一、引言
在电商交易领域,管理类目作为业务责权划分、统筹、管理核心载体,随着业务复杂性的提高,其规则调整频率从最初的 1 次 / 季度到多次 / 季度,三级类目的规则复杂度也呈指数级上升。传统依赖数仓底层更新的方式暴露出三大痛点:
- 行业无法自主、快速调管理类目;
- 业务管理类目规则调整,不支持校验类目覆盖范围是否有重复/遗漏,延长交付周期;
- 规则变更成功后、下游系统响应滞后,无法及时应用最新类目规则。
本文将从技术视角解析 "管理类目配置线上化" 项目如何通过全链路技术驱动,将规则迭代周期缩短至 1-2 天。
二、业务痛点与技术挑战:为什么需要线上化?
2.1 效率瓶颈:手工流程与
高频迭代的矛盾
问题场景:业务方需线下通过数仓提报规则变更,经数仓开发、测试、BI需要花费大量精力校验确认,一次类目变更需 3-4 周左右时间才能上线生效,上线时间无法保证。
技术瓶颈:数仓离线同步周期长(T+1),规则校验依赖人工梳理,无法应对 "商品类目量级激增"。
2.2 质量风险:规则复杂度与
校验能力的失衡
典型问题:当前的管理类目映射规则,依赖业务收集提报,但从实际操作看管理三级类目映射规则提报质量较差(主要原因为:业务无法及时校验提报规则是否准确,是否穷举完善,是否完全无交叉),存在大量重复 / 遗漏风险。
2.3 系统耦合:底层变更对
下游应用的多米诺效应
连锁影响:管理类目规则变更会需同步更新交易后台、智能运营系统、商运关系工作台等多下游系统,如无法及时同步,可能会影响下游应用如商运关系工作台的员工分工范围的准确性,影响商家找人、资质审批等场景应用。
三、技术方案:从架构设计到核心模块拆解
3.1 分层架构:解耦业务与数据链路
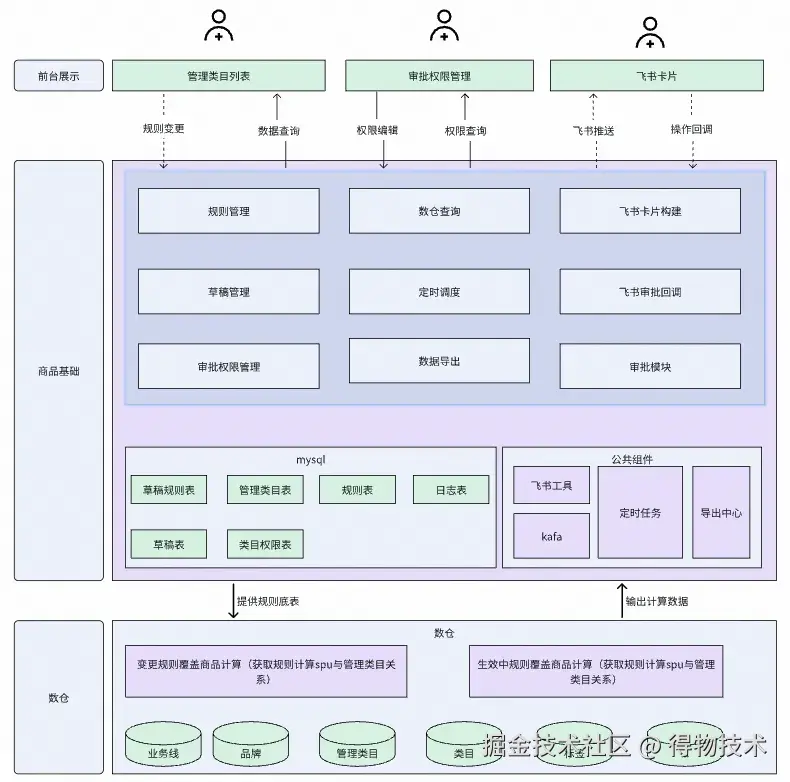
3.2 核心模块技术实现
规则生命周期管理: 规则操作流程
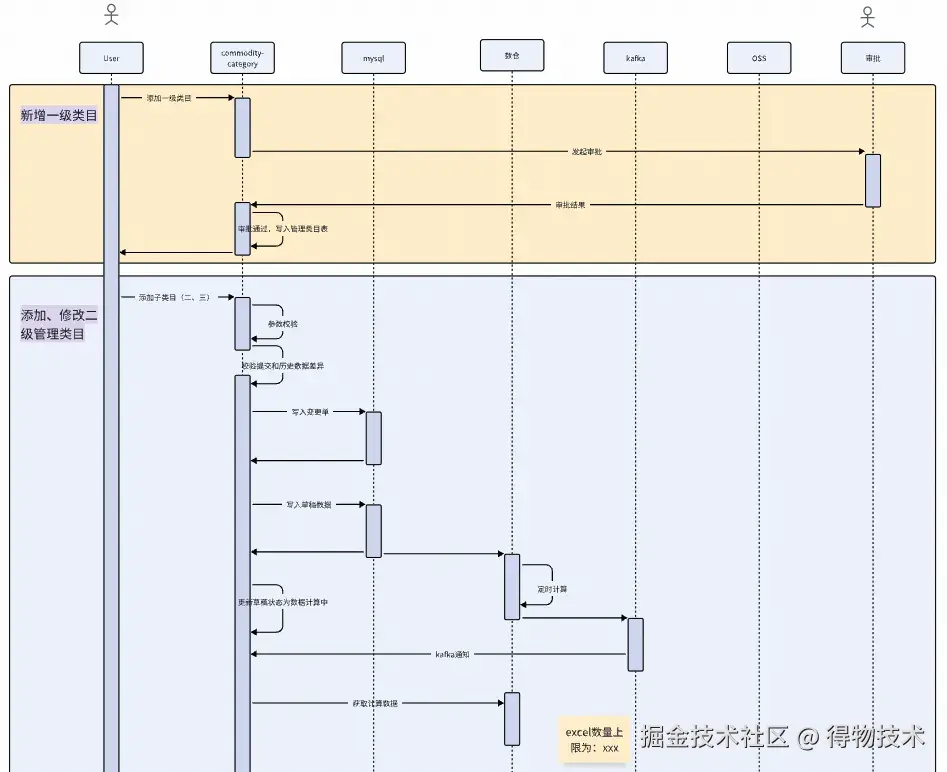

提交管理类目唯一性校验规则
新增:id为空,则为新增
删除:当前db数据不在提交保存列表中
更新:名称或是否兜底类目或规则改变则发生更新【其中如果只有名称改变则只触发审批,不需等待数据校验,业务规则校验逻辑为将所有规则包含id,按照顺序排序拼接之后结果是否相等】
多级类目查询
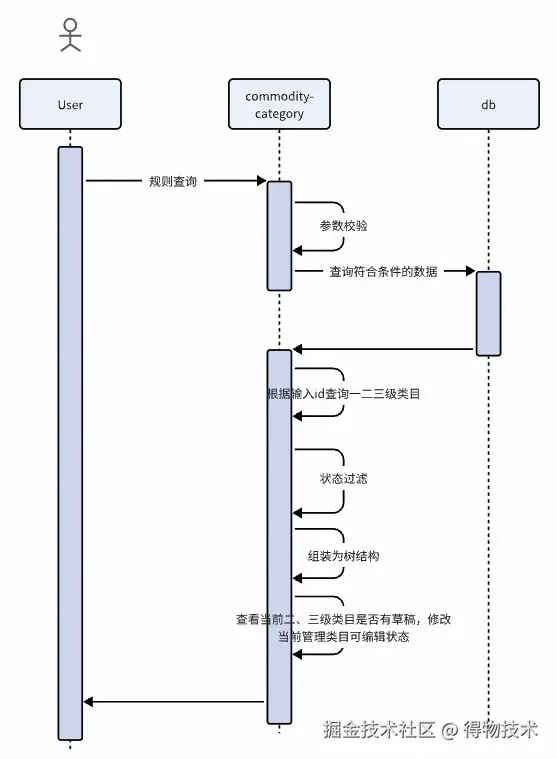
构建管理类目树
scss
/**
* 构建管理类目树
*/
public List<ManagementCategoryDTO> buildTree(List<ManagementCategoryEntity> managementCategoryEntities) {
Map<Long, ManagementCategoryDTO> managementCategoryMap = new HashMap<>();
for (ManagementCategoryEntity category : managementCategoryEntities) {
ManagementCategoryDTO managementCategoryDTO = ManagementCategoryMapping.convertEntity2DTO(category);
managementCategoryMap.put(category.getId(), managementCategoryDTO);
}
// 找到根节点
List<ManagementCategoryDTO> rootNodes = new ArrayList<>();
for (ManagementCategoryDTO categoryNameDTO : managementCategoryMap.values()) {
//管理一级类目 parentId是0
if (Objects.equals(categoryNameDTO.getLevel(), ManagementCategoryLevelEnum.FIRST.getId()) && Objects.equals(categoryNameDTO.getParentId(), 0L)) {
rootNodes.add(categoryNameDTO);
}
}
// 构建树结构
for (ManagementCategoryDTO node : managementCategoryMap.values()) {
if (node.getLevel() > ManagementCategoryLevelEnum.FIRST.getId()) {
ManagementCategoryDTO parentNode = managementCategoryMap.get(node.getParentId());
if (parentNode != null) {
parentNode.getItems().add(node);
}
}
}
return rootNodes;
}填充管理类目规则
scss
/**
* 填充规则信息
*/
private void populateRuleData
(List<ManagementCategoryDTO> managementCategoryDTOS, List<ManagementCategoryRuleEntity> managementCategoryRuleEntities) {
if (CollectionUtils.isEmpty(managementCategoryDTOS) || CollectionUtils.isEmpty(managementCategoryRuleEntities)) {
return;
}
List<ManagementCategoryRuleDTO> managementCategoryRuleDTOS =managementCategoryMapping.convertRuleEntities2DTOS(managementCategoryRuleEntities);
// 将规则集合按 categoryId 分组
Map<Long, List<ManagementCategoryRuleDTO>> rulesByCategoryIdMap = managementCategoryRuleDTOS.stream()
.collect(Collectors.groupingBy(ManagementCategoryRuleDTO::getCategoryId));
// 递归填充规则到树结构
fillRulesRecursively(managementCategoryDTOS, rulesByCategoryIdMap);
}
/**
* 递归填充规则到树结构
*/
private static void fillRulesRecursively
(List<ManagementCategoryDTO> managementCategoryDTOS, Map<Long, List<ManagementCategoryRuleDTO>> rulesByCategoryIdMap) {
if (CollectionUtils.isEmpty(managementCategoryDTOS) || MapUtils.isEmpty(rulesByCategoryIdMap)) {
return;
}
for (ManagementCategoryDTO node : managementCategoryDTOS) {
// 获取当前节点对应的规则列表
List<ManagementCategoryRuleDTO> rules = rulesByCategoryIdMap.getOrDefault(node.getId(), new ArrayList<>());
node.setRules(rules);
// 递归处理子节点
fillRulesRecursively(node.getItems(), rulesByCategoryIdMap);
}
}状态机驱动:管理类目生命周期管理
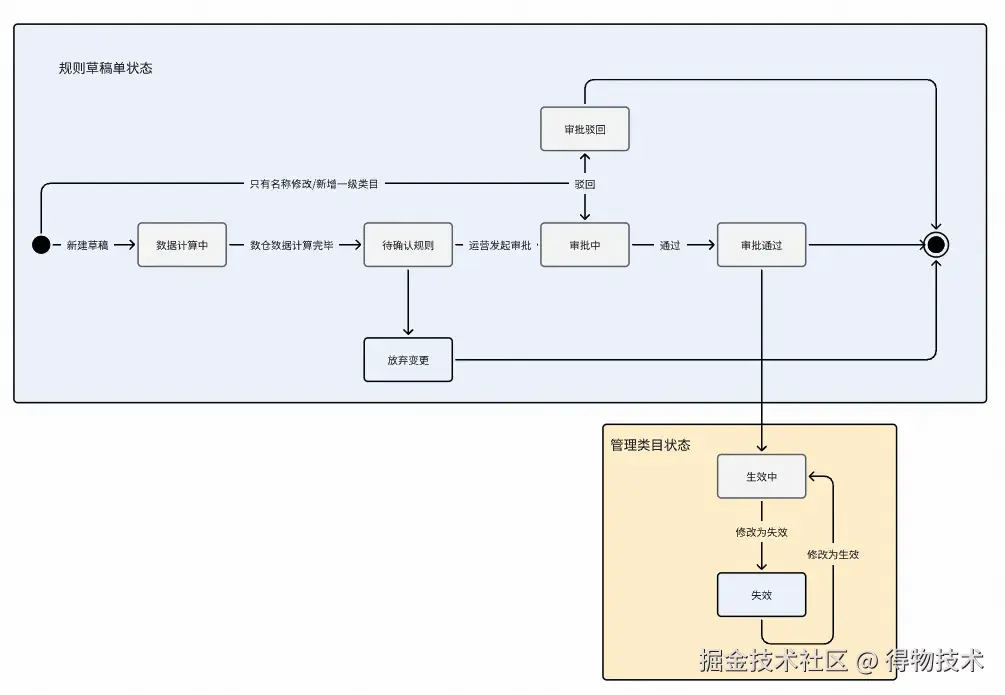
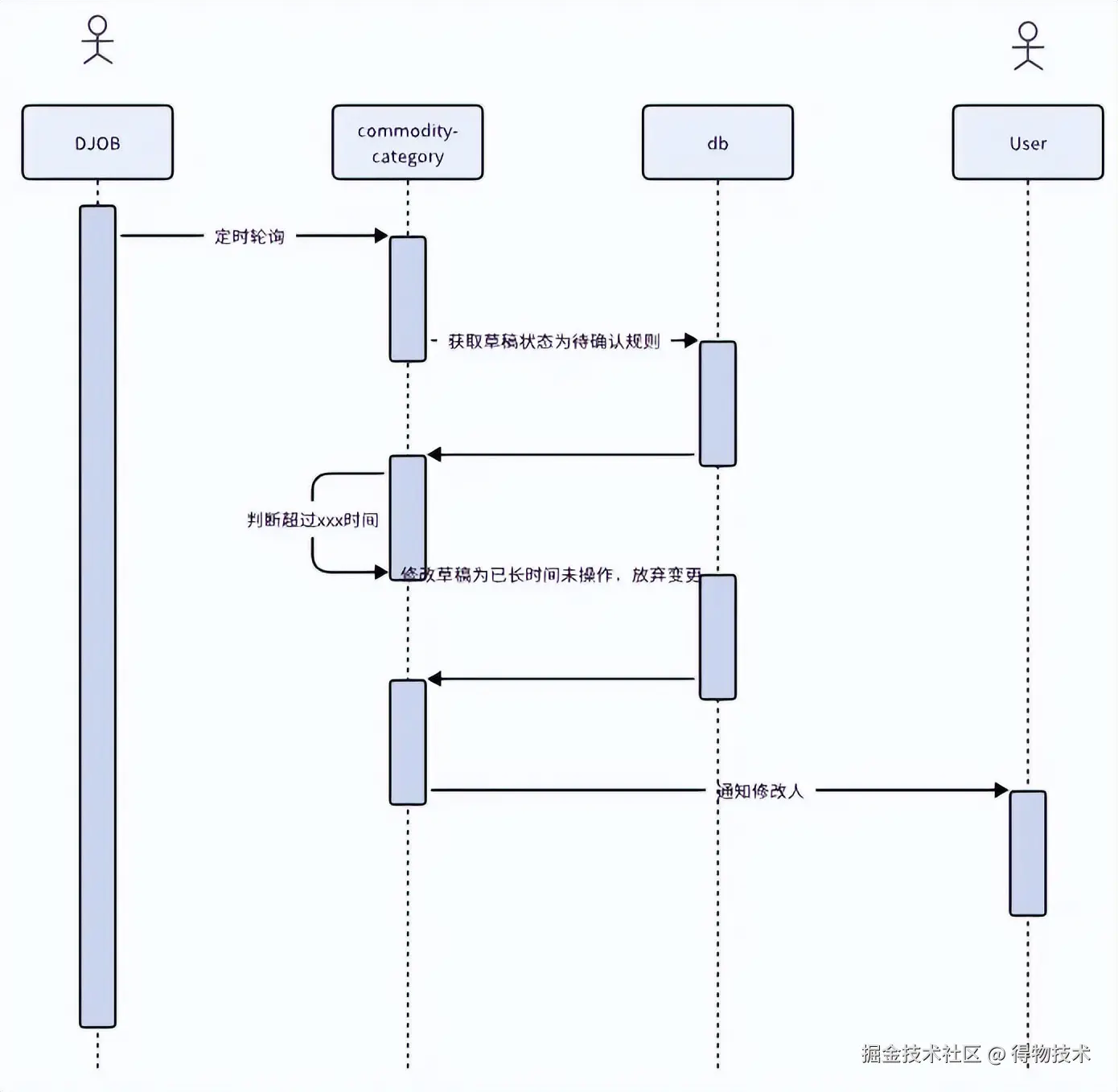
超时机制 :基于时间阈值的流程阻塞保护
其中,为防止长时间运营处于待确认规则状态,造成其他规则阻塞规则修改,定时判断待确认规则状态持续时间,当时间超过xxx时间之后,则将待确认状态改为长时间未操作,放弃变更状态,并飞书通知规则修改人。
管理类目状态变化级联传播策略
类目生效和失效状态为级联操作。规则如下:
- 管理二级类目有草稿状态时,不允许下挂三级类目的编辑;
- 管理三级类目有草稿状态时,不允许对应二级类目的规则编辑;
- 类目生效失效状态为级联操作,上层修改下层级联修改状态,如果下层管理类目存在草稿状态,则自动更改为放弃更改状态。
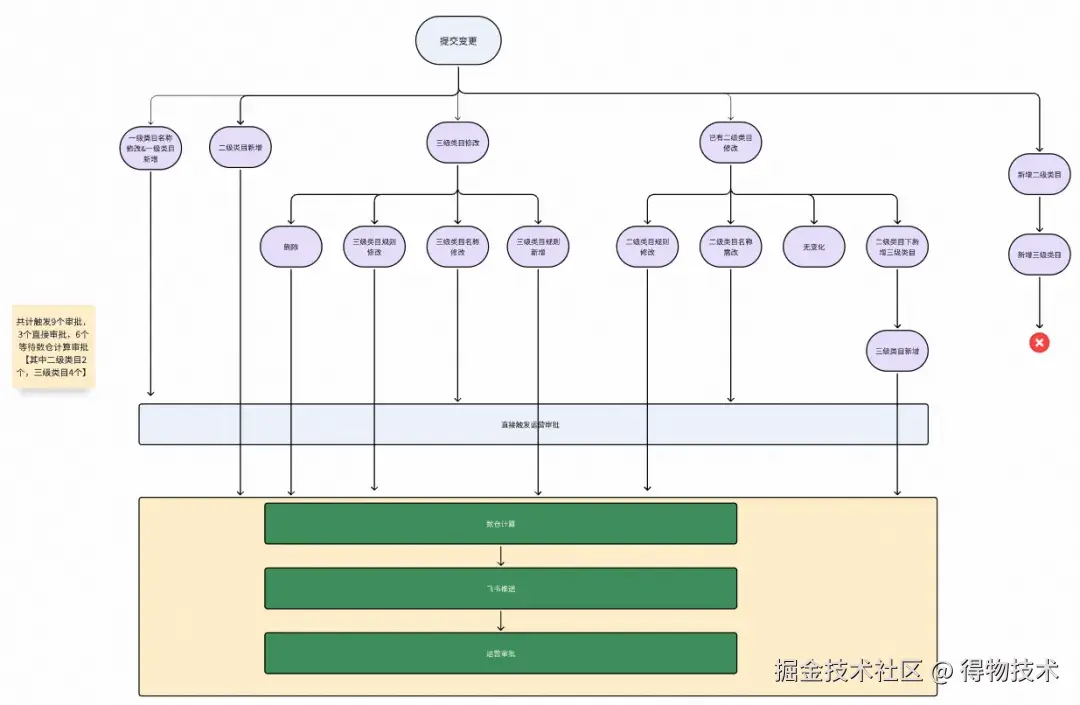
规则变更校验逻辑
当一次提交,可能出现的情况如下。一次提交可能会产生多个草稿,对应多个审批流程。
新增管理类目规则:
- 一级管理类目可以直接新增(点击新增一级管理类目)
- 二级管理类目和三级管理类目不可同时新增
- 三级管理类目需要在已有二级类目基础上新增
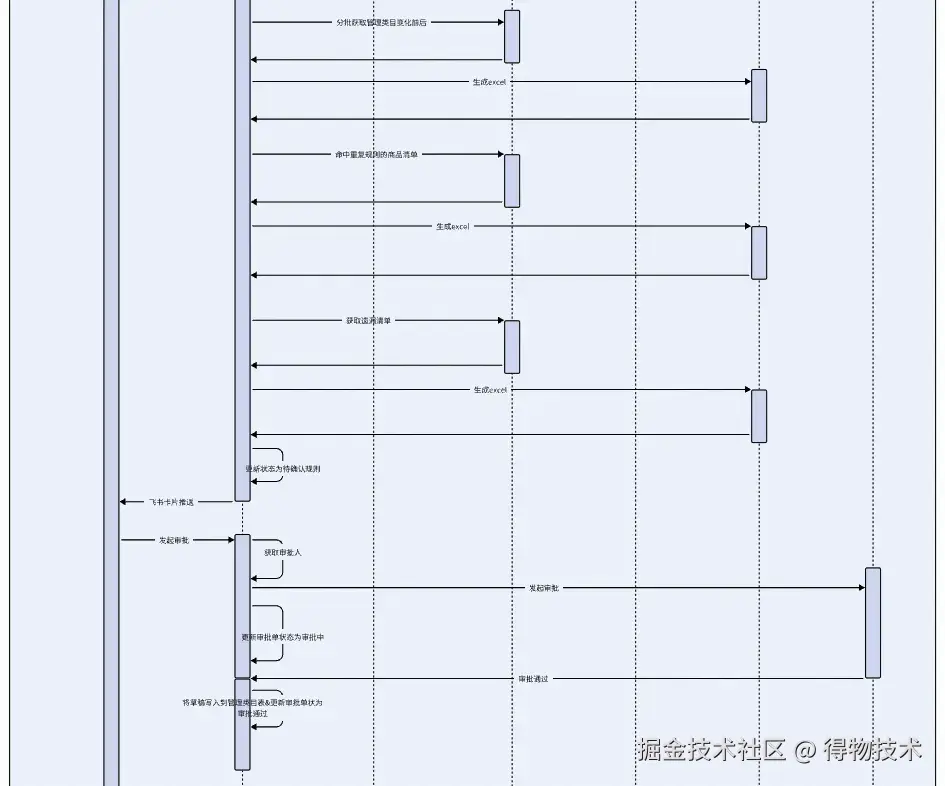
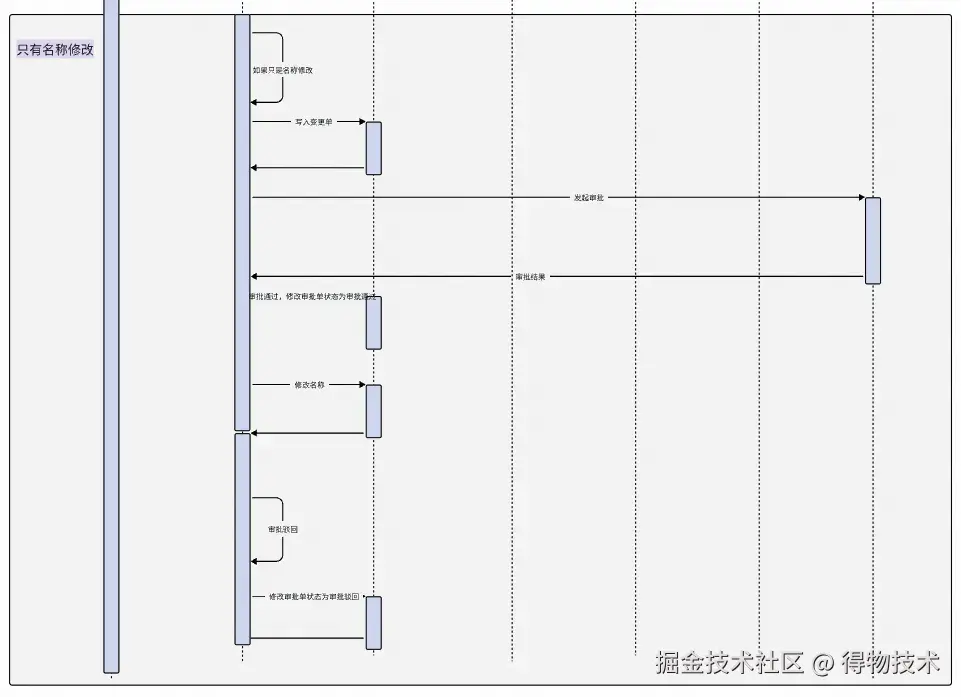
只有名称修改触发直接审批,有规则修改需要等待数仓计算结果之后,运营提交发起审批。
交互通知中心:飞书卡片推送
- 变更规则数据计算结果依赖数仓kafka计算结果回调。
- 基于飞书卡片推送数仓计算结果,回调提交审批和放弃变更事件。
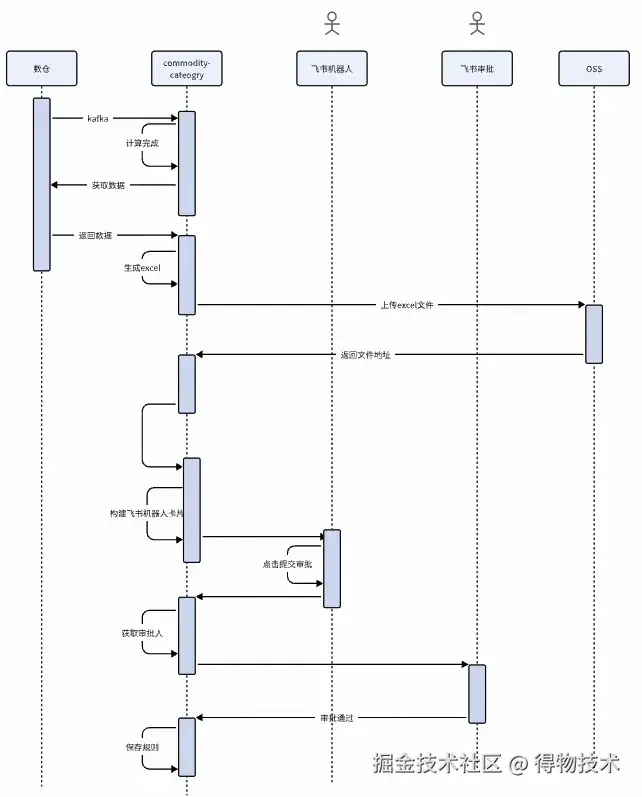
飞书卡片:
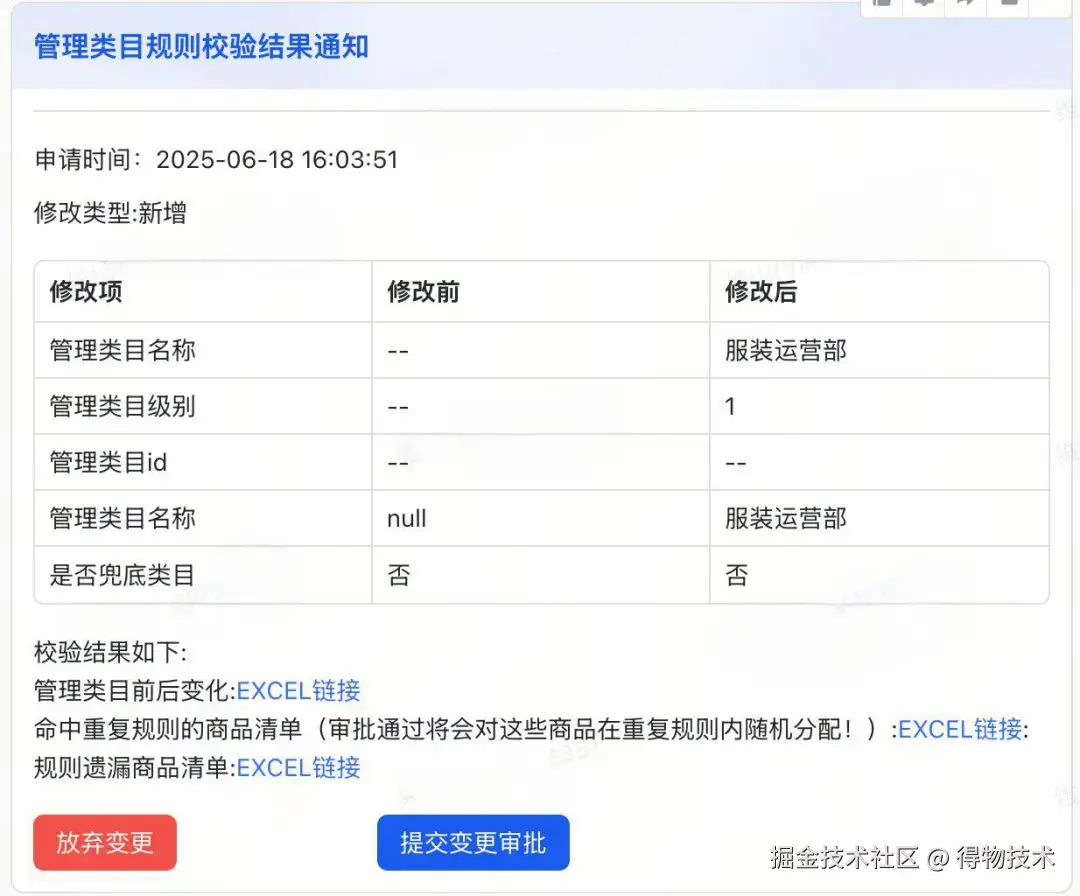
卡片结果
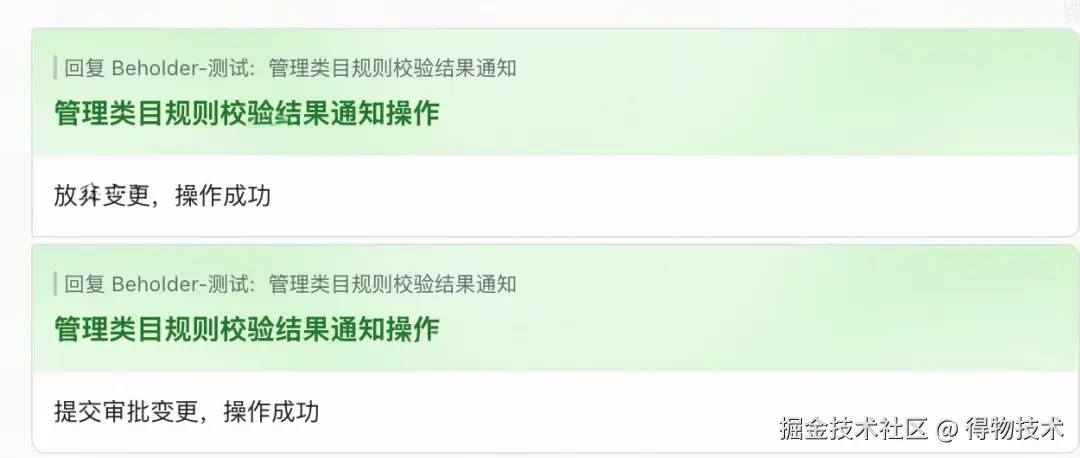
卡片操作结果
审批流程:多维度权限控制与飞书集成
提交审批的四种情况:
- 名称修改
- 一级类目新增
- 管理类目规则修改
- 生效失效变更
审批通过,将草稿内容更新到管理类目表中,将管理类目设置为生效中。
审批驳回,清空草稿内容。
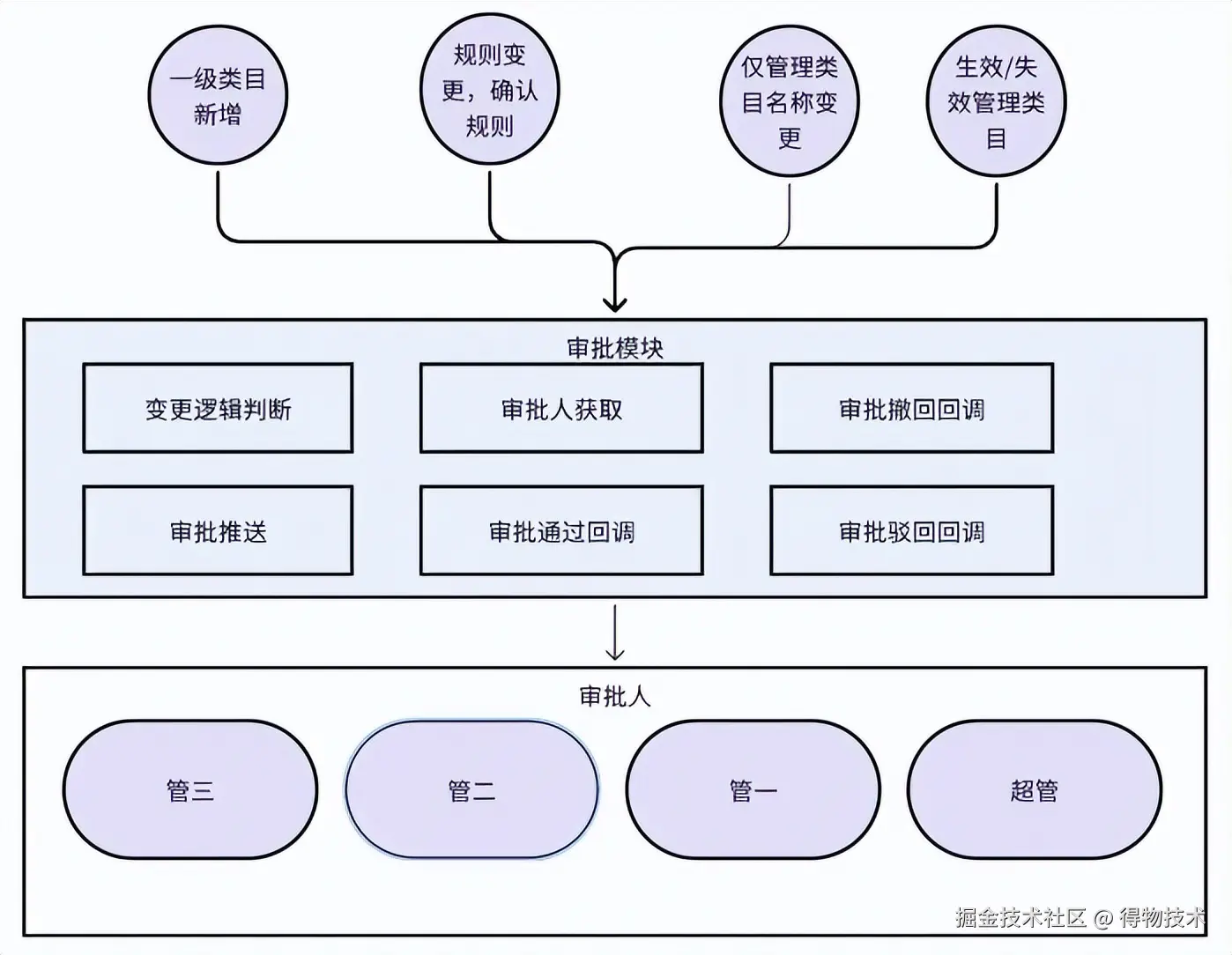
审批人分配机制:多草稿并行审批方案
一次提交可能会产生多个草稿,对应多个审批流程。
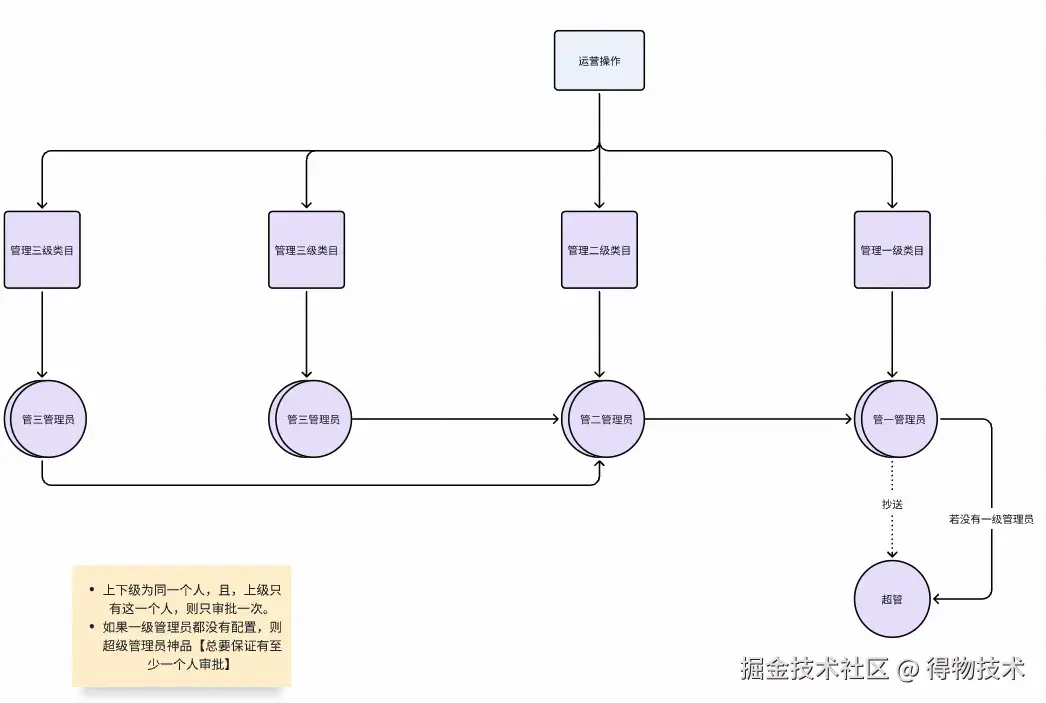
审批逻辑
ini
public Map<String, List<String>> buildApprover(
ManagementCategoryDraftEntity draftEntity,
Map<Long, Set<String>> catAuditorMap,
Map<String, String> userIdOpenIdMap,
Integer hasApprover) {
Map<String, List<String>> nodeApprover = new HashMap<>();
// 无审批人模式,直接查询超级管理员
if (!Objects.equals(hasApprover, ManagementCategoryUtils.HAS_APPROVER_YES)) {
nodeApprover.put(ManagementCategoryApprovalField.NODE_SUPER_ADMIN_AUDIT,
queryApproverList(0L, catAuditorMap, userIdOpenIdMap));
return nodeApprover;
}
Integer level = draftEntity.getLevel();
Integer draftType = draftEntity.getType();
boolean isEditOperation = ManagementCategoryDraftTypeEnum.isEditOp(draftType);
// 动态构建审批链(支持N级类目)
List<Integer> approvalChain = buildApprovalChain(level);
for (int i = 0; i < approvalChain.size(); i++) {
int currentLevel = approvalChain.get(i);
Long categoryId = getCategoryIdByLevel(draftEntity, currentLevel);
// 生成节点名称(如:NODE_LEVEL2_ADMIN_AUDIT)
String nodeKey = String.format(
ManagementCategoryApprovalField.NODE_LEVEL_X_ADMIN_AUDIT_TEMPLATE,
currentLevel
);
// 编辑操作且当前层级等于提交层级时,添加本级审批人 【新增的管理类目没有还没有对应的审批人】
if (isEditOperation && currentLevel == level) {
addApprover(nodeApprover, nodeKey, categoryId, catAuditorMap, userIdOpenIdMap);
}
// 非本级审批人(上级层级)
if (currentLevel != level) {
addApprover(nodeApprover, nodeKey, categoryId, catAuditorMap, userIdOpenIdMap);
}
}
return nodeApprover;
}
private List<Integer> buildApprovalChain(Integer level) {
List<Integer> approvalChain = new ArrayList<>();
if (level == 3) {
approvalChain.add(2); // 管二审批人
approvalChain.add(1); // 管一审批人
} else if (level == 2) {
approvalChain.add(2); // 管二审批人
approvalChain.add(1); // 管一审批人
} else if (level == 1) {
approvalChain.add(1); // 管一审批人
approvalChain.add(0); // 超管
}
return approvalChain;
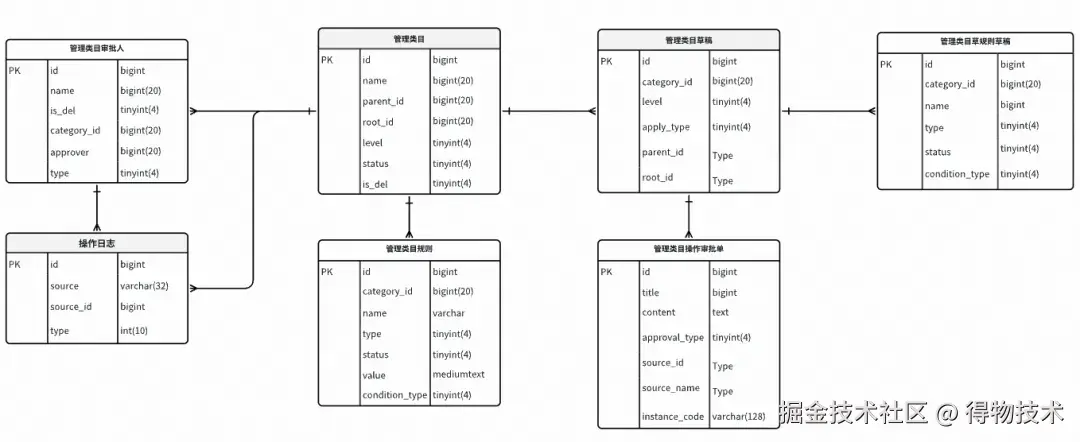
}3.3 数据模型设计
3.4 数仓计算逻辑
同步数据方式
方案一:
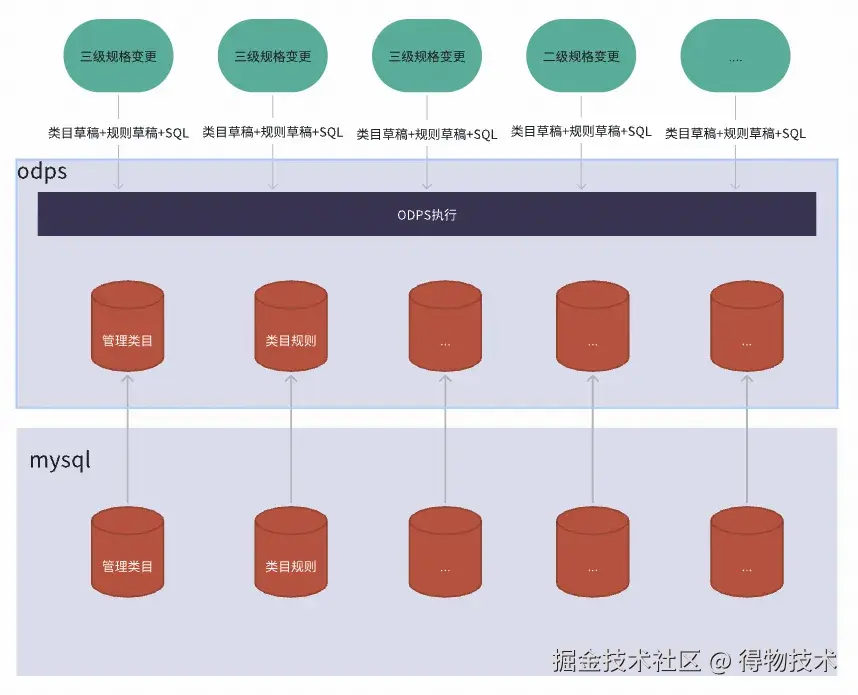
每次修改规则之后通过调用SQL触发离线计算
优势:通过SQL调用触发计算,失效性较高
劣势:ODPS 资源峰值消耗与SQL脚本耦合问题
- 因为整个规则修改是三级类目维度,如果同时几十几百个类目触发规则改变,会同时触发几十几百个离线任务。同时需要大量ODPS 资源;
- 调用SQL方式需要把当前规则修改和计算逻辑的SQL一起调用计算。
方案二:
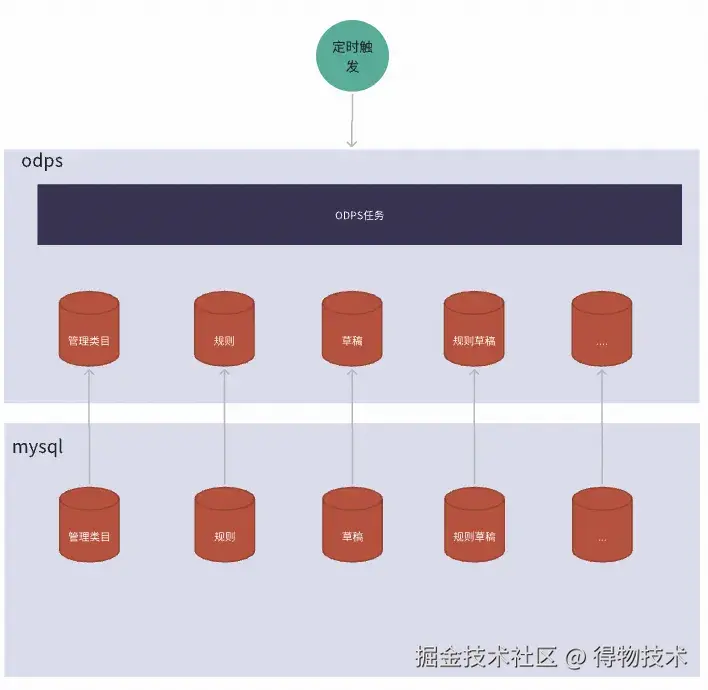
优势:同时只会产生一次规则计算
劣势:实时性受限于离线计算周期
- 实时性取决于离线规则计算的定时任务配置和离线数据同步频率,实时性不如直接调用SQL性能好
- 不重不漏为当前所有变更规则维度
技术决策:常态化迭代下的最优解
考虑到管理类目规则平均变更频率不高,且变更时间点较为集中(非紧急场景占比 90%),故选择定时任务方案实现:
- 资源利用率提升:ODPS 计算资源消耗降低 80%,避免批量变更时数百个任务同时触发的资源峰值;
- 完整性保障:通过全量维度扫描确保规则校验无遗漏,较 SQL 触发方案提升 20% 校验覆盖率;
- 可维护性优化:减少 SQL 脚本与业务逻辑的强耦合,维护成本降低 80%。
数据取数逻辑
生效中规则计算
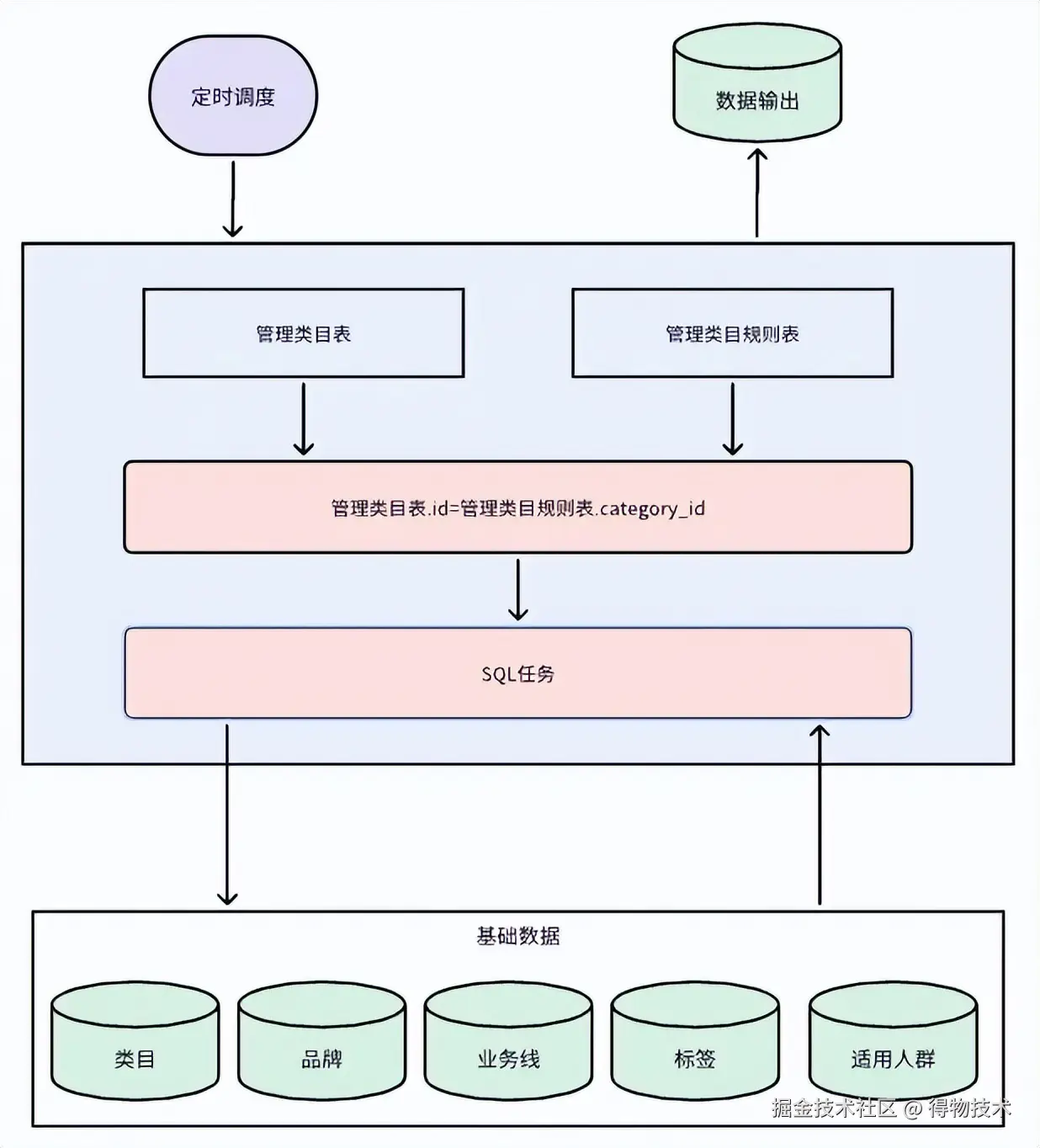
草稿+生效中规格计算
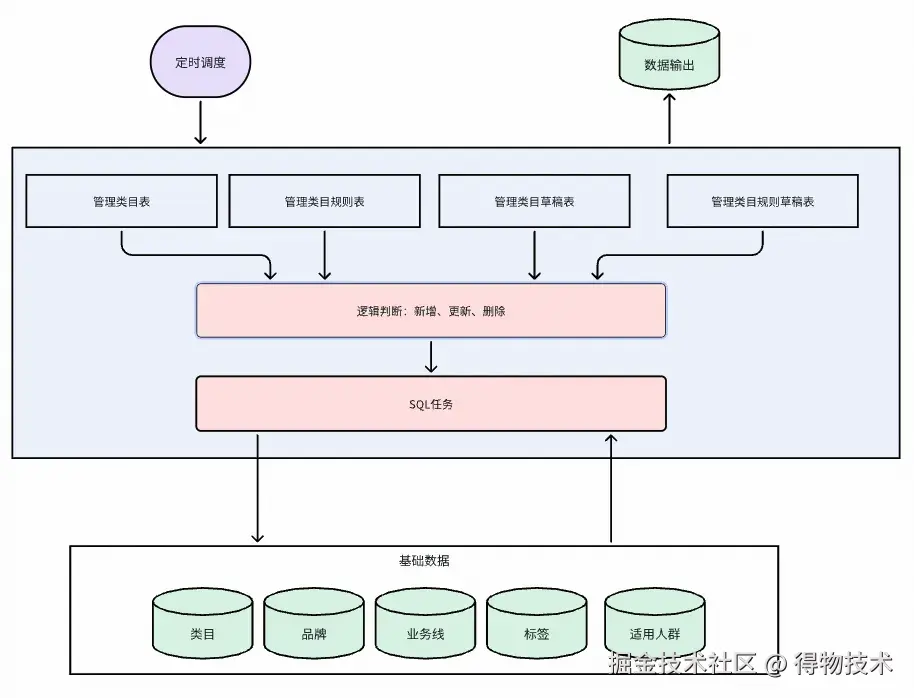
如果是新增管理类目,直接参与计算。
如果是删除管理类目,需要将该删除草稿中对应的生效管理类目排除掉。
如果是更新:需要将草稿中的管理类目和规则替换生效中对应的管理类目和规则。
数仓实现
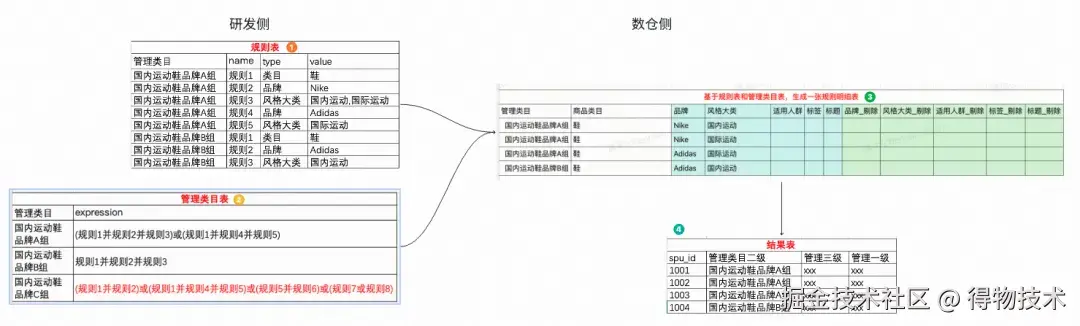
数据流程图
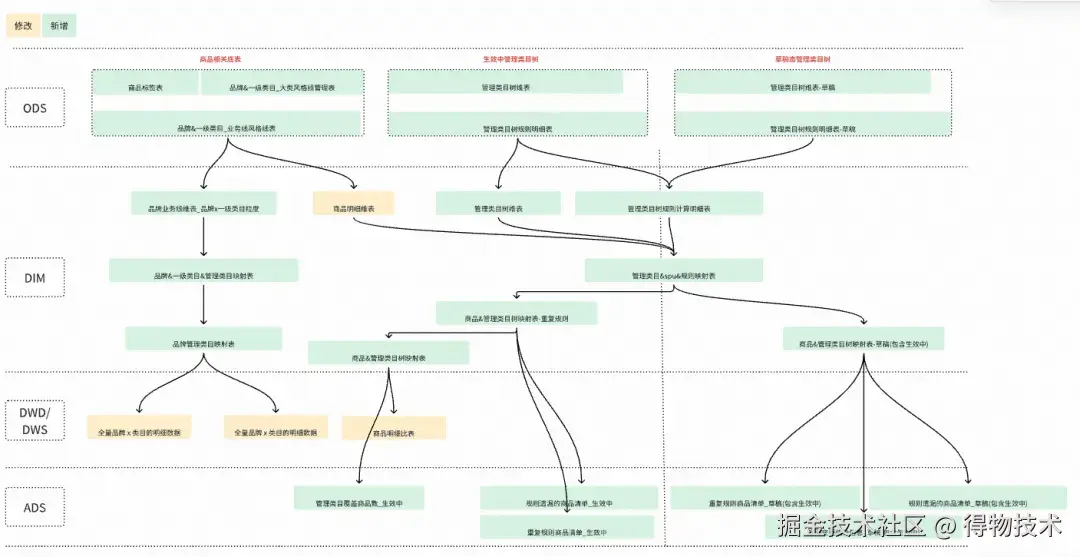
四、项目成果与技术价值
预期效率提升:从 "周级" 到 "日级" 的跨越
- 管理一级 / 二级类目变更开发零成本,无需额外人力投入
- 管理三级类目变更相关人力成本降低 100%,无需额外投入开发资源
- 规则上线周期压缩超 90%,仅需 1 - 2 天即可完成上线
质量保障:自动化校验替代人工梳理
- 规则重复 / 遗漏检测由人工梳理->自动化计算
- 下游感知管理类目规则变更由人工通知->实时感知
技术沉淀:规则模型化能力
沉淀管理类目规则配置模型,支持未来四级、五级多级管理类目快速适配。
五、总结
未来优化方向:
- 规则冲突预警:基于AI预测高风险规则变更,提前触发校验
- 接入flink做到实时计算管理类目和对应商品关系
技术重构的本质是 "释放业务创造力"
管理类目配置线上化项目的核心价值,不仅在于技术层面的效率提升,更在于通过自动化工具链,让业务方从 "规则提报的执行者" 转变为 "业务策略的设计者"。当技术架构能够快速响应业务迭代时,企业才能在电商领域的高频竞争中保持创新活力。
往期回顾
-
大模型如何革新搜索相关性?智能升级让搜索更"懂你"|得物技术
-
RAG---Chunking策略实战|得物技术
-
告别数据无序:得物数据研发与管理平台的破局之路
-
从一次启动失败深入剖析:Spring循环依赖的真相|得物技术
-
Apex AI辅助编码助手的设计和实践|得物技术
文 /维山
关注得物技术,每周更新技术干货
要是觉得文章对你有帮助的话,欢迎评论转发点赞~
未经得物技术许可严禁转载,否则依法追究法律责任。