u1s1,现在模型能力是Plus了,但Rollout阶段的速度却越来越慢......
于是月之暗面出手了:爆改RL训练速度,让LLM"越跑越快"!
最近月之暗面联合清华大学提出了全新的加速引擎**Seer**,能够在不改变核心训练算法的前提下,大幅度提升LLM的强化学习训练速度。
依托组内上下文设计,可实现同步RL的Rollout效率提升74%~97% ,长尾延迟减少75%~93%。
好好好,几乎是模型换代式的效率提升。

下面来康康详细内容。
跑得更快、更省资源
强化学习目前已成为推动LLM发展的核心技术,但现有系统面临着严重的性能瓶颈。
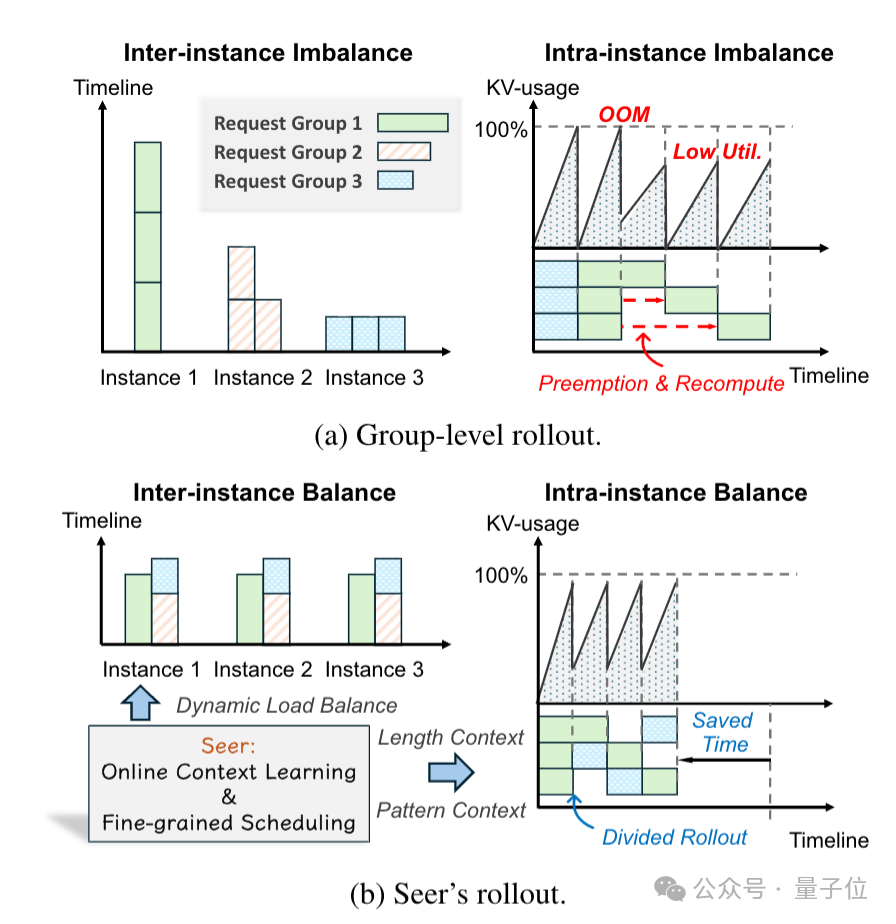
具体来说,就是在端到端迭代过程中,生成阶段(rollout phase)会耗费大量的时间资源,然而该阶段受固有工作负载不均衡的影响,存在明显的长尾延迟问题,且资源利用率较低。
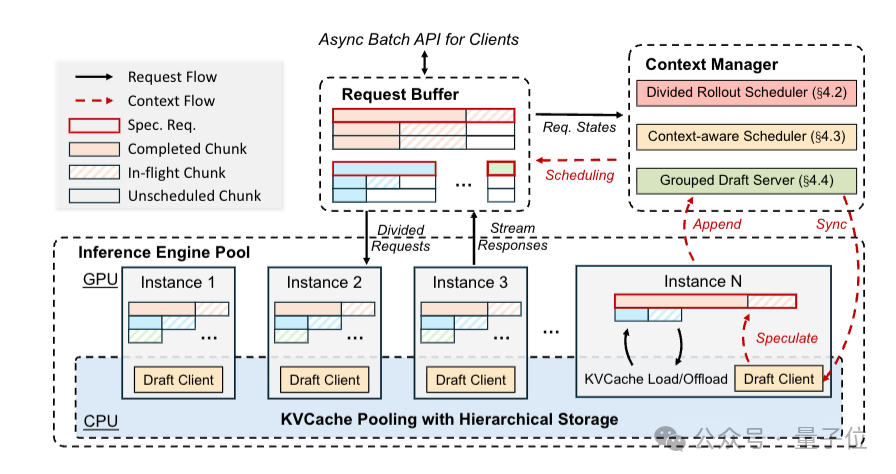
因此研究团队针对性推出了高效同步RL框架**Seer**。
其核心架构包括三大模块:
1、推理引擎池(Inference Engine Pool)
基于DRAM/SSD构建,包括多个推理实例与跨节点的全局KVCache池,不仅可以支持负载均衡,又能通过KVCache池复用中间数据,避免重复计算。
2、请求缓冲区(Request Buffer)
作为所有rollout请求的统一入口,负责维护请求的全量元数据(包括组ID、提示词长度、原始最大生成长度、已生成长度等),并管理请求状态(未调度/处理中/已完成片段),实现资源的精细化调度。
3、上下文管理器(Context Manager)
负责维护所有请求的上下文视图,并基于上下文信号生成调度决策。
另外,Seer还引入了三项关键技术,包括用于动态负载均衡的分段生成、上下文感知调度以及自适应分组推测解码,协同降低长尾延迟和提高资源利用效率。
技术一:分段生成 (Divided Rollout)
针对内存波动与负载失衡,Seer提出"精细化分段+全局KVCache支撑" 的解决方案。
首先是将GRPO中隶属同一提示词的响应拆解为多个独立请求,再将每个请求按照生成长度进一步拆分为多个片段。
然后重新回到请求缓冲区,更新已生成长度,等待后续调度直到生成原始最大长度。
同时为避免重新调度时的提示词编码重计算,Seer复用全局KVCache池,将每个片段的中间数据都存储在共享池中。
这样就能在片段迁移到新实例时,直接从共享池中读取KVCache,而无需重新编码提示词,大幅降低迁移开销。
技术二:上下文感知调度 (Context-Aware Scheduling)
为了解决调度失衡、长请求延迟导致的长尾问题,Seer使用"先探路+后调度"的策略。
先为每个提示词组指定第一个响应为投机请求(speculative request),优先获取该组的长度特征,再基于特征调度剩余请求,避免长请求被保留到最后。
技术三:自适应分组推测解码 (Adaptive Grouped Speculative Decoding)
由于传统推测解码依赖静态小模型生成草稿,无法适配RL中目标模型的迭代更新,Seer利用组内响应模式相似的特性,通过DGDS(分布式分组草稿服务器)聚合组内所有响应的token序列,构建动态模式参考库。
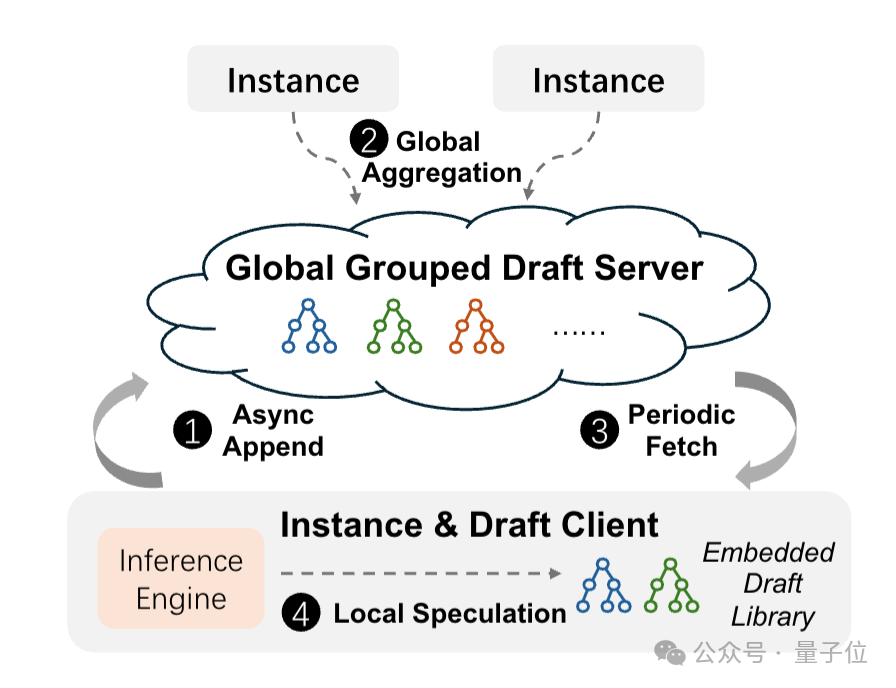
然后基于参考库生成草稿,就能削减额外模型开销,并随着组内响应的增加进一步提升草稿质量。
最终依靠三者的协同作用,既能保障同步RL的算法保真度,又可从内存、调度、推理三个维度全面优化rollout效率。
实验验证
为了验证系统性能,研究团队选取Moonlight 、Qwen2-VL-72B 、Kimi-K2三个模型,均采用GRPO算法训练,并将veRL(同步RL系统,支持训练与rollout协同部署)作为基线系统进行对比。
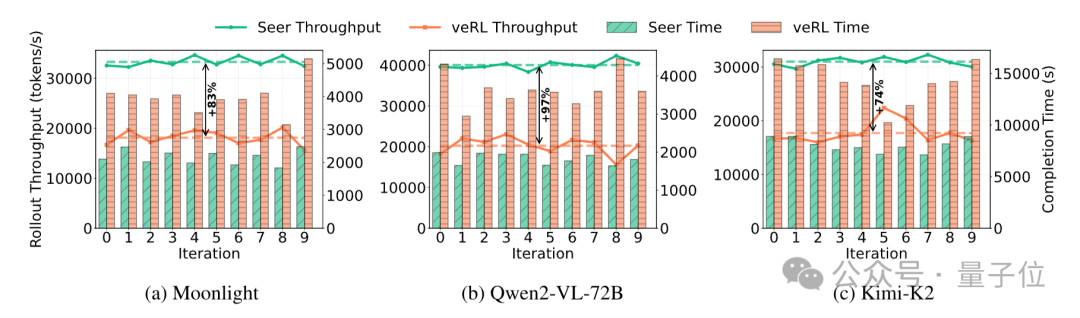
在端到端性能验证上,实验结果发现Seer在不同工作负载中均实现性能突破,其中吞吐量可提升74%~97%,显著高于veRL,且稳定性更强。
而veRL的长尾延迟则相当严重,例如在Moonlight任务中,veRL最后10%请求需耗时3984秒(占总时长约50%),而Seer仅需364秒,长尾延迟可实现降低85%。
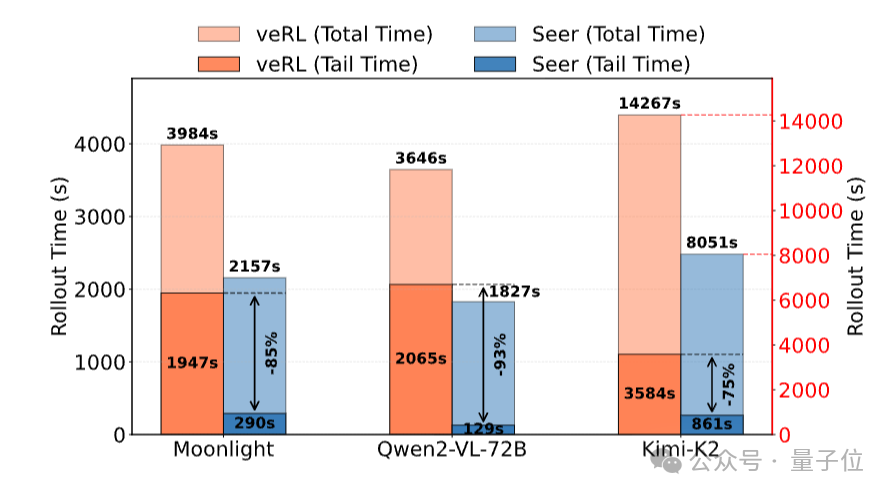
此外,Qwen2-VL-72B任务中可降低93%,Kimi-K2任务降低75%。
研究团队还对Seer的核心创新点(上下文感知调度、分组推测解码)进行了专项实验。
先是在Qwen2-VL-72B任务的第5次迭代中,设置三组对比:
- No-Context:仅分段生成,无长度预测。
- Context-Aware:Seer的调度策略。
- Oracle:提前知道所有请求的真实长度,执行理想LFS调度。
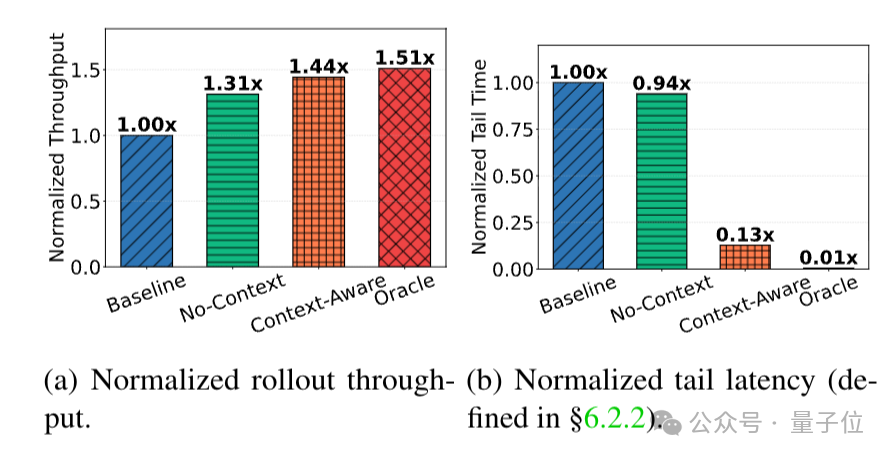
结果表明,在吞吐量上Context-Aware可达到Oracle的95%,远高于No-Context;在长尾延迟上,Context-Aware也仅为No-Context的13%,接近Oracle。
说明基于组内长度上下文的调度,虽无法达到理想Oracle水平,但已能大幅缓解长尾问题,且无需提前知道真实长度,实用性较强。
然后同样是在Qwen2-VL-72B任务中,设置四组对比推测解码的有效性:
- No-SD:无推测解码。
- No-Context:有推测解码,但不聚合组内模式。
- No-Adapt:有组模式,但固定推测参数。
- Seer:完整分组推测解码。
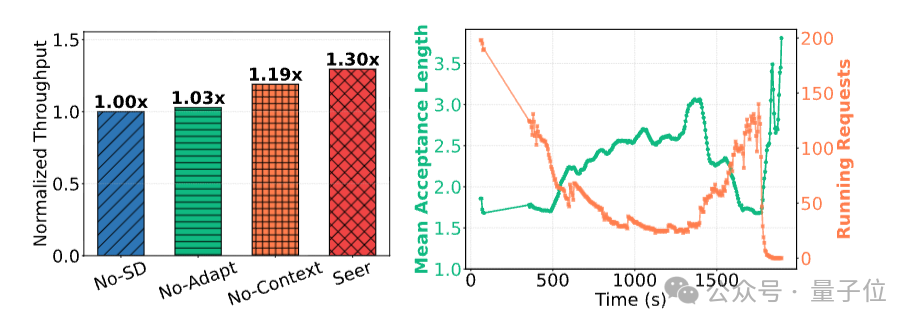
结果显示,Seer在吞吐量上远高于No-Context与No-Adapt,Seer的接受长度也随rollout推进而动态提升,证明了只有组内模式上下文 和自适应参数相互结合才能最大化推测解码的效率。
One More Thing
另外,有消息称,月之暗面即将完成新一轮融资,融资金额将高达数亿美元。
本轮融资一旦完成,该公司估值将提升至40亿美元。

目前月之暗面正在积极与IDG Capital等在内的投资机构进行融资洽谈,其中潜在投资方还包括现有股东腾讯。
消息还称,预期计划将在今年年底前完成该轮融资,并在明年下半年启动IPO进程。