各种技术快速发展的今天,编程语言也是从出不穷,仓颉作为一门新兴的编程语言,凭借着其独特的优势也是快速的进入各路开发者的视野。仓颉出现之初其目标就是打造一款面向全场景智能,主打原生智能化、天生全场景、高性能、强安全,并主要应用于鸿蒙原生应用及服务应用等场景中,为开发者提供良好的编程体验的编程语言。
在充分了解到仓颉的优势后,我对其也是产生了强烈的兴趣,正好最近项目中有一个核心案例,目前是使用Python进行解决的,不知道如果将其迁移到仓颉后,性能和代码量会如何变化。接下来,我会详细介绍,我是如何一步步将代码从Python迁移到仓颉的,分享其中的经验以及踩过的坑。

一、刚上手仓颉,如何快速搭建好仓颉环境
安装仓颉插件
仓颉官方目前除了专用的仓颉编辑器外,同时为VSCode提供了仓颉插件,可以让我们方便快速的开发仓颉程序。
在VSCode的插件市场搜索"Cangjie"就可以免费安装使用了。

安装仓颉SDK
安装完仓颉插件后,就要按照仓颉SDK了,仓颉 SDK 主要提供了仓颉语言编译命令(cjc)、仓颉语言官方包管理工具(Cangjie Package Manager,简称 CJPM),以及仓颉格式化工具(Cangjie Formatter,简称 cjfmt)等命令行工具。正确安装并配置仓颉 SDK 后,可使用工程管理、编译构建、格式化、静态检查和覆盖率统计等功能。
可以直接去下载中心-仓颉编程语言官网进行下载
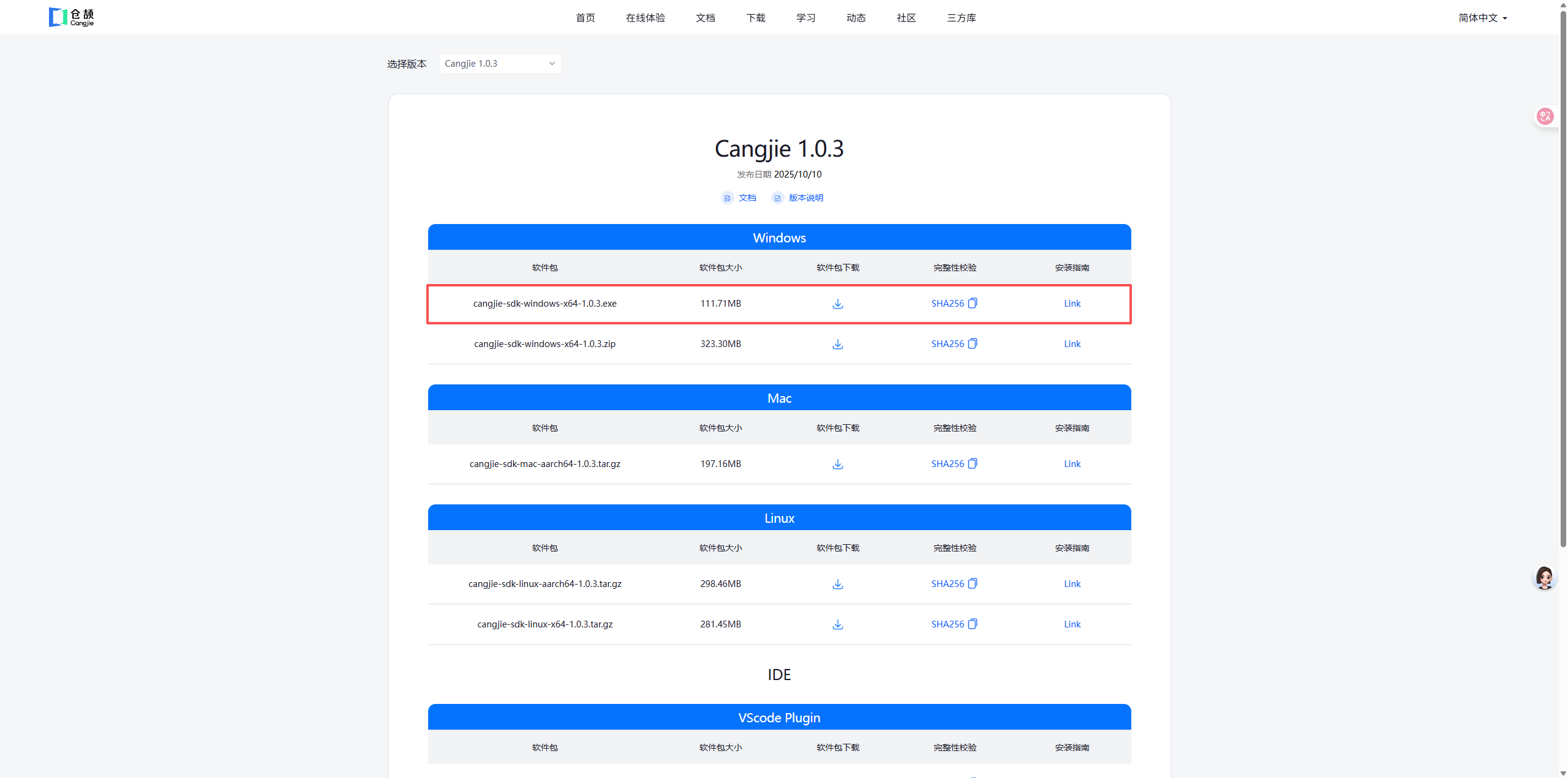
我是下载的setup,这样可以避免后续的环境变量的配置,无脑点击下一步,安装即可,大约等待3-5分钟即可安装完毕。
安装完毕后记得重启一下电脑
SDK安装完毕后,就要给插件配置SDK路径了。
右键插件,选择Settings,就可以看到配置页面了。
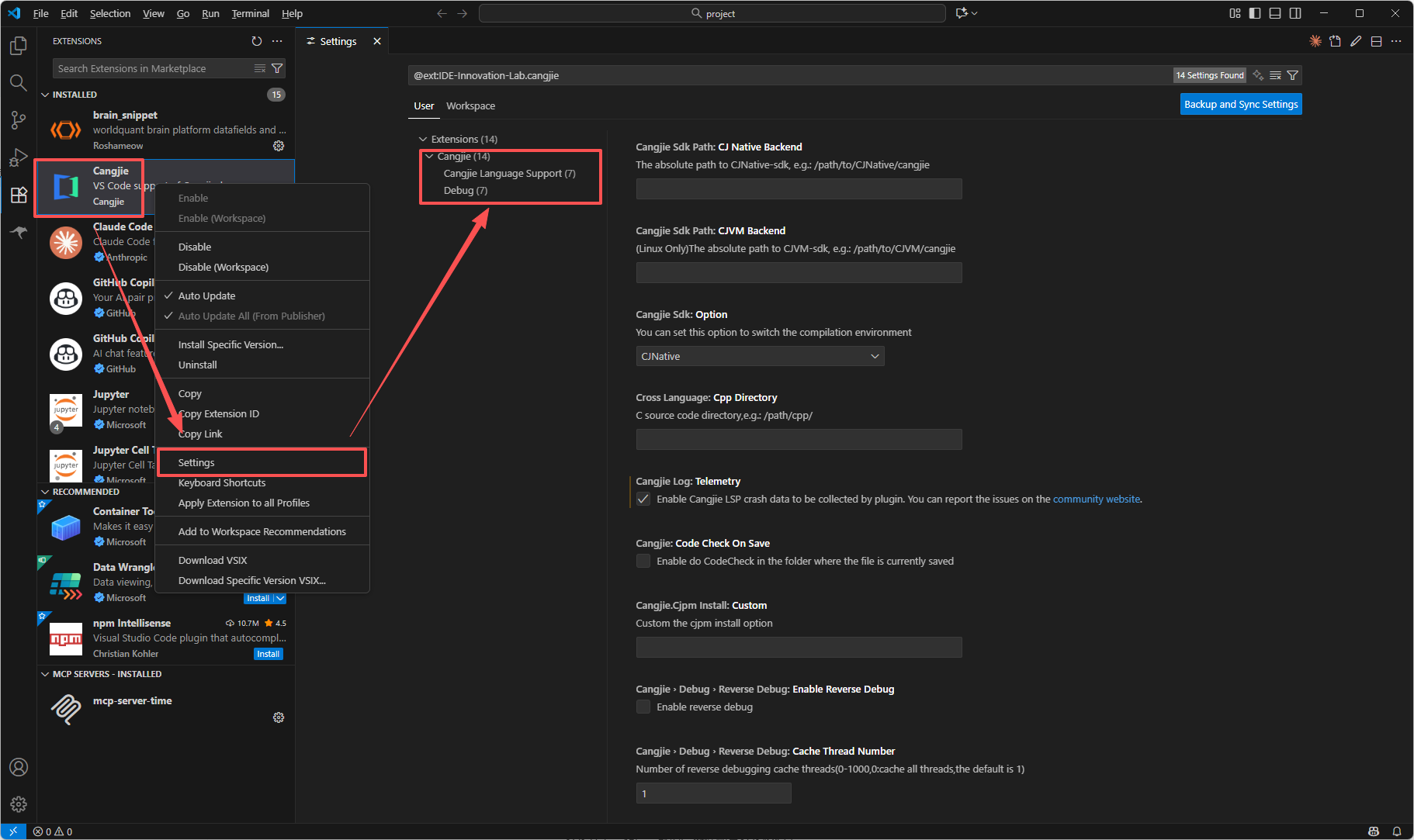
主要需要配置两个位置,一个是CJ Native Backend ,一个是Option 。CJ Native Backend 需要填写SDK文件夹所在的绝对路径,Option需要选择CJNative(默认就是CJNative)
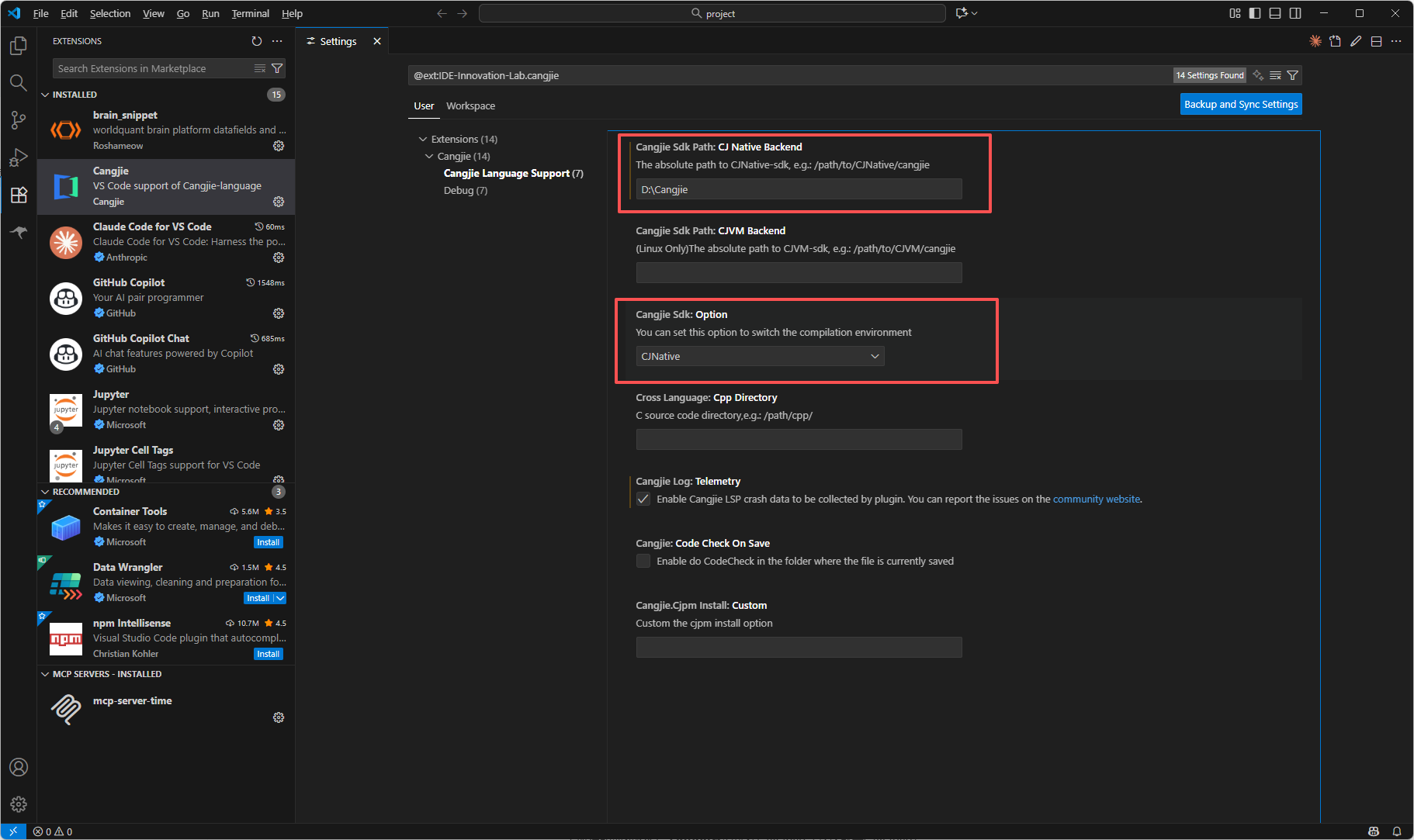
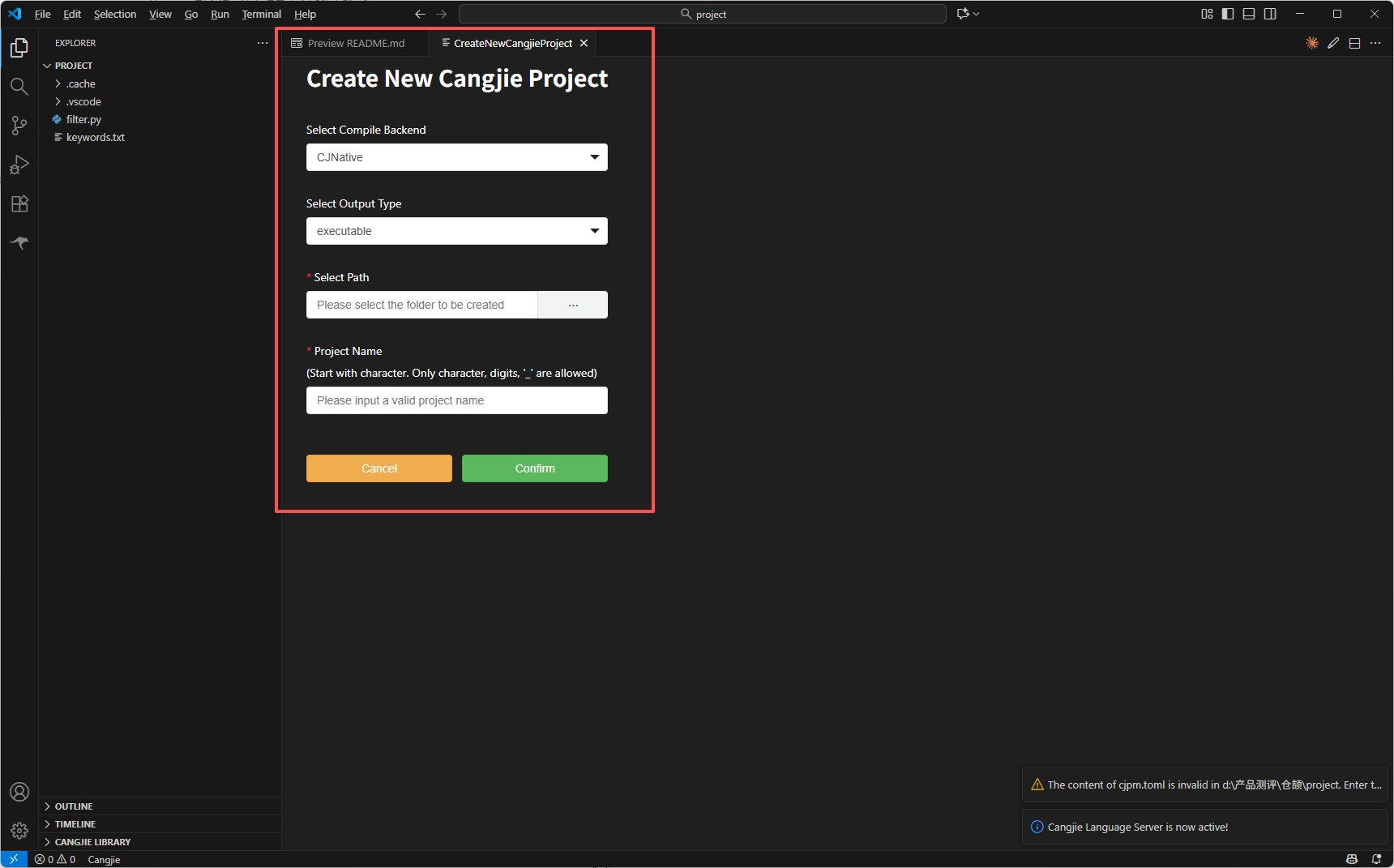
配置完成后记得重启一下VSCode,然后通过快捷键 Ctrl + Shift + P(macOS 系统的快捷键为 Command + Shift + P) 调出 VSCode 的命令面板,选择 cangjie: Create Cangjie Project View 命令,来快速验证一下是否配置成功了。
成功弹出以下页面则说明配置成功了。
二、项目迁移实战
一个完整的项目,动辄几百个文件,上万条代码,完整的进行迁移还是会有不小的工作量,因此本次的项目迁移实战,仅选择了项目中部分核心内容的迁移,进而探究迁移过程,并进行前后的代码量、性能等多方面对比。
核心内容是一个敏感词过滤器,通过实现了三种不同的敏感词(NaiveFilter、BSFilter、DFAFilter)过滤算法并进行性能比较。这里选取了最简的一种NaiveFilter来进行迁移。
代码实现对比
包/模块导入
Python版本:
python
import time仓颉版本:
markdown
import std.collection.*
import std.fs.*
import std.time.*差异分析:
- Python使用简单的
import语句 - 仓颉采用更明确的模块导入系统,需要指定完整路径
- 仓颉的导入更接近Java或C#的风格
类定义和构造函数
Python版本:
python
class NaiveFilter():
def __init__(self):
self.keywords = set()仓颉版本:
markdown
class NaiveFilter {
var keywords: Set<String> = HashSet<String>()
public init() {}
}差异分析:
- Python使用
__init__作为构造函数 - 仓颉使用
init关键字,更接近传统面向对象语言 - 仓颉需要显式声明变量类型(
Set<String>) - 仓颉的访问修饰符(
public)是可选的
文件读取实现
Python版本:
python
def parse(self, path):
try:
with open(path, 'r', encoding='utf-8') as f:
for keyword in f:
self.keywords.add(keyword.strip().lower())
except FileNotFoundError:
print(f"Warning: Keywords file '{path}' not found.")
except Exception as e:
print(f"Error reading keywords file: {e}")仓颉版本:
markdown
public func parse(path: String) {
try {
let filePath: Path = Path(path)
var file: File = File(filePath, Read)
let allBytes = File.readFrom(filePath)
let str = String.fromUtf8(allBytes)
let fields: Array<String> = str.split('\n')
for (field in fields) {
let keyword: String = field
keywords.add(keyword)
}
file.close()
} catch(e: Exception) {
println("Warning: Keywords file '${path}' not found or error reading file.")
}
}差异分析:
- Python使用
with语句自动管理文件资源,更简洁 - 仓颉需要手动创建File对象并关闭文件
- Python逐行读取更节省内存
- 仓颉一次性读取整个文件到内存
- Python的字符串处理更简洁(
strip().lower()) - 仓颉需要显式的字节到字符串转换
文本过滤逻辑
Python版本:
python
def filter(self, message, repl="*"):
if not isinstance(message, str):
message = str(message)
message = message.lower()
for kw in self.keywords:
message = message.replace(kw, repl)
return message仓颉版本:
markdown
public func filter(message: String): String {
let repl: String = "*"
let mutableMessage = StringBuilder(message)
for (keyword in keywords) {
let originalMessage = mutableMessage.toString()
let filteredMessage = originalMessage.replace(keyword, repl)
mutableMessage.reset()
mutableMessage.append(filteredMessage)
}
return mutableMessage.toString()
}差异分析:
- Python直接修改字符串变量,更简洁
- 仓颉使用StringBuilder来处理字符串修改,可能更高效
- Python自动处理类型转换
- 仓颉需要显式使用StringBuilder进行字符串操作
- Python支持默认参数,仓颉不支持
性能测试实现
Python版本:
python
def test_naive_filter_performance(test_messages, keywords_file="keywords.txt"):
filter_instance = NaiveFilter()
load_start = time.time()
filter_instance.parse(keywords_file)
load_time = time.time() - load_start
total_time = 0
start_time = time.time()
for i, message in enumerate(test_messages):
filter_instance.filter(message)
total_time += time.time() - start_time
avg_time = total_time / len(test_messages)
return {
'load_time': load_time,
'total_time': total_time,
'avg_time': avg_time
}仓颉版本:
markdown
struct FilterTestResult {
let loadTime: Duration
let totalTime: Duration
let avgTime: Duration
public init(loadTime: Duration, totalTime: Duration, avgTime: Duration) {
this.loadTime = loadTime
this.totalTime = totalTime
this.avgTime = avgTime
}
}
func testNaiveFilterPerformance(testMessages: ArrayList<String>) {
let keywordsFile: String = "keywords.txt"
let filterInstance = NaiveFilter()
let loadStartTime = DateTime.now()
filterInstance.parse(keywordsFile)
let loadTime = (DateTime.now() - loadStartTime)
let startTime = DateTime.now()
for (i in 0..testMessages.size) {
let message = testMessages[i]
_ = filterInstance.filter(message)
}
let totalTime = (DateTime.now() - startTime)
let avgTime = totalTime / testMessages.size
return FilterTestResult(loadTime, totalTime, avgTime)
}差异分析:
- Python使用字典返回多个值,更灵活
- 仓颉定义了专门的结构体来返回结果,类型更安全
- Python的时间计算使用简单的浮点数
- 仓颉使用Duration类型,更精确和类型安全
- Python的循环语法更简洁(enumerate)
- 仓颉的循环需要显式索引范围
数据结构使用
Python版本:
python
self.keywords = set() # 使用内置的set类型
test_messages = [...] # 使用list仓颉版本:
markdown
var keywords: Set<String> = HashSet<String>() # 明确指定泛型类型
var testMessages = ArrayList<String>() # 使用ArrayList差异分析:
- Python的集合类型更简洁,类型推断自动
- 仓颉需要显式指定泛型类型,更严格
- 仓颉的类型系统更接近静态类型语言
代码量对比
完整的Python版本代码
python
import time
class NaiveFilter():
def __init__(self):
self.keywords = set()
def parse(self, path):
try:
with open(path, 'r', encoding='utf-8') as f:
for keyword in f:
self.keywords.add(keyword.strip().lower())
except FileNotFoundError:
print(f"Warning: Keywords file '{path}' not found.")
except Exception as e:
print(f"Error reading keywords file: {e}")
def filter(self, message, repl="*"):
if not isinstance(message, str):
message = str(message)
message = message.lower()
for kw in self.keywords:
message = message.replace(kw, repl)
return message
def test_naive_filter_performance(test_messages, keywords_file="keywords.txt"):
filter_instance = NaiveFilter()
load_start = time.time()
filter_instance.parse(keywords_file)
load_time = time.time() - load_start
total_time = 0
start_time = time.time()
for i, message in enumerate(test_messages):
filter_instance.filter(message)
total_time += time.time() - start_time
avg_time = total_time / len(test_messages)
return {
'load_time': load_time,
'total_time': total_time,
'avg_time': avg_time
}
if __name__ == "__main__":
print("="*30 + "NaiveFilter性能测试" + "="*30)
test_messages = [
"这里有一些测试词汇:管理员 超级用户 系统权限 后台入口 数据库连接",
"这是一个正常的句子,不包含敏感词汇。",
"测试英文词汇:admin root password private secret confidential",
"混合语言测试:这是一个包含english词汇的测试句子,用来验证过滤功能。",
"这是一个很长的测试句子,用来测试过滤器在处理长文本时的性能表现。" * 10,
"测试特殊字符:@#$%^&*()_+-={}[]|\\:;\"'<>?,./",
"技术术语测试:API接口 SQL注入 XSS攻击 CSRF防护 OAuth认证 JWT令牌",
"这是一个包含英文的句子: hello world, how are you today?",
"测试数字和符号:123456 7890 !@# $%^ &*()",
"这是一个正常的测试句子,用来验证过滤器的准确性。"
] * 50
try:
result = test_naive_filter_performance(test_messages)
print(f"\n{'='*60}")
print("NaiveFilter性能测试结果")
print(f"{'='*60}")
print(f"{'指标':<25} {'加载时间(s)':<12} {'总耗时(s)':<12} {'平均耗时(s)':<12}")
print("-" * 70)
print(f"{'NaiveFilter':<25} {result['load_time']:<12.6f} "
f"{result['total_time']:<12.6f} {result['avg_time']:<12.6f}")
if result['avg_time'] > 0:
print(f"\n测试完成!NaiveFilter平均耗时: {result['avg_time']:.6f} 秒")
else:
print("\n测试完成!执行时间过短,无法准确测量性能")
except Exception as e:
print(f"测试 NaiveFilter 时出错: {e}")
print(f"\n测试完成!")完整的仓颉版本代码
plain
package cangjie
import std.collection.*
import std.fs.*
import std.time.*
class NaiveFilter {
var keywords: Set<String> = HashSet<String>()
public init() {}
public func parse(path: String) {
try {
let filePath: Path = Path(path)
var file: File = File(filePath, Read)
let allBytes = File.readFrom(filePath)
let str = String.fromUtf8(allBytes)
let fields: Array<String> = str.split('\n')
for (field in fields) {
let keyword: String = field
keywords.add(keyword)
}
file.close()
} catch(e: Exception) {
println("Warning: Keywords file '${path}' not found or error reading file.")
}
}
public func filter(message: String): String {
let repl: String = "*"
let mutableMessage = StringBuilder(message)
for (keyword in keywords) {
let originalMessage = mutableMessage.toString()
let filteredMessage = originalMessage.replace(keyword, repl)
mutableMessage.reset()
mutableMessage.append(filteredMessage)
}
return mutableMessage.toString()
}
}
struct FilterTestResult {
let loadTime: Duration
let totalTime: Duration
let avgTime: Duration
public init(loadTime: Duration, totalTime: Duration, avgTime: Duration) {
this.loadTime = loadTime
this.totalTime = totalTime
this.avgTime = avgTime
}
}
func testNaiveFilterPerformance(testMessages: ArrayList<String>) {
let keywordsFile: String = "keywords.txt"
let filterInstance = NaiveFilter()
let loadStartTime = DateTime.now()
filterInstance.parse(keywordsFile)
let loadTime = (DateTime.now() - loadStartTime)
let startTime = DateTime.now()
for (i in 0..testMessages.size) {
let message = testMessages[i]
_ = filterInstance.filter(message)
}
let totalTime = (DateTime.now() - startTime)
let avgTime = totalTime / testMessages.size
return FilterTestResult(loadTime, totalTime, avgTime)
}
main() {
println("==============NaiveFilter性能测试==============")
let baseMessages = [
"这里有一些测试词汇:管理员 超级用户 系统权限 后台入口 数据库连接",
"这是一个正常的句子,不包含敏感词汇。",
"测试英文词汇:admin root password private secret confidential",
"混合语言测试:这是一个包含english词汇的测试句子,用来验证过滤功能。",
"这是一个很长的测试句子,用来测试过滤器在处理长文本时的性能表现。" + "这是一个很长的测试句子,用来测试过滤器在处理长文本时的性能表现。" + "这是一个很长的测试句子,用来测试过滤器在处理长文本时的性能表现。" + "这是一个很长的测试句子,用来测试过滤器在处理长文本时的性能表现。" + "这是一个很长的测试句子,用来测试过滤器在处理长文本时的性能表现。" + "这是一个很长的测试句子,用来测试过滤器在处理长文本时的性能表现。" + "这是一个很长的测试句子,用来测试过滤器在处理长文本时的性能表现。" + "这是一个很长的测试句子,用来测试过滤器在处理长文本时的性能表现。" + "这是一个很长的测试句子,用来测试过滤器在处理长文本时的性能表现。" + "这是一个很长的测试句子,用来测试过滤器在处理长文本时的性能表现。",
"测试特殊字符:@#$%^&*()_+-={}[]|\\:;\"'<>?,./",
"技术术语测试:API接口 SQL注入 XSS攻击 CSRF防护 OAuth认证 JWT令牌",
"这是一个包含英文的句子: hello world, how are you today?",
"测试数字和符号:123456 7890 !@# $%^ &*()",
"这是一个正常的测试句子,用来验证过滤器的准确性。"
]
// 重复消息以增加测试数据量
var testMessages = ArrayList<String>()
for ( _ in 0..50) {
testMessages.add(all: baseMessages)
}
// 测试NaiveFilter过滤器
try {
let result = testNaiveFilterPerformance(testMessages)
// 性能测试结果
println("\n============================================================")
println("NaiveFilter性能测试结果")
println("============================================================")
println("指标 加载时间(s) 总耗时(s) 平均耗时(s)")
println("----------------------------------------------------------------------")
println("NaiveFilter ${result.loadTime} ${result.totalTime} ${result.avgTime}")
if (result.avgTime > Duration.Zero) {
println("\n测试完成!NaiveFilter平均耗时: ${result.avgTime} 秒")
} else {
println("\n测试完成!执行时间过短,无法准确测量性能")
}
} catch (e: Exception) {
println("测试 NaiveFilter 时出错: ${e}")
}
println("\n测试完成!")
}对比后可以发现Python版本仅需要82行代码即可实现全部功能,而仓颉版本需要124行才能实现全部功能,两者相差不大,因为语言的特性,例如仓颉对于结构类型的数据需要单独定义其结构所以代码量上可能会更多一些,但是这个对比的价值不是很高,因为换行符等其他因素影响。
性能对比
Python版本:
- 使用内置set和字符串操作,性能良好
- 逐行读取文件,内存效率高
- 字符串不可变性可能导致额外内存分配
仓颉版本:
- 使用StringBuilder进行字符串操作,可能更高效
- 一次性读取文件,可能消耗更多内存
- 静态类型有助于编译器优化
实际性能测试结果对比:
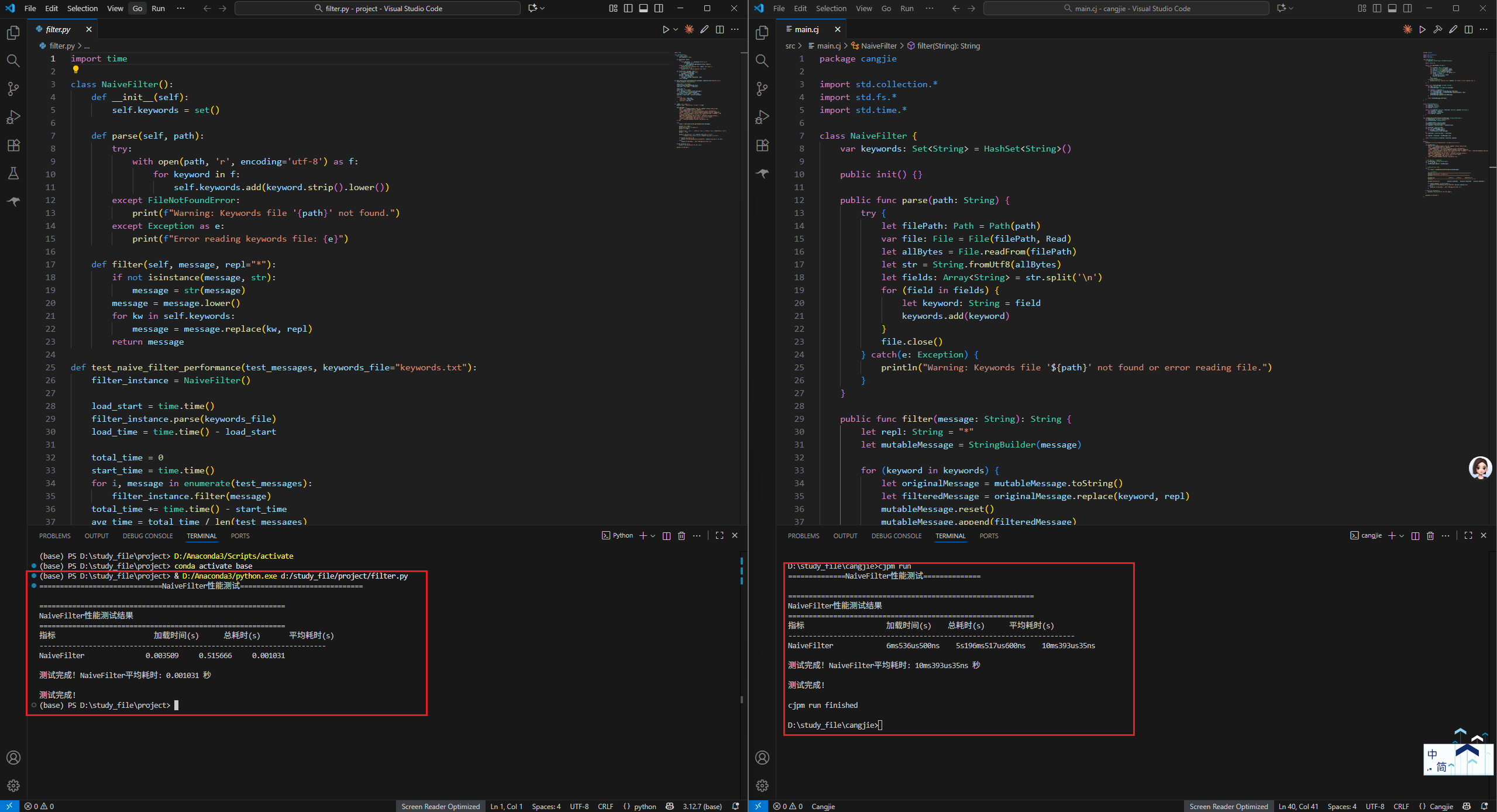
两种版本的时间输出格式不统一,还望见谅,仓颉版本只找到了上述的时间输出(后续再研究研究)
从两者的加载时间可以看出来,Python版本用时3.509毫秒,仓颉版本用时6.536毫秒,仓颉版本的用时是Python版本的两倍左右。
从总耗时来看,Python版本用时0.5156秒,仓颉版本用时5.196秒,Python版本比仓颉版本快了10倍。
尽管仓颉的用时比Python要慢一些,但是仓颉对于数据类型更加严格,更加规范,例如代码中存在不规范的写法时,编译时虽然不会报错,但是会进行warning提醒,如下:
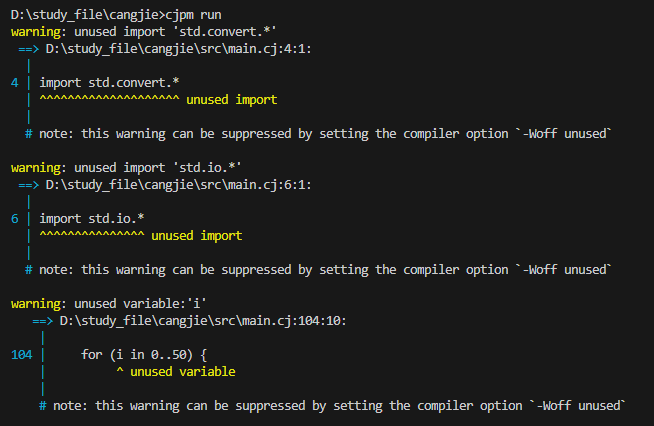
就我个人而言,还是非常喜欢这种做法的,严格规范代码格式,对个人,对团队来说都是利远大于弊。
代码风格和可读性对比
Python风格特点:
- 简洁明了,代码行数较少
- 动态类型,灵活性高
- 内置函数丰富,如
strip(),lower() - 异常处理更精细(FileNotFoundError vs Exception)
- 字符串插值使用f-string
仓颉风格特点:
- 类型安全,编译时检查
- 语法更接近传统静态语言(Java/C#)
- 需要显式类型声明
- 使用结构体封装数据,更规范
- 字符串插值使用
${}语法
踩坑点
官方文档给出的教程、示例都比较完善,这次就只踩到了一个坑:

项目的路径一定不要存在中文,不然运行的时候会报错,提示:Invalid utf8 byte sequence.
感兴趣的可以多去官方文档学习一下,下面附上一些官方提供的学习资料:
仓颉开源仓库:https://gitcode.com/cangjie
仓颉官方文档:https://cangjie-lang.cn/docs
仓颉开源三方库:https://gitcode.com/cangjie-tpc
仓颉编程语言白皮书:https://developer.huawei.com/consumer/cn/doc/cangjie-guides-V5/cj-wp-abstract-V5
三、总结
这次的迁移给我带来了很大的收货,不仅仅是对仓颉编程语言的了解,也是对不同编程语言之间的差异有了更深层次的认识。每一门编程语言都有属于其专属的领域,只有在特定的场景下使用最合适的语言,才会得到效率的最大化。仓颉给我印象深刻的就是其类型的标注,使其可以胜任更多的需要类型安全和性能优化的场景,仓颉更适合大型项目、系统级编程。
最后,希望众多的优秀开发者可以更多的关注一下国产编程语言,更多的关注一下仓颉,为仓颉的生态建设贡献自己的力量!