视觉Transformer实战------Vision Transformer
-
- [0. 前言](#0. 前言)
- [1. ViT 技术原理](#1. ViT 技术原理)
-
- [1.1 核心思想](#1.1 核心思想)
- [1.2 使用 Transformer 处理图像数据](#1.2 使用 Transformer 处理图像数据)
- [2. ViT 关键组件](#2. ViT 关键组件)
-
- [2.1 图像分块](#2.1 图像分块)
- [2.2 patch 嵌入](#2.2 patch 嵌入)
- [2.3 位置编码](#2.3 位置编码)
- [2.4 分类 token](#2.4 分类 token)
- [3. 使用 PyTorch 实现 ViT](#3. 使用 PyTorch 实现 ViT)
-
- [3.1 模型构建](#3.1 模型构建)
- [3.2 模型训练](#3.2 模型训练)
0. 前言
在计算机视觉领域,卷积神经网络 (Convolutional Neural Network, CNN)长期以来一直是处理图像任务的主流架构。然而,随着 Transformer 在自然语言处理领域的巨大成功,研究人员开始探索将这种基于自注意力机制的架构应用于视觉任务。Vision Transformer (ViT) 是这一探索的重要里程碑,它首次证明了纯 Transformer 架构在图像分类任务上可以超越最先进的 CNN 模型。本文将详细介绍 ViT 的技术原理,并使用 PyTorch 从零开始构建 ViT 模型用于图像分类任务。
1. ViT 技术原理
1.1 核心思想
Vision Transformer (ViT) 的核心思想是将图像分割成固定大小的小块 (patch),将这些 patch 线性嵌入后加上位置编码,然后像自然语言处理 (Natuarl Language Processing, NLP)中的词元 (token) 一样将这些 patch 序列输入标准的 Transformer 编码器中进行处理。
1.2 使用 Transformer 处理图像数据
Transformer 非常擅长处理时间序列数据,图像在某种程度上也可以视为时间序列。例如,将图像分解成大小为 16 x 16 的小块,如果我们按顺序将这些图像块依次输入模型,那么这些块也具有序列格式。这与卷积神经网络非常相似,在卷积神经网络 (Convolutional Neural Network, CNN) 中,我们也将图像视为多个小块,并在块上应用卷积核(即创建一个卷积核并在图像上移动)。Transformer 会在在此基础上,增加一个基于全连接层的嵌入 (embedding) 层,这将使得每个块的大小不再是 16 x 16,而是该图像部分的密集表示,此外,还需要添加位置嵌入 (positional embedding)。
这些模型也可以仅包含编码器。例如,可以在每个操作的开头添加一个额外的词元,以创建整个图像的表示。在分类过程中,我们可以使用该词元将整个图像分类为给定的类别。ViT 架构如下图所示:
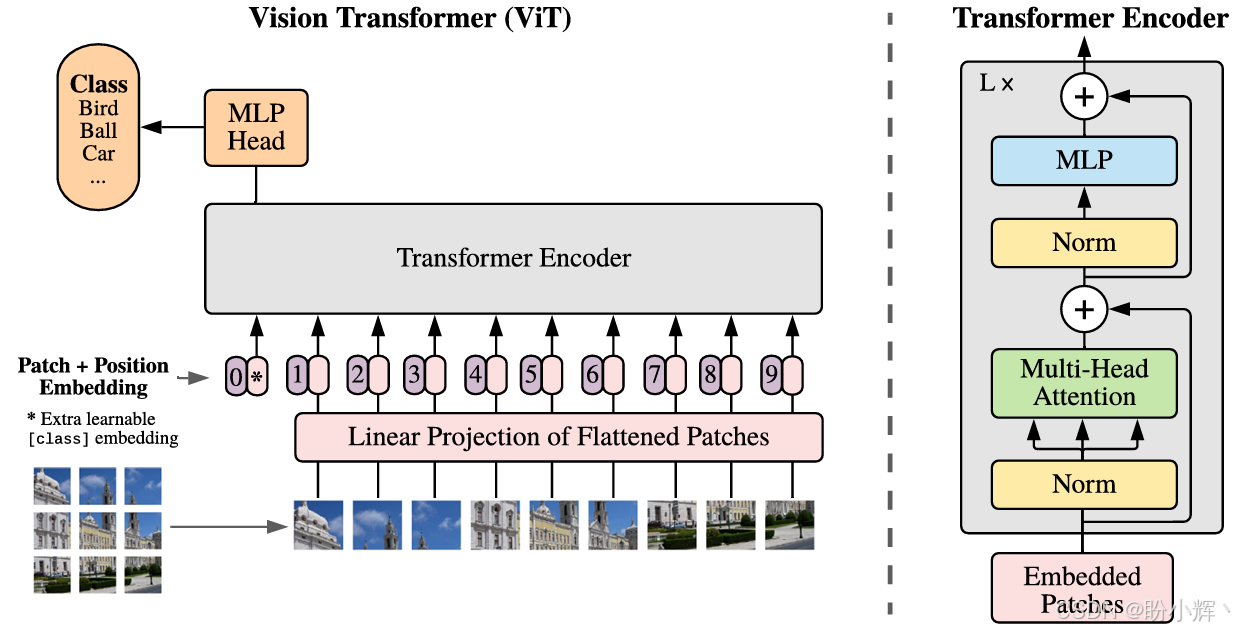
架构的其余部分与 Transformer 编码器块相同。ViT 架构的主要思想是分块并在图像块上应用位置嵌入。
2. ViT 关键组件
ViT 的成功依赖于几个精心设计的核心组件,这些组件共同实现了将 Transformer 架构有效应用于图像数据的创新方法。接下来,我们将深入剖析每个关键组件的设计原理和实现细节。
2.1 图像分块
Transformer 原本是为序列数据设计的,而图像是 2D 结构,图像分块 (Image Patching) 是将 2D 图像转换为 1D 序列的最直接方法,每个块 (patch) 相当于 NLP 中的一个 token。假设输入图像尺寸为 H × W × C (高度×宽度×通道),patch 大小为 P × P (通常 16×16),那么分块数量为 N = H W / P 2 N=HW/P^2 N=HW/P2。可以通过使用卷积实现高效分块:
python
self.proj = nn.Conv2d(in_channels, embed_dim,
kernel_size=patch_size,
stride=patch_size)较大的 patch 会丢失局部细节但计算效率高,较小的 patch 保留更多细节但增加序列长度。
2.2 patch 嵌入
patch 嵌入 (patch Embedding) 将每个 patch 展平并通过线性投影映射到 D 维空间,类似于 NLP 中的词嵌入,包括展平 patch ( P × P × C → P 2 C P×P×C → P²C P×P×C→P2C 维向量)和线性投影( P 2 C → D P²C → D P2C→D,通常 D=768),在 PyTorch 中可以使用以下代码实现:
python
x = x.flatten(2).transpose(1,2) # [B, N, P²C]
self.proj = nn.Linear(P²C, D)除此之外,也可以直接使用卷积层实现。
2.3 位置编码
Transformer 本身是排列不变的,因此必须注入空间位置信息,不同于 Transformer 的固定编码,ViT 使用可学习的位置编码 (position Embedding),形状为 N+1 × D (N 个 patche + 1 个分类 token),在 PyTorch 中可以使用以下代码实现:
python
self.pos_embed = nn.Parameter(torch.zeros(1, N+1, D))
nn.init.trunc_normal_(self.pos_embed, std=0.02)2.4 分类 token
分类 token (Class Token) 类似 BERT 的 [CLS] token,用于分类任务,作为整个图像的表征,通过自注意力聚合全局信息,在 PyTorch 中可以使用以下代码添加分类 token:
python
self.cls_token = nn.Parameter(torch.zeros(1, 1, D))3. 使用 PyTorch 实现 ViT
接下来,下面我们将从零开始实现 ViT 模型,并使用 CIFAR-10 数据集训练模型。ViT 工作流程如下:
- 输入图像
H×W×C - 分割为
N个P×P×C的patch( N = H W / P 2 N = HW/P² N=HW/P2) - 每个
patch展平为 P 2 C P²C P2C 维向量 - 通过线性投影映射到
D维 (Patch Embedding) - 添加位置编码和分类
token - 输入
L层的Transformer编码器 - 使用分类
token对应的输出进行分类
3.1 模型构建
(1) 首先,导入所需库:
python
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch import optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import numpy as np
from einops import rearrange, repeat
from einops.layers.torch import Rearrange
import matplotlib.pyplot as plt
from tqdm import tqdm(2) 将图像分割为 patch 并线性嵌入到 D 维空间:
python
class PatchEmbedding(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_channels=3, embed_dim=768):
super().__init__()
self.img_size = img_size
self.patch_size = patch_size
self.n_patches = (img_size // patch_size) ** 2
# 使用卷积层实现patch分割和嵌入
self.proj = nn.Conv2d(
in_channels=in_channels,
out_channels=embed_dim,
kernel_size=patch_size,
stride=patch_size
)
def forward(self, x):
# 输入x形状: [batch_size, in_channels, img_size, img_size]
# 输出形状: [batch_size, n_patches, embed_dim]
x = self.proj(x) # [batch_size, embed_dim, n_patches^0.5, n_patches^0.5]
x = x.flatten(2) # [batch_size, embed_dim, n_patches]
x = x.transpose(1, 2) # [batch_size, n_patches, embed_dim]
return x(3) 实现位置编码:
python
class PositionEmbedding(nn.Module):
def __init__(self, n_patches, embed_dim, dropout=0.1):
super().__init__()
self.pos_embed = nn.Parameter(torch.zeros(1, n_patches + 1, embed_dim)) # +1 for class token
self.dropout = nn.Dropout(dropout)
def forward(self, x):
# x形状: [batch_size, n_patches+1, embed_dim]
x = x + self.pos_embed # 添加位置编码
x = self.dropout(x)
return x(4) 实现多头注意力机制:
python
class MultiHeadAttention(nn.Module):
def __init__(self, embed_dim, num_heads, dropout=0.1):
super().__init__()
self.embed_dim = embed_dim
self.num_heads = num_heads
self.head_dim = embed_dim // num_heads
assert self.head_dim * num_heads == embed_dim, "Embedding dimension must be divisible by number of heads"
self.qkv = nn.Linear(embed_dim, embed_dim * 3) # 同时计算Q,K,V
self.attn_dropout = nn.Dropout(dropout)
self.proj = nn.Linear(embed_dim, embed_dim)
self.proj_dropout = nn.Dropout(dropout)
self.scale = self.head_dim ** -0.5
def forward(self, x):
batch_size, n_patches, embed_dim = x.shape
# 计算Q,K,V [batch_size, n_patches, num_heads, head_dim]
qkv = self.qkv(x).reshape(batch_size, n_patches, 3, self.num_heads, self.head_dim).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2]
# 计算注意力分数 [batch_size, num_heads, n_patches, n_patches]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_dropout(attn)
# 应用注意力权重到V上 [batch_size, num_heads, n_patches, head_dim]
out = attn @ v
out = out.transpose(1, 2).reshape(batch_size, n_patches, embed_dim)
# 线性投影和dropout
out = self.proj(out)
out = self.proj_dropout(out)
return out(5) 实现多层感知机 (Multilayer Perceptron, MLP) 模块,自注意力机制后进行非线性特征变换和维度扩展/收缩:
python
class MLP(nn.Module):
def __init__(self, in_features, hidden_features, out_features, dropout=0.1):
super().__init__()
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = nn.GELU()
self.fc2 = nn.Linear(hidden_features, out_features)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.dropout(x)
x = self.fc2(x)
x = self.dropout(x)
return x(6) 实现 Transformer 编码器模块 TransformerBlock:
python
class TransformerBlock(nn.Module):
def __init__(self, embed_dim, num_heads, mlp_ratio=4, dropout=0.1):
super().__init__()
self.norm1 = nn.LayerNorm(embed_dim)
self.attn = MultiHeadAttention(embed_dim, num_heads, dropout)
self.norm2 = nn.LayerNorm(embed_dim)
self.mlp = MLP(
in_features=embed_dim,
hidden_features=embed_dim * mlp_ratio,
out_features=embed_dim,
dropout=dropout
)
def forward(self, x):
# 残差连接和层归一化
x = x + self.attn(self.norm1(x))
x = x + self.mlp(self.norm2(x))
return x(7) 实现 ViT 模型:
python
class VisionTransformer(nn.Module):
def __init__(
self,
img_size=224,
patch_size=16,
in_channels=3,
n_classes=1000,
embed_dim=768,
depth=12,
num_heads=12,
mlp_ratio=4,
dropout=0.1
):
super().__init__()
self.patch_embed = PatchEmbedding(img_size, patch_size, in_channels, embed_dim)
n_patches = self.patch_embed.n_patches
# 分类token和位置编码
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.pos_embed = PositionEmbedding(n_patches, embed_dim, dropout)
# Transformer编码器
self.blocks = nn.ModuleList([
TransformerBlock(embed_dim, num_heads, mlp_ratio, dropout)
for _ in range(depth)
])
# 分类头
self.norm = nn.LayerNorm(embed_dim)
self.head = nn.Linear(embed_dim, n_classes)
# 初始化权重
nn.init.trunc_normal_(self.cls_token, std=0.02)
def forward(self, x):
batch_size = x.shape[0]
# 生成patch嵌入
x = self.patch_embed(x) # [batch_size, n_patches, embed_dim]
# 添加class token
cls_token = self.cls_token.expand(batch_size, -1, -1)
x = torch.cat([cls_token, x], dim=1) # [batch_size, n_patches+1, embed_dim]
# 添加位置编码
x = self.pos_embed(x)
# 通过Transformer编码器
for block in self.blocks:
x = block(x)
# 分类
x = self.norm(x)
cls_token_final = x[:, 0] # 只取class token对应的输出
x = self.head(cls_token_final)
return x3.2 模型训练
(1) 实现模型训练与评估函数:
python
def train_epoch(model, dataloader, criterion, optimizer, device):
model.train()
running_loss = 0.0
correct = 0
total = 0
for images, labels in tqdm(dataloader, desc="Training"):
images, labels = images.to(device), labels.to(device)
# 前向传播
outputs = model(images)
loss = criterion(outputs, labels)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 统计信息
running_loss += loss.item()
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
epoch_loss = running_loss / len(dataloader)
epoch_acc = 100. * correct / total
return epoch_loss, epoch_acc
def evaluate(model, dataloader, criterion, device):
model.eval()
running_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for images, labels in tqdm(dataloader, desc="Evaluating"):
images, labels = images.to(device), labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
running_loss += loss.item()
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
epoch_loss = running_loss / len(dataloader)
epoch_acc = 100. * correct / total
return epoch_loss, epoch_acc(2) 定义模型超参数:
python
img_size = 224
patch_size = 16
batch_size = 32
num_epochs = 20
learning_rate = 0.0001
num_classes = 10 # CIFAR-10有10个类别
# 设备配置
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")(3) 加载 CIFAR-10 数据集,并进行数据预处理:
python
transform = transforms.Compose([
transforms.Resize((img_size, img_size)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)(4) 初始化模型、损失函数和优化器:
python
model = VisionTransformer(
img_size=img_size,
patch_size=patch_size,
n_classes=num_classes,
embed_dim=768,
depth=6, # 减少深度以加快训练
num_heads=8
).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)(5) 训练模型 20 个 epoch:
python
train_losses, train_accs = [], []
test_losses, test_accs = [], []
for epoch in range(num_epochs):
print(f"Epoch {epoch+1}/{num_epochs}")
# 训练
train_loss, train_acc = train_epoch(model, train_loader, criterion, optimizer, device)
train_losses.append(train_loss)
train_accs.append(train_acc)
# 评估
test_loss, test_acc = evaluate(model, test_loader, criterion, device)
test_losses.append(test_loss)
test_accs.append(test_acc)
print(f"Train Loss: {train_loss:.4f}, Train Acc: {train_acc:.2f}%")
print(f"Test Loss: {test_loss:.4f}, Test Acc: {test_acc:.2f}%")
print()(6) 绘制模型训练过程中损失值和分类性能变化曲线:
python
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(train_losses, label='Train Loss')
plt.plot(test_losses, label='Test Loss')
plt.legend()
plt.title('Loss')
plt.subplot(1, 2, 2)
plt.plot(train_accs, label='Train Acc')
plt.plot(test_accs, label='Test Acc')
plt.legend()
plt.title('Accuracy')
plt.show()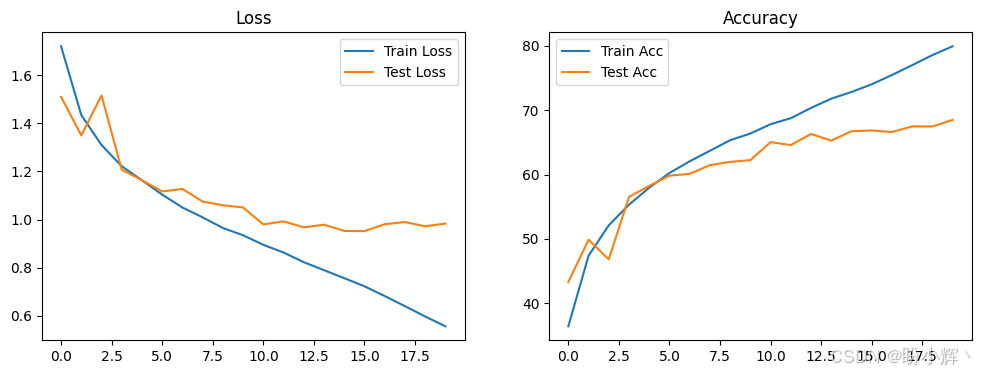
可以看到,从零开始训练的 ViT 在 CIFAR-10 数据集上的准确率大约在 67% 左右,在小规模数据集上从头训练时,ViT 的表现通常不如 CNN,这是由于ViT 的核心是全局自注意力机制,它需要足够多的数据来学习长距离依赖关系,在小规模数据集(如 CIFAR-10,仅 5 万张 32×32 图像)上,ViT 容易过拟合,无法有效学习有意义的特征映射。而使用在 ImageNet 上预训练的 ViT 进行微调,在 CIFAR-10 上可达到 98.5% 的准确率。