Spark on Yarn安装部署
(1)上传并解压
tar -zxvf spark-3.1.1-bin-hadoop3.2.tgz -C /opt/module/(2)环境变量
vim /etc/profile.d/my_env.sh
export SPARK_HOME=/opt/module/spark-3.1.1-bin-hadoop3.2
export PATH=$SPARK_HOME/bin:$PATH
source /etc/profile验证成功
spark-submit --version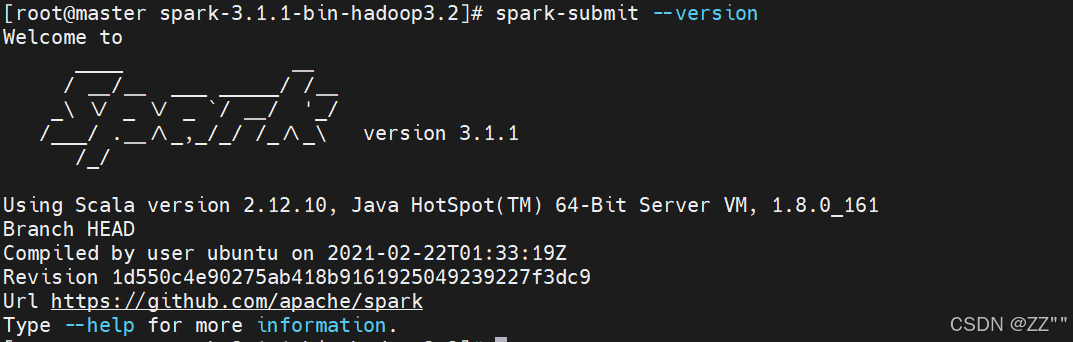
(3)修改hadoop配置文件yarn-site.xml
vim /opt/module/hadoop-3.1.4/etc/hadoop/yarn-site.xml
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--任务每使用1MB物理内存,最多可使用虚拟内存量,默认2.1-->
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4</value>
</property>分发
scp -r /opt/module/hadoop-3.1.4/etc/hadoop/yarn-site.xml slave1:/opt/module/hadoop-3.1.4/etc/hadoop/
scp -r /opt/module/hadoop-3.1.4/etc/hadoop/yarn-site.xml slave2:/opt/module/hadoop-3.1.4/etc/hadoop/重启yarn
(4)修改spark-env.sh
备份,复制一份文件改名。
cp spark-env.sh.template spark-env.sh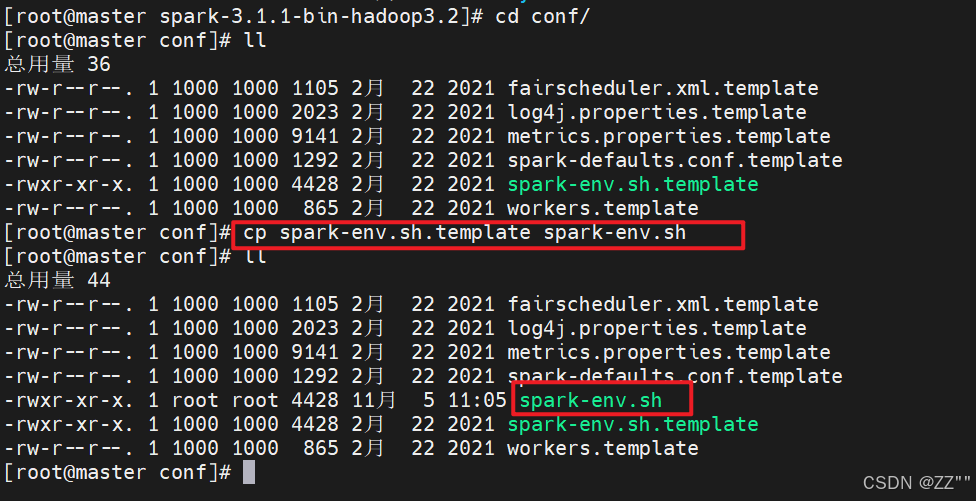
export JAVA_HOME=/opt/module/jdk1.8.0_161
export YARN_CONF_DIR=/opt/module/hadoop-3.1.4/etc/hadoop
export HADOOP_CONF_DIR=/opt/module/hadoop-3.1.4/etc/hadoop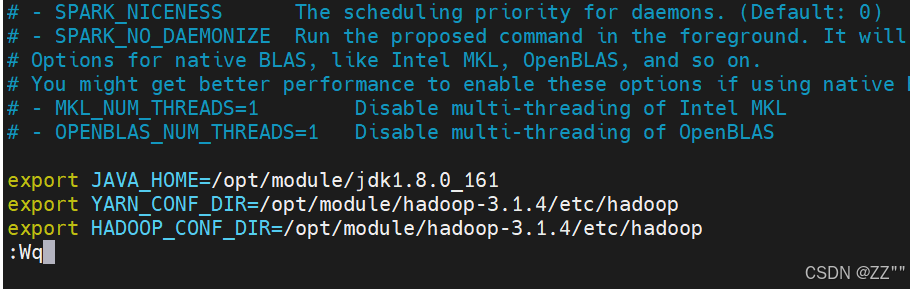
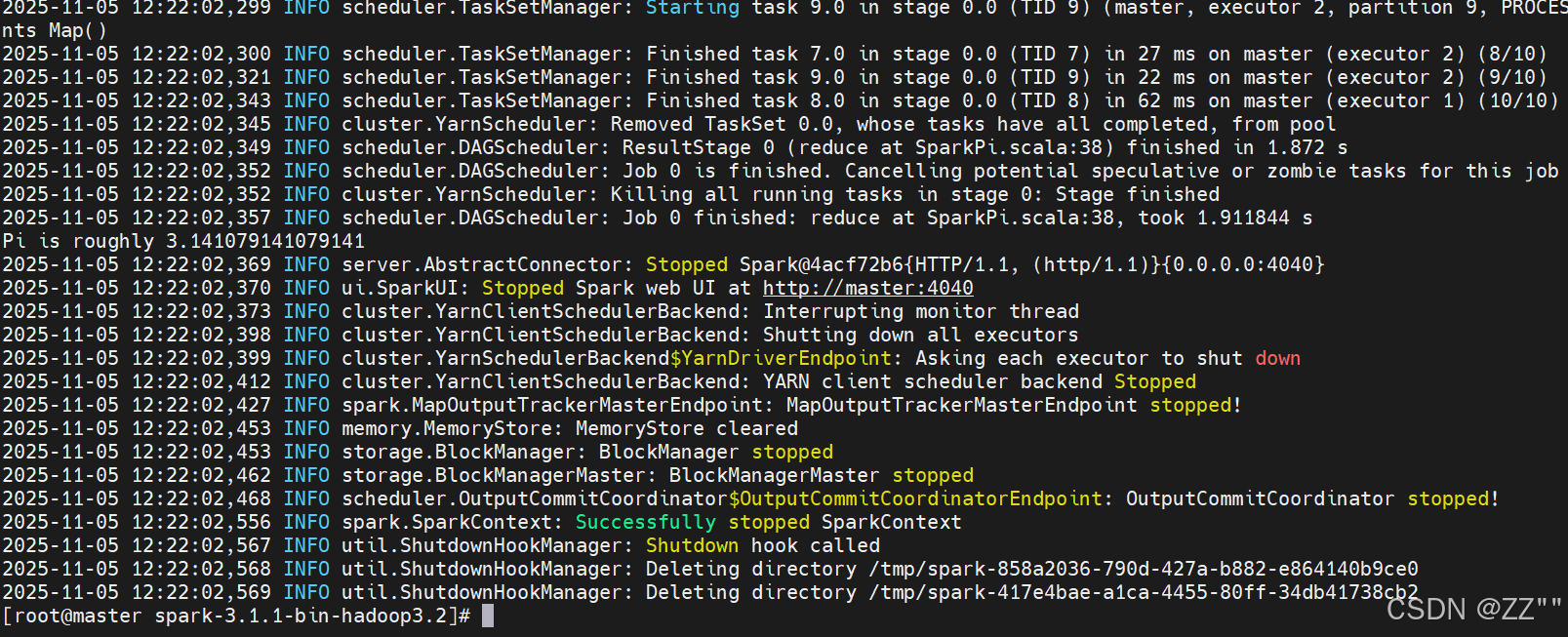
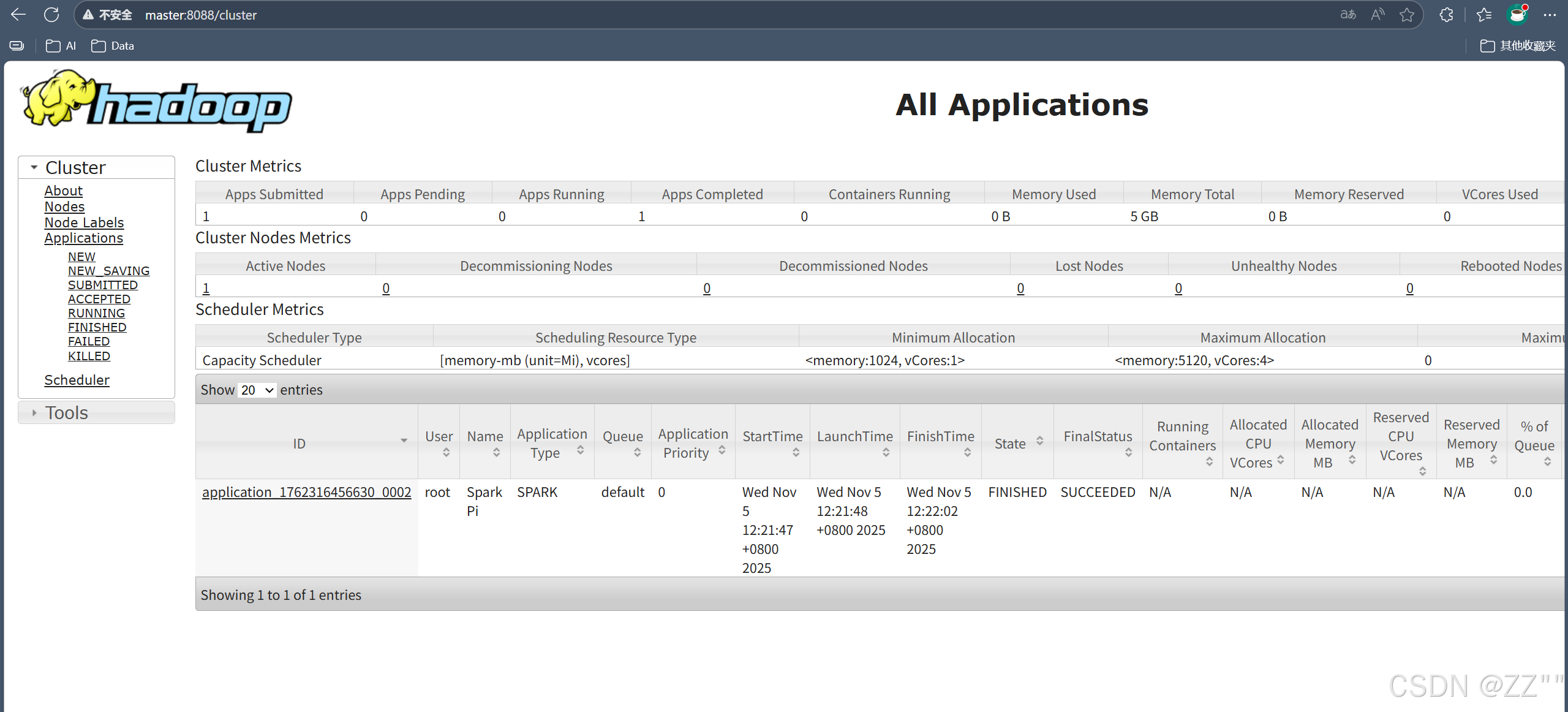
spark-submit --class org.apache.spark.examples.SparkPi --master yarn ./examples/jars/spark-examples_2.12-3.1.1.jar 10安装成功