一场开源与闭源的较量再次迎来转折点。
在AI模型快速迭代的竞技场上,开源与闭源之间你追我赶,但两者之间的差距一度被认为是难以逾越的鸿沟。然而,最新发布的Kimi K2 Thinking再次打破了鸿沟。
今天凌晨,月之暗面正式发布并开源了Kimi K2 Thinking模型,发布不到24小时,它已经被誉为 "迄今能力最强的开源思考模型" ,在多项关键基准测试中超越了GPT-5和Claude Sonnet 4.5等顶尖闭源模型。

更有网友再次放出了那张"经典梗图":

全面超越的技术表现
在被称为"人类最后考试"的HLE基准测试中,Kimi K2 Thinking在使用工具的条件下取得了44.9%的高分,创造了新的SOTA纪录。
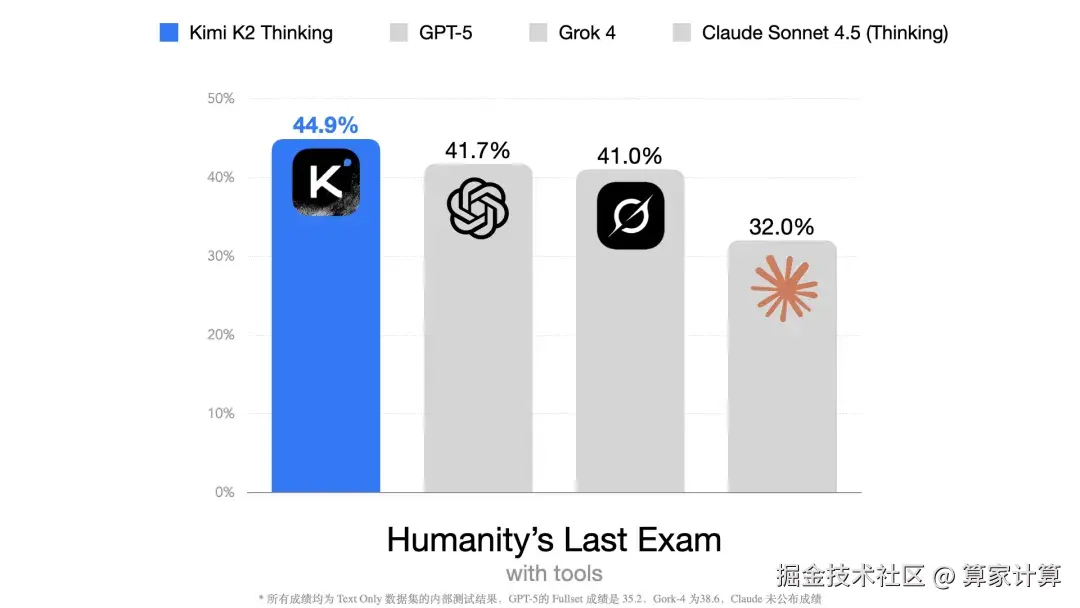
在另一项衡量网络搜索和推理能力的BrowseComp测试中,它的表现更为突出,达到了60.2%的得分,远超人类平均29.2%的水平,同时也超过了GPT-5的54.9%和Claude 4.5的24.1%。
在编程能力方面,Kimi K2 Thinking在SWE-bench Verified和LiveCodeBench v6两个编码评估中分别获得71.3%和83.1%的分数,展现出与顶尖闭源模型相抗衡的实力。
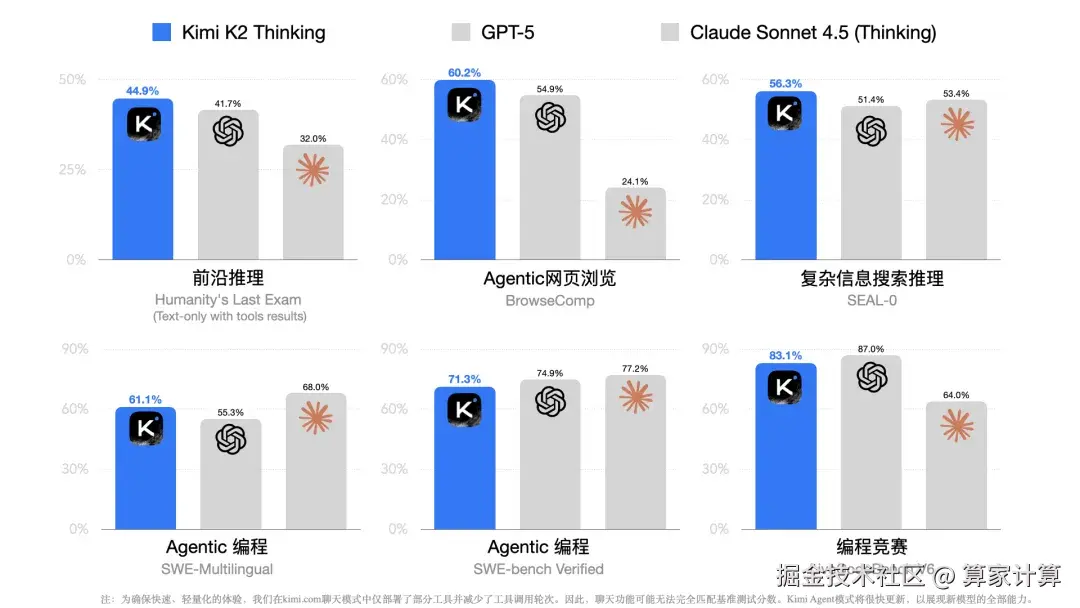
这意味着,开源模型不仅在追赶闭源模型,更在复杂的推理和工具使用任务中实现了反超。
架构创新的核心驱动力
Kimi K2 Thinking的技术突破源于其创新的模型架构。作为一个混合专家模型,它拥有1万亿的总参数 ,每次推理激活320亿参数。
模型采用INT4量化而非行业常见的FP8,这使得生成速度提升了约2倍,同时增强了对国产加速计算芯片的兼容性。
同时,该模型拥有256K的上下文窗口,结合"测试时扩展"技术,通过同时扩展思考Token和工具调用轮次,实现了更强的Agent和推理性能。
这种架构设计使得模型能够执行200-300次连续工具调用而无需人工干预,展现出真正的自主推理能力。
开源战略的加速度
Kimi K2 Thinking采用最为宽松的MIT协议,允许免费商业使用,仅在大规模部署时要求显示"Kimi K2"标识。
在定价策略上,其定价为缓存命中时0.15美元/百万Token ,缓存未命中时0.6美元/百万Token ,输出为2.5美元/百万Token。
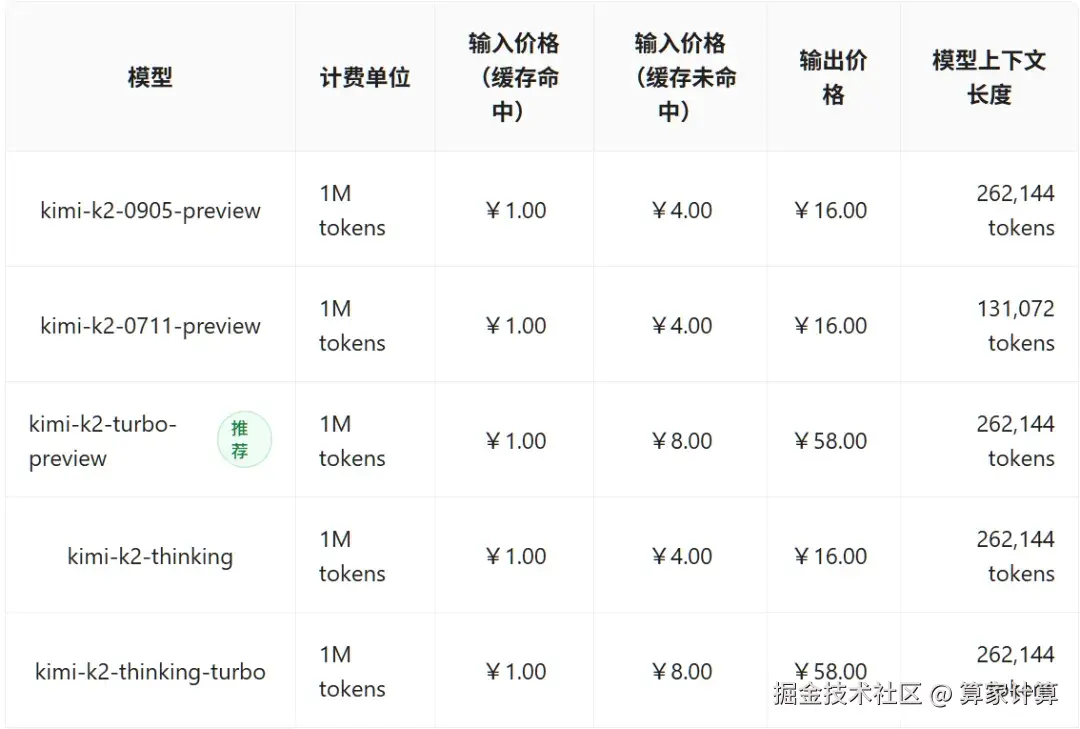
这一价格不仅远低于GPT-5的1.25美元输入和10美元输出定价,也低于MiniMax-M2的0.3美元输入和1.2美元输出定价。
低成本高性能的组合,使得像Kimi K2 Thinking这样的顶尖开源模型能够普惠全球开发者,为全球大模型创新生态带来巨大红利。
从技术追赶到实现反超,开源模型正以前所未有的速度缩短与闭源模型的差距。
Kimi K2 Thinking的成功不是孤例,它反映的是中国AI产业开源战略的集体加速度。在Hugging Face的大模型开源趋势榜单上,前10名全都是中国的开源模型。
李开复在近期的一次演讲中指出,世界大模型竞赛中只有中美两国,而竞争关键正是"开源与闭源的路线之争"。
Kimi K2 Thinking的突破不仅是一个产品的成功,更是开源发展路径的有力验证。
随着开源模型的不断成熟和算力成本的下降,AI技术将更加深入地渗透到各个行业。
当AI技术真正实现普惠,当每一个企业都能以合理成本获得顶尖的AI能力,我们将会见证一场前所未有的产业变革。
大家怎么看?欢迎交流讨论~