最近 Cursor 发布 2.0 版本,其中一个比较亮点的功能就是它可以同时指挥 8 个 Agent 执行任务,最后选择你觉得最好的那个答案。
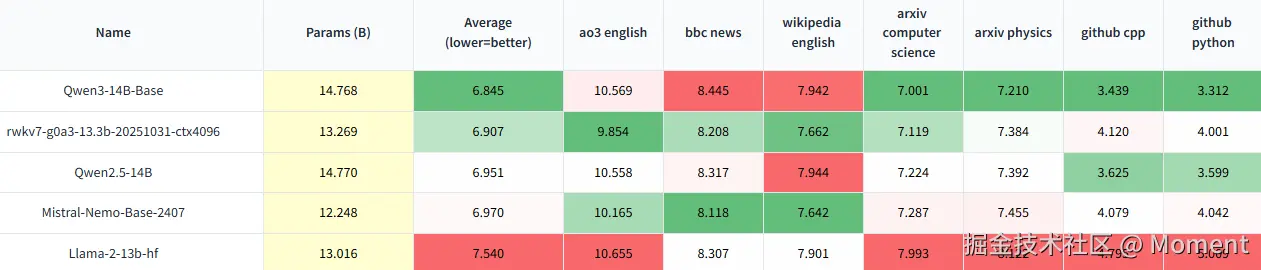
而在底层模型层面,来自中国本土团队的 RWKV 项目也带来了更具突破性的成果:RWKV7-G0a3 13.3B ------当前全球最强的开源纯 RNN 大语言模型。
这一版本以 RWKV6-world-v2.1 14B 为基础,继续训练了 2 万亿 tokens(并融合了 35B 来自 DeepSeek v3.1 的高质量语料),在保持完全 RNN 架构、无注意力机制(No Attention)、无微调、无刷榜的前提下,取得了与主流 Transformer 模型相媲美甚至更优的表现。

在多项权威基准测试中(包括 MMLU、MMLU-Pro、GSM8K、MATH500、CEval 等),RWKV7-G0a3 在语言理解、逻辑推理与数学推演等任务上均实现显著提升。其中,MMLU-Pro 测评显示模型在多学科综合知识上的掌握更加扎实;GSM8K 与 MATH500 结果表明,其在中高难度数学与逻辑问题上的推理能力已达到同规模模型的领先水平。与此同时,RWKV7-G0a3 继续保持了 RWKV 系列一贯的高推理效率与低显存占用优势,展现出纯 RNN 架构在大模型时代下的强大潜力。
Uncheatable Eval 使用最新的论文、新闻、代码与小说等实时数据进行评测,通过"压缩率"(即 Compression is Intelligence)指标,衡量模型在真实语料下的语言建模能力与泛化水平。
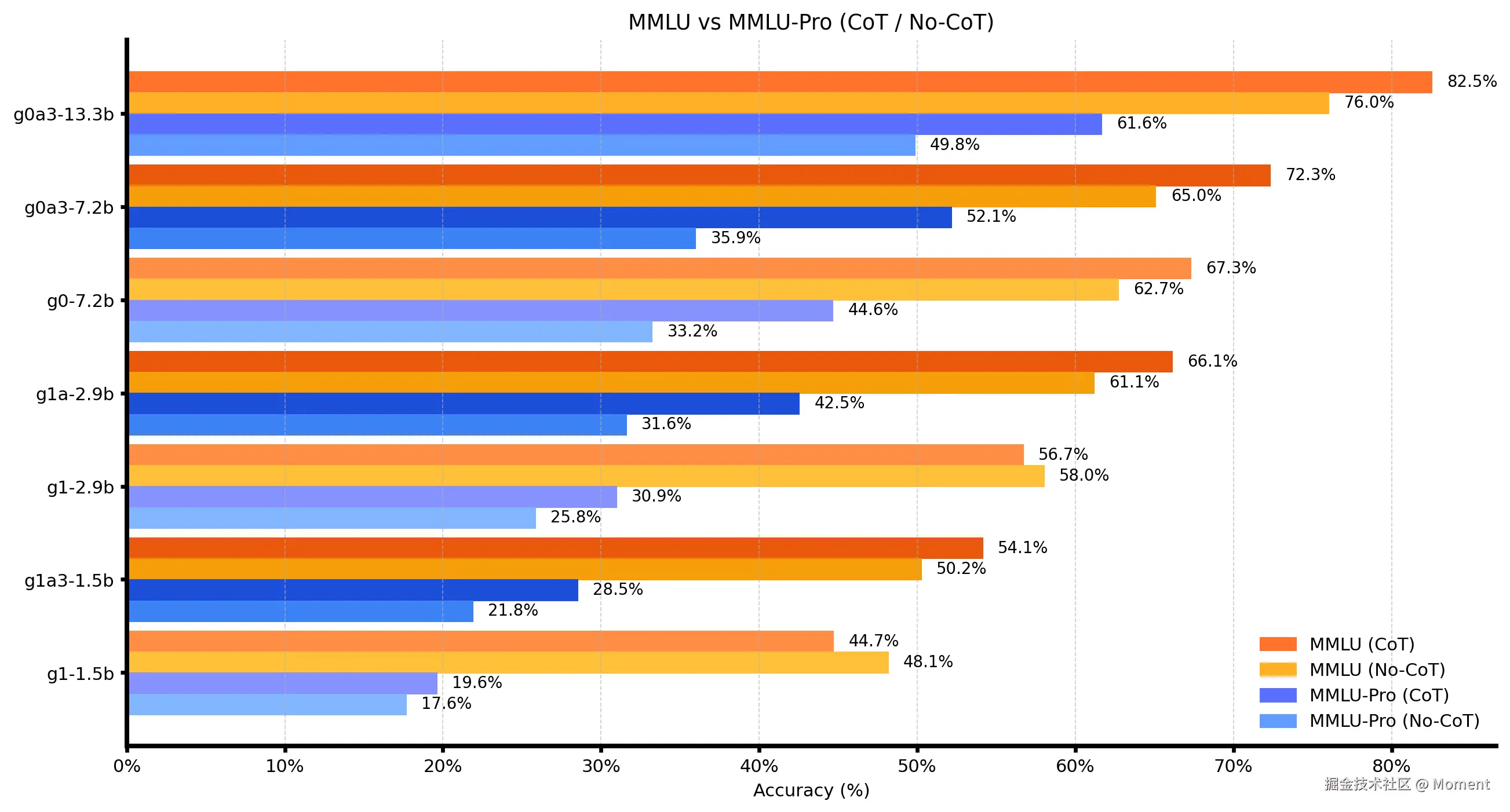
MMLU 系列用于测评语言模型在多学科知识与认知推理方面的能力,其中 MMLU Pro 为进阶版本,包含更复杂的问题设计与更严苛的评测标准。
欲获取更多详细信息,请访问该模型的 官方公众号文章 阅读。
这意味着:
在以 Transformer (deep learning architecture) 架构主导的大模型时代,RWKV 所代表的"纯 RNN "路线再度崛起:以更低的计算与显存成本、更自然的时序记忆机制,走出一条与主流 LLM 截然不同的进化路径。
在 RWKV 命名规则中,G0a3 标识了训练数据在版本与质量上的升级(例如:质量层级为 G# > G#a2 > G#,数据规模层级为 G1 > G0),即便参数量相同,G0a3 系列在泛化能力上也具备潜在优势。综合来看,RWKV7-G0a3 13.3B 的发布,不仅刷新了 RNN 模型性能的新高度,也象征着 RWKV 系列在"摆脱 Transformer 架构垄断"路径上迈出了一步。
模型下载
下载 RWKV7-G0a3 13.3B 模型(.pth 格式):
-
Hugging Face: huggingface.co/BlinkDL/rwk...
-
模搭 (ModelScope): modelscope.cn/models/RWKV...
-
Wisemodel: download.wisemodel.cn/file-proxy/...
下载 .gguf 格式: modelscope.cn/models/shou...
下载 Ollama 格式: ollama.com/mollysama
如何使用 RWKV 模型(本地部署)
可以使用 RWKV Runner、Ai00 或 rwkv pip 等推理工具在本地部署 RWKV 模型。
RWKV 模型同时兼容主流推理框架,如 llama.cpp 与 Ollama。
目前最快的 RWKV 推理工具是 Albatross。
由于 RWKV7-G0a3 13.3B 属于新模型,建议优先使用 RWKV Runner 以确保结果稳定与准确。
更多关于部署与推理的使用教程,可参考 RWKV 官网 - 模型部署和推理教程。
前端如何实现模型并发的效果
首先,我们要知道模型并发的效果,那我们要知道连接了发起了一个请求之后,它是怎么回复的:
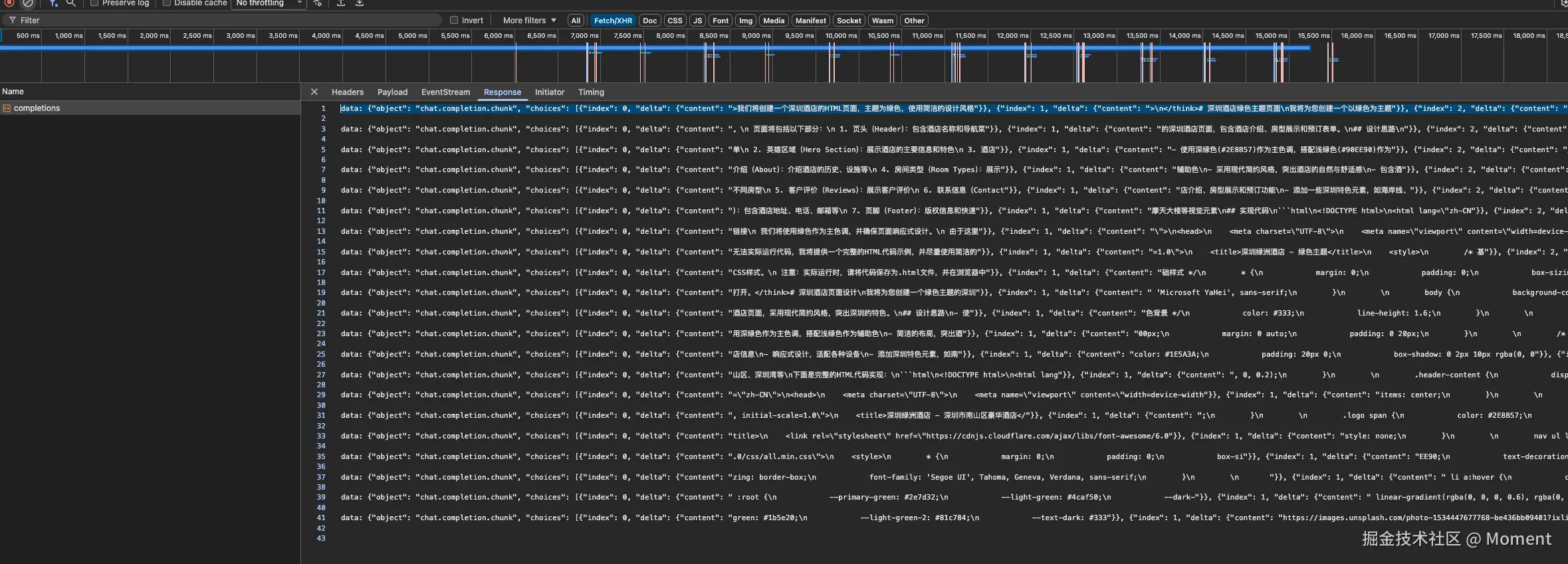
我们现在对的网络请求已经进行了截取,这是其中的一些数据,我们将一下核心的数据写到 json 文件里面让他能够更好的展示:
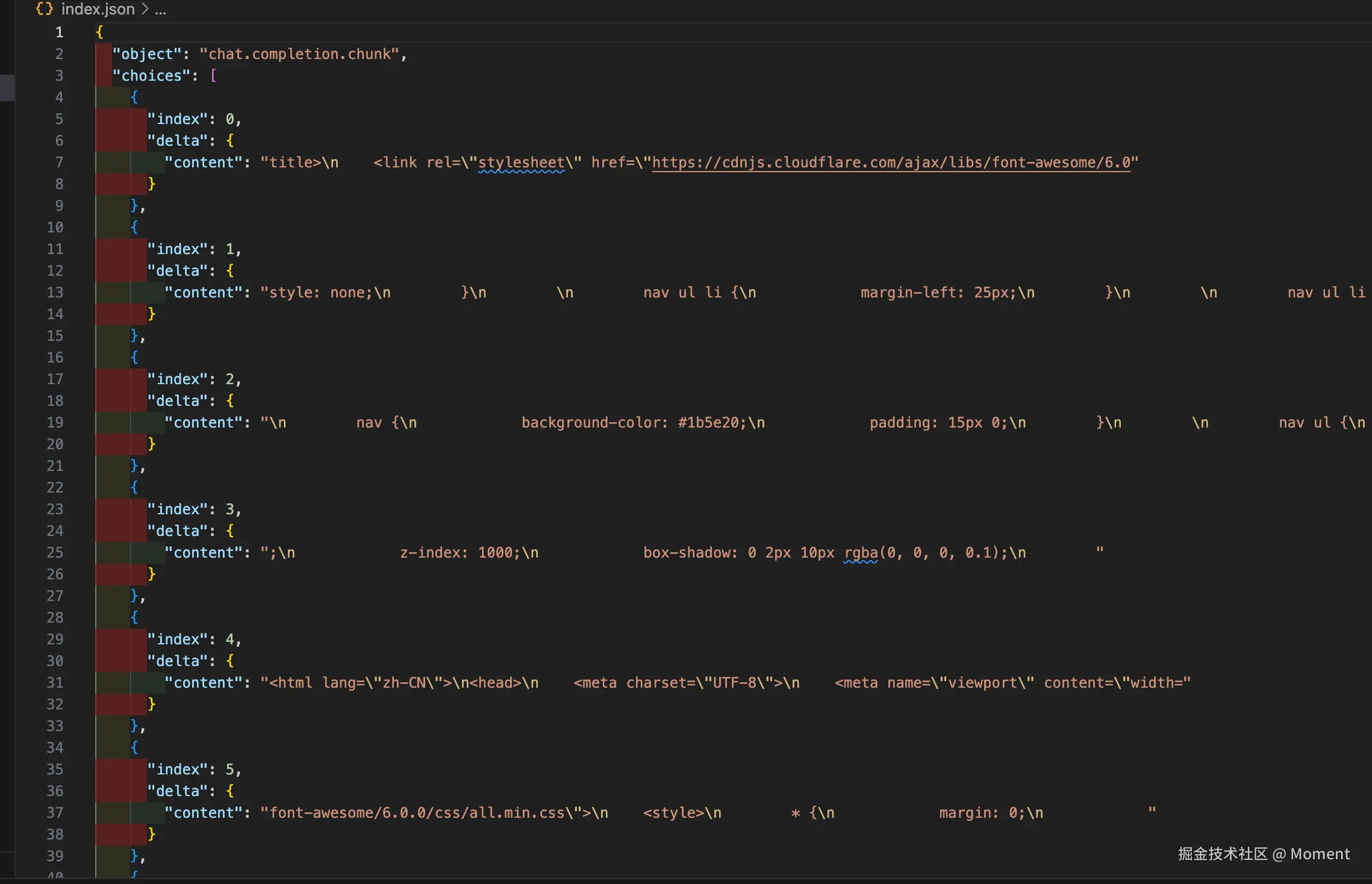
首先我们知道这是一个流式返回,但是一次流式返回了包含了的内容非常多,这里就是我们并发的关键了,这里的 index 代表并发的下标,而 delta.content 是具体的内容,这样我们知道了 SSE 实现并发的原理了,实际上就是调用 SSE,后端在一次 SSE 的返回中返回同一个问题的不同的结果并通过下标来区分。
我们已经把 SSE 返回机制摸清楚了。下面就轻松地走一遍"边生成边展示"的整个流程:从流式到达、到何时更新、再到怎么把半成品 HTML 安全地渲染出来,最后配上 UI 的滚动与分批加载。读完你就能一眼看懂这套实时渲染是怎么跑起来的。
先说结论:这件事其实就五步,顺次串起来就好了------流式接收、增量累积与触发、HTML 提取与补全、UI 局部更新、以及 iframe 的分批渲染。下面逐段拆开讲。
一、流式数据接收(ai.ts:195--251)
typescript
// 使用 ReadableStream 读取流式数据
const reader = response.body.getReader();
const decoder = new TextDecoder("utf-8");
let partial = ""; // 处理不完整的行
while (true) {
const { done, value } = await reader.read();
if (done) break;
const chunk = decoder.decode(value, { stream: true });
partial += chunk;
// 逐行解析 SSE 格式:data: {...}
const lines = partial.split("\n");
partial = lines.pop() || ""; // 保留不完整的行
for (const line of lines) {
if (!line.startsWith("data: ")) continue;
const json: StreamChunk = JSON.parse(data);
// 处理每个 chunk...
}
}这里的代码的核心要点如下:
- 逐行处理:SSE 数据按行到达,
split('\n')拆开,半截 JSON 用partial暂存。 - 字符安全:
TextDecoder(..., { stream: true })负责拼接多字节字符,避免中文或 emoji 被截断。 - 过滤噪声:只解析
data:开头的有效行,忽略心跳、空行、注释。 - 流式收尾:遇到
[DONE]仅结束对应流 index,其余继续处理。
二、增量累积与智能触发(ai.ts:224--244)
typescript
// 为每个 index 累积内容
contentBuffers[index] += delta;
// 判断是否应该触发渲染
const lastLength = lastRenderedLength.get(index) || 0;
const shouldRender = this.shouldTriggerRender(
contentBuffers[index],
lastLength
);
if (shouldRender && onProgress) {
const htmlCode = this.extractHTMLCode(contentBuffers[index]);
onProgress(index, contentBuffers[index], htmlCode);
lastRenderedLength.set(index, contentBuffers[index].length);
}这里的代码的核心要点如下:
- 多流并行:每个 index 各自独立累积,互不干扰。
- 智能触发:通过与
lastRenderedLength比较控制频率,避免"来一点就刷"。 - 精准更新:只触发对应 index 的渲染,避免全局重排。
- 兜底刷新:流结束后进行最终更新,确保结果完整。
三、触发策略(ai.ts:62--101)
typescript
private static shouldTriggerRender(
newContent: string,
oldLength: number,
): boolean {
// 1. 首次渲染:内容超过 20 字符
if (oldLength === 0 && newLength > 20) {
return true;
}
// 2. 关键闭合标签出现(语义区块完成)
const keyClosingTags = [
'</header>', '</section>', '</main>',
'</article>', '</footer>', '</nav>',
'</aside>', '</div>', '</body>', '</html>'
];
const addedContent = newContent.substring(oldLength);
for (const tag of keyClosingTags) {
if (addedContent.includes(tag)) {
return true; // 区块完成,立即渲染
}
}
// 3. 内容增长超过 200 字符(防止长时间不更新)
if (newLength - oldLength > 200) {
return true;
}
return false;
}这里的代码的核心要点如下:
- 首帧提速:内容首次超过 20 字符立即渲染,减少"首屏空白"。
- 语义闭合优先:检测新增片段中的关键闭合标签(如
</section>、</div>),保证块级内容完整展示。 - 超长兜底:即使未闭合,增量超 200 字符也强制刷新。
- 性能友好:仅比较"新增部分",无需重复扫描旧文本;参数可根据模型节奏与设备性能调节。
四、HTML 提取与自动补全(ai.ts:19--59, 104--145)
typescript
private static extractHTMLCode(content: string): string {
// 方式1: 完整的 ```html 代码块
const codeBlockMatch = content.match(/```html\s*([\s\S]*?)```/);
if (codeBlockMatch) return codeBlockMatch[1].trim();
// 方式2: 未完成的代码块(流式渲染)
const incompleteMatch = content.match(/```html\s*([\s\S]*?)$/);
if (incompleteMatch) {
return this.autoCompleteHTML(incompleteMatch[1].trim());
}
// 方式3: 直接以 <!DOCTYPE 或 <html 开头
if (trimmed.startsWith('<!DOCTYPE') || trimmed.startsWith('<html')) {
return this.autoCompleteHTML(trimmed);
}
return '';
}
private static autoCompleteHTML(html: string): string {
// 移除最后不完整的标签(如 "<div cla")
if (lastOpenBracket > lastCloseBracket) {
result = html.substring(0, lastOpenBracket);
}
// 自动闭合 script、body、html 标签
// 确保浏览器可以渲染未完成的 HTML
return result;
}这里的代码的核心要点如下:
- 多格式兼容:完整块、未闭合块、裸 HTML 均可识别。
- 容错补齐:遇到半截标签(如
<div cla)自动裁剪,再补上</script>、</body>、</html>等关键闭合。 - 最小修正:仅做"可渲染"层面的修复,保持生成内容原貌。
- 安全回退:提不出 HTML 时返回空字符串,避免将解释性文字误渲染。
五、UI 实时更新(ChatPage.tsx:240--253)
typescript
await AIService.generateMultipleResponses(
userPrompt,
totalCount,
(index, content, htmlCode) => {
// 实时更新对应 index 的结果
setResults((prev) =>
prev.map((result, i) =>
i === index
? {
...result,
content, // 原始 Markdown 内容
htmlCode, // 提取的 HTML 代码
isLoading: false,
}
: result
)
);
}
);这里的代码的核心要点如下:
- 局部更新:仅更新目标项,
prev.map保证不可变数据结构,减少重渲染。 - 双轨推进:
content用于 Markdown 文本,htmlCode用于预览展示。 - 快速反馈:首批数据到达即撤骨架屏,让用户感知"正在生成"。
- 状态持久:结果存入
sessionStorage,刷新或返回依旧保留上下文。
六、iframe 分批渲染优化(ChatPage.tsx:109--175)
typescript
// 找出已准备好但还未渲染的索引
const readyIndexes = results
.filter(({ result }) => !result.isLoading && result.htmlCode)
.map(({ index }) => index)
.sort((a, b) => a - b);
// 第一次渲染:一次性全部加载(用户体验优先)
if (!hasRenderedOnce.current) {
setIframeRenderQueue(new Set(readyIndexes));
hasRenderedOnce.current = true;
return;
}
// 后续渲染:分批加载(每批 8 个,间隔 300ms)
// 避免一次性创建太多 iframe 导致卡顿
const processBatch = () => {
const toAdd = stillNotInQueue.slice(0, batchSize); // 8 个
toAdd.forEach((index) => newQueue.add(index));
if (stillNotInQueue.length > batchSize) {
setTimeout(processBatch, 300); // 继续下一批
}
};这里的代码的核心要点如下:
- 首批全放:初次渲染不延迟,保证响应速度。
- 后续分批:按批次(默认 8 个/300ms)渐进挂载,防止主线程卡顿。
- 动态调度:每轮重新计算"未入队项",保证不遗漏。
- 轻量 DOM:仅渲染必要 iframe,滚动与交互更顺滑;参数可按性能灵活调整。
小结
通过语义闭合与字数阈值控制更新频率让画面稳定流畅,HTML 半成品自动补齐避免黑屏,iframe 分批挂载减轻主线程压力并配合 requestAnimationFrame 提升滚动顺滑度,状态由 sessionStorage 兜底并以日志辅助调参;整体逻辑是流式接收边累积、攒到关键点就渲染一帧、UI 精准更新该动的那格,调顺节奏即可实现实时渲染的又快又稳。
效果展示
前面我们说了这么多代码相关的,接下来我们可以把我们的项目运行起来看一下最终运行的效果:

为了让 UI 的效果显示得更好,建议使用 33%缩放的屏幕效果。
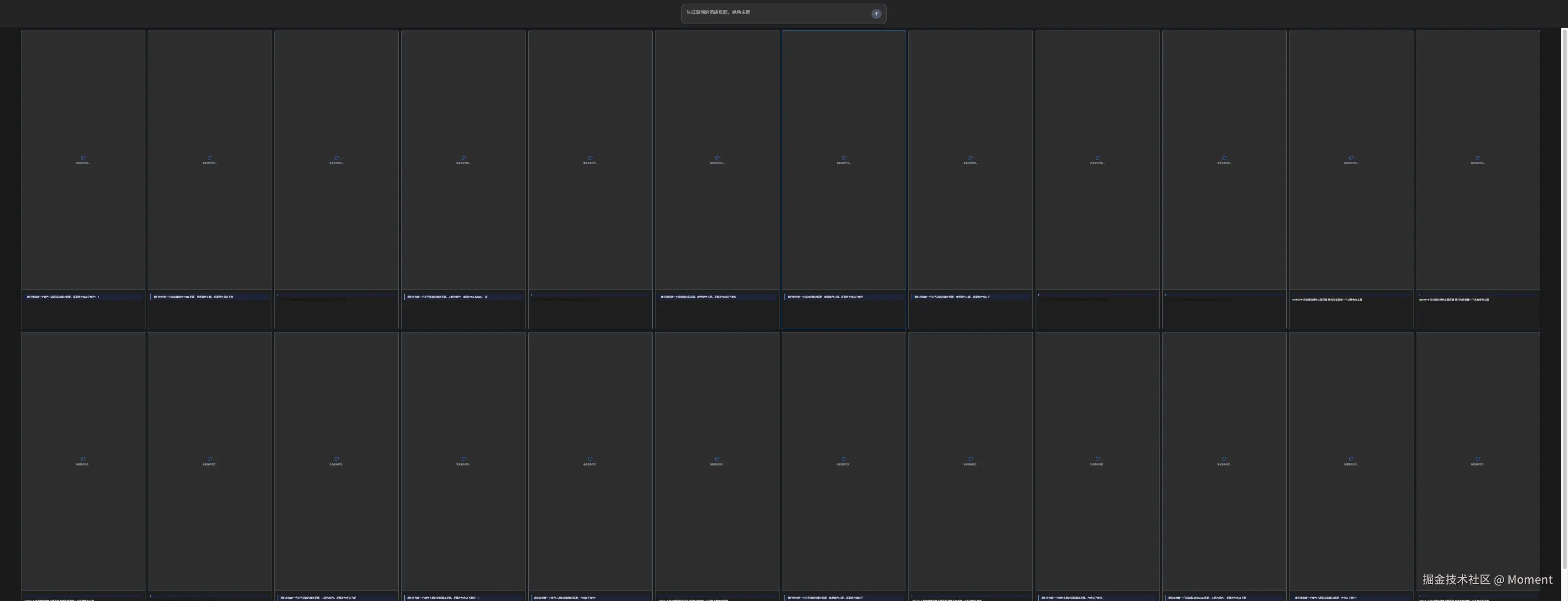
在输入框输入我们要问的问题,点击发送,你会看到这样的效果:
这会你能实时看到 24 个页面实时渲染的效果:
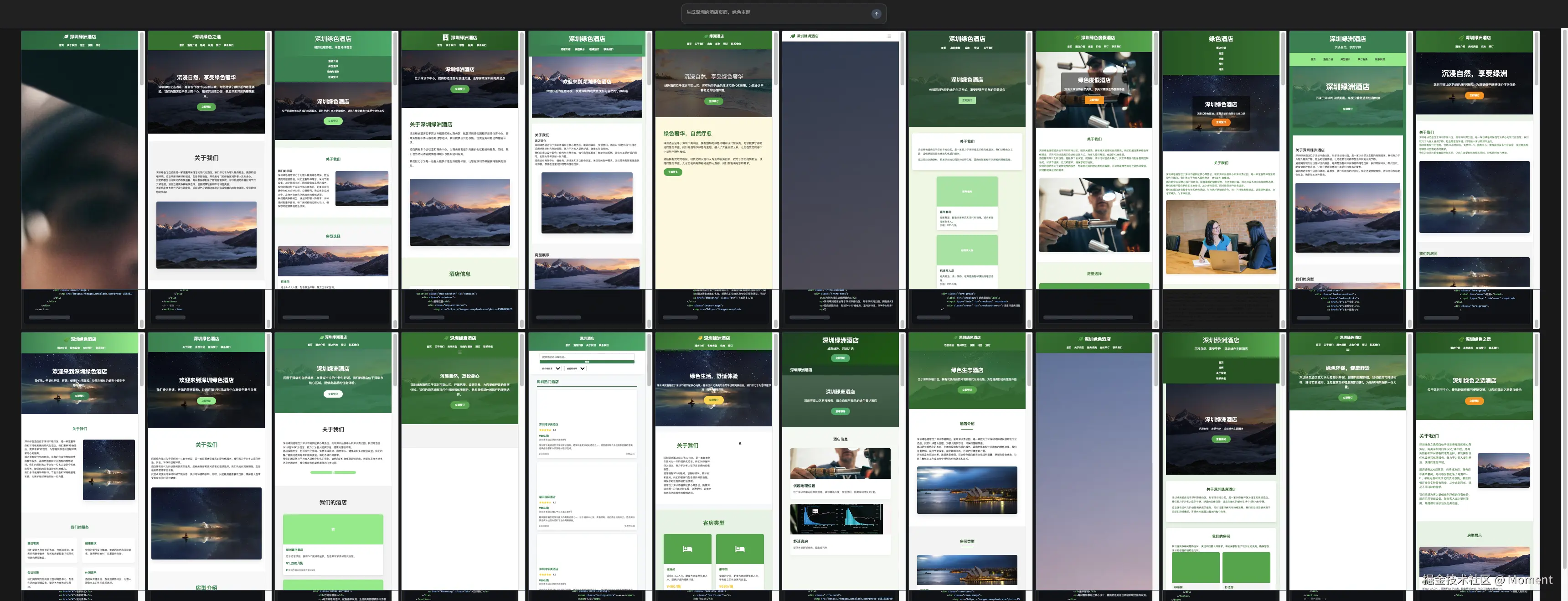
这样我们就借助 RWKV7-G0a3 13.3B 模型实现了一个跟 Cursor2.0 版本一模一样的效果了。
总结
RWKV7-G0a3 13.3B 是由中国团队推出的最新一代纯 RNN 大语言模型,在无 Attention 架构下实现了与主流 Transformer 模型相媲美的性能,并在多项基准测试中表现优异。它以更低显存占用和高推理效率展示了 RNN 架构的强大潜力。而前端并发实现中,通过 SSE 流式返回不同 index 的内容,实现了同时生成多个模型响应的并行效果。结合智能触发渲染与分批 iframe 更新,最终达成了类似 Cursor 2.0 的多 Agent 实时对比体验。