在交易系统中,数据一致性校验是保障资金安全的最后一道防线。传统的硬编码方式让每次规则变更都需要发版,能否让业务研发人员直接配置SQL就能完成核对?本文将分享我们从代码到SQL配置的演进之路。
一、痛点:每次规则变更都要发版
1.1 一个常见的场景
在传统的代码式核对系统中,哪怕只是类似"订单应付金额 = 商品金额 - 优惠金额"这样简单的规则,也要走完一整套流程:需求 → 评审 → 开发/测试 → 发版 → 上线(2--3 天),甚至微调阈值也要发版。对高频变化的业务而言,这样的流程明显低效。
1.2 传统方案的三大痛点
从这个场景可以看到,传统的代码式规则实现方式,存在以下三大痛点:
- 响应慢 :规则从提出到生效通常需要 2--3 天,难以支撑高节奏业务。
- 成本高 :每条规则迭代往往需要开发 2 人天、发版 1 人天;规则越多,成本线性增长。
- 风险大 :代码改动易引入新 Bug、干扰其他逻辑,发版失败还需紧急回滚。
1.3 我们的思考
在复盘这些问题时,我们发现: 核对规则的本质,其实就是" 数据查询 + 条件判断"。
它并不属于核心业务逻辑,而更像是数据层的一种"验证表达式"。
由此得出关键洞察是 :
- 核对规则的本质是 数据查询 + 条件判断
- SQL 天然适合表达这类逻辑
于是,我们决定用SQL成为规则。
二、让 SQL 成为规则
2.1 核心设计理念
我们的想法其实很简单:配置一条 SQL ,就是定义一条核对规则。
过去:
业务需求 → 开发 → 测试 → 发版 → 上线(2--3 天)
现在:
业务需求 → 配置 SQL → 调试 → 发布(30 分钟)
从"写代码发版"到"配置即生效",规则交付效率提升 95%+ 。
2.2 为什么选择 SQL?
- 表达能力强 :单表校验、跨表关联、聚合统计、复杂条件,SQL 均可优雅覆盖。
- 学习成本低 :团队普遍具备 SQL 能力,协作与落地成本低。
- 维护成本低 :规则变更无需代码改动,仅通过 SQL 调整即可生效,支持快速迭代与灰度验证。
三、架构设计与核心技术
3.1 架构设计理念
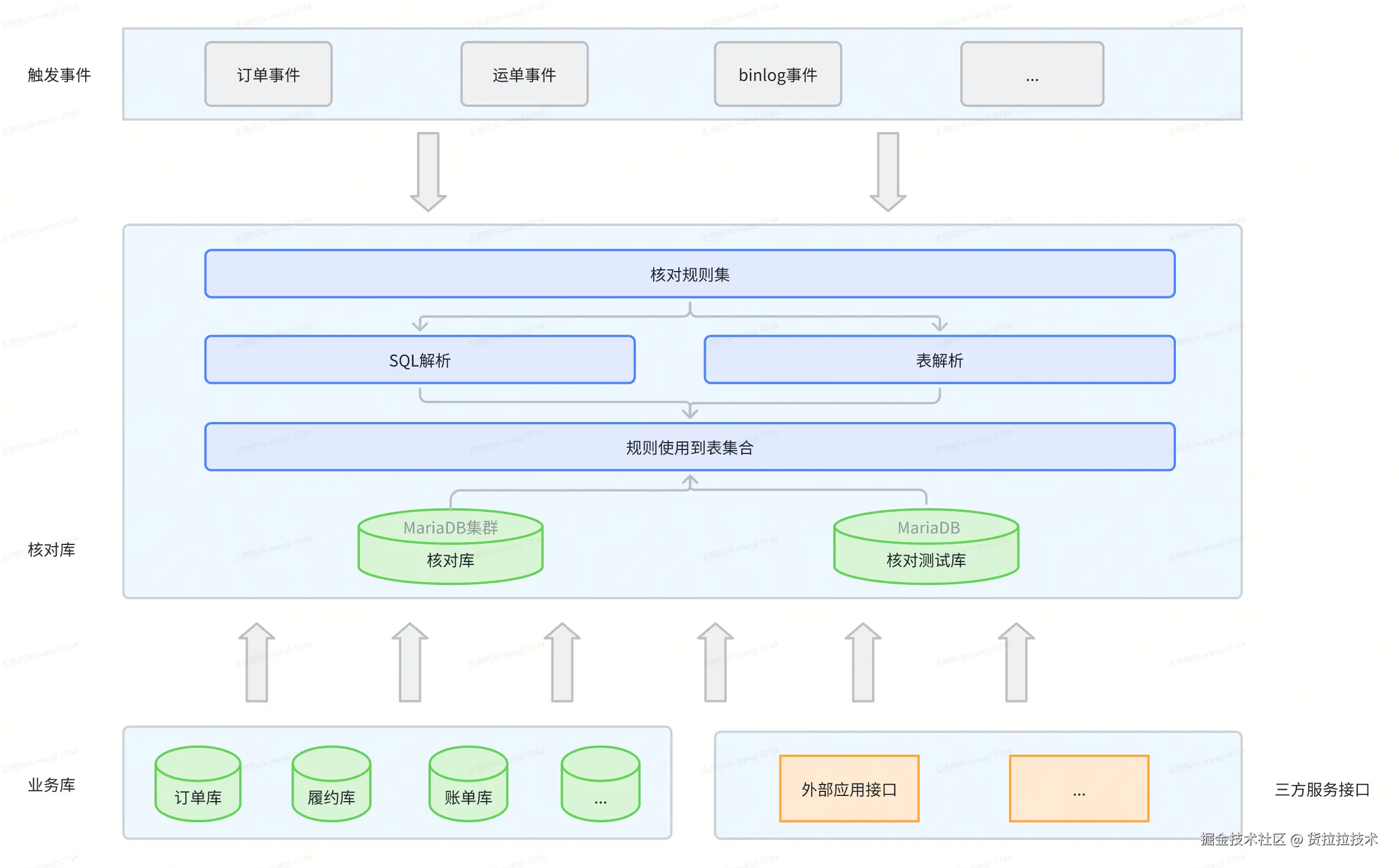
目标:让规则执行更快、更稳、更安全。架构围绕以下关键机制展开:
-
事件触发(可插拔)
- 支持多种数据源(如Kafka、MySQL)的动态注册,支持灰度放量与前置过滤,精准触发核对、避免无效计算。
-
规则 SQL化(可配置)
- 规则即 SQL,
${field}参数自动注入;支持在线调试与一键发布,分钟级生效,实现"配置即规则"。
- 规则即 SQL,
-
线上隔离(可控风险)
- 在内存级 MariaDB 集群中进行快照计算,与线上库解耦,不占用计算资源,天然支持跨库数据整合。
-
数据共享与并行(高吞吐)
- 同一事件下多规则共享数据快照,基于数据依赖分组执行,组内并行、组间串行,提高查询效率及性能。
总结:插件式触发、 SQL 化规则、内存级隔离、智能并行------把"代码逻辑"沉淀为"配置能力",高效且可控。
3.2 核心技术实现
3.2.1 SQL 解析与血缘分析(让系统"读懂 SQL")
3.2.1.1 核心问题:系统如何知道这条规则需要哪些数据?
当用户在平台上配置一条核对 SQL,比如:
sql
SELECT
o.order_no,
o.order_amount,
p.payment_amount
FROM order o
LEFT JOIN payment p ON o.order_no = p.order_no
WHERE o.order_no = '${order_no}'
AND ABS(o.order_amount - p.payment_amount) > 0.01系统必须回答两个关键问题:
- 这条 SQL 依赖哪些表?(从哪里取数据)
- 这条 SQL 需要哪些参数?(从消息中取哪些字段)
而答案的来源,就是------SQL 血缘关系分析。
3.2.1.2 构建 SQL 血缘关系图
在配置化核对场景中,系统需要对每条规则的 SQL 进行结构化理解,以识别其涉及的表、字段、条件及参数依赖。 为此,我们在 JSqlParser 的基础上进行了定制化扩展,构建了一个轻量级 SQL 元信息解析引擎,用于生成可视化的血缘关系图。
血缘分析流程:
sql
用户配置 SQL
↓
SQL 解析引擎(基于 JSqlParser)
↓
血缘信息提取(表、字段、条件、参数)
↓
生成血缘关系图最终系统能自动识别出:
ini
【表依赖关系】
order(订单表)
├─ 字段:order_no, order_amount
└─ 查询条件:order_no = '${order_no}'
payment(支付表)
├─ 字段:order_no, payment_amount
└─ 关联条件:order_no = o.order_no3.2.1.3 参数替换机制
SQL 中的占位符会被系统自动识别并替换。例如:
ini
WHERE order_no = '${order_no}'系统解析出占位符:
bash
${order_no}再从 Kafka 消息中提取对应字段:
json
{
"order_no": "20250101001"
}替换后生成最终可执行 SQL:
ini
WHERE order_no = '20250101001'整个过程无需人工干预,完全自动完成参数解析与注入。
3.2.1.4 核心价值:让系统"读懂"SQL
通过定制化 SQL 血缘解析,系统可以自动理解用户配置的 SQL,并生成完整的数据准备与执行逻辑。
对比传统 方式 :
| 传统方式 | SQL配置化 |
|---|---|
| 开发人员手动编写代码,明确数据来源、查询逻辑和比对规则 | 用户只需写 SQL,系统自动识别表、字段、条件和占位符,生成可执行查询 |
| 规则上线依赖开发、测试与发版流程 | 配置即生效,无需额外开发操作 |
| 调整规则需要重复修改代码 | 修改 SQL 即可,自动完成数据准备和逻辑执行 |
总结: SQL 解析与血缘分析让系统自动理解用户规则,完成数据依赖推导与执行准备。
3.2.2 SQL 在线调试与验证(让配置更可靠)
3.2.2.1 如何让用户放心配置 SQL ?
配置 SQL 规则时,用户最担心的是:
❓ SQL 写得对不对?
❓ 能否查到数据?
❓ 查询结果是否符合预期?
❓ 上线后会不会出问题?
如果没有调试能力,用户只能"盲配置",上线后才发现问题,需要来回修改,效率低,风险也大。
3.2.2.2 内置 SQL 在线调试器
我们提供了一个在线 SQL 调试器,让用户在配置规则时就能验证 SQL 的正确性、性能和结果。
SQL 调试流程:
sql
用户在配置页面编写 SQL
↓
输入测试参数(如 order_no)
↓
点击"调试"按钮
↓
系统自动执行:
├─ SQL 安全校验(防止 DROP/DELETE/UPDATE 等危险操作)
├─ 权限校验(检查用户是否有表权限)
├─ SQL 解析(提取表依赖)
├─ 数据查询(从业务库获取真实数据)
├─ 数据加载(写入测试数据库)
└─ SQL 执行(返回查询结果)
↓
用户查看调试结果(查询结果、表使用情况、执行耗时)3.2.2.3 三道安全阀:确保调试可信
-
SQL 安全校验(防破坏)
- 自动拒绝危险操作(DROP、DELETE、UPDATE)
- 防止 SQL 注入与语法异常
- 只允许SELECT查询
-
权限控制(防越权)
- 用户仅能调试有权限的表
- 防止访问敏感数据
-
性能兜底(防慢查)
- 显示 SQL 执行耗时
- 超时提示优化建议
支持两种调试模式:
| 模式 | 描述 | 适用场景 |
|---|---|---|
| 自动查询模式(推荐) | 系统自动从业务库获取数据,只需输入参数 | 大多数场景 |
| 手动编辑输入模式 | 用户可手动输入表数据(JSON) | 边界测试或无真实数据场景 |
3.2.2.4 核心价值:从"盲配置"到"可视化验证"
对用户:
- 配置前验证,降低上线风险
- 快速发现 SQL 错误,节省时间
- 验证实际数据匹配情况,增强规则可信度
对系统:
- 减少错误配置,降低线上问题
- 提升用户体验
总结:从"盲配置" → "可视化验证",让"配置即规则"真正可信、可用、可持续。
3.2.3 数据指纹驱动的分组执行(让多规则高效协同)
3.2.3.1 多规则重复查询问题
一个订单创建事件可能触发多条核对规则:
- 规则 1:订单金额核对(查询 order WHERE order_no='1001')
- 规则 2:优惠金额核对(查询 order WHERE order_no='1001')
- 规则 3:状态核对(查询 order WHERE status='PAID')
如果每个规则独立查询,会产生重复查询 IO:
ini
规则 1 → 查询 order (order_no='1001') → 100ms
规则 2 → 查询 order (order_no='1001') → 100ms ← 重复查询!
规则 3 → 查询 order (status='PAID') → 100ms
总耗时:300ms,且有 1 次重复查询3.2.3.2 数据指纹分组策略
我们通过 SQL 血缘分析,提取每个规则的"数据指纹"(表 + WHERE 条件),将"数据指纹相同"的规则分为一组:
步骤 1:提取数据指纹
ini
规则 1:订单金额核对
数据指纹:order WHERE order_no='1001'
规则 2:优惠金额核对
数据指纹:order WHERE order_no='1001' ← 与规则 1 相同
规则 3:状态核对
数据指纹:order WHERE status='PAID' ← 条件不同步骤 2:数据指纹分组(按数据指纹)
相同指纹 → 同一组(共享数据)
不同指纹 → 不同组(独立查询)
ini
分组 1:规则 1 + 规则 2
数据指纹:order WHERE order_no='1001'
共享策略:只查询一次,两个规则复用同一份数据快照
分组 2:规则 3
数据指纹:order WHERE status='PAID'
独立查询:指纹不同,需单独查询步骤 3:执行流程(数据共享 + 组内并行)
组内并行:相同指纹规则共享数据快照并行执行
组间串行:不同指纹组按顺序执行,避免资源冲突

核心价值:
- 减少重复查询:相同数据指纹只查一次,N 个规则 → M 次查询(M ≤ N)
- 组内并行加速:同组规则共享数据、并行执行,单组吞吐倍增
- 稳定可控:组间串行避免并发冲突,资源消耗可预期,不会因规则增多导致系统不稳定
总结:通过数据指纹分组与并行执行,实现高效、稳定的多规则协同处理。
3.2.4 内存快照隔离(让执行更安全)
3.2.4.1 为什么不直接用 MySQL?
从技术选型角度看,核对计算的场景与传统业务库存在明显差异。如果直接使用 MySQL,我们需要额外维护一套核对专用库,并同步所有业务表结构。这会带来几个问题:
- 资源浪费:核对任务通常只需在执行期间保存数据,结果生成后即可释放,不具备长期存储价值。
- 性能瓶颈:核对查询往往涉及多表关联与聚合,执行频繁且瞬时并发高,对计算与内存性能要求远超 MySQL 的事务型设计。
- 维护复杂:需要持续同步源表结构与数据,还要处理索引、空间膨胀与跨库依赖等问题。
基于这些限制,我们将执行引擎选型方向转向 MariaDB 内存数据库 。 它兼容 MySQL 生态,却以内存为计算核心,支持快速加载、计算与释放数据,非常契合"短生命周期、高性能计算"的特征。
3.2.4.2 内存快照 + 池化隔离
我们采用 MariaDB 内存数据库 + 池化管理 实现隔离计算,执行流程如下:
 执行链路:
执行链路:
sql
步骤 1:事件触发 → 匹配规则 → 解析 SQL 血缘图
↓
步骤 2:根据数据指纹分组,从多个业务库(MySQL/接口/...)拉取数据
→ 从池中租借一个空闲的 MariaDB 实例(独占)
→ 将拉取的跨库数据统一写入该 MariaDB 实例(实现数据汇聚)
↓
步骤 3:在该实例内执行规则 SQL(支持跨表 JOIN/聚合)
↓
步骤 4:获取执行结果 → 清理实例内数据 → 归还实例到池中(供下次复用)
↓
步骤 5:触发告警核心优势:
- 池化隔离:每个任务独占实例,彻底隔离计算,避免对线上库产生任何影响,实例池按需伸缩,支持高并发任务
- 跨库整合:多源数据在内存实例中汇聚,支持高效跨库 JOIN 与聚合计算,简化复杂规则执行;
- 轻量高性能:内存实例与优化参数加速数据访问,实现高吞吐量与低延迟,满足高 QPS 需求。
总结:通过 MariaDB 内存快照 + 池化管理,核对计算高性能、低成本,并实现跨库安全隔离。通过"空间换安全",计算更加灵活。
四、成果与实践总结
4.1 成果
- 配置效率:天级 → 分钟级 通过 SQL 配置化与在线调试,规则上线周期从原先的 2--3 天缩短至分钟级别。过去依赖开发、测试和发版,而现在仅需编写 SQL 并在线验证即可,交付效率提升约 95%以上。
- 成本节约:免开发与发版 SQL 配置化消除了开发、测试和发版环节,规则配置即可生效,显著降低人力成本与等待时间。
- 数据复用:规则越多,越高效 系统通过"数据指纹分组 + 共享快照"机制,让同一事件下的多条规则共享查询结果,避免重复查询;同组规则并行执行,节省 CPU 与 I/O 资源;规则数越多,复用率越高,边际成本越低。
4.2 实践总结
技术层面:
- SQL 配置化与动态执行:规则无需硬编码
- 内存数据库加速:降低对业务库影响,提高计算效率
- 智能并行执行:多规则共享数据、并行执行,提升性能
- 完善告警与重试机制:规则执行更可靠
业务层面:
- 配置效率大幅提升,核对规则从天级缩短到分钟级
- 降低人工成本,减少配置和维护工作量
- 数据复用显著:同一事件下多条规则共享查询结果,减少重复计算
五、展望
5.1 未来优化方向
- 可视化配置界面: 拖拽式配置、字段提示与校验、自动生成 SQL,降低使用门槛并减少配置错误
- AI 辅助规则生成:通过自然语言描述规则,系统自动识别字段关系并生成 SQL,简化规则创建
- 实时监控大屏: 核对状态、告警趋势和规则统计可视化,快速发现异常,提升资金运营安全
发展方向总结:未来平台将朝着"零门槛、智能化、可视化"的方向发展,使规则配置更高效、更安全,同时降低人工成本和维护复杂度。