使用 FastAPI 构建大模型应用的系统教程(工程化实战指南)
本文面向希望将大语言模型(LLM)能力落地为可部署服务的工程师、算法开发者与AI产品研发团队。我们将以 FastAPI 为核心框架,从架构设计、代码组织、配置治理、Prompt管理、模型集成、到部署监控,全流程讲解如何构建一个高性能、可维护的大模型应用系统。

一、为什么选择 FastAPI 构建大模型应用
FastAPI 是当下最受欢迎的 Python Web 框架之一,它具有以下特性,使其非常适合承载大模型应用:
| 特性 | 优势 |
|---|---|
| 异步高性能 | 基于 Starlette 和 uvicorn,轻量且支持并发IO,适合大模型推理和外部API调用 |
| 类型安全 | 内建 Pydantic 校验,自动生成 OpenAPI 文档 |
| 结构清晰 | 支持模块化路由与依赖注入,方便构建可扩展架构 |
| 易于部署 | 与 Docker、Gunicorn 等无缝集成,适合云端部署与微服务化 |
| 生态完善 | 拥有强大的中间件系统,可与日志、监控、鉴权体系集成 |
在大模型场景中,FastAPI 通常作为「推理服务层」的核心框架,用于封装模型调用、Prompt管理、知识检索、上下文拼接、RAG推理、会话管理等逻辑。
二、系统架构与分层设计
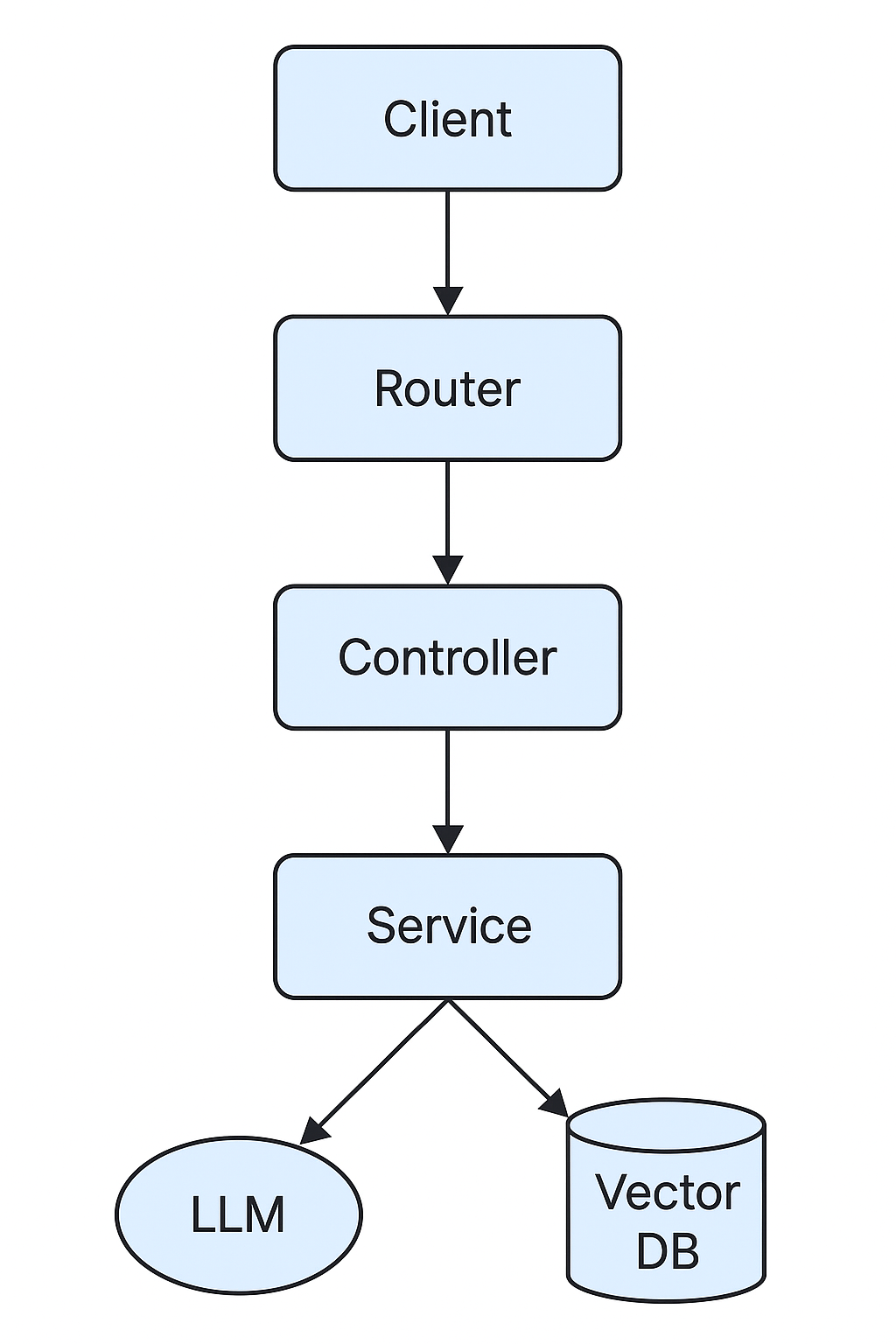
构建一个高质量的 LLM 应用,需要将"算法逻辑"与"工程架构"解耦。推荐采用以下五层结构:
app/
├── api/
│ ├── routes/ # URL 映射定义层(接口声明)
│ └── controllers/ # 控制层(请求逻辑、调用 service)
├── services/ # 业务逻辑层(模型推理、数据访问)
├── models/ # 数据结构与Pydantic模型
├── prompts/ # Prompt 模板与版本管理
├── config/ # 配置与环境变量
├── middlewares/ # 中间件(日志、trace、鉴权等)
├── registry/ # 业务注册表(案由/场景/模型配置)
├── utils/ # 工具函数(缓存、日志、通用方法)
└── main.py # 应用入口这种架构的优点是:
- 逻辑解耦:接口层、逻辑层、模型层职责单一;
- 模块复用:Service 可被多个 Controller 复用;
- 可扩展性强:新增模型、场景或Prompt不影响核心逻辑;
- 测试友好:单元测试与接口测试层次清晰。
三、FastAPI 核心机制详解
1️⃣ Router 模块化路由
FastAPI 使用 APIRouter 实现模块化注册,每个功能模块独立定义,最终统一挂载到应用中。
python
# api/routes/chat_routes.py
from fastapi import APIRouter
from api.controllers.chat_controller import chat_completion
router = APIRouter(prefix="/chat", tags=["Chat"])
@router.post("/completion")
async def completion(request: dict):
return await chat_completion(request)在主应用中注册:
python
# main.py
from fastapi import FastAPI
from api.routes import chat_routes
app = FastAPI(title="LLM Application")
app.include_router(chat_routes.router)✅ 最终路径为:POST /chat/completion
2️⃣ 控制层(Controller)
Controller 负责请求调度、调用 service 层逻辑、封装响应结构:
python
# api/controllers/chat_controller.py
from services.llm_service import generate_reply
from models.response import ChatResponse
async def chat_completion(request: dict) -> ChatResponse:
prompt = request.get("prompt", "")
response_text = await generate_reply(prompt)
return ChatResponse(result=response_text)3️⃣ 业务层(Service)
Service 层负责调用模型或外部服务,是核心业务逻辑的载体。
python
# services/llm_service.py
import httpx
from config.settings import settings
async def generate_reply(prompt: str):
async with httpx.AsyncClient(timeout=60) as client:
resp = await client.post(
settings.LLM_ENDPOINT,
json={"prompt": prompt, "temperature": 0.8}
)
return resp.json().get("output", "")4️⃣ 数据模型(Models)
Pydantic 模型确保请求和响应的数据安全与一致性。
python
# models/response.py
from pydantic import BaseModel
class ChatResponse(BaseModel):
result: str
model: str = "qwen-30b"5️⃣ 生命周期(Lifespan)
统一管理启动与关闭逻辑,如加载模型、连接数据库、注册向量库。
python
from contextlib import asynccontextmanager
from fastapi import FastAPI
import logging
@asynccontextmanager
async def lifespan(app: FastAPI):
logging.info("🔧 Loading models and cache...")
yield
logging.info("🧹 Releasing resources...")
app = FastAPI(lifespan=lifespan)6️⃣ 中间件与异常处理
- 中间件可用于日志、trace_id、鉴权;
- 异常处理器统一错误响应格式。
python
# middlewares/logging_middleware.py
from starlette.middleware.base import BaseHTTPMiddleware
import time, logging
class RequestLoggerMiddleware(BaseHTTPMiddleware):
async def dispatch(self, request, call_next):
start = time.time()
response = await call_next(request)
logging.info(f"{request.method} {request.url.path} - {time.time() - start:.2f}s")
return response
# main.py
from middlewares.logging_middleware import RequestLoggerMiddleware
app.add_middleware(RequestLoggerMiddleware)四、Prompt 与配置的工程化管理
1️⃣ Prompt 模板文件化
不要将 Prompt 写死在代码中,而应独立管理:
prompts/
├── summarize/
│ └── v1.yaml
└── classify/
└── v2.yaml内容:
yaml
version: 1.0
input_vars: ["context"]
template: |
请总结以下内容:
{context}加载器:
python
import yaml, os
class PromptLoader:
def __init__(self, base_path="prompts"):
self.base_path = base_path
def get(self, name, version="v1"):
path = os.path.join(self.base_path, name, f"{version}.yaml")
with open(path, "r", encoding="utf-8") as f:
return yaml.safe_load(f)2️⃣ 配置文件与环境管理
使用 pydantic-settings 实现多环境可切换配置:
python
# config/settings.py
from pydantic_settings import BaseSettings
class Settings(BaseSettings):
LLM_ENDPOINT: str
MILVUS_HOST: str
DEBUG: bool = True
class Config:
env_file = ".env"
settings = Settings().env 文件:
LLM_ENDPOINT=https://api.llm.local/infer
MILVUS_HOST=127.0.0.1
DEBUG=True五、大模型接口集成与优化建议
1️⃣ 集成通用模型 API(如 OpenAI / Qwen / Claude)
python
import httpx
async def call_openai(prompt):
async with httpx.AsyncClient() as client:
response = await client.post(
"https://api.openai.com/v1/chat/completions",
headers={"Authorization": f"Bearer {API_KEY}"},
json={"model": "gpt-4o", "messages": [{"role": "user", "content": prompt}]}
)
return response.json()["choices"][0]["message"]["content"]2️⃣ 增加缓存与异步队列
- 可使用
asyncio.create_task或Celery实现并发生成; - 使用
Redis做请求缓存与去重。
3️⃣ 向量检索 + RAG 示例
结合 Milvus、pgvector 等检索模块:
python
# services/rag_service.py
def search_similar_docs(query_vector, collection):
results = collection.search(
data=[query_vector],
anns_field="embedding",
param={"metric_type": "L2", "params": {"ef": 64}},
limit=3,
output_fields=["content"]
)
return [hit.entity.get("content") for hit in results[0]]六、部署与生产实践
| 环境 | 启动方式 | 说明 |
|---|---|---|
| 开发环境 | uvicorn main:app --reload |
自动重载,适合调试 |
| 生产环境 | gunicorn -k uvicorn.workers.UvicornWorker -w 4 main:app |
高并发部署 |
| 容器化部署 | Dockerfile 构建 | 便于跨环境迁移 |
| CI/CD | GitHub Actions / GitLab CI | 自动化测试与部署 |
| 监控 | Prometheus + Grafana / ELK | 日志与性能监控 |
七、总结:构建「可维护的大模型服务」
一个优秀的大模型应用,不仅仅是能调用模型,更要具备 结构清晰、可扩展、易部署、可治理 的工程特性。
| 模块 | 核心目标 |
|---|---|
| FastAPI + Router | 模块化结构、清晰路由 |
| Controllers / Services 分层 | 职责单一、逻辑复用 |
| Prompt Registry | 模板化、版本化、动态加载 |
| Config Layer | 统一配置与环境管理 |
| Middleware & Exception | 可观测与可恢复 |
| Packaging & CI/CD | 工程可维护与可交付 |
结语
FastAPI 并不仅仅是"一个 Web 框架",它是大模型工程化落地的理想中枢。
在它的基础上,我们可以灵活组合异步推理、RAG 检索、Prompt 编排、任务调度等组件,
构建出从单机开发到企业级 AI 服务的完整闭环。
未来的大模型系统竞争,不在于"能不能调用模型",
而在于"能否持续、稳定、优雅地让模型产生价值"------
而这,正是 FastAPI 架构化工程的意义。