一、RAGFlow是什么
RAGFlow 是一款基于深度文档理解构建的开源 RAG(Retrieval-Augmented Generation)引擎。RAGFlow 可以为各种规模的企业及个人提供一套精简的 RAG 工作流程,结合大语言模型(LLM)针对用户各类不同的复杂格式数据提供可靠的问答以及有理有据的引用。
二、安装与部署
2.1 前提条件
- CPU >= 4 核
- RAM >= 16 GB
- Disk >= 50 GB
- Docker >= 24.0.0 & Docker Compose >= v2.26.1
如果你并没有在本机安装 Docker(Windows、Mac,或者 Linux), 可以参考文档 Install Docker Engine 自行安装。
2.2 在Win11上部署的准备工作
2.2.1 安装前的准备工作
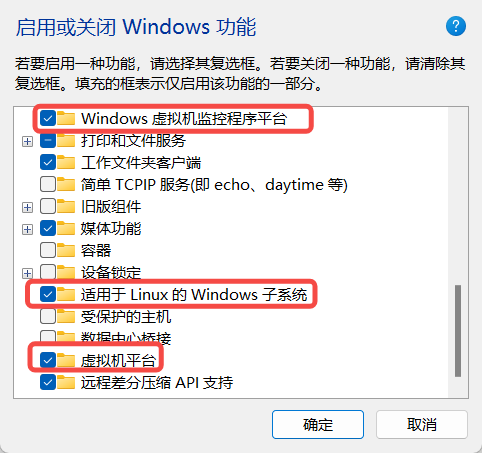
首先需要在开始菜单中搜索启用或关闭 Windows 功能,勾选上以下选项。勾选后需要重启计算机。
2.2.2 在windows上安装Docker
-
访问Docker-Desktop下载页面,下载对应的windows安装包。(建议安装版本较新的docker,本人下载的版本为4.38.0,旧版本打开时可能会出现WSL报错)
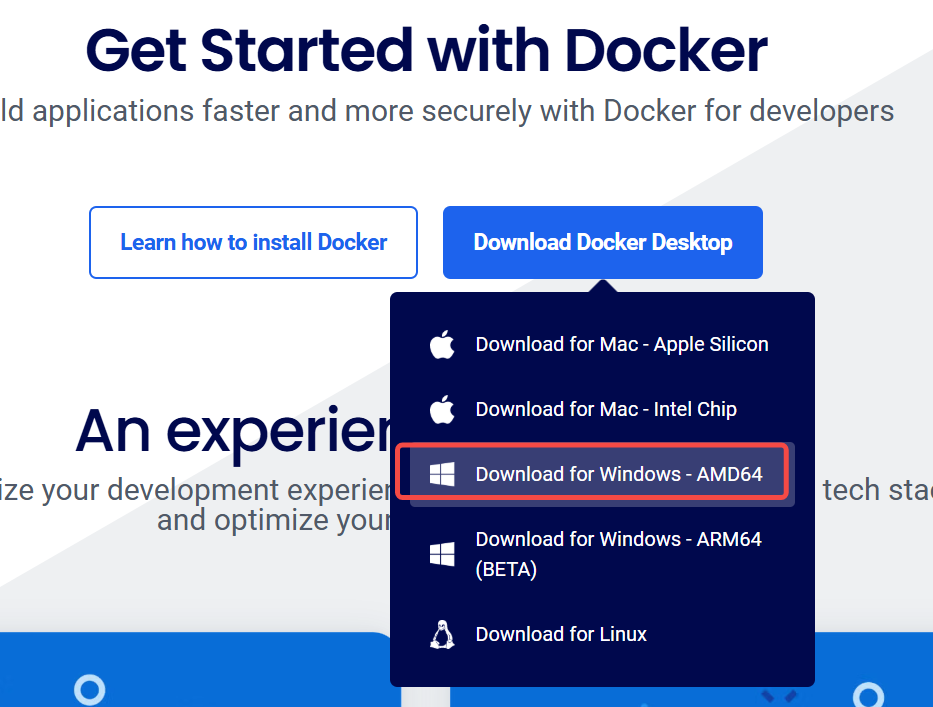
-
安装后勾选以下配置
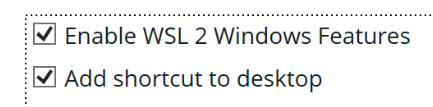
-
安装后运行,可跳过登录页面,看到下述界面就成功了
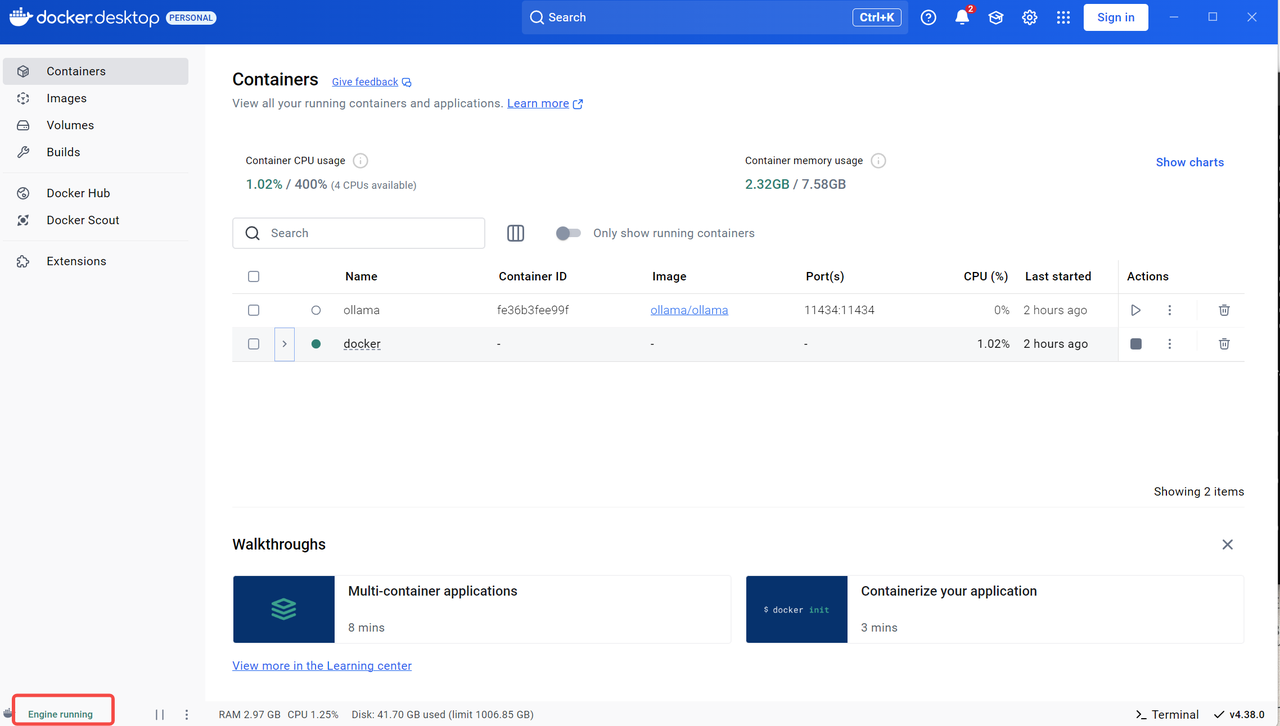
2.2.3 为Docker添加必要的镜像源
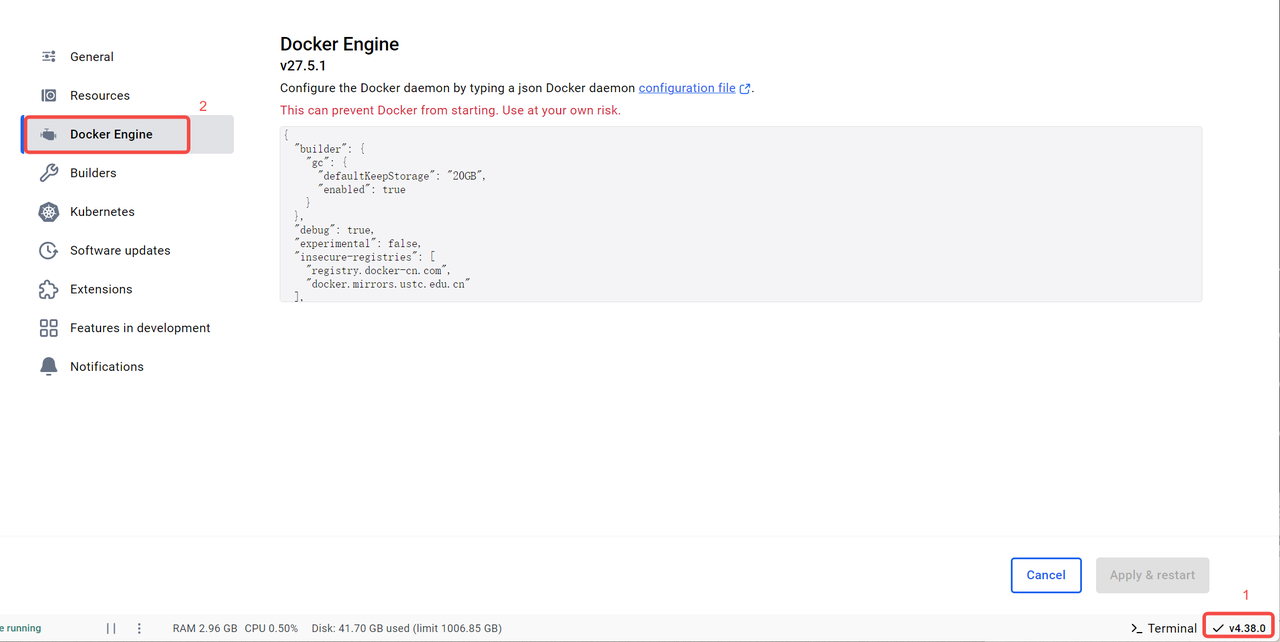
将默认内容修改为以下内容:(不添加镜像源在拉取docker时很可能会报错)
bash
{
"builder": {
"gc": {
"defaultKeepStorage": "20GB",
"enabled": true
}
},
"debug": true,
"experimental": false,
"insecure-registries": [
"registry.docker-cn.com",
"docker.mirrors.ustc.edu.cn"
],
"registry-mirrors": [
"https://docker.registry.cyou",
"https://docker-cf.registry.cyou",
"https://dockercf.jsdelivr.fyi",
"https://docker.jsdelivr.fyi",
"https://dockertest.jsdelivr.fyi",
"https://mirror.aliyuncs.com",
"https://dockerproxy.com",
"https://mirror.baidubce.com",
"https://docker.m.daocloud.io",
"https://docker.nju.edu.cn",
"https://docker.mirrors.sjtug.sjtu.edu.cn",
"https://docker.mirrors.ustc.edu.cn",
"https://mirror.iscas.ac.cn",
"https://docker.rainbond.cc",
"https://do.nark.eu.org",
"https://dc.j8.work",
"https://dockerproxy.com",
"https://gst6rzl9.mirror.aliyuncs.com",
"https://registry.docker-cn.com",
"http://hub-mirror.c.163.com",
"http://mirrors.ustc.edu.cn/",
"https://mirrors.tuna.tsinghua.edu.cn/",
"http://mirrors.sohu.com/"
]
}2.2.4 修改Docker的Container memory usage
这项内容可以不用修改,如果docker内存运行容量不足可能需要(例如在docker中再运行ollama),以下是修改步骤:
-
在C:\Users<你的用户名> 文件夹下修改/新建 .wslconfig 文件
-
在文件中添加以下内容:
bash[wsl2] memory=8GB # 分配给WSL 2的最大内存量 processors=4 # 可以使用的处理器核心数 swap=6GB # 交换分区大小 -
关闭wsl(在命令行中输入wsl --shutdown)
-
等待docker恢复重连即可(或者在命令行中输入wsl,检查配置是否报错)
2.3 在windows上中部署ollama相关服务
-
Ollama下载:在ollama文档中,点击windows的下载即可下载ollama框架服务,运行并安装。
-
下载chart模型:ollama run llama3.2
-
下载embedding模型:ollama run bge-m3
-
运行ollama服务:ollama serve
-
验证ollama服务是否正常运行:http://127.0.0.1:11434/
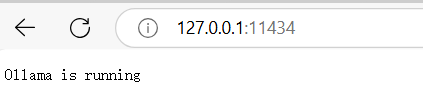
-
请检查是否可以从 RAGFlow 容器内部访问 ollama:
bashdocker exec -it ragflow-server bash root@8136b8c3e914:/ragflow# curl http://host.docker.internal:11434/
出现Ollama is running打印即代表从docker中可访问ollama服务
- 与 llama3.2 进行聊天(需启动ollama服务):ollama run llama3.2
你会立即收到来自模型的回复:
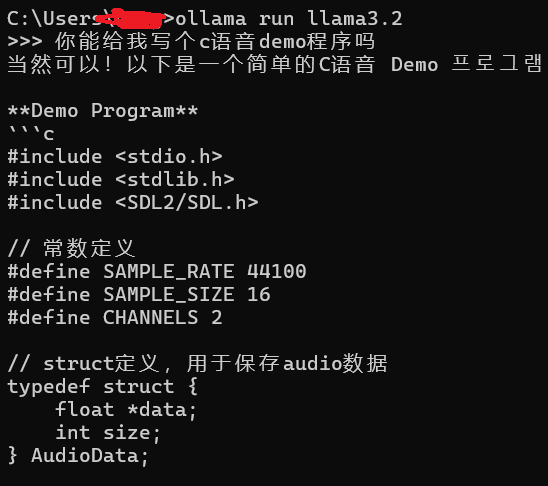
注意:在windows中部署ollama服务尽量不要在docker中进行部署,否则对gpu的使用默认是不支持的。
2.4 在Docker中部署RAGFlow相关服务并运行验证
完整的RAGFlow流程可参考:官方中文文档。
-
在命令行中进入docker文件夹,修改.env文件:根据变量 RAGFLOW_IMAGE 的注释提示选择华为云或者阿里云的相应镜像。(这里本人使用的版本为 v0.15-sim 版本,0.17.1版本实测在系统模型设置中存在不能添加自定义模型的问题)

目前官方提供的所有 Docker 镜像均基于 x86 架构构建,并不提供基于 ARM64 的 Docker 镜像。 如果你的操作系统是 ARM64 架构,请参考这篇文档自行构建 Docker 镜像。
-
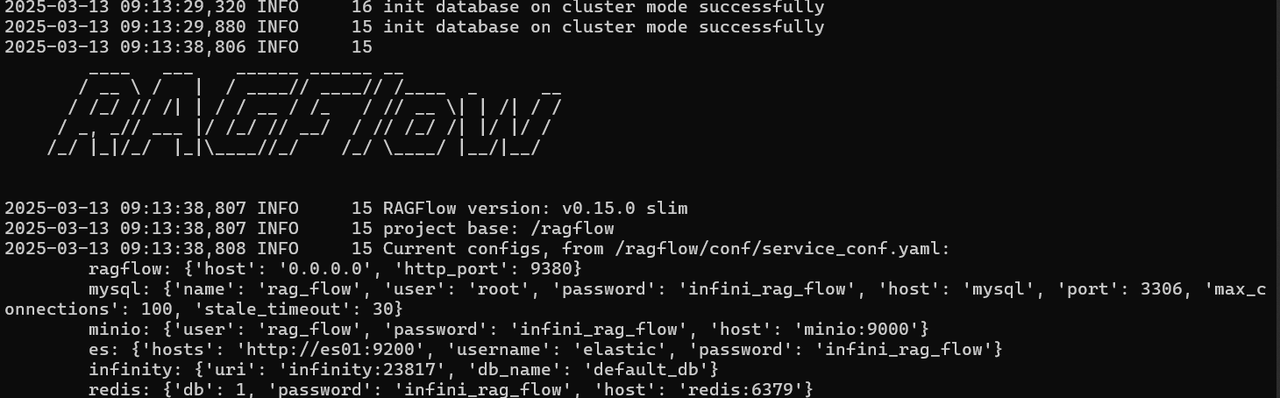
服务器启动成功后再次确认服务器状态:运行docker logs -f ragflow-server
出现以下内容即表示运行成功,此时可以在浏览器中输入http://120.0.0.1 即可:未改动过配置则无需输入端口(默认的 HTTP 服务端口 80)
-
进入系统后,需要注册一个账户就行(注意:此账户为本地账户)
-
登录系统后,点击右上角个人信息(可以修改页面语言模式,进入模型供应商添加自己的模型):
当然,下列模型你都可以选择,但是如果不是本地/公司部署的模型,需要你输入API Key
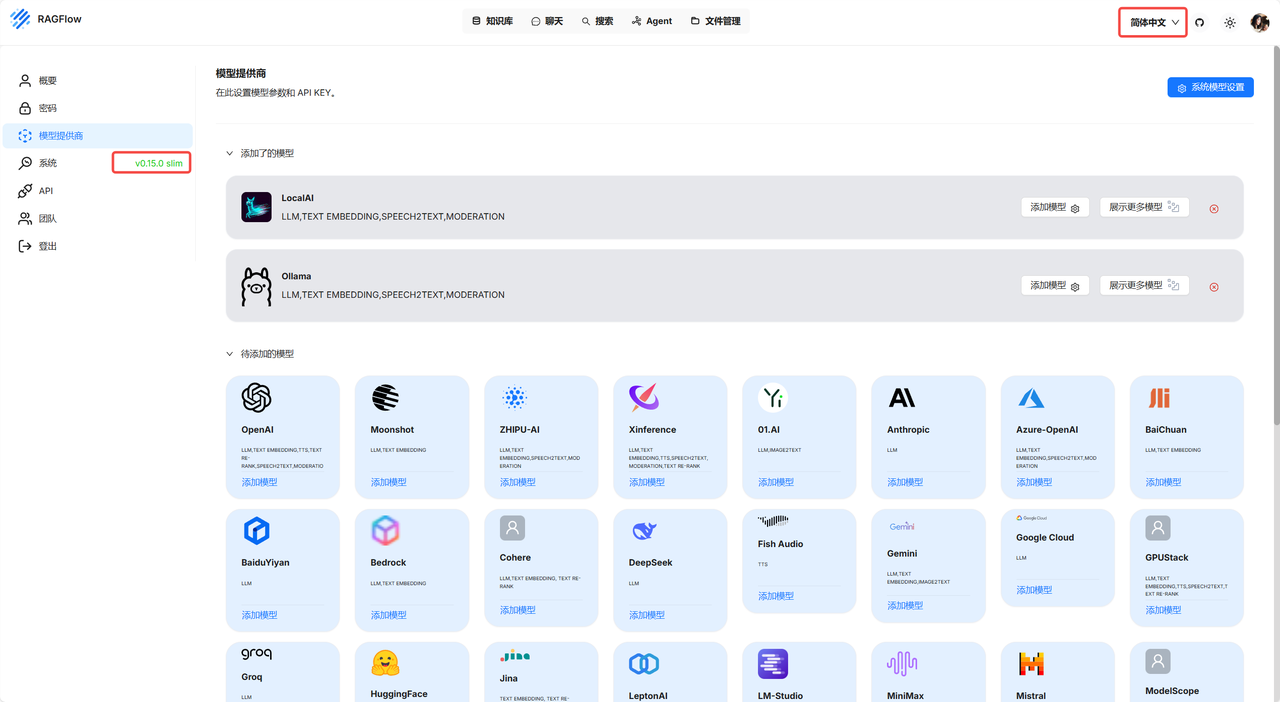
-
添加完自定义模型后,在系统模型设置中添加自己的模型即可。
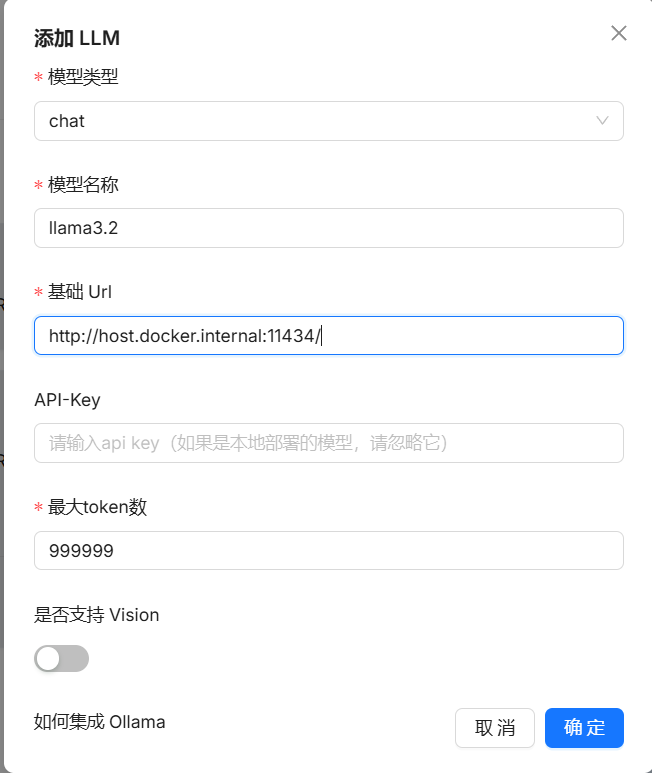
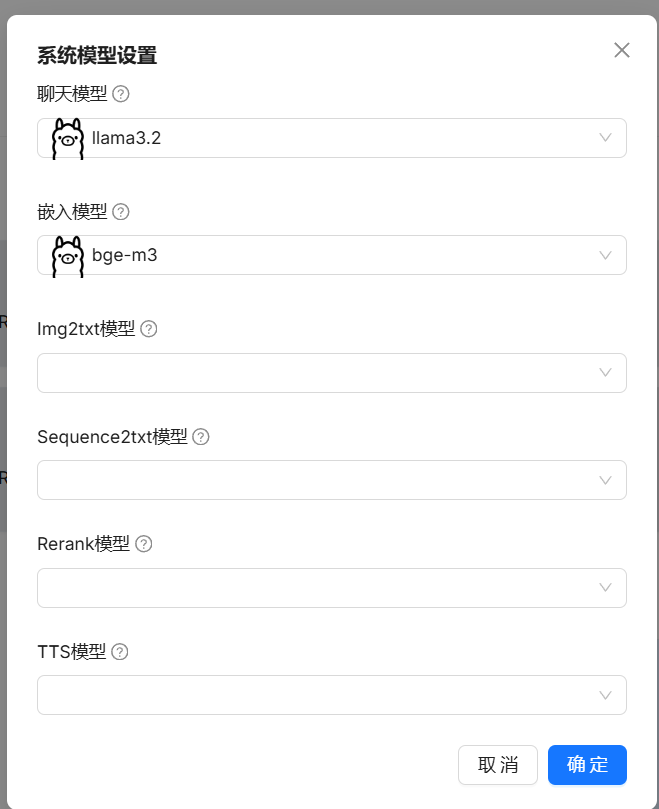
-
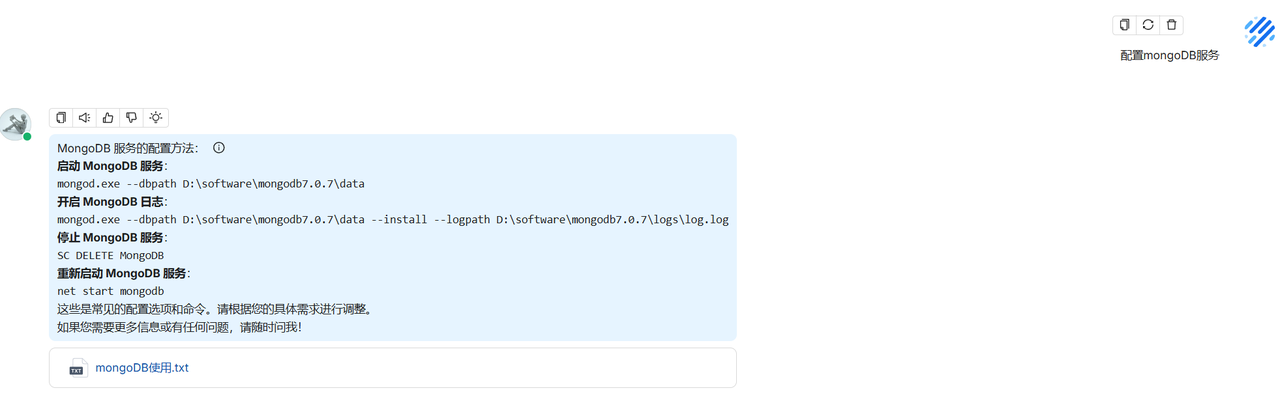
构建知识库:
选用自己的embedding模型进行解析
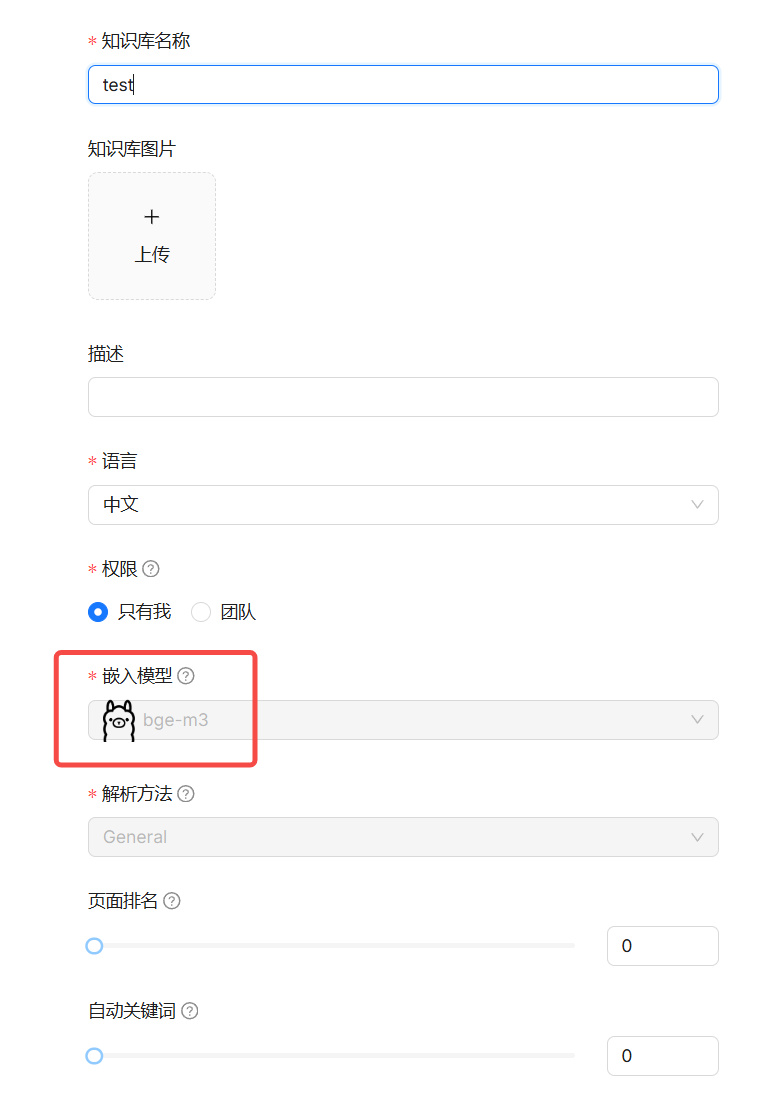
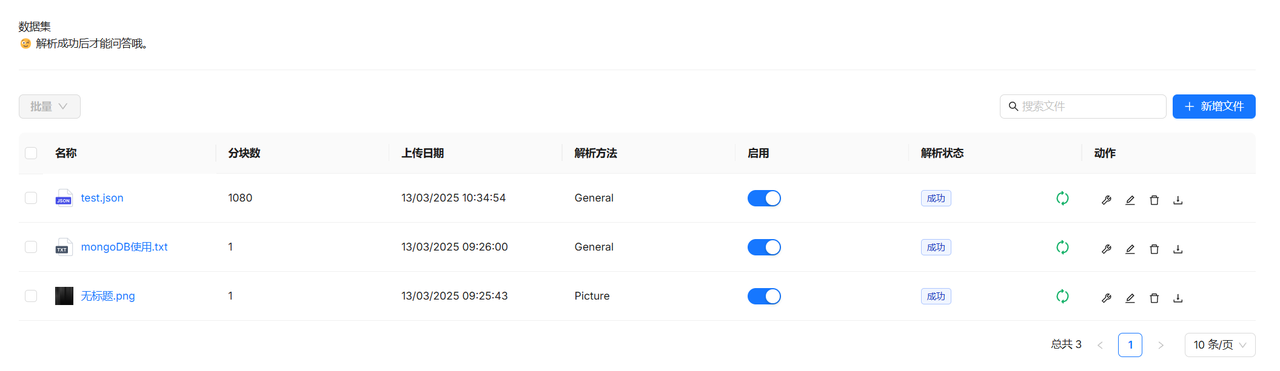
-
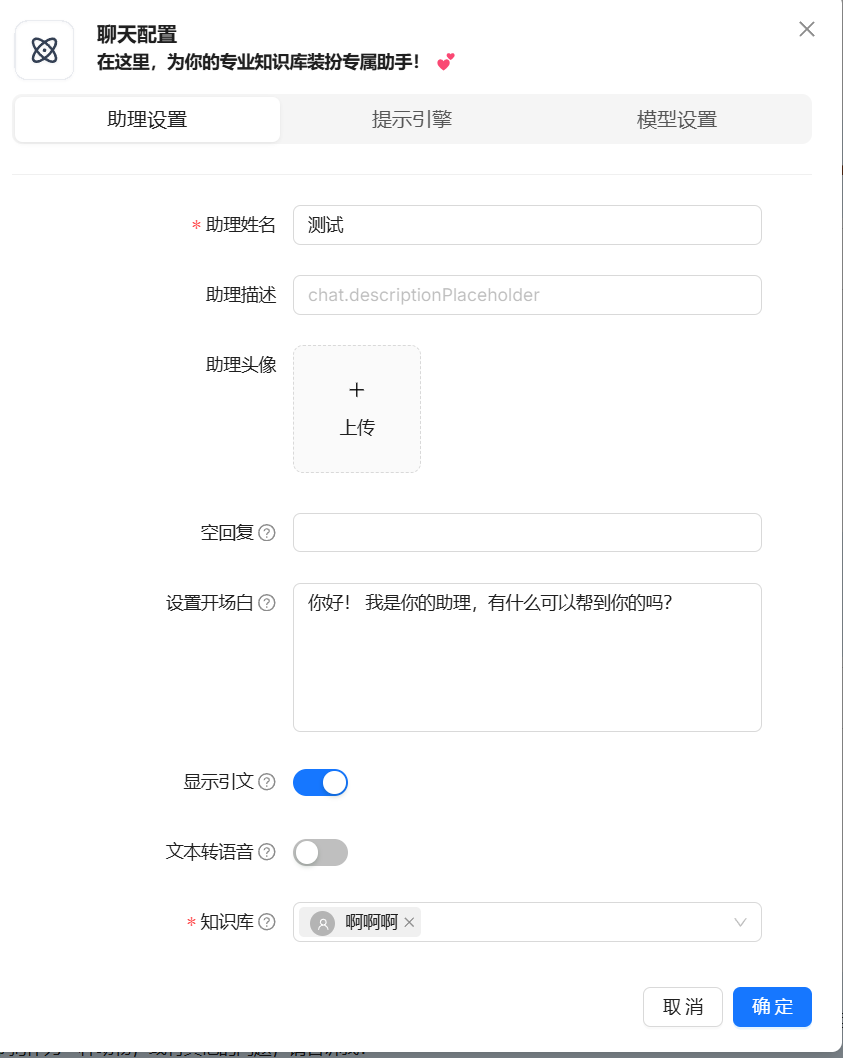
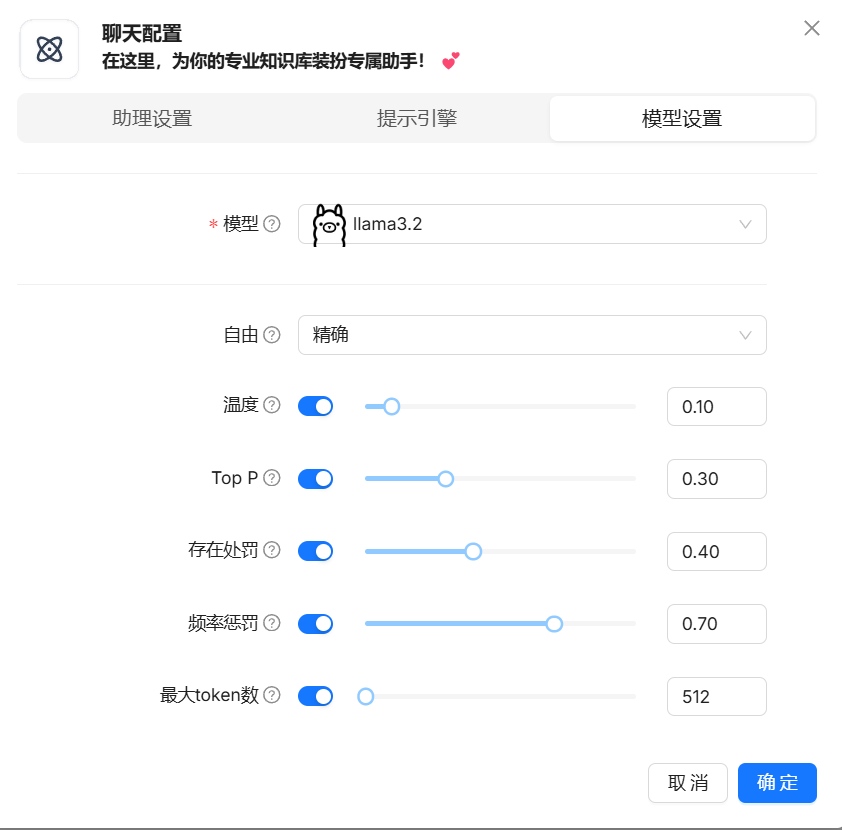
聊天:
创建助理(配置知识库和模型设置后,新建对话即可开始)