论文题目:SAMWISE: Infusing Wisdom in SAM2 for Text-Driven Video Segmentation(为文本驱动的视频分割注入SAM2的智慧)
会议:CVPR2025
摘要:参考视频对象分割(RVOS)依赖于自然语言表达式来分割视频片段中的对象。现有的方法将推理限制在独立的短片段上,失去了全局上下文,或者离线处理整个视频,从而削弱了它们在流媒体中的应用。在这项工作中,我们的目标是超越这些限制,设计一种RVOS方法,能够有效地在类似流的场景中运行,同时保留来自过去框架的上下文信息。我们建立在segmentanyanything 2 (SAM2)模型的基础上,它提供了鲁棒的分割和跟踪功能,非常适合流处理。我们让SAM2变得更聪明,通过在特征提取阶段赋予它自然语言理解和显式时间建模,而不需要对其权重进行微调,也不需要将模态交互外包给外部模型。为此,我们引入了一种新的适配器模块,在特征提取过程中注入时间信息和多模态线索。我们进一步揭示了SAM2中的跟踪偏差现象,并提出了一个可学习的模块,当当前帧特征建议一个与标题更一致的新对象时,可以调整其跟踪焦点。我们提出的方法SAMWISE通过添加一个可忽略不计的开销,即小于5m的参数,在各种基准测试中达到了最先进的水平。
代码可在https://github.com/ ClaudiaCuttano/SAMWISE获得。
核心贡献: 这是首个将自然语言理解能力集成到SAM2模型中的端到端解决方案,用于指称视频对象分割(RVOS)任务。
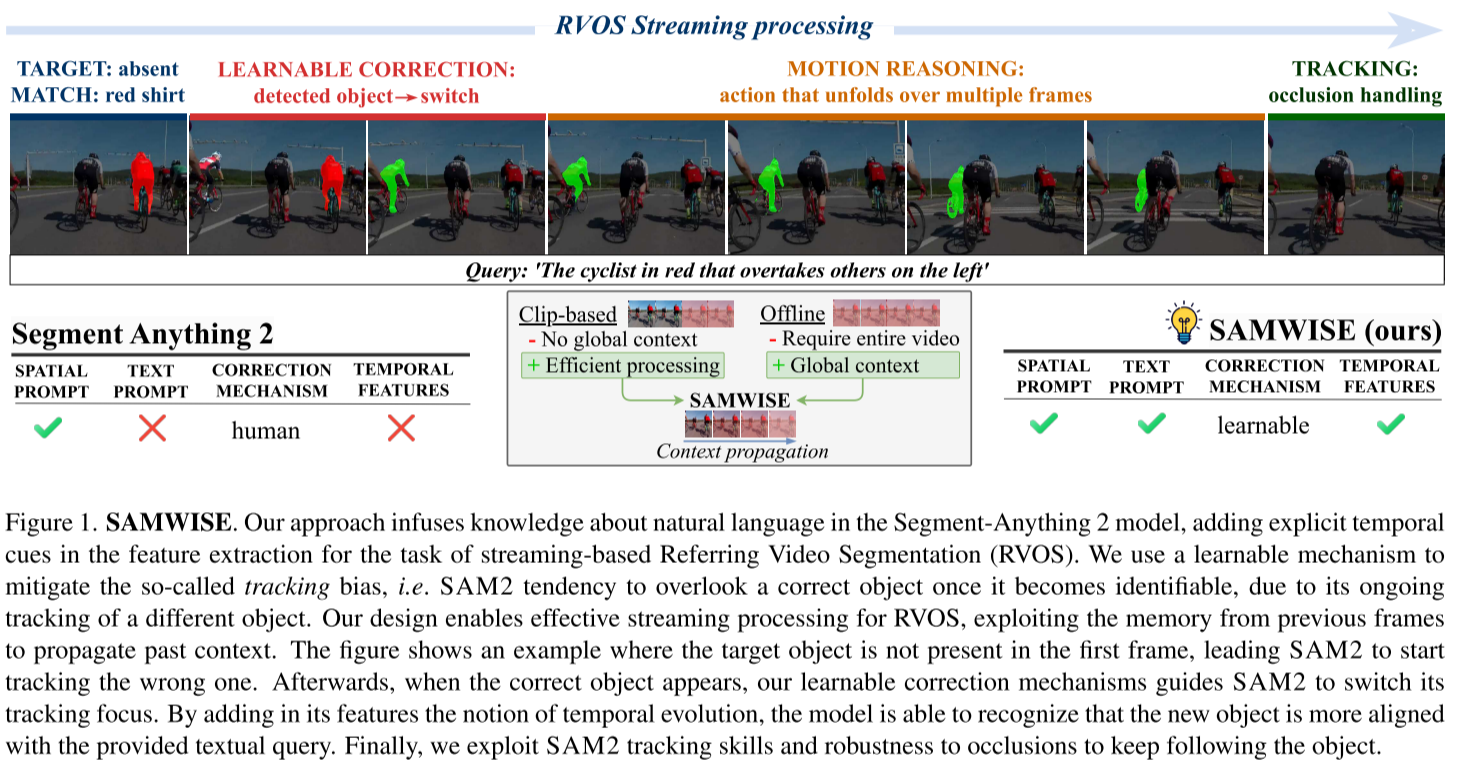
一、论文要解决的问题
1.1 传统RVOS方法的局限性
**参考视频对象分割(Referring Video Object Segmentation, RVOS)**是一个重要的计算机视觉任务,目标是根据自然语言描述在视频中分割并跟踪特定对象。然而,现有方法面临以下困境:
🔴 问题1: 短片段处理 vs 全局上下文的权衡
- 独立短片段处理:大多数现有方法将视频分割成短片段独立处理,导致丢失全局上下文信息
- 离线全视频处理:虽然能获得全局信息,但无法适应流式处理场景(如实时应用)
- 这种两难困境在MeViS数据集上体现得尤为明显,该数据集包含需要长期运动理解的复杂场景
🔴 问题2: 缺乏长期记忆机制
- OnlineRefer虽然提出了在线RVOS方案,但仅依赖单帧的过去上下文
- 无法有效捕捉长期时序依赖关系
1.2 将SAM2扩展到RVOS的挑战
SAM2(Segment-Anything 2)是一个强大的基础模型,具有流式处理能力和记忆机制。但将其应用于RVOS面临三大非平凡挑战:
🎯 挑战1: 文本理解能力缺失
- SAM2原始设计仅支持空间提示(如点、框)
- 缺乏理解语义文本提示的机制,无法进行视觉-文本跨模态推理
🎯 挑战2: 时序建模不足
- SAM2独立提取每帧特征,缺乏时序推理能力
- 无法理解需要多帧展开的动作(如"爬上"、"超越"等动词)
🎯 挑战3: 追踪偏差(Tracking Bias)
- 核心问题:当目标对象在某些时间段不可识别时(遮挡、多实例、动作未发生),SAM2可能开始追踪错误对象
- 一旦锁定错误对象,即使正确对象后来出现,也会持续追踪错误目标
- SAM2的设计允许人工手动纠正,但在无人工干预的RVOS任务中无法应用
二、SAMWISE的创新解决方案
论文提出的SAMWISE方法通过三大创新模块巧妙解决了上述挑战:
2.1 整体架构设计
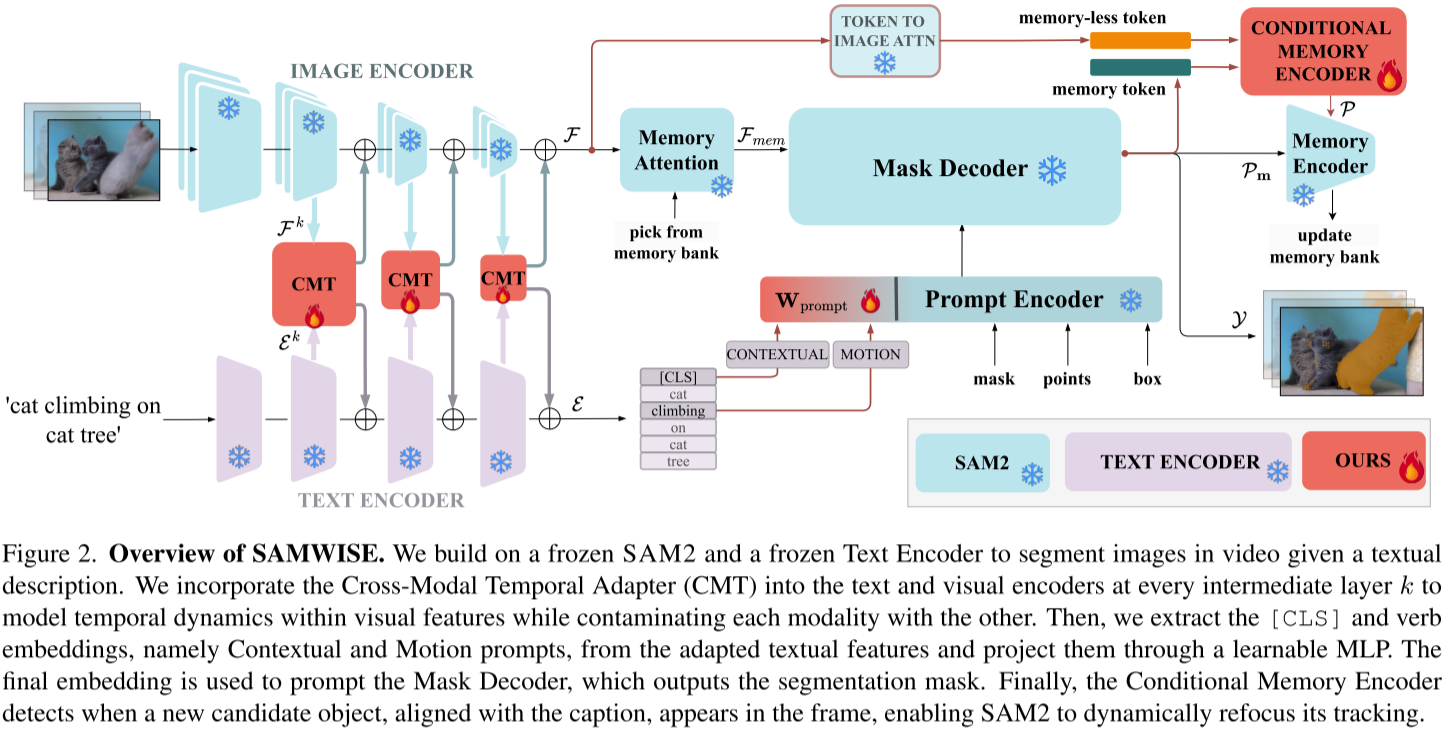
核心设计理念:
- ✅ 冻结SAM2和文本编码器权重,保留原始能力
- ✅ 不依赖外部大型VLM模型,避免额外计算开销
- ✅ 仅训练轻量级适配器模块(<5M参数)
2.2 创新点1: 跨模态时序适配器(CMT)
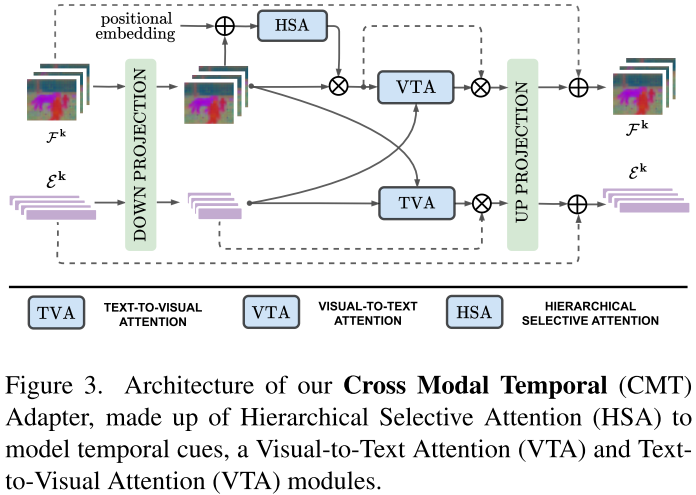
Cross-Modal Temporal Adapter (CMT) 是论文的核心创新,用于解决文本理解和时序建模问题。
📌 设计原则
- 实现视觉与语言模态的双向交互
- 将时序线索编码到视觉特征中
📌 三大核心组件
a) 分层选择性注意力(HSA - Hierarchical Selective Attention)
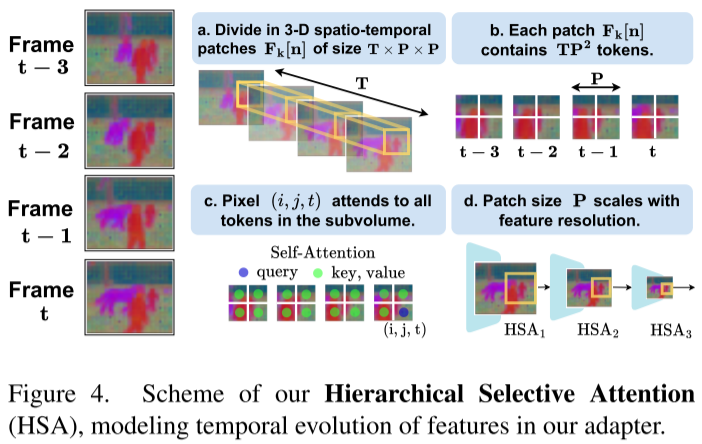
传统方法要么对所有token做自注意力(计算量大),要么只在时间轴上做注意力(局限性强)。HSA的创新在于:
关键观察:视频中物体运动通常发生在局部空间区域
创新策略:
1. 将视频特征分解为3D时空块(T×P×P)
2. 在每个子体积内进行自注意力计算
3. 块大小P随特征层级自适应缩放优势:
- 减少不必要的长距离计算
- 捕捉局部时空运动上下文
- 多尺度信息编码
b) 视觉到文本注意力(VTA)
让文本特征随视觉内容动态调整:
- 问题:文本描述的含义可能随视觉内容变化
- 解决:用平均视觉特征上下文化文本token
- 效果:使语言查询适应当前视觉场景
c) 文本到视觉注意力(TVA)
让视觉特征早期就对齐文本描述:
- 每个视觉特征关注完整文本表达
- 基于类别细节(如"猫")和动作线索(如"爬")识别候选区域
- 从特征提取早期就实现跨模态对齐
实验验证:通过PCA可视化清晰展示,CMT使视觉特征根据不同文本提示产生差异化响应。
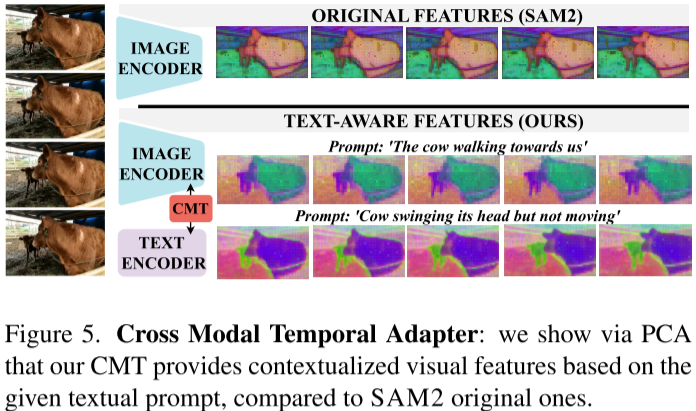
2.3 创新点2: 双提示策略
为了更好地引导SAM2解码器,论文设计了双提示机制:
🎯 上下文提示(Contextual Prompt)
- 使用文本特征的CLS token
- 编码整体语义信息
- 强调查询的关键方面
🎯 运动提示(Motion Prompt)
- 提取动词嵌入
- 捕捉动作相关线索
- 理解时序动态
融合策略:
ρ = MLP([Contextual_Prompt, Motion_Prompt])2.4 创新点3: 条件记忆编码器(CME)
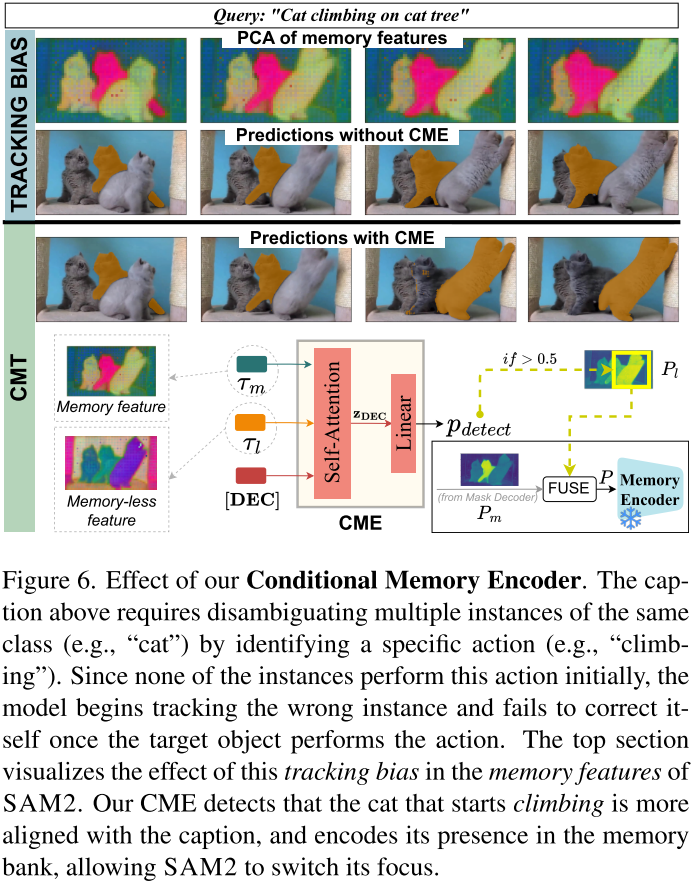
这是解决"追踪偏差"问题的关键创新。
📌 问题分析
追踪偏差的产生过程:
- 初始帧目标对象不可识别(如例子中"爬上猫树的猫"初始并未爬)
- SAM2开始追踪部分匹配的错误对象
- 即使正确对象后来执行了动作,SAM2仍持续追踪错误目标
- 这种偏差被编码到记忆特征中,传播到后续帧
📌 解决方案
核心洞察:
- 记忆特征(memory features):受过去预测影响,有偏差
- 无记忆特征(memory-less features) :
- 无偏表示当前帧
- 通过CMT与文本对齐
- 可提出与提示匹配的候选实例
CME工作流程:
-
生成两个token:
- τm(mask token):来自解码器,代表当前追踪对象
- τl(memory-less token):通过无偏特征与提示交叉注意力生成
-
检测不一致:
[决策token, τm, τl] → 自注意力 → 线性分类器 → p_detect -
软分配策略(非硬切换):
-
当检测到候选对象时(p_detect > 0.5)
-
融合两个预测的mask:
P = λ * P_memory-less ◦ M + P_memory ◦ (1 - M)
-
允许SAM2在保留上下文的同时"看到"其他对象
-
为什么是软分配?
- 无记忆特征缺乏历史上下文,可能产生误报
- 软融合在新信息和过去上下文间取得平衡
三、实验结果与分析
3.1 数据集与评估指标
测试数据集:
- MeViS: 最具挑战性,包含运动推理、实例歧义等复杂场景
- Ref-Youtube-VOS: 3,978个视频,约15K语言表达
- Ref-DAVIS17: 90个视频,1.5K语言标注
评估指标:
- J (区域相似度)
- F (轮廓准确度)
- J&F (平均值)
3.2 主要结果
📊 与SOTA方法对比
在MeViS上(最具挑战):
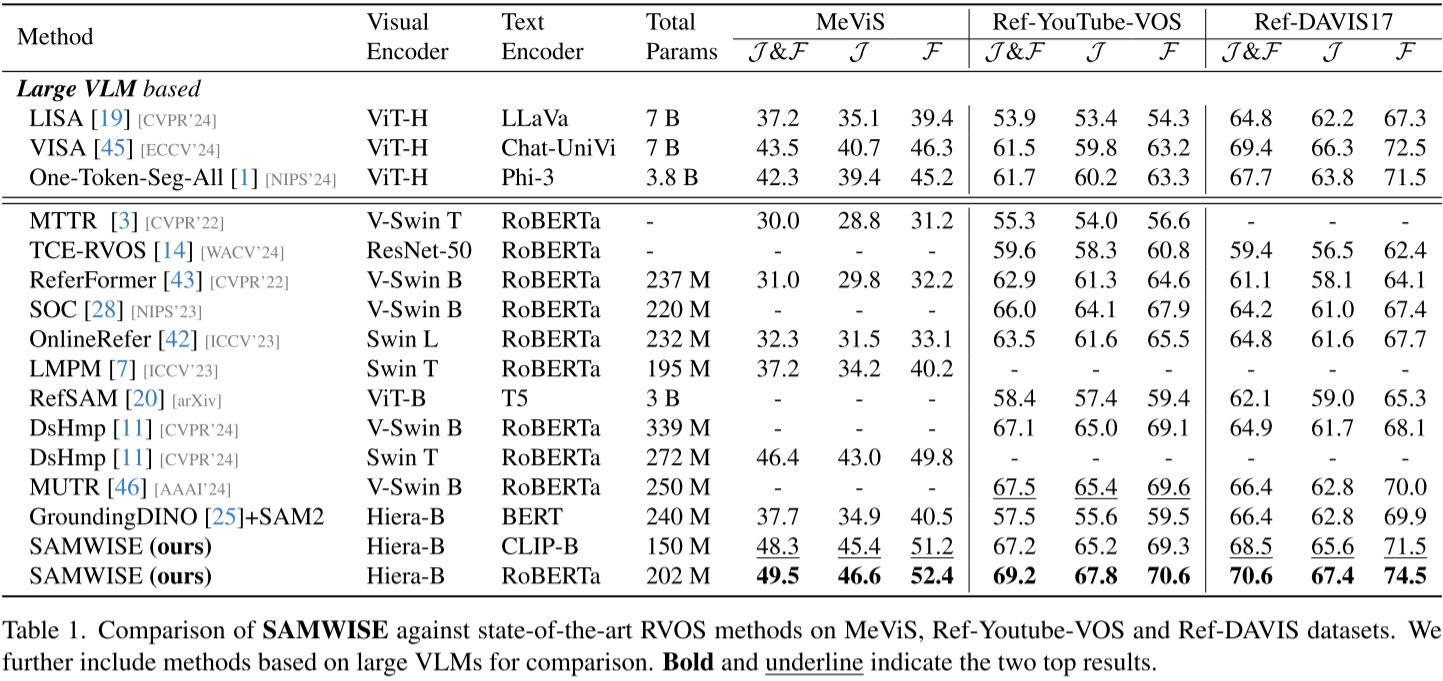
| 方法 | 文本编码器 | 总参数 | J&F |
|---|---|---|---|
| DsHmp (SOTA) | RoBERTa | 272M | 46.4 |
| SAMWISE | RoBERTa | 202M | 49.5 |
| SAMWISE | CLIP-B | 150M | 48.3 |
关键发现:
- 超越离线方法DsHmp +3.1%,且参数更少
- 使用CLIP版本仅150M参数,仍达到SOTA性能
在Ref-Youtube-VOS上:
| 方法 | J&F | 提升 |
|---|---|---|
| OnlineRefer | 63.5 | - |
| DsHmp | 67.1 | - |
| SAMWISE | 69.2 | +5.7% vs OnlineRefer |
| +2.1% vs DsHmp |
在Ref-DAVIS17上:
- SAMWISE: 70.6 J&F
- 比前SOTA提升 +5.7%
📊 与大型VLM方法对比
虽然参数量不在一个量级,但SAMWISE表现出色:
| 方法 | 参数 | MeViS J&F |
|---|---|---|
| VISA (VLM-based) | 7B | 43.5 |
| SAMWISE | 202M | 49.5 (+6.0%) |
3.3 消融实验
🔬 CMT各组件的贡献

| 配置 | J&F | 提升 |
|---|---|---|
| 仅MLP | 45.2 | baseline |
| + TVA + VTA | 48.3 | +3.1 |
| + HSA | 50.3 | +2.0 |
| + 完整CMT | 54.2 | +3.9 |
| + CME | 55.5 | +1.3 |
分析:
- 跨模态交互(TVA+VTA)贡献显著(+3.1%)
- 时序建模(HSA)进一步提升(+2.0%)
- CME有效缓解追踪偏差(+1.3%)
🔬 HSA的设计选择
补丁大小的影响:
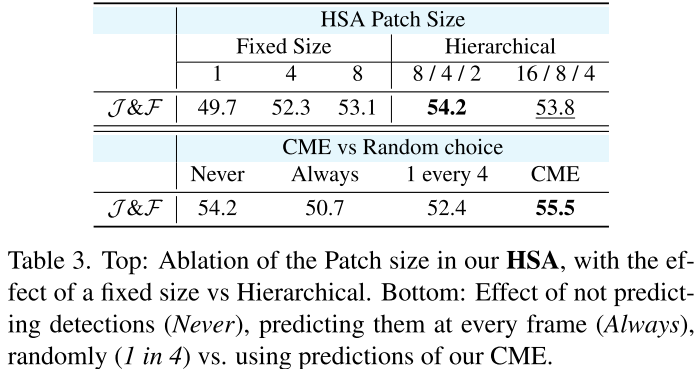
| 配置 | J&F |
|---|---|
| P=1 (逐像素) | 49.7 |
| P=4 | 52.3 |
| P=8 | 53.1 |
| 分层 (16/8/4) | 54.2 |
结论:分层补丁设计最优,适应不同特征分辨率。
🔬 CME的有效性
| 策略 | J&F |
|---|---|
| 从不检测 | 54.2 |
| 每帧检测 | 50.7 |
| 随机(1/4帧) | 52.4 |
| CME预测 | 55.5 |
结论:
- 总是检测会引入噪声(-3.5%)
- CME智能检测最有效(+1.3%)
3.4 与其他适配策略对比
| 方法 | MeViS J&F |
|---|---|
| 全微调 | 43.1 |
| LoRA | 44.2 |
| AdaptFormer | 43.9 |
| CMT (ours) | 48.3 |
结论:CMT专为跨模态时序任务设计,显著优于通用适配方法。
四、技术亮点与创新价值
4.1 方法论创新
-
首个SAM2的文本扩展方案
- 保留SAM2原始能力(冻结权重)
- 无需外部VLM模型
- 参数高效(<5M可训练参数)
-
早期跨模态融合
- 不同于以往在解码器层面的后期融合
- 在特征提取阶段就实现模态交互
- 更深层的视觉-文本对齐
-
时序推理的精细设计
- HSA的局部时空注意力兼顾效率与效果
- 多尺度分层设计捕捉不同粒度的运动
4.2 问题发现价值
追踪偏差(Tracking Bias)的识别:
- 论文首次系统性揭示SAM2的这一现象
- 提出了针对性的解决方案(CME)
- 为社区提供了重要洞察
4.3 实用价值
-
流式处理能力
- 无需一次性加载整个视频
- 适合实时应用和资源受限场景
-
参数效率
- 150M-202M总参数(vs VLM方法的数十亿参数)
- 训练成本低,部署友好
-
泛化能力强
- 在三个不同风格的数据集上均达到SOTA
- 既擅长复杂运动推理(MeViS)也适用于传统场景
五、局限性与未来方向
当前局限
- 依赖预训练的文本和视觉编码器
- CME需要额外的自监督训练
- 在极端遮挡场景下仍有改进空间
未来展望
- 探索更轻量级的时序建模方案
- 扩展到多对象同时分割场景
- 与其他视觉任务(如深度估计)结合
六、结论
SAMWISE成功地让SAM2"智慧"起来,实现了三个重要突破:
- ✅ 文本理解:通过CMT适配器赋予SAM2语言理解能力
- ✅ 时序建模:HSA机制有效捕捉视频中的运动演化
- ✅ 追踪纠正:CME智能调整追踪焦点,避免偏差积累
最终结果令人印象深刻:
- 在所有基准测试中达到SOTA性能
- 仅增加<5M参数
- 保持流式处理能力,适合实际应用
这项工作为视频理解领域提供了一个优雅且高效的解决方案,展示了如何通过精心设计的轻量级模块,充分挖掘大型预训练模型的潜力,而无需昂贵的全面微调或依赖外部重量级模型。
本文详细解读了CVPR 2025论文《SAMWISE: Infusing Wisdom in SAM2 for Text-Driven Video Segmentation》,希望能帮助读者深入理解这项创新工作的技术细节和价值。