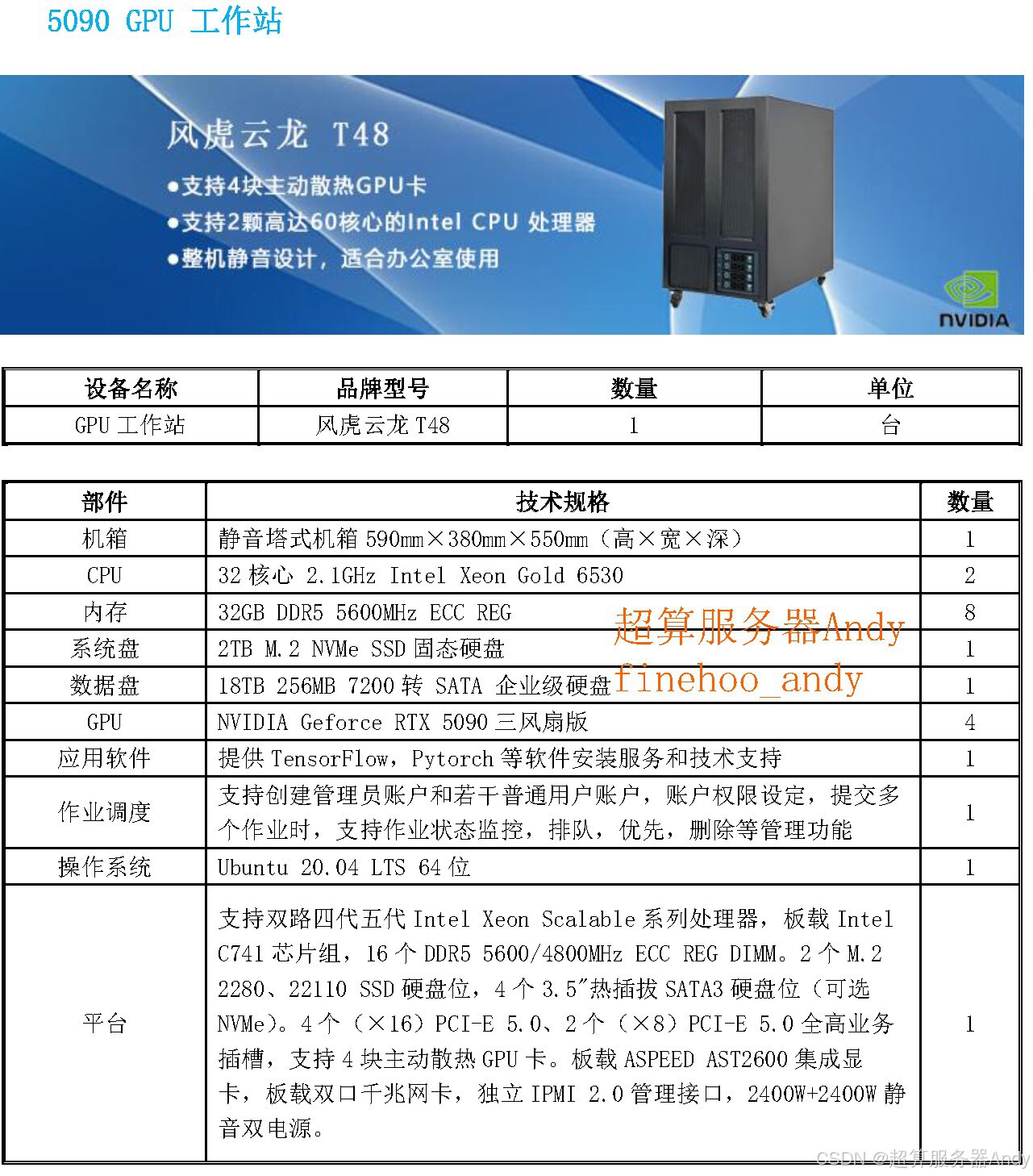
Alpha Arena 实盘赛中 AI 模型的收益分化,本质是背后 GPU 服务器硬件实力的直接体现 ------ 适配的 GPU 服务器能让 AI 模型充分发挥算力优势,反之则会制约模型性能,甚至导致巨额亏损。
一、AI 量化交易对 GPU 服务器的硬核配置要求
AI 量化交易的全流程(数据处理→模型训练→实盘决策)均依赖 GPU 服务器的硬件支撑,每一项配置都直接影响交易效率与收益,核心要求集中在四大维度:
1. 显存:决定 AI 模型 "思考深度" 的关键
超大规模 LLM(如 Qwen3-Max)参数规模达百亿级,单次推理需加载模型参数、实时行情、历史数据、多维度交易因子(MACD/RSI/ 舆情数据等),单卡 40GB 以上显存是最低运行门槛,具体配置需满足三大需求:
- 容量适配:8 卡 NVIDIA A6000 集群(单卡 48GB GDDR6 显存)总显存达 384GB,可轻松承载百亿参数模型,同时存储近 3 年的分钟级行情数据,避免因显存不足 "删减数据维度"------ 比如放弃舆情分析导致策略片面;
- 带宽保障:A6000 单卡显存带宽达 288GB/s,8 卡集群通过并行架构可实现 TB 级数据秒级读写,避免因数据传输卡顿导致 "行情已变,模型还在加载数据" 的延迟;
- 纠错能力:必须支持 ECC 显存(如 A6000 的 GDDR6 ECC),可实时检测并修正数据错误,避免因显存数据偏差导致模型做出错误交易决策(如误判股价支撑位)。
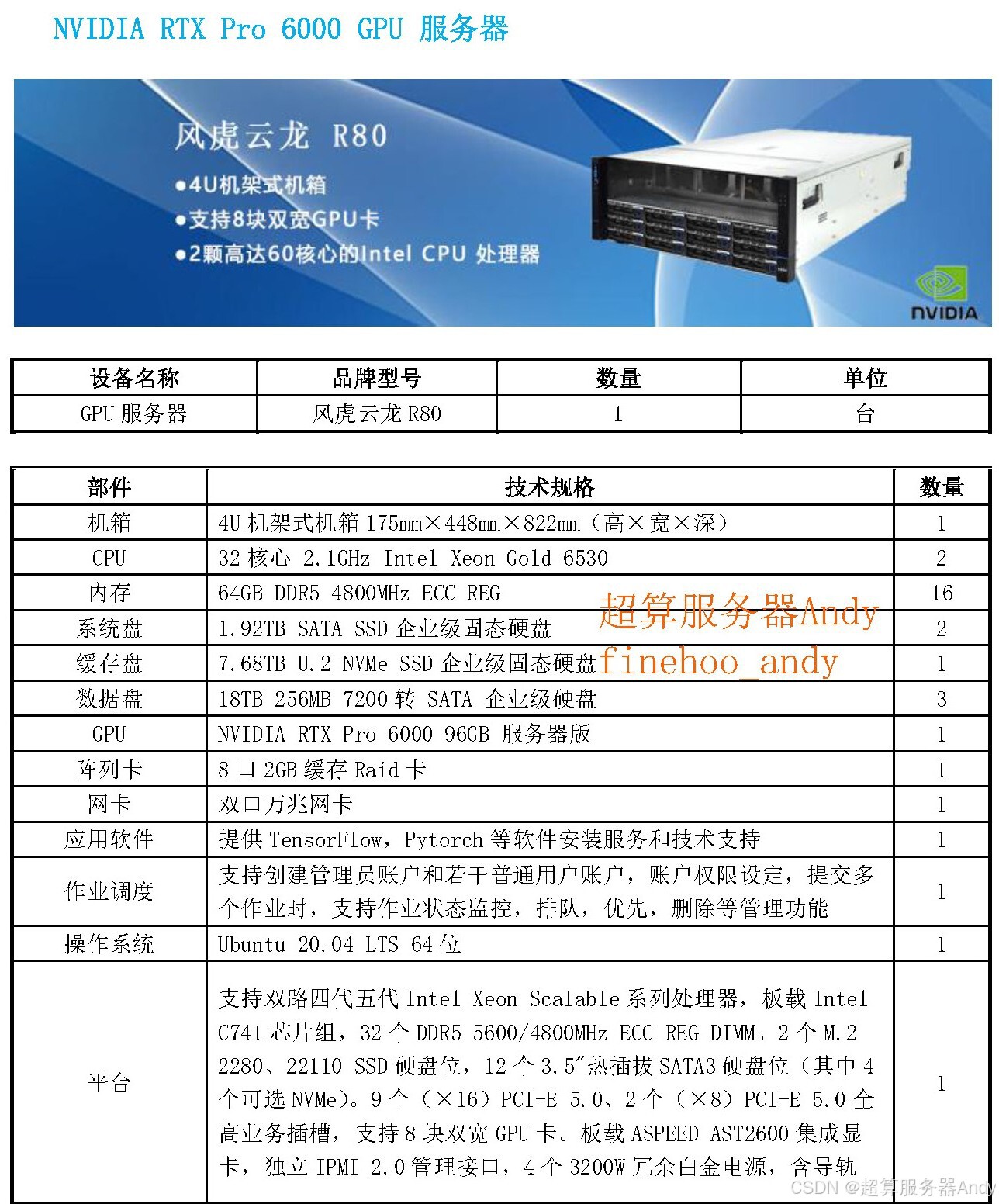
2. 算力:毫秒级交易决策的核心支撑
量化交易的 "Alpha 收益"(超额收益)源于对行情的快速反应,GPU 的并行算力直接决定决策速度与准确性,专业级配置需关注三大核心指标:
- 核心数量:A6000 单卡含 5472 个 CUDA 核心(负责通用计算)、486 个 Tensor 核心(负责 AI 推理加速),可同时运算上百个交易因子,比如在 1 毫秒内完成 "K 线形态 + 资金流向 + 舆情情绪" 的多维度分析;
- 算力性能:单卡 FP16 算力达 34.1 TFLOPS(万亿次浮点运算 / 秒),8 卡集群总算力突破 272.8 TFLOPS,对比传统 CPU(单路至强金牌算力约 0.5 TFLOPS),处理多模态数据速度提升 50 倍以上,可在行情波动时快 10-20 毫秒下单;
- 精度适配:支持 FP16/BF16 混合精度计算,在保证决策准确性的前提下,进一步提升算力效率 ------ 比如用 BF16 计算舆情数据,用 FP16 处理股价波动,算力利用率提升 30% 以上。
3. 互联技术:多卡协同的效率关键
单卡算力再强,若多卡无法高效协同,也无法支撑大规模 AI 量化需求,卡间互联技术直接决定集群性能上限,需满足两大核心要求:
- 带宽与延迟:支持 NVLink™技术的服务器(如 A6000 集群)卡间通信带宽达 600GB/s,延迟低至 1 微秒,比传统 PCIe 4.0×16(带宽 32GB/s,延迟 10 微秒)快近 20 倍,可实现 8 卡实时同步交易信号 ------ 避免 "某张卡判断该卖出,其他卡仍在买入" 的混乱;
- 扩展性:需支持灵活扩展架构(如 1U/2U 机架式设计),可从 4 卡集群升级至 16 卡集群,同时兼容 PCIe 5.0 与 NVLink 双协议,未来接入更高性能 GPU(如 H100)时无需更换服务器主板。
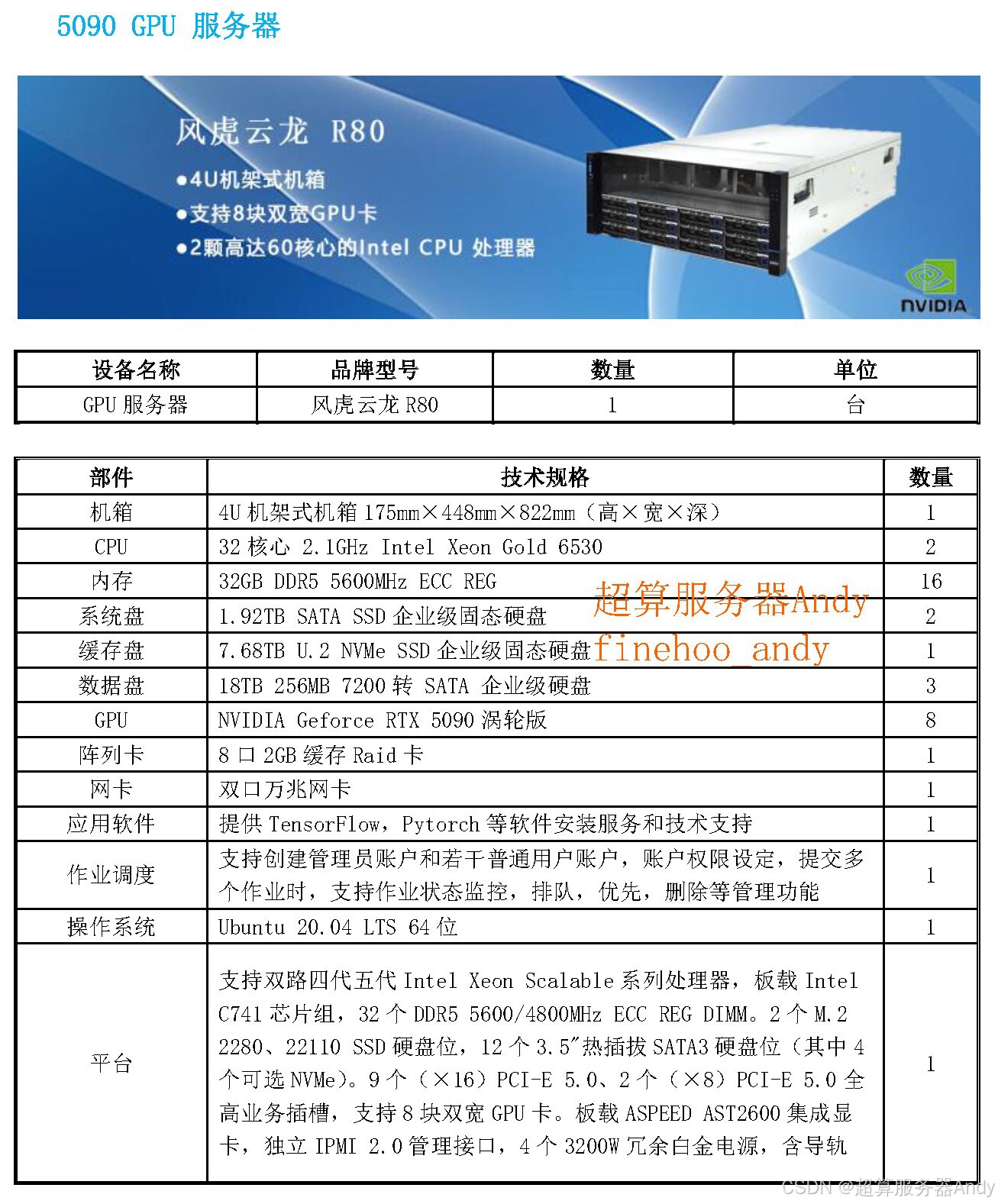
4. 稳定性:720 小时高负载运行的保障
AI 量化需连续回测数据(常需 720 小时以上)、24 小时实盘盯盘,服务器稳定性直接关系交易连续性与数据安全,硬件配置需满足四大标准:
- 算力基座:双路英特尔至强金牌 6348 处理器(28 核 56 线程)+1TB DDR4 ECC 内存,避免因 CPU / 内存性能不足拖慢 GPU 运算 ------ 比如内存带宽不足会导致 GPU "空等数据",算力利用率从 90% 降至 50%;
- 散热系统:采用 "多风扇 + 热管 + 均热板" 的高密度散热模组,单卡散热功率达 300W 以上,可将 GPU 温度控制在 80℃以内,避免因过热导致降频(温度超 90℃时,GPU 算力可能下降 20%);
- 供电设计:2+1 冗余电源(单电源功率 1600W),即使 1 个电源故障,剩余电源仍能支撑服务器运行,避免意外断电导致 "训练中断、数据丢失";
- 硬件监控:内置 IPMI 远程管理模块,可实时监控 GPU 温度、显存使用率、电源状态,出现异常时自动报警(如 GPU 温度超 85℃时触发邮件通知),方便及时排查故障。
二、GPU 服务器如何直接主导 AI 量化交易结果?
在 AI 量化中,GPU 服务器不是 "辅助工具",而是 "核心生产力",其配置差异会直接逆转模型表现:
- 盈利模型的算力支撑:Qwen3-Max 能实现 22.32% 收益率,核心是 8 卡 A6000 集群的 "全维度适配"------384GB 显存保障多数据维度分析,272.8 TFLOPS 算力支撑毫秒级决策,600GB/s 互联确保多卡协同,稳定系统避免交易中断,让模型策略 100% 落地;
- 亏损模型的算力瓶颈:GPT-5 亏损超 62%,根源是算力配置不足 ------ 比如单卡 24GB 显存无法加载完整模型,只能 "简化策略"(如仅看 K 线);PCIe 3.0 互联导致卡间同步延迟,出现 "模型已判断风险,却来不及下单止损";散热不足导致 GPU 频繁降频,算力利用率从 90% 降至 40%,决策速度慢于行情变化。
更关键的是 "算力升级的质变效应":算法优化的边际效益会逐渐递减(优化 10 次策略,收益提升可能仅 5%),但 GPU 服务器升级能带来 "跨越式提升"------ 从 4 卡 A6000 升级到 8 卡,算力提升 100%,模型处理数据维度增加 50%,交易决策速度提升 40%,收益可能直接翻倍;从 A6000 升级到 H100(单卡 FP16 算力 98 TFLOPS),算力提升近 3 倍,可支撑千亿参数模型,捕捉更复杂的市场规律。
三、AI 量化入局者:GPU 服务器选型的三大核心逻辑
对研究者或机构而言,选对 GPU 服务器比优化算法更重要,需紧扣 "模型规模、交易频率、运行需求" 三大维度精准匹配:
1. 按模型规模定显存与集群规模
|-------------------|---------|----------------|----------------|
| 模型参数规模 | 单卡显存要求 | 集群配置建议 | 核心优势 |
| 十亿级(如 Llama 2-7B) | 24GB 以上 | 4 卡 RTX 4090 | 成本低,适合策略原型验证 |
| 百亿级(如 Qwen3-Max) | 40GB 以上 | 8 卡 A6000 | 平衡性能与成本,支持实盘交易 |
| 千亿级(如 GPT-5) | 80GB 以上 | 16 卡 H100 SXM5 | 超大规模显存,支持复杂策略 |
2. 按交易频率定算力与互联技术
- 高频交易(日内短线 / 套利):优先选高算力 + 高带宽配置 ------ 如 8 卡 H100 集群(单卡 FP16 算力 98 TFLOPS,NVLink 带宽 600GB/s),确保 1 毫秒内完成 "数据接收→模型推理→下单指令" 全流程,避免因延迟错过套利机会;
- 中低频交易(日线 / 周线策略):可平衡成本与性能 ------ 如 8 卡 A6000 集群,算力满足日线数据处理需求,互联带宽保障多卡协同,成本比 H100 集群低 40%。
3. 按运行需求定稳定性配置
- 实验室场景(仅回测):可选用准工业级服务器(如单路 CPU + 非冗余电源),但需确保 ECC 内存与基础散热(避免数据错误);
- 实盘场景(24 小时运行):必须选工业级配置 ------ 双路 CPU+ECC 内存 + 2+1 冗余电源 + IPMI 监控,比如浪潮 NF5488A5(支持 8 卡 A6000,带 IPMI 远程管理),确保全年故障率低于 0.5%。