
一、Apache Airflow 是什么?
Apache Airflow is an open-source platform to programmatically author, schedule, and monitor workflows.
------ Apache Airflow 官网
- 起源:由 Airbnb 于 2014 年开发,2016 年开源,2019 年成为 Apache 顶级项目。
- 定位 :工作流编排引擎 (Workflow Orchestration),用于调度和监控有向无环图(DAG)形式的任务依赖。
- 核心理念 :代码即配置(Code as Configuration)------ 所有工作流用 Python 编写,版本可控、可测试、可复用。
✅ 关键验证:
- GitHub Stars: 33k+(截至 2025 年,数据工程领域最高之一)
- Apache 状态:Top-Level Project(活跃度高,月均数百次 commits)
- 生产采用:Google Cloud Composer、AWS MWAA、Microsoft Azure Data Factory 均基于或兼容 Airflow
- Stack Overflow 2024 调查:62% 的数据工程师使用 Airflow
二、核心能力
1. DAG 驱动的工作流编排
- 每个工作流是一个 DAG (Directed Acyclic Graph),由多个 Task 组成。
- 支持复杂依赖:
task_a >> task_b表示 a 成功后执行 b。 - 内置多种 Operator (任务类型):
BashOperator:执行 shell 命令PythonOperator:调用 Python 函数PostgresOperator/MySqlOperator:执行 SQLEmailOperator:发送邮件KubernetesPodOperator:在 K8s 中运行容器
2. 强大的调度与重试机制
- 支持 cron 表达式或 timedelta 调度(如
@daily,*/5 * * * *) - 自动处理 任务失败重试(可配置次数、间隔)
- 支持 回填(Backfill):补跑历史数据
- 任务超时控制:避免僵尸任务占用资源
3. 可视化监控与告警
- Web UI 实时展示 DAG 状态、任务日志、依赖关系
- 支持 SLA 监控:任务超时自动标记
- 集成告警渠道:Email、Slack、钉钉、PagerDuty(通过 Callbacks)
4. 可扩展架构
- Executor 模式灵活切换 :
SequentialExecutor(单机调试)LocalExecutor(多进程,适合中小规模)CeleryExecutor/KubernetesExecutor(分布式,生产推荐)
- 支持自定义 Operator、Hook、Sensor
5. 安全与权限
- 基于角色的访问控制(RBAC)
- 支持 LDAP/OAuth 集成
- 敏感变量加密存储(通过
airflow variables+ Fernet key)
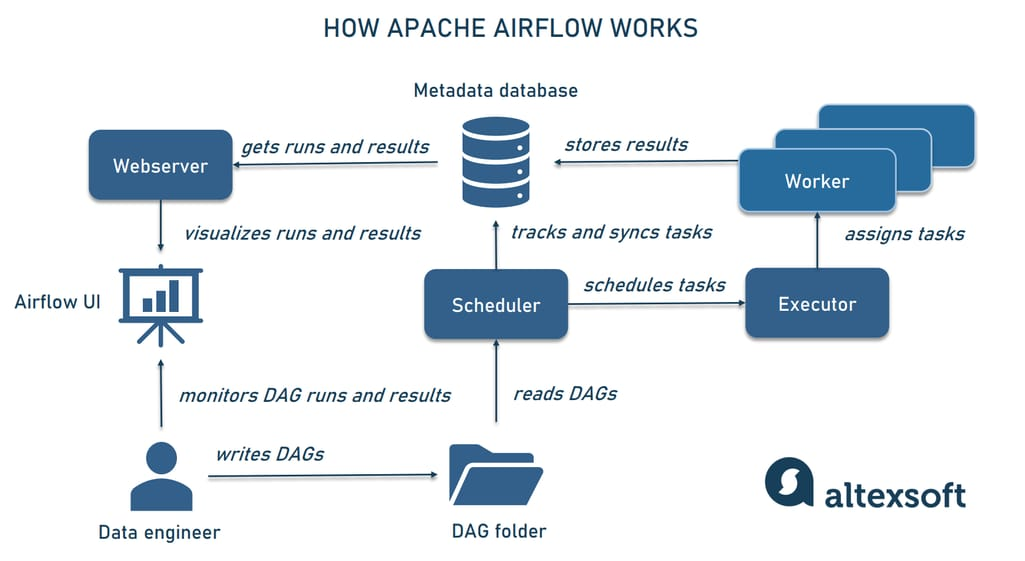
三、不适合的场景(客观局限)
| 场景 | 原因 |
|---|---|
| 实时流处理 | Airflow 是批调度引擎,非 Flink/Spark Streaming 替代品 |
| 高频任务(秒级触发) | 最小调度粒度为分钟级,不适用于毫秒/秒级场景 |
| 无依赖的简单脚本 | 若仅需定时执行单脚本,cron 更轻量 |
📌 验证:Airflow 官方 FAQ 明确指出:"Airflow is not a streaming solution."
四、快速实践:5 步运行第一个 DAG
目标:每日从 PostgreSQL 提取 GMV 数据 → 生成日报 → 发送邮件
步骤 1:安装 Airflow(单机版)
bash
# 推荐使用 pip(Python ≥ 3.8)
pip install apache-airflow==2.8.1 --constraint "https://raw.githubusercontent.com/apache/airflow/constraints-2.8.1/constraints-3.8.txt"
# 初始化数据库
airflow db init
# 创建管理员账号
airflow users create \
--username admin \
--firstname Admin \
--lastname User \
--role Admin \
--email admin@example.com \
--password admin
# 启动 Web Server 和 Scheduler
airflow webserver --port 8080
airflow scheduler访问
http://localhost:8080,登录账号admin/admin
步骤 2:配置数据库连接
- 在 Web UI → Admin → Connections 添加 PostgreSQL 连接:
- Conn Id:
pg_ods - Conn Type:
PostgreSQL - Host/Schema/Username/Password 按实际填写
- Conn Id:
步骤 3:编写 DAG 文件(dags/gmv_daily.py)
python
from datetime import datetime, timedelta
from airflow import DAG
from airflow.providers.postgres.operators.postgres import PostgresOperator
from airflow.operators.email import EmailOperator
default_args = {
'owner': 'data_team',
'retries': 2,
'retry_delay': timedelta(minutes=5),
}
dag = DAG(
'gmv_daily_report',
default_args=default_args,
description='Daily GMV Aggregation',
schedule_interval='0 2 * * *', # 每天凌晨2点
start_date=datetime(2025, 1, 1),
catchup=False,
)
extract_gmv = PostgresOperator(
task_id='extract_gmv',
postgres_conn_id='pg_ods',
sql="""
INSERT INTO ads.daily_gmv (dt, gmv)
SELECT '{{ ds }}', SUM(amount)
FROM dwd.fact_order
WHERE dt = '{{ ds }}' AND status = 'paid';
""",
dag=dag,
)
send_report = EmailOperator(
task_id='send_email',
to='ops@example.com',
subject='GMV Daily Report - {{ ds }}',
html_content='GMV for {{ ds }} has been updated.',
dag=dag,
)
extract_gmv >> send_report步骤 4:放置 DAG 文件
- 将
gmv_daily.py放入 Airflow 的dags_folder(默认~/airflow/dags) - Web UI 会自动加载(每 30 秒扫描一次)
步骤 5:触发与监控
- 在 UI 中点击 Trigger DAG 手动运行
- 查看 Graph View 和 Logs 确认执行成功
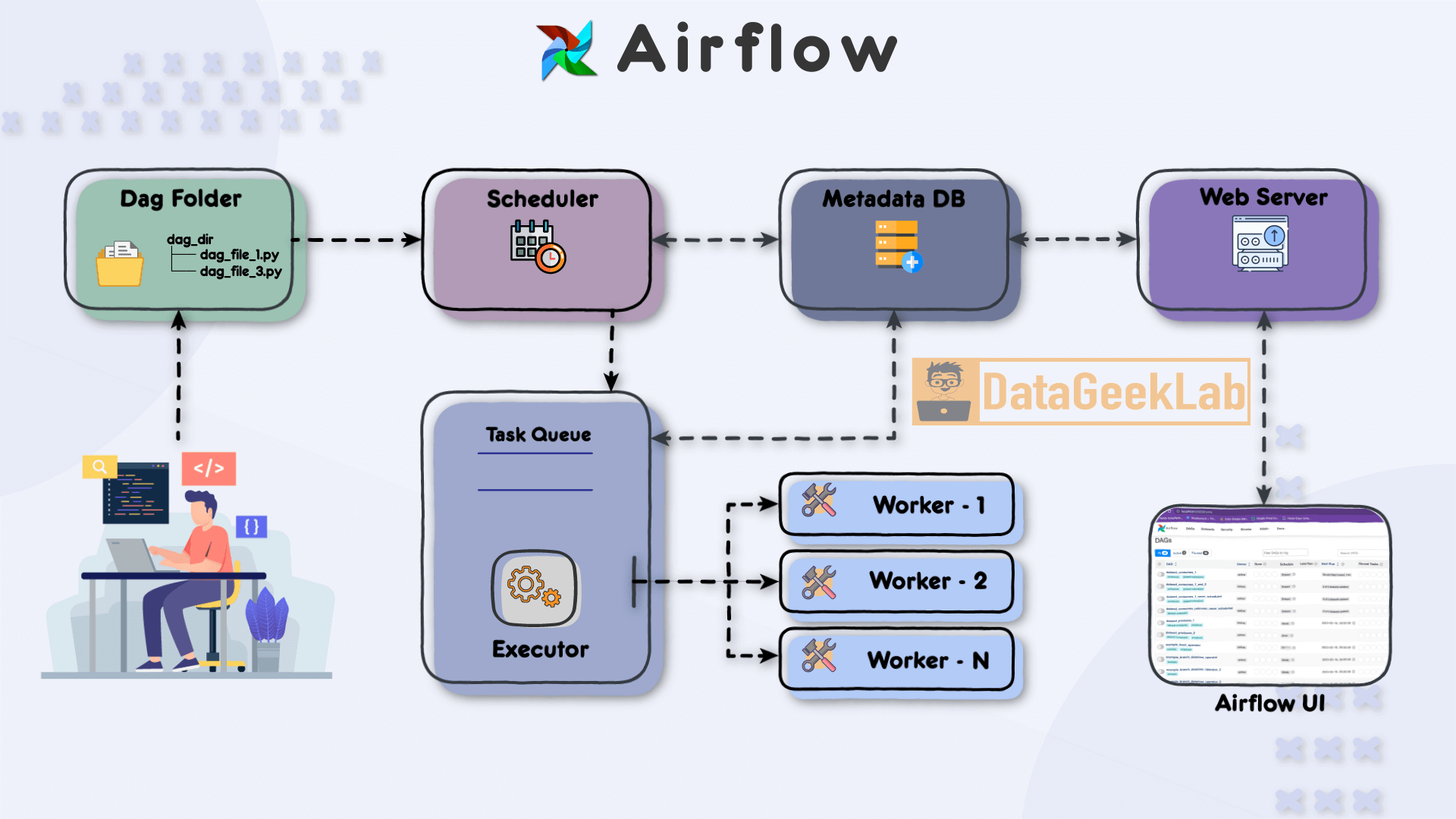
五、生产部署建议
| 项目 | 推荐方案 |
|---|---|
| Executor | KubernetesExecutor(云原生)或 CeleryExecutor(自建集群) |
| 元数据存储 | PostgreSQL 或 MySQL(不要用 SQLite) |
| 日志存储 | S3 / MinIO / HDFS(避免本地磁盘) |
| 监控 | Prometheus + Grafana(Airflow 内置 metrics) |
| CI/CD | Git 管理 DAG,通过 CI 测试后部署 |
✅ 验证:Google Cloud Composer、AWS MWAA 均采用上述架构。
六、权威学习资源
| 类型 | 链接 |
|---|---|
| 官方文档 | https://airflow.apache.org/docs/ |
| GitHub | https://github.com/apache/airflow |
| 社区 | https://airflow.apache.org/community/ |
| 示例 DAG 库 | https://github.com/apache/airflow/tree/main/airflow/example_dags |
| 视频教程 | Astronomer.io(Airflow 核心贡献者运营) |
✅ 结论
Apache Airflow 是构建轻量级数据中台"调度与开发层"的事实标准,尤其适合:
- 需要可靠调度 SQL/Python 脚本的企业
- 追求工作流可视化与可观测性的团队
- 希望用代码管理 ETL 逻辑的工程化组织
但它不是数据处理引擎,应与 PostgreSQL(存储)、NiFi(接入)、FastAPI(服务)协同使用。