目录
摘要
今天深入学习了K-means算法的数学原理和优化过程。通过分析成本函数的构成,我理解了算法如何通过交替优化聚类分配和中心位置来最小化平方距离。具体来说,第一步是将每个点分配到最近的聚类中心,第二步是重新计算聚类中心为所属点的平均值。这种迭代过程能保证成本函数持续下降直至收敛,让我对算法的内在机制有了更清晰的认识。
Abstract
Today's lesson delved into the mathematical foundation of the K-means algorithm and its optimization process. By examining the cost function composition, I learned how the algorithm minimizes squared distances through alternating optimization of cluster assignments and centroid positions. The first step assigns points to nearest centroids, while the second recalculates centroids as the mean of assigned points. This iterative process ensures consistent reduction of the cost function until convergence, providing deeper insight into the algorithm's internal mechanics.
一、优化目标
在我们之前学习的过程中,我们看到了许多监督学习算法,它们使用训练集,提出一个代价函数,然后使用梯度下降或者其他算法来优化这个代价函数,事实证明,我们在上一段视频中,看到的K均值算法也在优化一个特定的代价函数,尽管它用来优化这个函数的算法不是梯度下降,其实是我们上一节学习的那个算法
让我们看看K均值的代价函数是什么,首先我们复习一下我们学的一些符号
ci是聚类的索引,ci是1到k的某个数字,表示当前分配给训练样本xi的聚类的索引
μk是聚类中心k的位置
μc(i)为样本xi被分配的聚类的中心
例如如果我查看某个训练样本,然后我问,第10个训练样本被分配到的聚类中心的位置是什么,这会给我一个从1到k的数字,告诉我们样本10被分配到了红色还是蓝色或其他聚类中心,然后下标为c10的μ就是样本x10被分配的聚类中心的位置,所以使用这个符号,可以让我们写出k-means正在最小化的成本函数,成本函数j是c1到cm的函数,这些是所有点分配到聚类中心的情况
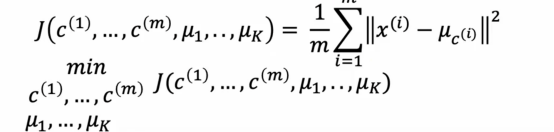
这是平均值,所以除以1/m,从i等于1到m的综合,每个训练样本xi之间的平方距离,这是xi和下标为ci的μ之间的平方距离,所以这里的这个量,换句话说k-means的成本函数是每个训练样本xi与分配给该训练样本xi的聚类中心位置之间的平均平方距离,我们会测量x10和下标为c10的μ之间的距离,也就是x10被分配到的聚类中心,这将是我们在这里的平均的项之一,事实证明k-means算法所做的是试图找到点到聚类中心的分配,以及找到最小化平方距离的聚类中心的位置
二、K-means算法的直观理解
直观上,这是我们在前面视频中K-means算法运行一部分时看到的

在这一步中,成本函数如果我们计算它,会是查看每一个蓝点,测量这些距离并计算平方值,然后同样查看每一个红点,计算这些距离并取平方值
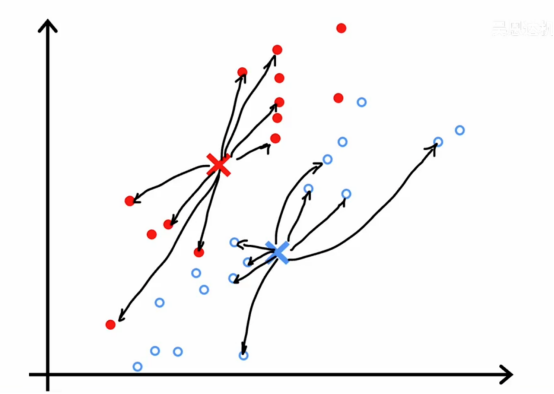
然后红点和蓝点所有这些差异的平方和平均值就是成本的值,在这种特定的参数配置下的k-means算法的代价值,,在每一步中,它会尝试更新这个例子中的聚类分配c1到c30或者更新聚类中心μ1和μ2的位置,以继续减少这个成本函数j
现在让我们更深入的看看这个算法,以及为什么算法试图最小化这个成本函数j,在上面我们复制了刚刚我们说的成本函数

事实证明,k-means的第一部分,实际上是试图更新c1到cm以尽可能最小化成本函数j同时保持μ1到μk固定,即移动聚类中心,实际上是试图保持c1到cm固定,而更新μ1到μk尽可能地最小化成本函数或失真
在第一步,如果我们选择c1到cm的值或保存特定的ci值以尽量减少这个,那么是什么使xi-μci尽可能的小呢
我们知道成本函数是训练样本xi和聚类中心位置之间的距离或者平方距离,所以如果我们想要最小化这个距离或这个平方距离,我们应该做的是将xi分配到最近的聚类中心,为了举一个简化的例子,比如说,聚类中心1和2
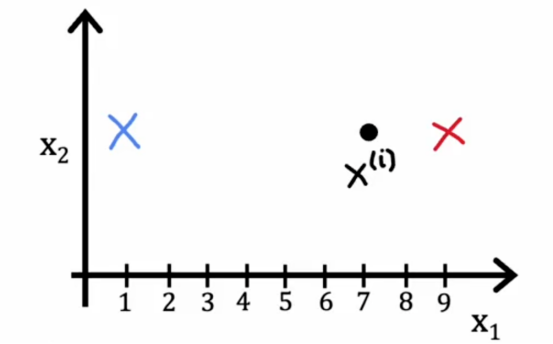
如果我们把它分配到聚类中心1,那么这个平方距离将是这个大距离的平方
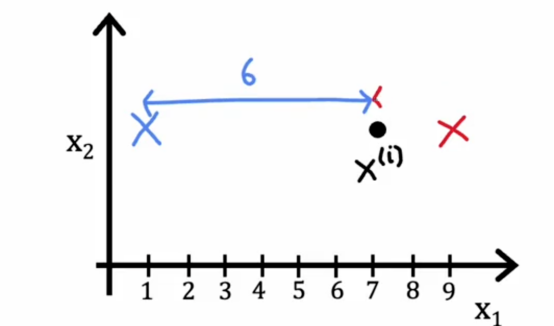
如果我们分配到聚类中心2,那么这个平方的距离将是这个较小的平方距离
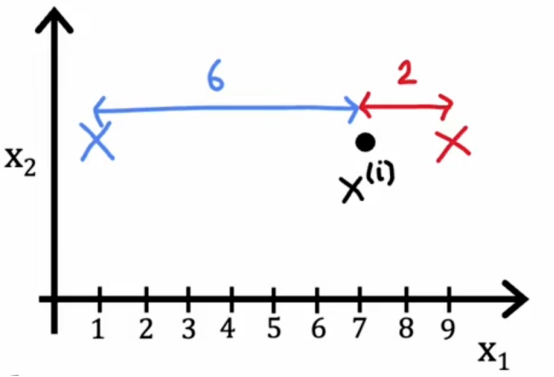
所以如果我们想要最小化这个项,我们会更加趋向把点分配到最近的聚类中心中去,这也正是上面算法所做的事情,因此,这就是为什么在分配点到聚类中心的步骤中是选择ci的值尽可能减少j,而不是改变μ1到μk,仅仅是选择c1到cm的值以尽可能减小这些项
那么k-means算法的第二步呢?
即移动聚类中心,事实证明,选择μk为分配到它的点的平均值或均值是这些项μ的选择,举一个简化的例子,假设我们有一个聚类只有两个点分配给它,如下所示

所以在这里的聚类中心,距离的平均值将是这里的距离1的平方加上这里的距离,即9的平方
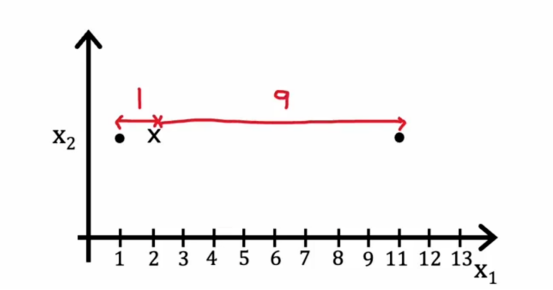
然后我们取这两个数的平均值,所以结果是41,所以我们要移动到1/2*(1+11)中去后,那么这里的距离平均值是5和5
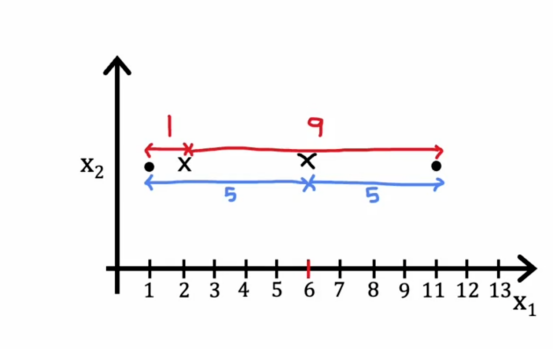
那么得到的数值是25,远远小于42,实际上,我们可以试验聚类中心的位置,并且可能发现取这个位置,在这两个训练示例之间的平均位置,因此k-means算法优化成本函数j的事实意味着它保证收敛,失真成本函数应该降低或者保持不变,但如果它不能减低或者保持不变,在最坏的情况下,如果它提高了,说明代码出现问题了,它不应该永远上升,因此k-means的每一步都在设置ci和μk以试图减少成本,此外,如果成本函数停止下降,一旦有一次迭代爆出不变,这通常意味着k-means已经收敛,我们应该停止算法。
总结
今天的学习让我真正理解了K-means算法背后的数学原理。之前只知道算法步骤,现在明白了每个步骤都是在优化那个平方距离的成本函数。最让我印象深刻的是看到具体数值例子------当聚类中心移动到两个点的中间位置时,成本从41降到了25,这种直观的演示让我理解了为什么取平均值是最优选择。算法保证收敛的特性也很重要,成本函数要么下降要么保持不变,这为我们判断算法何时停止提供了明确依据。通过今天的学习,我不再只是机械地记住算法步骤,而是真正懂了为什么这些步骤能够有效工作,这对后续应用和调试算法都有很大帮助。