编程概念
c++高级编程过程:源文件(*.cpp)→编译→目标文件(*.obj)→链接→可执行文件(*.exe)
容其中链接的过程是为了将头文件与目标文件结合起来。
c++输入输出流
头文件:iostream(必须包含)
输入流:将设备输入的内容插到程序到中 ,接收外部信息。用cin的代码进行插入,而》为提取
输出流:将程序的内容显示到设备中,发送信息到外部。用 cout的代码进输出,而《为插入。常常用于发送表达式的结果,因此可以将表达式放入其中。
endl:常与cin和cout结合,用于换行,多个endl可以换多个行。
主函数:main,一般将代码放入主函数中进行一一执行。
内联函数
概念:将函数直接生成在调用的位置,可以节省调用的时间,但会耗费多的空间,因此是以空间换时间的方式。
语法:在函数前面加上inline
与普通函数的区别:
| 阶段 | 内联函数 | 普通函数 |
|---|---|---|
| 预处理 | 不处理 | 不处理 |
| 编译 | 可能将代码插入调用处 | 生成函数调用指令 |
| 链接 | 无额外操作 | 解析函数地址 |
| 调用 | 在调用处直接插入代码 | 跳转到函数 |
案例:
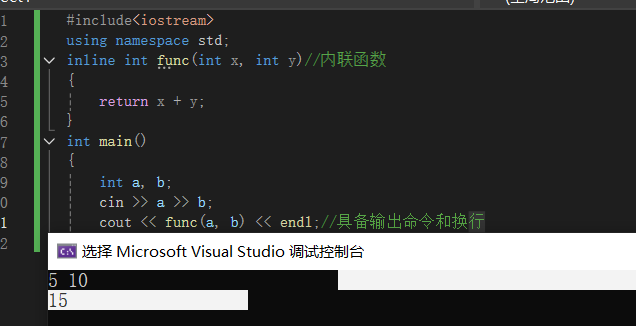
#include<iostream>
using namespace std;
inline int func(int x, int y)//内联函数
{
return x + y;
}
int main()
{
int a,b;
cin>>a>>b;
cout << func(a, b) << endl;//具备输出命令和换行
}
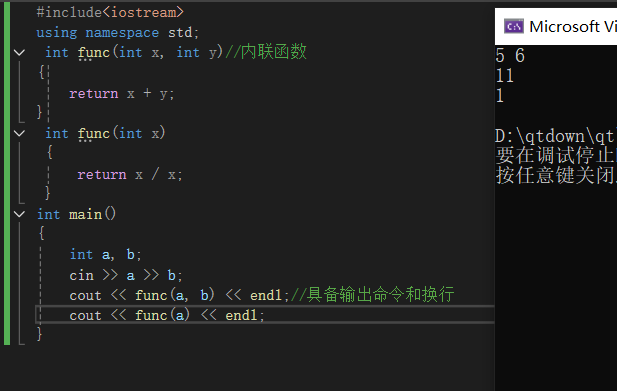
重载函数
概念:在一个项目,需要用同样的函数名表达类似的含义,就可以通过重载函数的方式。系统是根据参数来区分应该调用哪一个函数
特点:函数名相同,参数个数或者参数类型不同。但是最重要的是函数类型或返回值不同但参数相同就无法构成。
指针
前置知识
地址:在系统中为变量设置的每字节空间的编号,如果在程序中定义了一个变量或数组,那么就会随机生成地址,这个变量放入这个地址,这个变量或数组的地址就确定为一个常量。
直接访问:创建变量后,存在某个地址中,但访问时,是直接对变量本身进行访问
int a = 0;
cout << a << endl;//直接访问间接访问:将变量的地址放入指针中,通过指针对变量进行访问。
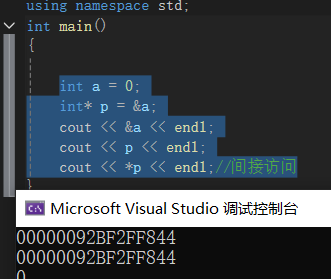
指针概念
将地址作为变量存储的对象,一个变量的地址可以称为变量的指针。
语法
类型*变量名。表示只能存放这类型变量的地址。*表示指向,&表示取地址。对地址或指针取(*)可以对地址所对应的变量进行访问。

应用
指针变量作为函数参数:可以将函数外部的变量地址传入函数内部,就可以在函数内部更改外部变量,本质上就是将变量在内存的地址传给函数 。但是如果不传地址,只普通传变量,这个函数就会创建新的地址来存放这个变量,无法对外部变量进行更改,只会获得外部变量的值。本质上就是传递的具体值。
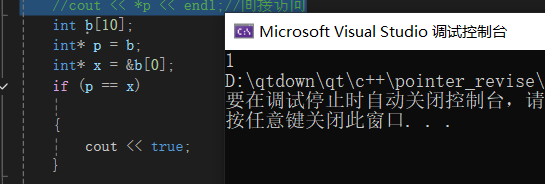
指针指向数组:本质上就是指向数组的第一个元素的地址,而对指针++,便会移动这个数组类型大小的字节。
引用
概念
对一个以及创建好的对象,取别名,它们共用一块地址。这块地址两个名字。
语法
<类型> &<引用变量名>=****<原变量名>
应用
- 对一个具体变量取别名 int& s=a
- 对一块手动开辟好的空间取别名 int& s = *new int
要点
- 引用定义时必须要引用一个创建好具体的变量
- 引用一旦定义好了,就不能更改指向的变量
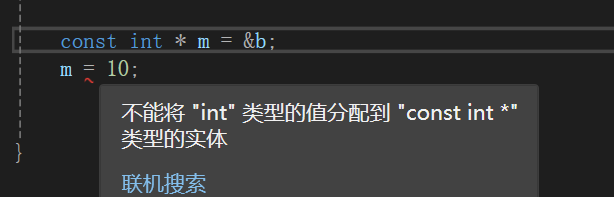
- 不能针对常量进行引用,除非这个引用加上const (const int& s = 10;)
- 不能建立引用数组
- 不能建立引用指针
- 不能建立引用的引用
指针和引用的区别
- 指针是通过地址间接访问变量的,而引用是直接访问变量
- 指针初始化可以不设置具体变量,并且可以更换指向的地址。而引用初始化必须要指定变量,并且一旦指定不能更改
函数中的引用
- 作为函数参数时,可以直接对外部实参变量操作
- 作为函数返回值时,就是对函数内部某一个返回值取别名,因此与这个返回值的地址是一样的,因此这个返回值的生命周期不能只在这个函数内部,否则会报错。 要点:作为返回值的引用,要考虑这个引用是在函数运行结束之后产生的,所有不能返回形参和自动变量。返回的变量必须为全局变量或者静态变量。返回值为引用的函数可以做左值,可以对其进行赋值和操作,本质的就是操作的是取别名的那个对象。
const类型变量
概念:对变量进行加上const修饰,表示这变量变成了常量,不能对其进行更改,只能访问。
应用:
1.禁写指针
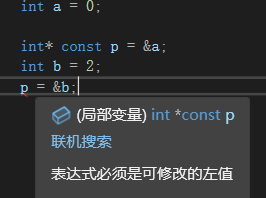
表明这个指针指向其它变量的地址
2.禁写间接引用
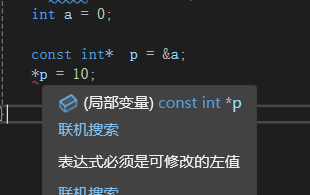
表明不能通过对指针解引用去修改a的值
面向对象
概念:是一种编程风格,将现实世界的事物和概念抽象成计算机程序的对象。主要思想是把构成问题的各个食物分解成各个对象,建立的对象的目的不是完成一个步骤,而是为了描述一个事务在解决问题中充当的角色,需要执行的行为。面向对象程序设计中的概念主要包括:对象(现实的实体)、 类(对实体的描述)、数据抽象(隐藏实体描述的细节)、继承(同类对象,但部分不同)、动态绑定(根据具体场景来表达对象的方法)、数据封装(把对象打包)、多态性(同一个操作作用于不同的对象,可能具有不同的方法)、消息传递(对象直接可以进行交互)。
程序设计语言
面向对象的语言:具备封装、继承多态的特性。执行任务时,需要一个对象去执行某一行为。公式组成:算法+数据结构=对象 程序=对象+对象+....+消息。消息用于对对象的控制,以及相关联。类是对 象的抽象,而对象是类的具体实例(instance)。
基于对象(面向过程)的语言:使用函数去执行完成任务中需要执行的某一步骤。公式组成:算法+数据结构=程序
类的实现
在面向对象的风格中,所有数据都封装在类中,完成任务,只需要通过创建类的实例或者少量新类进行通信操作,来完成任务
类的应用
类一般由属性和行为组成
属性:属于静态的。类似于一个人的外貌身高
行为:属于动态的。类似于一个人会打篮球、踢足球
面向对象创建程序的思路为:首先完成这个任务需要那些对象,而这些对象有那些的属性和行为能对完成任务有帮助。而属性就是类中的成员变量,而行为就是类中的成员函数。因此人们设想把相关的数据和操作放在一起,形成一个整体,与外界相对分隔。这就是 面向对象的程序设计中的对象。
C++类
类的定义
class 类名
{
private:
私有成员数据;
私有成员函数;
public:
公有成员数据;
公有成员函数;
protected:
保护成员函数;
保护成员数据;
};private:只能在类内部使用,在外部不能使用,如果需要使用成员数据,需要通过公有函数来实现。默认不加限定词就是私有。
public:作用域在类内部和外部,不受类的限制
protected:作用域在类内部和派生类内部,即该类和该类的派生类
其中成员函数可以在外部定义,类内部声明
语法:
<type> < class_name > :: < func_name > (<参数表>)
{
...... //函数体
}如果函数在类内部定义就相当于内联函数,如果在外部定义时加上inline也是内联函数。并且函数的参数可以设置为缺省,不够缺省的参数要从右往左进行放置
类成员的访问和使用
私有和保护成员:在类内部可以直接使用,但在外部需要通过公有函数的结合来获取或者是更改。
公有成员:普通类的实例化可以通过.来获取,指针型的实例化通过->来获取
类作用域、类类型的作用域和对象的作用域
类的成员函数和成员数据,在类内部可以直接调用,出了类,在外部调用需根据成员的特性以及结合类的实例化进行调用,不能单独调用
类类型的作用域根据所定义的位置,在函数内部,表明作用域只能在函数内部使用,而在函数外部定义就可以全局使用
类的对象作用域就是与普通对象一样的作用域,根据位置所在来判断作用域。
类的嵌套
概念:就是在类内部再定义一个类做为成员。
语法:
class 类名1{
class 类名2
{};
};实例:
class student {
public:
class appearance {
public:
int height;
int weight;
};
private:
};
int main()
{
student s;
student::appearance b;
b.height = 10;
b.weight = 10;
cout << b.height << b.weight << endl;
}对象引用私有数据成员
-
通过公有函数的的方式进行访问和赋值
-
通过构造函数的方式进行赋值
-
利用传指针的方式获取私有数据成员
-
利用引用的方式获取私有数据成员
class student {
public:
student(int x, int y)
{
this->x = x;
this->y = y;
}
void setxy(int a, int b)
{
x = a;
y = b;
}
void setxy(int* a, int* b)
{
*a = x;
*b = y;
}
void setxy(int& a, int& b)
{
a = x;
b = y;
}
int getx()
{
return x;
}
int gety()
{
return y;
}
private:
int x;
int y;
};
成员函数重载
概念:通过类中同名不同参数类型或个数的方式实现函数重载。
class student {
public:
student(int x, int y)
{
this->x = x;
this->y = y;
}
void setxy(int a)//函数重载
{
x = a;
y = a;
}
void setxy(int* a, int* b)
{
*a = x;
*b = y;
}
void setxy(int& a, int& b)
{
a = x;
b = y;
}
int getx()
{
return x;
}
int gety()
{
return y;
}
private:
int x;
int y;
};this指针
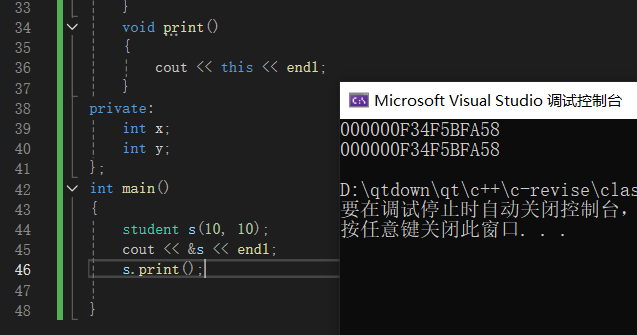
概念:在类实例化后,对成员函数进行调用时,会自动生成一个this指针,这个this指针与类的实例化对象的地址时相同的。在类内部定义时,this指针会被隐藏,但也可以显式调用。
静态成员
概念:
类的静态数据是静态分配存储空间的,而其它成员则是动态分配空间。动态分配空间是在代码运行到类实例化后,而静态分配空间就是在编译时。静态数据成员必须文件作用域进行定义说明,默认初始值为0,静态成员不使用不分配空间。
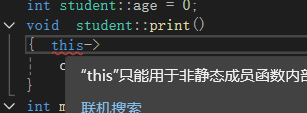
静态成员函数
概念:在类中对函数添加static就表明这个函数时静态成员函数,它将不会包含this指针,并且在public中的成员函数可以通过不对类实例化就可以使用成员函数。使用的语法为:类名::函数名
静态成员数据变量
概念:在类声明一个静态成员变量,就表明所有类的实例化对象共用一个内存来存储这个变量,因此每个实例化对象都会影响这个变量,并且其它实例化对象会受到这影响。并且,这个静态成员变量可以在类外初始化或者是在构造函数中初始化。
class student {
public:
student(int x, int y)
{
this->x = x;
this->y = y;
age = 10;
}
void setxy(int a)//函数重载
{
x = a;
y = a;
}
void setxy(int* a, int* b)
{
*a = x;
*b = y;
}
void setxy(int& a, int& b)
{
a = x;
b = y;
}
int getx()
{
return x;
}
int gety()
{
return y;
}
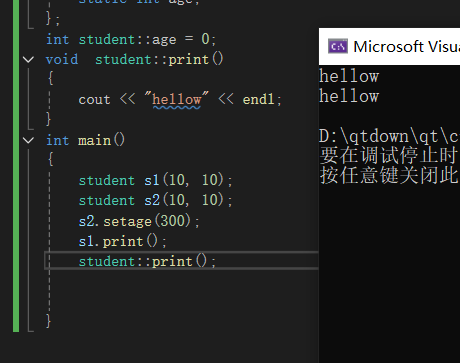
static void print()
{
cout << "hellow" << endl;
}
void setage(int a)
{
age = a;
}
void printage()
{
cout << age << endl;
}
private:
int x;
int y;
static int age;
};
int student::age = 0;
int main()
{
student s1(10, 10);
s1.printage();
}
age此时为10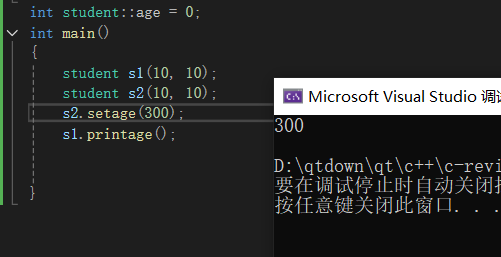
要点:
- 静态成员函数在类外部使用需要加上类名::,就可以直接使用
- 静态成员函只能直接使用本类的静态数据和静态成员函数,不能调用非静态成员,原因是静态成员函数不包含this指针
- 静态成员函数在类外定义时,不能加static,原因是static不是数据类型的组成部分
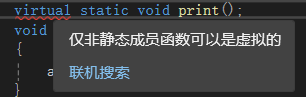
- 静态成员函数不能实现多态性,因此不能作为虚函数。
构造函数
概念:在对类实例化生成对象时,会自动调用构造函数。因此构造函数必须为公有的,如果类定义只用于派生类,可以将构造函数设置为保护成员函数,每个对象都必须调用构造函数。
语法:与类名相同,可带参数和不带参数,并且没有返回值,一个类可以有多个构造函数但需要满足函数重载的原则,并且可以对参数设置缺省值。
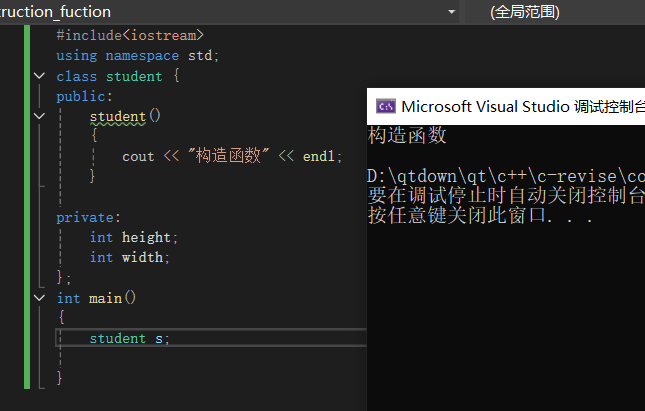
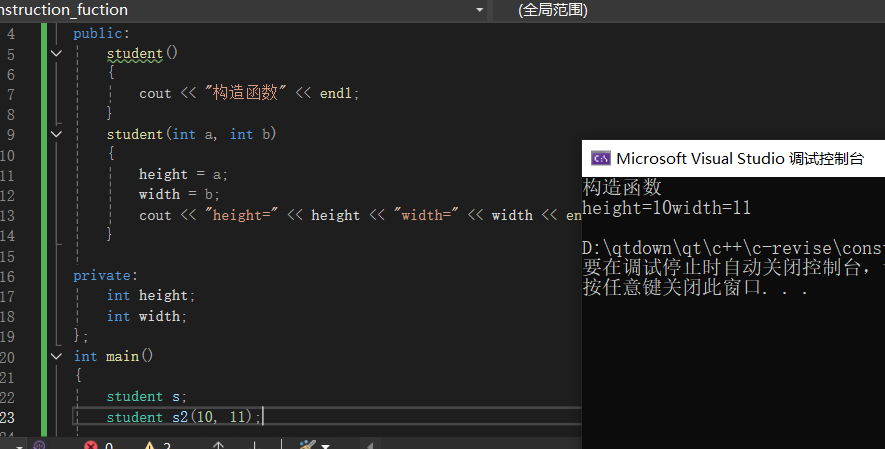
默认构造函数:当没有显式设置构造函数时,系统会自动分配一个构造函数。它不会对数据成员赋值,因此数据成员的值时不确定的。
调用构造函数的场景:当它时局部对象时,每次调用都会生成一个构造函数。当时全局对象时,程序只会在遇到它后调用一次构造函数,并且直到程序结束。当时静态对象的时候,首次定义对象,需要构造函数并且需要程序执行到这个静态对象的构造位置。

#include<iostream>
using namespace std;
class student {
public:
student(string name)
{
this->name = name;
cout << "构造函数" << "名字:"<<this->name<<endl;
}
private:
int height;
int width;
string name;
};
void func()
{
student s(string("局部对象"));
static student s3("静态对象");
}
student s2(string("全局对象"));
int main()
{
int n = 3;
while (n--)
{
func();
}
}构造函数与new运算符
可以使用new运算符来动态地建立对象,而new的对象需要手动释放,建立时要自动调用构造函数,以便完成初始化对象的数据成员。最后返回这个动态对象的起始地址。用new运算符产生的动态对象,在不再使用这种对象时,必须用****delete运算符来释放对象所占用的存储空间。 用new建立类的对象时,可以使用参数初始化动态空间。 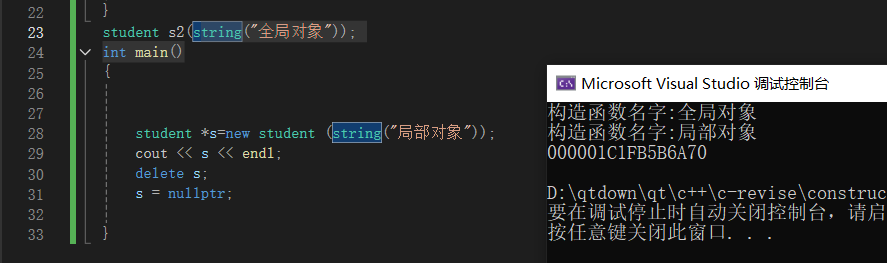
析构函数
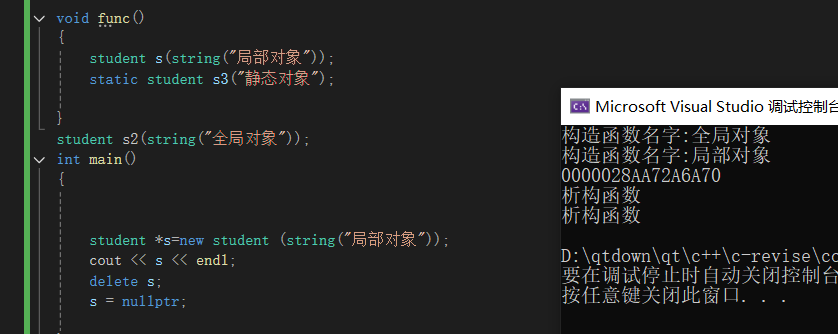
概念:类构造的实例对象在出生命周期就会自动调用析构函数,便于对对象内部开辟的地址进行销毁,避免内存泄漏,当类对象有手动开辟的空间,需要在析构函数中对这个空间进行释放。
语法:~加函数名,需要设置为公有函数,不能带参数和返回值,以及不直到函数类型,不允许重载。
默认析构函数:当没有显式定义析构函数时,系统会自动生成析构函数。系统就会自动收回为对象所分配的存储空间,但是不能自动收回new开辟的空间,因此需要显式定义析构函数。
#include<iostream>
using namespace std;
class student {
public:
student(string name)
{
this->name = name;
s = new int;
cout << "构造函数" << "名字:"<<this->name<<endl;
}
~student()
{
delete s;
cout << "析构函数" << endl;
}
private:
int height;
int width;
string name;
int* s;
};
void func()
{
student s(string("局部对象"));
static student s3("静态对象");
}
student s2(string("全局对象"));
int main()
{
student *s=new student (string("局部对象"));
cout << s << endl;
delete s;
s = nullptr;
}
拷贝构造
概念:当两个对象属于同一个类,当一个对象需要实例化,并且与另一个已经实例化的对象的数据成员一样的值,便可以通过拷贝构造,省去对数据成员赋值的步骤,提高效率。如果在类中没有定义拷贝构造函数,编译器会自行定义一个。如果类带有指针变量,并有动态内存分配,则它必须有一个拷贝构造函数。
语法:classname (const classname &obj) { // 构造函数的主体}
#include<iostream>
using namespace std;
class student {
public:
student(string name,int a,int b)
{
this->name = name;
s = new int;
height = a;
width = b;
cout << "构造函数" << "名字:"<<this->name<<" height: "<<height<<" width: "<<width << endl;
}
~student()
{
delete s;
cout << "析构函数" << endl;
}
student(student& obj)
{
height = obj.height;
width = obj.width;
s = new int;
*s = *(obj.s);
cout << "拷贝构造函数" << "名字:" << this->name << " height: " << height << " width: " << width << endl;
}
private:
int height;
int width;
string name;
int* s;
};
//void func()
//{
// student s(string("局部对象"));
// static student s3("静态对象");
//
//}
//student s2(string("全局对象"));
int main()
{
//student *s=new student (string("局部对象"));
student s("局部对象1", 1, 2);
student s2(s);
}
默认拷贝构造:可以不用显式写出拷贝构造函数,只适用于类成员没有携带指针变量并动态内存分配,因为防止浅拷贝(两个指针指向同一块区域)
class teacher {
public:
teacher(int a, int b)
{
height = a;
width = b;
cout << "构造函数" << " height: " << height << " width: " << width << endl;
}
public:
int height;
int width;
};
int main()
{
teacher t1(10, 20);
teacher t2(t1);
cout <<"t2:" << " height: " << t2.height << " width: " << t2.width << endl;
}
友元函数
概念:友元函数可以方法类里面的所有数据成员和函数成员,不受限定符限制。它不属于成员函数,但是可以访问类中的私有成员。类具有封装性和信息隐藏的特性,只要类成员和友元函数可以访问,友元可以提高程序效率,但友元会破坏这些特性。
语法:在类中声明加上friend和函数名
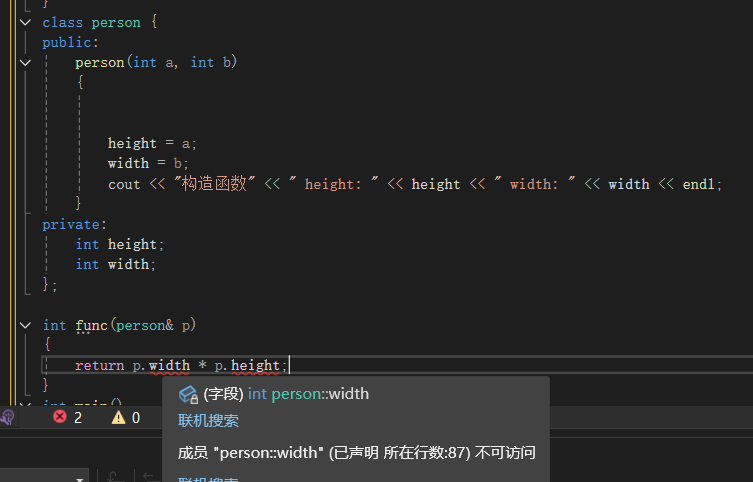
class person {
friend int func(person& p);//友元声明
public:
person(int a, int b)
{
height = a;
width = b;
cout << "构造函数" << " height: " << height << " width: " << width << endl;
}
private:
int height;
int width;
};
int func(person& p)//函数定义
{
return p.width * p.height;
}
int main()
{
person p(10, 20);
cout << func(p) << endl;
}
要点:
- 友元函数不是类的成员函数
- 友元函数没有this指针,它只是一个普通类,一般需要将类对象作为参数来访问私有成员。
- 友元关系不能继承
友元函数与一般函数的区别
- 友元函数可以定义在类中或者类外,普通函数只能定义在类外
- 友元函数可以访问类的所有成员,普通函数只能访问公有成员
友元类
概念:一个类作为另一个类的友元,意味着这个类可以访问另一个类的所有成员。
语法:在类中声明friend class 类名(友元类的类名)
class person {
friend int func(person& p);
friend class child;
public:
person(int a, int b)
{
height = a;
width = b;
cout << "构造函数" << " height: " << height << " width: " << width << endl;
}
private:
int height;
int width;
};
class child {
public:
int getheigtandwidth(person& p)
{
return p.height * p.width;
}
};
int func(person& p)
{
return p.width * p.height;
}
int main()
{
person p(10, 20);
child c;
cout << func(p) << endl;
cout << c.getheigtandwidth(p) << endl;
}
要点:
- 友元关系不能继承
- 友元关系是单向的,比如b是a的友元,b能够使用a的所有成员,a不能使用b的所有成员
- 友元关系不具有传递性,比如b是a的友元,a是c的友元,b不是c的友元。
动态内存分配
概念:在定义变量或数组时,可以手动为其分配内存,一般用于在程序开始之后根据需要开指定大小的空间,以避免直接在栈上创建对象,消耗多余的内存。也用于需要非常长的生命周期或很大内存空间的场景。
语法:内存分配(malloc/new) 销毁内存(free/delete)
要点:
- 内存泄漏问题,开空间后必须要销毁,如果不销毁,这快空间只要重新开机才能使用
- 野指针的问题,为对指向销毁内存的指针进行指向空,防止对空的地址使用。
- 重复释放问题,因为害怕后面要使用销毁的那块地址,所有要对指针悬空。
c++中new和delete的用法
#include<iostream>
using namespace std;
int main()
{
int* p1 = new int(10);//分配一个int类型对象,不初始化
int* p2 = new int[10];//分配十个int的数组
delete p1;//销毁一个int类型对象
delete[]p2;//销毁一个int数组
}运算符重载
概念:在c++类中,可以针对类进行使用运算符,而且还可以对运算符进行重载,一个运算符可以表达多个含义,目的是为了解决类内部需要开空间的问题和返回值的问题。
语法:返回类型 operator运算符(参数列表) { // 实现 }
#include<iostream>
using namespace std;
class student {
public:
student(int a, int b)
{
age = a;
height = b;
}
student operator+(const student& other)//算数运算符重载
{
return student(this->age + other.age, this->height + other.height);
}
bool operator==(const student& other)//关系运算符重载
{
return this->age == other.age && this->height == other.height;
}
student operator=(const student& other)//赋值运算符重载
{
if (this != &other) { // 防止自赋值
this->age = other.age;
this->height = other.height;
}
return *this; // 返回当前对象的引用
}
friend ostream& operator<<(ostream& os, const student& s)
{
os << "Age: " << s.age << ", Height: " << s.height;
return os;
}
student& operator++()//前置++
{
this->age++;
this->height++;
return *this;
}
student operator++(int)//后置++
{
student p(this->age, this->height);
this->age++;
this->height++;
return p;
}
private:
int age;
int height;
};
int main() {
student s1(20, 170);
student s2(22, 175);
// 算术运算
student s3 = s1 + s2;
cout << s3 << endl; // 输出: Age: 42, Height: 345
// 关系运算
cout << (s1 == s2) << endl; // 输出: 0 (false)
// 赋值运算
student s4(0,0);
s4 = s1;
cout << s4 << endl; // 输出: Age: 20, Height: 170
// 递增运算
++s1;
cout << s1 << endl; // 输出: Age: 21, Height: 171
s2++;
cout << s2 << endl; // 输出: Age: 23, Height: 176
return 0;
}继承
概念:继承性是面向对象的一种机制,目的是在原有的基础上进行扩展和完善,从而节省重新程序开发的时间,并且节省资源。
单继承
概念:就是在原有的类上,添加一些新的内容再建立一个类,并且可以使用原有类的成员。其中原来的类被称为基类(父类),继承基类的类被称为派生类(子类)。并且只继承一个类。
此时父类的属性会被子类继承,子类可以使用父类的公有成员和保护成员,并且会生成父类。
派生类的作用:
- 可以使用基类的成员数据和成员函数
- 可以增加新的成员
- 可以重新定义已有的成员函数
- 可以改变现有的成员属性
派生方式:
1.公有派生方式:
子类可以访问派生类的私有成员和公有成员,但不能访问私有成员,其中公有成员始终保持公有成员的性质(可以在类外面调用),保护对象也保留保护的性质。
2.保护派生方式:
子类可以访问派生类的私有成员和公有成员,但不能访问私有成员,其中公有成员和保护成员都变为保留保护性质。
#include<iostream>
using namespace std;
class call {
public:
call()
{
}
call(int Age)
{
age = Age;
cout << "动物叫" << endl;
}
public:
int age;//父类成员
protected:
string name;
};
class dogcall : protected call
{
public:
dogcall()
{
}
dogcall(int a,int b):call(a){
height = 10;
name = "dog";
cout << "狗叫" << endl;
}
public:
int height;
};
class D :public dogcall
{
public:
D()
{ age=10;
name = 10;
cout << "D()" << endl;
}
};
int main()
{
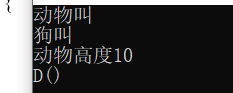
dogcall d(2,10);
cout << "动物高度" << d.height << endl;
D s;
}
2.私有派生方式:
子类不能访问父类的私有成员,而父类的公有和保护成员都变为子类的私有成员。
#include<iostream>
using namespace std;
class call {
public:
call()
{
}
call(int Age)
{
age = Age;
cout << "动物叫" << endl;
}
public:
int age;//父类成员
protected:
string name;
};
class dogcall : private call
{
public:
dogcall()
{
}
dogcall(int a,int b):call(a){
height = 10;
name = "dog";
cout << "狗叫" << endl;
}
public:
int height;
};
int main()
{
dogcall d(2,10);
cout << "动物高度" << d.height << endl;
}多继承
概念:一个派生类继承多个基类,这个派生类便可以根据继承类型来访问对应的基类成员。
class A {
public:
A()
{
cout << "A()" << endl;
}
~A()
{
cout << "~A()" << endl;
}
};
class B {
public:
B()
{
cout << "B()" << endl;
}
~B()
{
cout << "~B()" << endl;
}
};
class C {
public:
C()
{
cout << "C()" << endl;
}
~C()
{
cout << "~C()" << endl;
}
};
class D:public A,B,C
{
public:
D()
{
cout << "D()" << endl;
}
~D()
{
cout << "~D()" << endl;
}
private:
A a;
};
int main()
{
D d;
}
特点:创建先从基类开始,然后到成员对象,再到自身对象创建。销毁则是显式自身,再是成员,最好父类对象。基类的构造函数 子对象类的构造函数 派生类的构造函数
抽象类
概念:定义一个类,这个类的所有成员都不进行定义,而只是为了让派生类去定义属于派生类的这个成员,而且这个类的所有成员,派生类必须实现,并且这个类的构造函数或析构函数的访问权限定义为保护。表明基类只能通过派生类创建,无法在类外实例化。
#include<iostream>
using namespace std;
class call {
public:
protected:
call(int Age)
{
age = Age;
cout << "动物叫" << endl;
}
public:
int age;//父类成员
protected:
string name;
};
class dogcall : private call
{
public:
dogcall(int a,int b):call(a){
height = 10;
name = "dog";
cout << "狗叫" << endl;
}
public:
int height;
};
int main()
{
dogcall d(2,10);
cout << "动物高度" << d.height << endl;
}继承冲突问题
概念:为了解决多继承时,遇到基类们的成员名相同的情况。
class A {
public:
A()
{
cout << "A()" << endl;
}
~A()
{
cout << "~A()" << endl;
}
int x;
};
class B {
public:
B()
{
cout << "B()" << endl;
}
~B()
{
cout << "~B()" << endl;
}
int x;
};
class C {
public:
C()
{
cout << "C()" << endl;
}
~C()
{
cout << "~C()" << endl;
}
int x;
};
class D:public A,public B, public C
{
public:
D()
{
cout << "D()" << endl;
}
~D()
{
cout << "~D()" << endl;
}
private:
A a;
};
多继承访问相同名字的成员时,就不知道要访问能够基类的成员,如果是在派生类新加的同盟成员时,不加限制,优先调用派生类的成员。
只有通过这种方式进行特定使用
基类和对象成员类的区别
- 如果基类是多个,遇见基类名相同就会触发冲突。
- 而在类中创建类成员来访问相同名的成员就不会触发冲突
赋值兼容性
概念:子类对象可以直接赋值给基类对象,但是基类对象不能直接赋值给子类对象。
class C {
public:
C()
{
cout << "C()" << endl;
}
~C()
{
cout << "~C()" << endl;
}
int x;
};
class D : public virtual C
{
public:
D(int a,int b)
{
y = a;
x = b;
cout << "D()" << endl;
}
~D()
{
cout << "~D()" << endl;
}
private:
int y;
};
int main()
{
D d(10,20);
C c;
c = d;
cout << c.x << endl;
}此时c.x的结果为20。
派生类对象的地址赋给基类的指针变量
作用:通过一个统一接口,来操作不同的派生类对象,从而实现"一个接口,多种方法"
- 结合虚函数构成多态,通过结合虚函数 。当基类中的函数被声明为
virtual时,通过基类指针调用该函数,程序会在运行时根据指针实际指向的对象的类型(而不是指针本身的类型)来决定调用哪个版本的函数。 - 实现统一的接口和代码复用
- 可以用同一个容器存放不同类型的对象
派生类对象可以初始基类的引用
作用:与地址赋指针的功能一样。
不同之处:
| 特性 | 基类指针 | 基类引用 |
|---|---|---|
| 语法 | Base* ptr = &derived; |
Base& ref = derived; |
| 可为空 | 可以设置为 nullptr |
必须绑定到有效对象 |
| 重新绑定 | 可以指向其他对象 | 一旦初始化就不能改变绑定 |
| 内存管理 | 需要关注所有权和释放 | 自动管理生命周期 |
| 安全性 | 需要检查空指针 | 更安全,总是指向有效对象 |
// 基类:形状
class Shape {
public:
// 虚函数
virtual void draw() const {
std::cout << "Drawing a generic shape." << std::endl;
}
// 虚析构函数至关重要(后面会讲)
virtual ~Shape() = default;
};
// 派生类:圆形
class Circle : public Shape {
public:
// 重写基类的虚函数
void draw() const override {
std::cout << "Drawing a circle." << std::endl;
}
};
// 派生类:矩形
class Rectangle : public Shape {
public:
// 重写基类的虚函数
void draw() const override {
std::cout << "Drawing a rectangle." << std::endl;
}
};
int main() {
// 创建派生类对象,但用基类指针指向它们
Shape* shape1 = new Circle();
Shape* shape2 = new Rectangle();
// 同一个接口(shape->draw()),不同的行为
shape1->draw(); // 输出:Drawing a circle.
shape2->draw(); // 输出:Drawing a rectangle.
// 甚至可以放在一个数组里统一处理
Shape* shapes[] = { shape1, shape2 };
for (int i = 0; i < 2; ++i) {
shapes[i]->draw(); // 运行时决定调用哪个draw
}
delete shape1;
delete shape2;
return 0;
}虚基类
概念:当B、C都继承统A类时,然后再有一个D类同时继承B/C类时,进行实例化,就会创建两个A类对象,就会多开辟一个空间,并且会造成多个拷贝中的数据不一致和模糊引用。而虚基类就可以只开一个A类对象,而B、C 共用一块A类对象和资源,就可以节省资源,使用A类成员时,不用指定继承类标识,因为它们都是一块资源。
class A {
public:
A()
{
cout << "A()" << endl;
}
~A()
{
cout << "~A()" << endl;
}
int x;
};
class B:public A
{
public:
B()
{
cout << "B()" << endl;
}
~B()
{
cout << "~B()" << endl;
}
};
class C :public A
{
public:
C()
{
cout << "C()" << endl;
}
~C()
{
cout << "~C()" << endl;
}
};
class D : public C ,public B
{
public:
D(int a,int b)
{
y = a;
cout << "D()" << endl;
}
~D()
{
cout << "~D()" << endl;
}
private:
int y;
};
int main()
{
D d(10,20);
} 此时会构建两个A类对象,原因C和B都继承了它,所以都要为A类开空间
此时会构建两个A类对象,原因C和B都继承了它,所以都要为A类开空间
class A {
public:
A()
{
cout << "A()" << endl;
}
~A()
{
cout << "~A()" << endl;
}
int x;
};
class B:public virtual A
{
public:
B()
{
cout << "B()" << endl;
}
~B()
{
cout << "~B()" << endl;
}
};
class C :public virtual A
{
public:
C()
{
cout << "C()" << endl;
}
~C()
{
cout << "~C()" << endl;
}
};
class D : public C ,public B
{
public:
D(int a,int b)
{
y = a;
x = b;
cout << "D()" << endl;
}
~D()
{
cout << "~D()" << endl;
}
private:
int y;
};
int main()
{
D d(10,20);
cout << d.x << endl;//不用指定类就可以访问A类成员
} 此时就少开了一个A类对象空间,并且可以直接访问A类成员
此时就少开了一个A类对象空间,并且可以直接访问A类成员
作用
- 避免重复构造
- 确保单一实例
注意事项
1.调用顺序:虚基类构造函数、非虚基类构造函数、成员对象构造函数、派生类构造函数
2.如果虚基类没有显式写默认构造函数,并且写了一个新的构造函数,此时就需要在非虚基类构造函数中显式构造虚基类对象。

class A {
public:
A(int a)
{
x = a;
}
/*A()
{
cout << "A()" << endl;
}*/
~A()
{
cout << "~A()" << endl;
}
int x;
};
class B:public virtual A
{
public:
B():A(10)
{
cout << "B()" << endl;
}
~B()
{
cout << "~B()" << endl;
}
};
class C :public virtual A
{
public:
C() :A(10)
{
cout << "C()" << endl;
}
~C()
{
cout << "~C()" << endl;
}
};
class D : public C ,public B
{
public:
D(int a,int b):A(b)
{
y = a;
cout << "D()" << endl;
}
~D()
{
cout << "~D()" << endl;
}
private:
int y;
};
int main()
{
D d(10,20);
cout << d.x << endl;//不用指定类就可以访问A类成员
}虚函数
概念:当基类的函数被声明为虚函数时,派生类中重写该函数就可以实现多态。这意味着通过基类指针或引用时就会调用派生类的该函数,将根据实际对象的类型来调用相应函数。这样就可以通过统一接口调用不同的功能。
这是为虚函数的场景
class Shape {
public:
// 虚函数
virtual void draw() const {
std::cout << "Drawing a generic shape." << std::endl;
}
// 虚析构函数至关重要(后面会讲)
virtual ~Shape() = default;
};
//
// 派生类:圆形
class Circle : public Shape {
public:
// 重写基类的虚函数
void draw() const override {
std::cout << "Drawing a circle." << std::endl;
}
};
// 派生类:矩形
class Rectangle : public Shape {
public:
// 重写基类的虚函数
void draw() const override {
std::cout << "Drawing a rectangle." << std::endl;
}
};
int main() {
// 创建派生类对象,但用基类指针指向它们
Shape* shape1 = new Circle();
Shape* shape2 = new Rectangle();
// 同一个接口(shape->draw()),不同的行为
shape1->draw(); // 输出:Drawing a circle.
shape2->draw(); // 输出:Drawing a rectangle.
// 甚至可以放在一个数组里统一处理
//Shape* shapes[] = { shape1, shape2 };
//for (int i = 0; i < 2; ++i) {
// shapes[i]->draw(); // 运行时决定调用哪个draw
//}
delete shape1;
delete shape2;
return 0;
}这是不为虚函数的场景
//基类:形状
class Shape {
public:
// 虚函数
void draw() const {
std::cout << "Drawing a generic shape." << std::endl;
}
// 虚析构函数至关重要(后面会讲)
virtual ~Shape() = default;
};
//
// 派生类:圆形
class Circle : public Shape {
public:
// 重写基类的虚函数
void draw() const {
std::cout << "Drawing a circle." << std::endl;
}
};
// 派生类:矩形
class Rectangle : public Shape {
public:
// 重写基类的虚函数
void draw() const {
std::cout << "Drawing a rectangle." << std::endl;
}
};
int main() {
// 创建派生类对象,但用基类指针指向它们
Shape* shape1 = new Circle();
Shape* shape2 = new Rectangle();
// 同一个接口(shape->draw()),不同的行为
shape1->draw(); // 输出:"Drawing a generic shape."
shape2->draw(); // 输出:"Drawing a generic shape."
delete shape1;
delete shape2;
return 0;
}| 特性 | 虚函数重写 (Virtual Override) | 非虚函数"重写" (实际是隐藏) |
|---|---|---|
| 多态性 | 支持运行时多态 | 不支持多态 |
| 函数绑定 | 动态绑定(运行时) | 静态绑定(编译时) |
| 调用决定 | 由对象实际类型决定 | 由指针/引用类型决定 |
| 关键字 | 需要 virtual 和 override |
不需要特殊关键字 |
| 设计意图 | 明确设计为可扩展的接口 | 意外行为,通常应该避免 |
为什么要添加虚析构函数
核心原因:
-
多态安全:确保通过基类指针删除派生类对象时,派生类的析构函数被调用
-
资源管理:避免内存泄漏、资源泄漏
-
符合RAII:确保所有资源在对象生命周期结束时正确释放
虚函数的关键字
override关键字
概念:只有是虚函数,才能添加这个关键字,否者会报错
final关键字
概念:表明这个函数禁止被继承类重写
抽象类
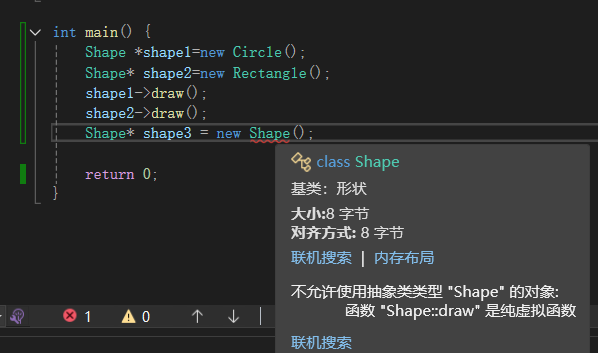
概念:一个类的成员没有具体实现,需要通过虚函数和继承的方式由派生类定义。而抽象类就是指带有纯虚函数的类。
语法:virtual 函数类型 函数名**(参数表)****=**0;
当为纯虚函数就无法构成对象,只能作为基类构成多态
class Shape {
public:
// 虚函数
virtual void draw() const = 0;
virtual ~Shape() = default;
};
//
// 派生类:圆形
class Circle : public Shape {
public:
// 重写基类的虚函数
void draw() const {
std::cout << "Drawing a circle." << std::endl;
}
};
// 派生类:矩形
class Rectangle : public Shape {
public:
// 重写基类的虚函数
void draw() const {
std::cout << "Drawing a rectangle." << std::endl;
}
};
int main() {
Shape *shape1=new Circle();
Shape* shape2=new Rectangle();
shape1->draw();
shape2->draw();
return 0;
}
命名空间
概念:命名空间是一个强大的工具,它不仅仅是让你"偷懒"不用写前缀。它的本质是工程化管理代码,划分逻辑边界,防止命名污染。
using namesapce:解决不用在函数前加命名空间名
自定义命名空间:namespace 名称{内容}
命名空间的作用
解决名称冲突,避免函数、类、变量等标识符的名称冲突
// 第三方网络库提供的功能
void connect() {
std::cout << "Connecting to network...\n";
}
// 你自己的数据库功能
void connect() { // 错误!重定义 'void connect()'
std::cout << "Connecting to database...\n";
}
int main() {
connect(); // 编译器不知道该调用哪个
return 0;
}这是没有使用命名空间调用方法,就无确定是哪一个,就会起冲突。
 这个就体现了命名空间的优势
这个就体现了命名空间的优势
命名空间的使用方式
- 通过命名空间名称+::+对象名进行调用空间中指定对象
- 在文件中使用using namespace 命名空间名,这样就可以实现本地化,不用命名空间名就可以调用空间内部的对象
- using 命名空间名+::+空间内部的对象,表明这个作用域下就在使用这个对象就不用显式的写出命名空间名。
名字空间的嵌套:一个命名空间内部定义另一个命名空间。使用方式:using 外部命名空间名::内部空间名
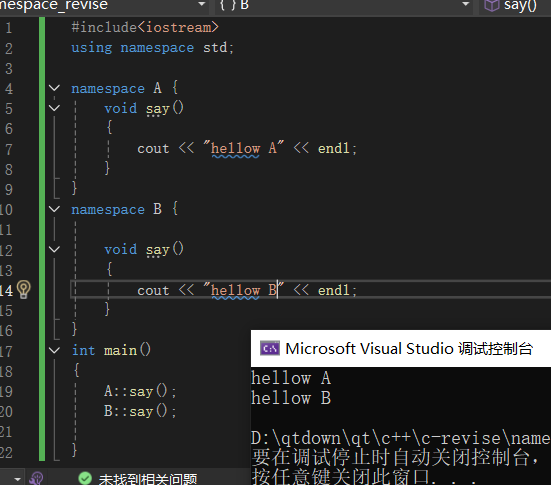
#include<iostream>
using namespace std;
namespace A {
void say()
{
cout << "hellow A" << endl;
}
namespace C{
void say()
{
cout << "hellow C" << endl;
}
}
}
namespace B {
void say()
{
cout << "hellow B" << endl;
}
}
int main()
{
A::C::say();//命名空间嵌套
}命名空间取别名:给命名空间的名字在当前作用域设置一个简单的名字
namespace newA = A;
int main()
{
newA::C::say();//命名空间嵌套
}模板
概念:模板式泛型编程的基础,泛型编程以一种独立于任何特定类型的方式编写代码。
函数模板
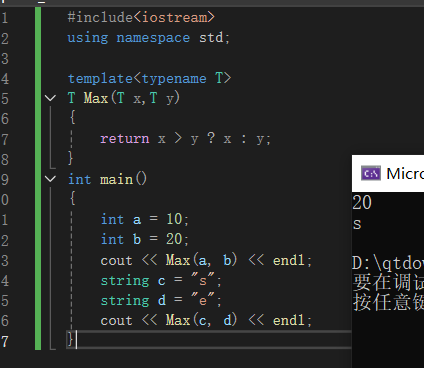
语法:template<typename 类型> 函数实现
调用函数模板:直接传数,不考虑类型,因为函数模板会根据传的参数自适应类型
#include<iostream>
using namespace std;
template<typename T>
T Max(T x,T y)
{
return x > y ? x : y;
}
int main()
{
int a = 10;
int b = 20;
cout << Max(a, b) << endl;
string c = "s";
string d = "e";
cout << Max(c, d) << endl;
}
类模板
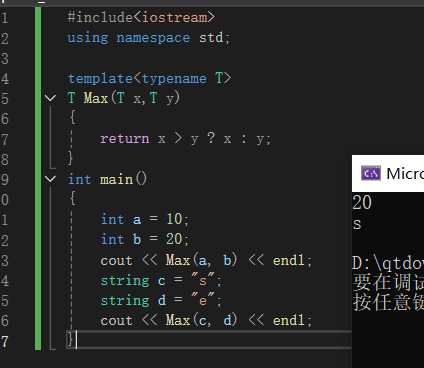
概念:template<typename 类型> class class-name{}
用类模板定义对象,T会被参数的类型替换 类名<参数类型> 对象名
template <typename T>
class student {
public:
student(T x, T y)
{
height = x;
width = y;
}
T sum()
{
return height + width;
}
private:
T height;
T width;
};
int main()
{
student<int> s(180, 120);
cout << s.sum() << endl;
}
IO流类库
概念:IO库的成员可以实现对外设的访问,与交互。编译系统已经通过运算符或函数的形式做好了标准外设(键盘、屏幕、打印机、文件)的接口,使用时只需要调用相关接口即可。
标准输入输出流
概念:c++语言的I/O系统为用户提供了一个统一接口,使得程序设计尽量与所访问的具体设备无关,在用户与设备直接提供了一个抽象的界面。
头文件:iostream

输入流:可以将外设的数据输入到程序中
输出流:可以将程序中的数据输出到外设中
重载输入输出运算符
重载输出
#include<iostream>
#include<fstream>
using namespace std;
class A {
public:
A(int a, int b)
{
x = a;
y = b;
}
friend ostream& operator<<(ostream& os, A&);
private:
int x;
int y;
};
ostream& operator<<(ostream& os, A&other)
{
cout << other.x << "\n" << other.y << endl;
return os;
}
int main()
{
A a(100, 200);
cout << a;
A b(300, 400);
cout << a << b;//<<重载会返回输出流,因此可以直接调用<<来输出
}重载输入,变化格式由变量格式决定的,对输出流,将数据变换字符串然后输出
#include<iostream>
#include<fstream>
using namespace std;
class A {
public:
A(int a, int b)
{
x = a;
y = b;
}
friend ostream& operator<<(ostream& os, A&);//输出到外设
friend istream& operator>>(istream& is, A& other);//输入到程序
private:
int x;
int y;
};
ostream& operator<<(ostream& os, A&other)
{
cout << other.x << "\n" << other.y << endl;
return os;
}
istream& operator>>(istream& is, A& other)
{
cin >> other.x >> other.y;
return is;
}
int main()
{
//A a(100, 200);
//cout << a;
//A b(300, 400);
//cout << a << b;//<<重载会返回输出流,因此可以直接调用<<来输出
A c(100, 200);
cin >> c;
cout << c;
}重载输出的语法:friend ostream&operator<<(ostream&,ClassName&)
重载输入的语法:friend istream&operator<<(istream&,ClassName&)
文件流类体系
将数据输出到文件和从文件输入到程序。
文件操作:文本文件、二进制文件。
文件流类
头文件<fstream>
ifstream :读取文件数据
ofstream:向文件写入
fstream:可写可读
fstream的常用成员:
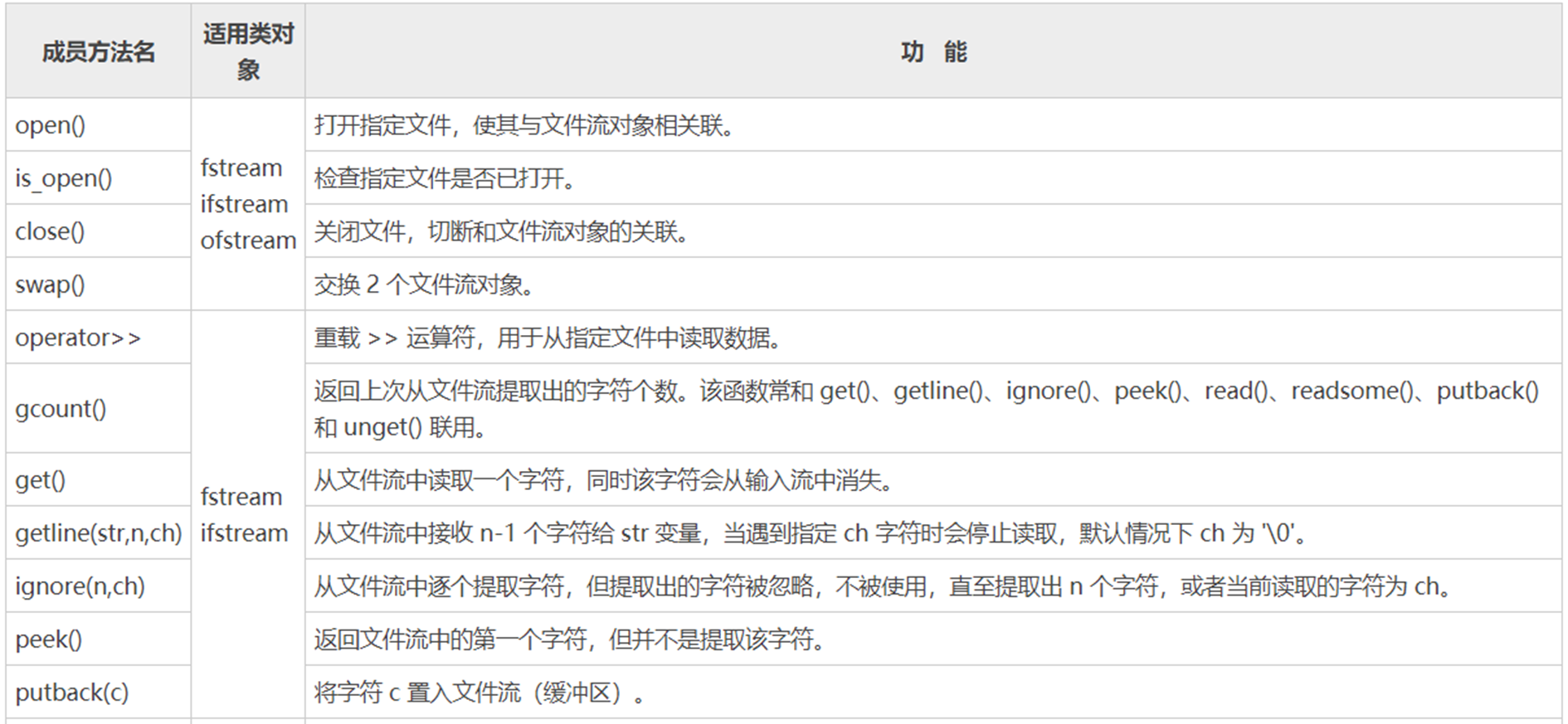
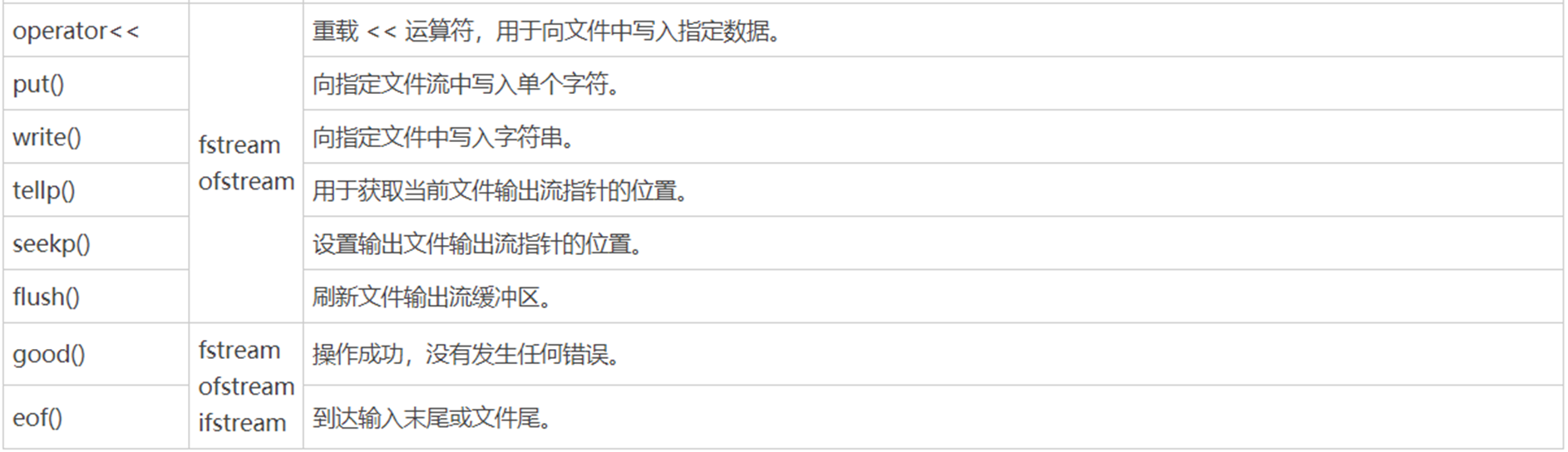
fstream 文件描述符(文件名,打开方式):文件流与文件建立关联
write(字符数组的起始位置,字符长度)
int main()
{
fstream fd("demo.txt",ios::out);//往文件中写入
if (fd.is_open())
{
cout << "文件已经打开" << endl;
}
else
{
cout << "文件打开失败" << endl;
return -1;
}
const char* buffer = "hellow world";
fd.write(buffer, strlen(buffer));//sizeof是指针长度,strlen用与字符串长度
fd.close();
}read(字符数组缓冲区,内容长度):可以从文件中读指定长度的字符到字符数组中,不会自动添加字符串结束符 \0 而cout << buffer 会一直输出直到遇到 \0
fstream fd("demo.txt", ios::in);//往文件中读取
if (fd.is_open())
{
cout << "文件已经打开" << endl;
}
else
{
cout << "文件打开失败" << endl;
return -1;
}
char buffer[13];
if (fd.read(buffer, 12))//sizeof是指针长度,strlen用与字符串长度,这个缺点是需要直到文件的字符长度,无法高效读取所有数据
{
buffer[fd.gcount()] = '\0';//gcount获取读取的字符数
cout << buffer << endl;
cout << fd.gcount() << endl;
}
fd.close();get(字符缓冲区):把文件的字符一一读取到字符缓冲区中,直到读到文件末尾(其中有一个读取指针,会往后移动)
string buffer;
fstream fd("demo.txt", ios::in);//往文件中读取
if (fd.is_open())
{
cout << "文件已经打开" << endl;
}
else
{
cout << "文件打开失败" << endl;
return -1;
}
char s;
while (fd.get(s))//循环读取文件的数据,到达末尾或遇到EOF
{
buffer += s;
}
cout << buffer.c_str() << endl;
fd.close();put成员方法:输入单个字符到文件,与cin结合,根据键盘输入来一个一个字符输入到文件中
实际上,按回车并不能直接停止输入 。要停止从键盘输入,需要使用 文件结束符(EOF):
Windows系统:
按 Ctrl + Z 然后按回车
Linux/Mac系统:
按 Ctrl + D
文件指针:当文件打开时,文件指针位于开头,并随读写字节数的多少顺序移动,可以利用seekg移动文件指针
fstream fd("demo.txt", ios::in);//往文件末尾进行添加新的数据
if (fd.is_open())
{
cout << "文件已经打开" << endl;
}
else
{
cout << "文件打开失败" << endl;
return -1;
}
string buffer;
string content;
while (getline(fd, buffer));//循环读取每行,直到读取到0个字符
{
content += buffer + '\n';
}
fd.close();
cout << content << endl;getline:属于c++的风格,按行读取内容,读取到文本末尾自动返回0。
文件打开方式标记

标记|标记:表明两个方式都可以实现
STL
概念:c++的一部分不需要额外库,
vector
序列式的容器(普通数组的升级版),属于一个动态数组(根据插入的数据开辟空间,不用提前规定数组的大小),可以对元素进行插入和删除,并且可以放各种类型的数据。
初始化方法
1.不加数据创建:
vector<int> v;2.加上数据创建
vector<int> v2{ 10,20,30 };3.直接设置元素个数:先只开辟2个元素的空间,设置初始包含几个元素,并且每个元素都默认为0
vector<int> v3(2);4.设置多个相同的数据
vector<int> v4(3, 10);5.复制,容器间赋值
vector<int>v5(v2);6.保存指定数组的数据:如果访问超出v6存放arr的值的范围会越界
int arr[] = { 10,2,13 };
vector<int>v6(arr, arr+1);7.保存vector中的指定数据
vector<int> v7(v2.begin() + 1, v2.end());begin:返回第一元素的迭代器
end:最后一个元素的后一位置的迭代器
size:返回元素个数
push_back:插入元素
insert:在指定位置插入数据(位置,数据)
at():获取对应下标的数据
\[\]:获取对应下标的数据
遍历容器的方法
vector<int> v;
v.push_back(1);
v.push_back(3);
v.push_back(5);
for (auto e : v)
{
cout << e << endl;
}
for (int i = 0; i < v.size(); i++)
{
cout << v[i] << endl;
}deque:双端队列容器
与vector:擅长在序列头部和尾部插入,时间复杂度比vector少
初始化:与vector大部分相同,
push_back:在后面插入
size
pop_front():删除队列头部的值
deque<int> d;
d.push_back(10);
d.push_front(5);
d.push_front(20);
d.push_front(15);
d.pop_back();
d.pop_front();
for (auto e : d)
{
cout << e<<" ";
}stack:堆栈
概念:堆栈是一种容器适配器,专门设计用于在后进先出环境(后进先出)中运行,其中元素仅从容器的一端插入和提取。后进先出类似于放一堆书一样,只有一一从书顶部取出书,放置也只能放在顶部。容器适配器是使用特定容器类的封装对象作为其底层容器的类,提供一组特定的成员函数来访问其元素。
要点:stack本身不是一个完整的容器,而是一个容器适配器。在大多数情况下,使用默认的stack<int>就足够了。只有当你有特定性能需求或特殊使用场景时,才需要考虑指定底层容器
考虑指定容器的情况:
-
明确知道元素数量且很大 →
vector+reserve() -
元素很大,复制成本高 →
list -
需要内存连续性 →
vector -
基准测试显示特定容器有明显优势

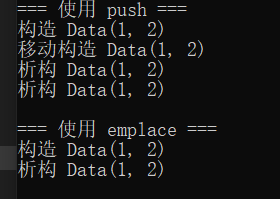
-
push:先构造临时对象,再拷贝/移动到容器 -
emplace:直接在容器中构造对象class Data {
public:
int x;
double y;// 构造函数 Data(int a, double b) : x(a), y(b) { std::cout << "构造 Data(" << x << ", " << y << ")" << std::endl; } // 拷贝构造函数 Data(const Data& other) : x(other.x), y(other.y) { std::cout << "拷贝构造 Data(" << x << ", " << y << ")" << std::endl; } // 移动构造函数 Data(Data&& other) noexcept : x(other.x), y(other.y) //剥夺other的资源,包括指针,全部给返回值,扩大生命周期,移动后原对象不再拥有资源 { std::cout << "移动构造 Data(" << x << ", " << y << ")" << std::endl; } // 析构函数 ~Data() { std::cout << "析构 Data(" << x << ", " << y << ")" << std::endl; }};
int main() {
std::cout << "=== 使用 push ===" << std::endl;
{
std::stack s1;
s1.push(Data(1, 2.0)); // 先构造临时对象,再移动(如果支持)到栈中
}std::cout << "\n=== 使用 emplace ===" << std::endl; { std::stack<Data> s2; s2.emplace(1, 2.0); // 直接在栈内存中构造对象 } return 0;}
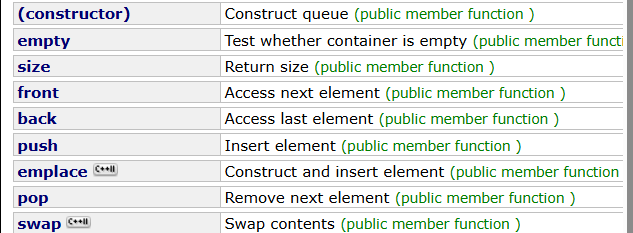
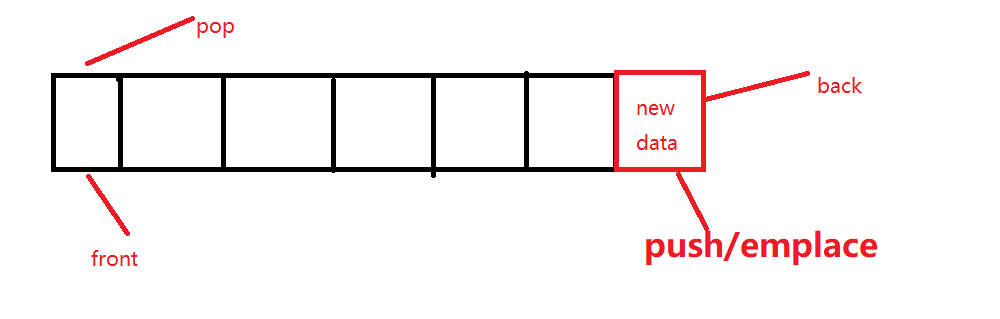
queue 双端队列
概念:队列是一种容器适配器,专门设计用于在 FIFO 上下文(先进先出)中运行,其中元素插入容器的一端并从另一端提取。
back():访问最后一个元素
push:在后面插入
pop:删除第一个元素
front:访问第一个元素
size:访问长度
emplace:末尾添加
swap:两个queue的内容交换
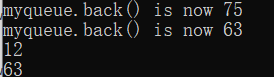
#include <iostream> // std::cout
#include <queue> // std::queue
int main()
{
std::queue<int> myqueue;
myqueue.push(12);
myqueue.push(75); // this is now the back
//myqueue.back() -= myqueue.front();
std::cout << "myqueue.back() is now " << myqueue.back() << '\n';//75
myqueue.back() -= myqueue.front();
std::cout << "myqueue.back() is now " << myqueue.back() << '\n';//63
while (!myqueue.empty())
{
std::cout << myqueue.front() << std::endl;
myqueue.pop();
}
return 0;
}
set/map
概念:map具有两个值,一个为键,一个为值,每个键对应一个值,元素是无序的。set具有一个值,元素是有序的。unordered_map和unordered_set是上面两个的另一种形式,它们是无序的,仅仅为了快速的查找。
组成:
键(key):唯一标识符,用于快速排序和查找
值(value):于键相关联的数据。
特性:
键是唯一的情况(map),重复的情况(multimap)。
键不可修改(若需要修改需要先删除再插入新的键值对)
值可以随意修改。
底层实现:
pair和make_pair是用于对创建和操作键值对的核心工具。
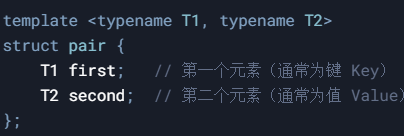
pair是std的模板类,用于将两个值(键和值)组合称为一个对象。

make_pair是一个模板函数,用于自动推导类型并生成pair对象,避免显示指定模板参数
函数原型:

自动类型推导:

插入容器(make_pair和pair的区别):


map
存储键值对(key-value pairs)
#include<iostream>
#include<map>
using namespace std;
int main()
{
map<string, int> m;//默认按键排序
m.insert(make_pair("apple", 8));//insert要带类型才能插入,除非用make_pair
m.insert(make_pair("banana", 2));
m.insert(pair<string, int>("cherr", 7));
for (auto it = m.begin(); it != m.end(); it++)//正向迭代器
{
cout << it->first << ":" << it->second << endl;
}
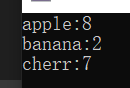
}
int main()
{
map<string, int,greater<string>> m;//按降序排序
m.insert(make_pair("apple", 8));//insert要带类型才能插入,除非用make_pair
m.insert(make_pair("banana", 2));
m.insert(pair<string, int>("cherr", 7));
for (auto it = m.begin(); it != m.end(); it++)//正向迭代器
{
cout << it->first << ":" << it->second << endl;
}
cout << "反向迭代器:" << endl;
for (auto it = m.rbegin(); it != m.rend(); it++)//反向迭代器
{
cout << it->first << ":" << it->second << endl;
}
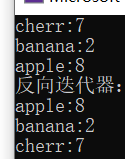
}
m.erase("apple");//根据键做出删除操作
for (auto it = m.begin(); it != m.end(); it++)//正向迭代器
{
cout << it->first << ":" << it->second << endl;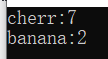
for (auto it = m.begin(); it != m.end(); it++)//正向迭代器
{
cout << m[it->first]<< endl;//根据键访问值
}
set
特性:只存储键(key),不存储值(value),自动去重功能,自动排序。
#include<iostream>
#include<set>
using namespace std;
int main()
{
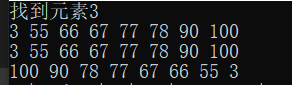
set<int> s{ 67,78,3,90,55,55,66,77,77 };//自动去重
s.insert(100);//插入元素
s.erase(1);//删除元素
//查找元素
auto it = s.find(3);//返回这个数的迭代器
if (it != s.end())
{
cout << "找到元素" <<*it<< endl;
}
// 方法1:范围for循环
for (const auto& e : s) {
std::cout << e << " ";
}
std::cout << std::endl;
// 方法2:迭代器
for (auto it = s.begin(); it != s.end(); ++it) {
std::cout << *it << " ";
}
std::cout << std::endl;
// 方法3:反向迭代器
for (auto rit = s.rbegin(); rit != s.rend(); ++rit) {
std::cout << *rit << " "; // 逆序输出
}
}
c++11的unordered_set/unordered_map
unordered_set:不会进行排序,而是按插入的顺序进行排列,因此时间复杂度会更少。
unordered_map:底层采用hash表结构,具备快速检索的功能,没有顺序,键值唯一,动态管理空间。
异常处理
程序中常见的错误有两大类:语法错误和运行错误。在编译时,编译系统能发现程序中的语法错误
常见的编译错误:
- 语法错误
- 类型错误
- 声明错误
- 链接错误
运行时错误:
- 内存访问错误:空指针引用、野指针、越界、使用已经释放的内存
- 资源管理错误:内存泄漏
- 逻辑错误:死循环、除零
- 异常:自定义的错误、动态分配失败
区别:
| 方面 | 编译错误 | 运行时错误 |
|---|---|---|
| 检测时间 | 编译时 | 运行时 |
| 错误示例 | 语法错误、类型错误、链接错误 | 内存访问错误、逻辑错误、资源错误 |
| 调试工具 | 编译器错误信息 | 调试器、Valgrind、ASan |
| 预防方法 | 代码审查、静态分析 | 测试、断言、异常处理 |
| 影响范围 | 整个程序无法运行 | 程序可能部分运行或崩溃 |
| 修复难度 | 通常较容易定位 | 可能难以重现和定位 |
概念:异常处理是运行程序遇到运行时错误时,将控制权从发生错误的部分转移到专门处理错误代码的部分。
throw:当问题出现,程序抛出异常
catch:捕捉异常
try:放置在可能会抛出异常的地方,然后立即进行处理
c++语言通过throw语句和try...catch实现对异常处理
throw 表达式;
此语句抛出一个异常,异常是一个表达式,其值的类型可以是基本类型,也可以是类
作用:对特定错误进行捕捉,而不是报错,捕捉到异常后可以对异常做出相应的处理
语法:
try{语句组}
catch(异常类型)
{异常处理代码}
标准异常类exception
bad_typeid(对空指针的引用) bad_cast(强制类型转换的错误) bad_alloc(开空间,空间不够 ios_base::failure out_of_range(越界)
#include<iostream>
#include<stdexcept>
#include<string>
double divide(double a, double b) {
if (b == 0) {
throw std::runtime_error("除数不能为零");
}
return a / b;
}
int main()
{
try {
double result = divide(10, 0);
std::cout << "结果: " << result << std::endl;
}
catch(const std::runtime_error& e)
{
std::cout << "捕获到运行时错误: " << e.what() << std::endl;
}
}
c++语言标准特性
类型推导
概念:类型推导是现代C++中非常重要的特性,它让编译器能够自动推断变量或表达式的类型。
auto 变量=值:自动为变量推导类型
int main()
{
auto x = 5;//推导出int
cout << sizeof(&x) << x<<endl;//32位下4字节,并且得到值
int x = 10;
const int cx = x;
const int& rx = x;
auto a1 = cx;//忽略const
a1 = 11;
auto a2 = rx;//忽略const和引用
// 规则2: 保留底层const
const int* ptr = &x;
auto a3 = ptr; // const int* (保留底层const)
// 规则3: auto& 会保留const和引用
auto& a4 = cx; // const int&
auto& a5 = rx; // const int&
// 规则4: auto&& 万能引用
auto&& a6 = x; // int&
auto&& a7 = cx; // const int&
auto&& a8 = 42; // int&&
}decltype(表达式)变量名称=值 :值可以有可以没有,根据表达式获取变量类型。推导表达式内部的类型
int main()
{
int x = 10;
// 规则1: 变量名 -> 变量类型
decltype(x)a;//a的类型位x的类型
cout << sizeof(&x) << endl;
// 规则2: 表达式 -> 表达式结果的类型
decltype(x + 5) c; // int
}lamdba表达式
概念:用于定义并创建匿名的函数对象,极大的提高了代码的简洁性和表现力。
语法:capture (parameters) mutable -> return-type { function-body }
-
[]- (捕获外部变量) -
()- (参数列表) -
mutable- (可修改性) -
-> type- (返回类型) -
{}-函数体#include<iostream> using namespace std; int main() { //最简单的形式 auto simple = []() { cout << "hellow" << endl; }; simple(); //当没有参数时,可以省去() auto simple2 = []{ cout << "hellow2" << endl; }; simple2(); //通过赋值的方式,获取之前定义的变量,用于表达式中 int x = 10, y = 20; //生成一个副本,此副本在函数中可修改并且不会原x auto simple3 = [x]()mutable ->int{//->int 可以省略 ++x; return x; }; auto temp = simple3();//11 auto temp2 = simple3();//12 cout << temp << " " << temp2<<endl; //引用捕获,不会生成副本,而是会影响原y auto simple4 = [&y]()mutable { y++; }; simple4(); cout << y << endl; //获取所以外部变量,生成副本 auto simple5 = [=]() { cout << x << " " << y << " " << temp << " " << temp2 << endl; }; simple5(); //引用捕获所有外部变量[&] , [a, &b] // 值捕获a,引用捕获b [=, &c] // 值捕获所有,但c是引用捕获 [&, a]// 引用捕获所有,但a是值捕获 }
委托构造
概念:使用当前类的其它构造函数来协助当前构造函数初始化操作,允许一个构造函数调用同一个类的另一个构造函数。
作用:在有一些对象需要使用特有且相同的构造函数时,就可以使用这个委托构造,直接设置好内部的一些成员变量的值,然后构造。比如:先写一个完整的构造函数,其中包含性别的选项,就可以在委托函数中直接定义好男性这个成员变量,此时生成对象时就可以直接调用这个委托构造。
普通构造和委托构造区别
它俩都是一个成员初始化值列表与一函数体
委托构造函数的成员初始化值列表只有唯一的参数就是构造函数
当被委托构造函数当中函数体有代码,那么会先指向函数体
委托构造函数的创建
在其中直接调用普通构造函数
#include<iostream>
using namespace std;
class member {
public:
member(int a, int s, string n)
{
age = a;
sex = s;
name = n;
cout << "调用构造函数" << endl;
}
member(string n) :member(18, 1, n)
{
cout << "调用委托构造" << endl;
}
private:
int age;
int sex;
string name;
};
int main()
{
//单独创建18岁男性成员
member m1("jack");
member m2("mike");
//创建其它成员
member m3(20, 0, "li");
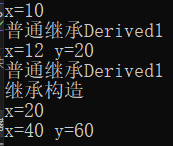
}继承构造函数
概念:继承构造函数允许派生类直接继承基类的构造函数,就像"子承父业",避免在派生类中重复编写相同的构造函数。
#include<iostream>
using namespace std;
class Base {
public:
Base(int a) {
x = a;
cout << "x=" <<x<< endl;
}
Base(int a, int b)
{
x = a;
y = b;
cout << "x=" << x<<" " << "y=" << y << endl;
}
private:
int x;
int y;
};
class Derived1 :public Base {
public:
//普通继承,手写构造函数
Derived1(int x) :Base(x) {
cout << "普通继承Derived1" << endl;
}
Derived1(int x, int y) :Base(x, y)
{
cout << "普通继承Derived1" << endl;
}
};
class Derived2 :public Base {
public:
//继承构造
using Base::Base;
};
int main()
{
Derived1 d1(10);
Derived1 d2(12,20);
cout << "继承构造" << endl;
Derived2 d3(20);
Derived2 d4(40,60);
}
作用:解决了传统方式的代码冗余问题。
注意事项:
array
是C++11引入的固定大小数组容器,它就像是给C风格数组穿上了"STL的外衣",既保持了原始数组的性能,又提供了现代容器的安全性。
#include<iostream>
#include<array>
#include <algorithm>
#include <numeric>
using namespace std;
int main()
{
//默认初始化
array<int, 4> a;//{0,0,0,0}
a = { 10,10,22,3 };
//列表初始化
array<int, 4> a2 = { 10,2,3,40 };
array<int, 4> a3{ 10,20,30,40 };
//部分初始化,剩余为0
array<int, 5> a4 = { 1,2 };//{1,2,0,0,0}
//拷贝构造的方法
array<int, 5>a5(a4);
//元素访问
cout << a5[2] << endl;//不会抛出异常
try {
cout << a5.at(5) << endl;//越界会自动抛出异常std::out_of_range异常
}
catch (std::out_of_range)
{
cout << "越界" << endl;
}
// 3. front()和back()访问首尾元素
std::cout << "第一个元素: " << a5.front() << std::endl; // 1
std::cout << "最后一个元素: " << a5.back() << std::endl; // 0
int* ptr = a5.data();//获取底层指针
cout << *(ptr + 1) << endl;//2
for (auto it = a5.begin(); it != a5.end(); it++)//迭代器
{
cout << *it << " ";
}
cout << endl;
//使用stl的函数算法
sort(a5.begin(), a5.end());//{0,0,0,1,2}
for (auto it = a5.begin(); it != a5.end(); it++)//迭代器
{
cout << *it << " ";
}
}forward_list
概念:c++11新增加的一类容器,底层实现与list容器类似,采用链表结构,只是是一个单向链表,而list位双向链表,只保留向前遍历的能力,以换取更好的性能。
区别
| 特性 | std::list | std::forward_list | std::vector |
|---|---|---|---|
| 遍历方向 | 双向 | 单向 | 随机访问 |
| 每个节点开销 | 2个指针 | 1个指针 | 无额外开销 |
| 内存局部性 | 差 | 差 | 优秀 |
| 插入删除 | O(1)任意位置 | O(1)在已知位置后 | O(n)中间插入 |
| size()方法 | 有 | 无(C++11) | 有 |
#include<iostream>
#include<forward_list>
using namespace std;
int main()
{
//单向链表不支持随机访问和访问back的方法
//只能访问头节点
std::forward_list<int> flist = { 10, 20, 30, 40 };
std::cout << "第一个元素: " << flist.front() << std::endl; // 10
//可以使用迭代器遍历
for (auto it = flist.begin(); it != flist.end(); ++it) {
std::cout << *it << " ";
}
std::cout << std::endl;
//插入方法,使用迭代器的方式
flist.push_front(5);//头部插入
flist.emplace_front(1);//头部插入
for (auto it = flist.begin(); it != flist.end(); ++it) {
if (*it == 10)
{
flist.insert_after(it, 15);//在10的节点后面插入新节点
}
}
for (auto it = flist.begin(); it != flist.end(); ++it) {
std::cout << *it << " ";
}
std::cout << std::endl;注意事项:插入和删除操作只能针对头部位置和当前节点的后面节点,不能操作前节点。并且删除当前节点的时候,迭代器会失效,要进行接收删除操作的返回值。
垃圾回收机制
概念:自动内存管理机制,就像有个"内存管家"自动帮你清理不再使用的内存,防止内存泄漏。
c++没有垃圾回收的原因:系统处理时的开销、设计耗内存、替代方法(析构函数)、没有共同基类
c/c++经典垃圾回收算法:引用技术算法(通过计数的方式查看内存是否使用,类似于unique_ptr)、标记清除算法(从根节点遍历所有节点,如果无法遍历的地方,就需要清除),节点拷贝算法(把整个堆分成两个半区,将一个半区的拷贝到另一半区,就可以解决内存碎片问题)
正则表达式
概念:正则表达式是文本模式匹配的工具,就像"文本搜索的超级放大镜",可以快速找到符合复杂规则的字符串
#include <regex> // 主要头文件
// 🎯 核心类:
std::regex // 正则表达式对象
std::smatch // 匹配结果(字符串)
std::cmatch // 匹配结果(C字符串)
std::sub_match // 子匹配结果
std::regex_iterator // 正则迭代器
std::regex_token_iterator // 正则令牌迭代器
#include <regex>
#include <iostream>
void regexMatchDemo() {
// 🎯 regex_match - 整个字符串必须完全匹配模式
std::regex date_pattern(R"(\d{4}-\d{2}-\d{2})");
std::string valid_date = "2024-03-20";
std::string invalid_date = "2024-03-20 extra";
if (std::regex_match(valid_date, date_pattern)) {
std::cout << "有效日期格式" << std::endl;
}
if (!std::regex_match(invalid_date, date_pattern)) {
std::cout << "无效日期格式" << std::endl;
}
// 🎯 提取匹配组
std::regex detailed_date(R"((\d{4})-(\d{2})-(\d{2}))");
std::smatch matches;
if (std::regex_match(valid_date, matches, detailed_date)) {
std::cout << "完整匹配: " << matches[0] << std::endl; // 2024-03-20
std::cout << "年份: " << matches[1] << std::endl; // 2024
std::cout << "月份: " << matches[2] << std::endl; // 03
std::cout << "日期: " << matches[3] << std::endl; // 20
}
}智能指针
概念:智能指针是自动管理内存生命周期的RAII包装器,就像"内存管家",自动处理资源的分配和释放。
头文件:<memory>
智能指针家族对比
| 智能指针 | 所有权语义 | 拷贝语义 | 使用场景 |
|---|---|---|---|
unique_ptr |
独占所有权 | 禁止拷贝,允许移动 | 单一所有者资源 |
shared_ptr |
共享所有权 | 引用计数,可拷贝 | 共享资源 |
weak_ptr |
观察所有权 | 不增加引用计数 | 打破循环引用 |
auto_ptr |
独占所有权 | 已废弃 | C++98遗留 |
unique_ptr:独占指针(内存占为己有,不支持拷贝和赋值)。unique_ptr对象在它们本身被销毁后立即删除它们管理的对象(使用删除器 ),或者一旦它们的值通过赋值作或显式调用 unique_ptr::reset 更改,它们就会自动删除它们管理的对象(使用删除器)。
特性:
-
一般用make_unique创建对象
-
可以通过move(指针)转移所有权,它自身会被释放
-
显式释放资源用reset或者出作用域自动释放
-
relase可以释放空间,把空间返回,这块空间可以被指针接收
-
get可以获得智能指针的的空间
-
unique_ptr的"独占"指的是所有权独占,不是访问权独占。这种设计既保证了内存安全,又提供了必要的灵活性!#include
#include
using namespace std;int main()
{
unique_ptru1 = make_unique (10);
int* a = u1.get();//获取u1指向的地址
*a = 100;int* b = u1.release();//释放u1的空间,并把空间给b *b = 50; cout << *a << endl; cout << u1 << endl; unique_ptr<int>u2(new int (100)); //unique_ptr<int>u3(u2);//无法进行拷贝构造 unique_ptr<int> u3(move(u2));//移动语义可以将u2的指向的内存给u3 cout << u2 << endl; cout << *u3 << endl; //u2.reset();//手动销毁空间 //cout << u2 << endl; //作用域结束自动释放内存}
shared_ptr:引用计数指针(共享拥有同一堆分配对象的内存,支持复制和赋值操作),通过计数的方式表明当前指针指向的内存有几个指针指向。一旦计数变为0,对象就会销毁。这在非环形数据结构中防止资源泄露很有帮助。
特性:
-
make_shared函数:最安全的分配和使用动态内存的方法,返回shared_ptr。 将对象和控制块分配在连续内存。构造函数(new 空间)
-
可以与其它指针共享同一块内存,通过use_count得到同一块空间的智能指针个数
-
大部分成员函数与unique_ptr相同
int main()//引用计数指针
{
shared_ptrs1(new string ("jack"));
shared_ptrs2 = s1;//两个指针指向同一块空间
cout << s2.use_count() << endl;//2
s2.reset();
cout << s1.use_count() << endl;//1
}
weak_ptr智能指针:配合shared_ptr而引入的一种智能指针协助shared_ptr工作。它的构造和析构不加或减少计数。并不用于资源的所有权,所以不能直接使用资源,但是可以查看shared_ptr的一些状态
特性:
- 与share_ptr相结合,但不参与计数,但可以指向同一块区域。
- 能够解决循环引用的问题(技术指针互相连接)
- 不能对指向的空间*引用,因此不能操作指向的空间的对象
- 目的是解决shared_ptr的循环引用问题
- 不能直接访问对象,必须通过
lock()方法获取临时所有权 - 当所有
shared_ptr都销毁对象后,weak_ptr能感知到对象已不存在,通过expired()
常用场景:
当两个或多个对象通过shared_ptr相互引用时,会形成循环引用:
-
对象A持有对象B的
shared_ptr -
对象B持有对象A的
shared_ptr -
引用计数永远不会归零
-
内存泄漏发生
weak_ptr通过打破所有权循环来解决这个问题:
-
单向所有权 :将其中一个方向的引用改为
weak_ptr -
不增加引用计数 :
weak_ptr不参与引用计数计算 -
需要时临时获取所有权 :通过
lock()在需要访问时临时获得所有权class Node : public enable_shared_from_this
{
public:
shared_ptrnext;
shared_ptrprev; // 🚨 循环引用! // ✅ 解决方案:使用weak_ptr weak_ptr<Node> weak_prev; ~Node() { cout << "Node 析构" << endl; }};
void demonstrateCyclicReference() {
auto node1 = make_shared();
auto node2 = make_shared(); node1->next = node2; node2->prev = node1; // 循环引用,内存泄漏! // 使用weak_ptr避免循环引用 node2->weak_prev = node1;}
关键字nullptr/constexpr
nullptr:替换NULL
consterpr:constexpr是C++11引入的关键字,用于声明编译期常量表达式。它的核心目标是让计算在编译阶段完成,而不是运行时。
#include<iostream>
using namespace std;
int max(int a, int b)
{
return a < b ? b : a;
}
int main()
{
constexpr int compile_const = 42; // 编译期初始化
const int a = max(10, 11);//运行时初始化
}Function
概念:std::function是一个通用的函数包装器,可以存储、复制和调用任何可调用对象。就像"函数容器",能容纳各种类型的函数。
函数对象类型:
- 普通函数
- lambda函数
- 结构体或类函数(通过operator实现的)
小点: 结构体或类函数对象优点:
成员函数是与类关联的函数 ,它们操作类的对象并访问其内部状态。与普通函数不同,成员函数隐式接收一个指向调用对象的指针(this指针)。
-
性能优越 - 可被编译器内联优化
-
状态保持 - 可以拥有成员变量和状态
-
类型安全 - 编译时类型检查
-
高度灵活 - 可模板化、可继承、可组合
-
现代C++集成 - 与Lambda、STL完美配合
#include
#include
using namespace std;
void print()
{
cout << "hellow " << endl;
}
struct print2
{
void operator ()()
{
cout << "func3" << endl;
}
};
class print3 {
public:
void operator()()
{
cout << "func" << ":" << id << endl;
}private:
int id = 4;
};
int main()
{
function<void()> func1 = print;
function<void()> func2 = {
cout << "func2";
};
function<void()> func3 = print2();
function<void()> func4 = print3();func1(); func2(); func3(); func4();}
共享内存
概念:共享内存是一种进程间通信(IPC)机制 ,允许多个不相关的进程访问同一块物理内存区域。这是速度最快 的IPC方式,因为数据不需要在内核和用户空间之间复制。共享文件句柄方式共享内存,正式名称为内存映射文件(Memory-mapped Files),它通过将磁盘文件映射到进程的虚拟地址空间,实现多个进程对同一内存区域的共享访问。
服务端创建共享内存区域部分,内存映射到当前应用程序进程,写入数据信息
客户端打开共享内存区域部分、内存映射到当前应用程序进程、读出数据信息
atomic_flag
概念:原子布尔类型,不同于atomic的特化,保证免锁,不提供加载或存储操作.它只支持两个操作:设置和清除。就像"原子开关",只能开或关。
| 特性 | 说明 | 优势 |
|---|---|---|
| 无锁保证 | 在所有平台上都是无锁的 | 性能最高 |
| 最小开销 | 只有两个状态操作 | 内存占用最小 |
| 简单接口 | 只有test_and_set()和clear() | 使用简单 |
语法:
①通过test_and_set设置标志并返回旧值
概念:实现多线程间的同步操作,当条件不满足,相关线程会一直阻塞,当某种条件满足时,线程才会唤醒。
std::thread多线程
join和detch的区别
异常处理exception类
c++中的一些类代表异常,都是从exception类派生出来的,因此要包含stdexcept头文件,来调用这些异常
// ❌ 错误理解:认为会抛出异常
try {
a[10] = 100; // 期望:抛出 std::out_of_range
} catch (const std::out_of_range& oor) {
// 实际上永远不会执行到这里!
}
// ✅ 实际情况:未定义行为
a[10] = 100; // 可能:
// - 静默覆盖相邻内存
// - 程序崩溃
// - 产生随机结果
// - 任何其他奇怪行为
#include <iostream>
#include <stdexcept>
#include <vector>
int main() {
std::vector<int> a(10); // 使用vector而不是原生数组
try {
a.at(10) = 100; // ✅ 使用at()方法,会进行边界检查
}
catch (const std::out_of_range& oor) {
std::cerr << "Out of Range error: " << oor.what() << '\n';
}
return 0;
}关键知识点:
-
原生数组不进行边界检查,越界访问是未定义行为
-
只有
std::vector::at()和std::array::at()会抛出std::out_of_range -
现代C++推荐使用标准容器而非原生数组
-
始终优先选择安全的访问方法
。