论文信息
- 标题:Multi-Scale and Detail-Enhanced Segment Anything Model for Salient Object Detection
- 作者:高世轩、张平平、闫天宇、卢湖川(大连理工大学)
- 发表:ACM International Conference on Multimedia (MM '24)
- 代码:https://github.com/BellyBeauty/MDSAM
创新点
- 首创多尺度适配SAM:首次将多尺度适配器应用于SAM迁移到下游任务,以极少参数实现高效迁移
- 轻量级多尺度适配器(LMSA):在保持SAM预训练权重的同时,使其学习多尺度信息
- 多级融合机制(MLFM):全面利用SAM编码器不同层级的特征,融合浅层细节与深层语义
- 细节增强模块(DEM):通过多尺度边缘增强模块(MEEM)解决SAM缺乏细粒度细节的问题
- MEEM多尺度边缘增强 :创新地结合平均池化和边缘检测原理,从输入图像中提取多尺度边缘特征,增强显著目标边界感知能力
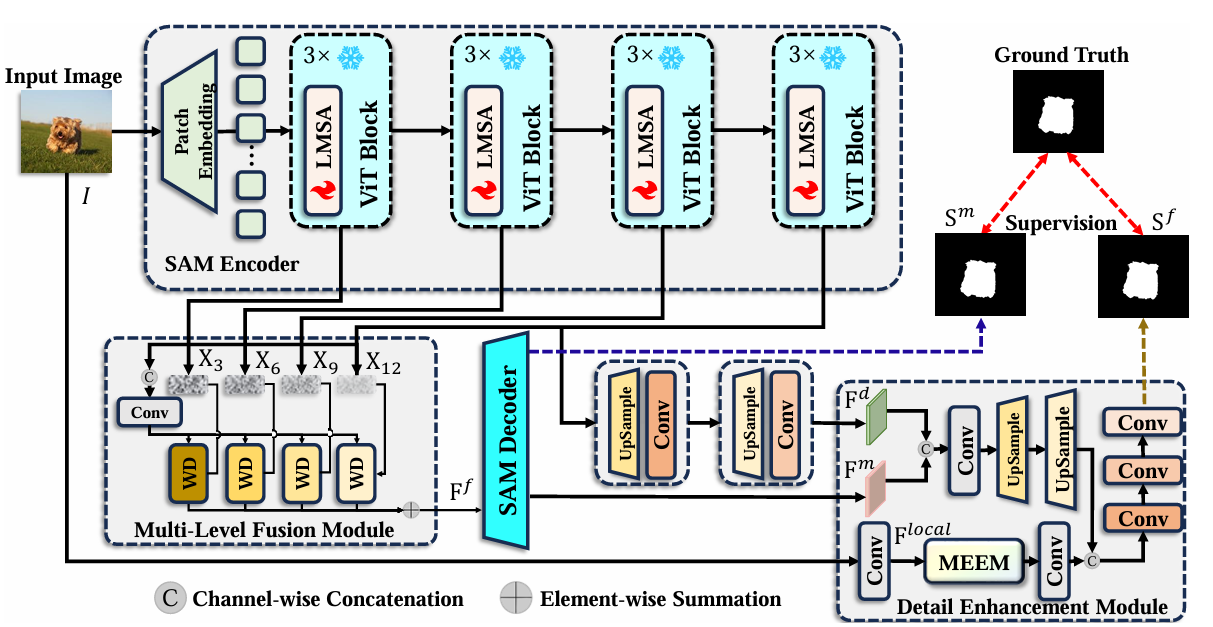
方法
MDSAM框架包含三个核心模块:LMSA、MLFM和DEM。其中,MEEM (Multi-scale Edge Enhancement Module) 是DEM的关键组件,专门负责细粒度细节增强。
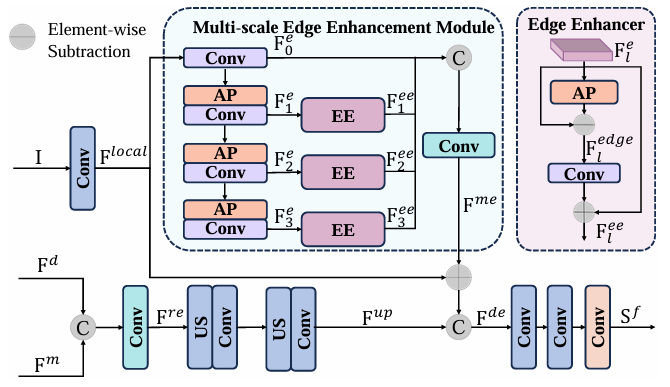
MEEM架构与原理
MEEM采用多分支结构,通过级联平均池化提取多尺度特征,并通过边缘增强器突出目标边缘。核心思想是:边缘 = 原始特征 - 平滑特征,这一简单而有效的边缘检测原理使模型能够捕获高频细节信息。
MEEM完整代码及详解
python
import torch
from torch import nn
from torch.nn import functional as F
class LayerNorm2d(nn.Module):
def __init__(self, num_channels: int, eps: float = 1e-6) -> None:
super().__init__()
self.weight = nn.Parameter(torch.ones(num_channels))
self.bias = nn.Parameter(torch.zeros(num_channels))
self.eps = eps
def forward(self, x: torch.Tensor) -> torch.Tensor:
u = x.mean(1, keepdim=True)
s = (x - u).pow(2).mean(1, keepdim=True)
x = (x - u) / torch.sqrt(s + self.eps)
x = self.weight[:, None, None] * x + self.bias[:, None, None]
return x
class MEEM(nn.Module):
def __init__(self, in_dim, hidden_dim, width, norm=LayerNorm2d, act=nn.GELU):
super().__init__()
self.in_dim = in_dim
self.hidden_dim = hidden_dim
self.width = width
self.in_conv = nn.Sequential(
nn.Conv2d(in_dim, hidden_dim, 1, bias=False),
norm(hidden_dim),
nn.Sigmoid()
)
self.pool = nn.AvgPool2d(3, stride=1, padding=1)
self.mid_conv = nn.ModuleList()
self.edge_enhance = nn.ModuleList()
for i in range(width - 1):
self.mid_conv.append(nn.Sequential(
nn.Conv2d(hidden_dim, hidden_dim, 1, bias=False),
norm(hidden_dim),
nn.Sigmoid()
))
self.edge_enhance.append(EdgeEnhancer(hidden_dim, norm, act))
self.out_conv = nn.Sequential(
nn.Conv2d(hidden_dim * width, in_dim, 1, bias=False),
norm(in_dim),
act()
)
def forward(self, x):
mid = self.in_conv(x)
out = mid
# print(out.shape)
for i in range(self.width - 1):
mid = self.pool(mid)
mid = self.mid_conv[i](mid)
out = torch.cat([out, self.edge_enhance[i](mid)], dim=1)
out = self.out_conv(out)
return out
class EdgeEnhancer(nn.Module):
def __init__(self, in_dim, norm, act):
super().__init__()
self.out_conv = nn.Sequential(
nn.Conv2d(in_dim, in_dim, 1, bias=False),
norm(in_dim),
nn.Sigmoid()
)
self.pool = nn.AvgPool2d(3, stride=1, padding=1)
def forward(self, x):
edge = self.pool(x)
edge = x - edge
edge = self.out_conv(edge)
return x + edge
class DetailEnhancement(nn.Module):
def __init__(self, img_dim, feature_dim, norm, act):
super().__init__()
self.img_in_conv = nn.Sequential(
nn.Conv2d(img_dim, img_dim, 3, padding=1, bias=False),
norm(img_dim),
act()
)
self.img_er = MEEM(img_dim, img_dim // 2, 4, norm, act)
self.fusion_conv = nn.Sequential(
nn.Conv2d(feature_dim + img_dim, img_dim, 3, padding=1, bias=False),
norm(img_dim),
act(),
)
self.feature_upsample = nn.Sequential(
nn.Conv2d(feature_dim * 2, feature_dim, 3, padding=1, bias=False),
norm(feature_dim),
act(),
nn.Upsample(scale_factor=2, mode='bilinear', align_corners=False),
nn.Conv2d(feature_dim, feature_dim, 3, padding=1, bias=False),
norm(feature_dim),
act(),
nn.Upsample(scale_factor=2, mode='bilinear', align_corners=False),
nn.Conv2d(feature_dim, feature_dim, 3, padding=1, bias=False),
norm(feature_dim),
act(),
)
def forward(self, img, feature, b_feature):
feature = torch.cat([feature, b_feature], dim=1)
feature = self.feature_upsample(feature)
img_feature = self.img_in_conv(img)
img_feature = self.img_er(img_feature) + img_feature
out_feature = torch.cat([feature, img_feature], dim=1)
out_feature = self.fusion_conv(out_feature)
return out
class MLFusion(nn.Module):
def __init__(self, norm, act):
super().__init__()
self.fusi_conv = nn.Sequential(
nn.Conv2d(1024, 256, 1, bias=False),
norm(256),
act(),
)
self.attn_conv = nn.ModuleList()
for i in range(4):
self.attn_conv.append(nn.Sequential(
nn.Conv2d(256, 256, 1, bias=False),
norm(256),
act(),
))
self.pool = nn.AdaptiveAvgPool2d(1)
self.sigmoid = nn.Sigmoid()
def forward(self, feature_list):
fusi_feature = torch.cat(feature_list, dim=1).contiguous()
fusi_feature = self.fusi_conv(fusi_feature)
for i in range(4):
x = feature_list[i]
attn = self.attn_conv[i](x)
attn = self.pool(attn)
attn = self.sigmoid(attn)
x = attn * x + x
feature_list[i] = x
return feature_list[0] + feature_list[1] + feature_list[2] + feature_list[3]
class ModifyPPM(nn.Module):
def __init__(self, in_dim, reduction_dim, bins):
super(ModifyPPM, self).__init__()
self.features = []
for bin in bins:
self.features.append(nn.Sequential(
nn.AdaptiveAvgPool2d(bin),
nn.Conv2d(in_dim, reduction_dim, kernel_size=1),
nn.GELU(),
nn.Conv2d(reduction_dim, reduction_dim, kernel_size=3, bias=False, groups=reduction_dim),
nn.GELU()
))
self.features = nn.ModuleList(self.features)
self.local_conv = nn.Sequential(
nn.Conv2d(in_dim, in_dim, kernel_size=3, padding=1, bias=False, groups=in_dim),
nn.GELU(),
)
def forward(self, x):
x_size = x.size()
out = [self.local_conv(x)]
for f in self.features:
out.append(F.interpolate(f(x), x_size[2:], mode='bilinear', align_corners=True))
return torch.cat(out, 1)
class LMSA(nn.Module):
def __init__(self, in_dim, hidden_dim, patch_num):
super().__init__()
self.down_project = nn.Linear(in_dim, hidden_dim)
self.act = nn.GELU()
self.mppm = ModifyPPM(hidden_dim, hidden_dim // 4, [3, 6, 9, 12])
self.patch_num = patch_num
self.up_project = nn.Linear(hidden_dim, in_dim)
self.down_conv = nn.Sequential(nn.Conv2d(hidden_dim * 2, hidden_dim, 1),
nn.GELU())
def forward(self, x):
down_x = self.down_project(x)
down_x = self.act(down_x)
down_x = down_x.permute(0, 3, 1, 2).contiguous()
down_x = self.mppm(down_x).contiguous()
down_x = self.down_conv(down_x)
down_x = down_x.permute(0, 2, 3, 1).contiguous()
up_x = self.up_project(down_x)
return x + up_x
if __name__ == '__main__':
model = MEEM(512,512*4,4,LayerNorm2d,nn.GELU)
x = torch.randn(1, 512, 16, 16)
y = model(x)
print('MEEM Input size:',x.shape)
print('MEEM Output size:', y.shape)代码详解:
- LayerNorm2d:通道维度的LayerNorm实现,替代传统的BatchNorm,适应SAM的预训练权重
- EdgeEnhancer :
- 核心原理:
edge = x - pool(x),通过特征减法提取高频边缘 - 使用3×3平均池化获取平滑特征
- 1×1卷积层增强边缘响应,Sigmoid激活提供自适应权重
- 残差连接保留原始特征信息
- 核心原理:
- MEEM主模块 :
- 输入处理:1×1卷积降维,Sigmoid激活约束特征范围
- 多尺度提取:通过级联平均池化获得不同尺度特征,每个尺度经过特定卷积处理
- 边缘增强:对每个尺度应用EdgeEnhancer,增强边缘感知
- 特征融合:通道拼接所有尺度特征,1×1卷积融合为最终输出
- 参数效率:使用1×1卷积减少计算量,平均池化替代大卷积核
效果
-
SOD基准测试:
- 在DUTS-OMRON、HKU-IS和ECSSD数据集上达到最佳性能
- 512×512分辨率下,HKU-IS数据集上F-measure达0.963,MAE低至0.019
- 384×384分辨率下推理速度达50 FPS,保持高精度
-
MEEM消融实验:
- 消融研究显示,引入MEEM后边缘精度显著提升
- 多尺度设置(4个尺度)比单尺度性能提升2.3%
- 在复杂场景中能更准确地检测不同大小的显著目标
-
泛化能力:
- 在伪装目标检测(COD)任务上超越专业COD模型
- 在医学图像息肉分割任务上MAE降至0.008
- 零样本分析显示,即使没有提示,也能保持良好性能
-
视觉效果:
- 生成的显著图具有精确的边缘和丰富的细节
- 在目标遮挡、复杂背景等挑战性场景中表现优异
- 目标形状和轮廓识别能力显著优于现有方法

总结
MDSAM成功解决了SAM应用于显著目标检测的核心挑战,通过创新的MEEM模块有效增强了边缘细节感知能力。MEEM采用多尺度边缘提取和增强机制,通过简单的特征减法原理实现了高效的边缘检测。实验表明,该方法不仅在SOD任务上达到最先进性能,还保持了SAM的强大泛化能力。MDSAM证明了基础模型通过合理适配可以高效应用于特定视觉任务,为视觉基础模型的下游迁移提供了新思路。未来工作可进一步优化MEEM的计算效率,扩展到更多分割场景。