Spring Boot异步接口性能优化:从单线程到高并发的优化历程
在现代Web应用开发中,接口性能往往是系统瓶颈的关键所在。特别是当业务逻辑涉及多个外部服务调用时,传统的同步处理方式会导致线程阻塞,严重影响系统吞吐量,因此进行优化。
业务场景描述
用户信息聚合接口需要从三个不同的数据源获取信息:
- 基础信息查询:耗时100ms(数据库查询)
- 详情信息查询:耗时300ms(复杂业务查询)
- 扩展信息查询:耗时500ms(第三方API调用)
这是一个典型的IO密集型场景,同步执行总耗时900ms,而理论上并行执行只需要600ms(基础信息查询必须最先执行后面并行)。
同步版本
java
@GetMapping("/user/sync")
public User getUserSync() throws InterruptedException {
return userService.assembleUser();
}
public User assembleUser() throws InterruptedException {
long startTime = System.currentTimeMillis();
// 1. 获取基础信息(100ms)
Long userId = getUserBaseInfo();
// 2. 获取详细信息(300ms)
UserDetail userDetail = getUserDetailInfo(userId);
// 3. 获取扩展信息(500ms)
UserExtraInfo extraInfo = getUserExtraInfo(userId);
// 组装完整User对象
User user = new User();
user.setId(userId);
user.setName(userDetail.getName());
user.setAge(userDetail.getAge());
user.setSex(userDetail.getSex());
user.setPhone(extraInfo.getPhone());
user.setLevel(extraInfo.getLevel());
System.out.println("用户对象组装完成,总耗时: " + (System.currentTimeMillis() - startTime) + "ms");
return user;
}测试结果:
- 单次调用耗时:~900ms
- 同步结果: User(id=1001, name=张三, age=25, sex=1, level=VIP会员, phone=13800138000)
异步并行
意识到这三个查询之间存在依赖关系(详情和扩展信息都需要userId),我设计了一个并行执行方案:
java
@GetMapping("/user/async-ultra")
public User getUserAsyncUltra() throws Exception {
return userService.assembleUserUltraPerformance();
}
public User assembleUserUltraPerformance() throws Exception {
long startTime = System.currentTimeMillis();
// 先获取基础信息
CompletableFuture<Long> baseInfoFuture = CompletableFuture.supplyAsync(() -> {
try {
return getUserBaseInfo();
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new RuntimeException(e);
}
}, highPerformanceExecutor);
// 基于baseInfo并行获取详情和扩展信息
CompletableFuture<UserDetail> detailFuture = baseInfoFuture.thenApplyAsync(userId -> {
try {
return getUserDetailInfo(userId);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new RuntimeException(e);
}
}, highPerformanceExecutor);
CompletableFuture<UserExtraInfo> extraFuture = baseInfoFuture.thenApplyAsync(userId -> {
try {
return getUserExtraInfo(userId);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new RuntimeException(e);
}
}, highPerformanceExecutor);
// 等待所有任务完成
CompletableFuture<Void> allTasks = CompletableFuture.allOf(baseInfoFuture, detailFuture, extraFuture);
allTasks.get();
// 获取结果并组装(此时所有任务都已完成,不会阻塞)
Long userId = baseInfoFuture.get();
UserDetail detail = detailFuture.get();
UserExtraInfo extra = extraFuture.get();
User user = new User();
user.setId(userId);
user.setName(detail.getName());
user.setAge(detail.getAge());
user.setSex(detail.getSex());
user.setPhone(extra.getPhone());
user.setLevel(extra.getLevel());
System.out.println("极致性能组装完成,总耗时: " + (System.currentTimeMillis() - startTime) + "ms");
return user;
}测试结果:
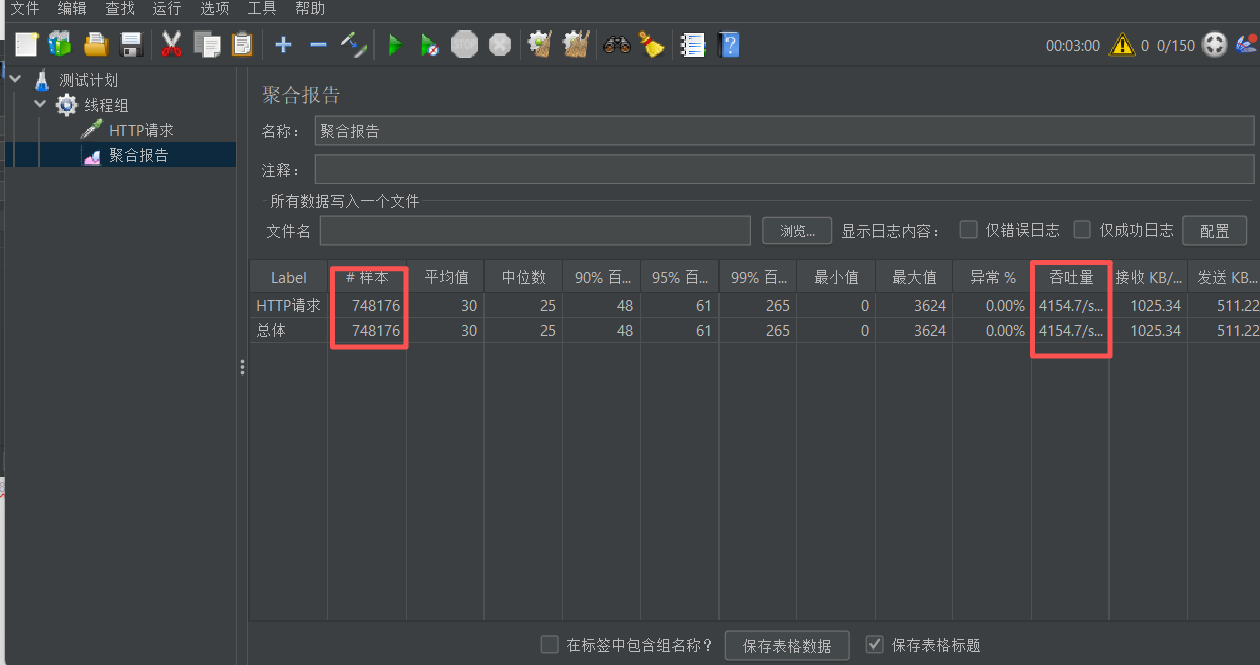
- 单次调用耗时:~600ms(相比同步版本提升33%)
- 异步结果: User(id=1001, name=张三, age=25, sex=1, level=VIP会员, phone=13800138000)
对比结果如下图:

问题发现:高并发下的性能反转
虽然单次调用异步版本更快,但在JMeter压测中却发现了一个令人困惑的现象:在高并发场景下,异步接口的吞吐量竟然没有明显提升!
压测环境
- 硬件配置:8核CPU,16GB内存
- JMeter配置 :150并发线程,60秒Ramp-up,180秒持续时间
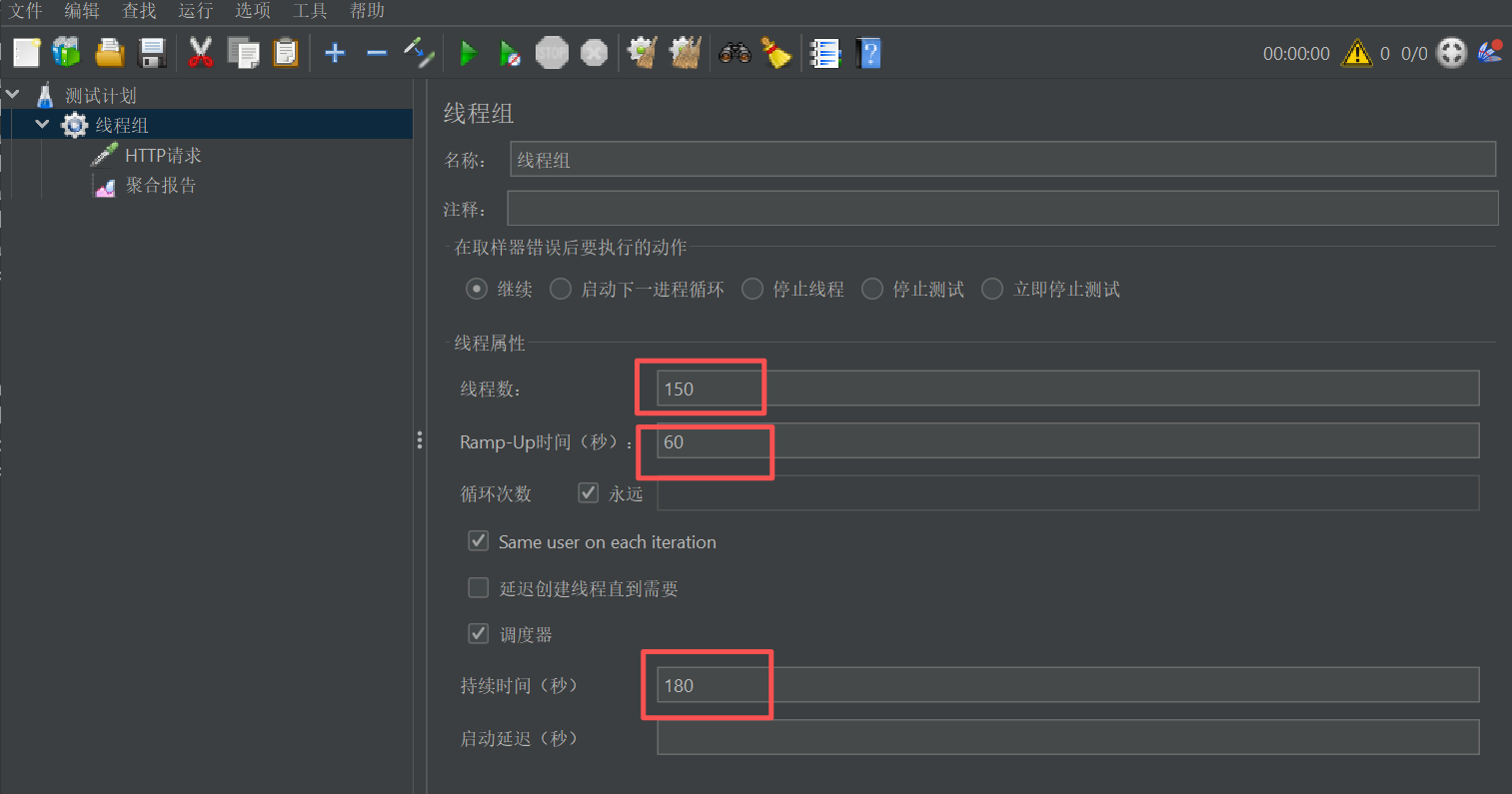
压测结果如下图:
同步压测结果如图:
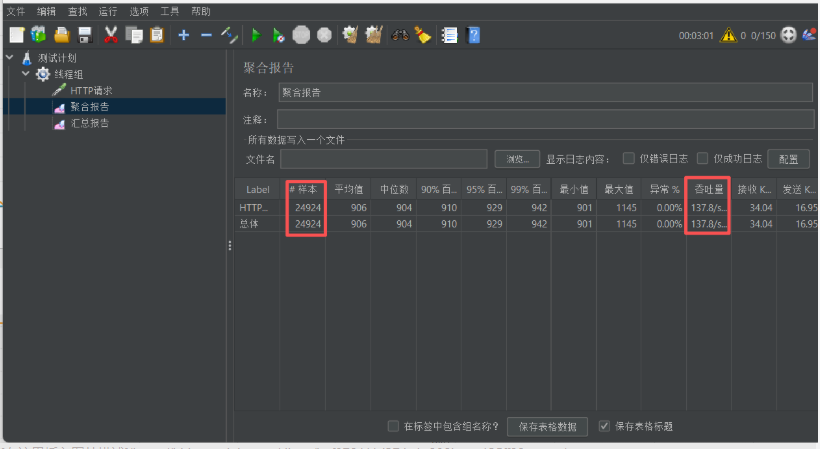
异步压测结果如图:
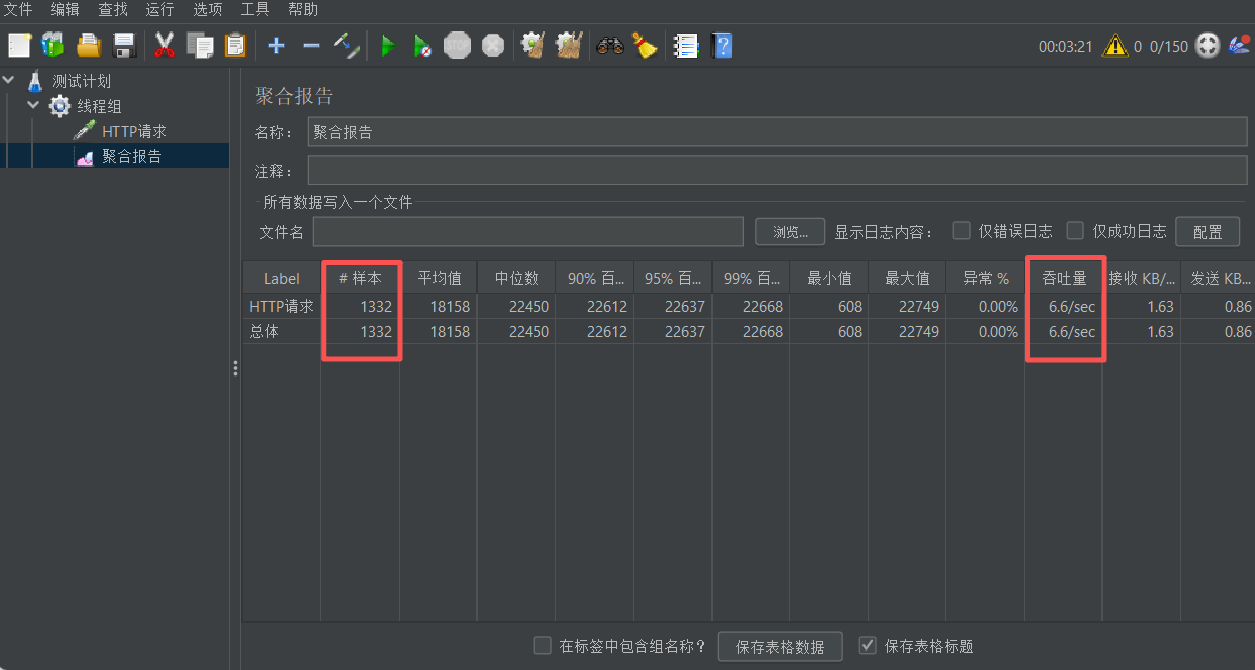
而且最严重的是:异步接口耗时时间显著增加
开始日志打印: 极致性能组装完成,总耗时: 601ms-711ms
后期日志打印: 极致性能组装完成,总耗时: 22441ms-22632ms
个人分析:
- 150并发请求同时到达
- 每个请求需要3个线程(baseInfo + detail + extra)
- 理论需要: 150 × 3 =450个线程 实际只有: 最大12个线程
- 线程严重不足!
线程池
初始的线程池配置:
java
@Bean("highPerformanceExecutor")
public ThreadPoolTaskExecutor highPerformanceExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
// 更保守的配置,减少线程切换
executor.setCorePoolSize(6); // 略小于CPU核数
executor.setMaxPoolSize(12); // CPU核数 * 1.5
executor.setQueueCapacity(500);
executor.setKeepAliveSeconds(30);
executor.setThreadNamePrefix("HighPerf-");
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
executor.initialize();
return executor;
}在150并发下,这个配置导致了严重的线程竞争。
线程池参数调优
java
@Bean("highPerformanceExecutor")
public ThreadPoolTaskExecutor highPerformanceExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
// 针对高并发调整
executor.setCorePoolSize(50); // 增加核心线程
executor.setMaxPoolSize(150); // 增加最大线程
executor.setQueueCapacity(50); // 减小队列,快速扩展线程
executor.setKeepAliveSeconds(60);
executor.setThreadNamePrefix("HighPerf-");
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
executor.initialize();
return executor;
}压测结果如下:可以看到吞吐量得到了明显提升
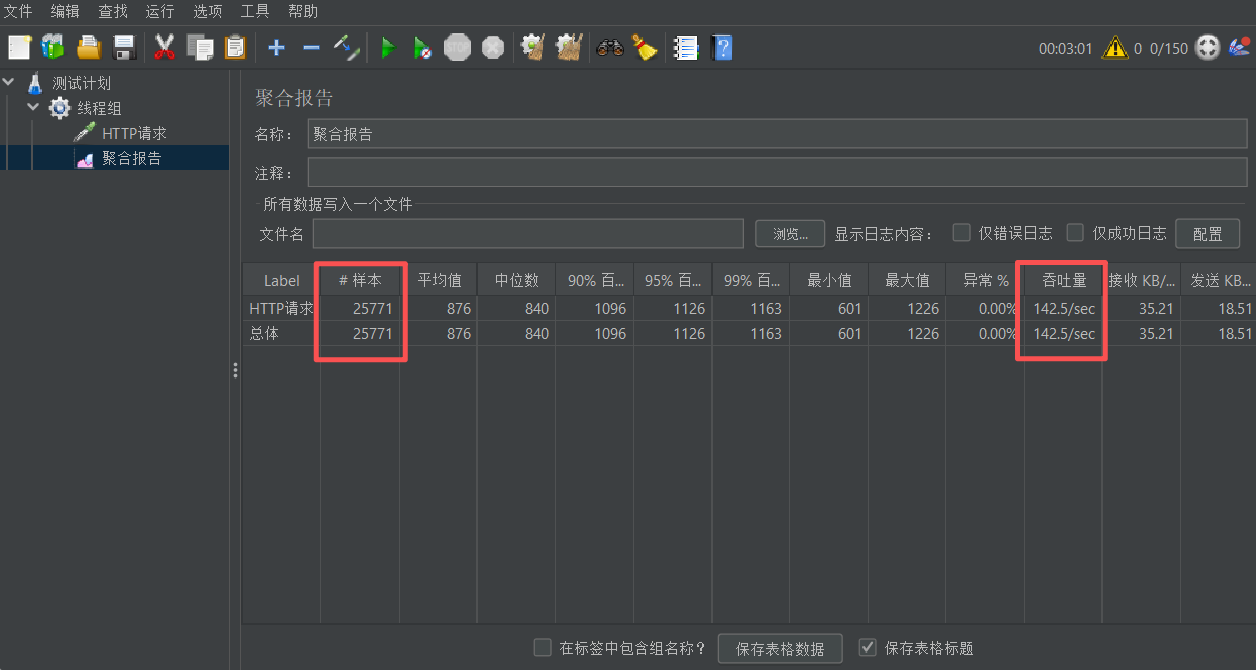
数据对比:
同步接口: 137 TPS
异步接口(优化前): 6.6 TPS
异步接口(优化后): 142 TPS
关键发现:
异步接口TPS提升了 2050% (142/6.6)
相比同步接口提升了 3.6% (142/137)
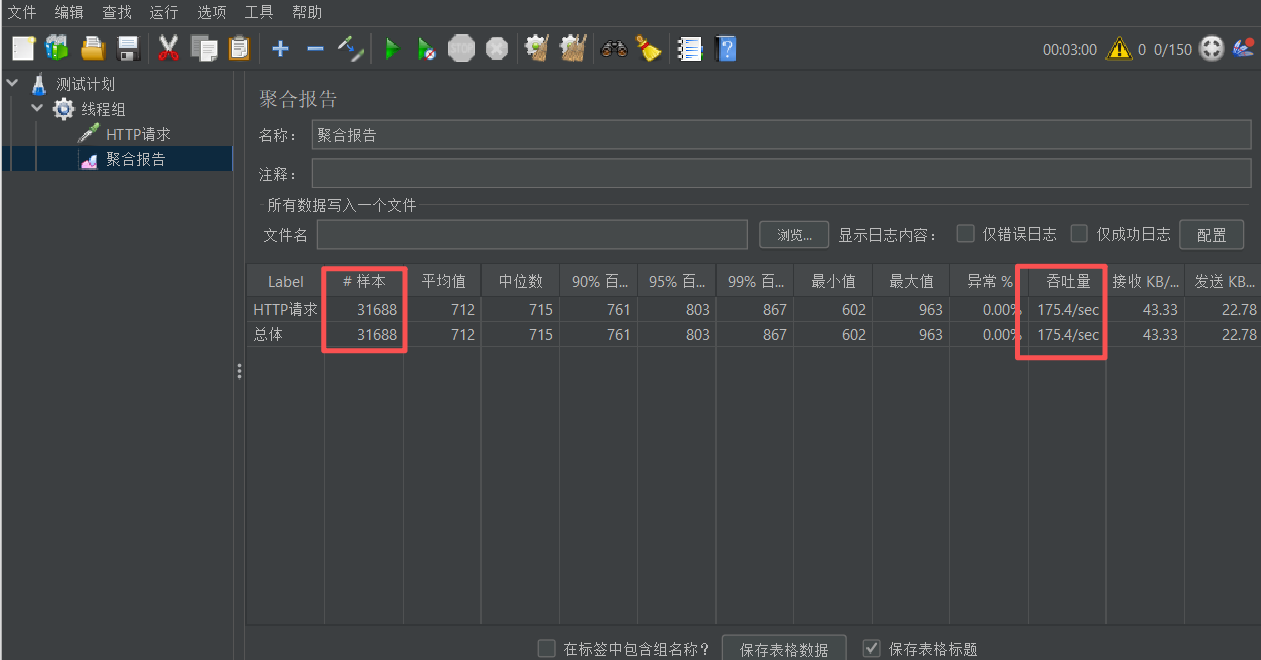
继续增大线程数压测如下图: 吞吐量提升到了175
java
@Bean("highPerformanceExecutor")
public ThreadPoolTaskExecutor highPerformanceExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
// 针对高并发调整
executor.setCorePoolSize(100); // 增加核心线程
executor.setMaxPoolSize(300); // 增加最大线程
executor.setQueueCapacity(50); // 减小队列,快速扩展线程
executor.setKeepAliveSeconds(60);
executor.setThreadNamePrefix("HighPerf-");
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
executor.initialize();
return executor;
}
分析:
不是设置得越高越好!虽然提升了吞吐量,但隐藏着很大的风险。这是一个典型的"用资源换性能"的策略,需要谨慎使用,而且后期的接口响应时间明显增加
1.🎯
每个线程栈大小:1MB (默认)
300个线程:300MB 栈内存
加上堆内存、方法区等:总内存需求激增
- OutOfMemoryError
- 频繁Full GC导致STW(Stop The World)
- 系统响应变慢
2.📊
理想情况:8个线程同时运行
300个线程:需要频繁的上下文切换
切换成本:每次切换消耗几微秒到几毫秒
- 轻微的压力就会创建大量线程,但线程数远远超过CPU处理能力
- CPU利用率虚高但实际处理能力下降
- 系统整体性能下降
3⚡
高并发(500+)下:严重不足
实际需求:500 × 3 = 1500个线程
结果:大量任务被CallerRunsPolicy拒绝,回到主线程执行
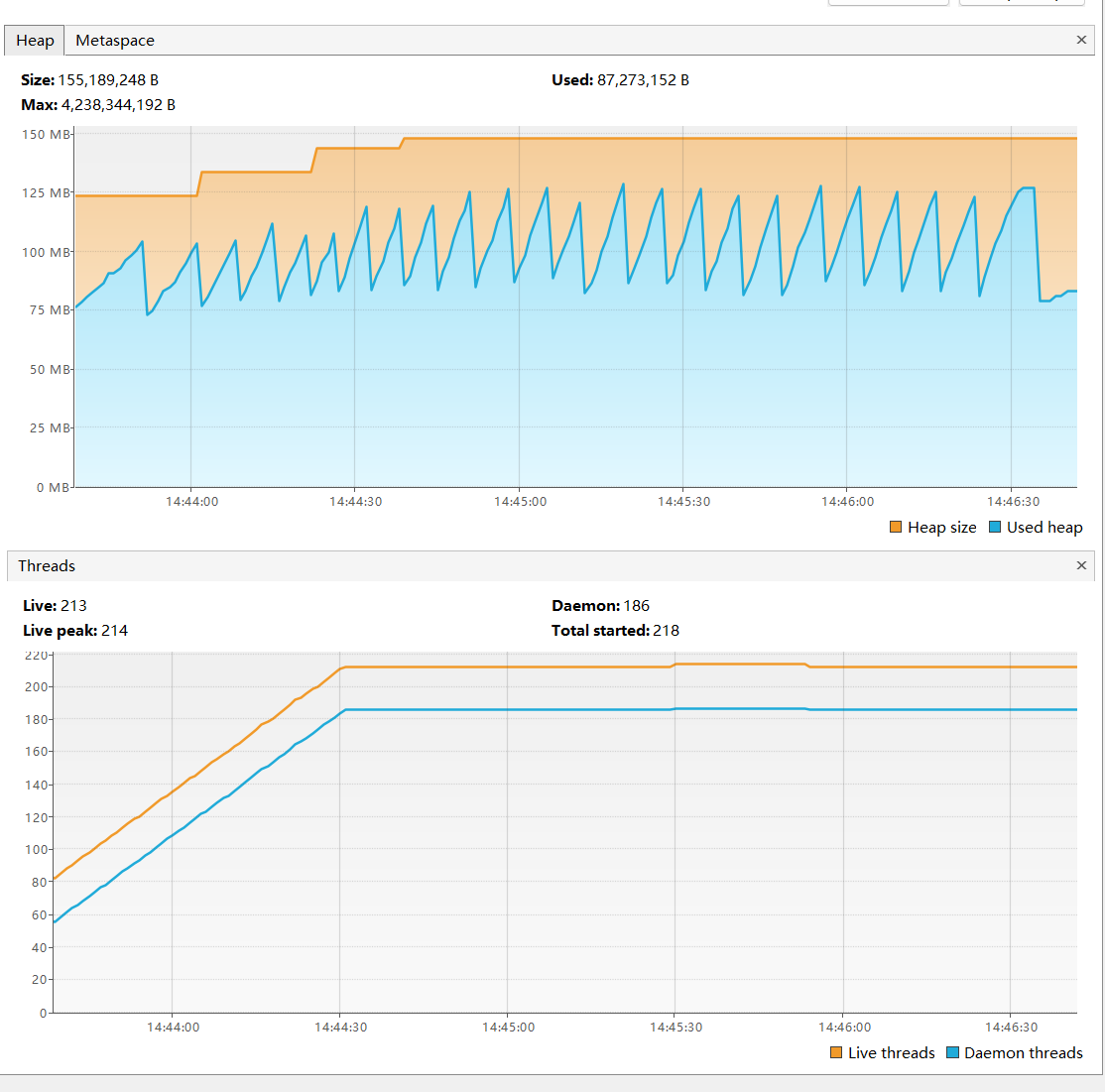
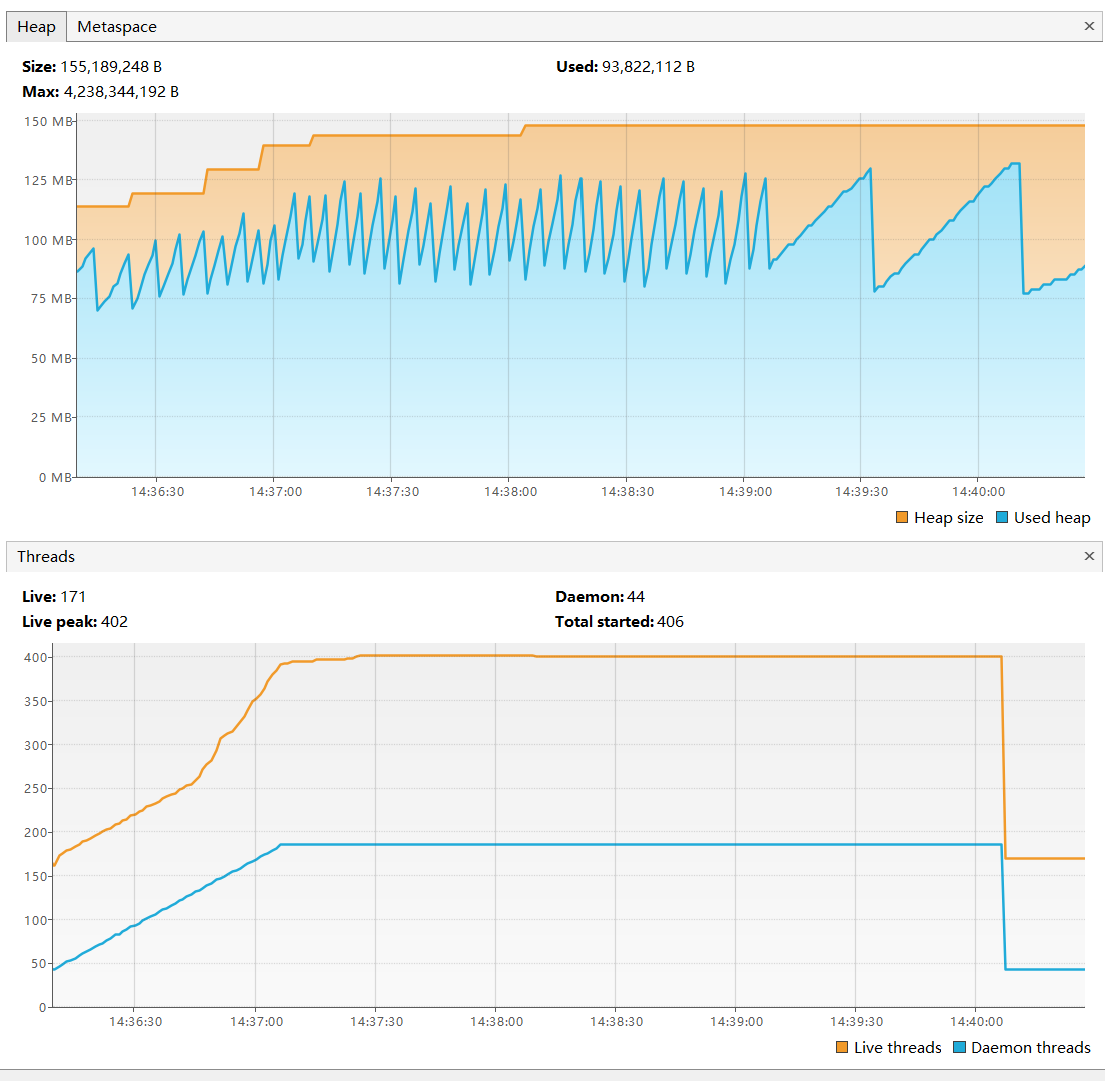
使用JVisualVM分析
- 线程数量激增:异步版本创建了大量线程
- CPU上下文切换频繁:8核CPU的上下文切换成为瓶颈
- 内存使用增加:每个线程占用约1MB栈空间
同步分析:
异步分析:
jvm参数增加堆的内存大小:-Xmx2g -Xms2g ,继续测试如下:

再次压测异步:
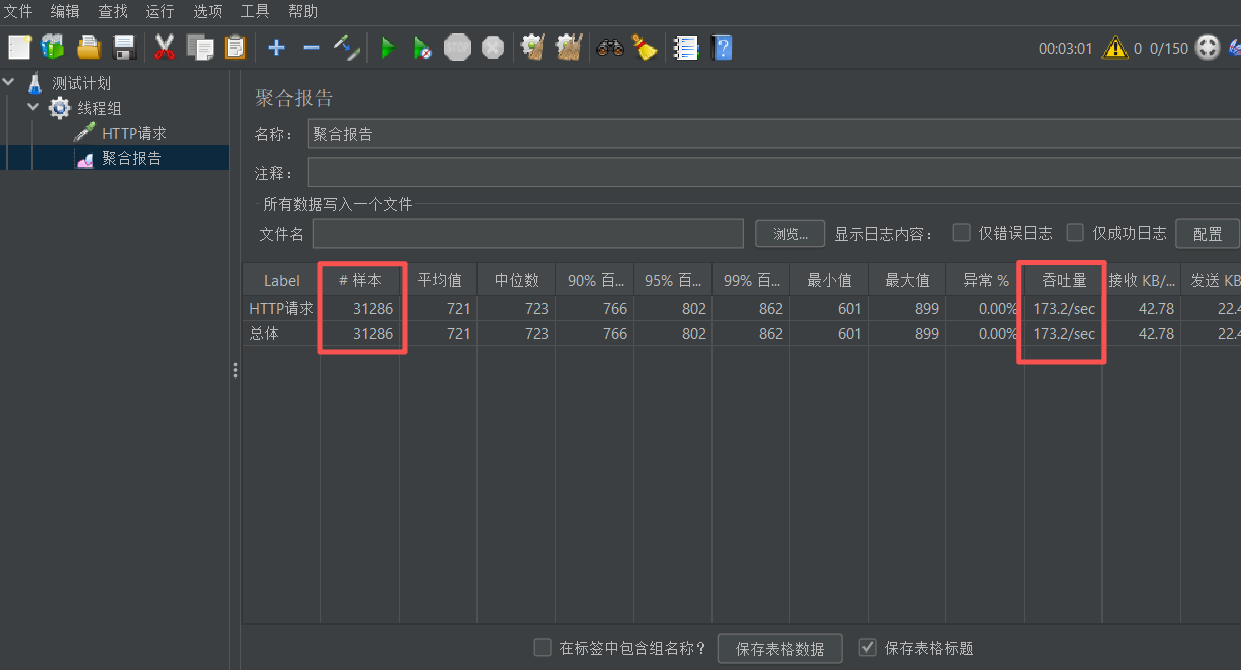
吞吐量前后差别不大,通过内存分析工具分析,之前的内存已经够用,GC发生次数也不多,内存增加反而可能带来负面影响:
- GC暂停时间变长:虽然频率降低,但每次Full GC时间可能从100ms→2s
- 内存扫描成本:G1GC需要扫描整个堆,堆越大扫描时间越长
线程切换次数优化
优化代码:减少一次线程切换
java
public User assembleUserOptimized() throws Exception {
long startTime = System.currentTimeMillis();
// 在当前线程执行最快的任务
Long userId = getUserBaseInfo(); // 100ms,无需异步
// 只对耗时任务异步
CompletableFuture<UserDetail> detailFuture = CompletableFuture.supplyAsync(() -> {
try {
return getUserDetailInfo(userId);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new RuntimeException(e);
}
}, highPerformanceExecutor);
CompletableFuture<UserExtraInfo> extraFuture = CompletableFuture.supplyAsync(() -> {
try {
return getUserExtraInfo(userId);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new RuntimeException(e);
}
}, highPerformanceExecutor);
// 并行等待
UserDetail detail = detailFuture.get();
UserExtraInfo extra = extraFuture.get();
User user = new User();
user.setId(userId);
user.setName(detail.getName());
user.setAge(detail.getAge());
user.setSex(detail.getSex());
user.setPhone(extra.getPhone());
user.setLevel(extra.getLevel());
System.out.println("高性能并行组装完成,总耗时: " + (System.currentTimeMillis() - startTime) + "ms");
return user;
}压测结果如下:确实明显提升了吞吐量
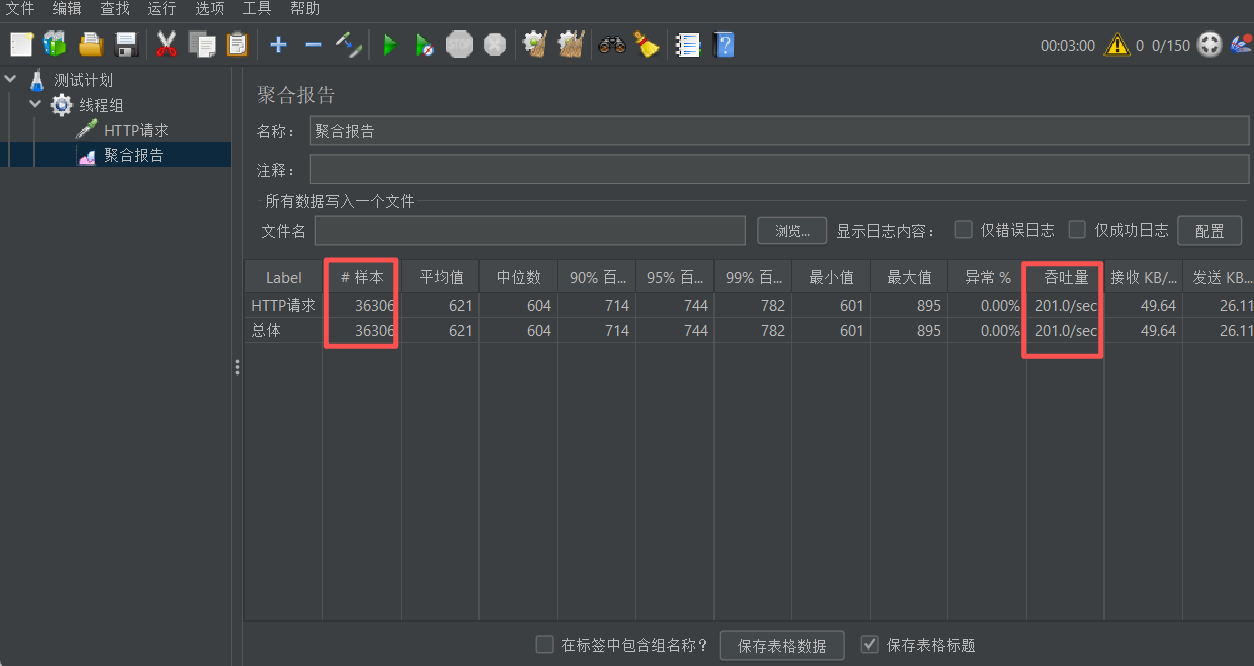
优化Tomcat配置(提升点)
yaml
server:
tomcat:
threads:
max: 300 # 增加最大线程数
min-spare: 50 # 增加最小线程数
accept-count: 200 # 增加连接队列
max-connections: 2000 # 增加最大连接数动态线程池补充
在Java开发中,ThreadPoolExecutor的使用常常面临以下挑战:
- 参数配置难:核心参数凭经验设置,无法精准匹配业务场景
- 调整成本高:参数优化需修改代码重启服务,影响业务连续性
- 运行无感知:线程池负载状态缺乏监控,问题爆发后才能察觉
动态线程池参考:springboot整合动态线程池
虚拟线程
虚拟线程是 Java 中的一种轻量级线程,它旨在解决传统线程模型中的一些限制,提供了更高效的并发处理能力,允许创建数千甚至数万个虚拟线程,而无需占用大量操作系统资源。
虚拟线程与传统线程具有如下几个优势:
- 更加轻量级:虚拟线程相比传统线程更加轻量级。因为它们不是直接映射到操作系统线程上,而是在用户空间内被管理。这种设计减少了线程创建和销毁的开销,允许在同一应用中运行成千上万的线程。
- 资源消耗更少:由于不是直接映射到操作系统线程,虚拟线程显著降低了内存和其他资源的消耗。这使得在有限资源下可以创建更多的线程。
- 上下文切换开销更低:由于虚拟线程在用户空间,而不是通过操作系统,所以它的上下文切换开销更低。
- 改善阻塞操作的处理:在传统线程模型中,阻塞操作(如 I/O)会导致整个线程被阻塞,浪费宝贵的系统资源。然而当一个虚拟线程阻塞时,它可以被挂起,底层的操作系统线程则可以用来运行其他虚拟线程。
- 简化并发编程:可以像编写普通顺序代码一样编写并发代码,而不需要过多考虑线程管理和调度。它简化了 Java 的并发编程模型。
- 提升性能:在 I/O 密集型应用中,虚拟线程能够显著地提升性能。而且由于它们的创建和销毁成本低,能够更加高效地利用系统资源。
参考学习: 虚拟线程
更改代码如下:
java
public User assembleUserVirtualThread() throws Exception {
long startTime = System.currentTimeMillis();
// 在当前线程执行最快的任务
Long userId = getUserBaseInfo(); // 100ms,无需异步
// 使用虚拟线程执行器
try (ExecutorService virtualExecutor = Executors.newVirtualThreadPerTaskExecutor()) {
// 只对耗时任务使用虚拟线程
CompletableFuture<UserDetail> detailFuture = CompletableFuture.supplyAsync(() -> {
try {
return getUserDetailInfo(userId);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new RuntimeException(e);
}
}, virtualExecutor);
CompletableFuture<UserExtraInfo> extraFuture = CompletableFuture.supplyAsync(() -> {
try {
return getUserExtraInfo(userId);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new RuntimeException(e);
}
}, virtualExecutor);
// 并行等待
UserDetail detail = detailFuture.get();
UserExtraInfo extra = extraFuture.get();
User user = new User();
user.setId(userId);
user.setName(detail.getName());
user.setAge(detail.getAge());
user.setSex(detail.getSex());
user.setPhone(extra.getPhone());
user.setLevel(extra.getLevel());
System.out.println("虚拟线程组装完成,总耗时: " + (System.currentTimeMillis() - startTime) + "ms");
return user;
}
}压测结果如下:吞吐量再次得到提升
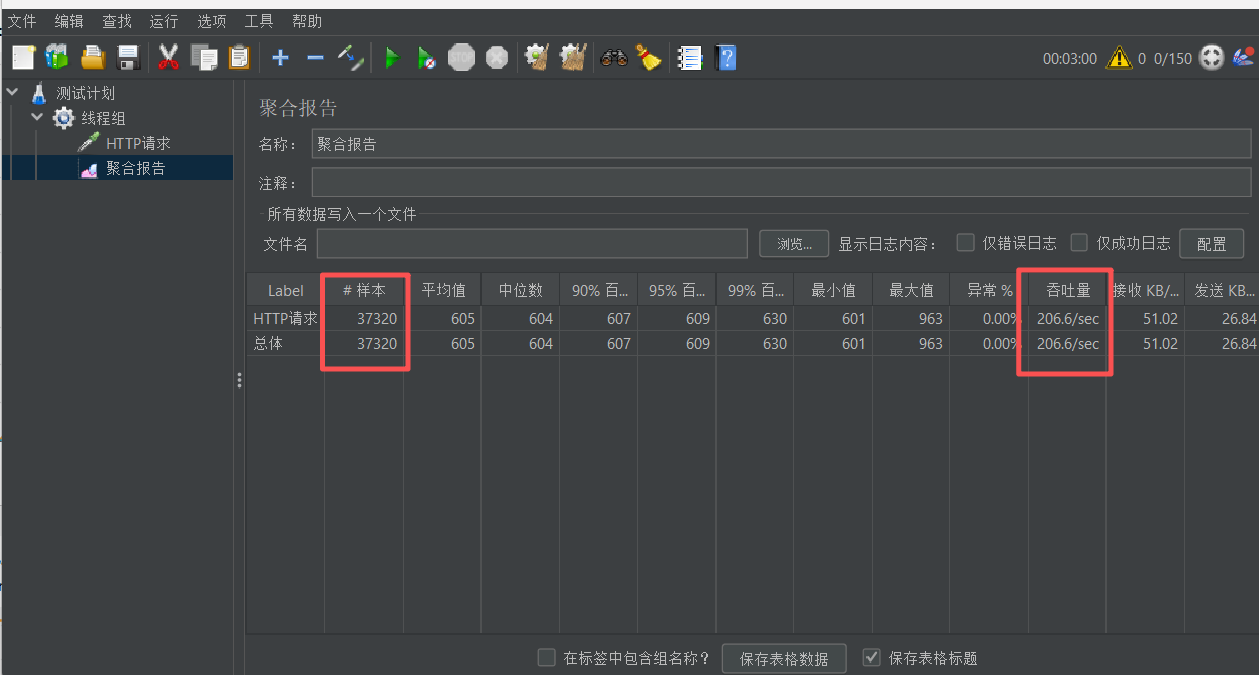
最最最重要的是:上下文切换开销更低:由于虚拟线程在用户空间,而不是通过操作系统,所以它的上下文切换开销更低。
直到压测结束: 接口的耗时时间均为600ms左右,相比之前的传统线程方案,后期的接口响应时间没有增加
虚拟线程组装完成,总耗时: 601ms
虚拟线程组装完成,总耗时: 601ms
虚拟线程组装完成,总耗时: 604ms
虚拟线程组装完成,总耗时: 602ms
虚拟线程组装完成,总耗时: 604ms
虚拟线程组装完成,总耗时: 602ms
虚拟线程组装完成,总耗时: 602ms
虚拟线程组装完成,总耗时: 602ms
虚拟线程组装完成,总耗时: 603ms
虚拟线程组装完成,总耗时: 601ms
虚拟线程组装完成,总耗时: 601ms
Spring WebFlux响应式编程
响应式编程(Reactive Programming)作为一种新的编程范式,解决了传统编程中存在的一些问题,尤其是在高并发和高延迟的场景下。Spring WebFlux 作为 Spring 5 引入的一部分,为开发者提供了一种基于响应式流的编程模型,结合 Reactor 库,能够高效处理异步非阻塞的请求。
参考学习: WebFlux
更改代码如下:
java
@GetMapping("/user/pure-reactive")
public Mono<User> getUserPureReactive() {
return userService.assembleUserWebFluxVirtualOptimized();
}
@Bean("virtualThreadScheduler")
public Scheduler virtualThreadScheduler() {
return Schedulers.fromExecutor(
Executors.newVirtualThreadPerTaskExecutor()
);
}
@Autowired
@Qualifier("virtualThreadScheduler")
private Scheduler virtualThreadScheduler; // 注入全局调度器
public Mono<User> assembleUserWebFluxVirtualOptimized() {
long startTime = System.currentTimeMillis();
return Mono.fromCallable(() -> getUserBaseInfo())
.subscribeOn(virtualThreadScheduler) // 使用注入的调度器
.flatMap(userId -> {
Mono<UserDetail> detailMono = Mono.fromCallable(() -> getUserDetailInfo(userId))
.subscribeOn(virtualThreadScheduler);
Mono<UserExtraInfo> extraMono = Mono.fromCallable(() -> getUserExtraInfo(userId))
.subscribeOn(virtualThreadScheduler);
return Mono.zip(detailMono, extraMono)
.map(tuple -> {
UserDetail detail = tuple.getT1();
UserExtraInfo extra = tuple.getT2();
User user = new User();
user.setId(userId);
user.setName(detail.getName());
user.setAge(detail.getAge());
user.setSex(detail.getSex());
user.setPhone(extra.getPhone());
user.setLevel(extra.getLevel());
System.out.println("优化WebFlux+虚拟线程组装完成,总耗时: " +
(System.currentTimeMillis() - startTime) + "ms");
return user;
});
});
}压测结果如下: 整体相差不大,可能还需要结合其余的场景进行分析
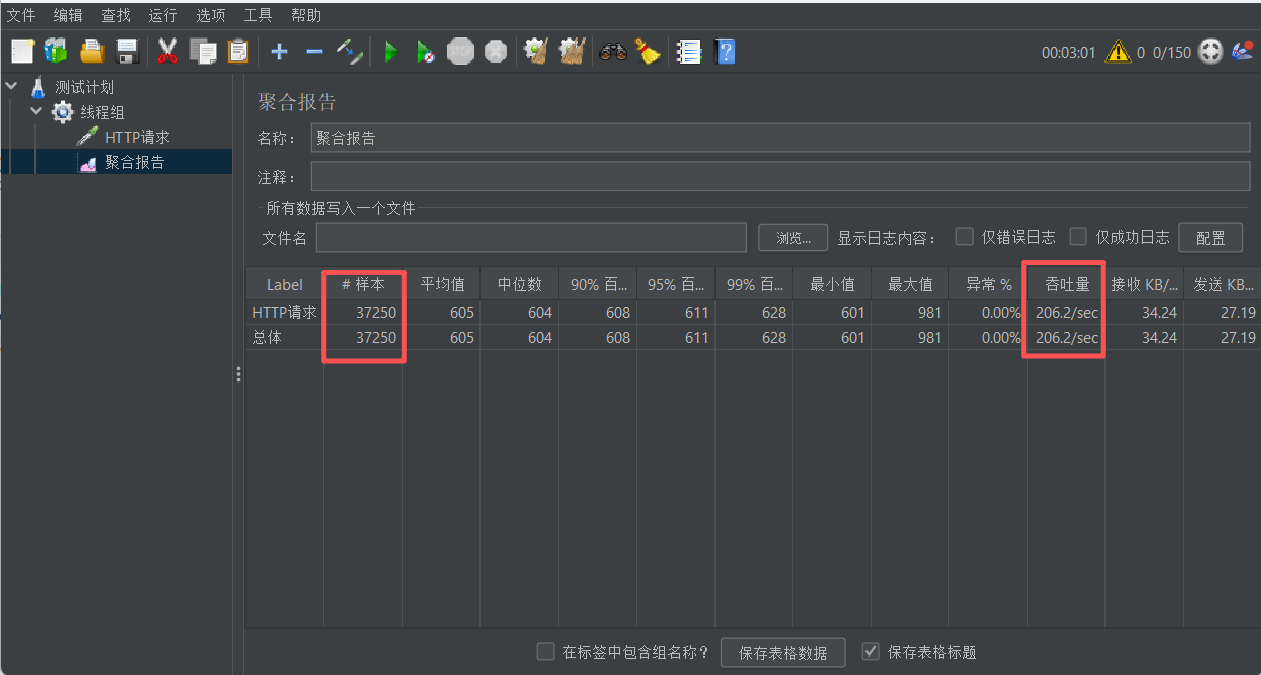
另外:虚拟线程和WebFlux确实是两种完全不同的并发范式,通常不推荐混合使用

纯webFlux版本:
代码更改:
java
@Bean("customScheduler")
public Scheduler customScheduler() {
Scheduler customScheduler = Schedulers.fromExecutor(
Executors.newFixedThreadPool(200, r -> {
Thread t = new Thread(r, "webflux-custom-" + System.currentTimeMillis());
t.setDaemon(true);
return t;
})
);
return customScheduler;
}
@Autowired
@Qualifier("customScheduler")
private Scheduler customScheduler;
public Mono<User> assembleUserCustomSchedulerWebFlux() {
long startTime = System.currentTimeMillis();
// 使用自定义的高性能调度器
return Mono.fromCallable(() -> getUserBaseInfo())
.subscribeOn(customScheduler)
.flatMap(userId -> {
Mono<UserDetail> detailMono = Mono.fromCallable(() -> getUserDetailInfo(userId))
.subscribeOn(customScheduler);
Mono<UserExtraInfo> extraMono = Mono.fromCallable(() -> getUserExtraInfo(userId))
.subscribeOn(customScheduler);
return Mono.zip(detailMono, extraMono)
.map(tuple -> {
UserDetail detail = tuple.getT1();
UserExtraInfo extra = tuple.getT2();
User user = new User();
user.setId(userId);
user.setName(detail.getName());
user.setAge(detail.getAge());
user.setSex(detail.getSex());
user.setPhone(extra.getPhone());
user.setLevel(extra.getLevel());
System.out.println("自定义调度器WebFlux组装完成,总耗时: " +
(System.currentTimeMillis() - startTime) + "ms");
return user;
});
});
}吞吐量测试如下:
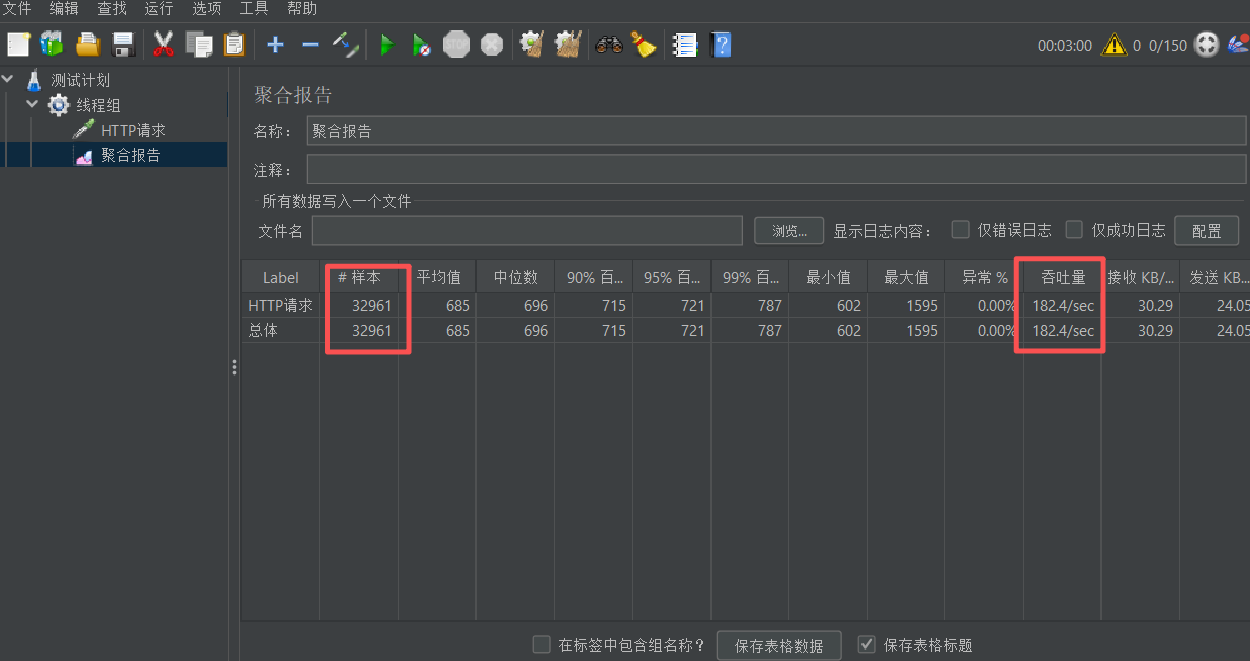
注意:
如果使用了webFlux后启动的一直是Tomcat,可以加入下面代码:
java
@Bean
public org.springframework.boot.web.embedded.netty.NettyReactiveWebServerFactory nettyReactiveWebServerFactory() {
return new org.springframework.boot.web.embedded.netty.NettyReactiveWebServerFactory(9000);
}缓存优化
JetCache 参考学习: SpringBoot3整合JetCache缓存
在同步的代码上加上缓存注解:
java
@GetMapping("/user/async-ultra")
@Cached(name="userCache:", expire = 3600, localExpire = 3500, cacheType = CacheType.BOTH)
public User getUserAsyncUltra() throws Exception {
return userService.assembleUserVirtualThread();
}压测结果如下: 恐怖如斯!!!!