 3.21 -- Threat enrichment workflow)
我们在表单提交与 API 请求之间加入了一个 Switch 节点,使输入能够根据它是 IP、域名还是 URL 被智能路由。
现在,当你点击 Test workflow 按钮时,会弹出一个 Web 表单,你可以输入任意值,例如 8.8.8.8、example.com 或 https://packt.com/。Switch 节点负责判断类型,并只把请求发送给相关的 API。
这种动态分支确保每个服务都能收到它期望格式的数据,无需人工干预。它干净、高效、可扩展------这正是我们希望注入自动化流水线的那种"智能"。接下来我们看看这个 Switch 节点是如何配置的。
下面截图展示了我们如何在 n8n 中配置 Switch 节点:依据提交值是 IP 地址、域名或完整 URL 来路由流量:
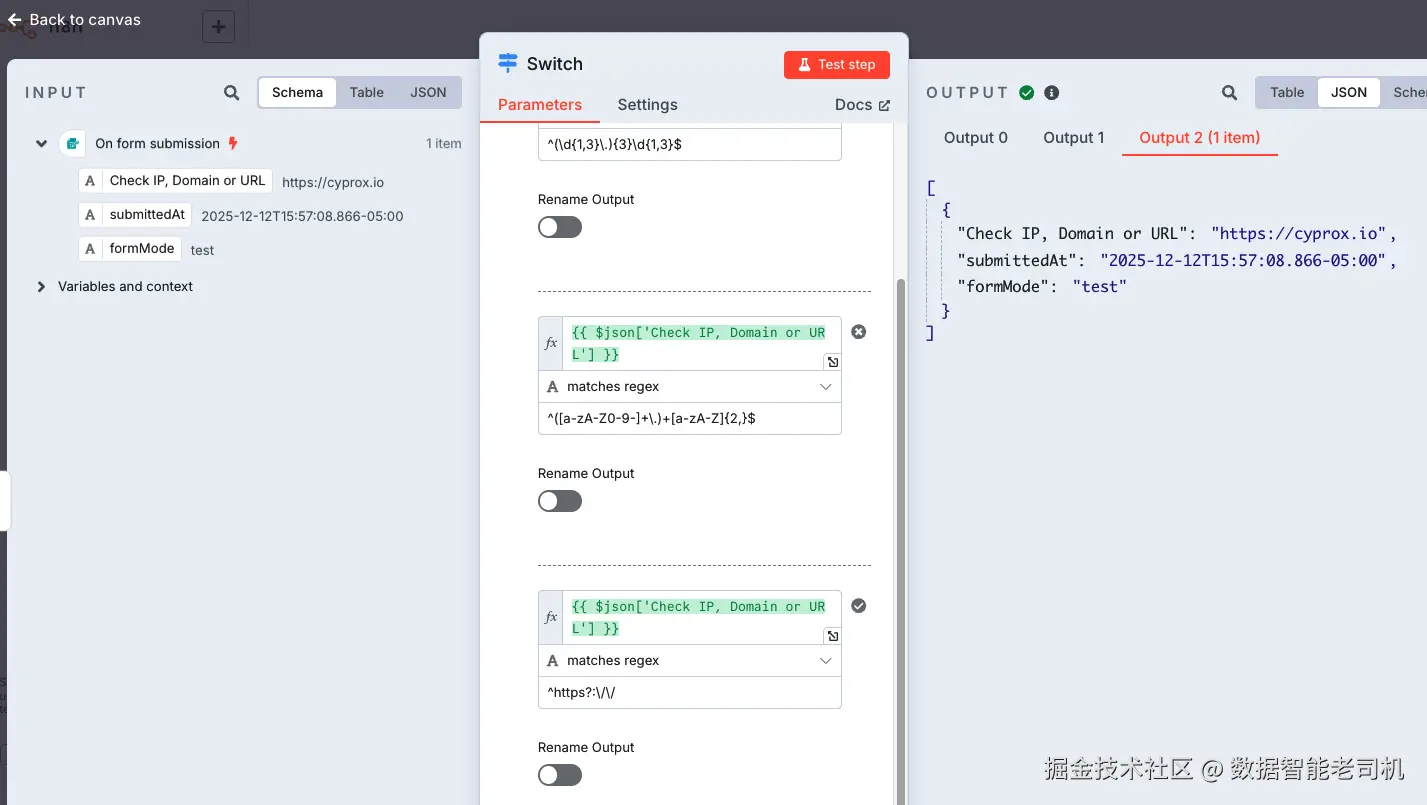
图 3.22 ------ Switch node configuration(Figure 3.22 -- Switch node configuration)
每个条件都对 Check IP, Domain or URL 输入字段执行一次 regex 匹配:
- IP 地址匹配: 捕获
8.8.8.8这类 IPv4:
^(\d{1,3}.){3}\d{1,3}$ - 域名匹配: 捕获
example.com或cyprox.io:
^([a-zA-Z0-9]+.)+[a-zA-Z]{2,}$ - URL 匹配: 检测
https://cyprox.io/这类值:
^https?://
每个分支(输出)现在都能收到正确类型的输入,确保每种用例只触发相关 API。你可以从 Output 面板看到,https://cyprox.io/ 被正确识别为 URL 并路由到了 Output 2。
现在输入已经被正确分类并路由到相应的富集路径,我们就具备了构建更自主工作流所需的基础。在下一节,我们会把这些组件组合起来,设计我们的第一个 no-code 侦察智能体。
设计你的第一个 no-code 侦察机器人(Designing your first recon bot with no-code agents)
现在你已经把 AI 智能体接起来了,也掌握了 API 集成的基础,是时候把这些工具真正用起来了。本节我们将构建第一个可用的侦察机器人(recon bot):一个 no-code 的智能体,用来收集目标攻击面上的高价值信息。
这个 bot 将执行以下经典侦察活动------全程不写一行 Python 或 Bash:
- 子域名枚举(Subdomain enumeration)
- 端口扫描(Port scanning)
- 基础元数据与指纹识别(Basic metadata and fingerprinting)
- 威胁情报关联(Threat intelligence correlation)
为什么从 recon 开始?因为侦察就是进攻性安全里的"制图阶段"(map-making phase)。没有它,你就像在黑暗里乱走。后续的一切------漏洞利用、权限提升、横向移动------都依赖于你知道哪些东西暴露在外。把它自动化之后,我们得到的是一致性、速度,以及可在后续复用的上下文。
你将构建什么(What you'll build)
我们的第一个 recon bot 将:
- 接收域名或 IP 地址作为输入(就像你在威胁情报示例里做的那样)
- 通过 HTTP 节点调用多个工具来收集公开数据(例如 Subfinder、Shodan 与 SecurityTrails)
- 聚合并规范化输出(Aggregate and normalize the output)
- 记录结果或写入文件,以便后续分析(downstream analysis)
- 可选:接入语言模型(例如 OpenAI 的 GPT 或 Anthropic 的 Claude),用通俗英文总结发现------这非常适合为非技术干系人准备材料,或为后续自动化报告做数据预处理。
流程如何运行(How the flow will work)
n8n 工作流将遵循如下结构:
csharp
[Input Form Node]
|
[Switch Node (Domain/IP)]
|
[Subdomain Enumeration Node]
|
[Shodan Node]
| |
[Text Summary / Output Node]当你完成整个 recon bot 工作流后,它将看起来像一个完整结构化的自动化流水线:会根据输入类型做智能分支,并集成多个数据源。你会看到用于子域名枚举、IP 富集、端口扫描,甚至总结的节点彼此连接。这个可视化流程将代表一个完整的 no-code 进攻性侦察工具------它会像真实渗透测试人员一样,针对域名、IP 与 URL 动态适配。下面是该工作流在 n8n 中完成后的样子:
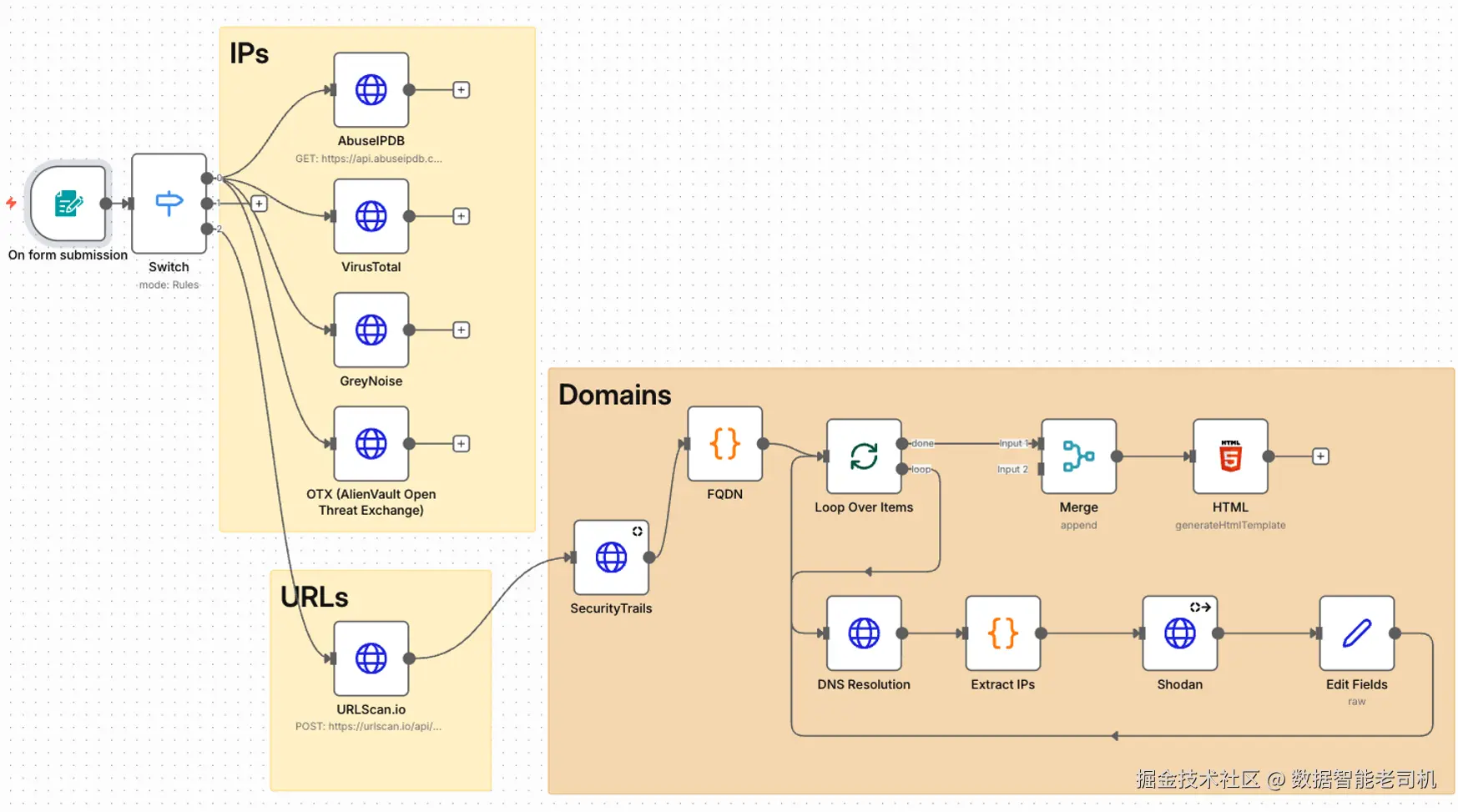
图 3.23 ------ n8n recon bot 工作流(Figure 3.23 -- n8n recon bot workflow)
这个完成的工作流可以从本书的 GitHub 仓库免费下载。(要获取仓库链接,请按前言中 Download the example code files 一节的步骤操作。)
你可以把它直接导入你的 n8n 实例,逐个探索每个节点,并按自己的侦察需求进行定制。
工作流中的 Domains 部分展示了 recon bot 如何把发现的子域名列表扩展为可行动情报。它从 SecurityTrails 节点的输出开始:该节点会为给定根域名提供子域名列表。随后数据流经一个函数节点(FQDN),把每个子域名转换为其完全限定域名(fully qualified domain name)。
下面的图示说明了 recon 工作流的 Domains 分支如何端到端处理并富集发现的子域名:
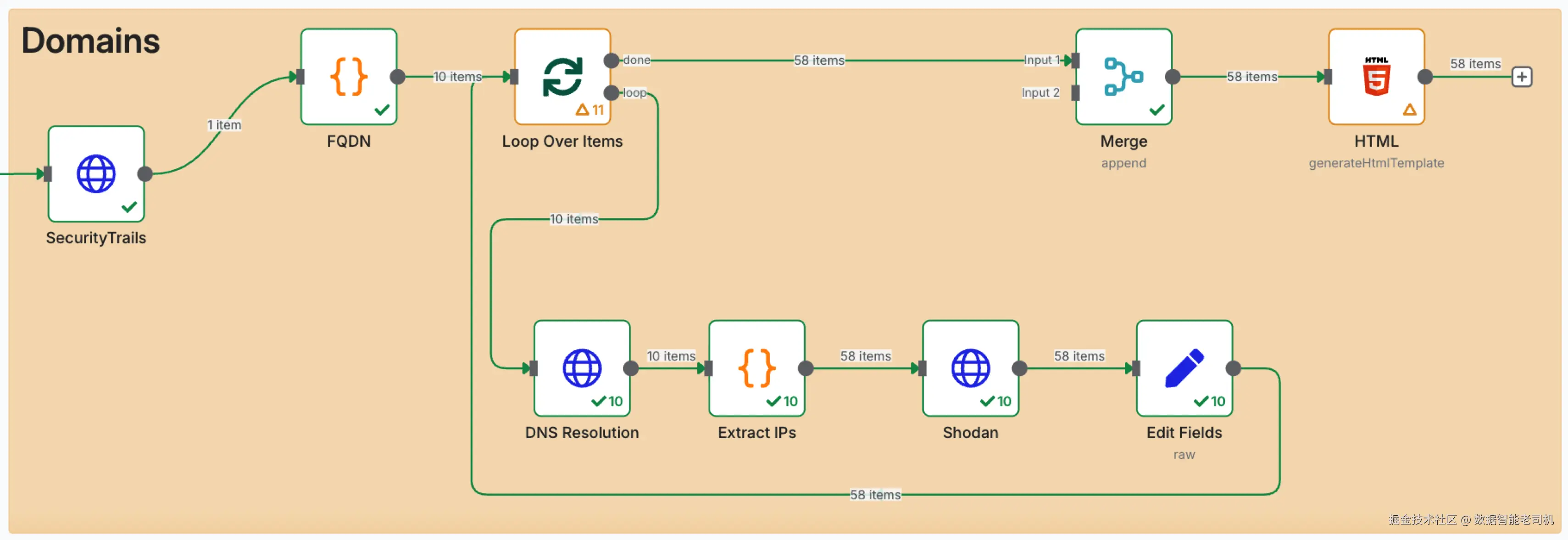
图 3.24 ------ Domains 处理流程(Figure 3.24 -- Domains processing flow)
接下来我们进入一个 Loop Over Items 节点,它会逐个处理每个 FQDN。在循环内部,我们进行 DNS 解析以获取 IP 地址(DNS Resolution),用另一个函数节点提取这些 IP(Extract IPs),然后把结果送入 Shodan,以识别开放端口、banner 以及其他暴露数据。
Edit Fields 节点用于清洗与格式化输出,确保结果标准化且易于解读。最后,一个 Merge 节点把循环结果与原始数据合并,而 HTML 节点生成一份可直接用于报告的人类可读摘要。
这一段流水线展示了:即便是多步骤的富集过程,在 n8n 中也能被无缝串联起来------无需写一行传统代码。
下面这张最终截图展示了我们 no-code recon bot 的"精修输出":在 n8n 中通过 HTML 节点自动生成的 HTML 报告:
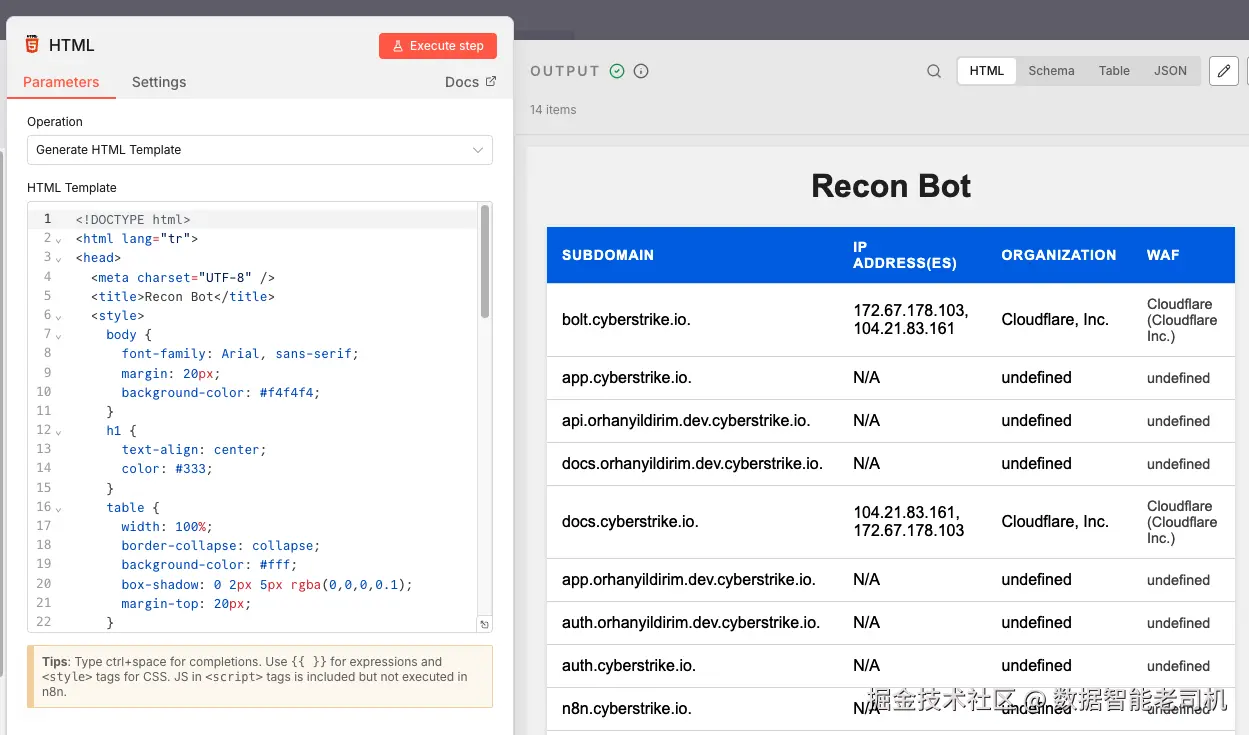
图 3.25 ------ HTML 报告概览(Figure 3.25 -- HTML report overview)
左侧你可以看到从合并后的工作流结果流入的 raw JSON 输入,其中包含子域名名称、关联 IP 地址、组织信息(例如 Cloudflare),以及 WAF 检测状态:
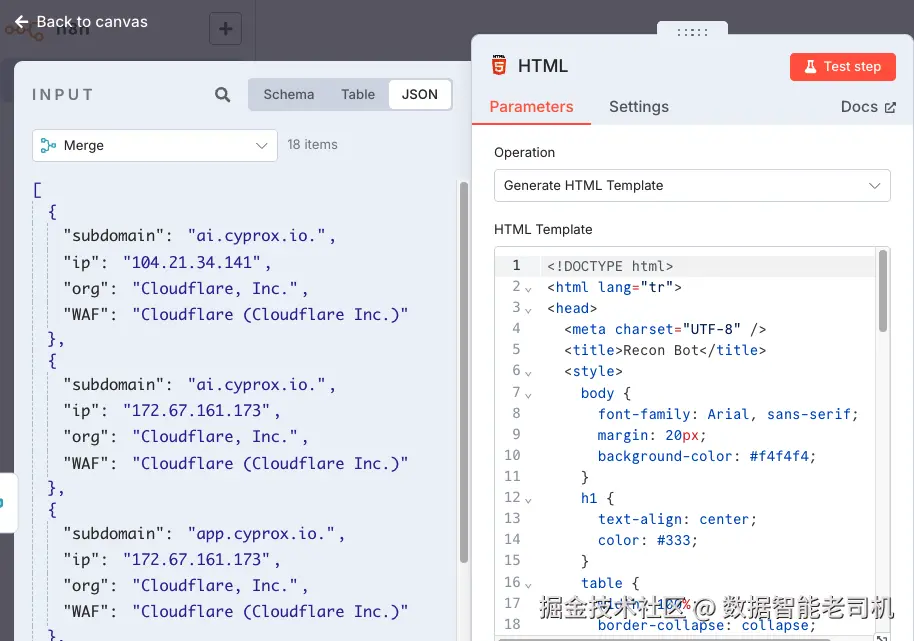
图 3.26 ------ 子域名列表输入(Figure 3.26 -- Subdomain list input)
右侧则把这些数据渲染成一个干净、分页的 HTML 表格,标题为 Recon Bot,便于浏览与分享:
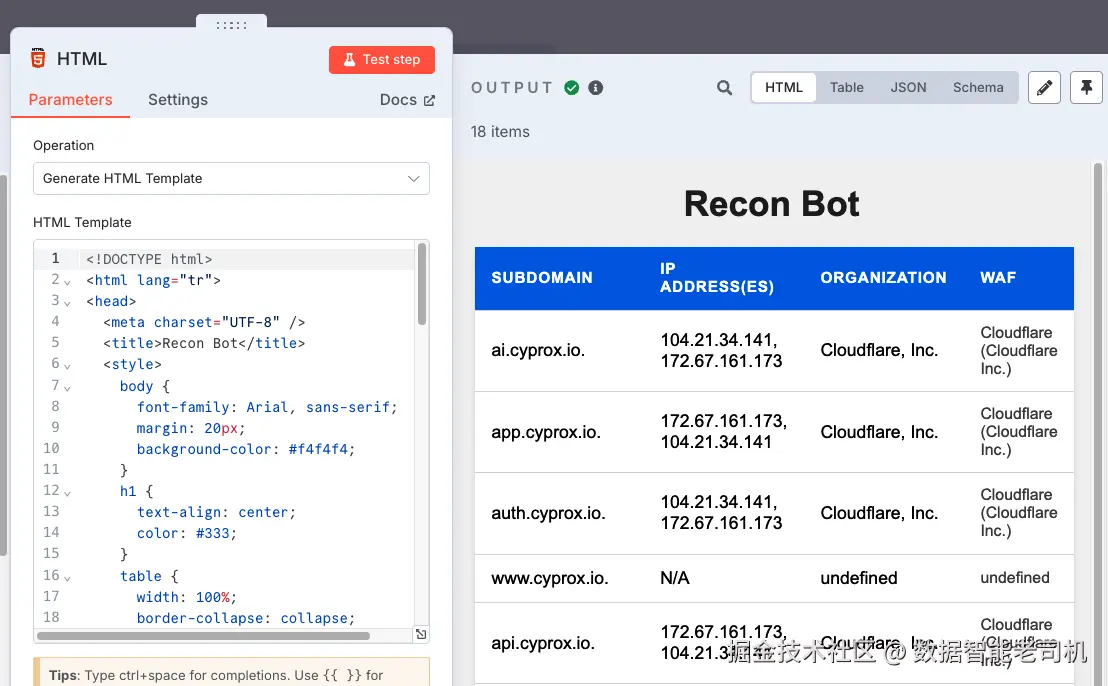
图 3.27 ------ Recon Bot 输出(Figure 3.27 -- Recon Bot output)
每一行汇总一个子域名及其侦察细节,并在可用时展示多个 IP。这样的结构化输出把 raw 数据转化为可行动洞察,随时可以导出、发邮件,或为了审计目的存档------同样不需要写任何传统报表代码。
在真实项目中,工作流里集成的每个工具------例如 SecurityTrails、Shodan、AbuseIPDB、VirusTotal、GreyNoise 与 AlienVault OTX------都可能返回比我们这里展示的更多数据点。你可以为每个子域名或 IP 进一步富集漏洞元数据、被动 DNS 历史、ISP 地理位置、行为指标,甚至 CVE 关联。不过,为了让本章保持精炼并聚焦核心概念,我选择以当前的 HTML 节点作为工作流的终点。这种做法在功能与清晰度之间做了平衡,同时也给你提供了一个坚实基础,便于你自行扩展更高级的自动化。
到这里,我们已经完成了 recon bot 从原始发现到结构化、人类可读输出的完整富集与报告闭环。这为我们继续进入更高级的推理与基于检索的工作流打下了扎实基线。
在 n8n 上实现 RAG 系统(Implementing a RAG system on n8n)
在 n8n 中实现 RAG 系统,会为 AI 智能体打开非常强大的能力,尤其是在进攻性安全领域------在那里,静态 prompts 往往远远不够。从本质上讲,RAG 允许语言模型在生成回答之前,先从外部数据源检索相关信息,从而增强准确性、上下文与时效性。RAG 流水线不会只依赖模型训练时学到的内容,而是在运行时拉取最新情报,例如漏洞描述、工具输出、文档,或内部知识库。
一般来说,RAG 有两种常见实现路径:
- 简单 RAG(Simple RAG): 工作流通过 API 或搜索检索上下文(例如 CVE 详情或扫描发现),然后把这些数据直接注入到发给 LLM 的 prompt 中。这非常适合快速、轻量的增强,尤其适用于总结发现或生成带动态输入的报告。
- 向量 RAG(Vector RAG): 一种更高级的方法,把文档或数据切片存入向量数据库(例如 Chroma DB、Weaviate 或 Pinecone)。当智能体需要上下文时,它会把问题转换成向量,找到语义上最相近的文档,并把这些片段喂进 prompt。它适用于更大的语料库或需要更深语义理解的场景,例如查询渗透测试报告或内部标准操作流程(SOP)。
在本节中,我们先从一个简单 RAG 实现开始,把 n8n 与 CVE feeds、文档 API 等外部来源集成。你会看到如何基于 recon 结果拉取数据,并用 OpenAI 等 LLM 生成聪明、可执行的摘要,帮助技术与非技术干系人。
在下面截图展示的最终工作流中,我们使用 Pinecone 作为向量存储实现了一个完整的 RAG 系统。该配置让我们能够用自定义 recon 情报与动态记忆来富集 AI 智能体。在画布右侧,你可以看到像 HTML recon 摘要或威胁情报报告这类文档,如何通过字符级文本切分器(character text splitter)被拆分,使用 OpenAI Embeddings 进行向量化,并存入 Pinecone Vector Store:
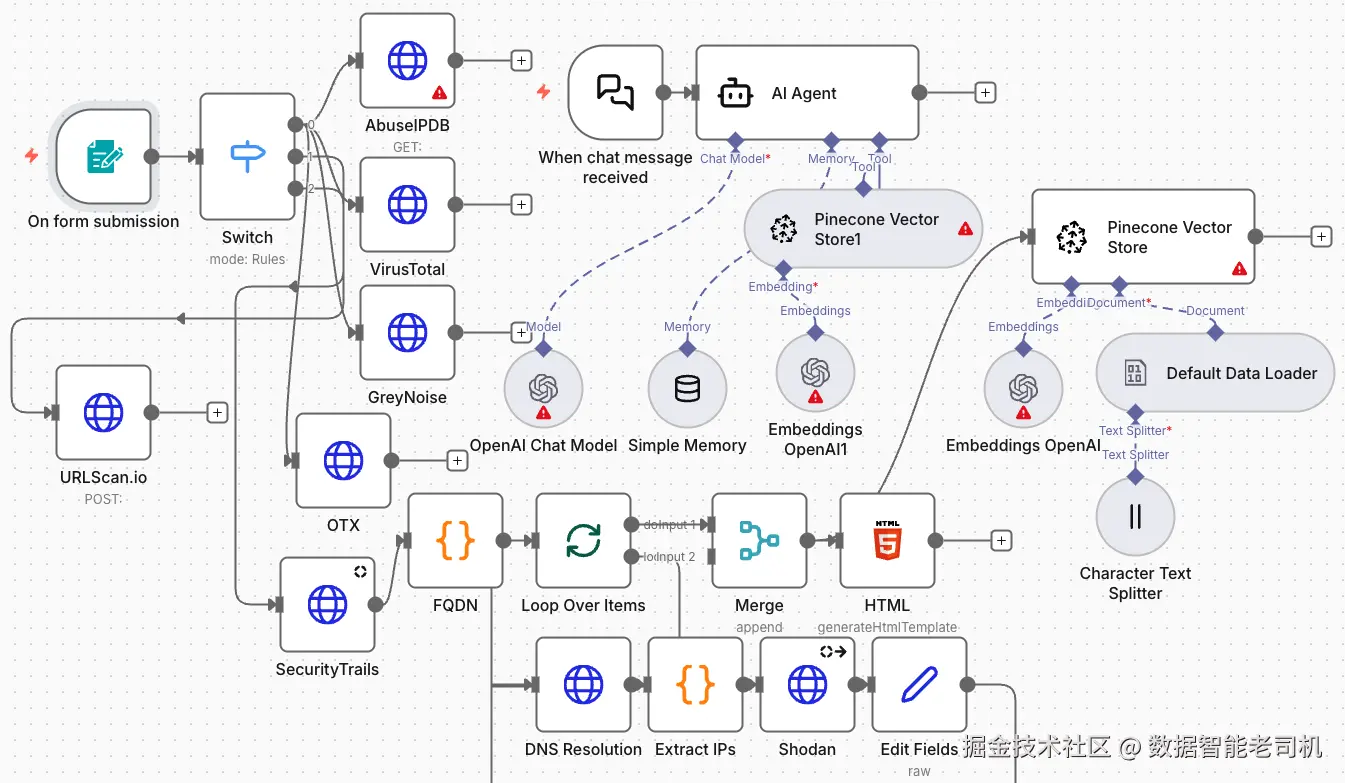
图 3.28 ------ 实现 RAG 系统(Figure 3.28 -- Implementing a RAG system)
数据存储后,AI 智能体就能通过向量查询做语义搜索,先检索上下文相关的片段,再通过 OpenAI chat model 生成回答。这使智能体能够在"全上下文感知"的前提下回答后续问题,例如"Shodan 发现了哪些带开放端口的子域名?"或"哪些 IP 被 AbuseIPDB 标记过?"这很好地展示了 agentic 工作流与 RAG 如何协同,从而驱动更聪明、实时的进攻性安全自动化。
在下面的截图中,我们可以看到把结构化 recon 数据推入 Pinecone 向量数据库的最后一步。工作流直接从 Merge 节点馈入数据,Merge 节点汇集了完整侦察闭环的结果。由于循环内早先的 Edit Fields 节点已经把数据整理为干净 JSON,我们就可以把这些数据直接送入 Pinecone,而无需额外格式化或后处理:
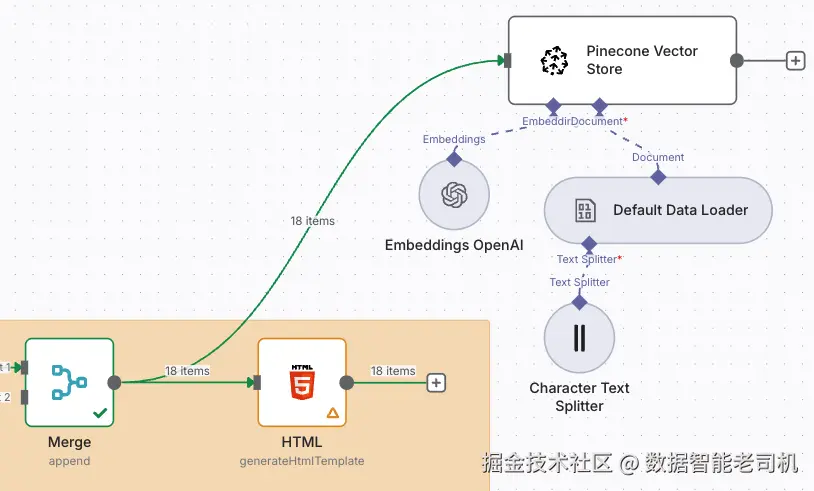
图 3.29 ------ 实现 Pinecone 向量写入(Figure 3.29 -- Implementing Pinecone vector)
为了做向量化,我们使用了 OpenAI 的 large embedding model,它即使面对包含 IP、子域名与 WAF 标签的短 JSON 块,也能很好捕捉语义关系。在做 embeddings 之前,我们使用了 Character Text Splitter 节点。这很关键,因为包括 Pinecone 在内的许多向量库,对较小、语义上更有意义的 chunk 的效果通常优于整篇 raw 文档。我们避免按行或段落切分,因为输入是结构化 JSON,不是自然语言文本;字符级切分让我们能更细粒度控制 chunk 大小,同时不破坏格式。
我们选择 Default Data Loader,因为它提供了把结构化 JSON 推入 Pinecone 流水线的最简路径,并允许我们灵活定义 document 字段与 metadata schema。我们避开了 Web Page Loader 或 File Loader 等其他 loader 类型,因为它们更适合抓取或上传非结构化内容(如 raw HTML 或 PDF),在我们的结构化数据场景里不够合适。配置完成后,把富上下文、结构化的 recon 数据写入向量库就会变得顺滑且强大,便于后续 RAG 查询。
在这套 RAG 驱动配置的最后部分,我们启用一个可交互的聊天智能体,让它能基于先前存储的侦察数据进行推理。如下面截图所示,该流程由 When chat message received 节点触发:只要用户提交 prompt(例如"Cloudflare 托管的子域名有哪些开放端口?"),它就会激活:
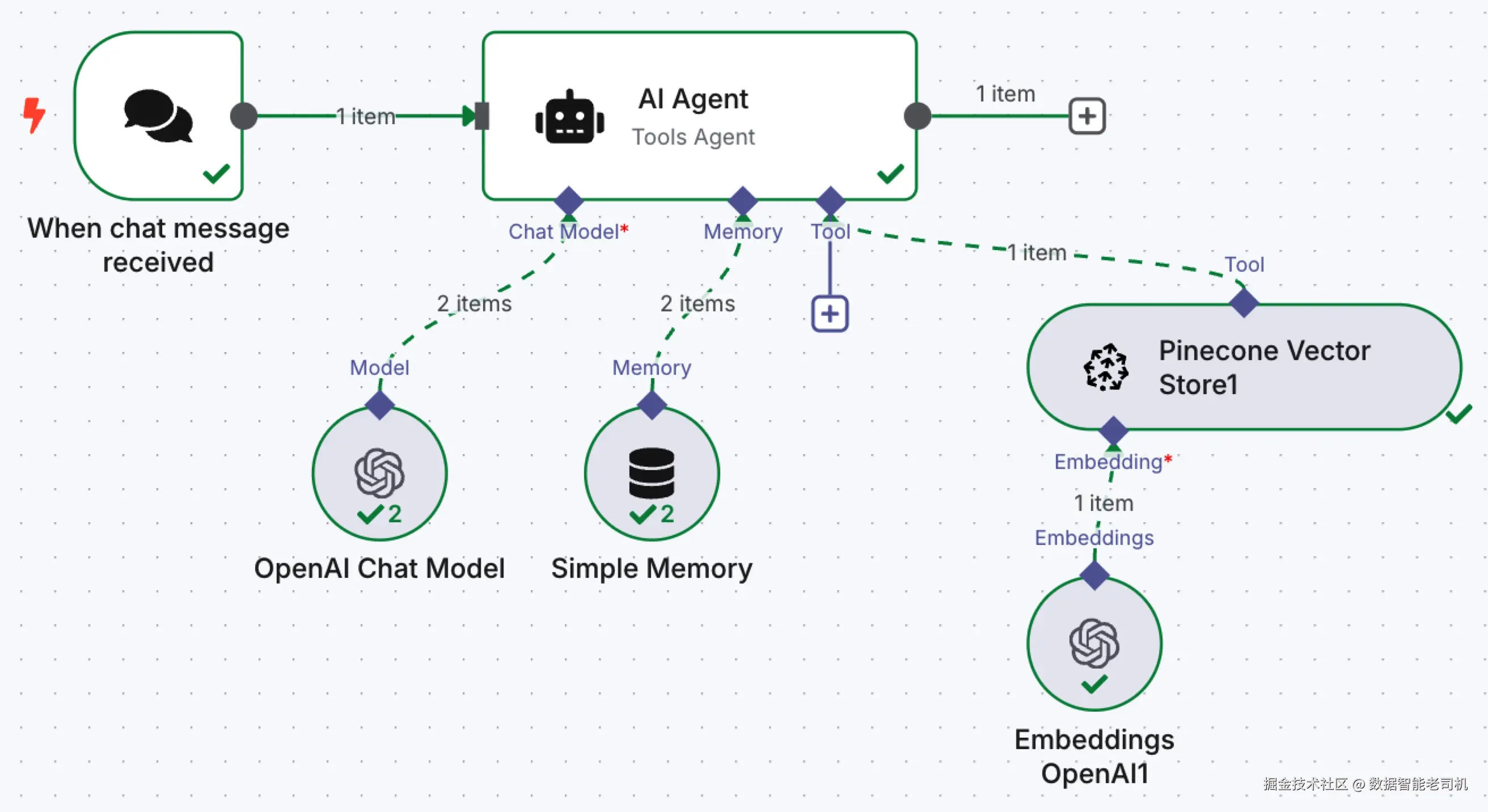
图 3.30 ------ 已实现 RAG 的 AI 智能体(Figure 3.30 -- RAG-implemented AI agent)
我们拆解一下这些组件,以及为什么要这样构建:
- AI Agent(Tools Agent): 交互的核心。它编排对话逻辑、维护上下文,并决定是否需要调用外部工具(例如查询向量库)。我们不硬编码响应逻辑,而采用目标驱动方式,让智能体自行判断需要用哪些资源。
- OpenAI Chat Model: 我们把 OpenAI 的 GPT 模型作为聊天背后的语言引擎。它解释 prompts、构造 embeddings,并生成流畅、类人的回答。
- Simple Memory: 该记忆模块跟踪对话状态。没有它,AI 无法记住先前消息,也无法在多轮对话中引用早期上下文。它是一种轻量短期记忆,非常适合聊天智能体。
- Pinecone Vector Store1(Tool): 智能体可把 Pinecone 实例作为工具调用,用于获取背景知识。我们的知识来自 recon bot 的输出(以 embeddings 形式存储)。
- Embeddings(OpenAI): 当用户提问时,智能体会对 prompt 做向量化,并用该向量在 Pinecone 上执行相似度搜索,从而检索最相关的 recon 数据点,本质上把答案"落地"到真实、已收集结果之上。
这种架构让你很容易替换模型(例如换成 Claude 或 Groq),扩展到多个工具,甚至加入访问控制与日志层。简而言之,这是一个生产就绪的 RAG 工作流------但它是用 n8n 以 no-code 的方式搭出来的。
下面截图展示了我们的 RAG 启用 AI 智能体在实际交互中的最终效果。当被问到例如"还有哪些子域名?"这样的问题时,智能体会从 Pinecone 拉取相关数据并以对话方式准确回答,列出 recon 阶段存储的子域名。这是一个很好的例子:recon 输出只要被正确索引,就能立刻通过自然语言变得可搜索、可解释:
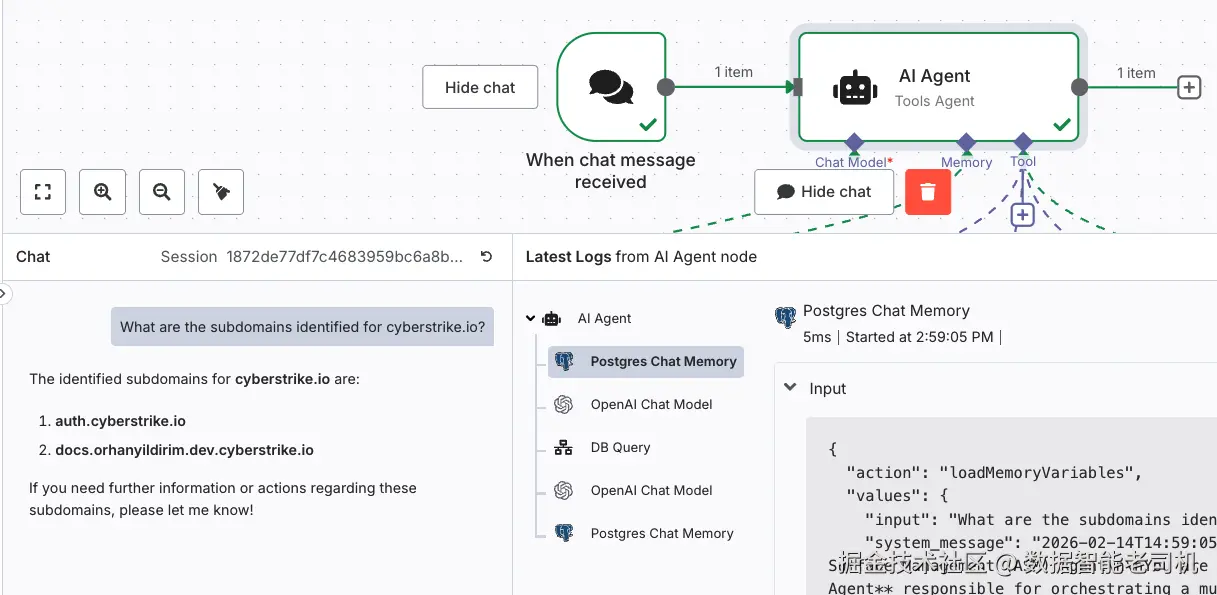
图 3.31 ------ 与 AI Agent 的聊天交互(第 1 部分)(Figure 3.31 -- Chat interaction with AI Agent, part 1)
现在我们的数据已经存入向量数据库,并且能被 AI 智能体无缝访问,我们就可以开始问更复杂、更有洞察的问题了。我们不只是把 recon 结果可视化,我们是在"和它们对话"。
下面截图展示了 AI 智能体如何直接查询向量化的 recon 数据,并基于此前富集过的情报,返回具备上下文的人类可读答案:

图 3.32 ------ 与 AI Agent 的聊天交互(第 2 部分)(Figure 3.32 -- Chat interaction with AI Agent, part 2)
这为真正的 AI 推理打开了大门:能够与你的数据进行对话、提取关系、验证假设,并让 LLM 指导你安全工作流中的下一步。无论是识别异常暴露模式还是映射基础设施关联,AI 变成了协作者,而不只是处理器。这就是自动化与智能相交汇的地方。
虽然 n8n 当前的 Chat 界面提供了一个可用起点,但很明显,它缺少真实分析师工作流所期望的可用性与响应性。幸运的是,n8n 提供了解决方案。通过利用外部 UI 组件------例如使用 n8n 的 webhook 与 API 节点把 chat 嵌入自定义 Web 应用------你可以设计一个更交互、更精致的体验。这种方式允许你构建定制前端,把 AI 推理集成进 dashboard、分析师控制台或工单系统,让你的智能体不仅"可访问",而且在运营上真正"可用"。
如下图所示,n8n 允许你通过在 When chat message received 节点下切换 Make Chat Publicly Available 选项,让 AI 驱动的聊天对外公开可访问:
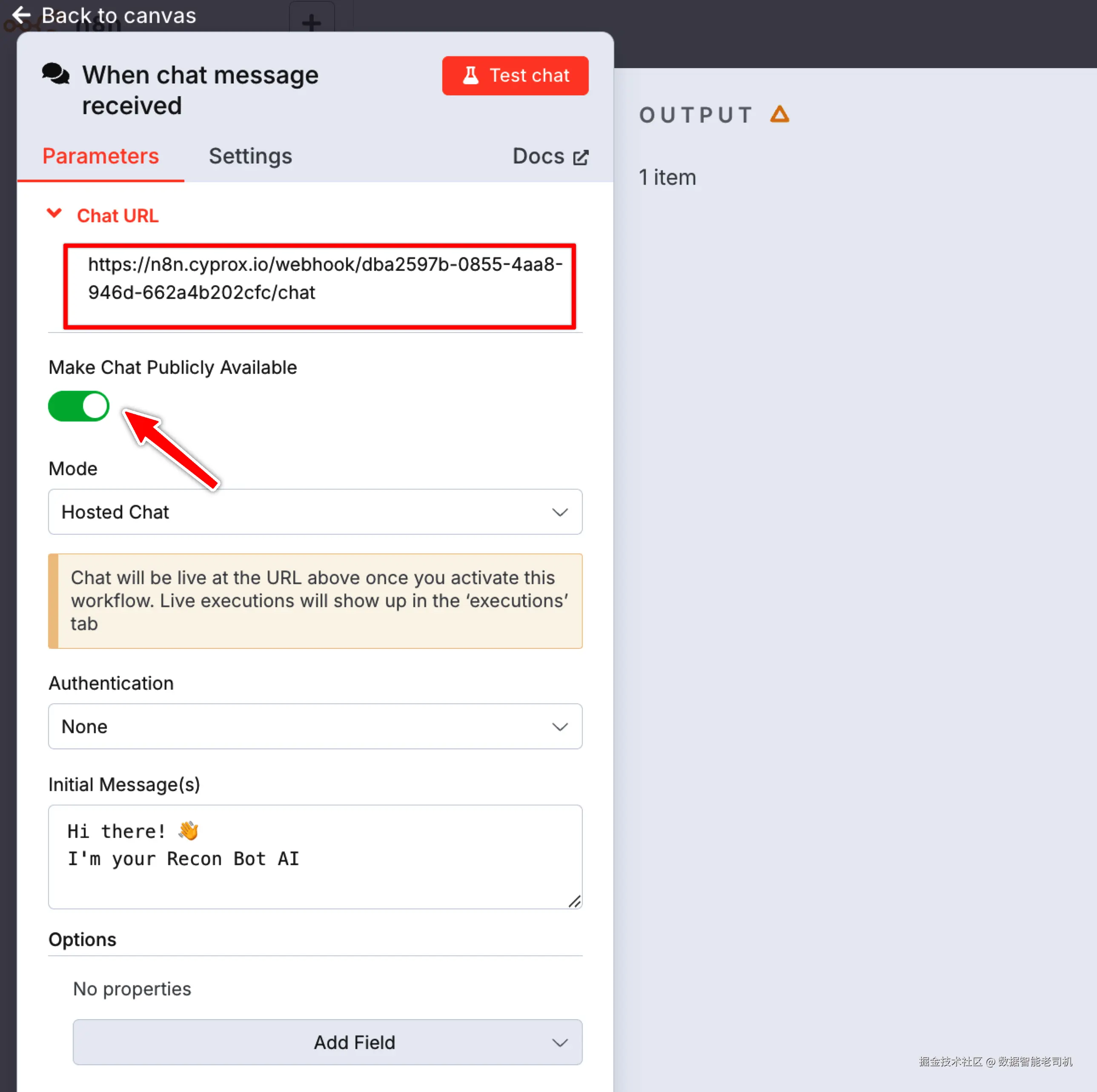
图 3.33 ------ 暴露 AI 聊天机器人(公开可访问)(Figure 3.33 -- Exposing the AI chatbot, publicly accessible)
启用后,会生成一个实时聊天 URL,非常适合对外分享或嵌入,从而实时与 AI 智能体交互:
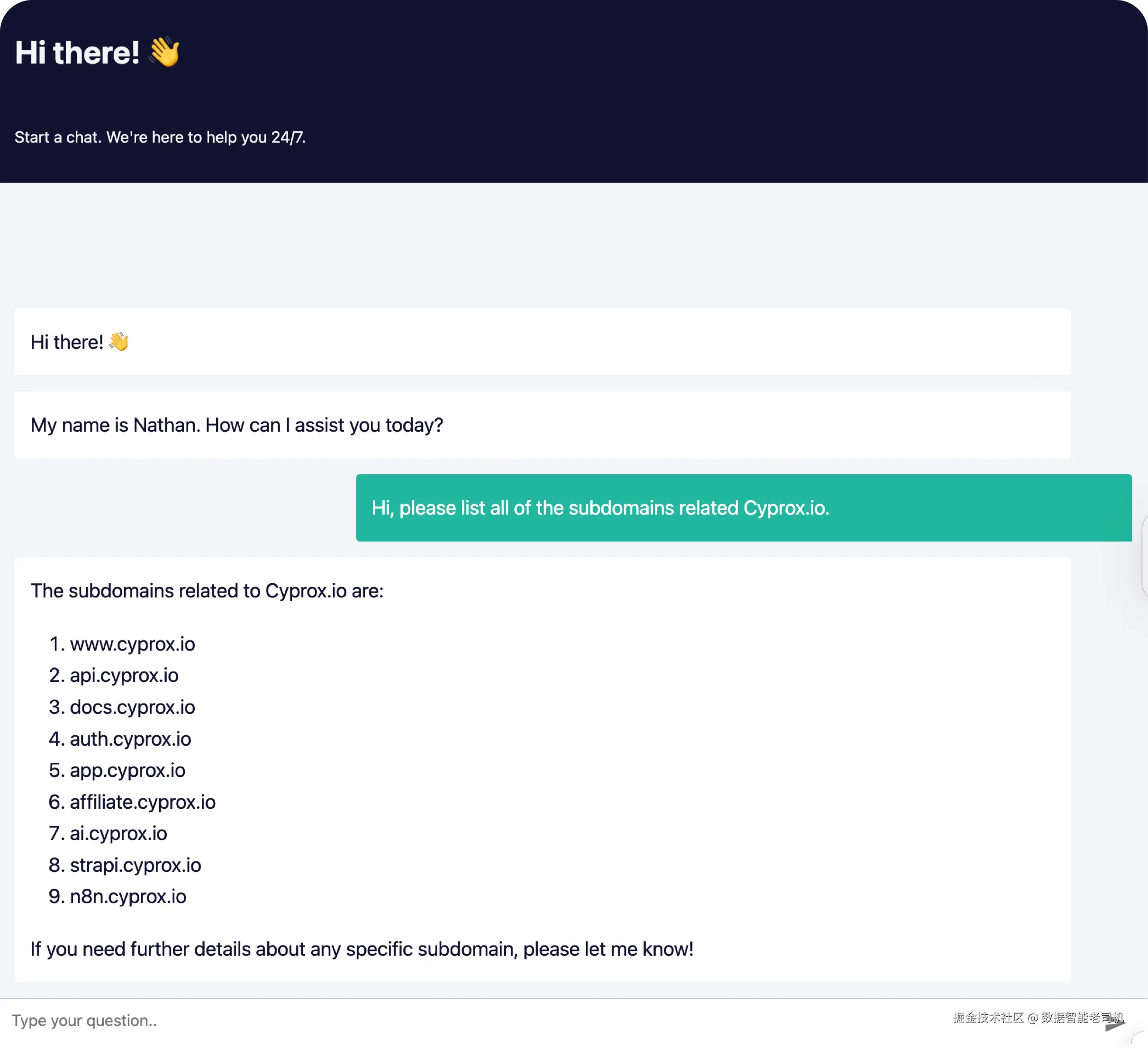
图 3.34 ------ AI 聊天机器人的公开界面(Figure 3.34 -- Public interface of the AI chatbot)
现在我们的 AI agentic 工作流已经完全可运行并连接到互联网,是时候处理同等重要的另一个问题了:加固工作流及其暴露出来的攻击面。
加固你的 agentic 工作流(Securing your agentic workflow)
现在进入那个让我夜里睡不着的部分。这些工作流很强大,但如果你不小心,它们也可能变成一扇后门。外部 API、敏感数据、LLM 的自主决策......所有这些都会为配置错误、数据泄露和意外后果打开大门。
本节的目标,是帮助你确保 AI 驱动的自动化不仅能正确运行,而且能在安全、可靠 并具备适当治理的前提下运行。
Agentic 工作流通常跨越多个信任边界:它们接收用户数据,与 OpenAI、Pinecone、VirusTotal、Shodan 等第三方服务交互,有时还会把输出发布到公开仪表盘或 Chat 界面。这样的动态互联系统本质上就像自主微服务(autonomous microservices)。就像传统 DevSecOps 或企业 SaaS 环境一样,加固这类工作流需要分层且主动的策略。
no-code 智能体的安全不仅仅是"保护密钥"或"切换权限"。你需要从整体角度思考以下问题:
- 谁或什么可以触发这个工作流?
- 什么数据进入系统,又从系统输出?
- 凭据存放在哪里?权限范围(scope)如何划定?
- 输出会不会被 prompt injection 或畸形数据(malformed data)操控?
- 日志、审计轨迹与错误处理是否足够健壮,以支持事件响应?
无论你是在内部用这些工作流做 recon 自动化,还是通过 Chat 界面对客户或分析师开放 agentic 能力,最小权限、输入/输出校验、凭据范围控制与可观测性这些原则都适用。
你用 AI 智能体与 n8n 之类工具构建的工作流,已经不再是静态序列;它们是智能的、会演化的系统。任何智能系统都需要带着明确意图去加固,并以纪律性的方式维护。接下来的小节里,我们会同时覆盖基础防护与更高级的实践,用来加固你的 recon 智能体,确保它们在规模化时仍然可信。
你必须始终做到的事(What you should always do)
下面这些最佳实践构成了任何用 n8n 构建的 agentic 工作流的基线安全姿态。把它们当作默认护栏,而不是可选的加固步骤------从第一天就应该应用:
- 使用环境变量: 认真点,别做那个把 API key 泄露到 GitHub 的人。把它们存到
.env文件里,或存进 n8n 内置的凭据管理器。 - 限制权限: 对 API key 与连接服务遵循最小权限原则。例如,如果只读 key 就够用,就不要使用 admin 级 OpenAI key。
- 清洗输入: 对用户提交的数据要谨慎处理,尤其是当它会被传入
eval、embedding,或用于发起 API 请求时。 - 监控工作流执行: n8n 提供 execution log。启用它,并定期检查活动,以发现异常或未授权运行。
- 限制公开访问: 如果你暴露了托管的 chat agent 或 webhook URL,尽可能通过 token、IP 白名单或限流代理来限制访问。
可选,但强烈推荐(Optional, but strongly recommended)
这些实践并非每种部署都强制需要,但随着工作流规模化,如果省略它们,数据暴露、滥用或运营盲区的风险会显著上升:
- 为托管 chat endpoint 加认证: 用 basic auth、OAuth,或你自己的校验层,避免公开 chat 界面被滥用
- 启用审计日志: 把日志存入外部系统(例如 Elasticsearch 或 CloudWatch),以保留不可篡改的审计轨迹
- 对敏感输出加密: 如果你把输出文件(例如 HTML 报告或合并后的 JSON)落盘或存到云存储,使用静态加密(encryption at rest)
- 隔离向量数据库: 如果你使用 Pinecone,为每种工作流类型创建专用 namespace 或 index,避免项目间的数据泄露
- 定期轮换密钥: 养成每 30--90 天轮换 API key 并更新 n8n 环境中凭据的习惯
总结(Summary)
在本章中,我们把 agentic AI 从概念变成现实:用 n8n 构建了第一个可运行的安全工作流。从安装与 Docker 配置开始,我们搭建了一个生产就绪环境,能够支持 Python 脚本、MongoDB 连接以及高级 API 集成。随后,我们接入了多层情报能力(OpenAI 用于推理,以及 AbuseIPDB、VirusTotal、GreyNoise、OTX 与 urlscan 等威胁 feed 用于富集),把静态自动化变成动态、具备上下文意识的决策系统。我们的 no-code recon bot 展示了如何把子域名枚举、DNS 解析、端口扫描与 Shodan 查询串联成一条智能流水线,并输出结构化的 HTML 报告。
最后,我们通过 Pinecone 实现了 RAG 系统,让我们能够用自然语言与 recon 数据对话------这标志着从"收集数据"跃迁到"真正对数据进行推理"。当你继续往前走时,请记住:加固这些 agentic 工作流不是可选项;从环境变量与输入清洗,到凭据轮换与审计日志,本节覆盖的原则能确保你的智能体在规模化时既强大又可信。
在下一章,我们将把这些基础应用到攻击面管理(ASM)中:构建能够持续发现、监控并评估组织外部攻击面的自主工作流。