1. 前言
本文介绍的内容主要基于InnoDB引擎的MySQL,全文相对内容较多。
你可以根据目录跳到你需要的部分,详细大概可以参考文章目录。
在日常的数据库运维和开发工作中,你是否曾困惑于以下现象?
- 明明通过
DELETE语句删除了大量"过期"数据,但服务器的磁盘空间并未如预期般释放,反而可能持续增长。 - 一个核心业务表的简单查询,在数据量没有显著变化的情况下,响应速度却越来越慢,但检查索引却又一切正常。
- 使用
SHOW TABLE STATUS命令查看,发现表的Data_free字段显示了一个巨大的数值,远远超出了你的理解。
这些看似诡异的问题,其幕后元凶往往就是"数据碎片"。碎片是数据库在长期运行后的一种自然现象,但它就像一个隐形的性能杀手,悄无声息地消耗着你的磁盘空间,拖慢你的查询效率。
阅读完本文,你将系统性地收获以下核心知识:
- MySQL数据表存储文件的结构
- 数据记录删除流程
- 什么是数据库表碎片
- 如何解决数据磁盘碎片问题
2. MySQL数据表是怎么存储的
要深入理解数据碎片,我们首先需要了解MySQL数据表的物理存储结构。MySQL使用多种不同类型的文件来存储数据库的各个组成部分,每种文件都有其特定的功能和重要性。
2.1 MySQL数据库文件类型全解析
2.1.1 核心文件类型及其作用
不同系统mysql位置不一样,可以自行科学上网
sql
-- MySQL数据目录典型结构
/var/lib/mysql/
├── database_name/
│ ├── table_name.frm # 表结构定义文件(MySQL 8.0前)
│ ├── table_name.ibd # InnoDB表数据和索引文件
│ ├── table_name.MYD # MyISAM表数据文件
│ └── table_name.MYI # MyISAM表索引文件
├── mysql/ # 系统数据库
├── ibdata1 # 共享表空间文件(可选)
├── ib_logfile0 # InnoDB重做日志
├── ib_logfile1 # InnoDB重做日志
└── error.log # 错误日志文件2.1.2 .frm文件:表结构定义
sql
-- MySQL 8.0之前版本的存储方式
-- 每个表对应一个.frm文件,存储表的结构信息
-- 示例:查看.frm文件内容(需要使用特殊工具)
-- 文件包含:列定义、索引信息、字符集、存储引擎等元数据
-- MySQL 8.0的变革:表结构信息移入数据字典
SELECT * FROM information_schema.TABLES WHERE TABLE_NAME = 'your_table';
SELECT * FROM information_schema.COLUMNS WHERE TABLE_NAME = 'your_table';2.1.3 .ibd文件:InnoDB独立表空间
sql
-- 当innodb_file_per_table=ON时,每个InnoDB表有自己的.ibd文件
SHOW VARIABLES LIKE 'innodb_file_per_table';
-- .ibd文件包含:
-- 1. 表数据(行记录)
-- 2. 聚簇索引(主键索引)
-- 3. 二级索引
-- 4. 插入缓冲位图等元数据2.1.4 .MYD和.MYI文件:MyISAM存储引擎
sql
-- MyISAM表使用三个独立文件:
-- table_name.frm:表结构
-- table_name.MYD:表数据(Data)
-- table_name.MYI:表索引(Index)
-- 创建MyISAM表示例
CREATE TABLE myisam_table (
id INT PRIMARY KEY,
data VARCHAR(100)
) ENGINE=MyISAM;2.1.5 日志文件
sql
-- 错误日志:记录启动、运行、停止过程中的错误信息
SHOW VARIABLES LIKE 'log_error';
-- 二进制日志:用于复制和恢复
SHOW VARIABLES LIKE 'log_bin';
-- 慢查询日志:记录执行缓慢的查询
SHOW VARIABLES LIKE 'slow_query_log';2.2 MySQL 8.0 文件结构实际案例
mysql目录下的文件结构:
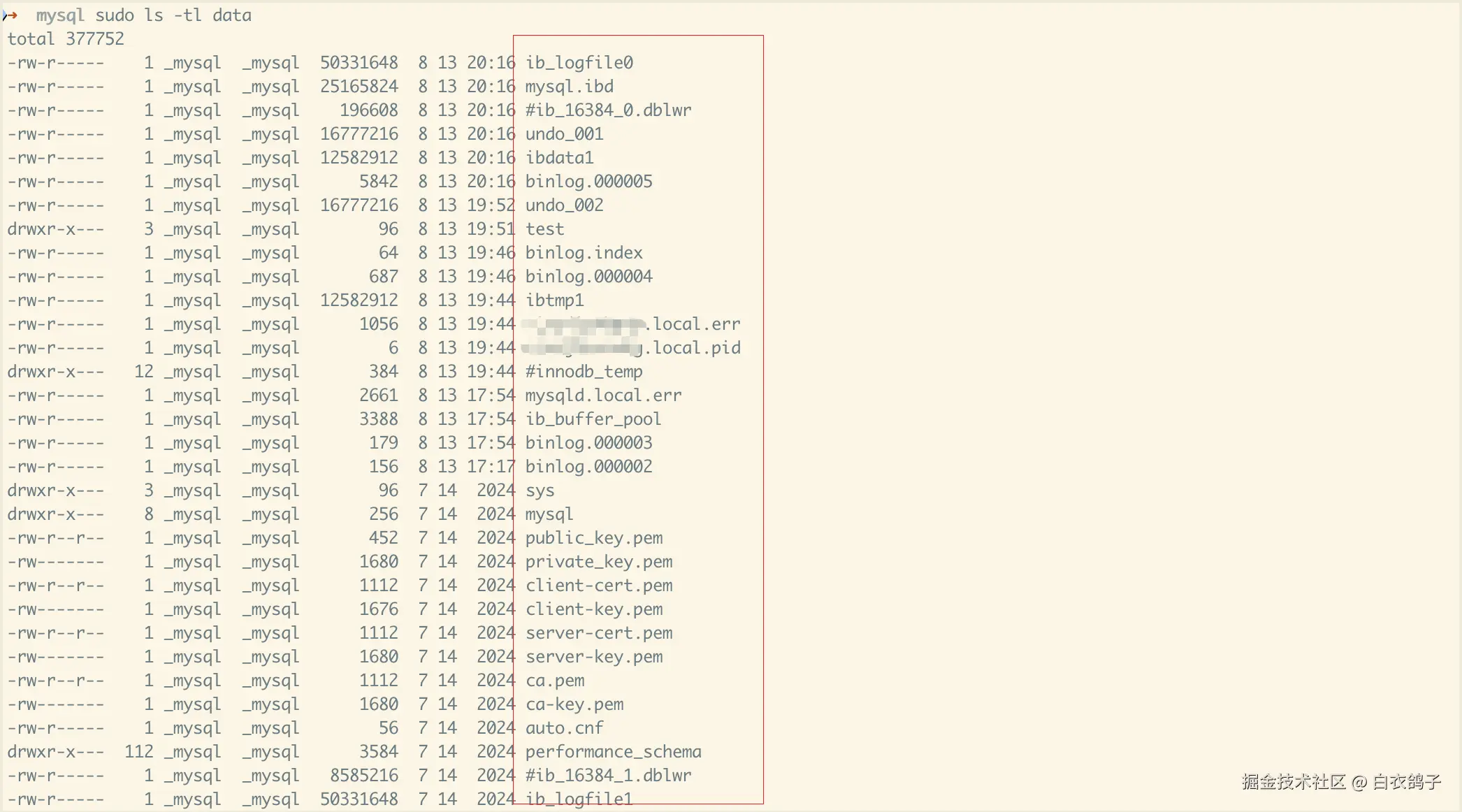
2.2.1 核心系统文件
yaml
-rw-r----- 1 _mysql _mysql 12582912 8 13 20:16 ibdata1 # 共享表空间文件
-rw-r----- 1 _mysql _mysql 50331648 8 13 20:16 ib_logfile0 # 重做日志文件0
-rw-r----- 1 _mysql _mysql 50331648 7 14 2024 ib_logfile1 # 重做日志文件1
-rw-r----- 1 _mysql _mysql 25165824 8 13 20:16 mysql.ibd # 系统表空间(数据字典)
-rw-r----- 1 _mysql _mysql 12582912 8 13 19:44 ibtmp1 # 临时表空间2.2.2 数据库目录
yaml
drwxr-x--- 3 _mysql _mysql 96 8 13 19:51 test # test数据库
drwxr-x--- 12 _mysql _mysql 384 8 13 19:44 #innodb_temp # InnoDB临时表空间目录
drwxr-x--- 3 _mysql _mysql 96 7 14 2024 sys # sys系统数据库
drwxr-x--- 8 _mysql _mysql 256 7 14 2024 mysql # mysql系统数据库
drwxr-x--- 112 _mysql _mysql 3584 7 14 2024 performance_schema # 性能模式数据库2.2.3 二进制日志文件
diff
-rw-r----- 1 _mysql _mysql 5842 8 13 20:16 binlog.000005 # 当前二进制日志
-rw-r----- 1 _mysql _mysql 687 8 13 19:46 binlog.000004 # 之前的二进制日志
-rw-r----- 1 _mysql _mysql 179 8 13 17:54 binlog.000003
-rw-r----- 1 _mysql _mysql 156 8 13 17:17 binlog.000002
-rw-r----- 1 _mysql _mysql 64 8 13 19:46 binlog.index # 二进制日志索引2.2.4 其他重要文件
yaml
-rw-r----- 1 _mysql _mysql 196608 8 13 20:16 #ib_16384_0.dblwr # 双写缓冲文件
-rw-r----- 1 _mysql _mysql 8585216 7 14 2024 #ib_16384_1.dblwr # 双写缓冲文件
-rw-r----- 1 _mysql _mysql 16777216 8 13 20:16 undo_001 # 撤销日志001
-rw-r----- 1 _mysql _mysql 16777216 8 13 19:52 undo_002 # 撤销日志002
-rw-r----- 1 _mysql _mysql 1056 8 13 19:44 xianjianhang.local.err # 错误日志
-rw-r----- 1 _mysql _mysql 6 8 13 19:44 xianjianhang.local.pid # 进程ID文件
-rw-r----- 1 _mysql _mysql 2661 8 13 17:54 mysqld.local.err # 旧的错误日志
-rw-r----- 1 _mysql _mysql 3388 8 13 17:54 ib_buffer_pool # 缓冲池状态2.2.5 数据库表文件

这里比较简单,只有一个.ibd数据文件,存储了数据表的数据和索引。
2.3 关于InoDB共享表空间的说明
2.3.1 传统共享表空间模式
(MySQL 5.5及之前)innodb_file_per_table = OFF 默认
sql
-- MySQL 5.5及之前版本的默认配置
SET GLOBAL innodb_file_per_table = OFF;- 所有表数据堆积在单个ibdata1文件中
- 删除表不会释放磁盘空间,空间只能被新数据重用
- 无法单独备份或移动特定表
- 文件容易变得巨大,影响IO性能
存储结构:
sql
ibdata1 文件内容(传统OFF模式):
├── 系统数据区域
│ ├── 数据字典(Data Dictionary)
│ ├── 双写缓冲(Double Write Buffer)
│ ├── 撤销日志(Undo Logs)
│ └── 插入缓冲(Insert Buffer)
└── 所有用户表的数据和索引
├── 用户表1的完整数据
├── 用户表2的完整数据
├── 用户表3的完整数据
└── ...所有其他表文件系统表现:
bash
/var/lib/mysql/
├── database1/
│ ├── table1.frm # 只有表结构文件
│ ├── table2.frm
│ └── table3.frm
└── ibdata1 # 包含所有表的数据和索引(可能很大)2.3.2 现代混合模式
(MySQL 5.6+) innodb_file_per_table = ON 默认
sql
-- MySQL 5.6.6+的默认配置
SET GLOBAL innodb_file_per_table = ON;- 用户表数据独立存储 :每个业务表有自己的
.ibd文件 - 灵活管理:可以单独备份、移动、压缩单个表
- 空间可回收 :删除表后,对应的
.ibd文件被删除,空间立即释放
存储结构详细说明:
vbnet
ibdata1 文件内容(现代ON模式):
├── 核心系统功能
│ ├── 双写缓冲(Double Write Buffer)
│ ├── 撤销日志(Undo Logs)
│ └── 变更缓冲(Change Buffer)
└── 系统表空间元数据
(注意:普通业务表的数据不在这里!)文件系统表现:
bash
/var/lib/mysql/
├── mydatabase/ # 业务数据库
│ ├── users.ibd ← 业务表数据在这里!
│ ├── orders.ibd ← 业务表数据在这里!
│ ├── products.ibd ← 业务表数据在这里!
│ └── logs.ibd ← 业务表数据在这里!
├── mysql.ibd # 数据字典(MySQL 8.0+)
└── ibdata1 # 仅系统数据(不包含用户表数据)2.3.3 参数配置与模式切换
sql
-- 查看当前表空间模式
SHOW VARIABLES LIKE 'innodb_file_per_table';
-- 动态切换(只影响新创建的表)
SET GLOBAL innodb_file_per_table = ON;
-- 永久配置(在my.cnf中)
[mysqld]
innodb_file_per_table = ON2.3.4 两种模式的对比分析
- 共享表空间模式(innodb_file_per_table = OFF)
- 优点:
- 减少文件数量,避免操作系统文件数限制
- 表空间管理相对简单
- 缺点:
- 空间无法回收:删除表后空间不释放,只能被新数据重用
- 性能瓶颈:单个大文件可能成为IO瓶颈
- 备份困难:无法单独备份特定表
- 迁移复杂:表空间传输功能受限
- 优点:
- 独立表空间模式(innodb_file_per_table = ON)
- 优点:
- 空间可回收:
DROP TABLE立即释放磁盘空间 - 性能优化:每个表有独立文件,IO更分散
- 备份灵活:支持单独备份和恢复表
- 高级功能:支持表压缩、传输表空间等
- 空间可回收:
- 缺点:
- 可能产生大量文件,需要考虑文件系统限制
- 需要更多的文件描述符
- 优点:
2.3.5 实际环境中的ibdata1管理
- 查看ibdata1使用情况
sql
-- 查看表空间使用情况
SELECT
FILE_NAME,
TABLESPACE_NAME,
ENGINE,
TOTAL_EXTENTS,
EXTENT_SIZE,
(TOTAL_EXTENTS * EXTENT_SIZE)/1024/1024 as SIZE_MB
FROM information_schema.FILES
WHERE FILE_NAME LIKE '%ibdata%';- 监控ibdata1增长
bash
# 监控ibdata1文件大小变化
watch -n 60 'ls -lh /usr/local/mysql/data/ibdata1'
# 查看文件详细信息
sudo ls -la /usr/local/mysql/data/ibdata13. MySQL数据记录删除流程
3.1 记录级别的删除与复用
在InnoDB的B+树索引结构中,删除操作采用巧妙的"标记-复用"策略:
sql
-- 当执行DELETE语句时
DELETE FROM table WHERE id = 500;实际发生的过程:
- 标记删除:InnoDB只是将R4这条记录标记为"已删除",并在记录头设置删除标志位
- 空间保留:记录的物理位置仍然保留在数据页中,磁盘文件大小不变
- 条件复用:只有后续插入的记录的ID值在300-600范围内,才能复用这个位置
关键限制:记录复用有严格的区间限制。如果删除ID=500的记录后插入ID=800的记录,无法复用原位置。
3.2 数据页级别的删除与复用
当更极端的情况发生------整个数据页的所有记录都被删除时,整个页可以被复用:
sql
-- 删除page A数据页上的所有记录
DELETE FROM table WHERE id BETWEEN 300 AND 600;页级复用的优势:
- 完全复用:整个page A被标记为可复用
- 无范围限制:可以被任何需要新页的插入操作复用,比如插入ID=50的记录
- 智能合并:如果相邻两个页的利用率都很低,InnoDB会自动合并它们
3.3 全表删除的特殊情况
sql
-- 删除整个表的数据
DELETE FROM table;结果:所有数据页都被标记为可复用,但磁盘文件大小依然不变。这些可复用但未被使用的空间就是"空洞"。
4. 数据库表碎片:增删改操作的空间代价
4.1 碎片的本质定义
碎片就是数据文件中存在的"空洞"------已被标记为可复用但尚未被实际使用的存储空间。
4.2 碎片产生的三大源头
4.2.1 删除操作产生的碎片
如前所述,DELETE操作在页内留下空洞,形成页内碎片:
关键特点:
- 删除操作只是标记空间可复用,不立即释放
- 空洞只能被符合条件的新记录复用
- 多个删除操作会导致页内出现多个空洞
4.2.2 插入操作产生的碎片
当数据页已满时,新记录插入会触发页分裂,这是碎片产生的重要机制:
页分裂的后果:
- 两个页都未达到最佳利用率
- 增加了额外的存储开销
- 破坏了数据的物理顺序性
4.2.3 更新操作产生的碎片
UPDATE操作可以理解为"删除旧值 + 插入新值"的组合:
- 如果新值比旧值大,可能需要在其他位置存储
- 旧位置留下空洞,新位置可能触发页分裂
4.3 碎片的双重影响
4.3.1 空间影响
空间问题表现:
- 表文件体积庞大,但实际数据量较小
- 磁盘空间占用持续增长,即使删除了大量数据
- 备份文件大小异常,包含大量无效空间
4.3.2 性能影响
具体性能问题:
- 读取放大:需要访问更多数据页获取相同数据
- 缓存污染:宝贵的内存缓存了无效的空洞数据
- IO效率低:随机IO比例增加,顺序IO减少
5. 碎片的解决方案
5.1 碎片监控
- 使用系统表检测碎片
sql
-- 检查表的碎片情况
SELECT
TABLE_NAME AS '表名',
ENGINE AS '存储引擎',
TABLE_ROWS AS '行数',
ROUND(DATA_LENGTH/1024/1024, 2) AS '数据大小(MB)',
ROUND(INDEX_LENGTH/1024/1024, 2) AS '索引大小(MB)',
ROUND(DATA_FREE/1024/1024, 2) AS '碎片空间(MB)',
ROUND((DATA_FREE / (DATA_LENGTH + INDEX_LENGTH)) * 100, 2) AS '碎片率(%)'
FROM information_schema.TABLES
WHERE TABLE_SCHEMA = 'your_database'
ORDER BY DATA_FREE DESC;- 碎片率判断标准
5.2 碎片治理:表重建OPTIMIZE TABLE 工作原理
5.3 表重建的具体方法
5.3.1 方法1:使用 OPTIMIZE TABLE
sql
-- 标准的表优化命令
OPTIMIZE TABLE your_table;
-- 监控优化进度(需要开启性能模式)
SELECT * FROM performance_schema.events_stages_current
WHERE EVENT_NAME LIKE '%optimize%';5.3.2 方法2:使用 ALTER TABLE
sql
-- 通过修改存储引擎重建表
ALTER TABLE your_table ENGINE=InnoDB;
-- 带压缩的重建(如果支持)
ALTER TABLE your_table ENGINE=InnoDB ROW_FORMAT=COMPRESSED;5.3.3 方法3:手动重建
sql
-- 创建新表
CREATE TABLE new_table LIKE your_table;
-- 按主键顺序插入数据
INSERT INTO new_table SELECT * FROM your_table ORDER BY primary_key_column;
-- 原子切换
RENAME TABLE your_table TO old_table, new_table TO your_table;
-- 清理
DROP TABLE old_table;6. 总结
通过本文的深入探讨,我们全面解析了MySQL数据库碎片的产生机制、影响范围及解决方案。碎片问题作为数据库运维中的"隐形杀手",其影响远不止于磁盘空间的浪费,更关乎系统整体性能和长期稳定运行。
有效的碎片管理需要技术手段与管理策略的完美结合:
- 技术层面:掌握OPTIMIZE TABLE、ALTER TABLE等工具的正确使用时机
- 监控层面:建立碎片率的预警机制和健康度评估体系
- 架构层面:通过合理的数据生命周期管理减少碎片产生
- 流程层面:将碎片优化纳入常规维护流程,形成制度化操作
思考与探讨
-
性能与成本的平衡:在高并发业务场景下,频繁的表重建可能影响服务可用性。如何在保证业务连续性的前提下有效管理碎片?
-
大数据量的特殊处理:对于TB级别的海量数据表,全表重建可能不现实。是否有更智能的增量优化策略?
-
多引擎混合环境:在使用InnoDB与MyISAM混合存储的环境中,碎片管理策略应该如何差异化制定?
-
预防优于治理:除了事后优化,我们能否通过更好的数据库设计(如合理选择主键、使用分区表等)从源头上减少碎片产生?
数据库碎片管理是一门既需要深厚技术功底,又需要丰富实践经验的学问。希望通过本文的分享,能够帮助大家建立完整的碎片认知体系,在实际工作中游刃有余地应对各种存储挑战,让数据库始终保持最佳性能状态。