机器学习的基本知识
如何防止过拟合:过拟合无非两个原因,数据不足或模型太复杂
- 数据方面可以增加训练数据/数据增强
- early stopping
- dropout修改隐层神经元个数,参数量减小,能够减少不同特征之间的协同效应
- L1正则化稀疏参数或L2正则化使得参数更小
- BN,具有某种正则作用
batch normalization 与 layer normalization 公式以及各自适用场景
- 首先,LayerNorm适合用于处理不定长行为序列场景,如果此时用BN,padding部分特征Pooling会扰乱正常非padding部分特征
- 随着网络深度的增加,每层特征值分布逐渐向激活函数饱和区(非敏感区)靠近,容易导致梯度消失,通过标准化操作后拉回正态分布,为了加入非线性,通过平移以及缩放参数调整正态分布,最终落入激活函数敏感区,通常BN加在DNN之后,激活函数之前,能够避免梯度消失,加快模型顺序
为什么用交叉熵而不用MSE
- sigmoid参数在输出接近0或1,梯度非常小,w学习比较慢
- MSE函数形式非凸,容易陷入局部最优
L1与L2正则
- L1正则是w参数各个元素绝对值之和,相当于对w引入拉普拉斯先验,拉普拉斯分布在极值点处是一个尖峰,参数w取0的可能性更大,因此可以用于稀疏矩阵,用于特征选择,实现参数稀疏化
- L2正则是w参数各元素平方和再取平方根,引入高斯先验,高斯分布在极值点处平滑,w在极值点附近取不同值的可能性接近,使得w更接近0但不会取0
LR推导以及代码实现
- 事件发生的概率为p,样本之间独立同分布
- 参数估计之极大似然估计:在给定样本的情况下,使得样本发生概率最大的参数估计的方法就叫极大似然估计
- 似然函数
对数几率服从线性分布
- 对w求导
- 对b求导
- LR代码实现
python
def LR_minibatch(x,y,num_steps,lr):
w, b = np.zeros(x.shape[1]), 0
for t in range(num_steps):
batch_index = np.random.choice(x.shape[0], 100) // batch_size:100
batch_x, batch_y = x[batch_index], y[batch_index]
p = sigmoid(np.dot(batch_x, w) + b)
grad_w = np.matmul(batch_x.T, p - batch_y)
grad_b = np.sum(p - y)
w = w - lr * grad_w
b = b - lr * grad_b
return w, b
def sigmoid(x):
return 1.0 / (1 + np.exp(-x))
def max_likelihood(x, y, w, b):
pos, neg = np.where(y == 1)[0], np.where(y == 0)[0]
pos_sum = np.sum(np.log(sigmoid(np.dot(x[pos], w) + b)))
neg_sum = np.sum(np.log(1 - sigmoid(np.dot(x[neg], w) + b)))
return pos_sum + neg_sum交叉熵函数与最大似然函数的关系
- 交叉熵损失函数是描述模型预测值与真实值之间的差距,越小越相近
- 似然函数衡量在某组参数下,整体估计与真实情况一样的概率,越大越接近
- 最小化交叉熵本质是对数似然函数最大化
BP链式法则求导
优化器optimizer
- BGD,所有样本更新一次参数
- SGD,每个样本都更新一次参数,步长固定,很容停滞在局部最小值;更新频繁,参数收敛过程震荡;但是潜力比较大,调好效果非常好
- Mini-batch GD ,每个batch更新一次参数,降低参数更新时的方差,相对于SGD更稳定,可以利用深度学习中高度优化的矩阵操作进行梯度计算,缺点时learning rate的选择问题,需要先设置大一点在设置小一点
- adagrade 自适应学习率
- adamgrade 自适应学习率 + 动量加快优化速度
AUC与ROC以及AUC、GAUC计算公式,AUC计算代码实现
- AUC即ROC曲线下面积,对于推荐算法,则表示正样本排在负样本前的概率
- 假设数据集有M个正样本,N个负样本,预测值有M+N个,将所有的样本按照预测值从小到大非降序排列,并排列序号1到M+N,对于概率最大的正样本,假设排序为rank1,则比它小的负样本的个数为rank1 - M,同样,对于概率次大的正样本,排序假设为rank2,比它概率小的负样本rank2-(M-1)个,一次类推,左右的正样本大于负样本的对数为rank1 + rank2 + ... + rankm - (1 + 2 + ... + M),则
- ROC曲线中,横坐标为FPR,即为假阳率,纵坐标为TPR,即为真阳率
- 假阳率,负样本中被预测为正样本的比例,越小越好
- 真阳率,正样本中被预测为正样本的比例,越大越好
AUC提升但线上效果没有提升的问题定位
- 特征离线在线一致性
- GAUC是否有涨
- 离线特征是否有穿越
- 后续策略等是否对精排模型排序有影响
EE探索与利用(汤普森采样与UCB)
- 汤普森采样,采用beta分布、参数
- UCB(upper confidence bound)
到底是继续展示"看起来最优"的内容(利用),还是尝试"可能更好但不确定"的内容(探索)?
过度利用(系统陷入局部最优)
过度探索(测试太多新内容,影响短期收益)
汤普森采样是一种概率式探索方法,核心思想是:按照每个动作(或广告、推荐位)成为最优选择的"概率"去抽样选择
也就是说,它并不总是选目前最高的,而是根据不确定性动态调整探索概率。
假设每个候选项的成功率(点击率、转化率)服从Beta分布:
αi:成功次数(如点击次数) + 1
βi:失败次数(未点击) + 1
Beta分布是二项分布的共轭先验,能方便地更新参数
算法步骤:
- 对每个选项i,从其后验分布中采样一个概率值:
选择使
根据实际反馈(点击/未点击)更新对应的
UCB是基于"置信上界"的方法,它强调乐观探索:对每个选项,不仅看平均收益,还要加上"不确定性"的置信区间上界,选择具有最高"上置信界"的选项
在时间步t,对每个动作i:
其中:
xˉi:选项 i的平均收益(例如平均点击率);
ni:该选项被选择的次数;
lnt/ni:反映不确定性,选得少的项置信区间更宽;
c:调节探索程度的超参数。
然后选择:
推荐系统相关知识
推荐系统特征分为哪几类,连续特征离散化方法以及为什么需要对连续特征离散化(好处)
-
用户侧特征(profile、bias),item侧特征(属性、bias),context侧特征,笛卡尔积特征(id类、可泛化类特征),序列特征
-
连续特征离散化方法比如等频分桶、log取整
-
连续特征离散化好处:
引入非线性变换,增强模型性能;对异常值不敏感,防止过拟合;可进一步对离散后的特征进行统计以及特征组合;增强模型可解释性。
FM、FFM、DeepFM、FNN,PNN、Wide&Deep,DeepFM,DCN、XDeepFM、AFM、CAN
每一个模型都要清楚逻辑,FM是为每一个特征引入隐向量v,向量维度为k,特征个数为n,则参数为kn,时间复杂度为O(kn)
FFM,每个特征有f个对应的隐向量,则参数量为knf,时间复杂度为O(kn^2)
FM(Factorization Machines)
对所有二阶特征交叉(pairwise interaction)建模
参数量:n + nk
时间复杂度:O(kn)
优点:显式建模交叉特征,稀疏数据下表现好
缺点:只建模二阶交叉,无法捕捉更高阶非线性关系
FFM(Field-aware Factorization Machines)
每个特征属于一个field,不同域的交叉用不同的隐向量
每个特征i有多个向量vi,fj,针对不同field
比FM更细粒度:考虑了"特征交叉时的语境"
参数量:n*f*k
时间复杂度:O(n^2 k)
优点:区分不同field的交互效果,更精准
缺点:参数爆炸、训练慢、内存消耗大'
FNN(Factorization-machine supported Neural Network)
用FM的隐向量作为DNN的初始化或输入特征
结构:FM Embedding -> DNN -> 输出层
创新点:引入深度网络学习高阶非线性组合
缺点:FM参数是预训练固定的,不能端到端更新
PNN(Product-based Neural Nerwork)
显式地在embedding层后添加乘积层,让网络自动建模特征交叉
Inner Product PNN(IPNN):内积交互
Outer Product PNN(OPNN):外积交互
优点:高阶非线性交叉,端到端学习
缺点:参数和计算量比FNN大
Wide & Deep
线性模型(wide) + DNN(deep)联合训练
Wide部分:手工或自动特征交叉(记忆能力)
Deep部分:DNN自动特征组合(泛化能力)
优点:兼顾记忆与泛化;端到端训练
应用:Google Play推荐系统
Deep FM
在Wide&Deep的基础上,用FM替换Wide部分
FM负责显式二阶交叉,DNN负责高阶交叉
结构:Embedding -> FM(二阶) + DNN(高阶) -> 拼接 -> 输出
共享同一embedding,端到端训练
优点:不需人工交叉特征,训练快、效果好
应用:CTR预估、推荐系统主流baseline
DCN(Deep & Cross Network)
核心逻辑:
通过Cross Layer显式建模多层交叉:
Cross层可堆叠L层
每层显式建模更高阶交互
优点:显式交叉可控;与Deep部分结合提升非线性表达
复杂度:O(n^2) -> O(n)
xDeepFM(Extreme DeepFM)
在DeepFM基础上,引入CIN(compressed interaction Network)显式高阶交互
CIN显式组合不同阶的特征交互
DNN负责隐式高阶关系
优点:同时捕获显式 + 隐式交叉
效果:CTR预估表现优于DeepFM
AFM(Attention FM)
在FM的二阶交互上引入注意力机制,学习不同交叉的重要性
优点:注意力机制可学习交互权重;模型更可解释
复杂度:O(kn^2)
CAN(Context-Aware Network)
在FM/DNN基础上引入上下文特征context,动态调节交叉强度
context(如时间、位置、场景)-> 影响embedding或权重
属于"条件建模"思路
优点:融合用户场景、时间、设备等信息,提升实时推荐精度
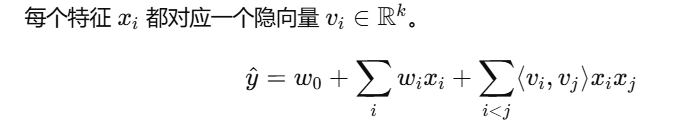
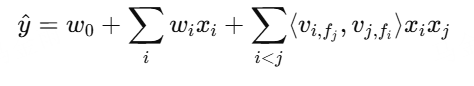
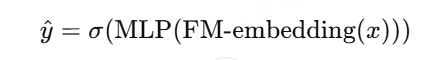
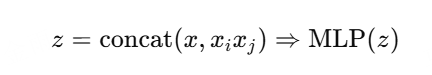
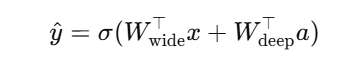
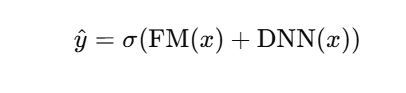
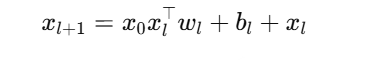
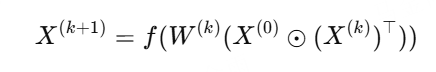
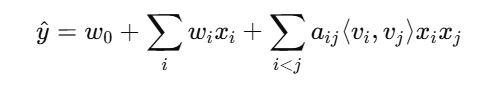
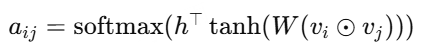
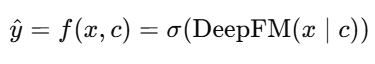
短期用户行为序列处理模型
pooling、attention、din、dien、dsin
主要解决:如何建模用户最近的行为序列,捕获与当前target item的兴趣匹配关系(短期兴趣)
Pooling-based(平均/加权池化)
思想:直接对用户的历史行为embedding做平均(mean pooling)或加权(sum/max pooling),得到用户兴趣向量
优点:简单高效,时间复杂度O(nk)
缺点:没有区分不同行为的重要性,无法捕捉序列顺序或target相关性
适用:baseline模型或embedding表征预训练
Attention-based(Target Attention)
思想:通过与目标物品(target item)计算注意力权重,选择相关的历史行为
优点:只强调与当前候选物品相关的行为;泛化性强
缺点:每次推理都需计算target与所有行为的注意力;时间复杂度O(nk)
DIN(Deep Interest Network)
解决问题:不同用户的兴趣是多样的,DIN引入target-aware attention,为每个候选item动态建模兴趣
核心思想:target item与每个历史行为交互;计算注意力权重,在聚合加权embedding
优点:能针对不同target item激活不同兴趣;端到端可训练;可解释性强
缺点:推理慢(需对每个target item 做 attention);无法捕捉序列依赖(只是集合级)
复杂度:O(nk)
DIEN(Deep Interest Evolution Network)
解决问题:DIN只能关注与target的相关性,无法建模兴趣随时间的演化
核心思想:用GRU/RNN建模兴趣演化;Interest Extractor + Interest Evolving Layer; 最后在与target做attention
优点:捕获时间依赖;兴趣演化建模;提升时序精度
缺点:训练复杂;序列过长计算慢;O(nk)
DSIN(Deep Session Interest Network)
解决问题:用户行为序列长、跨session(会话),兴趣跳变明显
核心思想:按session分段;session内用self-attention;session间用Bi-LSTM;最后target attention聚合
优点:模型用户兴趣的跳变;session粒度语义更清晰
缺点:结构复杂;序列长时仍较慢;时间复杂度O(S.L^2),S为session数
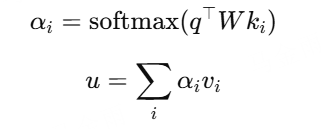
长期用户行为序列处理模型
MIMN、UBR4REC、SIM、ETA、SDIM,每个模型都在解决什么问题,有什么优缺点,注意时间复杂度
主要解决如何在行为序列极长(上千条)时,仍能高效捕获长期兴趣、保持实时推荐效率
MIMN(Memory Induction and Matching Network)
问题:DIEN、DSIN在超长序列上O(n^2)无法扩展
核心思想:引入外部记忆模块(Memory);每个slot存储长期兴趣;在线学习+匹配机制
优点:高效压缩长期行为;支持增量更新
缺点:记忆写入/读写策略复杂;参数较多;O(Mk),M为记忆块数量
UBR4REC(User Behavior Retrieval for Recommendation)
问题:如何高效从长期行为中检索相关历史item
核心思想:将用户历史行为embedding存入向量索引;检索与target item最相似的行为;Top-k聚合成用户表示
优点:检索高效;对冷启动友好
缺点:需构建大规模离线索引;召回/排序耦合复杂;O(logN)(检索阶段)+ O(K)
SIM(search-based Interest Model)
问题:DIN/DIEN 对超长序列慢;需要快速召回
核心思想:将行为序列切分为多个兴趣子序列;对每个子序列聚合生成兴趣向量;用Faiss等索引进行"兴趣检索"
优点:支持"hard search";减少序列长度;提升召回效率
缺点:离线索引构建耗时;不适合实时推荐;O(KlogN)
ETA(Efficient Target Attention)
问题:SIM的离线索引构建慢、更新不及时
核心思想:不在构建索引;在线通过target attention动态匹配兴趣;类似DIN的attention,但更高效。
优点:无需索引;支持实时在线推荐
缺点:每个target都要算attention;O(nk)
SDIM(Single-Stage Deep interest Model)
问题:ETA仍需target attention,推理成本高
核心思想:一步到位生成"融合目标信息的用户兴趣向量";无需target attention;单阶段预测
优点:极高推理效率;无需索引,无需target交互
缺点:可解释性略差;对多兴趣建模能力有限
复杂度:O(k)
比如,SIM用于hard search来缩短行为序列长度,但是用于检索的离线索引构建耗时,因此有了不需要构建索引的ETA,但ETA仍需要target attention,因此有了一步到位的SDIM
self-attention 以及din的target attention的时间复杂度
self-attention中Q*K^T的时间复杂度O(n^2 * d),softmax的时间复杂度为n^2,因此整体时间复杂度为O(n^2 * d)
din的target attention时间复杂度为O(n * d),n为序列长度
multi-head attention代码实现
python
import torch
import torch.nn as nn
import torch.nn.functional as F
class MultiHeadAttention(nn.Module):
def __init__(self, d_model: int, num_heads: int, dropout: float = 0.0, bias: bool = True):
# d_model:输入特征数
# num_heads:注意力头数
super().__init__()
assert d_model % num_heads == 0
self.h = num_heads # 注意力头数 H
self.d = d_model // num_heads # 每个头的维度 D = d_model / H
# Q, K, V 的线性映射层
self.q = nn.Linear(d_model, d_model, bais=bais)
self.k = nn.Linear(d_model, d_model, bias=bias)
self.v = nn.Linear(d_model, d_model, bias=bias)
# 输出层:将多个头拼接后的结果在映射回原维度
self.o = nn.Linear(d_model, d_model, bias=bias)
self.drop = nn.Dropout(dropout)
def _split(self, x): # 将特征分为多头
# 输入形状:[B, T, C]
# 输出形状:[B, H, T, D]
B, T, C = x.shape
return x.view(B, T, self.h, self.d).transpose(1, 2)
def forward(self, x_q, x_kv=None, *, key_padding_mask=None, causal=False):
# x_q:查询序列[B, Tq, C]
# x_kv:键值序列[B, Tk, C](若为自注意力可省略)
if x_kv is None:
x_kv = x_q # 自注意力:查询、键、值来自同一输入
# 线性投影到多头空间
Q = self._split(self.q(x_q)) # [B, H, Tq, D]
K = self._split(self.k(x_kv)) # [B, H, Tk, D]
V = self._split(self.v(x_kv)) # [B, H, Tk, D]
# 调用 PyTorch 2.x 的高效 Scaled Dot-Product Attention
# 公式:softmax((QK^T) / sqrt(D) + mask) @ V
attn = F.scaled_dot_product_attention(
Q, K, V,
attn_mask=None, # 可传入 [Tq, Tk] 或 [B,H,Tq,Tk]
dropout_p=self.drop.p if self.training else 0.0,#训练时加 dropout
is_causal=causal # 是否启用因果掩码(防止看未来)
) # 输出形状: [B, H, Tq, D]
# 合并多头输出 [B, H, Tq, D] -> [B, Tq, H*D]
out = attn.transpose(1, 2).contiguous().view(x_q.size(0), x_q.size(1), -1)
# 线性映射回原维度
return self.o(out)
B, T, C, H = 2, 5, 64, 8
x = torch.randn(B, T, C)
mha = MultiHeadAttention(d_model=C, num_heads=H, dropout=0.1)
y = mha(x, causal=True) # 自注意力 + 因果mask
print(y.shape) # torch.Size([2, 5, 64])多目标模型
- weighted LR 做法、ESMM、MMOE、PLE、DBMTL、SNR
- 多目标融合可选择加法或乘法加权,加法加权适合有主要目标的业务,乘法加权适合每个目标都很重要的业务
- 融合权重的调节方式
- grid search 在线每次请求随机出一组参数,然后计算不同组参数GAUC,选出最优参数组合
- 离线分别计算几组参数的GAUC
- CEM,cross entropy method
- 多目标损失函数权重如何优化,多目标优化中,loss通常存在三类问题:loss量级不同、loss优化速度不同,loss梯度优化方向不同导致任务间互相拉扯
- 权重优化方法有grad norm、UWL(uncertainty to weight loss)、DWA
item以及user冷启动有哪些方法策略
- 主要介绍item冷启动
- 尽快回收线上日志
- 用预训练embedding进行warm up
- top k 相似的old item 的ctr去纠正new item 打分
- EE探索与利用,比如汤普森采样与UCB
- 模型训练与serving,使用门控网络控制只有在新品特征中加入多模态信息
- KDD2022,对抗梯度探索