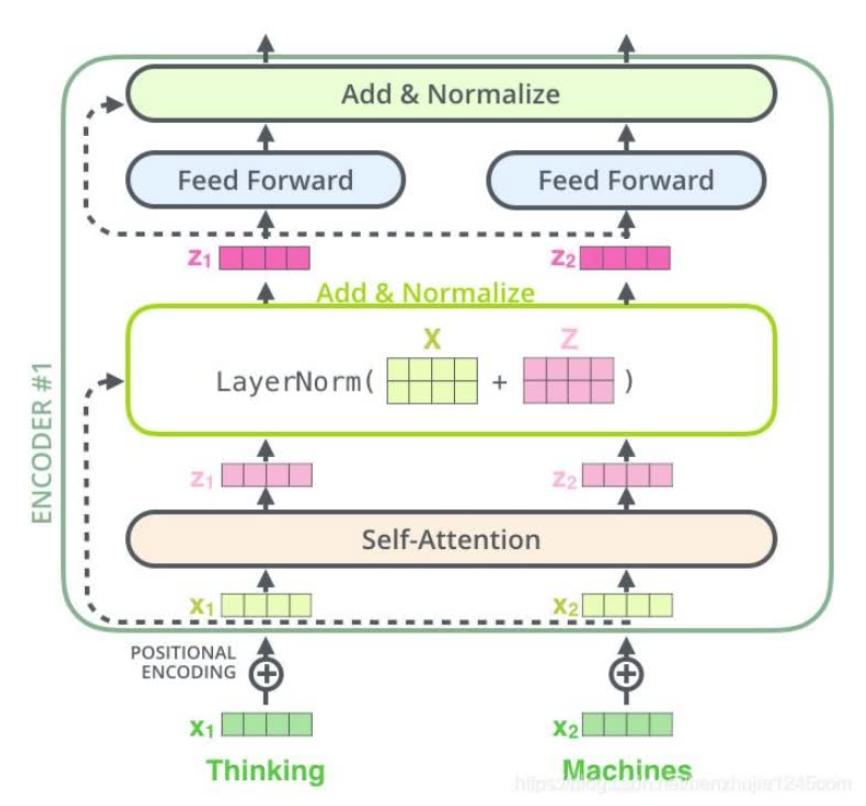
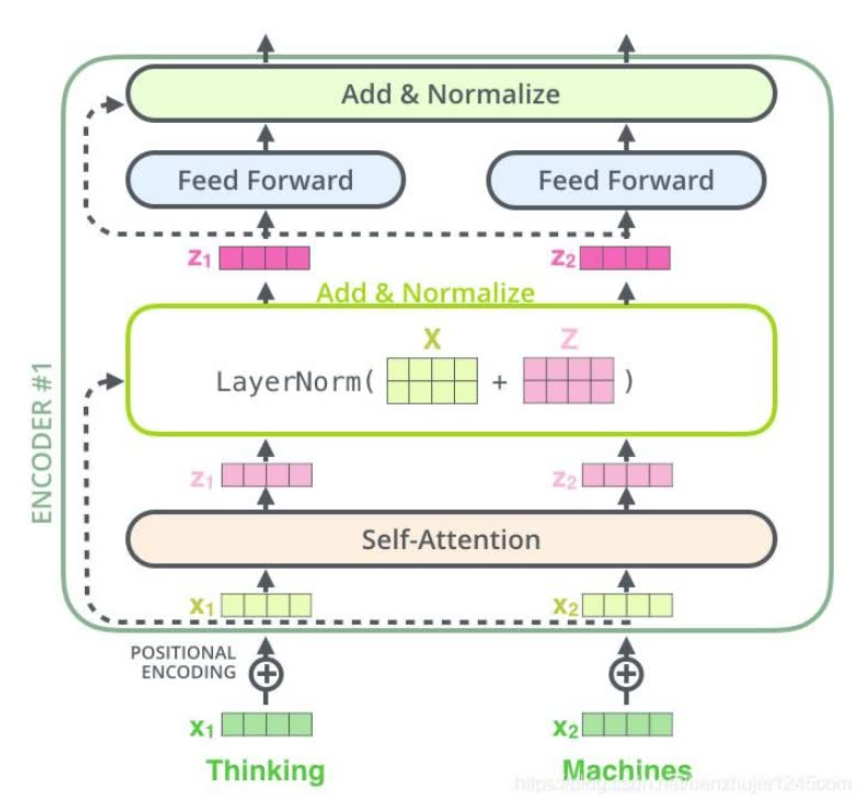
- Transformers的原理结构和流程。encoder-decoder,论文中是分别六层,实际也可以别的层数。每个encoder 由self-attention和feed forward network组成。编码器的输入先流入sa层,它可以让编码器在对特定词进行编码时,使用输入句子时其他词的信息,然后sa层的输出流入ffn。ffn的作用是引入非线性变换。decoder也有sa和ffn,但中间还有个注意力层(encoder-decoder attention),用来帮助解码器关注输入句子的相关部分。

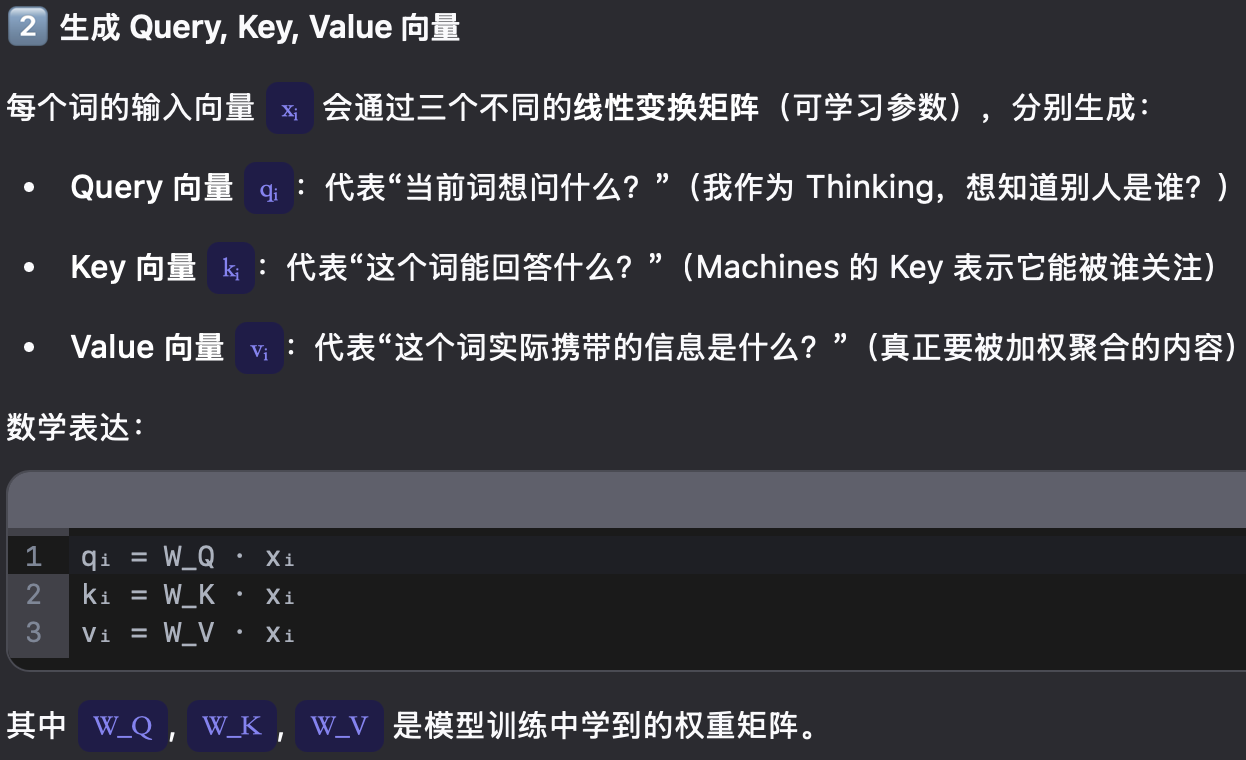
- Self-attention原理。矩阵X中的每一行,表示输入句子中的每一个词的词向量,QKV三个矩阵来自同一输入,首先计算q和k之间的点积,为了防止结果过大用softmax操作将其结果归一化为概率分布,再乘以V就得到权重求和的表示。dk是key向量的维度,除以根号dk是为了让反向传播的时候求梯度更加稳定。softmax将分数归一化,使得它们都为正数且和为1
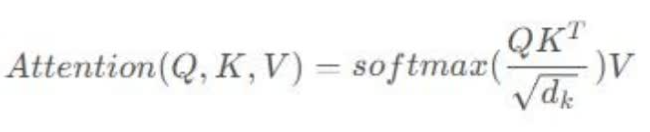
-
多头注意力机制。比如8个头,最后将不同的attention拼接起来,再进行一次线性变换。每一组注意力用于将输入映射到不同的子表示空间,这使得模型可以在不同子空间中关注不同的位置。
-
残差连接和层归一化。每个编码器的每个子层(sa和ffn)都有一个残差连接,再执行一个layer norm操作。
-
第一个编码器的输入是一个序列,最后一个编码器的输出是一组注意力向量key和value。这些向量在解码器的encoder-decoder attention层被使用,这有助于解码器把注意力集中在输入序列的合适位置。
-
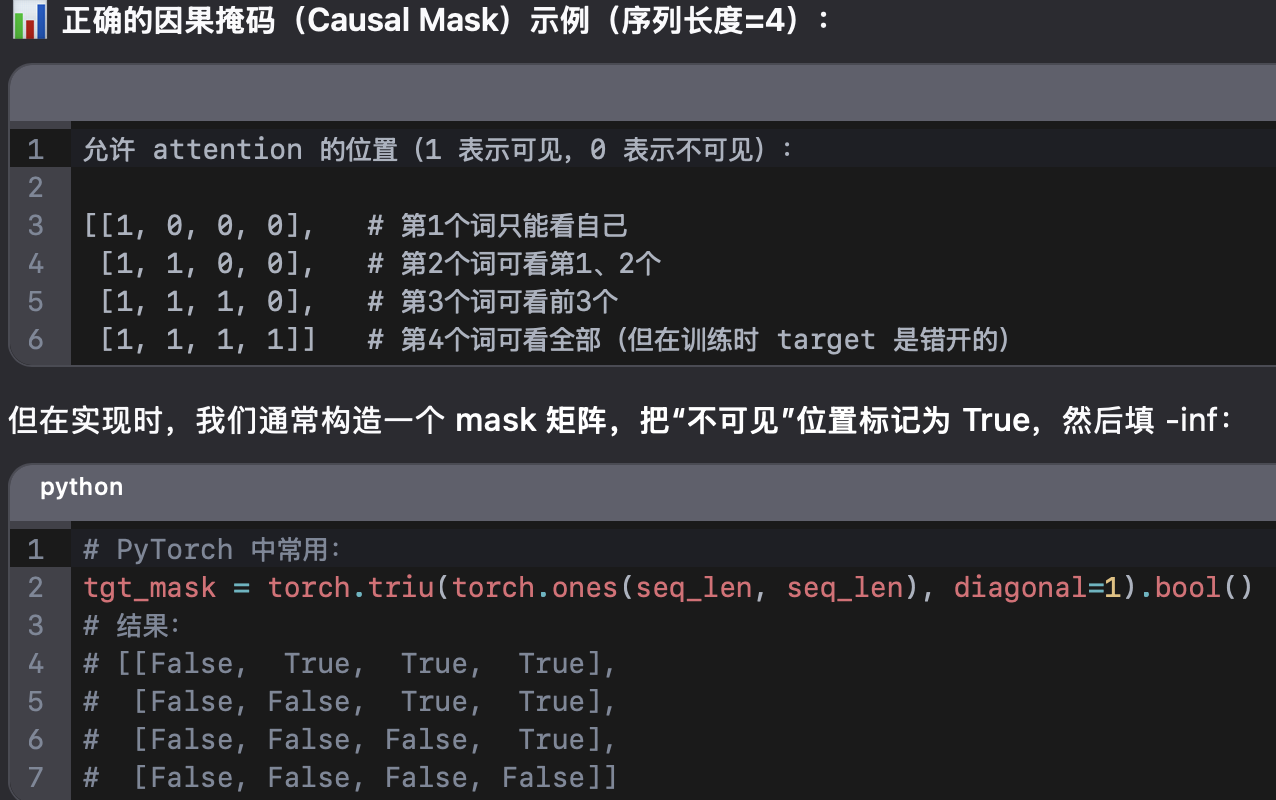
transformer中有两种mask,padding mask和sequence mask。
padding mask:每个批次输入序列的长度不一样,所以要对在较短的输入序列后面补0,太长的是截断。这些填充的位置没什么意义,所以我们的attention机制不应该把注意力放在这些位置上。具体做法:把这些位置的值加上一个非常大的负数,这样经过softmax后,这些位置的概率就会接近0。
sequence mask:使得decoder不能看见未来的信息。具体做法:产生一个上三角矩阵,上三角的值全为0,把这个矩阵作用在每个序列上即可。

- 最后的线性层和softmax层。线性层是一个简单的全连接神经网络,把解码器的输出映射到一个更长的向量,被称为logits向量。然后softmax层会把这些分数转换成概率,最后选择最高概率对应的单词。
8.Transformer 用 LN 不用 BN,是因为 BN 在小 batch、变长序列、含 padding 的 NLP 场景下统计量不可靠,而 LN 对每个样本独立归一化,稳定、高效、与 batch 无关,完美适配 Transformer 的自回归和序列建模需求。
改进方案:RMSNorm:去掉 LN 中的均值中心化(只除以均方根),计算更快,性能相当(LLaMA 使用)